本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
也許,全域資料表部署中最複雜的部分是管理請求路由。請求必須首先從終端使用者以某種方式選擇和路由到區域。請求會遇到該區域中的一些服務堆疊,包括運算層,該層可能由 AWS Lambda函數、容器或 Amazon Elastic Compute Cloud (Amazon EC2) 節點支援的負載平衡器組成,也可能包含其他資料庫。該運算層與 DynamoDB 通訊應該使用該區域的本機端點來執行此操作。全域資料表中的資料會複寫到所有其他參與的區域,而且每個區域在其 DynamoDB 資料表周圍都有類似的服務堆疊。
全域資料表會為不同區域中的每個堆疊提供相同資料的本機複本。如果本機 DynamoDB 資料表發生問題,您可以考慮為單一區域中的單一堆疊進行設計,並預期會對次要區域的 DynamoDB 端點進行遠端呼叫。這不是最佳實務。跨區域相關的延遲可能比本機存取高 100 倍。一系列來回的 5 個請求,本機執行時可能需要幾毫秒,但跨越全球時可能需要幾秒鐘。建議最好將終端使用者路由到另一個區域進行處理。為了確保彈性,您需要跨越多個區域進行複寫,複寫運算層和資料層。
有許多替代技術可將終端使用者請求路由到區域進行處理。最佳選擇取決於您的寫入模式和容錯移轉的考量。本節討論四個選項:用戶端驅動、運算層、Route 53 和 Global Accelerator。
用戶端驅動的請求路由
通過用戶端驅動的請求路由,終端使用者用戶端 (如應用程式,帶有 JavaScript 的網頁),另一個用戶端將追蹤有效的應用程式端點。在這種情況下,將像是 Amazon API Gateway 這樣的應用程式端點,而不是文字 DynamoDB 端點。最終使用者用戶端使用自己的內嵌邏輯來選擇要與哪個區域通訊。它可以根據隨機選擇、觀察到的最低延遲、觀察到的最高頻寬測量或本機執行的運作狀態檢查來選擇。
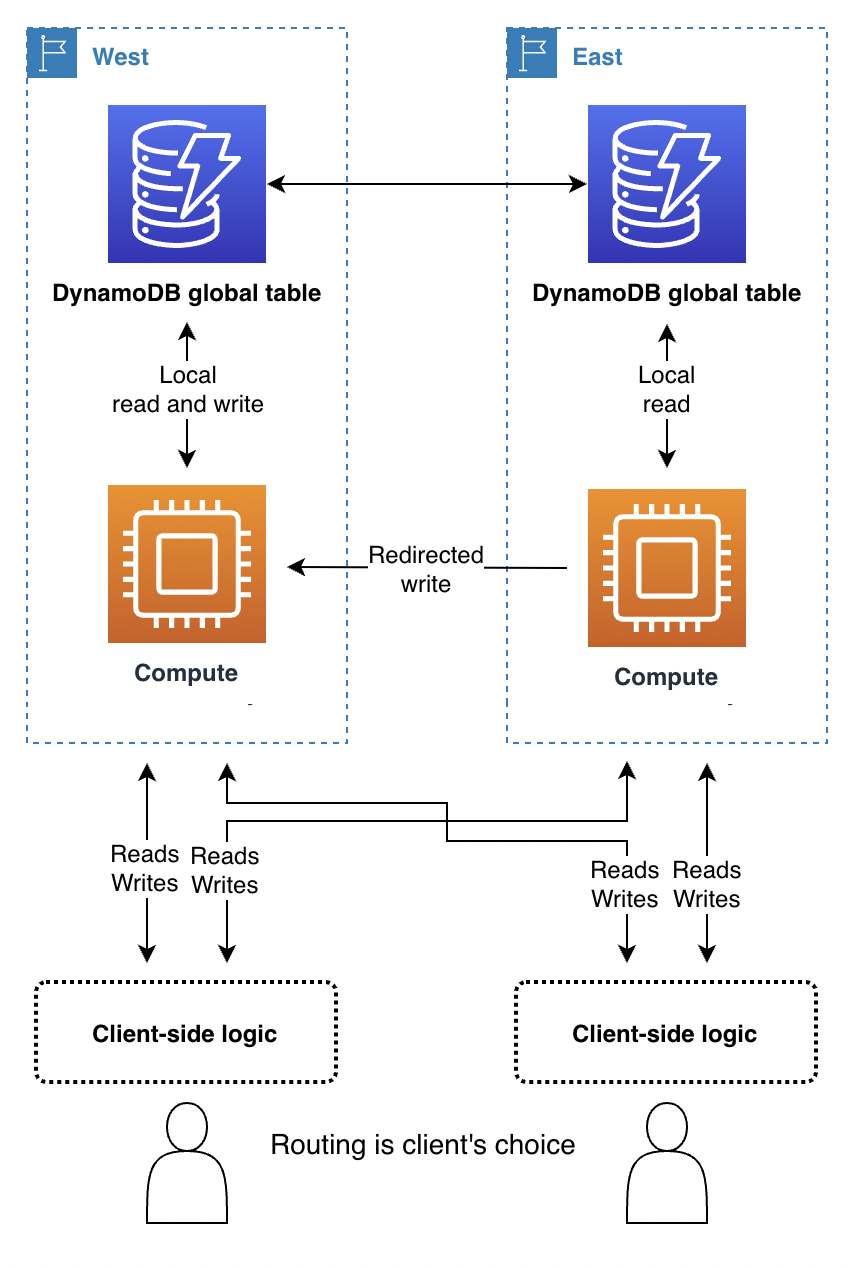
用戶端驅動的請求路由優點在於,它可以適應現實世界的公共網際網路流量狀況等情況,以便在發現任何性能下降時切換區域。用戶端必須瞭解所有可用端點,但啟動新的區域端點並不常見。
透過寫入任何區域模式,用戶端可以單方面選取其偏好的端點。如果對某個區域的存取受損,用戶端可以路由到另一個端點。
透過寫入單一區域模式,用戶端需要一種機制,將寫入路由到目前使用中的區域。這可能與經驗測試目前接受寫入的區域一樣基本 (注意任何寫入拒絕並退回替代),或者與呼叫全域協調器查詢目前的應用程式狀態一樣複雜 (可能建立在 Route 53 應用程式復原控制器 (ARC) 路由控制項上,該控制項提供 5 區域定量驅動系統以維護全域狀態以滿足此類需求)。用戶端可以決定讀取是否可以移轉到任何區域以取得最終一致性,還是必須路由到使用中的區域以取得高度一致性。如需進一步資訊,請參閱 Route 53 的運作方式。
使用寫入您的區域模式時,用戶端必須確定其處理之資料集的主區域。例如,如果用戶端對應一個使用者帳戶,且每個使用者帳戶都連結至一個區域,則用戶端可以從全域登入系統要求適當的端點。
例如,透過網路協助使用者管理其業務金融的金融服務公司,可以使用全域資料表和寫入您的區域模式。每個使用者都必須登入中央服務。該服務會傳回憑證,以及這些憑證將在該區域使用的端點。憑證僅在短時間內有效。之後,網頁會自動協商一個新的登入,提供一個可能將使用者活動重定導向新區域的機會。
運算層請求路由
透過運算層請求路由,在運算層中執行的程式碼會決定是否要在本機處理請求,或將它傳遞給在另一個區域中執行的自身複本。當您使用寫入單一區域模式時,運算層可能會偵測到它不是使用中的區域,並允許本機讀取操作,同時將所有寫入操作轉送至另一個區域。此運算層程式碼必須知道資料拓撲和路由規則,並根據指定哪些區域為哪些資料使用中的最新設定,強制可靠的執行這些規則。區域內的外部軟體堆疊不需要知道微服務如何路由讀取和寫入請求。在穩健的設計中,接收區域會驗證其是否為寫入操作的目前主要項目。如果不是,則會產生錯誤,指出需要全域狀態需要修改。如果主要區域正在變更,則接收區域也可能會緩衝寫入操作一段時間。在所有情況下,區域中的運算堆疊只會寫入其本機 DynamoDB 端點,但運算堆疊可能會彼此通訊。
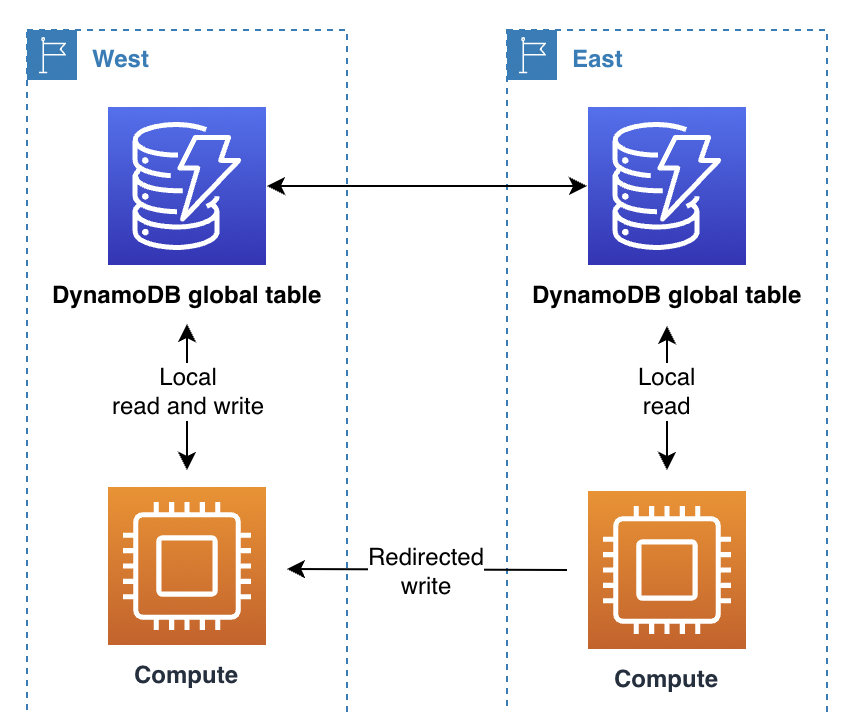
在此情況中,假設金融服務公司是使用全天候單一主要模型。他們使用系統和程式庫來進行此路由程序。其整體系統維護全域狀態,類似於 AWS ARC 路由控制。他們使用全域資料表來追蹤哪個區域是主要區域,以及排定下一個主要交換器的時間。所有的讀取和寫入操作都經過程式庫,該程式庫與它們的系統進行協調。該程式庫允許在本機上以低延遲執行讀取操作。對於寫入操作,應用程式會檢查本機區域是否為目前的主要區域。如果是,則寫入操作會直接完成。如果沒有,則程式庫會將寫入任務轉送到目前主要區域中的程式庫。接收程式庫會確認它也會將自己視為主要區域,如果不是,則會引發錯誤,表示全域狀態的傳播延遲。此方法不直接寫入遠端 DynamoDB 端點,進而提供驗證優勢。
Route 53 請求路由
Amazon Application Recovery Controller (ARC) 是一種網域名稱服務 (DNS) 技術。使用 Route 53 時,用戶端會透過查詢已知的 DNS 網域名稱來請求其端點,Route 53 會傳回與其認為最合適的區域端點對應 IP 地址。Route 53 有一份用於決定適當區域的路由政策的清單。Route 53 也可以執行容錯移轉路由,以將流量路由傳送出運作狀態檢查失敗的區域。
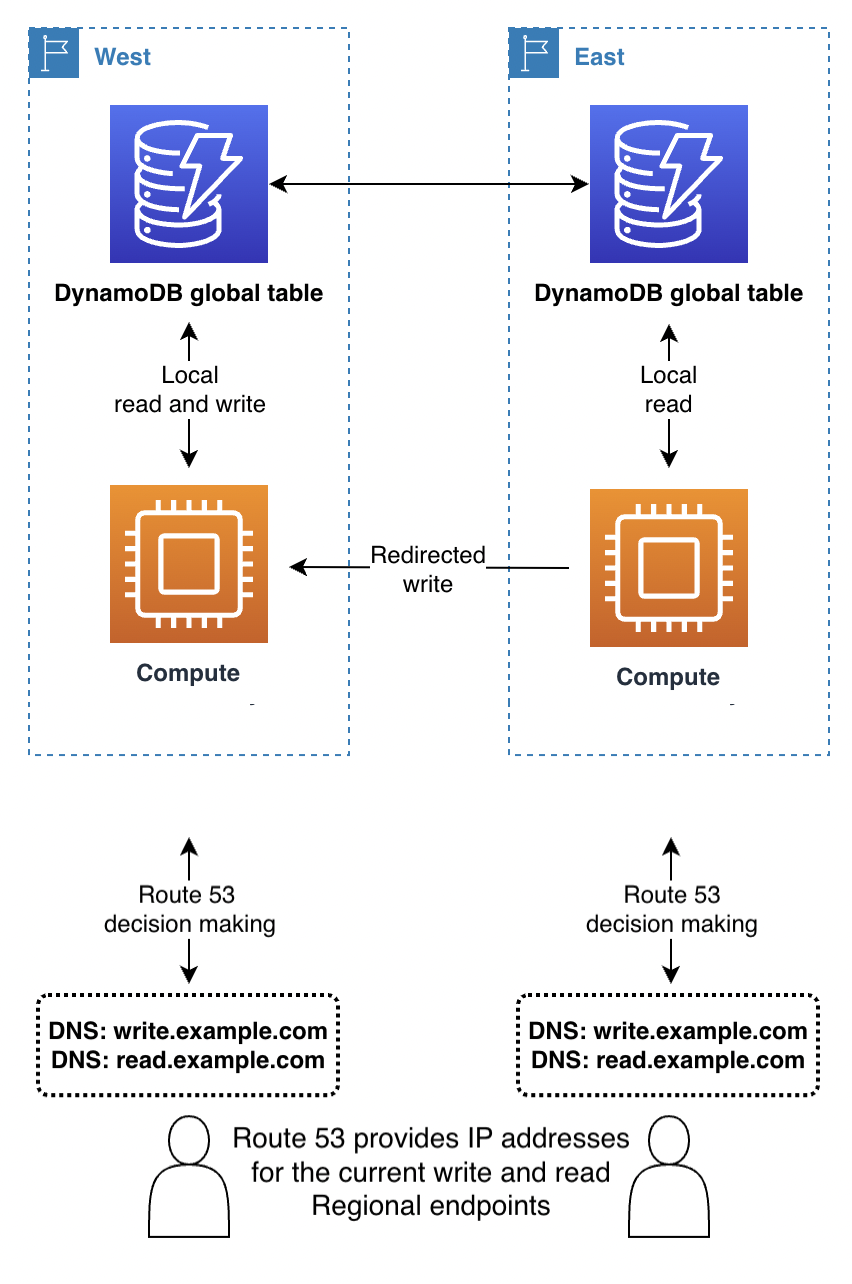
使用寫入任何區域模式,或者結合後台運算層請求路由使用,Route 53 可以取得完整存取權限,以根據任何複雜的內部規則 (例如,最近網絡鄰近的區域或最近的地理位置或任何其他選擇) 返回區域。
使用寫入單一區域模式,可以將 Route 53 設定為返回目前使用中區域 (使用 Route 53 ARC)。
注意
用戶端會快取 Route 53 回應中的 IP 地址一段時間,該時間由網域名稱上的存留時間 (TTL) 設定所指定的時間。較長的 TTL 會延長復原時間點目標 (RTO),讓所有用戶端辨識新的端點。60 秒是容錯移轉使用的典型值。並非所有軟體都能完全遵守 DNS TTL 逾期。
寫入您的區域模式時,最好避免使用 Route 53,除非您還使用運算層請求路由。
Global Accelerator 請求路由
用戶端使用 AWS Global Accelerator
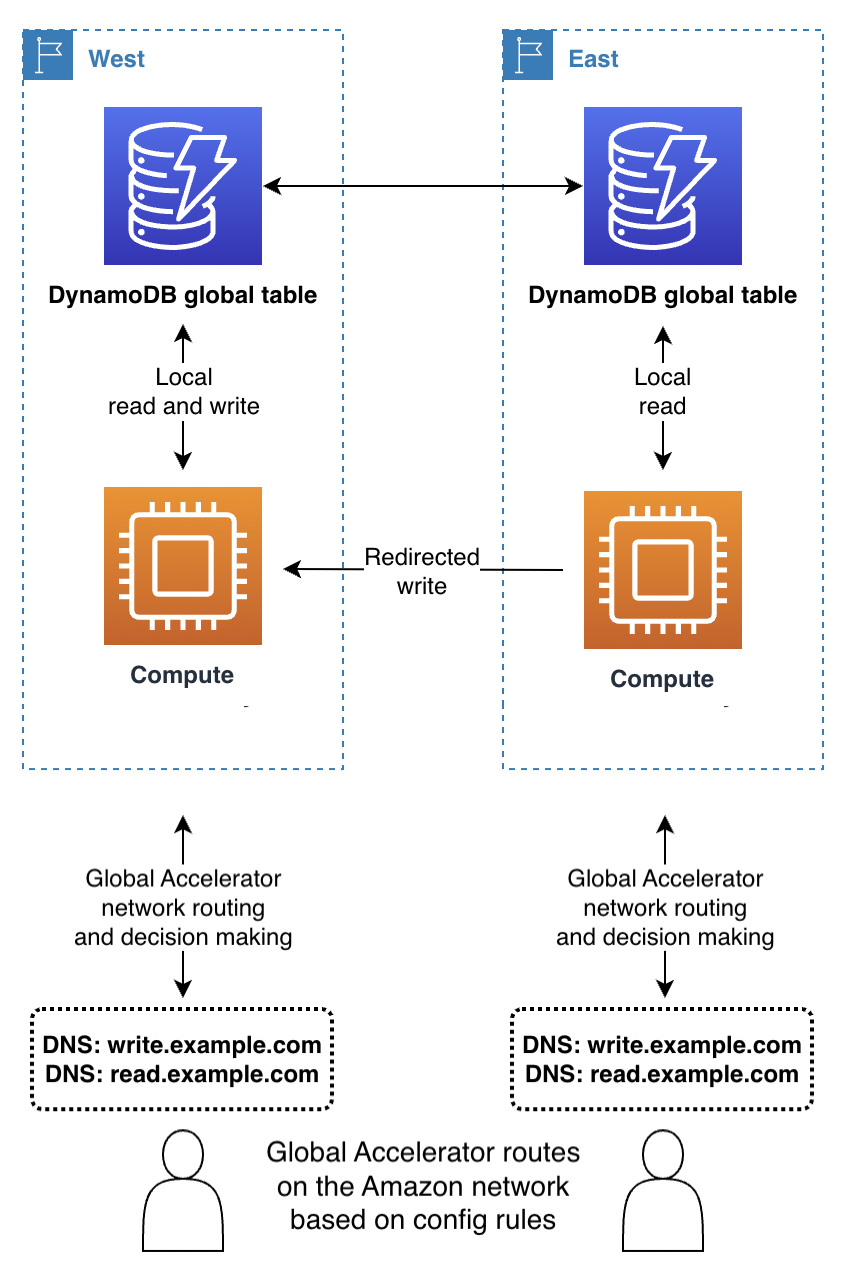
透過寫入任何區域模式,或者如果與後端的計算層請求路由結合使用,Global Accelerator 可以無縫工作。用戶端會連線到最近的邊緣節點,而且不需要擔心由哪個區域接收請求。
使用寫入單一區域的 Global Accelerator 路由規則時,必須將請求傳送到目前使用中的區域。您可以使用運作狀態檢查,以人為方式報告任何區域的故障,而這些區域並未被您的全域系統視為使用中區域。與 DNS 一樣,如果請求可能來自任何區域,則可以使用替代 DNS 網域名稱來路由讀取請求。
使用寫入您的區域模式時,最好避免使用 Global Accelerator,除非您同時使用運算層請求路由。
