기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
통화 후 자막의 범주 생성
통화 후 분석은 사용자 지정 범주 생성을 지원하므로 특정 비즈니스 요구 사항에 가장 적합하도록 트랜스크립트 분석을 조정할 수 있습니다.
다양한 시나리오를 다루기 위해 원하는 만큼 범주를 생성할 수 있습니다. 범주를 하나 생성할 때마다 1~20개의 규칙을 생성해야 합니다. 각 규칙은 중단, 키워드, 침묵 시간, 감정 등 4가지 기준 중 하나를 기반으로 합니다. CreateCallAnalyticsCategory 작업에 이러한 기준을 사용하는 방법에 대한 자세한 내용은 통화 후 분석 범주의 규칙 기준 섹션을 참조하세요.
미디어의 콘텐츠가 특정 범주에서 지정한 모든 규칙과 일치하는 경우 Amazon Transcribe 에서는 해당 범주로 출력에 레이블을 지정합니다. JSON 출력의 범주 일치 예는 통화 분류 출력을 참조하세요.
사용자 지정 범주로 수행할 수 있는 작업의 몇 가지 예는 다음과 같습니다.
-
부정적인 고객 감정으로 끝나는 통화와 같이 특정 특성을 가진 통화를 분리합니다.
-
특정 키워드 세트에 플래그를 지정하고 추적하여 고객 문제의 추세를 파악합니다.
-
에이전트가 통화 후 처음 몇 초 동안 특정 구절을 말하거나 생략하는 등, 규정 준수를 모니터링합니다.
-
에이전트의 중단이 많고 부정적인 고객 감정이 있는 통화에 플래그를 지정하여 고객 경험에 대한 인사이트를 확보합니다.
-
환영 문구를 사용하는 에이전트가 긍정적인 고객 감정과 상관관계가 있는지 분석하는 등 여러 범주를 비교하여 상관관계를 측정합니다.
통화 후 범주와 실시간 범주의 비교
새 범주를 만들 때 해당 범주를 통화 후 분석 범주(POST_CALL)로 생성할지 아니면 실시간 Call Analytics 범주(REAL_TIME)로 생성할지 지정할 수 있습니다. 옵션을 지정하지 않으면 기본적으로 범주가 통화 후 범주로 생성됩니다. 통화 후 분석 트랜스크립션이 완료되면 출력에서 통화 후 분석 범주 일치를 확인할 수 있습니다.
통화 후 분석을 위한 새 범주를 생성하려면 AWS Management Console, AWS CLI 또는 AWS SDK를 사용할 수 있습니다. 예를 보려면 다음을 참조하세요.
-
탐색 창의 아래에서 Amazon Transcribe Call Analytics를 Amazon Transcribe선택합니다.
-
통화 분석 범주를 선택하면 통화 분석 범주 페이지로 이동합니다. 범주 생성을 선택합니다.

-
이제 범주 생성 페이지로 이동했습니다. 범주 이름을 입력한 다음 범주 유형 드롭다운 메뉴에서 '배치 통화 분석'을 선택합니다.

-
템플릿을 선택하여 범주를 생성하거나 처음부터 새로 생성할 수 있습니다.
템플릿을 사용하는 경우: 템플릿 사용(권장)을 선택하고 원하는 템플릿과 범주 생성을 차례로 선택합니다.
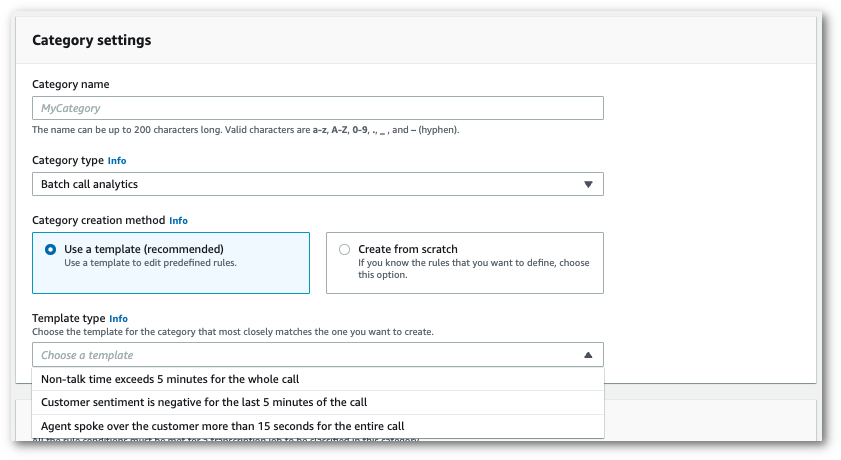
-
사용자 지정 범주를 생성하는 경우: 새로 생성을 선택합니다.
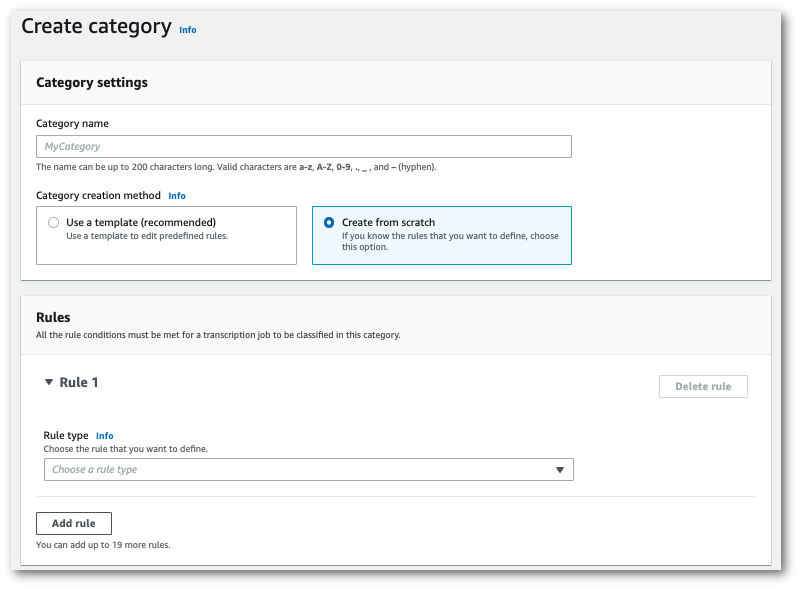
-
드롭다운 메뉴를 사용하여 범주에 규칙을 추가합니다. 범주당 최대 20개의 규칙을 추가할 수 있습니다.
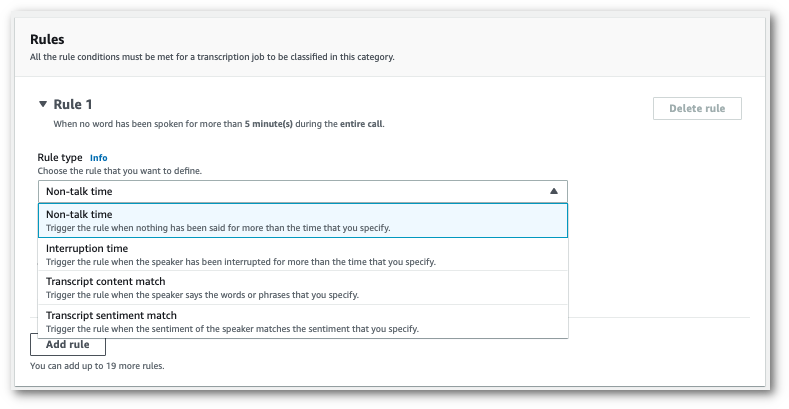
-
다음은 두 가지 규칙이 있는 범주의 예입니다. 하나는 통화 중에 15초 이상 고객의 말을 끊는 에이전트이고, 하나는 통화 마지막 2분 동안 고객 또는 에이전트가 느낀 부정적인 감정입니다.
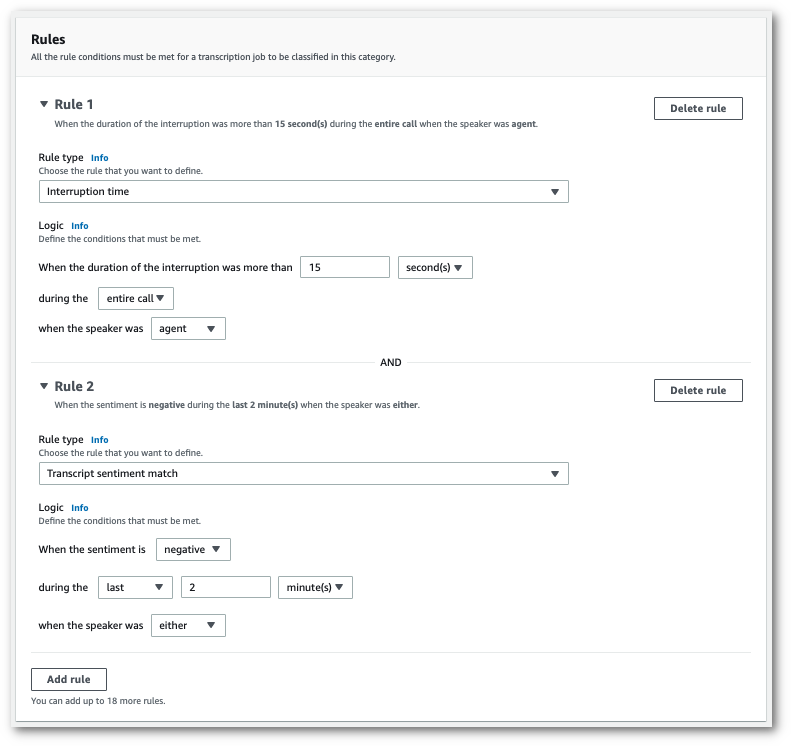
-
범주에 규칙을 모두 추가했으면 범주 생성을 선택합니다.
-
탐색 창의 아래에서 Amazon Transcribe Call Analytics를 Amazon Transcribe선택합니다.
-
통화 분석 범주를 선택하면 통화 분석 범주 페이지로 이동합니다. 범주 생성을 선택합니다.
-
이제 범주 생성 페이지로 이동했습니다. 범주 이름을 입력한 다음 범주 유형 드롭다운 메뉴에서 '배치 통화 분석'을 선택합니다.
-
템플릿을 선택하여 범주를 생성하거나 처음부터 새로 생성할 수 있습니다.
템플릿을 사용하는 경우: 템플릿 사용(권장)을 선택하고 원하는 템플릿과 범주 생성을 차례로 선택합니다.
-
사용자 지정 범주를 생성하는 경우: 새로 생성을 선택합니다.
-
드롭다운 메뉴를 사용하여 범주에 규칙을 추가합니다. 범주당 최대 20개의 규칙을 추가할 수 있습니다.
-
다음은 두 가지 규칙이 있는 범주의 예입니다. 하나는 통화 중에 15초 이상 고객의 말을 끊는 에이전트이고, 하나는 통화 마지막 2분 동안 고객 또는 에이전트가 느낀 부정적인 감정입니다.
-
범주에 규칙을 모두 추가했으면 범주 생성을 선택합니다.
이 예에서는 create-call-analytics-categoryCreateCallAnalyticsCategory, CategoryProperties, Rule 섹션을 참조하세요.
다음 예에서는 규칙을 사용하여 범주를 생성합니다.
-
고객은 처음 60,000밀리초 내에 방해를 받았습니다. 이러한 중단의 지속 시간은 최소 10,000밀리초였습니다.
-
통화 시작 후 10%와 80% 사이에 최소 20,000밀리초 동안 침묵이 지속되었습니다.
-
에이전트는 통화 중 어느 시점에서 부정적인 감정을 느꼈습니다.
-
통화의 첫 10,000밀리초 동안 "환영합니다" 또는 "안녕하세요"라는 단어를 사용하지 않았습니다.
이 예에서는 create-call-analytics-category
aws transcribe create-call-analytics-category \ --cli-input-json file://filepath/my-first-analytics-category.json
my-first-analytics-category.json 파일에는 다음과 같은 요청 본문이 포함되어 있습니다.
{
"CategoryName": "my-new-category",
"InputType": "POST_CALL",
"Rules": [
{
"InterruptionFilter": {
"AbsoluteTimeRange": {
"First": 60000
},
"Negate": false,
"ParticipantRole": "CUSTOMER",
"Threshold": 10000
}
},
{
"NonTalkTimeFilter": {
"Negate": false,
"RelativeTimeRange": {
"EndPercentage": 80,
"StartPercentage": 10
},
"Threshold": 20000
}
},
{
"SentimentFilter": {
"ParticipantRole": "AGENT",
"Sentiments": [
"NEGATIVE"
]
}
},
{
"TranscriptFilter": {
"Negate": true,
"AbsoluteTimeRange": {
"First": 10000
},
"Targets": [
"welcome",
"hello"
],
"TranscriptFilterType": "EXACT"
}
}
]
}이 예제에서는 AWS SDK for Python (Boto3) 를 사용하여 create_call_analytics_categoryCategoryName 및 Rules 인수를 사용하여 범주를 생성합니다. 자세한 내용은 CreateCallAnalyticsCategory, CategoryProperties, Rule 섹션을 참조하세요.
기능별, 시나리오 및 교차 서비스 예제 AWS SDKs를 사용하는 추가 예제는 AWS SDKs를 사용한 Amazon Transcribe의 코드 예제장을 참조하세요.
다음 예에서는 규칙을 사용하여 범주를 생성합니다.
-
고객은 처음 60,000밀리초 내에 방해를 받았습니다. 이러한 중단의 지속 시간은 최소 10,000밀리초였습니다.
-
통화 시작 후 10%와 80% 사이에 최소 20,000밀리초 동안 침묵이 지속되었습니다.
-
에이전트는 통화 중 어느 시점에서 부정적인 감정을 느꼈습니다.
-
통화의 첫 10,000밀리초 동안 "환영합니다" 또는 "안녕하세요"라는 단어를 사용하지 않았습니다.
from __future__ import print_function
import time
import boto3
transcribe = boto3.client('transcribe', 'us-west-2')
category_name = "my-new-category"
transcribe.create_call_analytics_category(
CategoryName = category_name,
InputType = POST_CALL,
Rules = [
{
'InterruptionFilter': {
'AbsoluteTimeRange': {
'First': 60000
},
'Negate': False,
'ParticipantRole': 'CUSTOMER',
'Threshold': 10000
}
},
{
'NonTalkTimeFilter': {
'Negate': False,
'RelativeTimeRange': {
'EndPercentage': 80,
'StartPercentage': 10
},
'Threshold': 20000
}
},
{
'SentimentFilter': {
'ParticipantRole': 'AGENT',
'Sentiments': [
'NEGATIVE'
]
}
},
{
'TranscriptFilter': {
'Negate': True,
'AbsoluteTimeRange': {
'First': 10000
},
'Targets': [
'welcome',
'hello'
],
'TranscriptFilterType': 'EXACT'
}
}
]
)
result = transcribe.get_call_analytics_category(CategoryName = category_name)
print(result)통화 후 분석 범주의 규칙 기준
이 섹션에서는 CreateCallAnalyticsCategory API 작업을 사용하여 생성할 수 있는 사용자 지정 POST_CALL 규칙의 유형을 간략하게 설명합니다.
중단 일치
중단(InterruptionFilter 데이터 유형)을 사용하는 규칙은 다음과 일치하도록 고안되었습니다.
-
에이전트가 고객의 말을 끊는 경우
-
고객이 에이전트의 말을 끊는 경우
-
상대방의 말을 끊는 모든 참가자
-
중단 없음
InterruptionFilter로 사용할 수 있는 파라미터의 예는 다음과 같습니다.
"InterruptionFilter": {
"AbsoluteTimeRange": {
Specify the time frame, in milliseconds, when the match should occur
},
"RelativeTimeRange": {
Specify the time frame, in percentage, when the match should occur
},
"Negate": Specify if you want to match the presence or absence of interruptions,
"ParticipantRole": Specify if you want to match speech from the agent, the customer, or both,
"Threshold": Specify a threshold for the amount of time, in seconds, interruptions occurred during the call
},이러한 파라미터 및 각 파라미터와 관련된 유효한 값에 대한 자세한 내용은 CreateCallAnalyticsCategory 및 InterruptionFilter를 참조하세요.
키워드 일치
키워드(TranscriptFilter 데이터 유형)를 사용하는 규칙은 다음과 일치하도록 고안되었습니다.
-
에이전트, 고객 또는 둘 다 사용하는 사용자 지정 단어나 구절, 또는 둘 다
-
에이전트, 고객 또는 둘 다 사용하지 않는 사용자 지정 단어나 구절, 또는 둘 다
-
특정 시간대에 나오는 사용자 지정 단어 또는 구절
TranscriptFilter로 사용할 수 있는 파라미터의 예는 다음과 같습니다.
"TranscriptFilter": {
"AbsoluteTimeRange": {
Specify the time frame, in milliseconds, when the match should occur
},
"RelativeTimeRange": {
Specify the time frame, in percentage, when the match should occur
},
"Negate": Specify if you want to match the presence or absence of your custom keywords,
"ParticipantRole": Specify if you want to match speech from the agent, the customer, or both,
"Targets": [ The custom words and phrases you want to match ],
"TranscriptFilterType": Use this parameter to specify an exact match for the specified targets
}이러한 파라미터 및 각 파라미터와 관련된 유효한 값에 대한 자세한 내용은 CreateCallAnalyticsCategory 및 TranscriptFilter를 참조하세요.
침묵 시간 일치
침묵 시간(NonTalkTimeFilter 데이터 유형)을 사용하는 규칙은 다음과 일치하도록 고안되었습니다.
-
통화 중 지정된 시간 동안 무음이 유지되는 경우
-
통화 중 지정된 시간에 음성이 나오는 경우
NonTalkTimeFilter로 사용할 수 있는 파라미터의 예는 다음과 같습니다.
"NonTalkTimeFilter": {
"AbsoluteTimeRange": {
Specify the time frame, in milliseconds, when the match should occur
},
"RelativeTimeRange": {
Specify the time frame, in percentage, when the match should occur
},
"Negate": Specify if you want to match the presence or absence of speech,
"Threshold": Specify a threshold for the amount of time, in seconds, silence (or speech) occurred during the call
},이러한 파라미터 및 각 파라미터와 관련된 유효한 값에 대한 자세한 내용은 CreateCallAnalyticsCategory 및 NonTalkTimeFilter를 참조하세요.
감정 일치
감정 일치(SentimentFilter 데이터 유형)를 사용하는 규칙은 다음과 일치하도록 고안되었습니다.
-
통화의 특정 시점에서 고객, 에이전트 또는 두 사람 모두가 표현한 긍정적인 감정의 유무
-
통화의 특정 시점에서 고객, 에이전트 또는 두 사람 모두가 표현한 부정적인 감정의 유무
-
통화의 특정 시점에서 고객, 에이전트 또는 두 사람 모두가 표현한 중립적인 감정의 유무
-
통화의 특정 시점에서 고객, 에이전트 또는 두 사람 모두가 표현한 복합적인 감정의 유무
SentimentFilter로 사용할 수 있는 파라미터의 예는 다음과 같습니다.
"SentimentFilter": {
"AbsoluteTimeRange": {
Specify the time frame, in milliseconds, when the match should occur
},
"RelativeTimeRange": {
Specify the time frame, in percentage, when the match should occur
},
"Negate": Specify if you want to match the presence or absence of your chosen sentiment,
"ParticipantRole": Specify if you want to match speech from the agent, the customer, or both,
"Sentiments": [ The sentiments you want to match ]
},이러한 파라미터 및 각 파라미터와 관련된 유효한 값에 대한 자세한 내용은 CreateCallAnalyticsCategory 및 SentimentFilter를 참조하세요.
