기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
화자 파티셔닝(분할)
화자 분할을 사용하면 트랜스크립션 출력에서 서로 다른 화자를 구분할 수 있습니다. Amazon Transcribe 는 최대 30개의 고유한 화자를 구분할 수 있으며 각 고유한 화자의 텍스트에 고유한 값(spk_0~)으로 레이블을 지정할 수 있습니다spk_9.
화자 파티셔닝이 활성화된 요청에는 표준 트랜스크립트 섹션(transcripts 및 items) 외에도 speaker_labels 섹션이 포함됩니다. 이 섹션은 화자별로 그룹화되어 있으며 화자 레이블과 타임스탬프를 포함하여 각 발화에 대한 정보를 포함합니다.
"speaker_labels": {
"channel_label": "ch_0",
"speakers": 2,
"segments": [
{
"start_time": "4.87",
"speaker_label": "spk_0",
"end_time": "6.88",
"items": [
{
"start_time": "4.87",
"speaker_label": "spk_0",
"end_time": "5.02"
},
...
{
"start_time": "8.49",
"speaker_label": "spk_1",
"end_time": "9.24",
"items": [
{
"start_time": "8.49",
"speaker_label": "spk_1",
"end_time": "8.88"
},화자 파티셔닝(화자 2명)이 포함된 전체 트랜스크립트 예시를 보려면 분할 출력 예시(배치)를 참조하세요.
배치 트랜스크립션의 화자 파티셔닝
배치 트랜스크립션에서 화자를 파티셔닝하려면 다음 예를 참조하세요.
-
AWS Management Console
에 로그인합니다. -
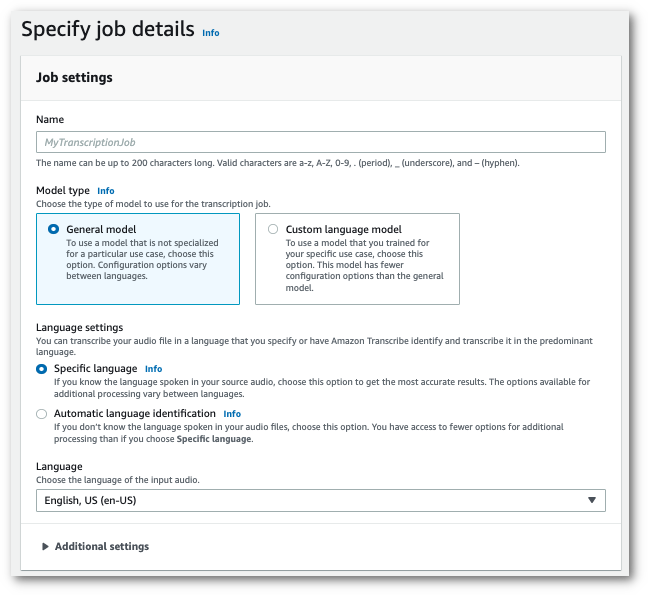
탐색 창에서 트랜스크립션 작업을 선택한 다음 작업 생성(오른쪽 상단)을 선택합니다. 그러면 작업 세부 정보 지정 페이지가 열립니다.
-
작업 세부 정보 지정 페이지에 포함하려는 필드를 모두 채운 후 다음을 선택합니다. 그러면 작업 구성 - 선택 사항 페이지로 이동합니다.
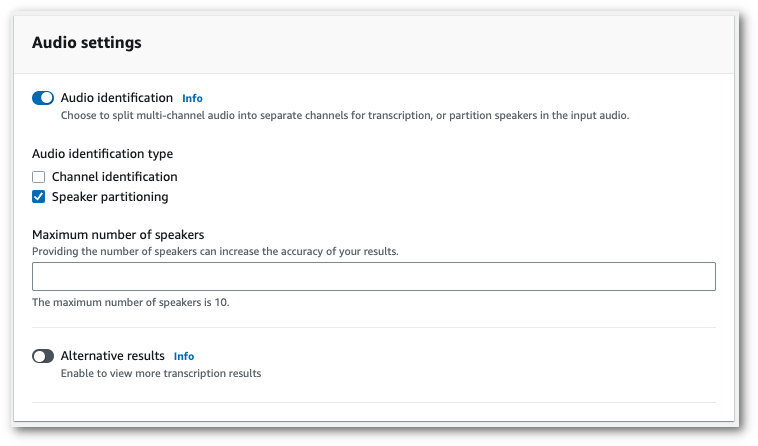
오디오 설정 패널에서 화자 파티셔닝('오디오 식별 유형' 제목 아래)을 선택합니다. 파티셔닝하려는 화자 수를 최대 10개까지 선택적으로 지정할 수 있습니다.
-
작업 생성을 선택하여 트랜스크립션 작업을 실행합니다.
-
AWS Management Console
에 로그인합니다. -
탐색 창에서 트랜스크립션 작업을 선택한 다음 작업 생성(오른쪽 상단)을 선택합니다. 그러면 작업 세부 정보 지정 페이지가 열립니다.
-
작업 세부 정보 지정 페이지에 포함하려는 필드를 모두 채운 후 다음을 선택합니다. 그러면 작업 구성 - 선택 사항 페이지로 이동합니다.
오디오 설정 패널에서 화자 파티셔닝('오디오 식별 유형' 제목 아래)을 선택합니다. 파티셔닝하려는 화자 수를 최대 10개까지 선택적으로 지정할 수 있습니다.
-
작업 생성을 선택하여 트랜스크립션 작업을 실행합니다.
이 예시에서는 start-transcription-jobStartTranscriptionJob 단원을 참조하십시오.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --language-codeen-US\ --settings ShowSpeakerLabels=true,MaxSpeakerLabels=3
다음은 start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://my-first-transcription-job.json
my-first-transcription-job.json 파일에는 다음과 같은 요청 본문이 포함되어 있습니다.
{
"TranscriptionJobName": "my-first-transcription-job",
"Media": {
"MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac"
},
"OutputBucketName": "amzn-s3-demo-bucket",
"OutputKey": "my-output-files/",
"LanguageCode": "en-US",
"ShowSpeakerLabels": 'TRUE',
"MaxSpeakerLabels": 3
}이 예제에서는 AWS SDK for Python (Boto3) 를 사용하여 start_transcription_job
from __future__ import print_function
import time
import boto3
transcribe = boto3.client('transcribe', 'us-west-2')
job_name = "my-first-transcription-job"
job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac"
transcribe.start_transcription_job(
TranscriptionJobName = job_name,
Media = {
'MediaFileUri': job_uri
},
OutputBucketName = 'amzn-s3-demo-bucket',
OutputKey = 'my-output-files/',
LanguageCode = 'en-US',
Settings = {
'ShowSpeakerLabels': True,
'MaxSpeakerLabels': 3
}
)
while True:
status = transcribe.get_transcription_job(TranscriptionJobName = job_name)
if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']:
break
print("Not ready yet...")
time.sleep(5)
print(status)스트리밍 트랜스크립션의 화자 파티셔닝
스트리밍 트랜스크립션에서 화자를 파티셔닝하려면 다음 예를 참조하세요.
-
AWS Management Console
에 로그인합니다. -
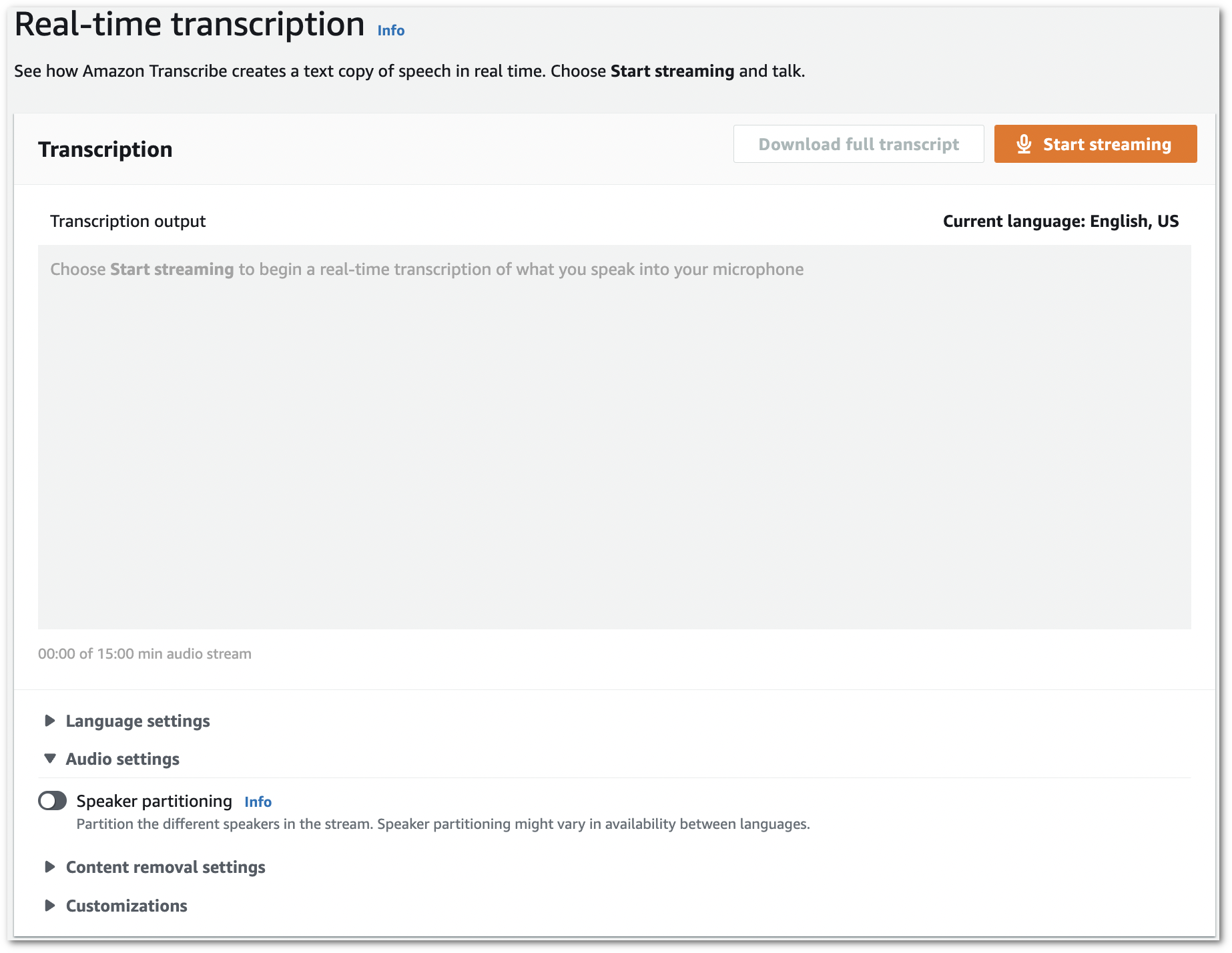
탐색 창에서 실시간 트랜스크립션을 선택합니다. 오디오 설정까지 아래로 스크롤하고 최소화된 경우 이 필드를 확장합니다.
-
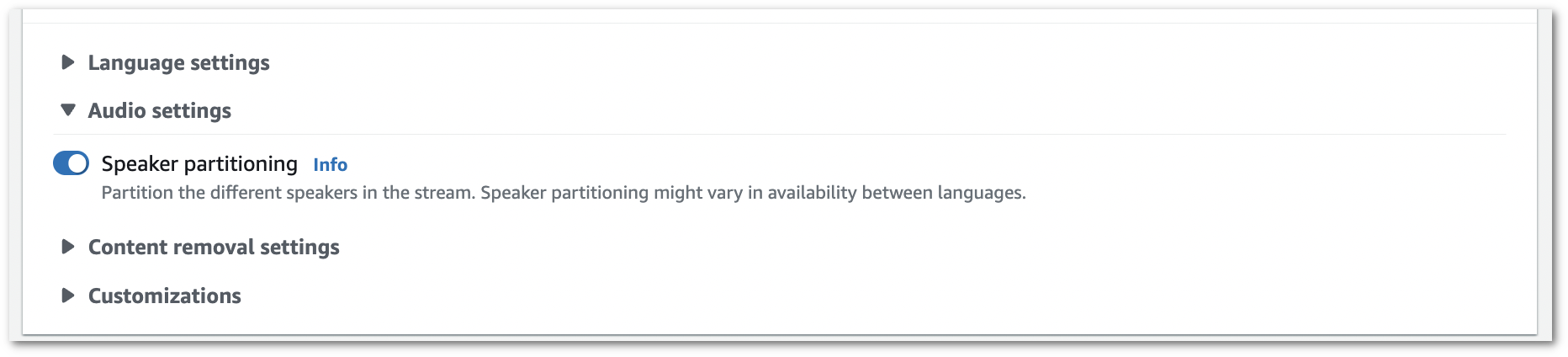
화자 파티셔닝을 켭니다.
-
이제 스트림을 트랜스크립션할 준비가 되었습니다. 스트리밍 시작을 선택하고 말하기 시작합니다. 구술을 끝내려면 스트리밍 중지를 선택합니다.
-
AWS Management Console
에 로그인합니다. -
탐색 창에서 실시간 트랜스크립션을 선택합니다. 오디오 설정까지 아래로 스크롤하고 최소화된 경우 이 필드를 확장합니다.
-
화자 파티셔닝을 켭니다.
-
이제 스트림을 트랜스크립션할 준비가 되었습니다. 스트리밍 시작을 선택하고 말하기 시작합니다. 구술을 끝내려면 스트리밍 중지를 선택합니다.
이 예시에서는 트랜스크립션 출력에서 화자를 파티셔닝하는 HTTP/2 요청을 생성합니다. 에서 HTTP/2 스트리밍을 사용하는 방법에 대한 자세한 내용은 섹션을 Amazon Transcribe참조하세요HTTP/2 스트림 설정. Amazon Transcribe관련 파라미터 및 헤더에 대한 자세한 내용은 StartStreamTranscription을 참조하세요.
POST /stream-transcription HTTP/2
host: transcribestreaming.us-west-2.amazonaws.com
X-Amz-Target: com.amazonaws.transcribe.Transcribe.StartStreamTranscription
Content-Type: application/vnd.amazon.eventstream
X-Amz-Content-Sha256: string
X-Amz-Date: 20220208T235959Z
Authorization: AWS4-HMAC-SHA256 Credential=access-key/20220208/us-west-2/transcribe/aws4_request, SignedHeaders=content-type;host;x-amz-content-sha256;x-amz-date;x-amz-target;x-amz-security-token, Signature=string
x-amzn-transcribe-language-code: en-US
x-amzn-transcribe-media-encoding: flac
x-amzn-transcribe-sample-rate: 16000
x-amzn-transcribe-show-speaker-label: true
transfer-encoding: chunked파라미터 정의는 API 참조에서 찾을 수 있습니다. 모든 AWS API 작업에 공통적인 파라미터는 공통 파라미터 섹션에 나열되어 있습니다.
이 예시에서는 트랜스크립션 출력에서 화자를 구분하는 미리 서명된 URL을 생성합니다. 가독성을 높이기 위해 줄바꿈이 추가되었습니다. 에서 WebSocket 스트림을 사용하는 방법에 대한 자세한 내용은 섹션을 Amazon Transcribe참조하세요WebSocket 스트림 설정. 파라미터에 대한 자세한 내용은 StartStreamTranscription을 참조하세요.
GET wss://transcribestreaming.us-west-2.amazonaws.com:8443/stream-transcription-websocket? &X-Amz-Algorithm=AWS4-HMAC-SHA256 &X-Amz-Credential=AKIAIOSFODNN7EXAMPLE%2F20220208%2Fus-west-2%2Ftranscribe%2Faws4_request &X-Amz-Date=20220208T235959Z &X-Amz-Expires=300&X-Amz-Security-Token=security-token&X-Amz-Signature=string&X-Amz-SignedHeaders=content-type%3Bhost%3Bx-amz-date &language-code=en-US &specialty=PRIMARYCARE&type=DICTATION&media-encoding=flac&sample-rate=16000&show-speaker-label=true
파라미터 정의는 API 참조에서 찾을 수 있습니다. 모든 AWS API 작업에 공통적인 파라미터는 공통 파라미터 섹션에 나열되어 있습니다.
