本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
您可以使用 AWS Glue 編目程式 將 AWS Glue Data Catalog 資料庫和資料表填入 。這是大多數 AWS Glue 使用者使用的主要方法。爬蟲程式可以在單一執行中抓取多個資料存放區。一旦完成,爬蟲程式即會在 Data Catalog 中建立或更新一或多個資料表。您在 AWS Glue 中定義的擷取、轉換和載入 (ETL) 任務,會將這些 Data Catalog 資料表做為來源和目標使用。ETL 任務可讀取和寫入來源及目標 Data Catalog 資料表中指定的資料存放區。
工作流程
以下任務流程圖顯示 AWS Glue 爬蟲程式如何與資料存放區和其他元素互動以填入資料目錄。
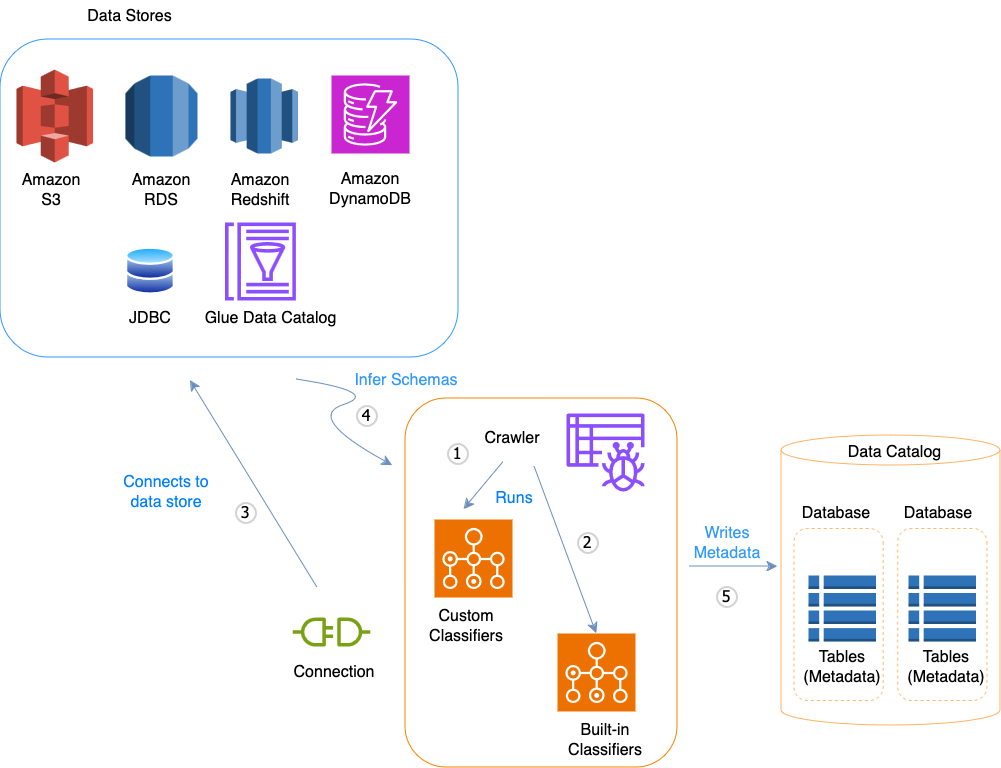
以下是爬蟲程式填入 AWS Glue Data Catalog的一般任務流程:
-
爬蟲程式會執行您選擇的任何自訂「分類器」以推斷資料的結構描述。您為自訂分類器提供程式碼,分類器依照您指定的順序執行。
第一個自訂分類器成功識別資料結構可用來建立結構描述。清單中較低的自訂分類器會被略過。
-
如果沒有自訂分類器符合您資料的結構描述,內建分類器將嘗試識別您資料的結構描述。可識別 JSON 的分類器即是一種內建分類器的範例。
-
爬蟲程式連接到資料存放區。有些資料存放區需要連線屬性才能讓爬蟲程式存取。
-
為您的資料建立經過推斷的結構描述。
-
爬蟲程式將中繼資料寫入資料目錄。資料表定義包含與資料存放區中的資料有關的中繼資料。資料表寫入資料庫,該資料庫是資料目錄中的資料表容器。資料表的屬性包含分類,它是由推斷資料表結構描述的分類器所建立的標籤。
主題
爬蟲程式的運作方式
爬蟲程式執行時,它會進行以下動作來詢問資料存放區:
-
分類器資料會判斷格式、結構描述及原始資料的相關屬性 – 您可以透過建立自訂分類器來設定分類的結果。
-
將資料分組至資料表或分區中 – 資料是根據爬蟲程式啟發來加以分組。
-
將中繼資料寫入到 Data Catalog – 您可以設定爬蟲程式如何新增、更新和刪除資料表和分區。
定義爬蟲程式時,您可選擇一個或多個分類器評估資料格式以推斷結構描述。爬蟲程式執行時,清單中第一個成功辨識資料存放區的分類器會用於為您的資料表建立結構描述。您可以使用內建的分類器或自行定義。您可以先在個別操作中定義自訂分類器,之後再定義爬蟲程式。AWS Glue 提供內建的分類器,可從常見檔案格式 (包括 JSON、CSV 和 Apache Avro) 來推斷結構描述。關於 AWS Glue 目前的內建分類器清單,請參閱內建分類器。
爬蟲程式建立的中繼資料資料表,會包含在您定義爬蟲程式時的資料庫裡。如果爬蟲程式未指定資料庫,資料表會存放於預設的資料庫。此外,每個資料表都有分類欄,會由第一個成功辨識資料存放區的分類器填寫。
如果抓取的檔案已壓縮,爬蟲程式就必須下載檔案才能處理。當爬蟲程式執行時,其會詢問檔案以判斷格式和壓縮類型,並將這些屬性寫入到 Data Catalog 。Apache Parquet 等部分檔案格式,可讓您在進行寫入時壓縮部分檔案。對於這些檔案,壓縮資料是檔案內部元件,且 AWS Glue 不會在將資料表寫入 Data Catalog 時填入 compressionType 屬性。反之,如果「整個檔案」是以壓縮演算法進行壓縮 (例如 gzip),則會在將資料表寫入 Data Catalog 時填入 compressionType 屬性。
爬蟲程式會為其建立的資料表產生名稱。存放在 中的資料表名稱 AWS Glue Data Catalog 遵循下列規則:
-
只能使用英數字元和底線 (
_)。 -
任何自訂的字首都不能超過 64 個字元。
-
名稱的長度上限不能超過 128 個字元。爬蟲程式會截斷產生的名稱以符合限制。
-
如果遇到重複的資料表名稱,爬蟲程式會為名稱加上雜湊字串尾碼。
如果爬蟲程式執行超過一次 (或許是按照排程),則會在資料存放區中尋找新的或變更過的檔案或資料表。爬蟲程式的輸出會包含前一次執行時找到的新資料表和分割區。
爬蟲程式如何決定何時建立分割區?
當AWS Glue爬蟲程式掃描 Amazon S3 資料臨時並偵測儲存貯體中的多個資料夾時,它會決定資料夾結構中資料表的根目錄,以及哪些資料夾是資料表的分割區。資料表名稱是根據 Amazon S3 字首或資料夾名稱。您提供的包含路徑會指向要探索的資料夾層級。當大部分資料夾層級的結構描述都很類似時,爬蟲程式會建立資料表分區,而不是不同的資料表。若要影響爬蟲程式來建立不同的資料表,請當您定義爬蟲程式時,新增每個資料表的根資料夾做為個別的資料存放區。
例如,請試想有以下 Amazon S3 資料夾結構。
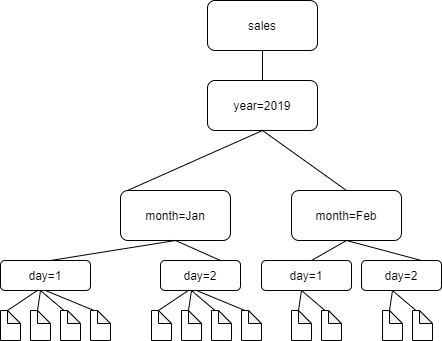
四個最低層級資料夾的路徑如下:
S3://sales/year=2019/month=Jan/day=1
S3://sales/year=2019/month=Jan/day=2
S3://sales/year=2019/month=Feb/day=1
S3://sales/year=2019/month=Feb/day=2假設爬蟲程式目標設為 Sales,並且 day=n 資料夾中的所有檔案具有相同的格式 (例如 JSON,未加密),並且具有相同或非常相似的結構描述。爬蟲程式將使用分割區索引鍵 year、month 以及 day,建立包含四個分割區的單一資料表。
在下一個範例中,請設想以下 Amazon S3 結構:
s3://bucket01/folder1/table1/partition1/file.txt
s3://bucket01/folder1/table1/partition2/file.txt
s3://bucket01/folder1/table1/partition3/file.txt
s3://bucket01/folder1/table2/partition4/file.txt
s3://bucket01/folder1/table2/partition5/file.txt
如果 table1 和 table2 下的檔案結構描述相似,且您是透過 Include path (包括路徑) s3://bucket01/folder1/ 在爬蟲程式中加以定義單一資料存放區,爬蟲程式即會建立含兩個分割區索引鍵欄的單一資料表。第一個分割區索引鍵欄包含 table1 和 table2,而第二個分割區索引鍵欄包含 partition1 到 partition3 (針對 table1 分割區) 和 partition4 和 partition5 (針對 table2 分割區)。若要建立兩個不同的資料表,定義含有兩個資料存放區的爬蟲程式。在這個範例中,定義第一個包含路徑為 s3://bucket01/folder1/table1/ 和第二個包含路徑為 s3://bucket01/folder1/table2。
注意
在 Amazon Athena,每個資料表會與資料表中所有物件的 Amazon S3 字首相對應。如果物件有不同的結構描述,Athena 無法將相同字首中的不同的物件識別為個別資料表。若爬蟲程式透過相同 Amazon S3 字首建立資料表,就可能會發生上述問題。這可能會導致 Athena 中的查詢傳回零結果。對於 Athena,若要正確識別和查詢資料表,使用個別 Include path (包含路徑),針對 Amazon S3 資料夾結構中的每個不同資料表結構描述建立爬蟲程式。如需詳細資訊,請參閱使用 Athena 搭配 AWS Glue 的最佳實務以及此 AWS
知識中心文章
