本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
教學課程:將 SageMaker AI 筆記本與開發端點搭配使用
在 AWS Glue 中,您可以建立開發端點,然後建立 SageMaker AI 筆記本以協助開發 ETL 和機器學習指令碼。SageMaker AI 筆記本執行個體是全受管的機器學習運算執行個體,可執行 Jupyter 筆記本應用程式。
-
在 AWS Glue 主控台,選擇 Dev endpoints (開發端點) 以導覽至開發端點清單。
-
在您要使用的開發端點名稱旁選取核取方塊,然後在 Action (動作) 選單中,選擇 Create SageMaker notebook (建立 SageMaker 筆記本)。
-
填寫 Create and configure a notebook (建立並設定筆記本) 頁面,如下所示:
-
輸入記事本名稱。
-
在 Attach to development endpoint (連接至開發端點),驗證開發端點。
-
建立或選擇 AWS Identity and Access Management (IAM) 角色。
建議您建立角色。如果您使用現有角色,請確定它具有必要的權限。如需詳細資訊,請參閱步驟 6:建立適用於 SageMaker AI 筆記本的 IAM 政策。
-
(選用) 選擇 VPC、子網路以及一或多個安全群組。
-
(選用) 選擇 AWS Key Management Service 加密金鑰。
-
(選用) 為筆記本執行個體新增標籤。
-
-
選擇建立筆記本。在 Notebooks (筆記本) 頁面中,選擇右上角的重新整理圖示,然後繼續操作,直到 Status (狀態) 顯示
Ready為止。 -
選取新筆記本名稱旁的核取方塊,然後選擇 Open notebook (開啟筆記本)。
-
建立新的筆記本:在 jupyter 頁面中,選擇 New (新增),然後選擇 Sparkmagic (PySpark)。
您的螢幕畫面現在看起來應該與下列類似:
-
(選用) 在頁面頂端,選擇 Untitled (為命名),然後為筆記本命名。
-
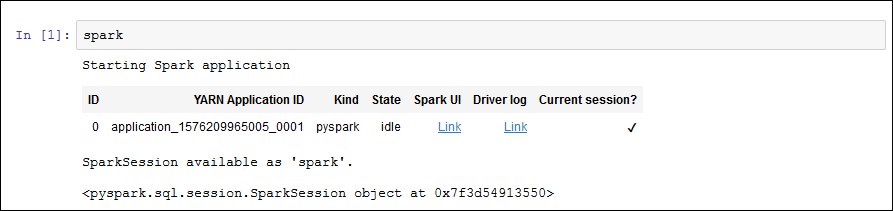
若要啟動 Spark 應用程式,請在記事本中輸入下列指令,然後在工具列中選擇 Run (執行)。
spark短暫的等待之後,您應可看到以下回應:
-
建立動態框架並針對其執行查詢:複製、貼上並執行下列程式碼,輸出
persons_json資料表的計數和結構描述。import sys from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.transforms import * glueContext = GlueContext(SparkContext.getOrCreate()) persons_DyF = glueContext.create_dynamic_frame.from_catalog(database="legislators", table_name="persons_json") print ("Count: ", persons_DyF.count()) persons_DyF.printSchema()
