本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
管理 DynamoDB 資料表中多對多關係的最佳實務
相鄰清單是一設計模式,在 Amazon DynamoDB 中建立多對多關係的模型時非常有用。整體來說,它們提供在 DynamoDB 中呈現圖形資料 (節點和邊緣) 的方式。
相鄰清單設計模式
當應用程式的不同實體彼此有多對多關係時,關係可以建立為相鄰清單的模型。在此模式中,所有頂層實體 (相當於圖形模型的節點) 會使用分割區索引鍵來呈現。任何具其他實體的關係 (圖形中的邊緣) 會透過將排序索引鍵值設為目標實體 ID (目標節點) 來以分割區中項目的形式呈現。
此模式的優點包含可將資料複製降到最低並簡化查詢模式,以尋找與目標實體相關 (有目標節點的邊緣) 的所有實體 (節點)。
此模式的實用實際範例為可開立多帳單發票的發票系統。一個帳單可屬於多個發票。此範例中的分割區索引鍵是 InvoiceID 或 BillID。BillID 分割區擁有專屬於帳單的所有屬性。InvoiceID 分割區有儲存特定發票屬性的項目,且擁有累計至發票的每個 BillID 項目。
結構描述看起來類似如下。
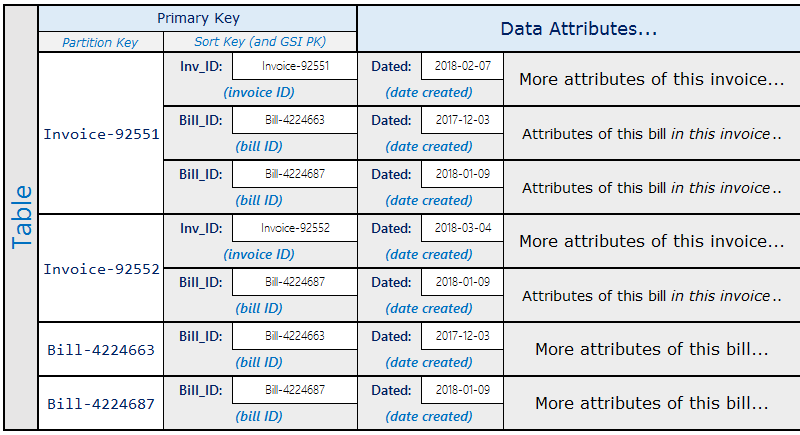
使用上述結構描述,您會發現可使用資料表上的主索引鍵來查詢發票的所有帳單。若要查詢包含部分帳單的所有發票,針對資料表的排序索引鍵建立全域次要索引。
全域次要索引的投影看起來類似如下。
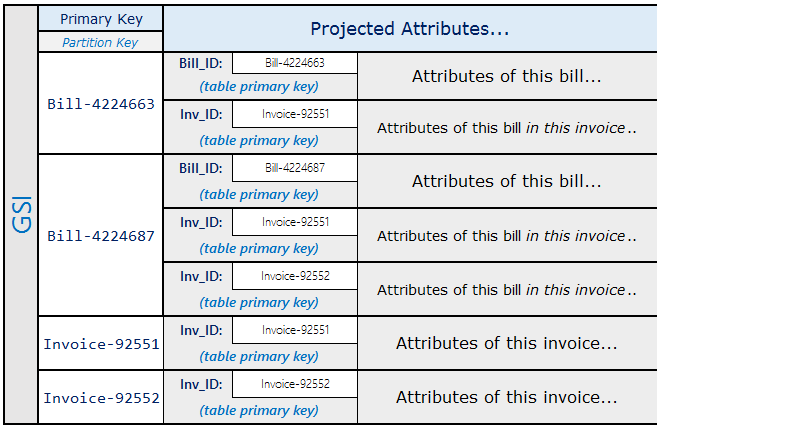
具體化圖形模式
許多應用程式會根據對等間的排名、實體間的一般關係、鄰接實體狀態和圖形樣式流程的其他類型來建置。如需這些類型的應用程式,請考量以下結構描述設計模式。
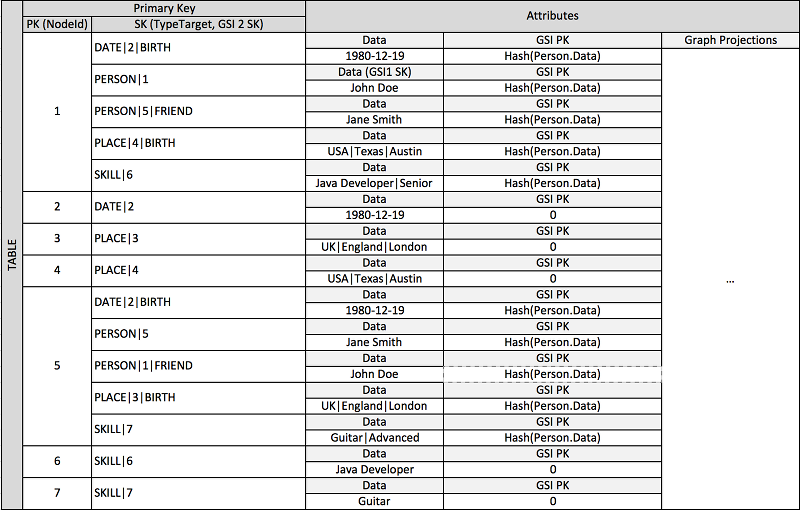
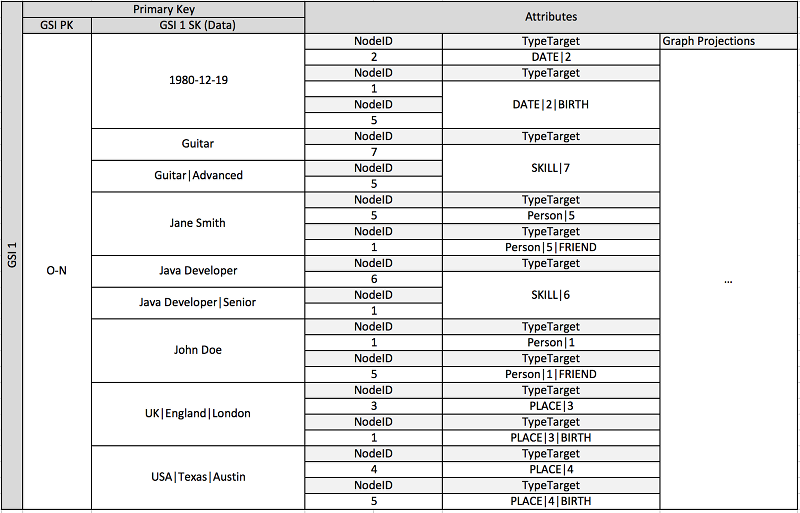
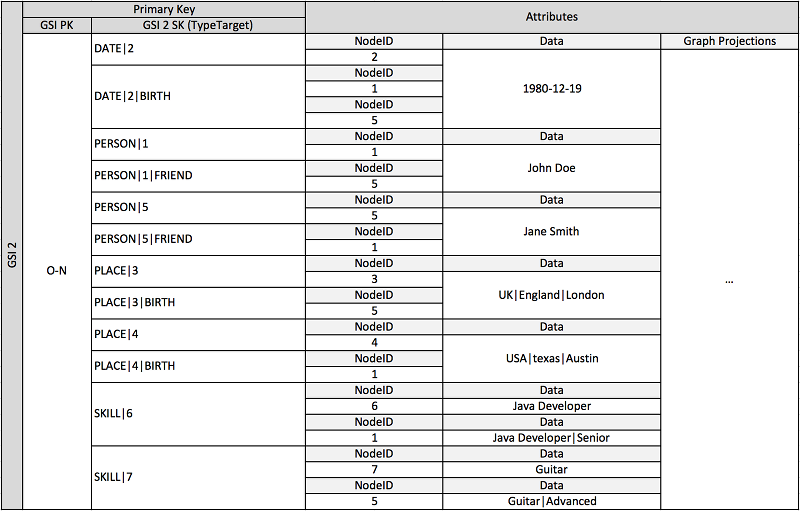
上述結構描述顯示的圖形資料結構會以內含項目的資料分割區組來定義,其內含項目會定義圖形的邊緣與節點。邊緣項目包含 Target 和 Type 屬性。這些屬性會用做為複合索引鍵「TypeTarget」的一部分,來識別在主要資料表或第二個全域次要索引中分割區中的項目。
第一個全域次要索引會根據 Data 屬性建置。此屬性會如先前數個不同屬性類型 (也就是 Dates、Names、Places 和 Skills) 所述,使用全域次要索引多載。在這裡,一個全域次要索引可有效地對四個不同的屬性製作索引。
隨著您將項目插入資料表,您可以使用智慧碎片策略來使用大型彙總 (生日、技能),在避免經常性讀取/寫入問題時所需的許多邏輯分割區中,對全域次要索引散佈項目。
結合設計模式後,您能得到一個功能扎實的資料儲存,可有效進行即時圖形流程。這些流程可以為建議的引擎、社交應用程式、節點排名、子樹系彙總和其他一般圖形使用者案例提供高效能鄰近實體狀態和邊緣彙總查詢。
如果您的使用案例對即時資料一致性並不敏感,您可以使用已排定的 Amazon EMR 程序,將適用於流程的相關圖形摘要彙總填入邊緣。如果您的應用程式不需要立即知道邊緣新增至圖形的時間,您可以使用排定的程序來彙總結果。
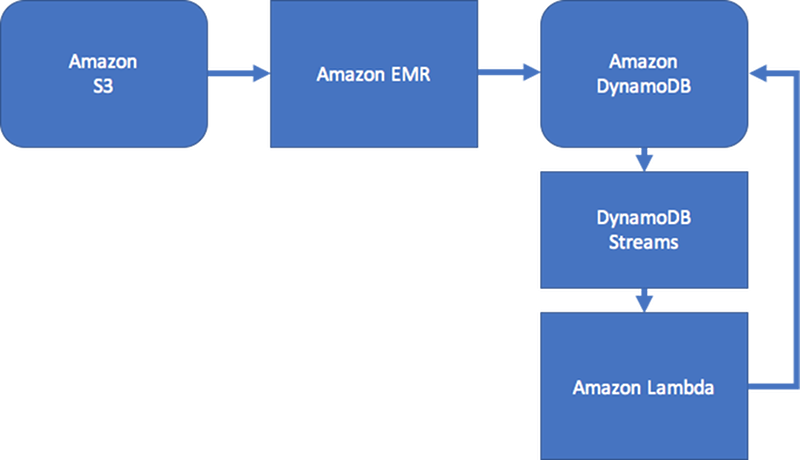
若要維持一定程度的一致性,設計可以包含 Amazon DynamoDB Streams 與 AWS Lambda 來處理邊緣更新。其可以使用 Amazon EMR 任務來驗證定期間隔的結果。下圖說明此方法。在社交應用程式會常常用到此方法,其中即時查詢的成本相當高,且立即知道個別使用者更新的需求很低。
IT 服務管理 (ITSM) 和安全性應用程式通常需要對由複雜邊際彙總構成的實體狀態變更回應做出即時回應。此類應用程式需要可以支援第二和第三層級關係之即時多節點彙總或複雜邊際尋訪的系統。若您的使用案例需要這些類型的即時圖形查詢工作流程,我們建議您使用 Amazon Neptune 來管理這些工作流程。
注意
如果您需要查詢高度連線的資料集,或執行需要以毫秒延遲周遊多個節點 (也稱為多躍點查詢) 的查詢,則應考慮使用 Amazon Neptune。Amazon Neptune 是專為高效能圖形資料庫引擎所打造,該服務將存放的數十億筆關係最佳化,且查詢圖形時只會有數毫秒的延遲。
