本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
建立或編輯任務時,AWS Glue Studio 會視乎您使用的版本,自動為您新增對應的 AWS Glue Hudi 程式庫。如需詳細資訊,請參閱使用 AWS Glue 中的 Hudi 架構。
在 Data Catalog 資料來源中使用 Apache Hudi 架構
若要將 Hudi 資料來源格式新增至任務,請執行下列操作:
-
從「來源」選單中,選擇 AWS Glue Studio Data Catalog。
-
在資料來源屬性索引標籤中,選擇資料庫和資料表。
-
AWS Glue Studio 顯示格式類型為 Apache Hudi 和 Amazon S3 URL。

在 Amazon S3 資料來源中使用 Hudi 架構
-
從「來源」選單中,選擇 Amazon S3。
-
如果您選擇 Data Catalog 資料表做為 Amazon S3 來源類型,請選擇資料庫和資料表。
-
AWS Glue Studio 顯示格式為 Apache Hudi 和 Amazon S3 URL。
-
如果您選擇 Amazon S3 位置做為 Amazon S3 來源類型,請按一下瀏覽 Amazon S3 來選擇 Amazon S3 URL。
-
在資料格式中,選取 Apache Hudi。
注意
如果 AWS Glue Studio 無法從您選取的 Amazon S3 資料夾或檔案推斷結構描述,請選擇其他選項,以選取新的資料夾或檔案。
在其他選項中,選擇結構描述推論下的下列選項:
-
讓 AWS Glue Studio 自動選擇一個範例檔案 – AWS Glue Studio 會在 Amazon S3 位置選擇一個範例檔案,以便推斷結構描述。在自動取樣檔案欄位中,您可以檢視自動選取的檔案。
-
從 Amazon S3 中選擇一個範例檔案 – 按一下瀏覽 Amazon S3,選擇要使用的 Amazon S3 檔案。
-
-
按一下推斷結構描述。然後,您可以按一下輸出結構描述索引標籤,來檢視輸出結構描述。
-
選擇其他選項,以輸入鍵值對。

在資料目標中使用 Apache Hudi 架構
在 Data Catalog 資料目標中使用 Apache Hudi 架構
-
從目標選單中,選擇 AWS Glue Studio Data Catalog。
-
在資料來源屬性索引標籤中,選擇資料庫和資料表。
-
AWS Glue Studio 顯示格式類型為 Apache Hudi 和 Amazon S3 URL。
在 Amazon S3 資料目標中使用 Apache Hudi 架構
輸入值,或者從可用選項中選取,以設定 Apache Hudi 格式。如需有關 Apache Hudi 的詳細資訊,請參閱 Apache Hudi 文件
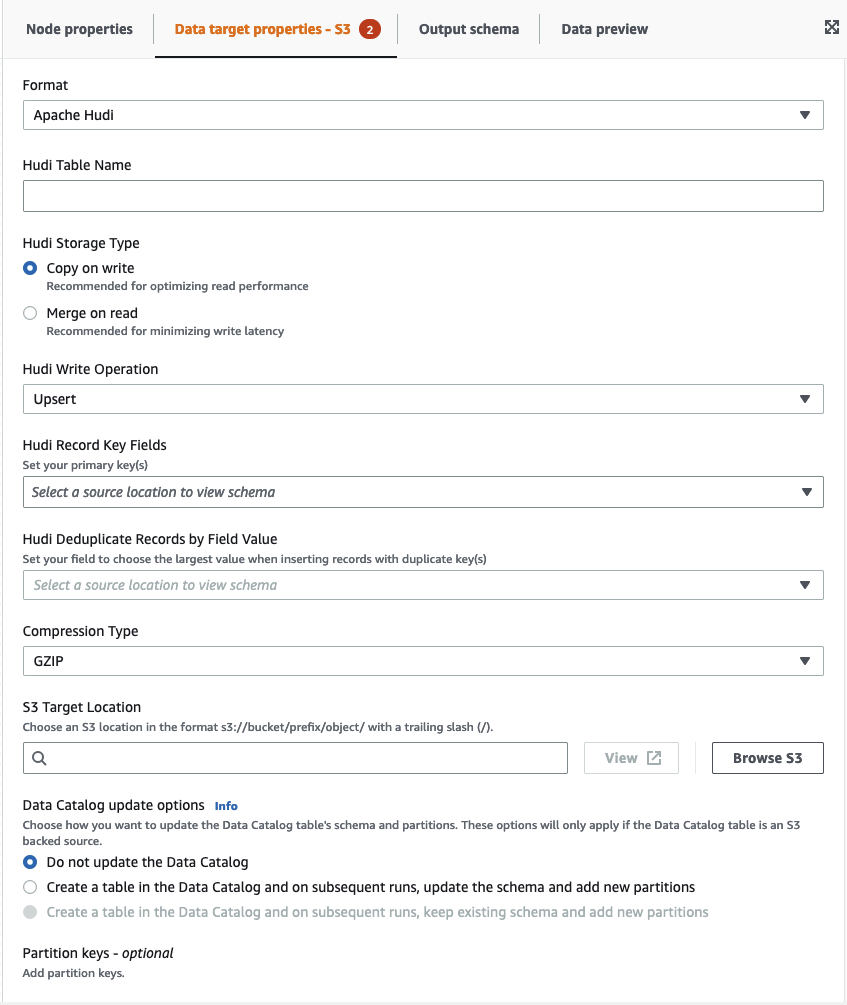
-
Hudi 資料表名稱 – 這是 hudi 資料表的名稱。
-
Hudi 儲存類型 – 從兩個選項中選擇:
-
寫入時複製 – 建議用於最佳化讀取效能。這是預設的 Hudi 儲存類型。每次更新都會在寫入期間建立新版檔案。
-
讀取時合併 – 建議將寫入延遲降至最低。更新會記錄到以資料列為基礎的 delta 檔案,並視需要壓縮以建立新版本的直欄式檔案。
-
-
Hudi 寫入操作 – 請從下列選項中選擇:
-
Upsert – 這是輸入記錄首先透過查詢索引標記為插入或更新的預設操作。建議您更新現有資料的位置。
-
插入 – 這會插入記錄,但不檢查現有記錄,並且可能會導致重複。
-
大量插入 – 這會插入記錄,建議用於大量資料。
-
-
Hudi 記錄關鍵字欄位 – 使用搜尋列來搜尋並選擇主要記錄索引鍵。Hudi 中的記錄由主索引鍵標識,這是記錄所屬的一對記錄索引鍵和分區路徑。
-
Hudi 預結合欄位 – 這是在實際寫入之前預結合中使用的欄位。當兩個記錄具有相同的索引鍵值時,AWS Glue Studio 會選擇預先組合欄位中值最大的記錄。設定增量值 (例如 updated_at) 所屬的欄位。
-
壓縮類型 – 從壓縮類型選項中選擇:未壓縮、GZIP、LZO 或 Snappy。
-
Amazon S3 目標位置 – 按一下瀏覽 S3 來選擇 Amazon S3 目標位置。
-
Data Catalog 更新選項 – 請從下列選項中選擇:
-
不更新資料目錄:(預設值) 如果您不希望任務更新資料目錄 (即使結構描述變更或新增分割區),請選擇此選項。
-
在 Data Catalog 中建立資料表,並在後續執行時,更新結構描述並新增分區:如果選擇此選項,任務會在第一次執行任務時,在 Data Catalog 中建立資料表。在後續任務執行中,如果結構描述變更或新增分割區,任務會更新 Data Catalog 資料表。
您還必須從 Data Catalog 中選取資料庫,然後輸入資料表名稱。
-
在資料目錄和後續執行中建立資料表,保留現有的結構描述並新增分割區:如果選擇此選項,任務會在第一次執行任務時,在資料目錄中建立資料表。在後續的任務執行中,任務只會更新 Data Catalog 資料表以新增新的分割區。
您還必須從 Data Catalog 中選取資料庫,然後輸入資料表名稱。
-
-
分割區索引鍵:選擇要在輸出中用作分割索引鍵的欄。若要新增更多分割區索引鍵,請選擇新增分割區索引鍵。
-
其他選項 – 根據需要輸入鍵值對。
透過 AWS Glue Studio 產生程式碼
儲存任務後,如果偵測到 Hudi 來源或目標,則會將下列任務參數新增至任務:
-
--datalake-formats– 在視覺化任務中偵測到不同的資料湖格式清單 (可直接選擇 “Format” 或間接選取由資料湖支援的目錄資料表)。 -
--conf– 根據--datalake-formats的值產生。例如,如果--datalake-formats的值為 'hudi',則 AWS Glue 會針對此參數產生spark.serializer=org.apache.spark.serializer.KryoSerializer —conf spark.sql.hive.convertMetastoreParquet=false的值。
覆寫 AWS Glue 提供的程式庫
若要使用 AWS Glue 不支援的 Hudi 版本,您可以指定自己的 Hudi 程式庫 JAR 檔案。若要使用您自己的 JAR 檔案:
-
請使用
--extra-jars任務參數。例如'--extra-jars': 's3pathtojarfile.jar'。如需詳細資訊,請參閱 AWS Glue 任務參數。 -
請勿包括
hudi作為--datalake-formats任務參數的值。輸入空白字串做為值,可確保 AWS Glue 不會自動為您提供任何資料湖程式庫。如需詳細資訊,請參閱使用 AWS Glue 中的 Hudi 架構。
