Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Der Amazon-Athena-Timestream-Konnektor ermöglicht Amazon Athena die Kommunikation mit Amazon Timestream
Amazon Timestream ist eine schnelle, skalierbare, vollständig verwaltete, speziell entwickelte Zeitreihendatenbank, mit der Sie mühelos Milliarden von Zeitreihendatenpunkten pro Tag speichern und analysieren können. Timestream spart Ihnen Zeit und Kosten bei der Verwaltung des Lebenszyklus von Zeitreihendaten, indem aktuelle Daten im Arbeitsspeicher aufbewahrt und historische Daten basierend auf benutzerdefinierten Richtlinien in eine kostenoptimierte Speicherebene verschoben werden.
Dieser Konnektor kann bei Glue Data Catalog als Verbundkatalog registriert werden. Es unterstützt in Lake Formation definierte Datenzugriffskontrollen auf Katalog-, Datenbank-, Tabellen-, Spalten-, Zeilen- und Tagebene. Dieser Konnektor verwendet Glue Connections, um die Konfigurationseigenschaften in Glue zu zentralisieren.
Wenn Sie Lake Formation in Ihrem Konto aktiviert haben, AWS Serverless Application Repository muss die IAM Rolle für Ihren Athena Federated Lambda Connector, den Sie in der bereitgestellt haben, Lesezugriff in Lake Formation haben. AWS Glue Data Catalog
Voraussetzungen
Stellen Sie den Konnektor für Ihr AWS-Konto mithilfe der Athena-Konsole oder AWS Serverless Application Repository bereit. Weitere Informationen finden Sie unter Erstellen Sie eine Datenquellenverbindung oder Verwenden Sie den AWS Serverless Application Repository , um einen Datenquellenconnector bereitzustellen.
Parameter
Verwenden Sie die Parameter in diesem Abschnitt, um den Timestream-Connector zu konfigurieren.
Anmerkung
Athena-Datenquellenconnectors, die am 3. Dezember 2024 und später erstellt wurden, verwenden AWS Glue Verbindungen.
Die unten aufgeführten Parameternamen und Definitionen beziehen sich auf Athena-Datenquellenconnectors, die vor dem 3. Dezember 2024 erstellt wurden. Diese können von ihren entsprechenden AWS Glue Verbindungseigenschaften abweichen. Verwenden Sie ab dem 3. Dezember 2024 die folgenden Parameter nur, wenn Sie eine frühere Version eines Athena-Datenquellenconnectors manuell bereitstellen.
-
spill_bucket – Gibt den Amazon S3-Bucket für Daten an, die die Lambda-Funktionsgrenzen überschreiten.
-
spill_prefix – (Optional) Ist standardmäßig ein Unterordner im angegebenen
spill_bucketgenanntathena-federation-spill. Wir empfehlen Ihnen, einen Amazon-S3-Speicher-Lebenszyklus an dieser Stelle zu konfigurieren, um die Überlaufe zu löschen, die älter als eine festgelegte Anzahl von Tagen oder Stunden sind. -
spill_put_request_headers — (Optional) Eine JSON kodierte Zuordnung von Anforderungsheadern und Werten für die Amazon S3
putObjectS3-Anfrage, die zum Verschicken verwendet wird (z. B.).{"x-amz-server-side-encryption" : "AES256"}Weitere mögliche Header finden Sie PutObjectin der Amazon Simple Storage Service API Reference. -
kms_key_id — (Optional) Standardmäßig werden alle Daten, die auf Amazon S3 übertragen werden, mit dem GCM authentifizierten Verschlüsselungsmodus und einem zufällig AES generierten Schlüssel verschlüsselt. Damit Ihre Lambda-Funktion stärkere Verschlüsselungsschlüssel verwendet, die von KMS like generiert wurden
a7e63k4b-8loc-40db-a2a1-4d0en2cd8331, können Sie eine KMS Schlüssel-ID angeben. -
disable_spill_encryption – (Optional) Bei Einstellung auf
True, wird die Spill-Verschlüsselung deaktiviert. Die Standardeinstellung istFalseso, dass Daten, die auf S3 übertragen werden, mit AES - verschlüsselt werden GCM — entweder mit einem zufällig generierten Schlüssel oder KMS zur Generierung von Schlüsseln. Das Deaktivieren der Überlauf-Verschlüsselung kann die Leistung verbessern, insbesondere wenn Ihr Überlauf-Standort eine serverseitige Verschlüsselung verwendet. -
glue_catalog – (Optional) Verwenden Sie diese Option, um einen kontoübergreifenden AWS Glue -Katalog anzugeben. Standardmäßig versucht der Connector, Metadaten von seinem eigenen AWS Glue Konto abzurufen.
Einrichten von Datenbanken und Tabellen in AWS Glue
Sie können das optional AWS Glue Data Catalog als Quelle für zusätzliche Metadaten verwenden. Um eine AWS Glue Tabelle für die Verwendung mit Timestream zu aktivieren, benötigen Sie eine AWS Glue Datenbank und eine Tabelle mit Namen, die mit der Timestream-Datenbank und der Tabelle übereinstimmen, für die Sie zusätzliche Metadaten bereitstellen möchten.
Anmerkung
Verwenden Sie für Ihre Datenbanknamen und -tabellen nur Kleinbuchstaben, um eine optimale Leistung zu erzielen. Bei der Verwendung gemischter Groß- und Kleinschreibung führt der Konnektor eine Suche ohne Berücksichtigung der Groß- und Kleinschreibung durch, die rechenintensiver ist.
Um die AWS Glue Tabelle für die Verwendung mit Timestream zu konfigurieren, müssen Sie ihre Tabelleneigenschaften unter festlegen. AWS Glue
Um eine AWS Glue Tabelle für zusätzliche Metadaten zu verwenden
-
Bearbeiten Sie die Tabelle in der AWS Glue Konsole, um die folgenden Tabelleneigenschaften hinzuzufügen:
timestream-metadata-flag— Diese Eigenschaft gibt dem Timestream-Connector an, dass der Connector die Tabelle für zusätzliche Metadaten verwenden kann. Sie können einen beliebigen Wert für
timestream-metadata-flagangeben, solange dietimestream-metadata-flag-Eigenschaft in der Liste der Tabelleneigenschaften vorhanden ist.-
_view_template — Wenn Sie AWS Glue für zusätzliche Metadaten verwenden, können Sie diese Tabelleneigenschaft verwenden und einen beliebigen Timestream als Ansicht angeben. SQL Der Athena Timestream-Konnektor verwendet den SQL from the View zusammen mit Ihrem SQL from Athena, um Ihre Abfrage auszuführen. Dies ist nützlich, wenn Sie eine Funktion von Timestream verwenden möchtenSQL, die sonst in Athena nicht verfügbar ist.
-
Stellen Sie sicher, dass Sie die geeigneten Datentypen verwenden, die AWS Glue in diesem Dokument aufgeführt sind.
Datentypen
Derzeit unterstützt der Timestream-Konnektor nur eine Teilmenge der in Timestream verfügbaren Datentypen, insbesondere: die Skalarwerte varchar, double und timestamp.
Um den timeseries-Datentyp abzufragen, müssen Sie eine Ansicht in AWS Glue
-Tabelleneigenschaften konfigurieren, die die CREATE_TIME_SERIES-Funktion von Timestream verwenden. Sie müssen auch ein Schema für die Ansicht bereitstellen, das die Syntax ARRAY<STRUCT<time:timestamp,measure_value::double:double>> als Typ für eine Ihrer Zeitreihenspalten verwendet. Achten Sie darauf, dass Sie double mit dem entsprechenden Skalartyp für Ihre Tabelle ersetzen.
Die folgende Abbildung zeigt ein Beispiel für AWS Glue Tabelleneigenschaften, die konfiguriert wurden, um eine Ansicht über eine Zeitreihe einzurichten.
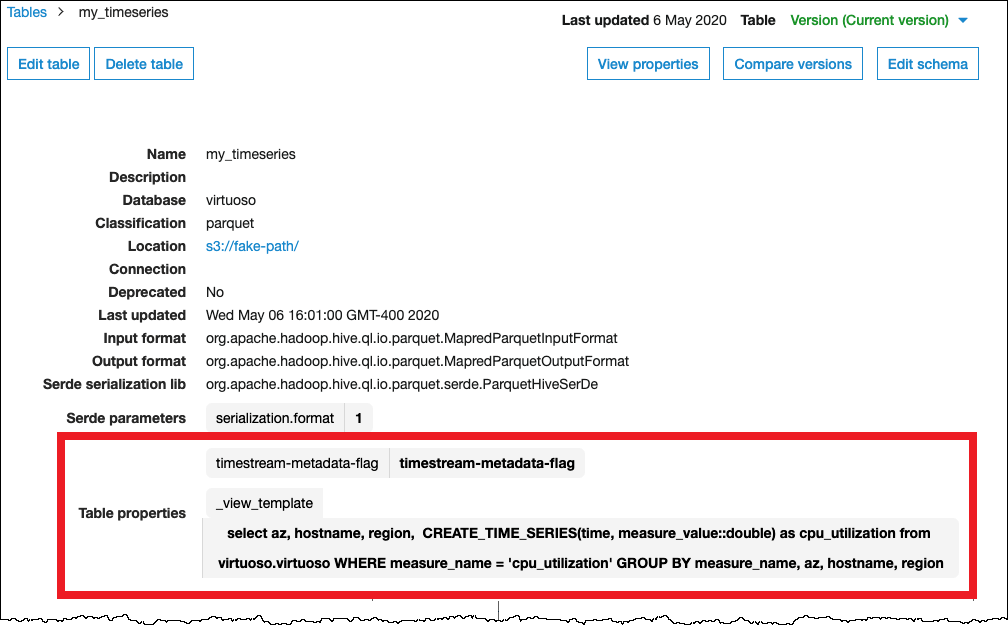
Erforderliche Berechtigungen
Vollständige Informationen zu den IAM Richtlinien, die für diesen Connector erforderlich sind, finden Sie im Policies Abschnitt der Datei athena-timestream.yaml
-
Amazon-S3-Schreibzugriff – Der Konnektor benötigt Schreibzugriff auf einen Speicherort in Amazon S3, um Ergebnisse aus großen Abfragen zu übertragen.
-
Athena GetQueryExecution — Der Konnektor verwendet diese Berechtigung, um einen Fast-Fail auszuführen, wenn die Upstream-Athena-Abfrage beendet wurde.
-
AWS Glue Data Catalog— Der Timestream-Konnektor benötigt nur Lesezugriff auf den, um Schemainformationen abzurufen AWS Glue Data Catalog .
-
CloudWatch Logs — Der Connector benötigt Zugriff auf CloudWatch Logs, um Logs zu speichern.
-
Timestream Access – Zum Ausführen von Timestream-Abfragen.
Leistung
Wir empfehlen die LIMIT-Klausel zu verwenden, um die zurückgegebenen Daten (nicht die gescannten Daten) auf weniger als 256 MB zu begrenzen, um sicherzustellen, dass interaktive Abfragen leistungsfähig sind.
Der Athena-Timestream-Konnektor führt ein Prädikat-Pushdown durch, um die von der Abfrage gescannten Daten zu reduzieren. LIMIT-Klauseln reduzieren die Menge der gescannten Daten, aber wenn Sie kein Prädikat angeben, sollten Sie davon ausgehen, dass SELECT-Abfragen mit einer LIMIT-Klausel mindestens 16 MB Daten scannen. Die Auswahl einer Teilmenge von Spalten beschleunigt die Abfragelaufzeit erheblich und reduziert die gescannten Daten. Der Timestream-Konnektor ist aufgrund der Gleichzeitigkeit widerstandsfähig gegenüber Drosselung.
Passthrough-Abfragen
Der Timestream-Connector unterstützt Passthrough-Abfragen. Passthrough-Abfragen verwenden eine Tabellenfunktion, um Ihre vollständige Abfrage zur Ausführung an die Datenquelle weiterzuleiten.
Um Passthrough-Abfragen mit Timestream zu verwenden, können Sie die folgende Syntax verwenden:
SELECT * FROM TABLE(
system.query(
query => 'query string'
))Mit der folgenden Beispielabfrage wird eine Abfrage an eine Datenquelle in Timestream weitergeleitet. Die Abfrage wählt alle Spalten in der customer Tabelle aus und begrenzt die Ergebnisse auf 10.
SELECT * FROM TABLE(
system.query(
query => 'SELECT * FROM customer LIMIT 10'
))Lizenzinformationen
Das Timestream-Konnektor-Projekt von Amazon Athena ist unter der Apache-2.0-Lizenz
Weitere Ressourcen
Weitere Informationen zu diesem Connector finden Sie auf der entsprechenden Website
