Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verstehen der Skalierung von Lambda-Funktionen
Parallelität ist die Anzahl der laufenden Anfragen, die Ihre AWS Lambda Funktion gleichzeitig bearbeitet. Für jede gleichzeitige Anfrage stellt Lambda eine separate Instance Ihrer Ausführungsumgebung bereit. Wenn Ihre Funktionen mehr Anfragen erhalten, sorgt Lambda automatisch für die Skalierung der Anzahl der Ausführungsumgebungen, bis Sie das Gleichzeitigkeitslimit für Ihr Konto erreichen. Standardmäßig stellt Lambda Ihrem Konto eine Gesamtnebenläufigkeitsgrenze von 1 000 gleichzeitigen Ausführungen für alle Funktionen in einer AWS-Region bereit. Um Ihre speziellen Kontoanforderungen zu unterstützen, können Sie eine Kontingenterhöhung anfordern
In diesem Thema werden Gleichzeitigkeitskonzepte und Funktionsskalierung in Lambda erläutert. Am Ende dieses Themas werden Sie in der Lage sein, die Gleichzeitigkeit zu berechnen, die beiden Hauptoptionen für die Gleichzeitigkeitskontrolle (reserviert und bereitgestellt) zu visualisieren, geeignete Einstellungen für die Gleichzeitigkeitskontrolle zu schätzen und Metriken zur weiteren Optimierung anzuzeigen.
Sections
Verstehen und Visualisieren der Gleichzeitigkeit
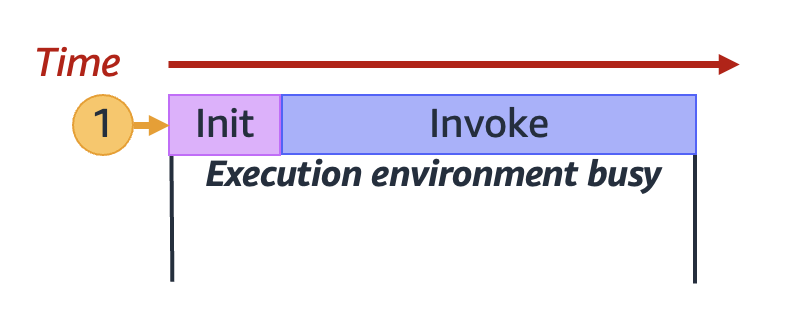
Lambda ruft Ihre Funktion in einer sicheren und isolierten Ausführungsumgebung auf. Um eine Anfrage zu bearbeiten, muss Lambda zuerst eine Ausführungsumgebung initialisieren (die Initialisierungsphase), bevor es zum Aufrufen Ihrer Funktion verwendet wird (die Aufrufphase):
Anmerkung
Die tatsächliche Initialisierungs- und Aufrufdauer kann von vielen Faktoren abhängen, z. B. von der von Ihnen ausgewählten Laufzeit und dem Lambda-Funktionscode. Das vorherige Diagramm soll nicht die genauen Proportionen der Initiierungs- und Aufrufphasendauer darstellen.
Im vorherigen Diagramm wird ein Rechteck verwendet, um eine einzelne Ausführungsumgebung darzustellen. Wenn Ihre Funktion ihre allererste Anfrage erhält (dargestellt durch den gelben Kreis mit der Bezeichnung 1), erstellt Lambda eine neue Ausführungsumgebung und führt den Code während der Initialisierungsphase außerhalb Ihres Haupthandlers aus. Anschließend führt Lambda den Haupthandlercode Ihrer Funktion während der Aufrufphase aus. Während des gesamten Prozesses ist diese Ausführungsumgebung ausgelastet und kann keine anderen Anfragen verarbeiten.
Wenn Lambda die Verarbeitung der ersten Anfrage abgeschlossen hat, kann diese Ausführungsumgebung weitere Anfragen für dieselbe Funktion verarbeiten. Für nachfolgende Anfragen muss Lambda die Umgebung nicht neu initialisieren.
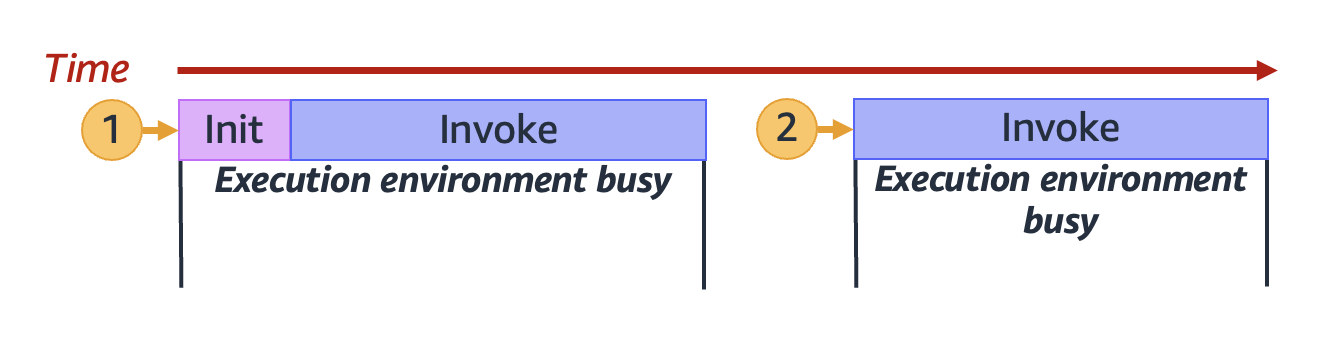
Im vorherigen Diagramm verwendet Lambda die Ausführungsumgebung erneut, um die zweite Anfrage zu verarbeiten (dargestellt durch den gelben Kreis mit der Bezeichnung 2).
Bisher haben wir uns nur auf eine einzige Instance Ihrer Ausführungsumgebung konzentriert (d. h. eine Gleichzeitigkeit von 1). In der Praxis muss Lambda möglicherweise mehrere Instances der Ausführungsumgebung parallel bereitstellen, um alle eingehenden Anfragen zu verarbeiten. Wenn Ihre Funktion eine neue Anfrage erhält, können zwei Dinge passieren:
-
Wenn eine vorinitialisierte Instance der Ausführungsumgebung verfügbar ist, verwendet Lambda diese, um die Anfrage zu verarbeiten.
-
Andernfalls erstellt Lambda eine neue Instance der Ausführungsumgebung, um die Anfrage zu verarbeiten.
Lassen Sie uns beispielsweise untersuchen, was passiert, wenn Ihre Funktion 10 Anfragen erhält:
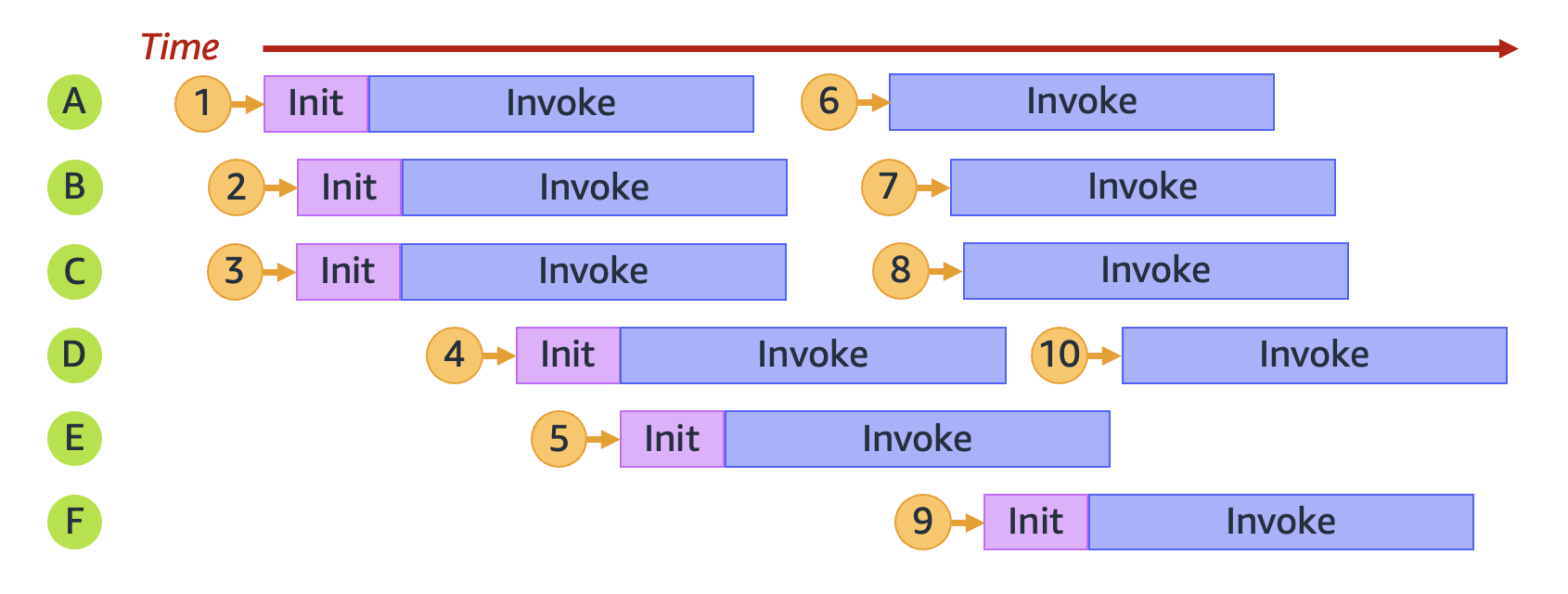
Im vorherigen Diagramm stellt jede horizontale Ebene eine einzelne Instance der Ausführungsumgebung dar (von A bis F). So behandelt Lambda jede Anfrage:
| Anforderung | Lambda-Verhalten | Reasoning |
|---|---|---|
|
1 |
Stellt neue Umgebung A bereit |
Dies ist die erste Anfrage. Es sind keine Instances der Ausführungsumgebung verfügbar |
|
2 |
Stellt neue Umgebung B bereit |
Die vorhandene Instance der Ausführungsumgebung A ist ausgelastet |
|
3 |
Stellt neue Umgebung C bereit |
Die vorhandenen Instances der Ausführungsumgebung A und B sind beide ausgelastet |
|
4 |
Stellt neue Umgebung D bereit |
Die vorhandenen Instances der Ausführungsumgebung A, B und C sind alle ausgelastet |
|
5 |
Stellt neue Umgebung E bereit |
Die vorhandenen Instances der Ausführungsumgebung A, B, C und D sind alle ausgelastet |
|
6 |
Wiederverwendung von Umgebung A |
Die Instance der Ausführungsumgebung A hat die Verarbeitung von Anfrage 1 abgeschlossen und ist jetzt verfügbar |
|
7 |
Wiederverwendung von Umgebung B |
Die Instance der Ausführungsumgebung B hat die Verarbeitung von Anfrage 2 abgeschlossen und ist jetzt verfügbar |
|
8 |
Wiederverwendung von Umgebung C |
Die Instance der AusführungsumgebungB hat die Verarbeitung von Anfrage 3 abgeschlossen und ist jetzt verfügbar |
|
9 |
Stellt neue Umgebung F bereit |
Die vorhandenen Instances der Ausführungsumgebung A, B, C, D und E sind alle ausgelastet |
|
10 |
Wiederverwendung von Umgebung D |
Die Instance der Ausführungsumgebung D hat die Verarbeitung von Anfrage 4 abgeschlossen und ist jetzt verfügbar |
Wenn Ihre Funktion mehr gleichzeitige Anfragen erhält, erhöht Lambda als Reaktion darauf die Anzahl der Instances der Ausführungsumgebung. Die folgende Animation verfolgt die Anzahl der gleichzeitigen Anfragen im Laufe der Zeit:
Durch das Einfrieren der vorherigen Animation an sechs verschiedenen Zeitpunkten erhalten wir das folgende Diagramm:
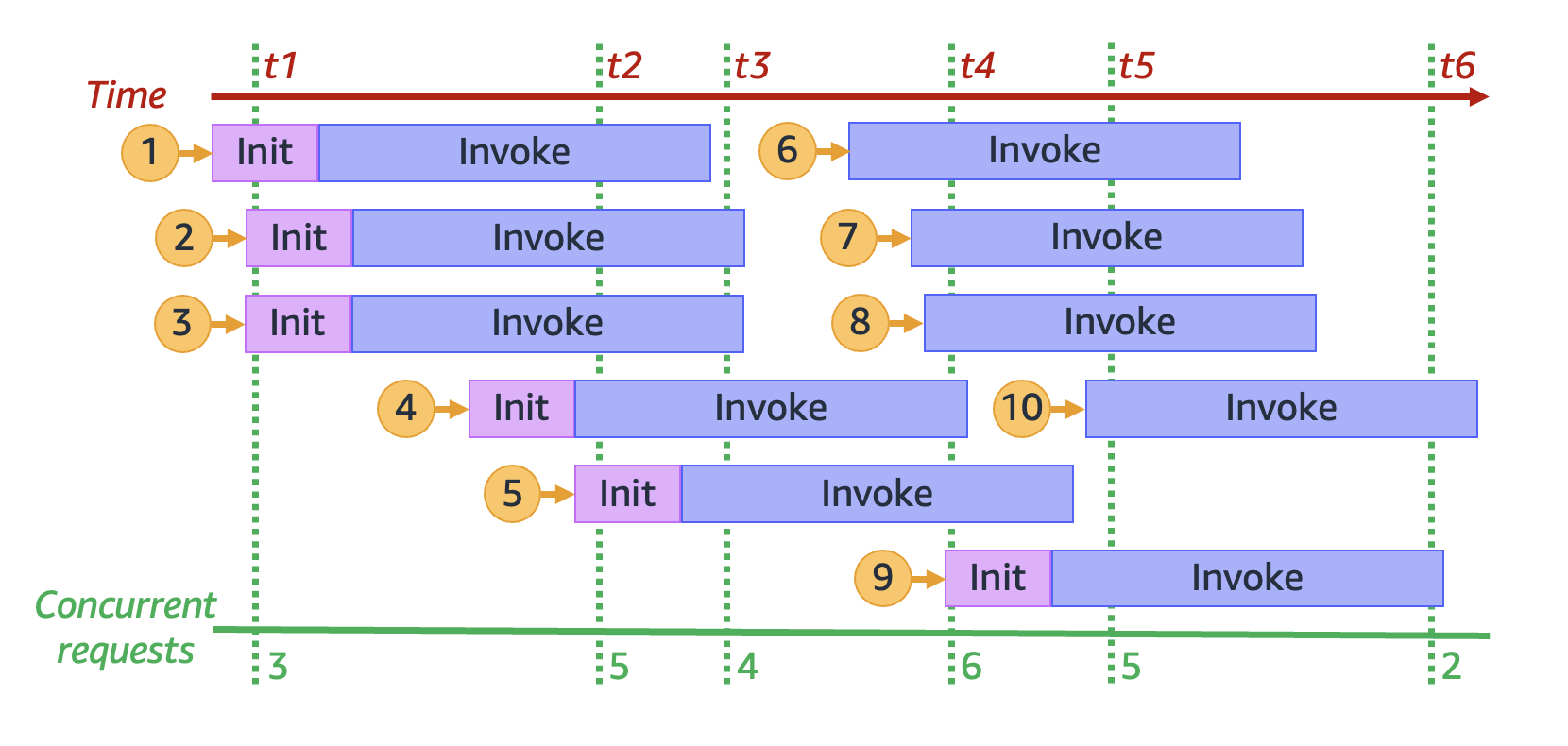
Im vorherigen Diagramm können wir zu jedem Zeitpunkt eine vertikale Linie zeichnen und die Anzahl der Umgebungen zählen, die diese Linie schneiden. Dadurch erhalten wir die Anzahl der gleichzeitigen Anfragen zu diesem Zeitpunkt. Beispielsweise gibt es zum Zeitpunkt t1 drei aktive Umgebungen, die drei gleichzeitige Anfragen bearbeiten. Die maximale Anzahl gleichzeitiger Anfragen in dieser Simulation wird zum Zeitpunkt t4 erreicht, an dem sechs aktive Umgebungen sechs gleichzeitige Anfragen bearbeiten.
Zusammengefasst beschreibt die Gleichzeitigkeit Ihrer Funktion die Anzahl der Anfragen, die diese gleichzeitig verarbeitet. Als Reaktion auf eine Zunahme der Gleichzeitigkeit Ihrer Funktion stellt Lambda mehr Instances der Ausführungsumgebung bereit, um die Anfragenachfrage zu erfüllen.
Berechnen der Gleichzeitigkeit einer Funktion
Im Allgemeinen ist die Gleichzeitigkeit eines Systems die Fähigkeit, mehr als eine Aufgabe gleichzeitig zu bearbeiten. In Lambda beschreibt die Gleichzeitigkeit die Anzahl der Anfragen, die Ihre Funktion gleichzeitig bearbeitet. Eine schnelle und praktische Methode zur Messung der Gleichzeitigkeit einer Lambda-Funktion ist die Verwendung der folgenden Formel:
Concurrency = (average requests per second) * (average request duration in seconds)
Gleichzeitigkeit unterscheidet sich von Anfragen pro Sekunde. Nehmen wir beispielsweise an, Ihre Funktion erhält durchschnittlich 100 Anfragen pro Sekunde. Wenn die durchschnittliche Dauer einer Anfrage 1 Sekunde beträgt, beträgt die Nebenläufigkeit ebenfalls 100:
Concurrency = (100 requests/second) * (1 second/request) = 100
Wenn die durchschnittliche Anfragedauer jedoch 500 ms beträgt, liegt die Nebenläufigkeit bei 50:
Concurrency = (100 requests/second) * (0.5 second/request) = 50
Was bedeutet eine Gleichzeitigkeit von 50 in der Praxis? Wenn die durchschnittliche Anfragedauer 500 ms beträgt, können Sie davon ausgehen, dass eine Instance Ihrer Funktion zwei Anfragen pro Sekunde verarbeiten kann. Dementsprechend sind 50 Instances Ihrer Funktion erforderlich, um eine Last von 100 Anfragen pro Sekunde zu verarbeiten. Eine Gleichzeitigkeit von 50 bedeutet, dass Lambda 50 Instances der Ausführungsumgebung bereitstellen muss, um diesen Workload ohne Drosselung effizient zu bewältigen. So drückt man dies in Gleichungsform aus:
Concurrency = (100 requests/second) / (2 requests/second) = 50
Wenn Ihre Funktion die doppelte Anzahl von Anfragen empfängt (200 Anfragen pro Sekunde), aber nur die Hälfte der Zeit benötigt, um jede Anfrage zu verarbeiten (250 ms), beträgt die Nebenläufigkeit immer noch 50:
Concurrency = (200 requests/second) * (0.25 second/request) = 50
Angenommen, Sie haben eine Funktion, deren Ausführung im Durchschnitt 200 ms benötigt. Während der Spitzenlast beobachten Sie 5 000 Anfragen pro Sekunde. Wie hoch ist die Gleichzeitigkeit Ihrer Funktion während der Spitzenlast?
Die durchschnittliche Funktionsdauer beträgt 200 ms oder 0,2 Sekunden. Mithilfe der Nebenläufigkeitsformel können Sie die Zahlen einfügen, um eine Nebenläufigkeit von 1 000 zu erhalten:
Concurrency = (5,000 requests/second) * (0.2 seconds/request) = 1,000
Alternativ bedeutet eine durchschnittliche Funktionsdauer von 200 ms, dass Ihre Funktion 5 Anfragen pro Sekunde verarbeiten kann. Um den Workload von 5 000 Anfragen pro Sekunde zu bewältigen, benötigen Sie 1 000 Instances der Ausführungsumgebung. Die Gleichzeitigkeit beträgt also 1 000:
Concurrency = (5,000 requests/second) / (5 requests/second) = 1,000
Verständnis der reservierten Gleichzeitigkeit und der bereitgestellten Gleichzeitigkeit
Standardmäßig verfügt Ihr Konto über eine Nebenläufigkeitsgrenze von 1 000 gleichzeitigen Ausführungen für alle Funktionen in einer Region. Ihre Funktionen teilen sich diesen Pool von 1 000 gleichzeitigen Anwendungen auf Bedarfsbasis. Bei Ihren Funktionen kommt es zu einer Drosselung (d. h. sie beginnen, Anfragen zu verwerfen), wenn Ihnen die verfügbare Parallelität ausgeht.
Einige Ihrer Funktionen sind möglicherweise kritischer als andere. Daher sollten Sie die Nebenläufigkeitseinstellungen konfigurieren, um sicherzustellen, dass kritische Funktionen die benötigte Gleichzeitigkeit erhalten. Es gibt zwei Arten von Gleichzeitigkeitskontrollen: reservierte Gleichzeitigkeit und bereitgestellte Gleichzeitigkeit.
-
Verwenden Sie die reservierte Parallelität, um die maximale und die minimale Anzahl gleichzeitiger Instances festzulegen, um einen Teil der Parallelität Ihres Kontos für eine Funktion zu reservieren. Dies ist nützlich, wenn Sie nicht möchten, dass andere Funktionen die gesamte verfügbare nicht reservierte Gleichzeitigkeit in Anspruch nehmen. Wenn für eine Funktion Gleichzeitigkeit reserviert ist, kann keine andere Funktion diese Gleichzeitigkeit nutzen.
-
Verwenden Sie die bereitgestellte Gleichzeitigkeit, um eine Reihe von Umgebungs-Instances für eine Funktion vorab zu initialisieren. Dies ist nützlich, um Kaltstartlatenzen zu reduzieren.
Reservierte Gleichzeitigkeit
Wenn Sie sicherstellen möchten, dass für Ihre Funktion jederzeit ein gewisses Maß an Gleichzeitigkeit verfügbar ist, verwenden Sie reservierte Gleichzeitigkeit.
Reservierte Parallelität legt die maximale und minimale Anzahl der gleichzeitigen Instances fest, die Sie Ihrer Funktion zuweisen möchten. Wenn Sie einer Funktion reservierte Gleichzeitigkeit zuweisen, kann keine andere Funktion diese Gleichzeitigkeit nutzen. Mit anderen Worten, das Festlegen von reservierter Gleichzeitigkeit kann sich auf den Gleichzeitigkeits-Pool auswirken, der anderen Funktionen zur Verfügung steht. Funktionen, die nicht über reservierte Gleichzeitigkeit verfügen, teilen sich den verbleibenden Pool an nicht reservierter Gleichzeitigkeit.
Das Konfigurieren der reservierten Gleichzeitigkeit wird auf das gesamte Gleichzeitigkeitslimit Ihres Kontos angerechnet. Für die Konfiguration reservierter Gleichzeitigkeit für eine Funktion wird keine Gebühr erhoben.
Betrachten Sie das folgende Diagramm, um die reservierte Gleichzeitigkeit besser zu verstehen:
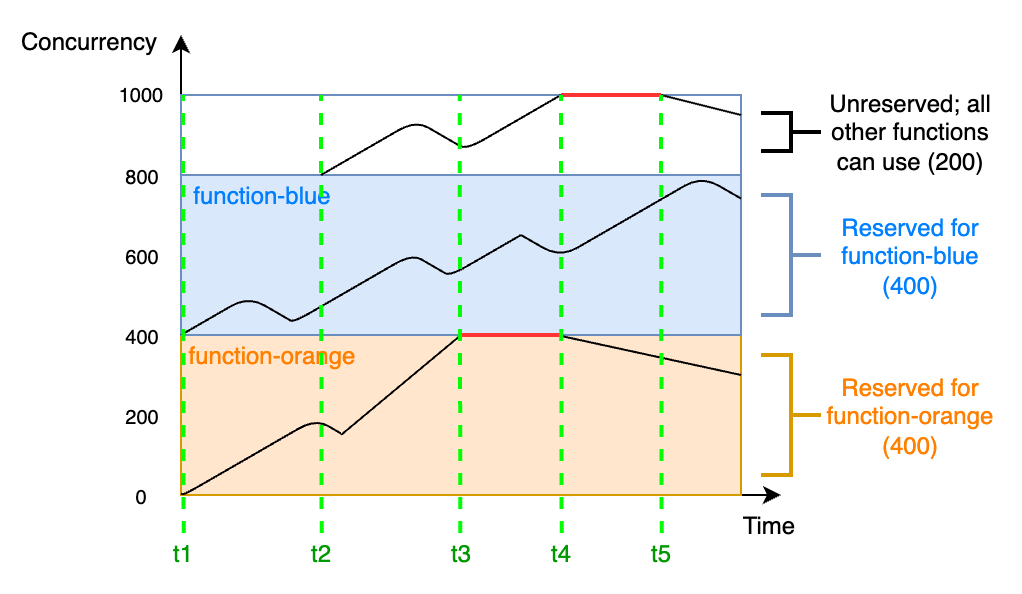
In diesem Diagramm ist das Gleichzeitigkeitslimit Ihres Kontos für alle Funktionen in diesem Bereich auf das Standardlimit von 1 000 festgelegt. Angenommen, Sie haben zwei kritische Funktionen, function-blue und function-orange, die routinemäßig hohe Aufrufvolumina erwarten. Sie entscheiden sich, 400 Einheiten reservierter Gleichzeitigkeit für function-blue und 400 Einheiten reservierter Gleichzeitigkeit für function-orange einzusetzen. In diesem Beispiel müssen sich alle anderen Funktionen in Ihrem Konto die verbleibenden 200 Einheiten an nicht reservierter Gleichzeitigkeit teilen.
Das Diagramm enthält fünf wichtige Punkte:
-
Bei
t1beginnen sowohlfunction-orangeals auchfunction-bluemit dem Empfang von Anfragen. Jede Funktion beginnt, ihren zugewiesenen Teil der reservierten Gleichzeitigkeitseinheiten zu verbrauchen. -
Bei
t2erhaltenfunction-orangeundfunction-bluestetig mehr Anfragen. Gleichzeitig stellen Sie einige andere Lambda-Funktionen bereit, die mit dem Empfang von Anfragen beginnen. Sie weisen diesen anderen Funktionen keine reservierte Nebenläufigkeit zu. Diese beginnen mit der Verwendung der verbleibenden 200 Einheiten der nicht reservierten Gleichzeitigkeit. -
Bei
t3erreichtfunction-orangedie maximale Gleichzeitigkeit von 400. Obwohl es an anderer Stelle in Ihrem Konto ungenutzte Gleichzeitigkeit gibt, kannfunction-orangenicht darauf zugreifen. Die rote Linie zeigt an, dassfunction-orangegedrosselt wird und Lambda-Anfragen möglicherweise verwirft. -
Bei
t4beginntfunction-orangeweniger Anfragen zu erhalten und wird nicht mehr gedrosselt. Ihre anderen Funktionen erfahren jedoch einen Anstieg des Datenverkehrs und werden gedrosselt. Obwohl es an anderer Stelle in Ihrem Konto ungenutzte Gleichzeitigkeit gibt, können diese anderen Funktionen nicht darauf zugreifen. Die rote Linie zeigt an, dass Ihre anderen Funktionen gedrosselt werden. -
Bei
t5beginnen andere Funktionen weniger Anfragen zu erhalten und werden nicht mehr gedrosselt.
Anhand dieses Beispiels können Sie sehen, dass die Reservierung von Gleichzeitigkeit folgende Auswirkungen hat:
-
Ihre Funktion kann unabhängig von anderen Funktionen in Ihrem Konto skaliert werden. Alle Funktionen Ihres Kontos in derselben Region, die über keine reservierte Gleichzeitigkeit verfügen, teilen sich den Pool an nicht reservierter Gleichzeitigkeit. Ohne reservierte Gleichzeitigkeit können andere Funktionen möglicherweise Ihre gesamte verfügbare Gleichzeitigkeit verbrauchen. Dadurch wird verhindert, dass kritische Funktion bei Bedarf hochskalieren.
-
Ihre Funktion kann nicht unkontrolliert aufskaliert werden. Die reservierte Parallelität legt eine Obergrenze für die maximale und minimale Parallelität Ihrer Funktion fest. Dies bedeutet, dass Ihre Funktion keine für andere Funktionen reservierte Gleichzeitigkeit oder Gleichzeitigkeit aus dem nicht reservierten Pool verwenden kann. Darüber hinaus dient die reservierte Parallelität sowohl als Untergrenze als auch als Obergrenze. Sie reserviert die angegebene Kapazität ausschließlich für Ihre Funktion und verhindert gleichzeitig, dass sie über diese Grenze hinaus skaliert wird. Sie können Gleichzeitigkeit reservieren, um zu verhindern, dass Ihre Funktion die gesamte verfügbare Gleichzeitigkeit in Ihrem Konto verwendet oder nachgelagerte Ressourcen überlastet.
-
Möglicherweise können Sie nicht die gesamte verfügbare Gleichzeitigkeit Ihres Kontos nutzen. Das Reservieren von Gleichzeitigkeit wird auf Ihr Kontolimit für Gleichzeitigkeit angerechnet, aber das bedeutet auch, dass andere Funktionen diesen Teil der reservierten Gleichzeitigkeit nicht verwenden können. Wenn Ihre Funktion nicht die gesamte Gleichzeitigkeit verbraucht, die Sie dafür reservieren, verschwenden Sie diese Gleichzeitigkeit effektiv. Das ist kein Problem, es sei denn, andere Funktionen in Ihrem Konto könnten von der ungenutzten Gleichzeitigkeit profitieren.
Informationen zur Verwaltung der reservierten Nebenläufigkeitseinstellungen für Ihre Funktionen finden Sie unter Konfigurieren reservierter Gleichzeitigkeit für eine Funktion.
Bereitgestellte Gleichzeitigkeit
Sie verwenden die reservierte Gleichzeitigkeit, um die maximale Anzahl der für eine Lambda-Funktion reservierten Ausführungsumgebungen festzulegen. Keine dieser Umgebungen ist jedoch vorinitialisiert. Infolgedessen können Ihre Funktionsaufrufe länger dauern, da Lambda zuerst die neue Umgebung initialisieren muss, bevor diese zum Aufrufen Ihrer Funktion verwendet werden kann. Wenn Lambda eine neue Umgebung initialisieren muss, um einen Aufruf auszuführen, wird dies als Kaltstart bezeichnet. Um Kaltstarts zu vermeiden, können Sie die bereitgestellte Gleichzeitigkeit verwenden.
Die bereitgestellte Nebenläufigkeit beschreibt die Anzahl der vorinitialisierten Ausführungsumgebungen, die Sie Ihrer Funktion zuweisen möchten. Wenn Sie bereitgestellte Gleichzeitigkeit für eine Funktion festlegen, initialisiert Lambda diese Anzahl von Ausführungsumgebungen, damit sie bereit sind, sofort auf Funktionsanfragen zu reagieren.
Anmerkung
Die Verwendung von bereitgestellter Gleichzeitigkeit verursacht zusätzliche Gebühren für Ihr Konto. Wenn Sie mit den Laufzeiten Java 11 oder Java 17 arbeiten, können Sie Lambda auch verwenden, SnapStart um Kaltstartprobleme ohne zusätzliche Kosten zu beheben. SnapStart verwendet zwischengespeicherte Snapshots Ihrer Ausführungsumgebung, um die Startleistung erheblich zu verbessern. Sie können nicht beide SnapStart und die bereitgestellte Parallelität auf derselben Funktionsversion verwenden. Weitere Informationen zu SnapStart Funktionen, Einschränkungen und unterstützten Regionen finden Sie unter. Verbesserung der Startleistung mit Lambda SnapStart
Bei der Verwendung von bereitgestellter Gleichzeitigkeit erneuert Lambda weiterhin die Ausführungsumgebung im Hintergrund. Dies kann beispielsweise nach einem Aufruffehler der Fall sein. Lambda stellt jedoch zu jedem Zeitpunkt sicher, dass die Anzahl der vorinitialisierten Umgebungen dem Wert der von Ihrer Funktion bereitgestellten Gleichzeitigkeitseinstellung entspricht. Wichtig: Selbst wenn Sie die bereitgestellte Parallelität verwenden, kann es dennoch zu einer Kaltstartverzögerung kommen, wenn Lambda die Ausführungsumgebung zurücksetzen muss.
Im Gegensatz dazu kann Lambda bei Verwendung von reservierter Parallelität eine Umgebung nach einem Zeitraum der Inaktivität vollständig beenden. Das folgende Diagramm veranschaulicht dies, indem der Lebenszyklus einer einzelnen Ausführungsumgebung beim Konfigurieren Ihrer Funktion mit reservierter Gleichzeitigkeit mit bereitgestellter Gleichzeitigkeit verglichen wird.
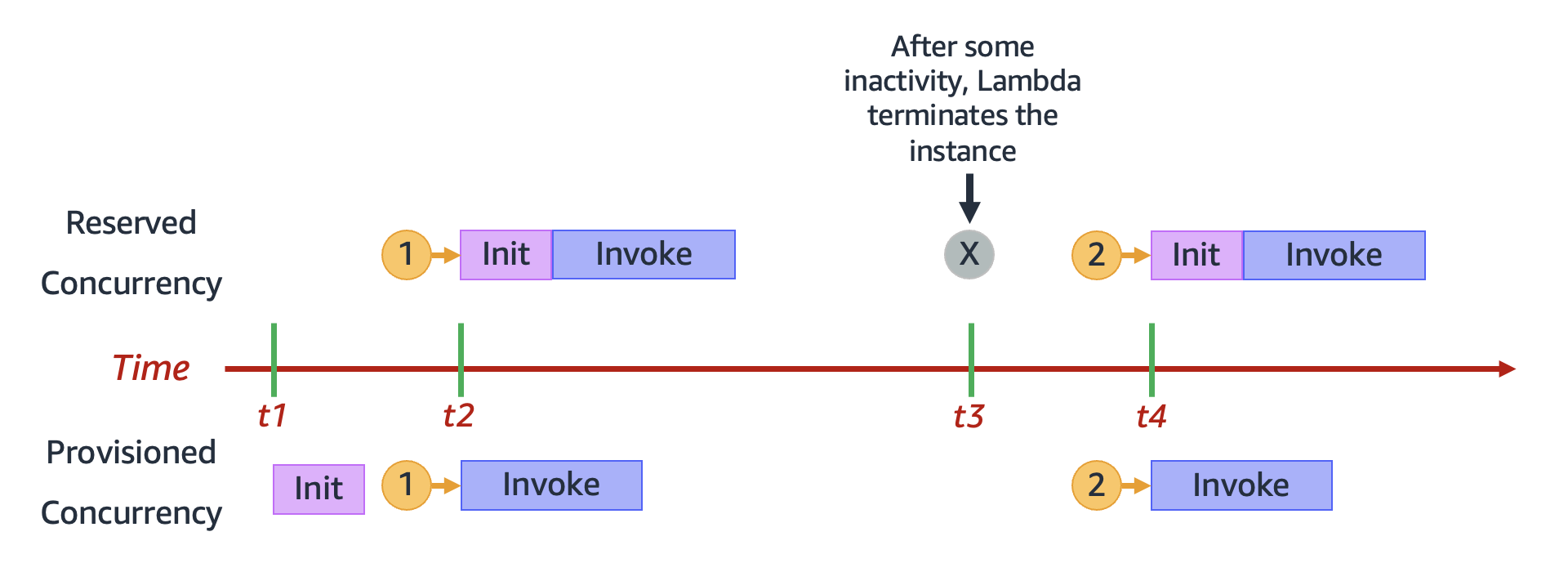
Das Diagramm enthält vier wichtige Punkte:
| Zeit | Reservierte Gleichzeitigkeit | Bereitgestellte Gleichzeitigkeit |
|---|---|---|
|
t1 |
Es passiert nichts. |
Lambda initialisiert eine Instance der Ausführungsumgebung vorab. |
|
t2 |
Anfrage 1 wird empfangen. Lambda muss eine neue Instance der Ausführungsumgebung initialisieren. |
Anfrage 1 wird empfangen. Lambda verwendet die vorinitialisierte Umgebungs-Instance. |
|
t3 |
Nach einer gewissen Inaktivität beendet Lambda die aktive Umgebungs-Instance. |
Es passiert nichts. |
|
t4 |
Anfrage 2 wird empfangen. Lambda muss eine neue Instance der Ausführungsumgebung initialisieren. |
Anfrage 2 wird empfangen. Lambda verwendet die vorinitialisierte Umgebungs-Instance. |
Betrachten Sie das folgende Diagramm, um die bereitgestellte Gleichzeitigkeit besser zu verstehen:
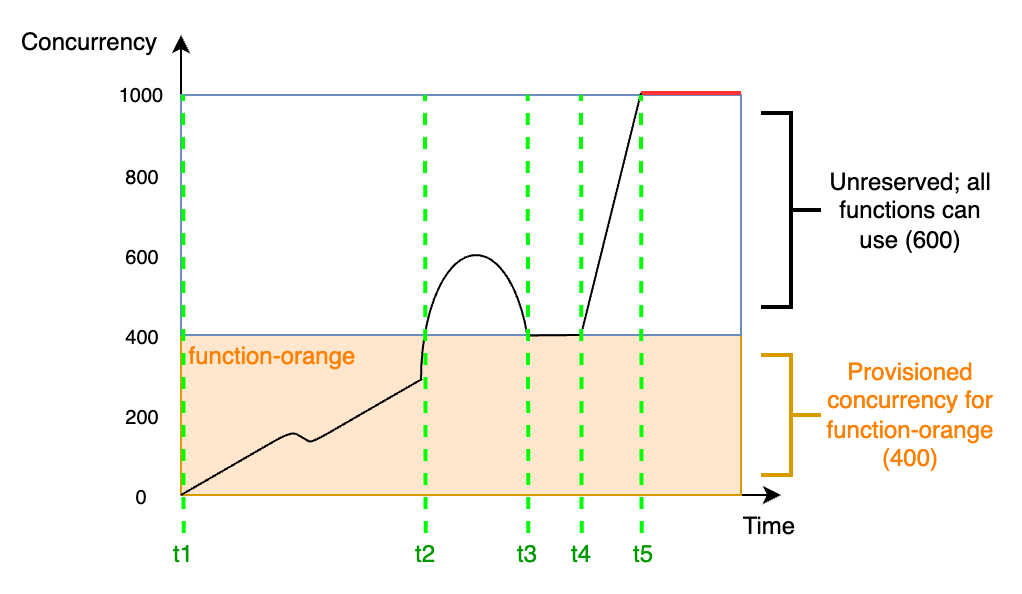
In diesem Diagramm haben Sie eine Kontogleichzeitigkeitslimit von 1 000. Sie entscheiden sich, 400 Einheiten der bereitgestellten Gleichzeitigkeit an function-orange zu vergeben. Alle Funktionen in Ihrem Konto, einschließlich function-orange, können die verbleibenden 600 Einheiten der nicht reservierten Gleichzeitigkeit nutzen.
Das Diagramm enthält fünf wichtige Punkte:
-
Bei
t1beginntfunction-orangemit dem Empfang von Anfragen. Da Lambda 400 Instances der Ausführungsumgebung vorinitialisiert hat, istfunction-orangefür den sofortigen Aufruf bereit. -
Bei
t2erreichtfunction-orange400 gleichzeitige Anfragen. Infolgedessen gehtfunction-orangedie bereitgestellte Gleichzeitigkeit aus. Da jedoch immer noch keine nicht reservierte Gleichzeitigkeit verfügbar ist, kann Lambda dies verwenden, um zusätzliche Anfragen anfunction-orangezu verarbeiten (es gibt keine Drosselung). Lambda muss neue Instances erstellen, um diese Anfragen zu bearbeiten und bei Ihrer Funktion kann es zu Kaltstartlatenzen kommen. -
Bei
t3kehrtfunction-orangenach einem kurzen Anstieg des Datenverkehrs zu 400 gleichzeitigen Anfragen zurück. Lambda ist wieder in der Lage, alle Anfragen ohne Kaltstartlatenzen zu bearbeiten. -
Bei
t4kommt es bei Funktionen in Ihrem Konto zu einem starken Anstieg des Datenverkehrs. Dieser Anstieg kann vonfunction-orangeoder einer anderen Funktion in Ihrem Konto stammen. Lambda verwendet nicht reservierte Gleichzeitigkeit, um diese Anfragen zu bearbeiten. -
Bei
t5erreichen die Funktionen in Ihrem Konto das maximale Gleichzeitigkeitslimit von 1 000 und es kommt zu Drosselungen.
Im vorherigen Beispiel wurde nur die bereitgestellte Nebenläufigkeit berücksichtigt. In der Praxis können Sie für eine Funktion sowohl die bereitgestellte als auch die reservierte Gleichzeitigkeit festlegen. Sie können dies beispielsweise tun, wenn Sie eine Funktion haben, die wochentags eine konstante Anzahl von Aufrufen verarbeitet, aber an den Wochenenden regelmäßig Datenverkehrsspitzen aufweist. In diesem Fall könnten Sie die bereitgestellte Gleichzeitigkeit verwenden, um eine Basismenge an Umgebungen festzulegen, die Anfragen an Wochentagen verarbeiten, und die reservierte Gleichzeitigkeit verwenden, um die Spitzenlasten am Wochenende zu verarbeiten. Betrachten Sie das folgende Diagramm:
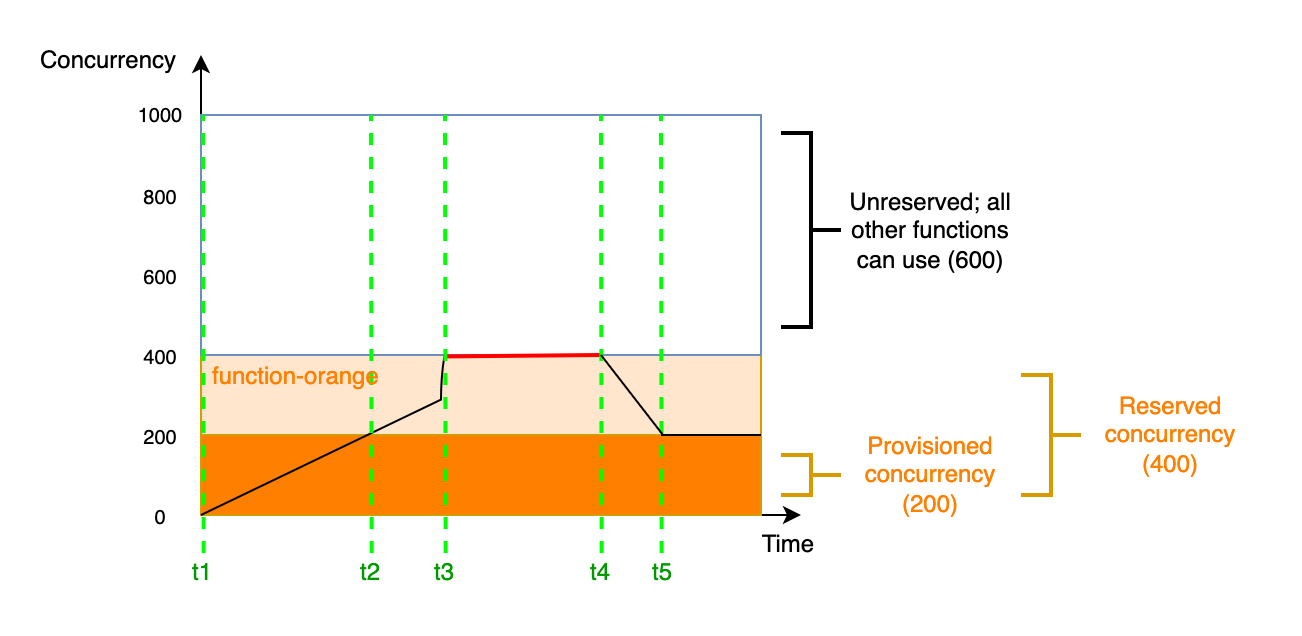
Nehmen wir in diesem Diagramm an, dass Sie 200 Einheiten bereitgestellter Gleichzeitigkeit und 400 Einheiten reservierter Gleichzeitigkeit für function-orange konfigurieren. Da Sie die reservierte Gleichzeitigkeit konfiguriert haben, kann function-orange keine der 600 Einheiten der nicht reservierten Gleichzeitigkeit verwenden.
Dieses Diagramm enthält fünf wichtige Punkte:
-
Bei
t1beginntfunction-orangemit dem Empfang von Anfragen. Da Lambda 200 Instances der Ausführungsumgebung vorinitialisiert hat, istfunction-orangefür den sofortigen Aufruf bereit. -
Bei
t2verbrauchtfunction-orangedie gesamte bereitgestellte Gleichzeitigkeit.function-orangekann weiterhin Anfragen über reservierte Gleichzeitigkeit bearbeiten, allerdings kann es bei diesen Anfragen zu Kaltstartlatenzen kommen. -
Bei
t3erreichtfunction-orange400 gleichzeitige Anfragen. Dadurch verbrauchtfunction-orangedie gesamte reservierte Gleichzeitigkeit. Dafunction-orangekeine nicht reservierte Gleichzeitigkeit nutzen kann, werden die Anfragen gedrosselt. -
Bei
t4beginntfunction-orangeweniger Anfragen zu erhalten und wird nicht mehr gedrosselt. -
Bei
t5sinktfunction-orangeauf 200 gleichzeitige Anfragen, sodass alle Anfragen wieder bereitgestellte Nebenläufigkeit verwenden können (d. h. keine Kaltstartlatenzen).
Sowohl die reservierte Gleichzeitigkeit als auch die bereitgestellte Gleichzeitigkeit werden auf das Gleichzeitigkeitslimit Ihres Kontos und die regionalen Kontingente angerechnet. Mit anderen Worten, die Zuweisung von reservierter und bereitgestellter Gleichzeitigkeit kann sich auf den Gleichzeitigkeit -Pool auswirken, der anderen Funktionen zur Verfügung steht. Für die Konfiguration der bereitgestellten Parallelität fallen Gebühren für Sie an. AWS-Konto
Anmerkung
Wenn die Menge der bereitgestellten Nebenläufigkeit für die Versionen und Aliase einer Funktion zur reservierten Nebenläufigkeit der Funktion hinzukommt, werden alle Aufrufe mit bereitgestellter Nebenläufigkeit ausgeführt. Diese Konfiguration hat auch zur Folge, dass die nicht veröffentlichte Version der Funktion ($LATEST) gedrosselt wird, was die Ausführung verhindert. Sie können nicht mehr bereitgestellte Gleichzeitigkeit als reservierte Gleichzeitigkeit für eine Funktion zuweisen.
Informationen zur Verwaltung der Einstellungen für reservierte Nebenläufigkeit für Ihre Funktionen finden Sie unter Konfigurieren von Provisioned Concurrency für eine Funktion. Informationen zum Automatisieren der bereitgestellten Gleichzeitigkeitsskalierung basierend auf einem Zeitplan oder der Anwendungsnutzung finden Sie unter Auto Scaling von Anwendungen zur Automatisierung der Verwaltung von Gleichzeitigkeit bei der Bereitstellung.
So weist Lambda bereitgestellte Gleichzeitigkeit zu
Bereitgestellte Gleichzeitigkeit wird nicht sofort nach der Konfiguration online geschaltet. Lambda beginnt die Zuweisung bereitgestellter Gleichzeitigkeit nach ein oder zwei Minuten Vorbereitung. Für jede Funktion kann Lambda jede Minute bis zu 6.000 Ausführungsumgebungen bereitstellen, unabhängig davon AWS-Region. Dies entspricht exakt der Skalierungsrate für die Gleichzeitigkeit von Funktionen.
Wenn Sie eine Anforderung zur Zuweisung bereitgestellter Gleichzeitigkeit einreichen, können Sie erst wieder auf diese Umgebungen zugreifen, wenn Lambda die Zuweisung vollständig abgeschlossen hat. Wenn Sie beispielsweise 5 000 bereitgestellte Gleichzeitigkeit anfordern, kann keine Ihrer Anfragen bereitgestellte Gleichzeitigkeit verwenden, bis Lambda die Zuweisung der 5 000 Ausführungsumgebungen vollständig abgeschlossen hat.
Vergleich zwischen reservierter und bereitgestellter Gleichzeitigkeit
Die folgende Tabelle fasst reservierte und bereitgestellte Nebenläufigkeit zusammen und vergleicht sie.
| Thema | Reservierte Gleichzeitigkeit | Bereitgestellte Gleichzeitigkeit |
|---|---|---|
|
Definition |
Maximale Anzahl von Instances in der Ausführungsumgebung für Ihre Funktion. |
Festgelegte Anzahl von vorbereiteten Instances in der Ausführungsumgebung für Ihre Funktion. |
|
Bereitstellungsverhalten |
Lambda stellt neue Instances auf On-Demand-Basis bereit. |
Lambda stellt Instances vorab bereit (d. h. bevor Ihre Funktion mit dem Empfang von Anfragen beginnt). |
|
Kaltstartverhalten |
Kaltstartlatenz möglich, da Lambda bei Bedarf neue Instances erstellen muss. |
Eine Kaltstartlatenz ist nicht möglich, da Lambda keine Instances On-Demand erstellen muss. |
|
Drosselungsverhalten |
Die Funktion wurde gedrosselt, als das reservierte Gleichzeitigkeitslimit erreicht wurde. |
Wenn die reservierte Gleichzeitigkeit nicht festgelegt ist: Die Funktion verwendet die nicht reservierte Gleichzeitigkeit, wenn das bereitgestellte Gleichzeitigkeitslimit erreicht ist. Wenn reservierte Gleichzeitigkeit festgelegt ist: Funktion wird gedrosselt, wenn das Limit für reservierte Gleichzeitigkeit erreicht wird. |
|
Standardverhalten, falls nicht festgelegt |
Die Funktion verwendet nicht reservierte Gleichzeitigkeit, die in Ihrem Konto verfügbar ist. |
Lambda stellt keine Instances vorab bereit. Wenn die reservierte Gleichzeitigkeit nicht festgelegt ist, verwendet die Funktion stattdessen die nicht reservierte Gleichzeitigkeit, die in Ihrem Konto verfügbar ist. Wenn reservierte Gleichzeitigkeit festgelegt ist: die Funktion verwendet reservierte Gleichzeitigkeit. |
|
Preisgestaltung |
Keine zusätzlichen Gebühren. |
Verursacht zusätzliche Gebühren. |
Gleichzeitigkeit und Anforderungen pro Sekunde verstehen
Wie im vorherigen Abschnitt erwähnt, unterscheidet sich die Gleichzeitigkeit von den Anforderungen pro Sekunde. Diese Unterscheidung ist besonders wichtig, wenn Sie mit Funktionen arbeiten, die eine durchschnittliche Anforderungsdauer von weniger als 100 ms haben.
Für alle Funktionen in Ihrem Konto erzwingt Lambda ein Limit für Anfragen pro Sekunde, das dem 10-fachen der Gleichzeitigkeit Ihres Kontos entspricht. Da der Standardgrenzwert für die Gleichzeitigkeit von Konten beispielsweise 1 000 beträgt, können die Funktionen in Ihrem Konto maximal 10 000 Anfragen pro Sekunde verarbeiten.
Stellen Sie sich etwa eine Funktion mit einer durchschnittlichen Anforderungsdauer von 50 ms vor. Bei 20 000 Anforderungen pro Sekunde lautet die Gleichzeitigkeit dieser Funktion wie folgt:
Concurrency = (20,000 requests/second) * (0.05 second/request) = 1,000
Ausgehend von diesem Ergebnis könnte man annehmen, dass die Gleichzeitigkeitsgrenze von 1 000 Konten ausreicht, um diese Last zu bewältigen. Aufgrund der Begrenzung auf 10 000 Anfragen pro Sekunde kann Ihre Funktion jedoch nur 10 000 der insgesamt 20 000 Anfragen pro Sekunde bearbeiten. Bei dieser Funktion kommt es zu einer Drosselung.
Fazit: Sie müssen bei der Konfiguration der Nebenläufigkeitseinstellungen für Ihre Funktionen sowohl Nebenläufigkeit als auch Anforderungen pro Sekunde berücksichtigen. In diesem Fall müssen Sie eine Erhöhung des Kontogleichzeitigkeitslimits auf 2 000 beantragen, da sich dadurch Ihr Gesamtlimit für Anfragen pro Sekunde auf 20 000 erhöhen würde.
Anmerkung
Basierend auf diesem Limit für Anfragen pro Sekunde ist es falsch zu sagen, dass jede Lambda-Ausführungsumgebung nur maximal zehn Anfragen pro Sekunde verarbeiten kann. Anstatt die Auslastung einer einzelnen Ausführungsumgebung zu beobachten, berücksichtigt Lambda bei der Berechnung der Quoten nur die Gesamtgleichzeitigkeit und die Gesamtanforderungen pro Sekunde.
Angenommen, Sie haben eine Funktion, deren Ausführung im Durchschnitt 20 ms benötigt. Während der Spitzenlast beobachten Sie 30 000 Anfragen pro Sekunde. Wie hoch ist die Gleichzeitigkeit Ihrer Funktion während der Spitzenlast?
Die durchschnittliche Funktionsdauer beträgt 20 ms oder 0,02 Sekunden. Mithilfe der Parallelitätsformel können Sie die Zahlen einfügen, um eine Parallelität von 600 zu erhalten:
Concurrency = (30,000 requests/second) * (0.02 seconds/request) = 600
Standardmäßig scheint eine Kontogleichzeitigkeitslimit von 1 000 ausreichend zu sein, um diese Last zu bewältigen. Das Limit für Anfragen pro Sekunde von 10 000 reicht jedoch nicht aus, um die eingehenden 30 000 Anfragen pro Sekunde zu verarbeiten. Um den 30 000 Anfragen in vollem Umfang gerecht zu werden, müssen Sie eine Erhöhung des Kontogleichzeitigkeitslimits auf 3 000 oder mehr beantragen.
Das Limit für Anfragen pro Sekunde gilt für alle Kontingente in Lambda, die Gleichzeitigkeit beinhalten. Mit anderen Worten: Sie gilt für synchrone On-Demand-Funktionen, Funktionen, die bereitgestellte Gleichzeitigkeit verwenden, und Skalierungsverhalten bei Gleichzeitigkeit. Im Folgenden finden Sie beispielsweise einige Szenarien, in denen Sie sowohl Ihre Grenzwerte für Parallelität als auch für Anfragen pro Sekunde sorgfältig abwägen müssen:
-
Bei einer Funktion, die On-Demand-Parallelität verwendet, kann es zu einem Anstieg der Parallelität um 500 Mal alle 10 Sekunden oder um 5 000 Anfragen pro Sekunde alle 10 Sekunden kommen, je nachdem, was zuerst eintritt.
-
Angenommen, Sie haben eine Funktion, die eine bereitgestellte Gleichzeitigkeitszuweisung von 10 hat. Diese Funktion geht nach 10 Gleichzeitigkeiten oder 100 Anfragen pro Sekunde, je nachdem, was zuerst eintritt, in die On-Demand-Gleichzeitigkeit über.
Gleichzeitigkeitskontingente
Lambda legt Kontingente für die Gesamtmenge der Nebenläufigkeit fest, die Sie für alle Funktionen in einer Region verwenden können. Diese Kontingente bestehen auf zwei Ebenen:
-
Auf Kontoebene können Ihre Funktionen standardmäßig bis zu 1 000 Einheiten an Gleichzeitigkeit verwenden. Informationen zum Erhöhen dieses Limits finden Sie unter Anfordern einer Kontingenterhöhung im Benutzerhandbuch für Service Quotas.
-
Auf Funktionsebene können Sie standardmäßig bis zu 900 Nebenläufigkeitseinheiten für alle Ihre Funktionen reservieren. Unabhängig von Ihrem Gesamtlimit für die Kontonebenläufigkeit reserviert Lambda immer 100 Nebenläufigkeitseinheiten für Ihre Funktionen, die Nebenläufigkeit nicht explizit reservieren. Wenn Sie beispielsweise Ihr Limit für die Nebenläufigkeit Ihres Kontos auf 2 000 erhöht haben, können Sie auf Funktionsebene bis zu 1 900 Einheiten an Nebenläufigkeit reservieren.
-
Sowohl auf Konto- als auch auf Funktionsebene erzwingt Lambda außerdem ein Limit für Anfragen pro Sekunde, das dem Zehnfachen der entsprechenden Gleichzeitigkeitsquote entspricht. Dies gilt beispielsweise für die Gleichzeitigkeit auf Kontoebene, für Funktionen, die die Gleichzeitigkeit auf Abruf verwenden, für Funktionen, die die provisorische Gleichzeitigkeit verwenden und für das Skalierungsverhalten der Gleichzeitigkeit. Weitere Informationen finden Sie unter Gleichzeitigkeit und Anforderungen pro Sekunde verstehen.
Um Ihr aktuelles Kontingent für Parallelität auf Kontoebene zu überprüfen, verwenden Sie AWS Command Line Interface (AWS CLI), um den folgenden Befehl auszuführen:
aws lambda get-account-settings
Die Ausgabe sollte ungefähr wie folgt aussehen:
{ "AccountLimit": { "TotalCodeSize": 80530636800, "CodeSizeUnzipped": 262144000, "CodeSizeZipped": 52428800, "ConcurrentExecutions": 1000, "UnreservedConcurrentExecutions": 900 }, "AccountUsage": { "TotalCodeSize": 410759889, "FunctionCount": 8 } }
ConcurrentExecutions ist Ihr Gesamtkontingent für die Nebenläufigkeit auf Kontoebene. UnreservedConcurrentExecutions ist die Menge an verbleibender Nebenläufigkeit, die Sie Ihren Funktionen noch zuweisen können.
Erhält Ihre Funktion mehr Anfragen, sorgt Lambda automatisch für die Skalierung der Anzahl der Ausführungsumgebungen, bis Ihr Konto das Nebenläufigkeitskontingent erreicht. Zum Schutz vor einer Überskalierung als Reaktion auf plötzliche Datenverkehrsspitzen begrenzt Lambda jedoch, wie schnell Ihre Funktionen skaliert werden können. Diese Gleichzeitigkeits-Skalierungsrate ist die maximale Rate, mit der Funktionen in Ihrem Konto als Reaktion auf erhöhte Anforderungen skaliert werden können. (Das heißt, sie gibt an, wie schnell Lambda neue Ausführungsumgebungen erstellen kann.) Die Skalierungsrate für die Gleichzeitigkeit unterscheidet sich von der Gleichzeitigkeitsgrenze auf Kontoebene, die die Gesamtmenge der Gleichzeitigkeit darstellt, die Ihren Funktionen zur Verfügung steht.
In jeder AWS-Region Funktion beträgt Ihre Skalierungsrate für Parallelität 1.000 Instanzen der Ausführungsumgebung alle 10 Sekunden (oder 10.000 Anfragen pro Sekunde alle 10 Sekunden). Mit anderen Worten: Lambda kann jeder Ihrer Funktionen alle 10 Sekunden höchstens 1 000 zusätzliche Instanzen der Ausführungsumgebung zuweisen oder 10 000 zusätzliche Anfragen pro Sekunde bearbeiten.
Normalerweise müssen Sie sich über diese Einschränkung keine Gedanken machen. Die Skalierungsrate von Lambda ist für die meisten Anwendungsfälle ausreichend.
Wichtig ist, dass die Skalierungsrate für die Gleichzeitigkeit eine Grenze auf Funktionsebene darstellt. Das bedeutet, dass jede Funktion in Ihrem Konto unabhängig von anderen Funktionen skaliert werden kann.
Weitere Informationen zum Skalierungsverhalten finden Sie unter Lambda-Skalierungsverhalten.
