Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Praktik terbaik untuk Amazon RDS
Pelajari praktik terbaik untuk menggunakan Amazon RDS. Saat praktik terbaik yang baru diidentifikasi, kami akan terus memperbarui bagian ini.
catatan
Untuk rekomendasi umum terkait Amazon RDS, lihat Rekomendasi dari RDS.
Pedoman operasional dasar Amazon RDS
Berikut ini adalah pedoman operasional dasar yang harus diikuti setiap orang saat menggunakan Amazon RDS. Perhatikan bahwa Perjanjian Tingkat Layanan Amazon RDS mewajibkan Anda untuk mengikuti pedoman ini:
-
Gunakan metrik untuk memantau memori, CPU, jeda replika, dan penggunaan penyimpanan Anda. Anda dapat mengatur Amazon CloudWatch untuk memberi tahu Anda saat pola penggunaan berubah atau saat penerapan mendekati batas kapasitas. Ini memungkinkan Anda untuk mempertahankan kinerja dan ketersediaan sistem.
-
Tingkatkan skala instans DB Anda saat mendekati batas kapasitas penyimpanan. Anda akan memiliki buffer dalam penyimpanan dan memori untuk mengakomodasi peningkatan permintaan yang tidak terduga dari aplikasi Anda.
-
Aktifkan pencadangan otomatis dan atur periode pencadangan agar pencadangan dilakukan selama IOPS tulis terendah harian. Pada saat itulah pencadangan tidak terlalu mengganggu penggunaan basis data Anda.
-
Jika beban kerja database Anda membutuhkan I/O lebih dari yang telah Anda sediakan, pemulihan setelah kegagalan atau kegagalan database akan lambat. Untuk meningkatkan I/O kapasitas instans DB, lakukan salah satu atau semua hal berikut:
Migrasi ke kelas instans DB yang berbeda dengan I/O kapasitas tinggi.
Konversi dari SSD Tujuan Umum ke penyimpanan SSD IOPS Tertentu, tergantung pada seberapa banyak peningkatan yang Anda butuhkan. Untuk informasi tentang jenis penyimpanan yang tersedia, lihat Jenis penyimpanan Amazon RDS.
Jika Anda mengonversi ke penyimpanan IOPS yang Tersedia, pastikan Anda juga menggunakan kelas instans DB yang dioptimalkan untuk IOPS yang Tersedia. Untuk informasi tentang IOPS yang Tersedia, lihat Penyimpanan SSD IOPS yang Tersedia.
Jika Anda sudah menggunakan penyimpanan IOPS yang Tersedia, sediakan kapasitas throughput tambahan.
-
Jika aplikasi klien menyimpan data Domain Name Service (DNS) instans DB Anda, atur nilai waktu untuk tayang (TTL) kurang dari 30 detik. Alamat IP yang mendasari untuk instans DB dapat berubah setelah failover. Menyimpan data DNS dalam cache untuk waktu yang lama dapat menyebabkan kegagalan koneksi. Aplikasi Anda mungkin mencoba untuk menghubungkan ke alamat IP yang sudah tidak berada dalam layanan.
-
Uji failover untuk instans DB Anda guna mengetahui berapa lama proses untuk kasus penggunaan khusus Anda. Uji failover untuk memastikan bahwa aplikasi yang mengakses instans DB Anda dapat terhubung secara otomatis ke instans DB baru setelah failover terjadi.
Rekomendasi RAM instans DB
Praktik terbaik performa Amazon RDS adalah mengalokasikan RAM yang cukup sehingga set kerja Anda hampir seluruhnya berada di memori. Set kerja adalah data dan indeks yang sering Anda gunakan pada instans. Makin banyak Anda menggunakan instans DB, makin banyak set kerja yang akan tumbuh.
Untuk mengetahui apakah set kerja Anda hampir semuanya ada dalam memori, periksa metrik ReadiOps (menggunakan CloudWatch Amazon) saat instans DB sedang dimuat. Nilai ReadIOPS harus kecil dan stabil. Dalam beberapa kasus, penskalaan kelas instans DB ke kelas yang memiliki lebih banyak RAM menghasilkan penurunan ReadIOPS yang signifikan. Dalam kasus ini, set kerja Anda hampir tidak seluruhnya berada di memori. Terus naikkan skala hingga ReadIOPS tidak lagi turun secara drastis setelah operasi penskalaan, atau ReadIOPS berkurang dengan jumlah yang sangat kecil. Untuk informasi tentang pemantauan metrik instans DB, lihat Melihat metrik di konsol Amazon RDS.
Menjaga versi mesin basis data tetap mutakhir
Tingkatkan versi mesin database Anda secara teratur untuk menjaga keamanan, kinerja, dan kepatuhan. Amazon RDS merilis versi minor dan utama baru yang mencakup patch keamanan, peningkatan kinerja, dan fitur baru. Menjalankan mesin database yang sudah ketinggalan zaman dapat mengekspos beban kerja Anda ke kerentanan yang diketahui, masalah kompatibilitas, dan pengurangan dukungan dari AWS dan vendor database.
Untuk meminimalkan gangguan, pertimbangkan hal berikut saat Anda merencanakan peningkatan:
-
Uji di lingkungan pementasan — Validasi versi baru terhadap beban kerja Anda sebelum Anda memutakhirkan basis data produksi.
-
Gunakan peningkatan terkelola Amazon RDS — Aktifkan peningkatan versi minor otomatis untuk penambalan yang lebih mudah.
-
Jadwalkan peningkatan versi utama - Tinjau catatan rilis, uji kompatibilitas aplikasi, dan rencanakan jendela pemutakhiran yang terkontrol.
Upgrade reguler membantu memastikan database Anda tetap aman, dioptimalkan, dan selaras dengan praktik AWS terbaik.
AWS driver basis data
Kami merekomendasikan AWS rangkaian driver untuk konektivitas aplikasi. Driver telah dirancang untuk memberikan dukungan untuk waktu peralihan dan failover yang lebih cepat, dan otentikasi dengan, AWS Identity and Access Management (IAM) AWS Secrets Manager, dan Federated Identity. AWS Driver mengandalkan pemantauan status instans DB dan menyadari topologi instance untuk menentukan penulis baru. Pendekatan ini mengurangi waktu peralihan dan failover menjadi satu digit detik, dibandingkan dengan puluhan detik untuk driver open-source.
Ketika fitur layanan baru diperkenalkan, tujuan dari AWS rangkaian driver adalah untuk memiliki dukungan bawaan untuk fitur layanan ini.
Untuk informasi selengkapnya, lihat Menghubungkan ke instans DB dengan driver AWS.
Menggunakan Pemantauan yang Ditingkatkan untuk mengidentifikasi masalah sistem operasi
Jika Pemantauan yang Ditingkatkan diaktifkan, Amazon RDS menyediakan metrik secara waktu nyata untuk sistem operasi (OS) yang dijalankan oleh instans DB Anda. Anda dapat melihat metrik instans DB menggunakan konsol tersebut. Anda juga dapat menggunakan output Enhanced Monitoring JSON dari Amazon CloudWatch Logs dalam sistem pemantauan pilihan Anda. Untuk informasi selengkapnya tentang Pemantauan yang Ditingkatkan, lihat Memantau metrik OS dengan Pemantauan yang Ditingkatkan.
Menggunakan metrik untuk mengidentifikasi masalah performa
Untuk mengidentifikasi masalah performa yang disebabkan oleh sumber daya yang tidak mencukupi dan kemacetan umum lainnya, Anda dapat memantau metrik yang tersedia untuk instans DB Amazon RDS Anda.
Melihat metrik performa
Anda harus memantau metrik performa secara rutin untuk mengetahui nilai rata-rata, maksimum, dan minimum dalam berbagai rentang waktu. Sehingga Anda dapat mengidentifikasi saat performa menurun. Anda juga dapat mengatur CloudWatch alarm Amazon untuk ambang metrik tertentu sehingga Anda diberi tahu jika mereka tercapai.
Untuk memecahkan masalah performa, penting untuk memahami performa dasar sistem. Saat Anda menyiapkan instans DB dan menjalankannya dengan beban kerja umum, catat nilai rata-rata, maksimum, dan minimum dari semua metrik performa. Lakukan hal tersebut pada sejumlah interval yang berbeda (misalnya, satu jam, 24 jam, satu minggu, dua minggu). Tindakan ini dapat memberi Anda gambaran tentang kondisi normal. Sehingga membantu mendapatkan perbandingan untuk jam sibuk dan tidak sibuk. Kemudian, Anda dapat menggunakan informasi ini untuk mengidentifikasi saat performa turun di bawah tingkat standar.
Jika Anda menggunakan cluster Multi-AZ DB, pantau perbedaan waktu antara transaksi terbaru pada instans DB penulis dan transaksi terbaru yang diterapkan pada instans DB pembaca. Selisih ini disebut jeda replika. Untuk informasi selengkapnya, lihat Replika lag dan cluster Multi-AZ DB.
Anda dapat melihat gabungan Performance Insights dan CloudWatch metrik di dasbor Performance Insights dan memantau instans DB Anda. Untuk menggunakan tampilan pemantauan ini, Wawasan Performa harus diaktifkan untuk instans DB Anda. Untuk informasi tentang tampilan pemantauan ini, lihat Melihat metrik gabungan dengan dasbor Performance Insights.
Anda dapat membuat laporan analisis performa untuk periode waktu tertentu dan melihat wawasan yang diidentifikasi serta rekomendasi untuk menyelesaikan masalah. Untuk informasi selengkapnya, lihat Membuat laporan analisis kinerja di Performance Insights.
Untuk melihat metrik performa
Masuk ke AWS Management Console dan buka konsol Amazon RDS di https://console.aws.amazon.com/rds/
. Di panel navigasi, pilih Basis Data, lalu pilih instans DB.
Pilih Pemantauan.
Dasbor menyediakan metrik performa. Metrik default untuk menampilkan informasi selama tiga jam terakhir.
Gunakan tombol pagination ke halaman melalui metrik tambahan, atau sesuaikan pengaturan untuk melihat metrik lainnya.
Pilih metrik performa untuk menyesuaikan rentang waktu agar dapat melihat data untuk selain hari ini. Anda dapat mengubah nilai Statistik, Rentang Waktu, dan Periode untuk menyesuaikan informasi yang ditampilkan. Misalnya, Anda mungkin ingin melihat nilai puncak untuk metrik pada masing-masing hari dalam dua minggu terakhir. Jika demikian, atur Statistik ke Maksimum, Rentang Waktu ke 2 Minggu Terakhir, dan Periode ke Hari.
Anda juga dapat melihat metrik performa menggunakan CLI atau API. Untuk informasi selengkapnya, lihat Melihat metrik di konsol Amazon RDS.
Untuk mengatur CloudWatch alarm
-
Masuk ke AWS Management Console dan buka konsol Amazon RDS di https://console.aws.amazon.com/rds/
. -
Di panel navigasi, pilih Basis Data, lalu pilih instans DB.
-
Pilih Log & peristiwa.
-
Di bagian alarm CloudWatch , pilih Buat alarm.
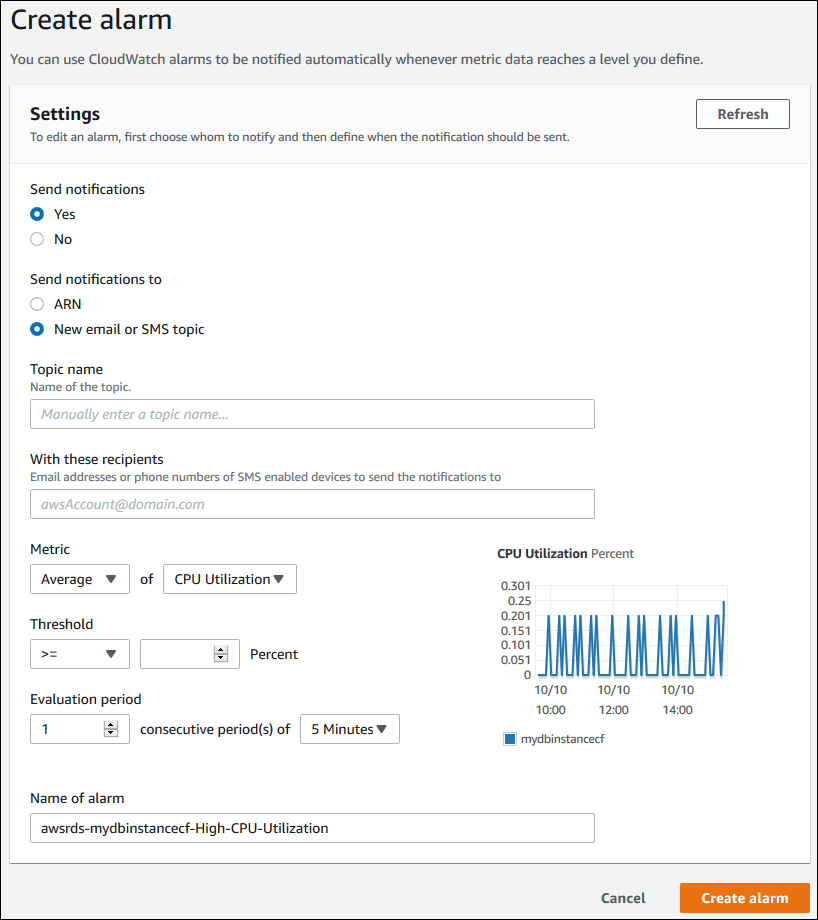
-
Untuk Kirim pemberitahuan, pilih Ya, dan untuk Kirim pemberitahuan ke, pilih Topik SMS atau email baru.
-
Untuk Nama topik, masukkan nama untuk pemberitahuan, dan untuk Dengan penerima ini, masukkan daftar alamat email dan nomor telepon yang dipisahkan dengan koma.
-
Untuk Metrik, pilih statistik dan metrik alarm yang akan diatur.
-
Untuk Ambang Batas, tentukan apakah metrik harus lebih besar dari, kurang dari, atau sama dengan ambang batas, dan tentukan nilai ambang batas.
-
Untuk Periode evaluasi, pilih periode evaluasi untuk alarm. Untuk periode berurutan, pilih periode ketika ambang batas harus sudah tercapai untuk memicu alarm.
-
Untuk Nama alarm, masukkan nama untuk alarm.
-
Pilih Buat Alarm.
Alarm akan muncul di bagian alarm CloudWatch .
Mengevaluasi metrik performa
Instans DB memiliki sejumlah kategori metrik yang berbeda, dan cara menentukan nilai yang dapat diterima bergantung pada metrik.
CPU
Pemanfaatan CPU – Persentase kapasitas pemrosesan komputer yang digunakan.
Memori
-
Freeable Memory — Berapa banyak RAM yang tersedia pada instans DB, dalam byte. Garis merah dalam metrik tab Pemantauan ditandai pada 75% untuk Metrik CPU, Memori, dan Penyimpanan. Jika penggunaan memori instans sering melewati garis tersebut, hal ini menunjukkan bahwa Anda harus memeriksa beban kerja atau meningkatkan instans.
Penggunaan Swap — Berapa banyak ruang swap yang digunakan oleh instans DB, dalam byte.
Ruang disk
Ruang Penyimpanan Kosong – Jumlah ruang disk yang saat ini tidak digunakan oleh instans DB, dalam megabyte.
Input/output operasi
IOPS Baca, IOPS Tulis – Jumlah rata-rata operasi baca atau tulis disk per detik.
Latensi Baca, Latensi Tulis – Waktu rata-rata untuk operasi baca atau tulis dalam milidetik.
Throughput Baca, Throughput Tulis – Rata-rata jumlah megabyte yang dibaca dari atau ditulis ke disk per detik.
Kedalaman Antrian — Jumlah I/O operasi yang menunggu untuk ditulis atau dibaca dari disk.
Lalu lintas jaringan
Throughput Penerimaan Jaringan, Throughput Pengiriman Jaringan – Tingkat lalu lintas jaringan ke dan dari instans DB dalam byte per detik.
Koneksi basis data
Koneksi DB – Jumlah sesi klien yang terhubung ke instans DB.
Untuk deskripsi individual yang lebih mendetail tentang metrik performa yang tersedia, lihat Memantau Amazon RDS metrik dengan Amazon CloudWatch.
Secara umum, nilai yang dapat diterima untuk metrik performa bergantung pada seperti apa garis dasar Anda dan apa yang dilakukan aplikasi Anda. Periksa varian yang konsisten atau sedang tren dari garis dasar Anda. Informasi tentang jenis metrik khusus sebagai berikut:
Penggunaan CPU atau RAM yang tinggi – Nilai yang tinggi untuk penggunaan CPU atau RAM mungkin sesuai. Misalnya, hal tersebut mungkin terjadi jika sesuai dengan tujuan aplikasi Anda (seperti throughput atau konkurensi) dan memang diharapkan.
Penggunaan ruang disk – Periksa penggunaan ruang disk jika ruang yang digunakan selalu berada di atau di atas 85 persen dari total ruang disk. Periksa apakah ada kemungkinan untuk menghapus data dari instans atau mengarsipkan data ke sistem yang berbeda guna mengosongkan sebagian ruang.
Lalu lintas jaringan – Untuk lalu lintas jaringan, bicaralah kepada administrator sistem Anda untuk memahami throughput yang diharapkan bagi jaringan domain dan koneksi internet Anda. Periksa lalu lintas jaringan jika throughput selalu lebih rendah dari yang diharapkan.
Koneksi basis data – Sebaiknya batasi koneksi basis data jika Anda melihat jumlah koneksi pengguna yang tinggi sehubungan dengan penurunan performa instans dan waktu respons. Jumlah koneksi pengguna terbaik untuk instans DB Anda akan bervariasi berdasarkan kelas instans Anda dan kerumitan operasi yang dilakukan. Untuk menentukan jumlah koneksi basis data, kaitkan instans DB Anda dengan grup parameter. Dalam grup ini, atur parameter Koneksi Pengguna ke selain 0 (tidak terbatas). Anda dapat menggunakan grup parameter yang sudah ada atau membuat grup baru. Untuk informasi selengkapnya, lihat Kelompok parameter untuk Amazon RDS.
Metrik IOPS – Nilai yang diharapkan untuk metrik IOPS bergantung pada spesifikasi disk dan konfigurasi server; jadi, gunakan acuan dasar Anda untuk mengetahui nilai yang lazim. Periksa apakah nilainya selalu berbeda dari garis dasar Anda. Untuk performa IOPS terbaik, pastikan set kerja Anda sesuai dengan memori untuk meminimalkan operasi baca dan tulis.
Untuk masalah pada metrik performa, langkah pertama untuk meningkatkan performa adalah menyetel kueri yang paling sering digunakan dan paling menghabiskan biaya. Setel kueri tersebut untuk melihat apakah langkah ini dapat menurunkan tekanan pada sumber daya sistem. Untuk informasi selengkapnya, lihat Menyetel kueri.
Jika kueri sudah disetel dan masalah tetap ada, sebaiknya tingkatkan Amazon RDS Kelas instans DB. Anda dapat memutakhirkannya ke satu dengan lebih banyak sumber daya (CPU, RAM, ruang disk, bandwidth jaringan, I/O kapasitas) yang terkait dengan masalah tersebut.
Menyetel kueri
Salah satu cara terbaik untuk meningkatkan performa instans DB adalah dengan menyetel kueri yang paling sering digunakan dan paling sarat sumber daya. Di sini, Anda menyetelnya agar dapat dijalankan dengan biaya yang lebih terjangkau. Untuk informasi tentang peningkatan kueri, gunakan sumber daya berikut:
-
MySQL – Lihat Optimizing SELECT statements
dalam dokumentasi MySQL. Untuk sumber daya tambahan tentang penyetelan kueri, lihat Sumber daya penyetelan dan pengoptimalan performa MySQL . -
Oracle – Lihat Database SQL Tuning Guide
dalam dokumentasi Oracle Database. -
SQL Server – Lihat Analyzing a query
dalam dokumentasi Microsoft. Anda juga dapat menggunakan tampilan eksekusi, indeks, dan manajemen I/O-related data (DMV) yang dijelaskan dalam Tampilan Manajemen Dinamis Sistem dalam dokumentasi Microsoft untuk memecahkan masalah kueri SQL Server. Aspek umum penyetelan kueri adalah membuat indeks yang efektif. Untuk perbaikan indeks instans DB yang dapat dilakukan, lihat Database Engine Tuning Advisor
dalam dokumentasi Microsoft. Untuk informasi tentang penggunaan Tuning Advisor di RDS for SQL Server, lihat Menganalisis beban kerja basis data di instans DB Amazon RDS for SQL Server dengan basis data Engine Tuning Advisor. -
PostgreSQL – Lihat Using EXPLAIN
dalam dokumentasi PostgreSQL untuk mempelajari cara menganalisis rencana kueri. Anda dapat menggunakan informasi ini untuk mengubah kueri atau tabel yang mendasarinya guna meningkatkan performa kueri. Untuk informasi tentang cara menentukan gabungan dalam kueri Anda untuk performa terbaik, lihat Mengontrol perencana dengan klausul JOIN eksplisit
. -
MariaDB – Lihat Query optimizations
dalam dokumentasi MariaDB.
Praktik terbaik dalam menggunakan MySQL
Ukuran tabel dan jumlah tabel dalam basis data MySQL dapat memengaruhi performa.
Ukuran tabel
Biasanya, batasan sistem operasi pada ukuran file menentukan ukuran tabel maksimum yang efektif untuk basis data MySQL. Jadi, batasannya biasanya tidak ditentukan oleh batasan MySQL internal.
Untuk instans DB MySQL, hindari tabel di basis data Anda yang tumbuh terlalu besar. Meskipun batas penyimpanan umum adalah 64 TiB, batas penyimpanan yang tersedia membatasi ukuran maksimum file tabel MySQL hingga 16 TiB. Partisi tabel besar Anda sehingga ukuran file berada di bawah batas 16 TiB. Pendekatan ini juga dapat meningkatkan performa dan waktu pemulihan. Untuk informasi selengkapnya, lihat Batas ukuran file MySQL di Amazon RDS.
Tabel yang sangat besar (dengan ukuran lebih dari 100 GB) dapat memengaruhi performa baik secara negatif untuk baca dan tulis (termasuk pernyataan DML dan terutama pernyataan DDL). Indeks pada tabel besar dapat secara signifikan meningkatkan performa tertentu, tetapi juga dapat menurunkan performa laporan DML. Pernyataan DDL, seperti ALTER TABLE, dapat menjadi lebih lambat secara signifikan untuk tabel besar karena operasi tersebut mungkin sepenuhnya membangun ulang tabel dalam beberapa kasus. Pernyataan DDL ini dapat mengunci tabel selama operasi berlangsung.
Jumlah memori yang diperlukan oleh MySQL untuk baca dan tulis tergantung pada tabel yang terlibat dalam operasi. Praktik terbaiknya adalah memiliki setidaknya RAM yang cukup untuk menyimpan indeks tabel yang digunakan secara aktif. Untuk menemukan sepuluh tabel dan indeks terbesar dalam basis data, gunakan kueri berikut:
select table_schema, TABLE_NAME, dat, idx from (SELECT table_schema, TABLE_NAME, ( data_length ) / 1024 / 1024 as dat, ( index_length ) / 1024 / 1024 as idx FROM information_schema.TABLES order by 3 desc ) a order by 3 desc limit 10;
Jumlah tabel
Sistem file yang mendasarinya mungkin memiliki batas jumlah file yang mewakili tabel. Namun, MySQL tidak memiliki batasan jumlah tabel. Meskipun demikian, total jumlah tabel dalam mesin penyimpanan MySQL InnoDB dapat berkontribusi pada penurunan performa, terlepas dari ukuran tabel tersebut. Untuk membatasi dampak sistem operasi, Anda dapat memisahkan tabel di beberapa basis data dalam instans DB MySQL yang sama. Tindakan tersebut dapat membatasi jumlah file dalam direktori, tetapi tidak akan menyelesaikan masalah secara keseluruhan.
Penurunan performa karena sejumlah besar tabel (lebih dari 10 ribu) disebabkan oleh MySQL yang bekerja dengan file penyimpanan, termasuk membuka dan menutupnya. Untuk mengatasi masalah ini, Anda dapat meningkatkan ukuran parameter table_open_cache dan table_definition_cache. Namun, meningkatkan nilai parameter tersebut dapat secara signifikan meningkatkan jumlah penggunaan memori MySQL, dan bahkan mungkin menggunakan semua memori yang tersedia. Untuk informasi selengkapnya, lihat How MySQL Opens and Closes Tables
Selain itu, terlalu banyak tabel dapat secara signifikan memengaruhi waktu pemulaian MySQL. Pematian dan pengaktifan ulang yang bersih dan pemulihan crash dapat terpengaruh, khususnya dalam versi sebelum MySQL 8.0.
Kami merekomendasikan total kurang dari 10.000 tabel di semua basis data dalam instans DB. Untuk kasus penggunaan dengan sejumlah besar tabel dalam basis data, lihat Satu Juta Tabel di MySQL 8.0
Mesin penyimpanan
Fitur pemulihan titik waktu dan pemulihan snapshot dari Amazon RDS for MySQL memerlukan mesin penyimpanan yang dapat dipulihkan. Fitur ini hanya didukung untuk mesin penyimpanan InnoDB. Meskipun MySQL mendukung banyak mesin penyimpanan dengan berbagai kemampuan, tidak semuanya dioptimalkan untuk pemulihan crash dan durabilitas data. Misalnya, mesin penyimpanan MyISAM tidak mendukung pemulihan crash yang andal dan mungkin mencegah pemulihan titik waktu atau pemulihan snapshot sehingga tidak berfungsi sebagaimana mestinya. Hal ini dapat mengakibatkan hilangnya atau rusaknya data ketika MySQL dimulai ulang setelah terjadi kerusakan.
InnoDB adalah mesin penyimpanan yang direkomendasikan dan didukung untuk instans DB MySQL di Amazon RDS. Instans InnoDB juga dapat dimigrasikan ke Aurora, sementara instans MyISAM tidak dapat dimigrasikan. Namun, MyISAM berperforma lebih baik daripada InnoDB jika Anda memerlukan pencarian teks penuh yang intens. Jika Anda masih memilih untuk menggunakan MyISAM dengan Amazon RDS, mengikuti langkah-langkah yang diuraikan di Cadangan otomatis dengan mesin penyimpanan MySQL yang tidak didukung dapat membantu dalam skenario tertentu untuk fungsi pemulihan snapshot.
Jika Anda ingin mengonversi tabel MyISAM yang ada ke tabel InnoDB, Anda dapat menggunakan proses yang diuraikan dalam Mengonversi Tabel dari MyISAM ke InnoDB dalam
Selain itu, Federated Storage Engine saat ini tidak didukung oleh Amazon RDS for MySQL.
Praktik terbaik untuk menggunakan MariaDB
Ukuran tabel dan jumlah tabel dalam basis data MariaDB dapat memengaruhi performa.
Ukuran tabel
Biasanya, batasan sistem operasi pada ukuran file menentukan ukuran tabel maksimum yang efektif untuk basis data MariaDB. Jadi, batasannya biasanya tidak ditentukan oleh batasan MariaDB internal.
Untuk instans DB MariaDB, hindari tabel di basis data Anda yang tumbuh terlalu besar. Meskipun batas penyimpanan umum adalah 64 TiB, batas penyimpanan yang tersedia membatasi ukuran maksimum file tabel MariaDB hingga 16 TiB. Partisi tabel besar Anda sehingga ukuran file berada di bawah batas 16 TiB. Pendekatan ini juga dapat meningkatkan performa dan waktu pemulihan.
Tabel yang sangat besar (dengan ukuran lebih dari 100 GB) dapat memengaruhi performa baik secara negatif untuk baca dan tulis (termasuk pernyataan DML dan terutama pernyataan DDL). Indeks pada tabel besar dapat secara signifikan meningkatkan performa tertentu, tetapi juga dapat menurunkan performa laporan DML. Pernyataan DDL, seperti ALTER TABLE, dapat menjadi lebih lambat secara signifikan untuk tabel besar karena operasi tersebut mungkin sepenuhnya membangun ulang tabel dalam beberapa kasus. Pernyataan DDL ini dapat mengunci tabel selama operasi berlangsung.
Jumlah memori yang diperlukan oleh MariaDB untuk baca dan tulis tergantung pada tabel yang terlibat dalam operasi. Praktik terbaiknya adalah memiliki setidaknya RAM yang cukup untuk menyimpan indeks tabel yang digunakan secara aktif. Untuk menemukan sepuluh tabel dan indeks terbesar dalam basis data, gunakan kueri berikut:
select table_schema, TABLE_NAME, dat, idx from (SELECT table_schema, TABLE_NAME, ( data_length ) / 1024 / 1024 as dat, ( index_length ) / 1024 / 1024 as idx FROM information_schema.TABLES order by 3 desc ) a order by 3 desc limit 10;
Jumlah tabel
Sistem file yang mendasarinya mungkin memiliki batas jumlah file yang mewakili tabel. Namun, MariaDB tidak memiliki batasan jumlah tabel. Meskipun demikian, total jumlah tabel dalam mesin penyimpanan MariaDB InnoDB dapat berkontribusi pada penurunan performa, terlepas dari ukuran tabel tersebut. Untuk membatasi dampak sistem operasi, Anda dapat memisahkan tabel di beberapa basis data dalam instans DB MariaDB yang sama. Tindakan tersebut dapat membatasi jumlah file dalam direktori, tetapi tidak menyelesaikan masalah secara keseluruhan.
Penurunan performa karena sejumlah besar tabel (lebih dari 10.000) disebabkan oleh MariaDB yang bekerja dengan file penyimpanan. Pekerjaan ini mencakup pembukaan dan penutupan file penyimpanan MariaDB. Untuk mengatasi masalah ini, Anda dapat meningkatkan ukuran parameter table_open_cache dan table_definition_cache. Namun, meningkatkan nilai parameter tersebut dapat secara signifikan meningkatkan jumlah penggunaan memori MariaDB. Bahkan mungkin menggunakan semua memori yang tersedia. Untuk informasi selengkapnya, lihat Optimizing table_open_cache
Selain itu, terlalu banyak tabel dapat secara signifikan memengaruhi waktu pemulaian MariaDB. Pematian dan pengaktifan ulang yang bersih dan pemulihan crash dapat terpengaruh. Kami merekomendasikan jumlah total kurang dari sepuluh ribu tabel di semua basis data dalam instans DB.
Mesin penyimpanan
Fitur pemulihan titik waktu dan pemulihan snapshot dari Amazon RDS for MariaDB memerlukan mesin penyimpanan yang dapat dipulihkan. Meskipun MariaDB mendukung banyak mesin penyimpanan dengan berbagai kemampuan, tidak semuanya dioptimalkan untuk pemulihan crash dan durabilitas data. Misalnya, meskipun Aria adalah pengganti yang aman dari crash untuk MyISAM, Aria mungkin masih mencegah pemulihan titik waktu atau pemulihan snapshot sehingga tidak berfungsi sebagaimana mestinya. Hal ini dapat mengakibatkan hilangnya atau rusaknya data ketika MariaDB dimulai ulang setelah terjadi kerusakan. InnoDB adalah mesin penyimpanan yang direkomendasikan dan didukung untuk instans DB MariaDB di Amazon RDS. Jika Anda masih memilih untuk menggunakan Aria dengan Amazon RDS, mengikuti langkah-langkah yang diuraikan di Cadangan otomatis dengan mesin penyimpanan MariaDB yang tidak didukung dapat membantu dalam skenario tertentu untuk fungsi pemulihan snapshot.
Jika Anda ingin mengonversi tabel MyISAM yang ada ke tabel InnoDB, Anda dapat menggunakan proses yang diuraikan dalam Mengonversi Tabel dari MyISAM ke InnoDB dalam
Praktik terbaik untuk menggunakan Oracle
Informasi tentang praktik terbaik untuk menggunakan Amazon RDS for Oracle dapat dilihat di Praktik terbaik untuk menjalankan basis data Oracle di Amazon Web Services.
Lokakarya AWS virtual 2020 menyertakan presentasi tentang menjalankan basis data Oracle produksi di Amazon RDS. Video presentasi tersedia di sini:
Praktik terbaik untuk menggunakan PostgreSQL
Dari dua area penting tempat Anda dapat meningkatkan performa dengan RDS for PostgreSQL, salah satunya adalah saat memuat data ke instans DB. Area lainnya adalah saat menggunakan fitur autovacuum PostgreSQL. Bagian berikut mencakup beberapa praktik yang direkomendasikan untuk kedua area tersebut.
Untuk informasi tentang cara Amazon RDS mengimplementasikan tugas DBA umum untuk PostgreSQL lainnya, lihat Tugas DBA umum untuk Amazon RDS for PostgreSQL.
Memuat data ke dalam instans DB PostgreSQL
Saat memuat data ke instans DB Amazon RDS for PostgreSQL, ubah pengaturan instans DB dan nilai grup parameter DB Anda. Ubah pengaturan dan nilai tersebut untuk memungkinkan pengimporan data yang paling efisien ke instans DB Anda.
Ubah pengaturan instans DB Anda sebagai berikut:
-
Nonaktifkan pencadangan instans DB (ubah backup_retention menjadi 0)
-
Nonaktifkan Multi-AZ
Ubah grup parameter DB Anda untuk menyertakan pengaturan berikut. Selain itu, uji juga pengaturan parameter untuk menemukan pengaturan yang paling efisien untuk instans DB Anda.
-
Tingkatkan nilai parameter
maintenance_work_mem. Untuk informasi selengkapnya tentang parameter penggunaan sumber daya PostgreSQL, lihat dokumentasi PostgreSQL. -
Tingkatkan nilai parameter
max_wal_sizedancheckpoint_timeoutuntuk mengurangi jumlah penulisan ke log write-ahead log (WAL). -
Nonaktifkan parameter
synchronous_commit. -
Nonaktifkan parameter autovacuum PostgreSQL.
-
Pastikan tidak ada satu pun tabel yang Anda impor yang tidak masuk log. Data yang disimpan dalam tabel yang tidak masuk log dapat hilang selama failover. Untuk informasi selengkapnya, lihat MEMBUAT TABEL YANG TIDAK MASUK LOG
.
Gunakan perintah pg_dump -Fc (terkompresi) atau pg_restore -j (paralel) dengan pengaturan ini.
Setelah operasi pemuatan selesai, pulihkan instans DB dan parameter DB Anda ke pengaturan normalnya.
Menggunakan fitur autovacuum PostgreSQL
Fitur autovacuum untuk basis data PostgreSQL adalah fitur yang sangat kami rekomendasikan bagi Anda untuk menjaga kondisi instans DB PostgreSQL. Autovacuum mengotomatiskan eksekusi perintah VACUUM dan ANALYZE. Penggunaan autovacuum diwajibkan oleh PostgreSQL, tidak diberlakukan oleh Amazon RDS, dan penggunaannya sangat penting untuk performa yang baik. Fitur ini diaktifkan secara default untuk semua instans DB Amazon RDS for PostgreSQL baru, dan parameter konfigurasi terkait diatur dengan tepat secara default.
Administrator basis data Anda perlu mengetahui dan memahami operasi pemeliharaan ini. Untuk dokumentasi PostgreSQL tentang autovacuum, lihat Daemon Autovacuum
Autovacuum bukan merupakan operasi "bebas sumber daya", tetapi operasi yang bekerja di latar belakang dan menghasilkan operasi pengguna sebanyak mungkin. Saat diaktifkan, autovacuum memeriksa tabel yang memiliki banyak tuple yang diperbarui atau dihapus. Autovacuum juga melindungi dari kehilangan data yang berumur sangat lama karena penyelesaian ID transaksi. Untuk informasi selengkapnya, lihat Mencegah kegagalan penyelesaian ID transaksi
Autovacuum sebaiknya tidak dianggap sebagai operasi dengan overhead tinggi yang dapat dikurangi untuk mendapatkan performa yang lebih baik. Sebaliknya, tabel yang memiliki pembaruan dan penghapusan dengan kecepatan tinggi akan dengan cepat memburuk seiring waktu jika autovacuum tidak dijalankan.
penting
Tidak menjalankan autovacuum dapat mengakibatkan gangguan yang pada akhirnya diperlukan untuk melakukan operasi vakum yang jauh lebih mengganggu. Dalam beberapa kasus, instans DB RDS for PostgreSQL mungkin menjadi tidak tersedia karena penggunaan autovacuum yang terlalu konservatif. Dalam kasus ini, basis data PostgreSQL dimatikan untuk melindungi dirinya sendiri. Pada saat itu, Amazon RDS harus melakukan vakum penuh mode pengguna tunggal secara langsung pada instans DB. Vakum penuh ini dapat mengakibatkan gangguan selama beberapa jam. Oleh karena itu, kami sangat merekomendasikan agar Anda tidak mematikan autovacuum, yang diaktifkan secara default.
Parameter autovacuum menentukan kapan dan seberapa keras autovacuum bekerja. Parameter autovacuum_vacuum_threshold dan autovacuum_vacuum_scale_factor menentukan kapan autovacuum dijalankan. Parameter autovacuum_max_workers, autovacuum_nap_time, autovacuum_cost_limit, dan autovacuum_cost_delay menentukan seberapa keras autovacuum bekerja. Untuk informasi selengkapnya tentang autovacuum, kapan autovacuum berjalan, dan parameter apa yang diperlukan, lihat Routine Vacuuming
Kueri berikut ini menunjukkan jumlah tuple "mati" dalam tabel dengan nama table1:
SELECT relname, n_dead_tup, last_vacuum, last_autovacuum FROM pg_catalog.pg_stat_all_tables WHERE n_dead_tup > 0 and relname = 'table1';
Hasil kueri akan seperti berikut ini:
relname | n_dead_tup | last_vacuum | last_autovacuum ---------+------------+-------------+----------------- tasks | 81430522 | | (1 row)
Video praktik terbaik Amazon RDS for PostgreSQL
Konferensi re AWS : Invent 2020 menyertakan presentasi tentang fitur-fitur baru dan praktik terbaik untuk bekerja dengan PostgreSQL di Amazon RDS. Video presentasi tersedia di sini:
Praktik terbaik untuk menggunakan SQL Server
Praktik terbaik untuk Multi-AZ penerapan dengan instans SQL Server DB meliputi yang berikut:
Gunakan peristiwa DB Amazon RDS untuk memantau failover. Misalnya, Anda akan mendapatkan pemberitahuan melalui pesan teks atau email jika ada kegagalan instans DB. Untuk informasi selengkapnya tentang peristiwa Amazon RDS, lihat Menggunakan pemberitahuan peristiwa Amazon RDS.
Jika aplikasi Anda menyimpan nilai DNS dalam cache, atur waktu untuk beroperasi (TTL) menjadi kurang dari 30 detik. Mengatur TTL adalah praktik yang baik jika terjadi failover. Dalam failover, alamat IP mungkin berubah dan nilai yang disimpan dalam cache mungkin tidak lagi digunakan.
Kami menyarankan Anda untuk tidak mengaktifkan mode berikut karena mereka mematikan pencatatan transaksi, yang diperlukan untuk Multi-AZ:
-
Mode pemulihan sederhana
-
Mode offline
-
Read-only modus
-
Lakukan pengujian untuk menentukan durasi yang dibutuhkan bagi instans DB Anda untuk failover. Waktu failover dapat bervariasi berdasarkan jenis basis data, kelas instans, dan jenis penyimpanan yang Anda gunakan. Anda juga harus menguji kemampuan aplikasi Anda untuk terus bekerja jika terjadi failover.
Untuk mempersingkat waktu failover, lakukan hal berikut:
Pastikan Anda memiliki cukup IOPS yang Tersedia, yang dialokasikan untuk beban kerja Anda. Tidak memadai I/O dapat memperpanjang waktu failover. Pemulihan basis data membutuhkan I/O.
Gunakan transaksi yang lebih kecil. Pemulihan basis data bergantung pada transaksi, jadi jika Anda dapat memecah transaksi besar menjadi beberapa transaksi yang lebih kecil, waktu failover Anda akan lebih singkat.
Pertimbangkan kenaikan latensi selama failover. Sebagai bagian dari proses failover, Amazon RDS mereplikasi data Anda ke instans siaga baru secara otomatis. Replikasi ini berarti bahwa data baru dimasukkan ke dua instans DB yang berbeda. Jadi, mungkin ada beberapa latensi hingga instans DB siaga berhasil mengimbangi instans DB primer yang baru.
Deploy aplikasi Anda di semua Zona Ketersediaan. Jika Zona Ketersediaan tidak aktif, aplikasi Anda di Zona Ketersediaan lain akan tetap tersedia.
Saat bekerja dengan Multi-AZ penerapan SQL Server, ingatlah bahwa Amazon RDS membuat replika untuk semua database SQL Server pada instans Anda. Jika Anda tidak ingin database tertentu memiliki replika sekunder, siapkan instans DB terpisah yang tidak digunakan Multi-AZ untuk database tersebut.
Video praktik terbaik Amazon RDS for SQL Server
Konferensi AWS re:Invent 2019 menyertakan presentasi tentang fitur-fitur baru dan praktik terbaik untuk bekerja dengan SQL Server di Amazon RDS. Video presentasi tersedia di sini:
Menggunakan grup parameter DB
Sebaiknya Anda mencoba perubahan grup parameter DB pada instans DB pengujian sebelum menerapkan perubahan grup parameter pada instans DB produksi Anda. Pengaturan parameter mesin DB yang tidak tepat dalam grup parameter DB dapat memiliki efek merugikan yang tidak diinginkan, termasuk penurunan performa dan ketidakstabilan sistem. Selalu berhati-hati saat memodifikasi parameter mesin DB dan mencadangkan instans DB sebelum memodifikasi grup parameter DB.
Untuk informasi tentang mencadangkan instans DB, lihat Mencadangkan, memulihkan, dan mengekspor data.
Praktik terbaik untuk mengotomatiskan pembuatan instans DB
Ini adalah praktik terbaik Amazon RDS untuk membuat instans DB dengan versi minor pilihan mesin basis data. Anda dapat menggunakan AWS CLI, Amazon RDS API, atau AWS CloudFormation untuk mengotomatiskan pembuatan instans DB. Jika menggunakan metode ini, Anda hanya dapat menentukan versi utama dan Amazon RDS otomatis membuat instans dengan versi minor pilihan. Misalnya, jika PostgreSQL 12.5 adalah versi minor pilihan, dan jika Anda menentukan versi 12 dengan create-db-instance, instans DB akan menjadi versi 12.5.
Untuk menentukan versi minor pilihan, Anda dapat menjalankan perintah describe-db-engine-versions dengan opsi --default-only seperti yang ditunjukkan dalam contoh berikut.
aws rds describe-db-engine-versions --default-only --engine postgres { "DBEngineVersions": [ { "Engine": "postgres", "EngineVersion": "12.5", "DBParameterGroupFamily": "postgres12", "DBEngineDescription": "PostgreSQL", "DBEngineVersionDescription": "PostgreSQL 12.5-R1", ...some output truncated... } ] }
Untuk informasi tentang pembuatan instans DB secara pemrograman, lihat sumber daya berikut:
Menggunakan AWS CLI — create-db-instance
Menggunakan API Amazon RDS – CreateDBInstance
Menggunakan AWS CloudFormation — AWS: :RDS: :DBInstance
Amazon RDS fitur baru video
Konferensi AWS Re: Invent 2023 menyertakan presentasi tentang fitur Amazon RDS baru. Video presentasi tersedia di sini:
