Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Der Amazon HBase Athena-Connector ermöglicht Amazon Athena die Kommunikation mit Ihren HBase Apache-Instances, sodass Sie Ihre HBase Daten mit abfragen können. SQL
Im Gegensatz zu herkömmlichen relationalen Datenspeichern haben HBase Sammlungen kein festgelegtes Schema. HBasehat keinen Metadatenspeicher. Jeder Eintrag in einer HBase Sammlung kann unterschiedliche Felder und Datentypen haben.
Der HBase Konnektor unterstützt zwei Mechanismen zum Generieren von Tabellenschemainformationen: grundlegende Schemainferenz und AWS Glue Data Catalog Metadaten.
Die Schemainferenz ist die Standardeinstellung. Mit dieser Option werden eine kleine Anzahl von Dokumenten in Ihrer Sammlung gescannt, eine Vereinigung aller Felder gebildet und Felder mit nicht überlappenden Datentypen erwzungen. Diese Option eignet sich gut für Sammlungen, die größtenteils einheitliche Einträge haben.
Für Sammlungen mit einer größeren Vielfalt an Datentypen unterstützt der Konnektor das Abrufen von Metadaten aus dem AWS Glue Data Catalog. Wenn der Konnektor eine AWS Glue Datenbank und eine Tabelle erkennt, die Ihren HBase Namespace- und Sammlungsnamen entsprechen, bezieht er seine Schemainformationen aus der entsprechenden AWS Glue Tabelle. Wenn Sie Ihre AWS Glue Tabelle erstellen, empfehlen wir, dass Sie sie zu einer Obermenge aller Felder machen, auf die Sie möglicherweise von Ihrer HBase Sammlung aus zugreifen möchten.
Wenn Sie Lake Formation in Ihrem Konto aktiviert haben, AWS Serverless Application Repository muss die IAM Rolle für Ihren Athena Federated Lambda Connector, den Sie in der bereitgestellt haben, Lesezugriff in Lake Formation haben. AWS Glue Data Catalog
Dieser Konnektor kann nicht als Verbundkatalog bei Glue Data Catalog registriert werden. Dieser Konnektor unterstützt keine in Lake Formation definierten Datenzugriffskontrollen auf Katalog-, Datenbank-, Tabellen-, Spalten-, Zeilen- und Tagebene. Dieser Konnektor verwendet Glue Connections, um die Konfigurationseigenschaften in Glue zu zentralisieren.
Voraussetzungen
Stellen Sie den Konnektor für Ihr AWS-Konto mithilfe der Athena-Konsole oder AWS Serverless Application Repository bereit. Weitere Informationen finden Sie unter Erstellen Sie eine Datenquellenverbindung oder Verwenden Sie den AWS Serverless Application Repository , um einen Datenquellenconnector bereitzustellen.
Parameter
Verwenden Sie die Parameter in diesem Abschnitt, um den HBase Konnektor zu konfigurieren.
Anmerkung
Athena-Datenquellenconnectors, die am 3. Dezember 2024 und später erstellt wurden, verwenden AWS Glue Verbindungen.
Die unten aufgeführten Parameternamen und Definitionen beziehen sich auf Athena-Datenquellenconnectors, die vor dem 3. Dezember 2024 erstellt wurden. Diese können von ihren entsprechenden AWS Glue Verbindungseigenschaften abweichen. Verwenden Sie ab dem 3. Dezember 2024 die folgenden Parameter nur, wenn Sie eine frühere Version eines Athena-Datenquellenconnectors manuell bereitstellen.
-
spill_bucket – Gibt den Amazon S3-Bucket für Daten an, die die Lambda-Funktionsgrenzen überschreiten.
-
spill_prefix – (Optional) Ist standardmäßig ein Unterordner im angegebenen
spill_bucketgenanntathena-federation-spill. Wir empfehlen Ihnen, einen Amazon-S3-Speicher-Lebenszyklus an dieser Stelle zu konfigurieren, um die Überlaufe zu löschen, die älter als eine festgelegte Anzahl von Tagen oder Stunden sind. -
spill_put_request_headers — (Optional) Eine JSON kodierte Zuordnung von Anforderungsheadern und Werten für die Amazon S3
putObjectS3-Anfrage, die zum Verschicken verwendet wird (z. B.).{"x-amz-server-side-encryption" : "AES256"}Weitere mögliche Header finden Sie PutObjectin der Amazon Simple Storage Service API Reference. -
kms_key_id — (Optional) Standardmäßig werden alle Daten, die auf Amazon S3 übertragen werden, mit dem GCM authentifizierten Verschlüsselungsmodus und einem zufällig AES generierten Schlüssel verschlüsselt. Damit Ihre Lambda-Funktion stärkere Verschlüsselungsschlüssel verwendet, die von KMS like generiert wurden
a7e63k4b-8loc-40db-a2a1-4d0en2cd8331, können Sie eine KMS Schlüssel-ID angeben. -
disable_spill_encryption – (Optional) Bei Einstellung auf
True, wird die Spill-Verschlüsselung deaktiviert. Die Standardeinstellung istFalseso, dass Daten, die auf S3 übertragen werden, mit AES - verschlüsselt werden GCM — entweder mit einem zufällig generierten Schlüssel oder KMS zur Generierung von Schlüsseln. Das Deaktivieren der Überlauf-Verschlüsselung kann die Leistung verbessern, insbesondere wenn Ihr Überlauf-Standort eine serverseitige Verschlüsselung verwendet. -
disable_glue — (Optional) Falls vorhanden und auf true gesetzt, versucht der Connector nicht, zusätzliche Metadaten von abzurufen. AWS Glue
-
glue_catalog – (Optional) Verwenden Sie diese Option, um einen kontoübergreifenden AWS Glue -Katalog anzugeben. Standardmäßig versucht der Connector, Metadaten von seinem eigenen Konto abzurufen. AWS Glue
-
default_hbase — Gibt, falls vorhanden, eine HBase Verbindungszeichenfolge an, die verwendet werden soll, wenn keine katalogspezifische Umgebungsvariable vorhanden ist.
-
enable_case_insensitive_match — (Optional) Wenn, führt Suchen ohne Berücksichtigung der Groß- und Kleinschreibung anhand von Tabellennamen in durch.
trueHBase Der Standardwert istfalse. Verwenden Sie diese Option, wenn Ihre Abfrage Tabellennamen in Großbuchstaben enthält.
Angeben von Verbindungszeichenfolgen
Sie können eine oder mehrere Eigenschaften angeben, die die HBase Verbindungsdetails für die HBase Instanzen definieren, die Sie mit dem Connector verwenden. Legen Sie dazu eine Lambda-Umgebungsvariable fest, die dem Katalognamen entspricht, den Sie in Athena verwenden möchten. Nehmen wir beispielsweise an, Sie möchten die folgenden Abfragen verwenden, um zwei verschiedene HBase Instanzen von Athena abzufragen:
SELECT * FROM "hbase_instance_1".database.tableSELECT * FROM "hbase_instance_2".database.tableBevor Sie diese beiden SQL Anweisungen verwenden können, müssen Sie Ihrer Lambda-Funktion zwei Umgebungsvariablen hinzufügen: hbase_instance_1 undhbase_instance_2. Bei jedem Wert sollte es sich um eine HBase Verbindungszeichenfolge im folgenden Format handeln:
master_hostname:hbase_port:zookeeper_port
Verwendung von Secrets
Sie können den Wert optional AWS Secrets Manager für einen Teil oder den gesamten Wert für Ihre Verbindungszeichenfolgendetails verwenden. Um die Athena Federated Query-Funktion mit Secrets Manager zu verwenden, sollte die mit Ihrem Lambda VPC verbundene Funktion über einen Internetzugang
Wenn Sie die Syntax ${my_secret} verwenden, um den Namen eines Secrets aus Secrets Manager in Ihre Verbindungszeichenfolge einzufügen, ersetzt der Konnektor den geheimen Namen durch Ihren Benutzernamen und die Kennwortwerte aus Secrets Manager.
Angenommen, Sie setzen die Lambda-Umgebungsvariable für hbase_instance_1 auf den folgenden Wert:
${hbase_host_1}:${hbase_master_port_1}:${hbase_zookeeper_port_1}
Die Athena Query Federation versucht SDK automatisch, ein Secret mit dem Namen Secrets Manager abzurufen und diesen Wert anstelle hbase_instance_1_creds von einzufügen. ${hbase_instance_1_creds} Ein beliebiger Teil der Verbindungszeichenfolge, der in der ${
}-Zeichenkombination enthalten ist, wird als Secret aus Secrets Manager interpretiert. Wenn Sie einen geheimen Namen angeben, den der Konnektor in Secrets Manager nicht finden kann, ersetzt der Konnektor den Text nicht.
Einrichten von Datenbanken und Tabellen in AWS Glue
Die integrierte Schemainferenz des Konnektors unterstützt nur Werte, die HBase als Zeichenketten serialisiert sind (z. B.String.valueOf(int)). Da die integrierten Schemainferenzfunktionen des Konnektors begrenzt sind, sollten Sie stattdessen AWS Glue
für Metadaten verwenden. Um eine AWS Glue Tabelle für die Verwendung mit zu aktivierenHBase, benötigen Sie eine AWS Glue Datenbank und eine Tabelle mit Namen, die dem HBase Namespace und der Tabelle entsprechen, für die Sie zusätzliche Metadaten bereitstellen möchten. Die Verwendung von Benennungskonventionen für HBase Spaltenfamilien ist optional, aber nicht erforderlich.
Um eine AWS Glue Tabelle für zusätzliche Metadaten zu verwenden
-
Wenn Sie die Tabelle und die Datenbank in der AWS Glue Konsole bearbeiten, fügen Sie die folgenden Tabelleneigenschaften hinzu:
hbase-metadata-flag— Diese Eigenschaft zeigt dem HBase Konnektor an, dass der Konnektor die Tabelle für zusätzliche Metadaten verwenden kann. Sie können einen beliebigen Wert für
hbase-metadata-flagangeben, solange diehbase-metadata-flag-Eigenschaft in der Liste der Tabelleneigenschaften vorhanden ist.-
hbase-native-storage-flag— Verwenden Sie dieses Flag, um zwischen den beiden vom Connector unterstützten Modi für die Werteserialisierung umzuschalten. Wenn dieses Feld nicht vorhanden ist, geht der Konnektor standardmäßig davon aus, dass alle Werte HBase als Zeichenketten gespeichert sind. Daher versucht er, Datentypen wie
INTBIGINT, undDOUBLEfrom HBase als Zeichenketten zu analysieren. Wenn in diesem Feld ein Wert in der Tabelle angegeben ist AWS Glue, wechselt der Konnektor in den „systemeigenen“ Speichermodus und versuchtINT,,BIGINT, undDOUBLEals Byte zu lesenBIT, indem er die folgenden Funktionen verwendet:ByteBuffer.wrap(value).getInt() ByteBuffer.wrap(value).getLong() ByteBuffer.wrap(value).get() ByteBuffer.wrap(value).getDouble()
-
Stellen Sie sicher, dass Sie die in diesem Dokument aufgeführten Datentypen verwenden, die für AWS Glue geeignet sind.
Modellieren von Spaltenfamilien
Der HBase Athena-Konnektor unterstützt zwei Möglichkeiten, HBase Spaltenfamilien zu modellieren: vollqualifizierte (abgeflachte) Benennung wie oder Verwendung von family:column Objekten. STRUCT
Im STRUCT-Model sollte der Name des STRUCT-Feldes mit der Spaltenfamilie übereinstimmen und die untergeordneten Elementen von STRUCT sollten mit den Namen der Spalten der Familie übereinstimmen. Da Prädikat-Push-Down- und Columnar-Lesevorgänge jedoch für komplexe Typen wie STRUCT noch nicht vollständig unterstützt werden, wird die Verwendung von STRUCT derzeit nicht empfohlen.
Die folgende Abbildung zeigt eine konfigurierte Tabelle AWS Glue , in der eine Kombination der beiden Ansätze verwendet wird.
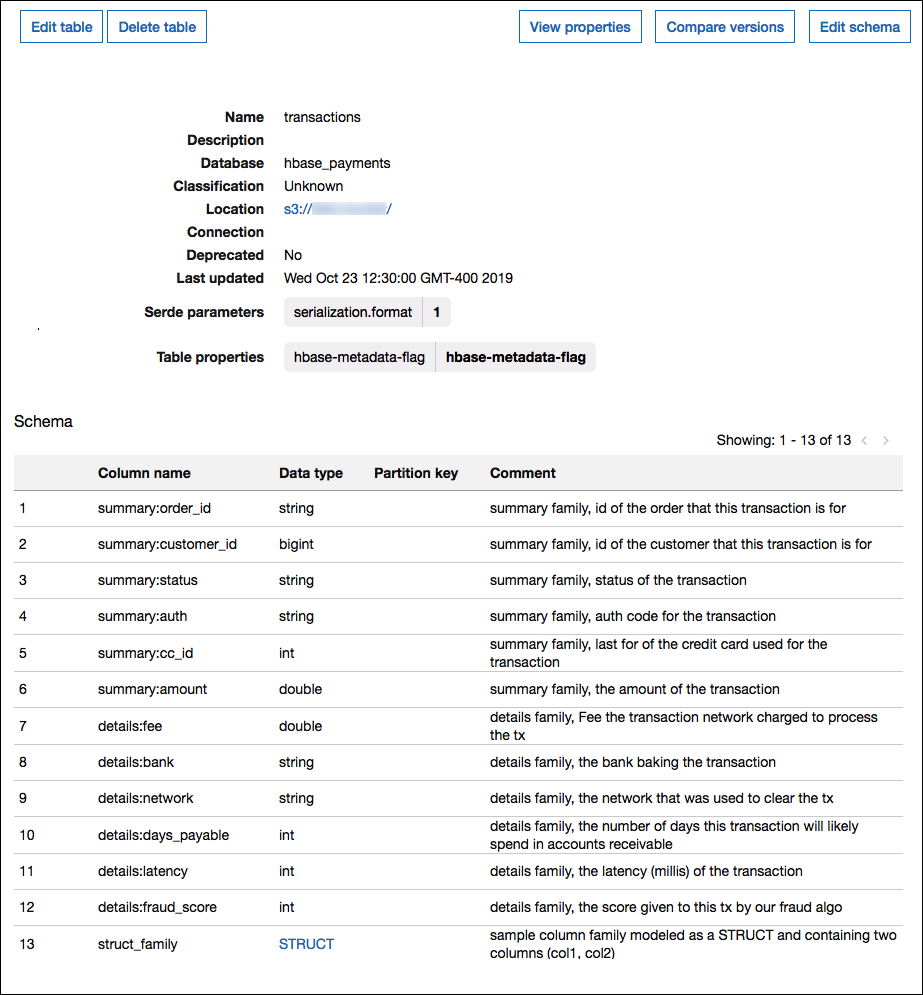
Datentypunterstützung
Der Konnektor ruft alle HBase Werte als Basis-Byte-Typ ab. Basierend darauf, wie Sie Ihre Tabellen im AWS Glue Datenkatalog definiert haben, ordnet er die Werte dann einem der Apache Arrow-Datentypen in der folgenden Tabelle zu.
| AWS Glue Datentyp | Apache Arrow-Datentyp |
|---|---|
| int | INT |
| bigint | BIGINT |
| double | FLOAT8 |
| float | FLOAT4 |
| Boolean | BIT |
| Binary | VARBINARY |
| Zeichenfolge | VARCHAR |
Anmerkung
Wenn Sie Ihre Metadaten nicht ergänzen, verwendet die Schemainferenz des Connectors nur die Datentypen BIGINTFLOAT8, undVARCHAR. AWS Glue
Erforderliche Berechtigungen
Vollständige Informationen zu den IAM Richtlinien, die für diesen Connector erforderlich sind, finden Sie im Policies Abschnitt der Datei athena-hbase.yaml
-
Amazon-S3-Schreibzugriff – Der Konnektor benötigt Schreibzugriff auf einen Speicherort in Amazon S3, um Ergebnisse aus großen Abfragen zu übertragen.
-
Athena GetQueryExecution — Der Konnektor verwendet diese Berechtigung, um einen Fast-Fail auszuführen, wenn die Upstream-Athena-Abfrage beendet wurde.
-
AWS Glue Data Catalog— Der HBase Konnektor benötigt nur Lesezugriff auf die, um Schemainformationen AWS Glue Data Catalog abzurufen.
-
CloudWatch Logs — Der Connector benötigt Zugriff auf CloudWatch Logs, um Logs zu speichern.
-
AWS Secrets Manager Lesezugriff — Wenn Sie HBase Endpunktdetails in Secrets Manager speichern möchten, müssen Sie dem Connector Zugriff auf diese Geheimnisse gewähren.
-
VPCZugriff — Der Connector benötigt die Fähigkeit, Schnittstellen an Ihren anzuhängen und zu trennen, VPC damit er sich mit ihm verbinden und mit Ihren HBase Instances kommunizieren kann.
Leistung
Der HBase Athena-Connector versucht, Abfragen für Ihre HBase Instance zu parallelisieren, indem er jeden Regionalserver parallel liest. Der HBase Athena-Konnektor führt einen Prädikat-Pushdown durch, um die Anzahl der von der Abfrage gescannten Daten zu verringern.
Die Lambda-Funktion führt auch Projektions-Pushdown durch, um die von der Abfrage gescannten Daten zu reduzieren. Die Auswahl einer Teilmenge von Spalten führt jedoch manchmal zu einer längeren Laufzeit der Abfrageausführung. LIMIT-Klauseln reduzieren die Menge der gescannten Daten, aber wenn Sie kein Prädikat angeben, sollten Sie davon ausgehen, dass SELECT-Abfragen mit einer LIMIT-Klausel mindestens 16 MB an Daten scannen.
HBaseist anfällig für Abfragefehler und variable Abfrageausführungszeiten. Möglicherweise müssen Sie Ihre Abfragen mehrmals wiederholen, damit diese erfolgreich sind. Der HBase Konnektor ist aufgrund der Parallelität widerstandsfähig gegen Drosselung.
Passthrough-Abfragen
Der HBase Connector unterstützt Passthrough-Abfragen und ist No-Based. SQL Informationen zum Abfragen von Apache HBase mithilfe von Filtern finden Sie in der Apache-Dokumentation unter Filtersprache
Verwenden Sie die folgende SyntaxHBase, um Passthrough-Abfragen mit zu verwenden:
SELECT * FROM TABLE(
system.query(
database => 'database_name',
collection => 'collection_name',
filter => '{query_syntax}'
))Das folgende Beispiel für eine HBase Passthrough-Abfrage filtert innerhalb der employee Datenbanksammlung nach Mitarbeitern im Alter von 24 oder 30 Jahren. default
SELECT * FROM TABLE(
system.query(
DATABASE => 'default',
COLLECTION => 'employee',
FILTER => 'SingleColumnValueFilter(''personaldata'', ''age'', =, ''binary:30'')' ||
' OR SingleColumnValueFilter(''personaldata'', ''age'', =, ''binary:24'')'
))Lizenzinformationen
Das Amazon Athena HBase Connector-Projekt ist unter der Apache-2.0-Lizenz
Weitere Ressourcen
Weitere Informationen zu diesem Connector finden Sie auf der entsprechenden Website unter .com
