本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
監控 DynamoDB 中的裝置狀態更新
本使用案例將說明如何使用 DynamoDB 監控 DynamoDB 中的裝置狀態更新 (或裝置狀態變更)。
使用案例
在 IoT 使用案例 (例如智慧工廠) 中,許多裝置需要由作業員監控,並定期將其狀態或日誌傳送至監控系統。當裝置發生問題時,裝置的狀態會從正常轉為警告。根據裝置中異常行為的嚴重性和類型,會有不同的日誌層級或狀態。然後,系統會指派作業員檢查裝置,並在需要時將問題呈報給主管。
此系統的典型存取模式包括:
-
建立裝置的日誌項目
-
取得特定裝置狀態的所有日誌,並顯示最新日誌
-
取得兩個日期之間,給指定作業員的所有日誌
-
取得呈報給指定主管的所有日誌
-
取得呈報給指定主管,並包含特定裝置狀態的所有日誌
-
取得呈報給指定主管,並包含特定日期之特定裝置狀態的所有日誌
實體關係圖
這是用於監控裝置狀態更新實體關係圖 (ERD)。
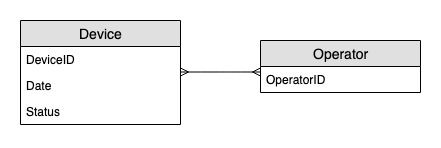
存取模式
須使用此存取模式監控裝置狀態更新。
-
createLogEntryForSpecificDevice -
getLogsForSpecificDevice -
getWarningLogsForSpecificDevice -
getLogsForOperatorBetweenTwoDates -
getEscalatedLogsForSupervisor -
getEscalatedLogsWithSpecificStatusForSupervisor -
getEscalatedLogsWithSpecificStatusForSupervisorForDate
架構設計演進
步驟 1:位址存取模式 1 (createLogEntryForSpecificDevice) 和 2 (getLogsForSpecificDevice)
裝置追蹤系統的擴展單位為個別裝置。在這個系統中,deviceID 會唯一識別裝置,進一步讓 deviceID 成為分割區索引鍵的理想候選者。每個設備會定期向追蹤系統發送資訊 (例如每五分鐘左右),而這類排序會依日期為邏輯排序準則,因此成為排序索引鍵。此使用案例中的範例資料看起來應會與以下內容相似:
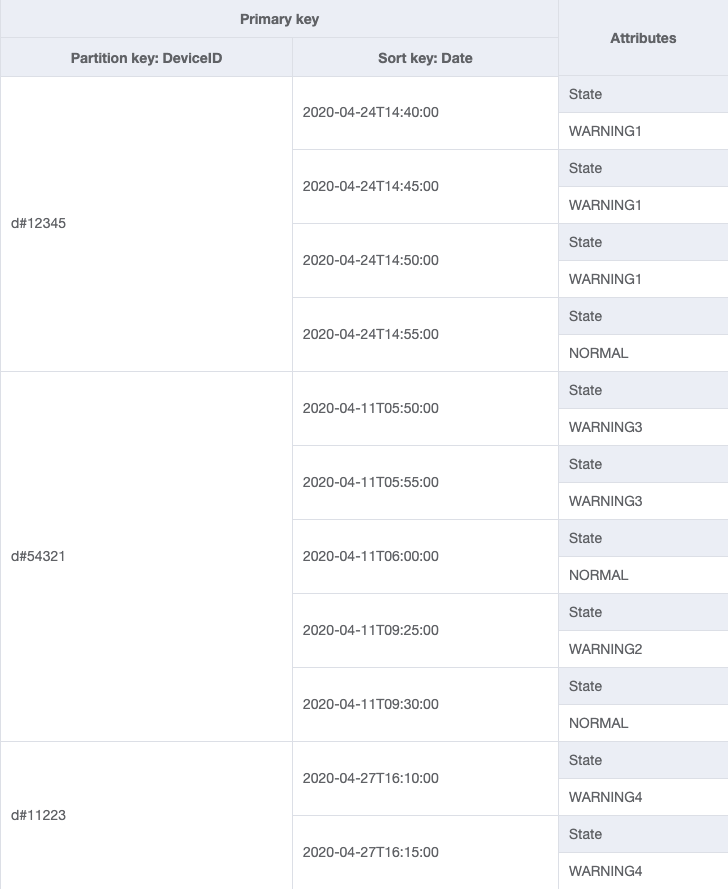
若要擷取特定裝置的日誌項目,可以使用分割區索引鍵 DeviceID="d#12345" 執行查詢操作。
步驟 2:位址存取模式 3 (getWarningLogsForSpecificDevice)
由於 State 是非索引鍵屬性,必須使用篩選條件表達式,才可利用目前的結構描述處理存取模式 3。在 DynamoDB 中,使用索引鍵條件表達式讀取資料後,才會套用篩選條件表達式。例如若想針對 d#12345 擷取警告日誌,利用分割區索引鍵 DeviceID="d#12345" 進行的查詢操作會讀取上表中的四個項目,然後篩選掉非處於警告狀態的項目。這種方法無法有效地大規模進行。如果排除項目的比例較低或不常執行查詢,則篩選條件表達式是排除查詢項目的好方法。但是,我們可以持續改善資料表設計,以便更有效率地從資料表中擷取大量項目,並篩選掉大部分的項目。
若想改變存取模式的處理方法,可以透過複合排序索引鍵。您可以從排序索引鍵已改為 State#Date 的 DeviceStateLog_3.jsonState、# 以及 Date 屬性。此範例中,# 用來作為分隔符。資料現在看起來會像這樣:
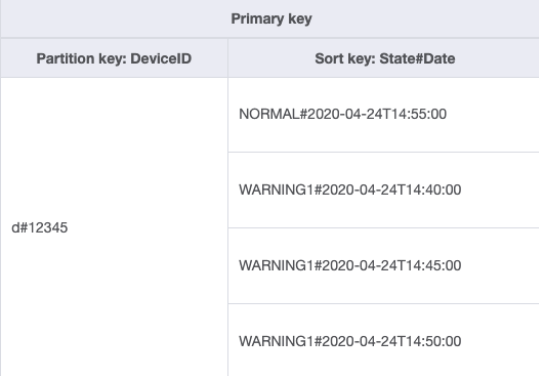
若僅想擷取裝置的警告日誌,可利用此結構描述更切合查詢。查詢的索引鍵條件使用分割區索引鍵 DeviceID="d#12345" 與排序索引鍵 State#Date begins_with
“WARNING”。此查詢只會讀取三個與警告狀態相關的項目。
步驟 3:位址存取模式 4 (getLogsForOperatorBetweenTwoDates)
您可以匯入 DeviceStateLog_4.jsonOperator 屬性已新增至具有範例資料的 DeviceStateLog 資料表。
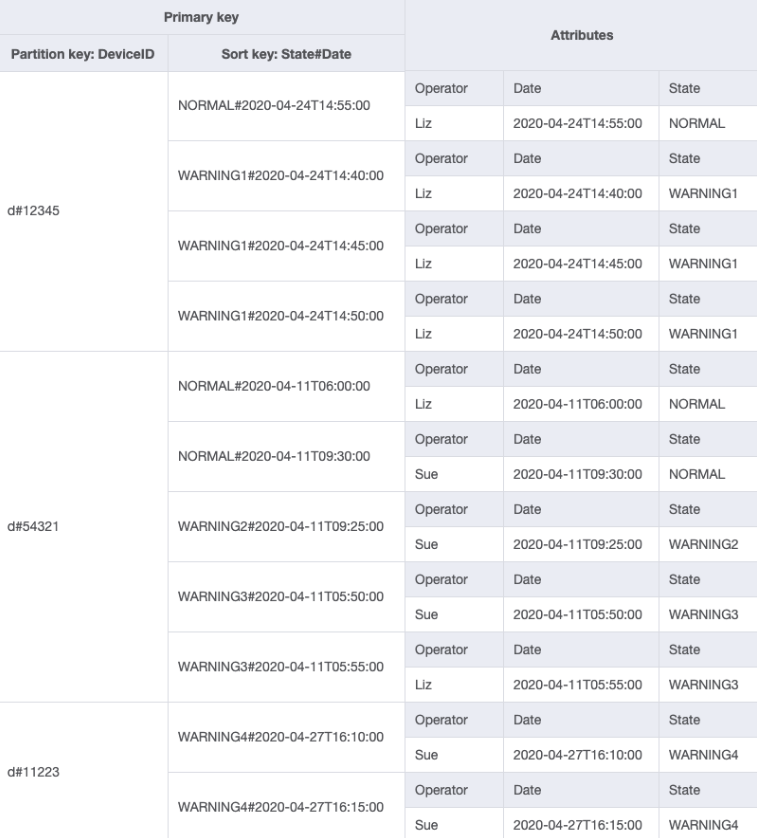
由於 Operator 目前不是分割區索引鍵,因此無法根據以 OperatorID 為基礎的資料表執行直接鍵值對查詢。我們必須使用 OperatorID 上的全域次要索引,建立一個新的項目集合。存取模式必須根據日期進行查詢,因此日期是全域次要索引 (GSI) 的排序索引鍵屬性。這就是 GSI 現在的樣子:
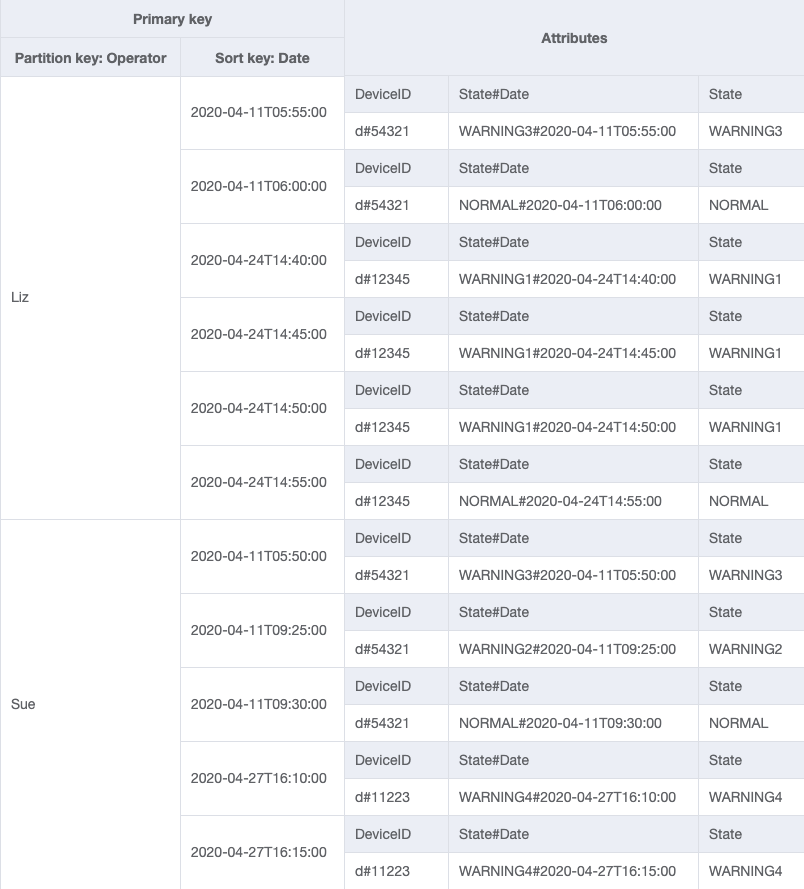
針對存取模式 4 (getLogsForOperatorBetweenTwoDates),您可以使用分割區索引鍵 OperatorID=Liz 查詢此 GSI,以及 2020-04-11T05:58:00 和 2020-04-24T14:50:00 之間的排序索引鍵 Date。
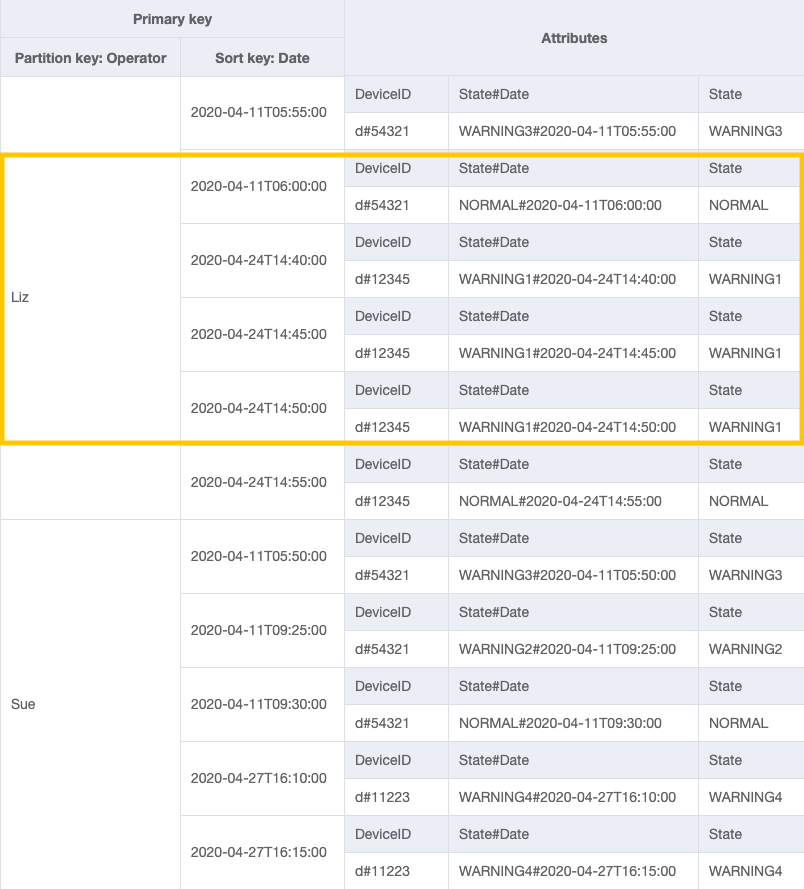
步驟 4:位址存取模式 5 (getEscalatedLogsForSupervisor)、6 (getEscalatedLogsWithSpecificStatusForSupervisor) 和 7 (getEscalatedLogsWithSpecificStatusForSupervisorForDate)
我們可以利用疏鬆索引處理這些存取模式。
全域次要索引依預設是疏鬆的,因此只有基礎資料表中包含主索引鍵屬性的項目,才會實際出現在索引中。針對要建模的存取模式,這是另一種排除無關項目的方式。
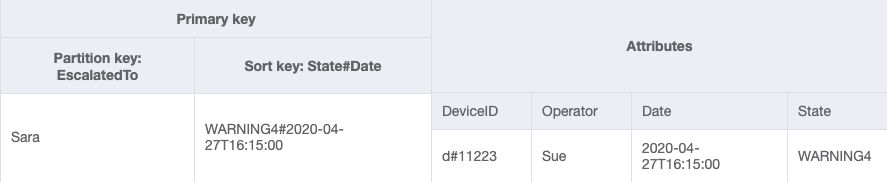
您可以匯入 DeviceStateLog_6.jsonEscalatedTo 屬性已新增至具有範例資料的 DeviceStateLog 資料表。如前所述,並非所有日誌都會呈報給主管。
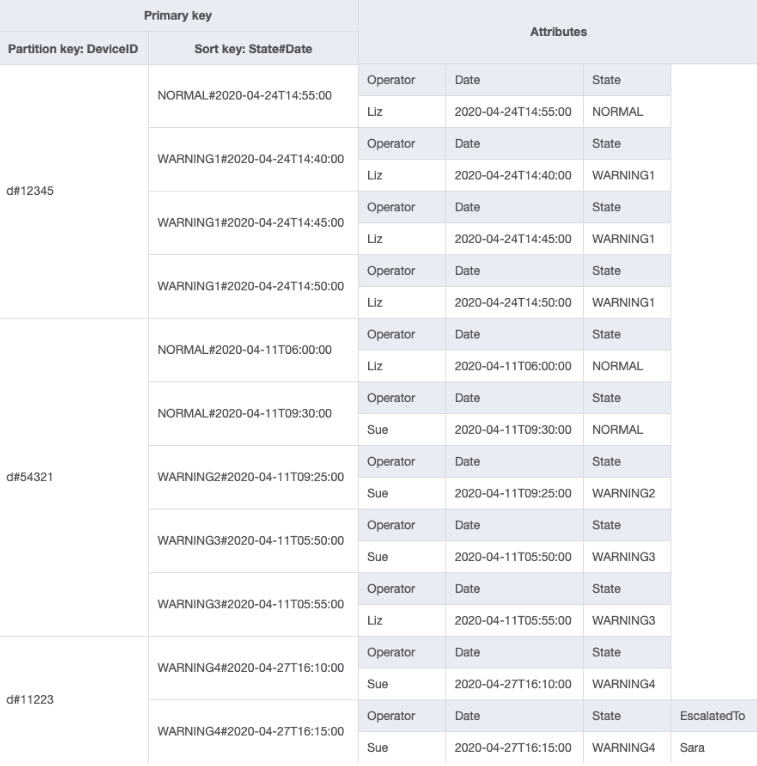
您現在可以建立分割區索引鍵為 EscalatedTo、排序索引鍵為 State#Date 的新 GSI。請注意,只有當項目同時具有 EscalatedTo 和 State#Date 屬性時,才會顯示在索引中。

其餘的存取模式摘要如下:
下表摘要整理了所有存取模式,以及結構描述設計處理這些模式的方式:
| 存取模式 | 基礎資料表/GSI/LSI | 作業 | 分割區索引鍵值 | 排序索引鍵值 | 其他條件/篩選條件 |
|---|---|---|---|---|---|
| createLogEntryForSpecificDevice | 基礎資料表 | PutItem | DeviceID=deviceId | State#Date=state#date | |
| getLogsForSpecificDevice | 基礎資料表 | Query | DeviceID=deviceId | State#Date begins_with "state1#" | ScanIndexForward = False |
| getWarningLogsForSpecificDevice | 基礎資料表 | Query | DeviceID=deviceId | State#Date begins_with "WARNING" | |
| getLogsForOperatorBetweenTwoDates | GSI-1 | Query | Operator=operatorName | Date between date1 and date2 | |
| getEscalatedLogsForSupervisor | GSI-2 | Query | EscalatedTo=supervisorName | ||
| getEscalatedLogsWithSpecificStatusForSupervisor | GSI-2 | Query | EscalatedTo=supervisorName | State#Date begins_with "state1#" | |
| getEscalatedLogsWithSpecificStatusForSupervisorForDate | GSI-2 | Query | EscalatedTo=supervisorName | State#Date begins_with "state1#date1" |
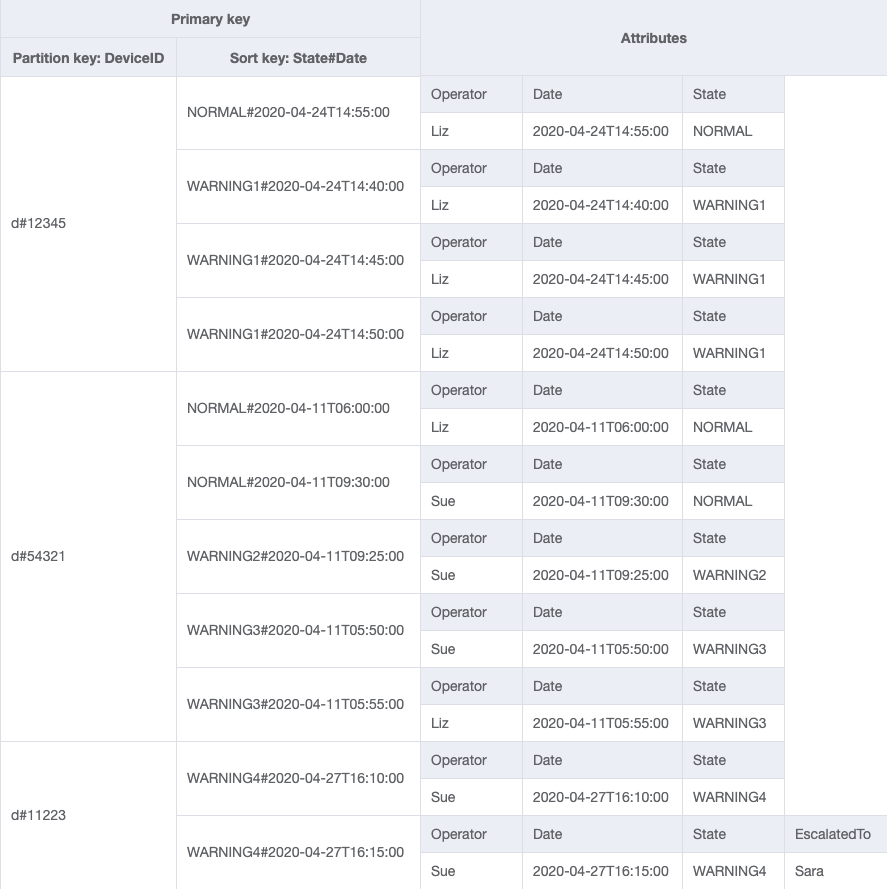
最終結構描述
以下是最終結構描述設計。若要將此結構描述設計下載為 JSON 檔案,請參閱 GitHub 上的 DynamoDB 範例
基礎資料表
GSI-1
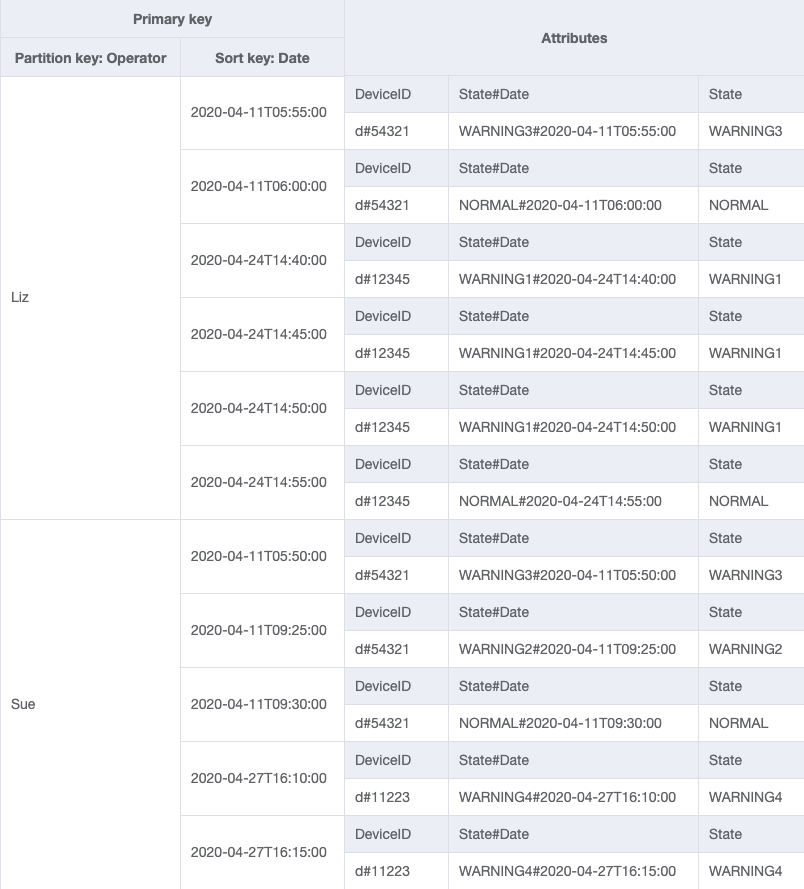
GSI-2
使用 NoSQL Workbench 與此結構描述設計
您可以將此最終結構描述匯入 NoSQL Workbench,這是為 DynamoDB 提供資料建模、資料視覺化,和查詢開發功能的視覺化工具,以進一步探索和編輯新專案。請依照下列步驟以開始使用:
-
下載 NoSQL Workbench。如需詳細資訊,請參閱下載 DynamoDB 專用 NoSQL Workbench。
-
下載上面列出的 JSON 結構描述檔案,該檔案已經是 NoSQL Workbench 模型格式。
-
將 JSON 結構描述檔案匯入到 NoSQL Workbench。如需詳細資訊,請參閱匯入現有的資料模型。
-
一旦您匯入到 NOSQL Workbench 後,便可以編輯資料模型。如需詳細資訊,請參閱編輯現有的資料模型。
