Integrações ETL zero do Aurora
Uma Integração ETL zero do Aurora com o Amazon Redshift e o Amazon SageMaker AI permite analytics e machine learning (ML) quase em tempo real usando dados do Aurora. Essa é uma solução totalmente gerenciada para disponibilizar dados transacionais no destino de analytics depois que eles são gravados em um cluster de banco de dados do Aurora. Extração, transformação e carregamento (ETL) é o processo de combinar dados de várias fontes em um grande data warehouse central.
Uma Integração ETL zero torna os dados no cluster de banco de dados do Aurora disponíveis no Amazon Redshift ou em um lakehouse do Amazon SageMaker AI quase em tempo real. Quando esses dados estiverem no data warehouse ou data lake de destino, você poderá potencializar suas workloads de analytics, ML e IA usando os recursos integrados, como machine learning, visões materializadas, compartilhamento de dados, acesso federado a vários datastores e data lakes e integrações ao Amazon SageMaker AI, ao Quick e a outros Serviços da AWS.
Para criar uma Integração ETL zero, especifique um cluster de banco de dados do Aurora como a origem e um data warehouse ou lakehouse compatível como o destino. A integração replica os dados do banco de dados de origem no data warehouse ou lakehouse de destino.
O seguinte diagrama mostra essa funcionalidade de Integração ETL zero com o Amazon Redshift:
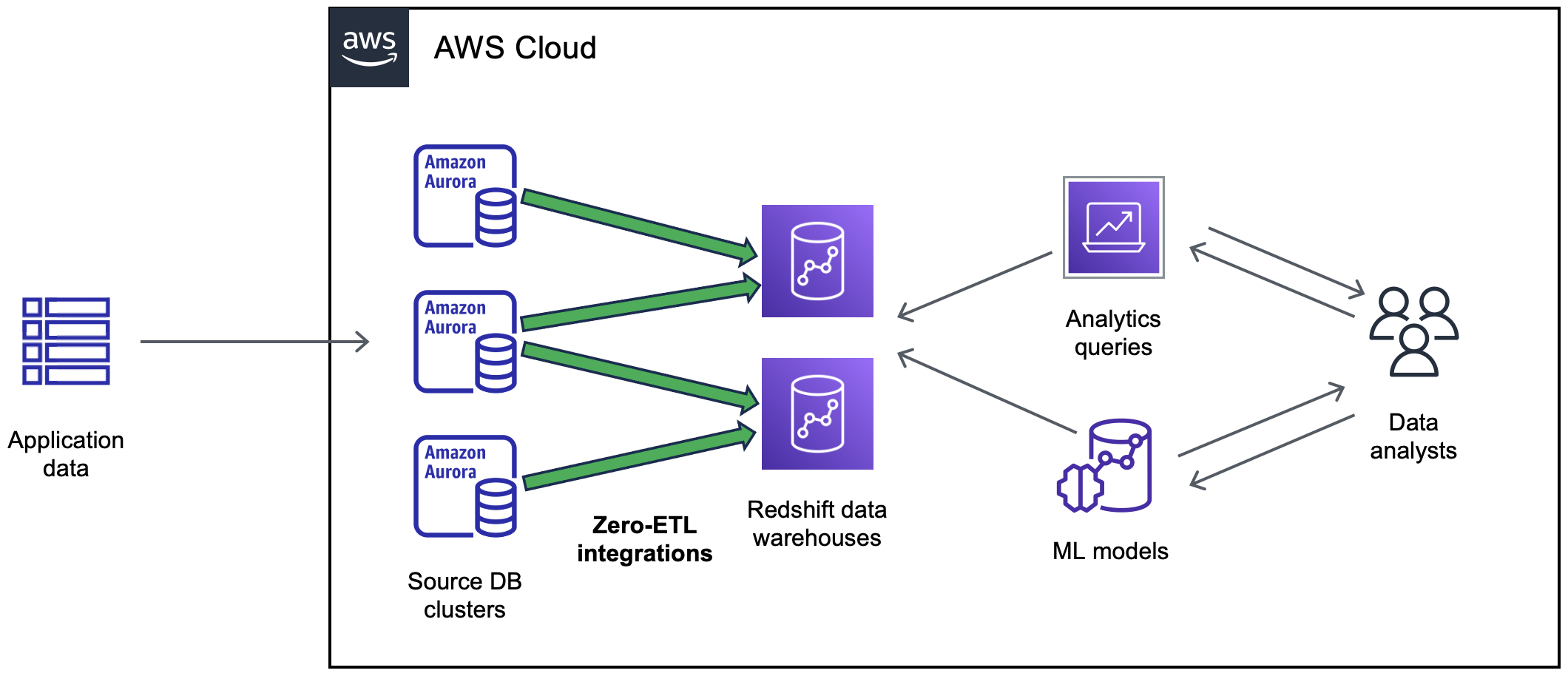
O seguinte diagrama mostra essa funcionalidade para uma Integração ETL zero com um lakehouse do Amazon SageMaker AI:

A integração monitora a integridade do pipeline de dados e se recupera de problemas quando possível. É possível criar integrações de vários clusters de banco de dados do Aurora em um único data warehouse ou lakehouse de destino, o que permite que você obtenha insights em várias aplicações.
Para ter informações sobre preços de Integrações ETL zero, consulte Definição de preço do Amazon Aurora
Tópicos
Benefícios
As Integrações ETL zero do Aurora oferecem os seguintes benefícios:
-
Ajudam você a obter insights holísticos de várias fontes de dados.
-
Eliminam a necessidade de criar e manter canais de dados complexos que executam operações de extração, transformação e carregamento (ETL). As integrações ETL zero eliminam os desafios que surgem com a criação e o gerenciamento de pipelines, provisionando-os e gerenciando-os para você.
-
Reduzem a carga e os custos operacionais para que você possa se concentrar em melhorar as aplicações.
-
Permitem que você aproveite os recursos de analytics e ML do destino pretendido para obter insights de dados transacionais e outros dados e responder de forma eficaz a eventos críticos e urgentes.
Principais conceitos
Ao começar a usar integrações ETL zero, considere os seguintes conceitos:
- Integração
-
Um pipeline de dados totalmente gerenciado que replica automaticamente dados e esquemas transacionais de um cluster de banco de dados do Aurora em um data warehouse ou catálogo.
- Cluster de banco de dados de origem
-
O cluster de banco de dados do Aurora do qual os dados são replicados. É possível especificar um cluster de banco de dados que use instâncias de bancos de dados provisionadas ou instâncias de banco de dados do Aurora serverless como origem.
- Target
-
O data warehouse ou lakehouse para o qual os dados são replicados. Há dois tipos de data warehouse: um data warehouse de cluster provisionado e um data warehouse sem servidor. Um data warehouse de cluster provisionado é um conjunto de recursos computacionais chamados nós, que são organizados em um grupo chamado cluster. Um data warehouse sem servidor é composto por um grupo de trabalho que armazena recursos computacionais e um namespace que abriga os objetos e usuários do banco de dados. Ambos os data warehouses executam um mecanismo de analytics e contêm um ou mais bancos de dados.
Um lakehouse de destino consiste em catálogos, bancos de dados, tabelas e visualizações. Para ter mais informações sobre arquitetura de lakehouse, consulte SageMaker Lakehouse components no Guia do usuário do Amazon SageMaker AI Unified Studio.
Vários clusters de banco de dados de origem podem gravar no mesmo destino.
Para obter mais informações, consulte Arquitetura do sistema de data warehouse no Guia do desenvolvedor do Amazon Redshift.
Limitações
As limitações a seguir se aplicam às Integrações ETL zero do Aurora.
Tópicos
Limitações gerais
-
O cluster de banco de dados de origem deve estar na mesma região que o destino.
-
Não será possível renomear um cluster de banco de dados ou qualquer uma de suas instâncias se o cluster tiver integrações existentes.
-
Não é possível criar várias integrações entre os mesmos bancos de dados de origem e destino.
-
Você não pode excluir um cluster de banco de dados que tenha integrações existentes. É necessário excluir todas as integrações correspondentes primeiro.
-
Se você interromper o cluster de banco de dados de origem, as últimas transações provavelmente não serão replicadas no destino enquanto você não retomar o cluster.
-
Se o cluster for a origem de uma implantação azul/verde, os ambientes azul e verde não poderão ter integrações ETL zero existentes durante a transição. Você deve excluir a integração primeiro, alternar e, depois, recriá-la.
-
Um cluster de banco de dados deve conter pelo menos uma instância de banco de dados para ser a origem de uma integração.
-
Você não pode criar uma integração para um cluster de banco de dados de origem que seja um clone entre contas, como aqueles compartilhados usando AWS Resource Access Manager (AWS RAM).
-
Se o cluster de origem for o cluster de banco de dados primário em um banco de dados global do Aurora e fizer o failover em um de seus clusters secundários, a integração se tornará inativa. Você precisa excluir e recriar a integração.
-
Não é possível criar uma integração para um banco de dados de origem que tenha outra integração sendo criada ativamente.
-
Quando você cria inicialmente uma integração ou quando uma tabela está sendo ressincronizada, a propagação de dados da origem para o destino pode levar de 20 a 25 minutos ou mais, dependendo do tamanho do banco de dados de origem. Esse atraso pode levar a um maior atraso na réplica.
-
Alguns tipos de dados não são compatíveis. Para obter mais informações, consulte Diferenças de tipos de dados entre os bancos de dados Aurora e Amazon Redshift.
-
As tabelas do sistema, tabelas temporárias e visualizações não são replicadas nos warehouses de destino.
-
A execução de comandos de DDL (por exemplo,
ALTER TABLE) em uma tabela de origem pode acionar uma ressincronização da tabela, tornando a tabela indisponível para consulta durante a ressincronização. Para obter mais informações, consulte Uma ou mais das minhas tabelas do Amazon Redshift exigem ressincronização..
Limitações do Aurora MySQL
-
Seu cluster de banco de dados de origem deve estar executando uma versão compatível do Aurora MySQL. Para conferir uma lista de versões compatíveis, consulte Regiões e mecanismos de banco de dados do Aurora compatíveis com Integrações ETL zero.
-
As integrações ETL zero dependem do registro em log binário (binlog) do MySQL para capturar alterações contínuas de dados. Não use a filtragem de dados baseada em log binário, pois isso pode causar inconsistências de dados entre os bancos de dados de origem e de destino.
-
As integrações ETL zero são compatíveis apenas com bancos de dados configurados para usar o mecanismo de armazenamento InnoDB.
-
Referências de chave externa com atualizações de tabelas predefinidas não são compatíveis. Especificamente, as regras
ON DELETEeON UPDATEnão são compatíveis com as açõesCASCADE,SET NULLeSET DEFAULT. A tentativa de criar ou atualizar uma tabela com essas referências a outra tabela colocará a tabela em um estado de falha. -
As transações XA
realizadas no cluster de banco de dados de origem fazem com que a integração entre no estado Syncing.
Limitações do Aurora PostgreSQL
-
O cluster de banco de dados de origem executar uma versão compatível do Aurora PostgreSQL. Para conferir uma lista de versões compatíveis, consulte Regiões e mecanismos de banco de dados do Aurora compatíveis com Integrações ETL zero.
-
Se você selecionar um cluster de banco de dados de origem do Aurora PostgreSQL, deverá especificar pelo menos um padrão de filtro de dados. O padrão deve incluir no mínimo um banco de dados único (
database-name.*.* -
Todos os bancos de dados criados no cluster de banco de dados do Aurora PostgreSQL de origem devem usar a codificação UTF-8.
-
Ao usar o particionamento declarativo, as partições da tabela serão replicadas no Amazon Redshift. No entanto, a tabela particionada em si não é replicada no Amazon Redshift.
-
Transações em duas fases
não são aceitas. -
Se você excluir todas as instâncias de banco de dados de um cluster de banco de dados que seja a origem de uma integração, depois adicionar novamente uma instância de banco de dados, a replicação será interrompida entre os clusters de origem e de destino.
-
O cluster de banco de dados de origem não pode usar o Aurora Limitless Database.
-
As chaves primárias são necessárias em todas as tabelas presentes no filtro de dados. Qualquer tabela sem uma chave primária será colocada no estado de falha.
Limitações do Amazon Redshift
Para conferir uma lista das limitações do Amazon Redshift relacionadas às integrações ETL zero, consulte Considerações ao usar integrações ETL zero com o Amazon Redshift no Guia de gerenciamento do Amazon Redshift.
Amazon SageMaker AILimitações referentes a lakehouses do
A seguir é apresentada uma limitação para Integrações ETL zero com lakehouses do Amazon SageMaker AI.
-
Os nomes de catálogo podem ter no máximo 19 caracteres de comprimento.
Cotas
Sua conta tem as cotas a seguir relacionadas a Integrações ETL zero do Aurora. Salvo indicação em contrário, cada cota aplica-se por região.
| Nome | Padrão | Descrição |
|---|---|---|
| Integrações | 100 | O número total de integrações em uma Conta da AWS. |
| Integrações por destino | 50 | O número de integrações que enviam dados a um único data warehouse ou lakehouse de destino. |
| Integrações por cluster de origem | 5 | O número de integrações que enviam dados de um único cluster de banco de dados de origem. |
Além disso, o warehouse de destino impõe certos limites ao número de tabelas permitidas em cada instância de banco de dados ou nó de cluster. Para ter mais informações sobre cotas e limites do Amazon Redshift, consulte Cotas e limites no Amazon Redshift no Guida de gerenciamento do Amazon Redshift.
Regiões com suporte
As Integrações ETL zero do Aurora estão disponíveis em um subconjunto de Regiões da AWS. Para obter uma lista de regiões compatíveis, consulte Regiões e mecanismos de banco de dados do Aurora compatíveis com Integrações ETL zero.
