本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
您現在可以在 Amazon Q Data Integration 中使用查詢型內容感知和 PySpark DataFrame 程式碼產生,更有效率地建立資料處理任務。例如,您可以使用此提示來產生 PySpark 程式碼:「建立任務以使用連線 ‘erp_conn」從 Redshift 資料表 ‘analytics.salesorder’ 載入銷售資料、篩選低於 50 USD 的 order_amount,並以parquet 格式儲存至 Amazon S3」。
Amazon Q 會根據您的提示和設定資料整合工作流程設定產生指令碼,其中包含您問題提供的詳細資訊,例如連線組態、結構描述詳細資訊、資料庫/資料表名稱,以及轉換的資料欄規格。敏感資訊,例如連線選項密碼,會持續修訂。
如果提示中未提供必要資訊,Amazon Q 會放置預留位置,您必須在執行程式碼之前,使用適當的值更新產生的程式碼。
以下是如何使用內容感知的範例。
範例:互動
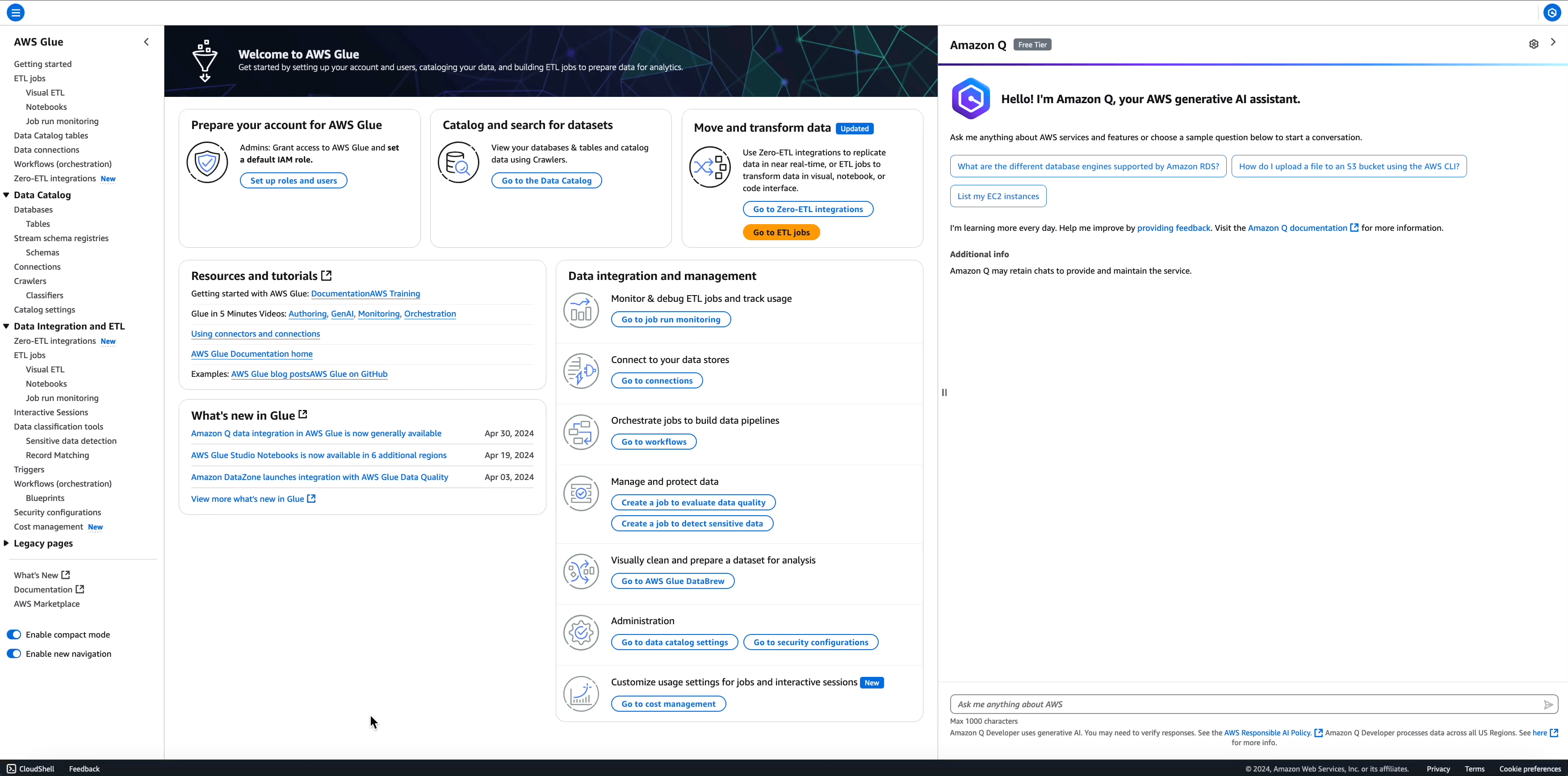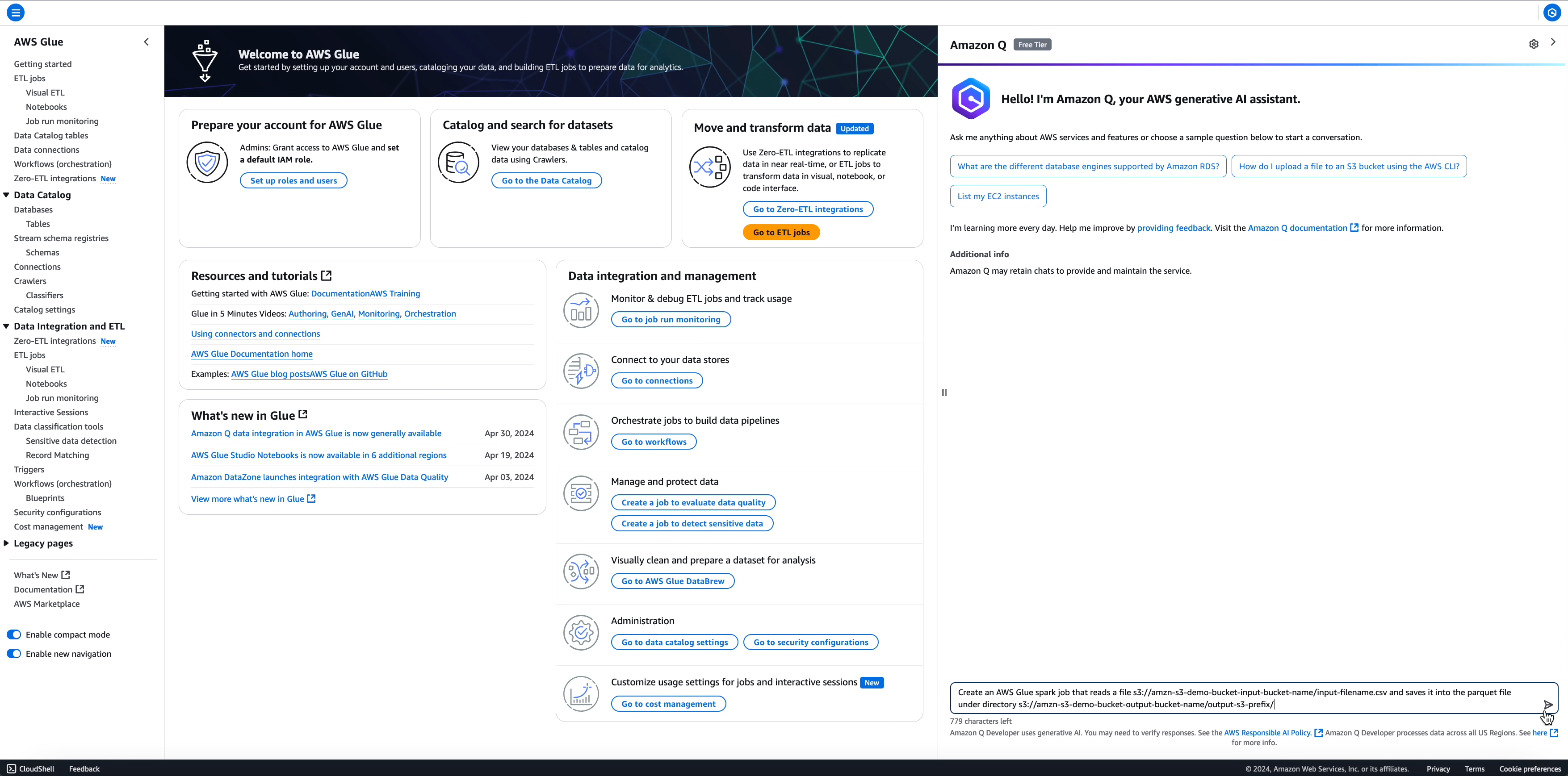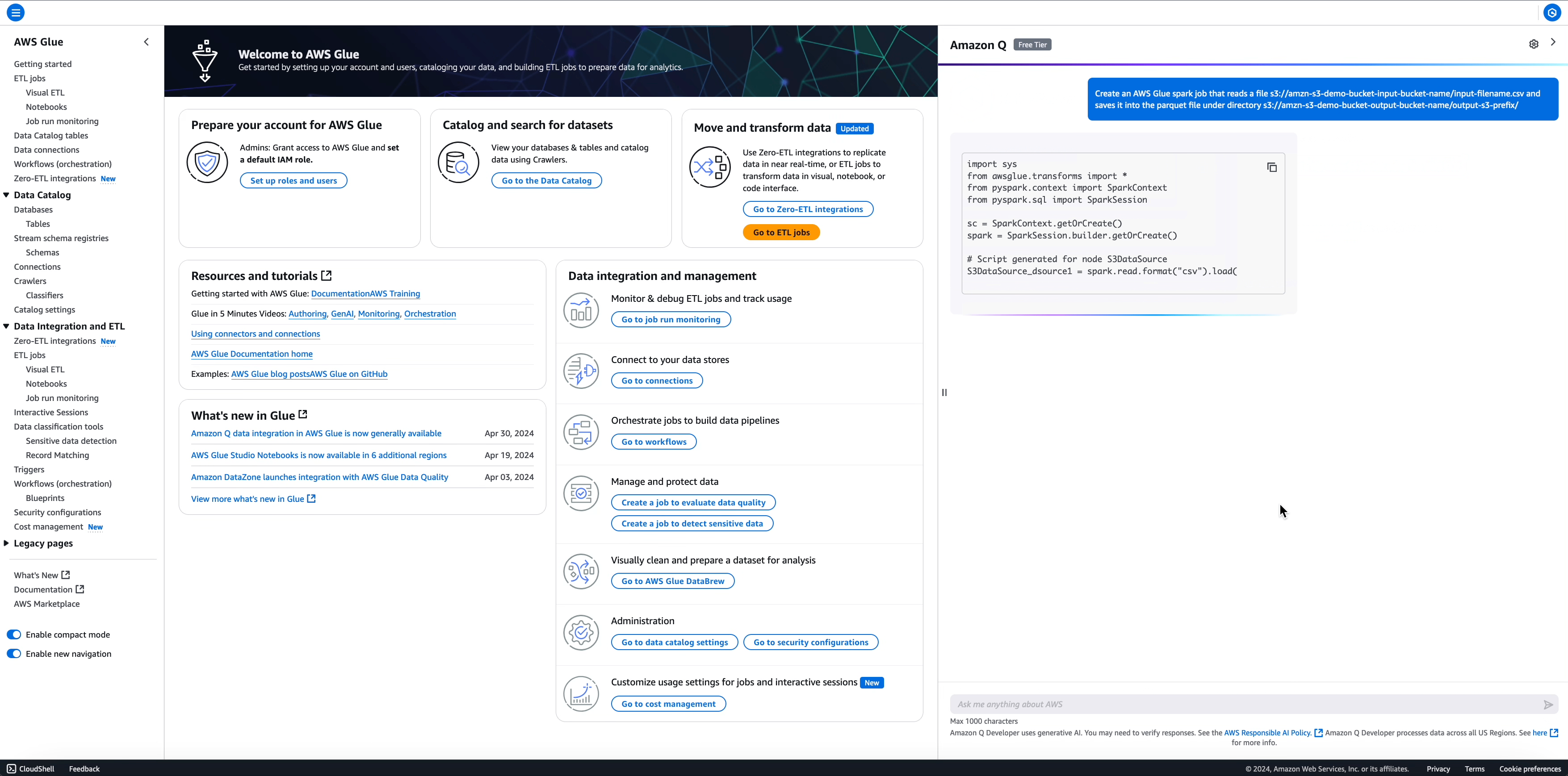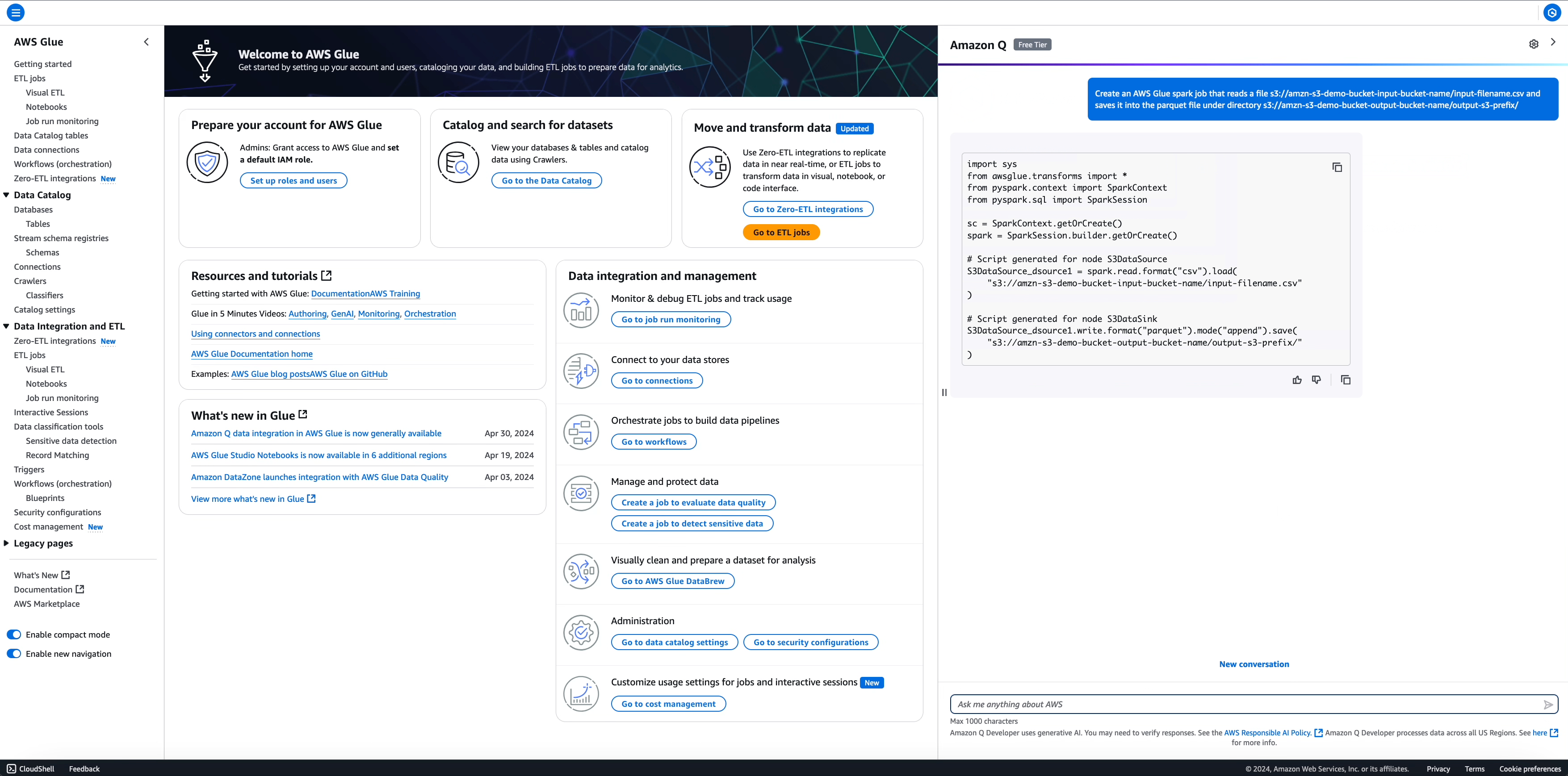
提示: Create an AWS Glue spark job that reads a file s3://amzn-s3-demo-bucket-input-bucket-name/input-filename.csv and saves it into the parquet file under directory s3://amzn-s3-demo-bucket-output-bucket-name/output-s3-prefix/
import sys
from awsglue.transforms import *
from pyspark.context import SparkContext
from pyspark.sql import SparkSession
sc = SparkContext.getOrCreate()
spark = SparkSession.builder.getOrCreate()
# Script generated for node S3DataSource
S3DataSource_dsource1 = spark.read.format("csv").load(
"s3://amzn-s3-demo-bucket-input-bucket-name/input-filename.csv"
)
# Script generated for node S3DataSink
S3DataSource_dsource1.write.format("parquet").mode("append").save(
"s3://amzn-s3-demo-bucket-output-bucket-name/output-s3-prefix/"
)
提示: Create an AWS Glue spark job that reads a file s3://amzn-s3-demo-bucket-input-bucket-name/input-filename.csv and saves it into the parquet file under directory s3://amzn-s3-demo-bucket-output-bucket-name/output-s3-prefix/
import sys
from awsglue.transforms import *
from pyspark.context import SparkContext
from pyspark.sql import SparkSession
sc = SparkContext.getOrCreate()
spark = SparkSession.builder.getOrCreate()
# Script generated for node S3DataSource
S3DataSource_dsource1 = spark.read.format("csv").load(
"s3://amzn-s3-demo-bucket-input-bucket-name/input-filename.csv"
)
# Script generated for node S3DataSink
S3DataSource_dsource1.write.format("parquet").mode("append").save(
"s3://amzn-s3-demo-bucket-output-bucket-name/output-s3-prefix/"
) 提示: write an ETL script to read from a Lakehouse table my-table in database my-database and write it to a RDS MySQL table my-target-table
對於您未提供資訊的欄位 (例如,connectionName 為 MySQL 資料接收器所需,預設在產生的程式碼中具有 placehoder <connection-name>),預留位置會保留,供您在執行指令碼之前填寫所需資訊。
產生的指令碼:
import sys
from awsglue.transforms import *
from pyspark.context import SparkContext
from pyspark.sql import SparkSession
from connectivity.adapter import CatalogConnectionHelper
sc = SparkContext.getOrCreate()
spark = SparkSession.builder.getOrCreate()
# Script generated for node S3DataSource
S3DataSource_dsource1 = spark.read.format("parquet").load(
"s3://amzn-lakehouse-demo-bucket/my-database/my-table"
)
# Script generated for node ConnectionV2DataSink
ConnectionV2DataSink_dsink1_additional_options = {"dbtable": "my-target-table"}
CatalogConnectionHelper(spark).write(
S3DataSource_dsource1,
"mysql",
"<connection-name>",
ConnectionV2DataSink_dsink1_additional_options,
)
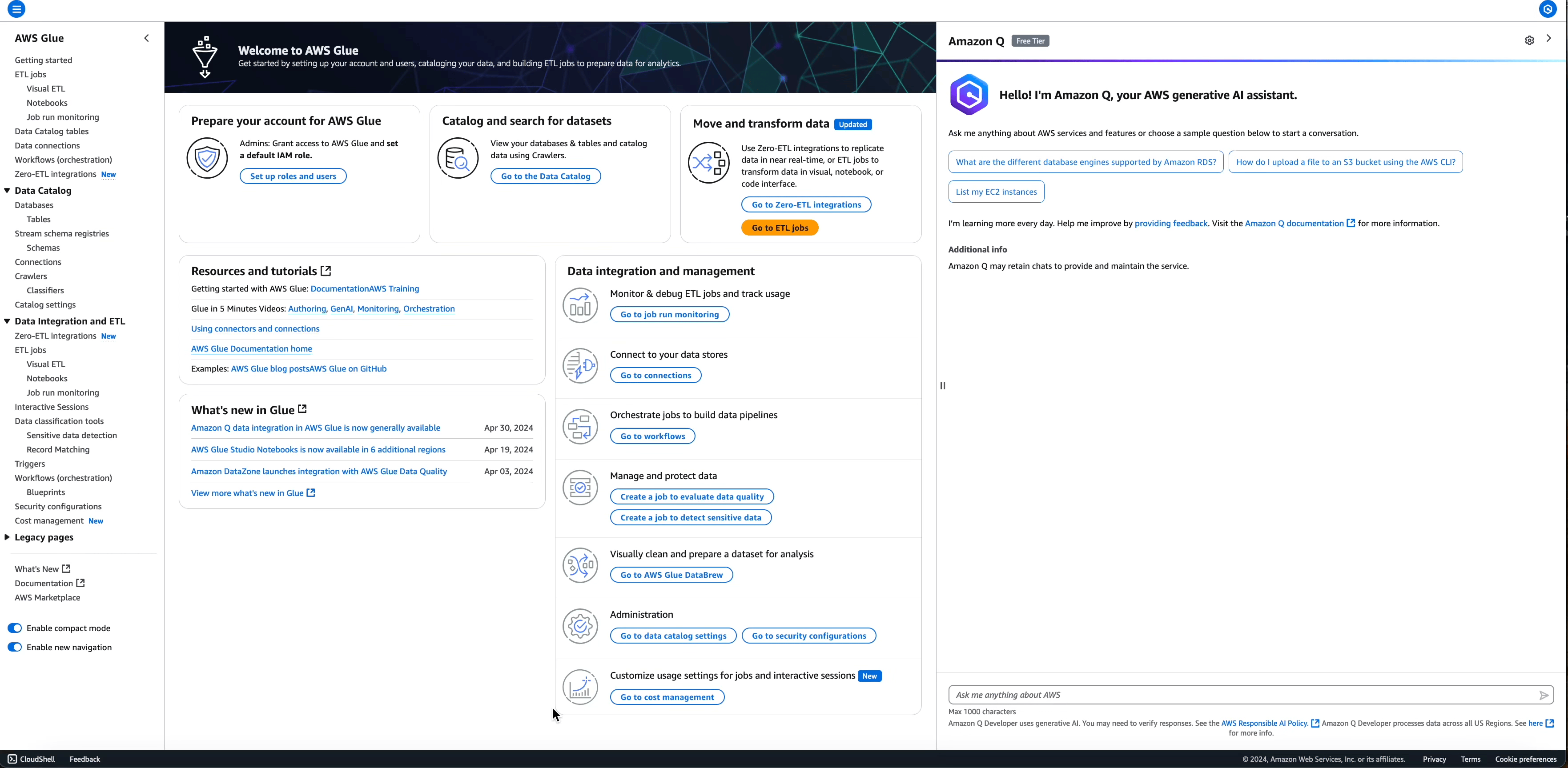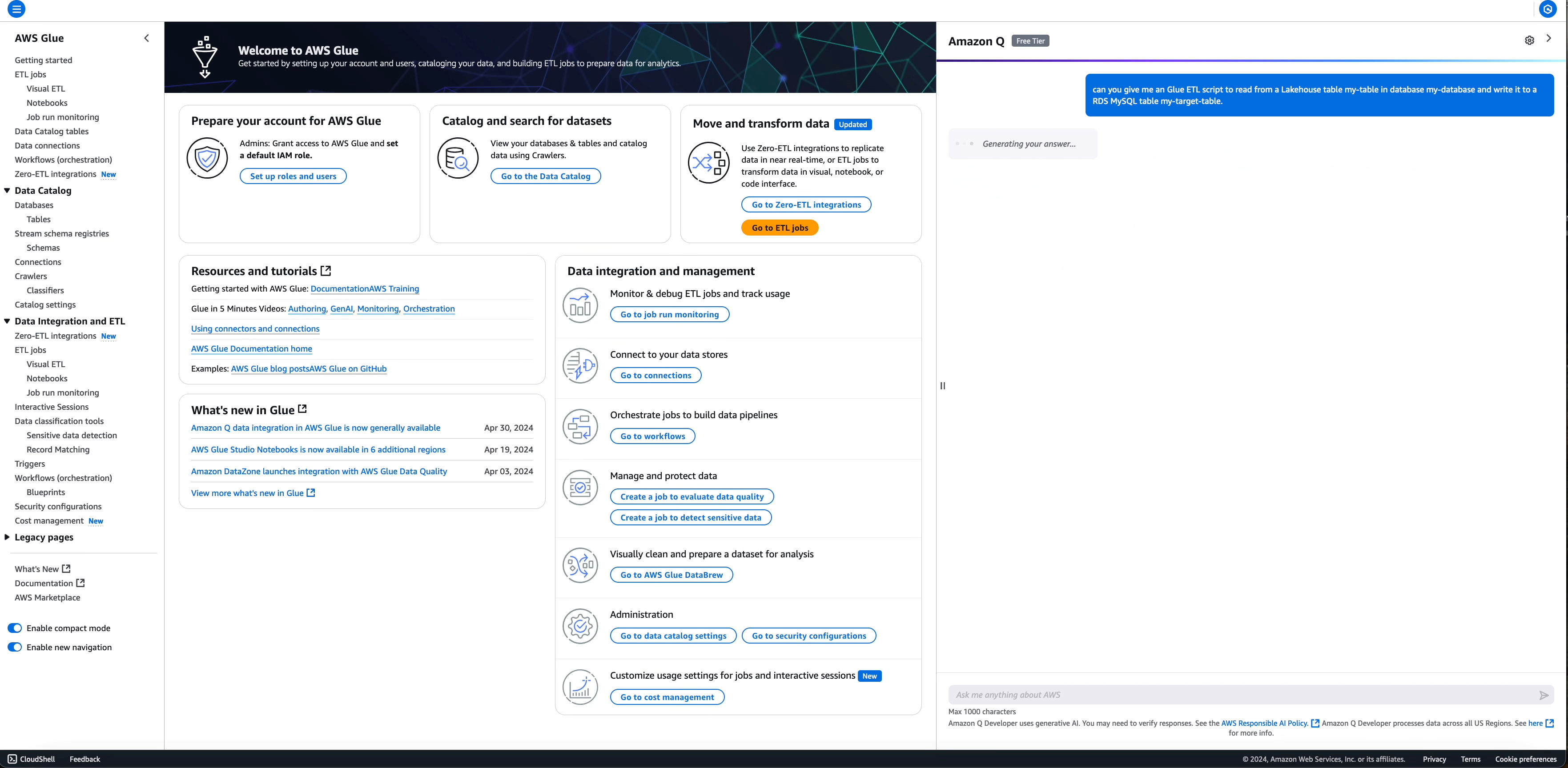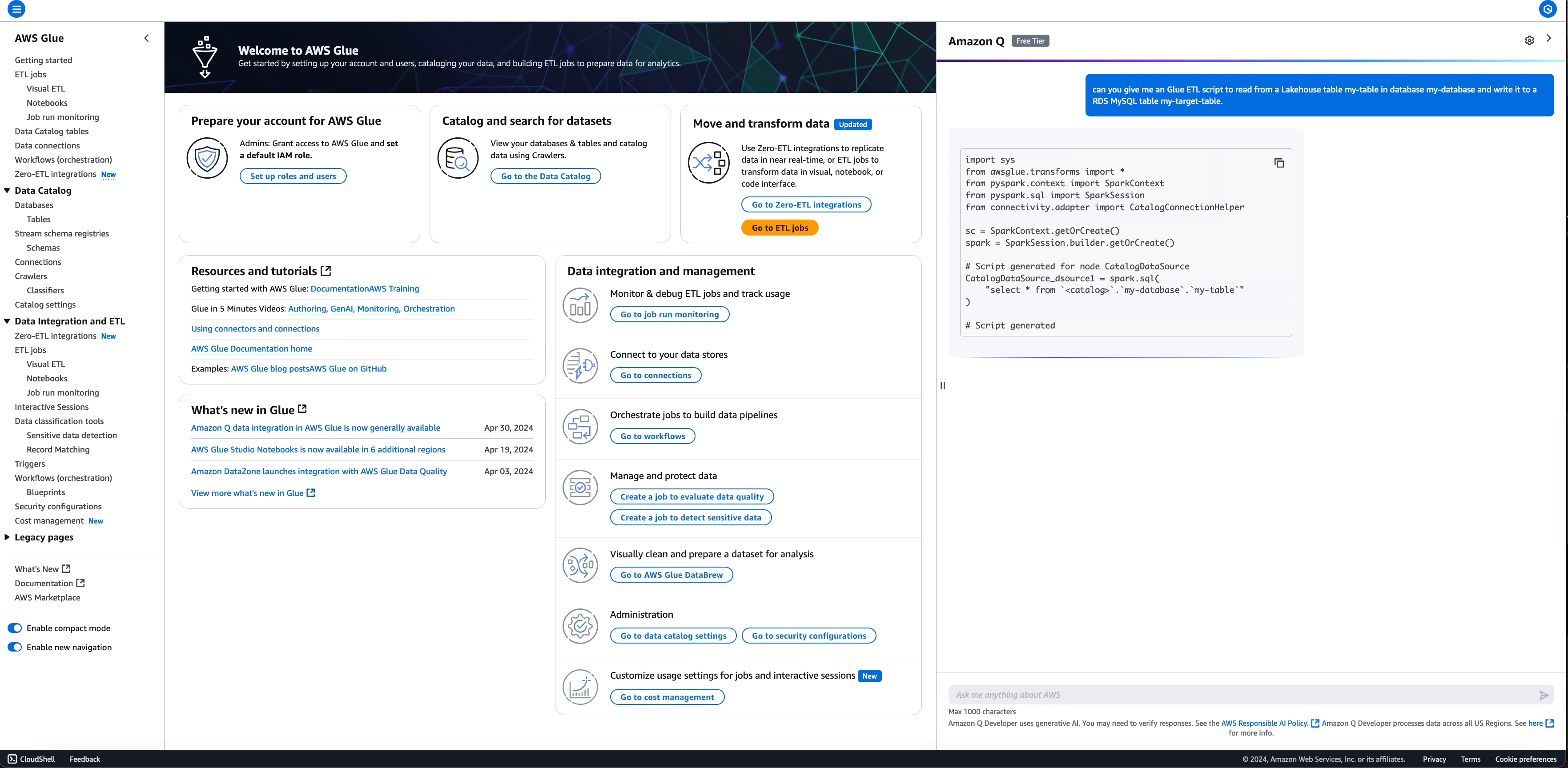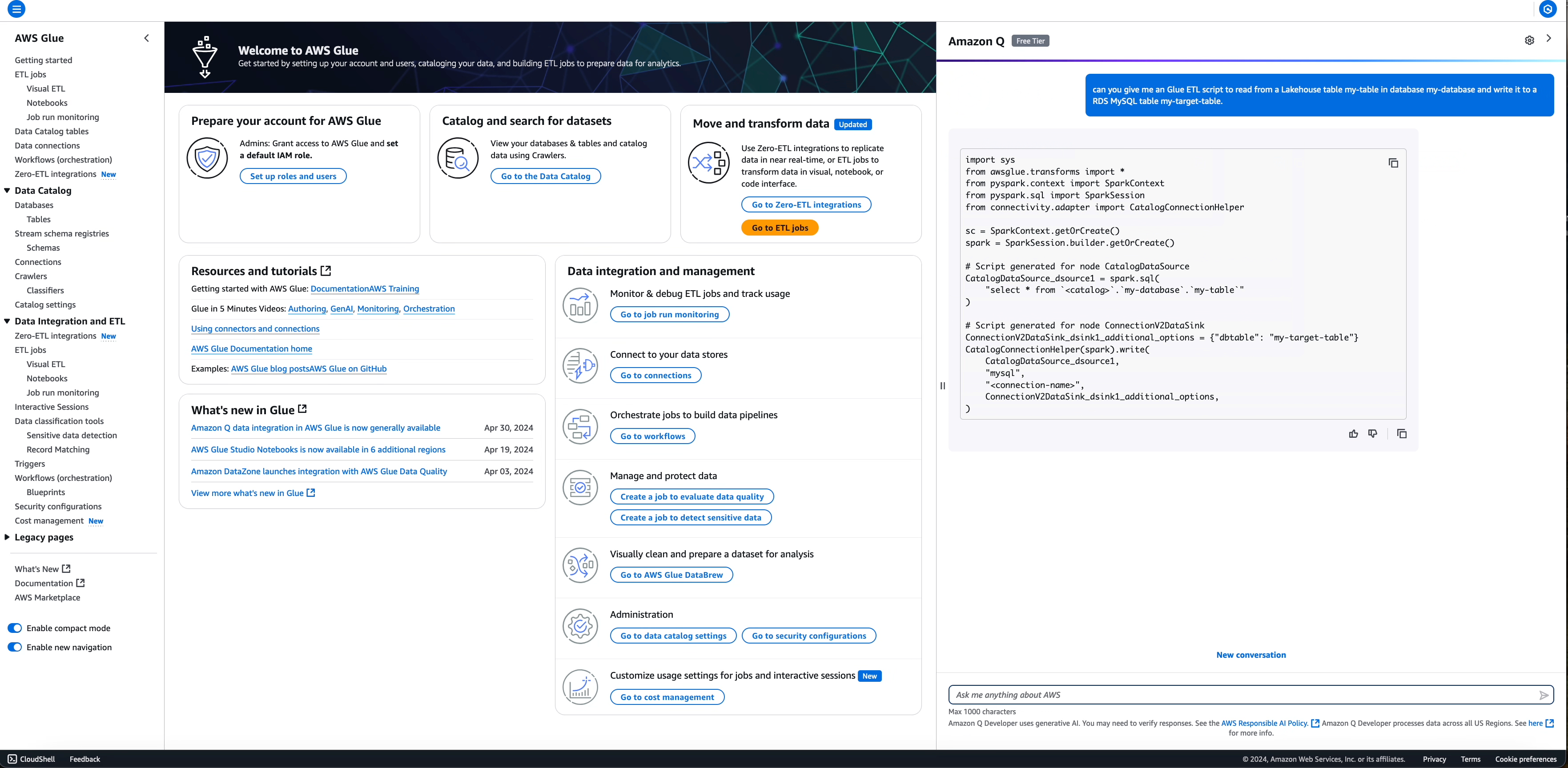
提示: write an ETL script to read from a Lakehouse table my-table in database my-database and write it to a RDS MySQL table my-target-table
對於您未提供資訊的欄位 (例如,connectionName 為 MySQL 資料接收器所需,預設在產生的程式碼中具有 placehoder <connection-name>),預留位置會保留,供您在執行指令碼之前填寫所需資訊。
產生的指令碼:
import sys
from awsglue.transforms import *
from pyspark.context import SparkContext
from pyspark.sql import SparkSession
from connectivity.adapter import CatalogConnectionHelper
sc = SparkContext.getOrCreate()
spark = SparkSession.builder.getOrCreate()
# Script generated for node S3DataSource
S3DataSource_dsource1 = spark.read.format("parquet").load(
"s3://amzn-lakehouse-demo-bucket/my-database/my-table"
)
# Script generated for node ConnectionV2DataSink
ConnectionV2DataSink_dsink1_additional_options = {"dbtable": "my-target-table"}
CatalogConnectionHelper(spark).write(
S3DataSource_dsource1,
"mysql",
"<connection-name>",
ConnectionV2DataSink_dsink1_additional_options,
)
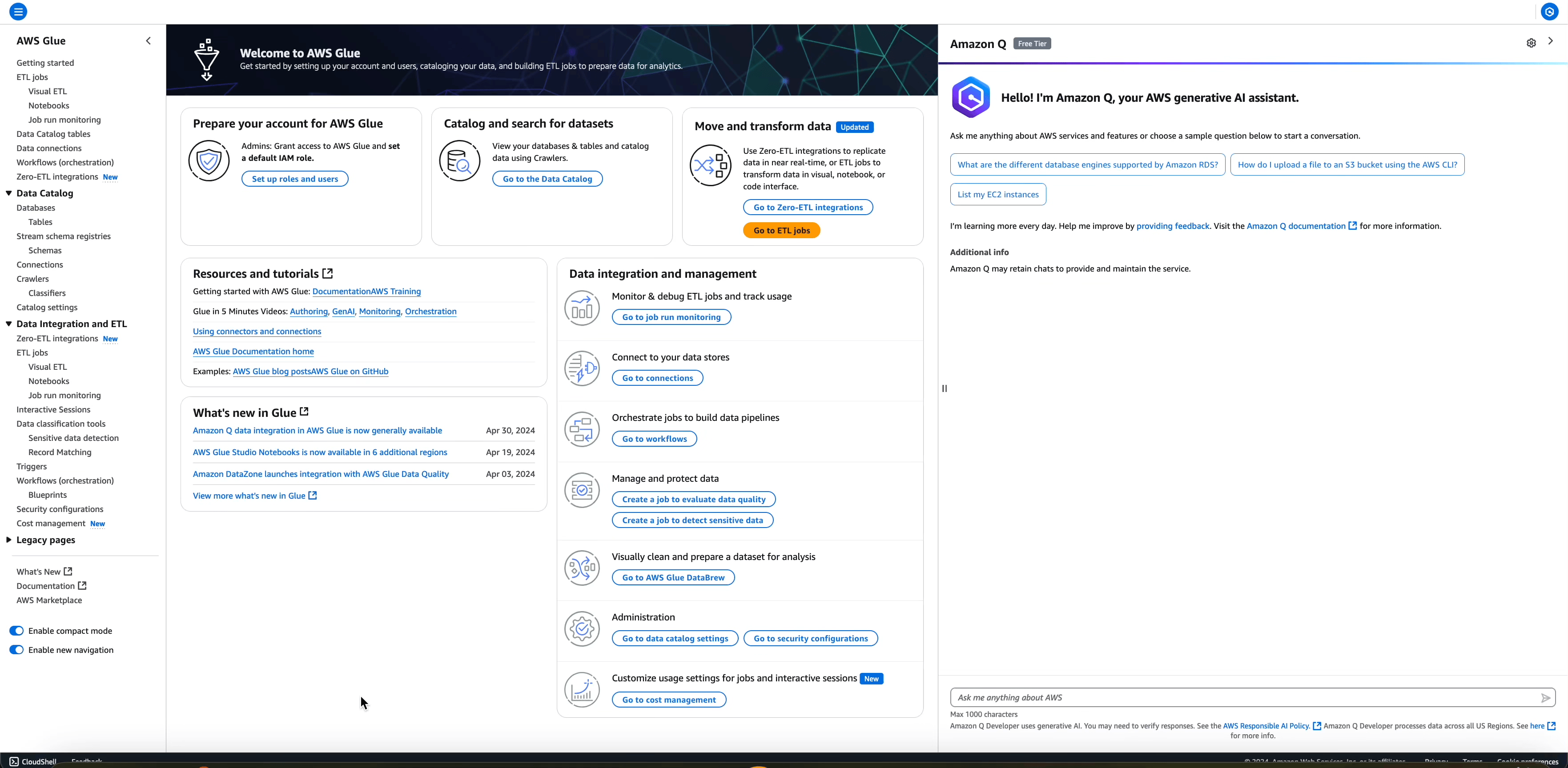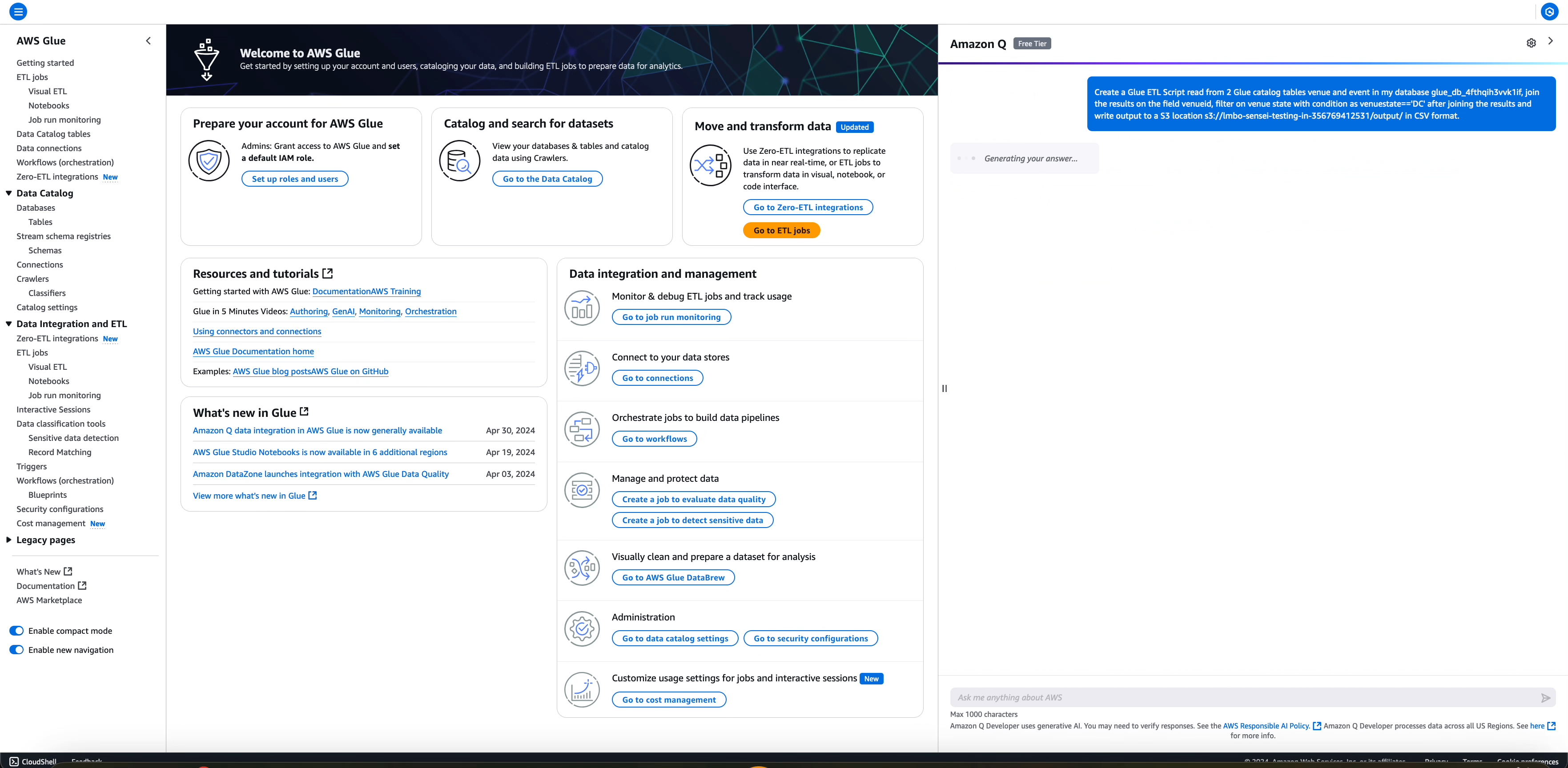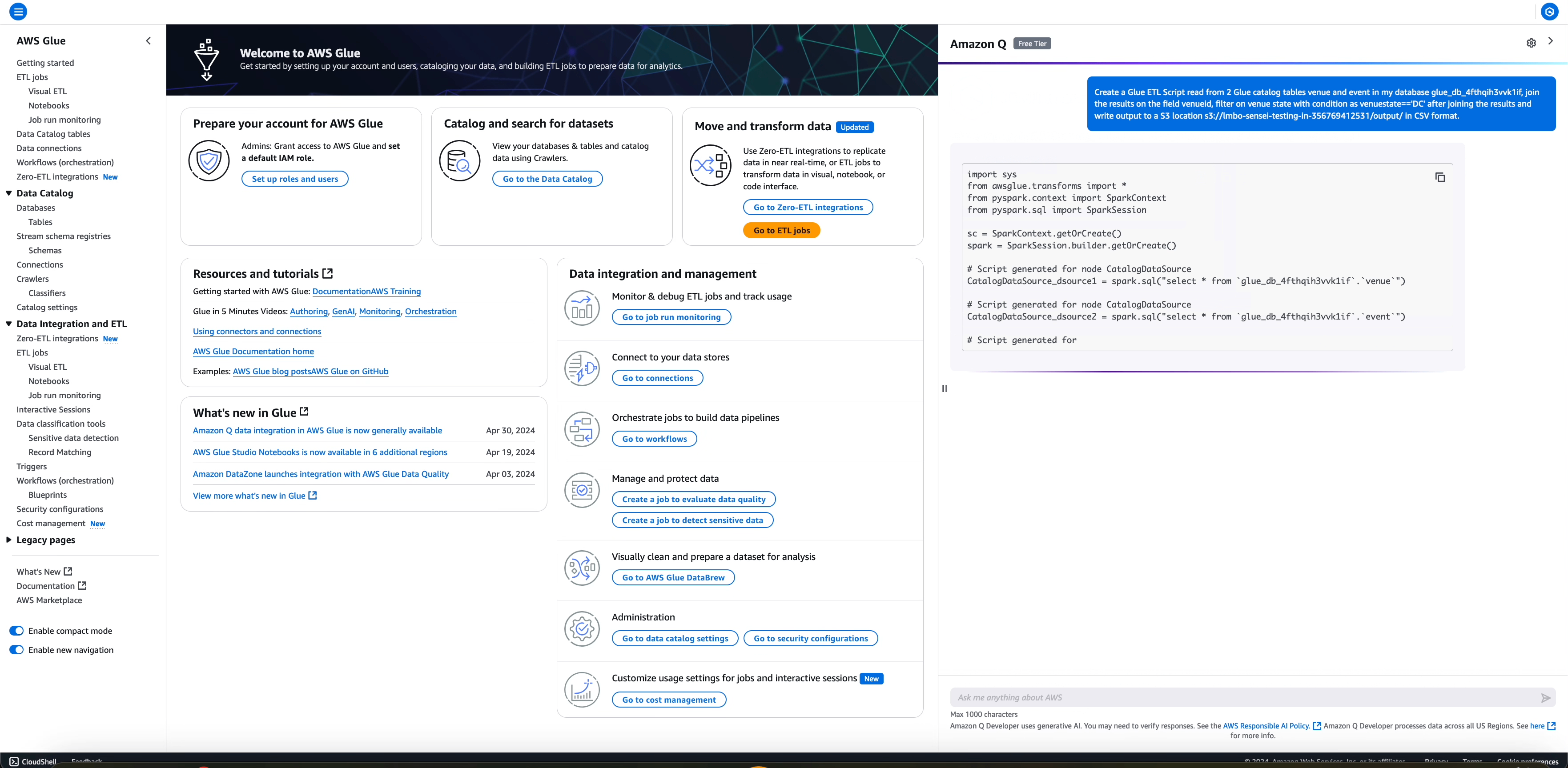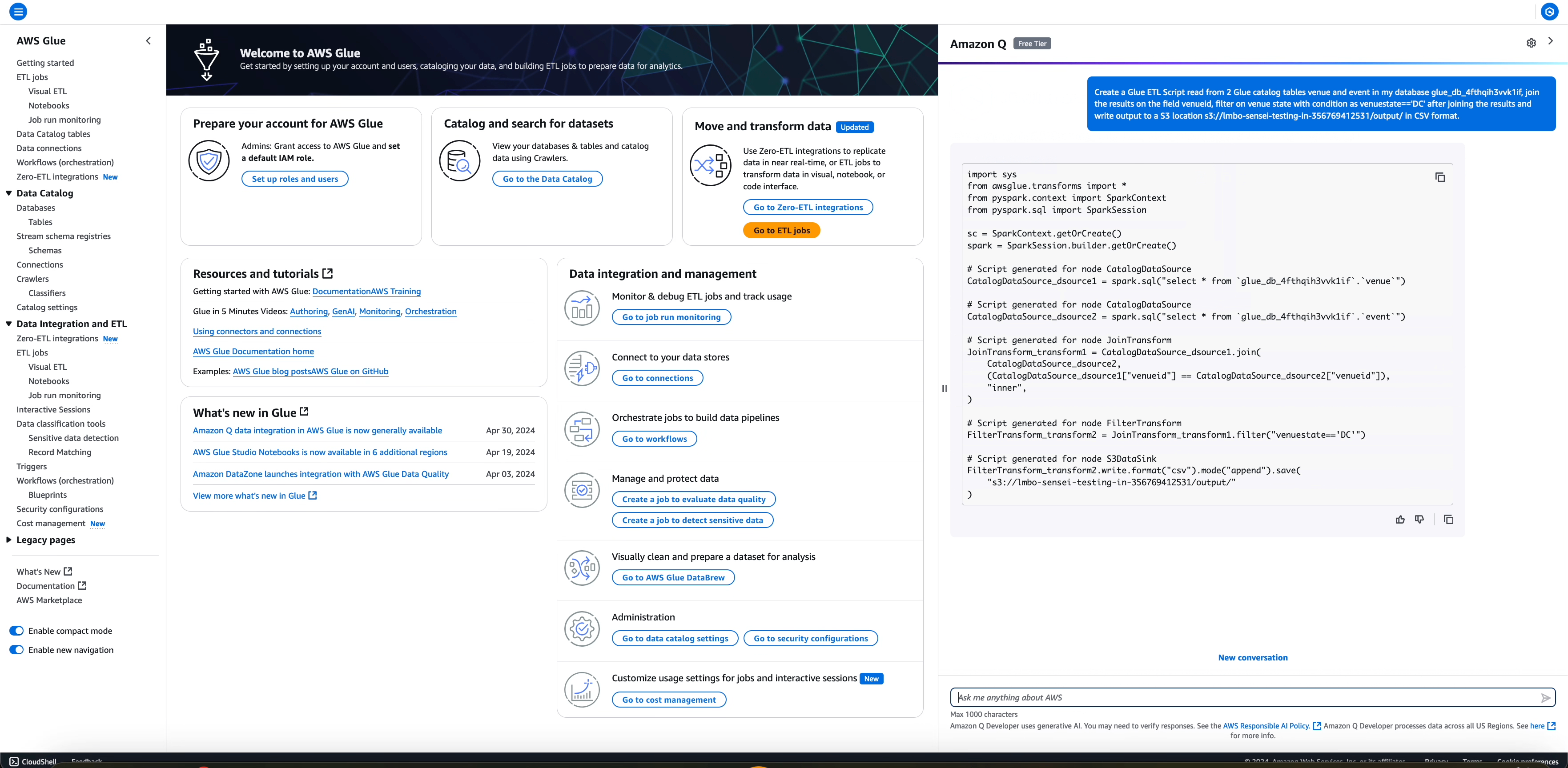
下列範例示範如何透過下列提示,要求 AWS Glue 建立 AWS Glue 指令碼以完成完整的 ETL 工作流程:Create a AWS Glue ETL Script read from two AWS Glue Data Catalog tables venue and event in my database glue_db_4fthqih3vvk1if, join the results on the field venueid, filter on venue state with condition as venuestate=='DC' after joining the results and write output to an Amazon S3 S3 location s3://amz-s3-demo-bucket/output/ in CSV format。
工作流程包含從不同資料來源 (兩個 AWS Glue Data Catalog 資料表) 讀取,以及在讀取後透過從兩個讀取加入結果來進行幾個轉換,根據某些條件進行篩選,並以 CSV 格式將轉換的輸出寫入 Amazon S3 目的地。
產生的任務會填入資料來源、轉換和接收操作的詳細資訊,以及從使用者問題擷取的對應資訊,如下所示。
import sys
from awsglue.transforms import *
from pyspark.context import SparkContext
from pyspark.sql import SparkSession
sc = SparkContext.getOrCreate()
spark = SparkSession.builder.getOrCreate()
# Script generated for node CatalogDataSource
CatalogDataSource_dsource1 = spark.sql("select * from `glue_db_4fthqih3vvk1if`.`venue`")
# Script generated for node CatalogDataSource
CatalogDataSource_dsource2 = spark.sql("select * from `glue_db_4fthqih3vvk1if`.`event`")
# Script generated for node JoinTransform
JoinTransform_transform1 = CatalogDataSource_dsource1.join(
CatalogDataSource_dsource2,
(CatalogDataSource_dsource1["venueid"] == CatalogDataSource_dsource2["venueid"]),
"inner",
)
# Script generated for node FilterTransform
FilterTransform_transform2 = JoinTransform_transform1.filter("venuestate=='DC'")
# Script generated for node S3DataSink
FilterTransform_transform2.write.format("csv").mode("append").save(
"s3://amz-s3-demo-bucket/output//output/"
)
下列範例示範如何透過下列提示,要求 AWS Glue 建立 AWS Glue 指令碼以完成完整的 ETL 工作流程:Create a AWS Glue ETL Script read from two AWS Glue Data Catalog tables venue and event in my database glue_db_4fthqih3vvk1if, join the results on the field venueid, filter on venue state with condition as venuestate=='DC' after joining the results and write output to an Amazon S3 S3 location s3://amz-s3-demo-bucket/output/ in CSV format。
工作流程包含從不同資料來源 (兩個 AWS Glue Data Catalog 資料表) 讀取,以及在讀取後透過從兩個讀取加入結果來進行幾個轉換,根據某些條件進行篩選,並以 CSV 格式將轉換的輸出寫入 Amazon S3 目的地。
產生的任務會填入資料來源、轉換和接收操作的詳細資訊,以及從使用者問題擷取的對應資訊,如下所示。
import sys
from awsglue.transforms import *
from pyspark.context import SparkContext
from pyspark.sql import SparkSession
sc = SparkContext.getOrCreate()
spark = SparkSession.builder.getOrCreate()
# Script generated for node CatalogDataSource
CatalogDataSource_dsource1 = spark.sql("select * from `glue_db_4fthqih3vvk1if`.`venue`")
# Script generated for node CatalogDataSource
CatalogDataSource_dsource2 = spark.sql("select * from `glue_db_4fthqih3vvk1if`.`event`")
# Script generated for node JoinTransform
JoinTransform_transform1 = CatalogDataSource_dsource1.join(
CatalogDataSource_dsource2,
(CatalogDataSource_dsource1["venueid"] == CatalogDataSource_dsource2["venueid"]),
"inner",
)
# Script generated for node FilterTransform
FilterTransform_transform2 = JoinTransform_transform1.filter("venuestate=='DC'")
# Script generated for node S3DataSink
FilterTransform_transform2.write.format("csv").mode("append").save(
"s3://amz-s3-demo-bucket/output//output/"
) 限制
-
內容轉移:
-
內容感知功能只會傳遞相同對話中先前使用者查詢的內容。它不會保留前一個查詢以外的內容。
-
-
支援節點組態:
-
目前,內容感知功能僅支援各種節點的所需組態子集。
-
未來版本會規劃對選用欄位的支援。
-
-
可用性:
-
Q Chat 和 SageMaker Unified Studio 筆記本提供內容感知和 DataFrame 支援。不過,這些功能尚未在 Glue Studio AWS 筆記本中使用。
-
