本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
DynamoDB 的分割區與資料分配
Amazon DynamoDB 將資料存放在分割區中。分割區是資料表的儲存配置,由固態硬碟 (SSDs) 提供支援,並自動複寫至 AWS 區域內的多個可用區域。分割區管理完全是由 DynamoDB 處理,您永遠不需要自行管理分割區。
當您建立資料表時,資料表的初始狀態為 CREATING。在此階段期間,DynamoDB 會配置足夠的分割區給資料表,讓它可以處理您的佈建輸送量需求。您可以在資料表狀態變更為 ACTIVE 之後,開始寫入及讀取資料表資料。
DynamoDB 會在下列情況下配置額外的分割區給資料表:
-
如果您將資料表的佈建輸送量設定,增加到超過現有分割區所能支援的設定。
-
如果現有的分割區容量將滿且需要更多儲存空間。
分割區管理會在背景自動進行,而且對您的應用程式是透明的。您的資料表會全程可供使用,並完整支援您的佈建輸送量需求。
如需詳細資訊,請參閱分割區索引鍵設計。
DynamoDB 中的全域次要索引也是由分割區所組成。全域次要索引中的資料會與其基礎資料表中的資料分開存放,但索引分割區的運作方式與資料表分割區相同。
資料分佈:分割區索引鍵
如果您的資料表具有簡易主索引鍵 (僅限分割區索引鍵),DynamoDB 會根據每個項目的分割區索引鍵值來存放與擷取項目。
為了將項目寫入資料表,DynamoDB 使用分割區索引鍵值作為內部雜湊函數的輸入。雜湊函數的輸出值決定要存放項目的分割區。
若要讀取資料表的項目,您必須指定項目的分割區索引鍵值。DynamoDB 會使用此值作為雜湊函數的輸入,產生能夠找到此項目的分割區。
下圖顯示一個名為 Pets 的資料表,其橫跨多個分割區。該資料表的主索引鍵是 AnimalType (僅顯示此索引鍵屬性)。DynamoDB 使用其雜湊函數來判斷新項目的存放位置,在此例中是依據字串 Dog 的雜湊值。請注意,項目不會依序存放。每個項目的位置取決於其分割區索引鍵的雜湊值。
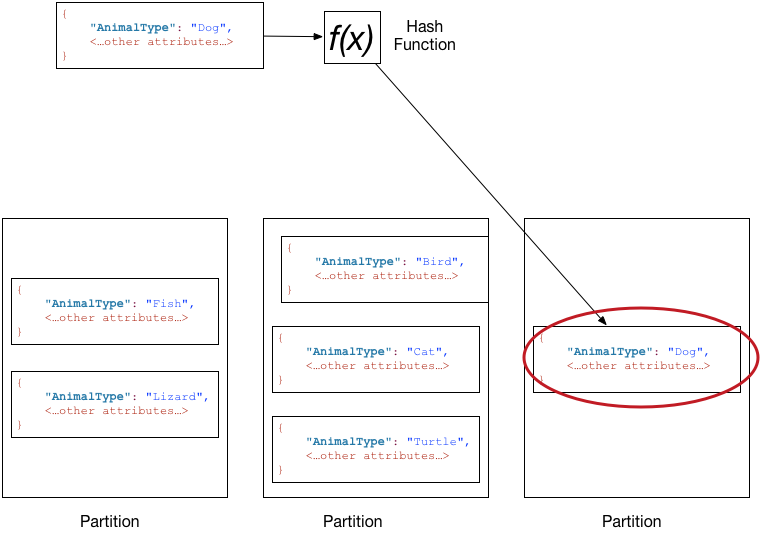
注意
DynamoDB 已經過最佳化,可將項目一致分佈到資料表的分割區,不論有多少分割區。建議您選擇相較於資料表中的項目數,可擁有大量相異值的分割區索引鍵。
資料分佈:分割區索引鍵與排序索引鍵
如果資料表具有複合主鍵 (分割區索引鍵和排序索引鍵),則 DynamoDB 會以與 資料分佈:分割區索引鍵 中所述相同的方式計算分割區索引鍵的雜湊值。系統傾向將具有相同分割區索引鍵值的項目存放在相鄰位置,並依排序索引鍵屬性的值排序。具有相同分割區索引鍵屬性值的一組項目稱為「項目集合」。項目集合經過最佳化,可高效擷取集合中指定範圍的項目。若資料表未設定本機次要索引,DynamoDB 會自動將項目集合分配至所需數量的分割區,以存放資料並維持讀寫輸送量。
為了將項目寫入資料表,DynamoDB 會計算分割區索引鍵的雜湊值,來決定哪個分割區應該包含項目。在該分割區中,多個項目可以具有相同的分割區索引鍵值。因此,DynamoDB 使用相同的分割區索引鍵將項目儲存在其他項目中,按排序索引鍵遞增排列。
若要讀取資料表的項目,您必須指定項目的分割區索引鍵值和排序索引鍵值。DynamoDB 會計算分割區索引鍵的雜湊值,產生能夠找到此項目的分割區。
如果您想要的項目具有相同的分割區索引鍵值,您可以在單一操作 (Query) 中從資料表讀取多個項目。DynamoDB 會傳回具有該分割區索引鍵值的所有項目。您可以選擇性地將條件套用至排序索引鍵,讓它只傳回特定值範圍內的項目。
假設 Pets 資料表具有複合主鍵,其中包含 AnimalType (分割區索引鍵) 與 Name (排序索引鍵)。下圖顯示 DynamoDB 寫入一個項目,其分割區索引鍵值為 Dog,排序索引鍵值為 Fido。
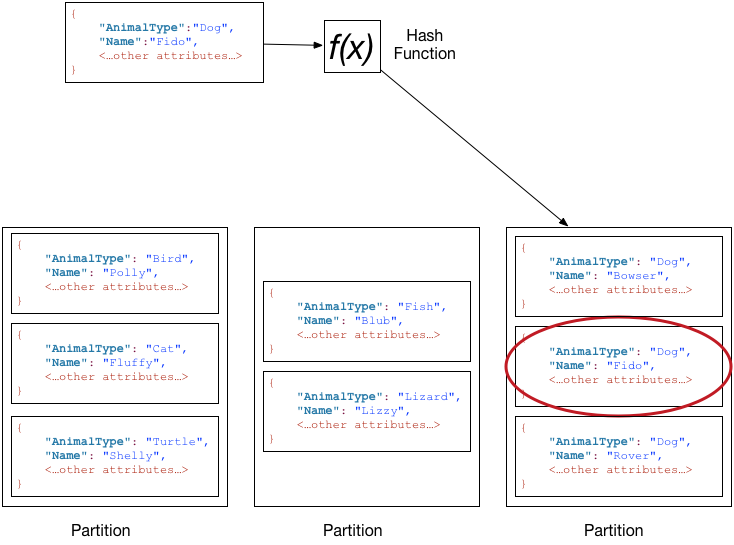
若要從 Pets 資料表讀取同樣的項目,DynamoDB 會計算 Dog 的雜湊值,產生存放這些項目的分割區。然後,DynamoDB 會掃描排序索引鍵屬性值,直到找到 Fido。
若要讀取 AnimalType 為 Dog 的所有項目,您可以發出 Query 操作,而不需要指定排序索引鍵條件。根據預設,項目會依存放順序 (即依排序索引鍵的遞增順序) 傳回。您也可以改為請求遞減順序。
若只要查詢其中的一些 Dog 項目,您可以將條件套用至排序索引鍵 (例如僅限 Dog 項目,其中 Name 開始的字母介於 A 到 K 的範圍內)。
注意
在 DynamoDB 資料表中,每個分割區索引鍵值的相異排序索引鍵值數目沒有上限。如果您需要在 Pets 資料表中存放數十億個 Dog 項目,則 DynamoDB 會分配足夠的儲存空間來自動處理此需求。
