Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Erste Schritte mit Amazon Neptune
Amazon Neptune ist ein vollständig verwalteter Graphdatenbank-Service, der für Milliarden von Beziehungen skaliert werden kann und es Ihnen ermöglicht, diese mit einer Latenz von Millisekunden abzufragen, und dies zu geringen Kosten für diese Art von Kapazität.
Weitere Informationen zu Neptune finden Sie unter Übersicht über Amazon-Neptune-Features.
Wenn Sie sich bereits mit Diagrammen auskennen, fahren Sie mit oder fort. Schneller Start mit CloudShell Neptune mit Grafiknotizbüchern verwenden Wenn Sie sofort eine Neptune-Datenbank erstellen möchten, finden Sie weitere Informationen unter Erstellen eines Amazon Neptune Neptune-Clusters mit AWS CloudFormation.
Andernfalls möchten Sie vielleicht etwas mehr über Graphdatenbanken erfahren, bevor Sie beginnen.
Die wichtigsten Konzepte von Graphdatenbanken
Graphdatenbanken sind für das Speichern und Abfragen der Beziehungen zwischen Datenelementen optimiert.
Sie speichern Datenelemente selbst als Scheitelpunkte des Graphen und die Beziehungen zwischen ihnen als Edges. Jede Edge hat einen Typ und verläuft von einem Vertex (dem Anfang) zum anderen (dem Ende). Beziehungen können sowohl als Prädikate als auch als Edges bezeichnet werden und Scheitelpunkte werden manchmal auch als Knoten bezeichnet. In sogenannten Eigenschaftsgraphen können sowohl Scheitelpunkten als auch Edges zusätzliche Eigenschaften zugeordnet werden.
Hier ist ein kleiner Graph, der Freunde und Hobbys in einem sozialen Netzwerk darstellt:
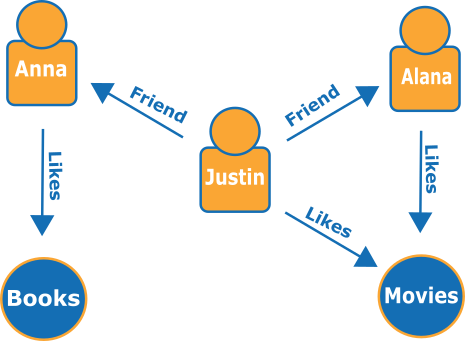
Die Edges werden als benannte Pfeile dargestellt und die Scheitelpunkte stehen für bestimmte Personen und Hobbys, die sie miteinander verbinden.
Mit einer einfachen Verschiebung dieses Graphen erfahren Sie, was die Freunde von Justin mögen.
Warum sollte ich eine Graphdatenbank verwenden?
Wenn Verbindungen oder Beziehungen zwischen Entitäten zum Kern der Daten gehören, die Sie darstellen möchten, ist eine Graphdatenbank die logische Konsequenz.
Zum einen ist es einfach, Datenverbindungen als Graph zu modellieren und dann komplexe Abfragen zu schreiben, die reale Informationen aus dem Graphen extrahieren.
Um eine äquivalente Anwendung mithilfe einer relationalen Datenbank zu erstellen, müssen Sie zahlreiche Tabellen mit mehreren Fremdschlüsseln erstellen und dann verschachtelte SQL-Abfragen und komplexe Verknüpfungen schreiben. Dieser Ansatz wird nicht nur aus Sicht der Programmierung schnell unhandlich, auch nimmt seine Leistung schnell ab, wenn die Datenmenge zunimmt.
Im Gegensatz dazu kann eine Graphdatenbank wie Neptune Beziehungen zwischen Milliarden von Scheitelpunkten abfragen, ohne dabei ins Stocken zu geraten.
Was können Sie mit einer Graphdatenbank tun?
Graphen können die Wechselbeziehungen zwischen realen Entitäten auf vielfältige Weise darstellen, was Handlungen, Eigentumsverhältnisse, Abstammung, Kaufentscheidungen, persönliche Verbindungen, familiäre Bindungen usw. angeht.
Im Folgenden sind einige der häufigsten Bereiche aufgeführt, in denen Graphdatenbanken verwendet werden:
-
Wissensgraphen – Mit Wissensgraphen können Sie alle Arten von zusammenhängenden Informationen organisieren und abfragen, um allgemeine Fragen zu beantworten. Mithilfe eines Wissensgraphen können Sie aktuelle Informationen zu Produktkatalogen hinzufügen und vielfältige Informationen modellieren, wie sie beispielsweise in Wikidata
enthalten sind. Weitere Informationen zu Wissensdiagrammen und ihren Einsatzbereichen finden Sie unter Knowledge Graphs on AWS
. -
Identitätsgraphen – In einer Graphdatenbank können Sie Beziehungen zwischen Informationskategorien wie Kundeninteressen, Freunden und Kaufhistorie speichern und diese Daten dann abfragen, um personalisierte und relevante Empfehlungen abzugeben.
Zum Beispiel können Sie eine hochverfügbare Graphdatenbank verwenden, um einem Benutzer Produktempfehlungen basierend darauf zu unterbreiten, welche Produkte von anderen gekauft wurden, die denselben Sport betreiben und eine ähnliche Kaufhistorie aufweisen. Oder Sie können Personen identifizieren, die einen gemeinsamen Freund haben, sich aber noch nicht kennen, und eine Freundschaftsempfehlung abgeben.
Graphen dieser Art werden als Identitätsgraphen bezeichnet und häufig zur Personalisierung von Interaktionen mit Benutzern verwendet. Weitere Informationen finden Sie unter Identitätsgraphen auf AWS
. Um mit der Erstellung Ihres eigenen Identitätsgraphen zu beginnen, können Sie mit dem Beispiel Identitätsgraph unter Verwendung von Amazon Neptune beginnen. -
Betrugsgraphen – Dies ist eine häufige Anwendung von Graphdatenbanken. Sie können Ihnen dabei helfen, Kreditkartenkäufe und Einkaufsstandorte nachzuverfolgen, um ungewöhnliche Nutzungen zu erkennen oder um festzustellen, dass ein Käufer versucht, dieselbe E-Mail-Adresse und Kreditkarte zu verwenden, die in einem bekannten Betrugsfall verwendet wurden. Damit können Sie nach mehreren Personen suchen, die mit einer persönlichen E-Mail-Adresse verknüpft sind, oder nach mehreren Personen an verschiedenen physischen Standorten, die dieselbe IP-Adresse nutzen.
Sehen Sie sich diesen Graphen an. Er zeigt die Beziehung zwischen drei Personen und ihren identitätsbezogenen Daten. Jede Person hat eine Adresse, ein Bankkonto und eine Sozialversicherungsnummer. Wir sehen aber, dass Matt und Justin dieselbe Sozialversicherungsnummer nutzen. Dies ist ungewöhnlich und weist auf einen möglichen Betrug durch eine dieser Personen hin. Eine Abfrage eines Betrugsdiagramms kann Verbindungen dieser Art aufdecken, so dass sie überprüft werden können.
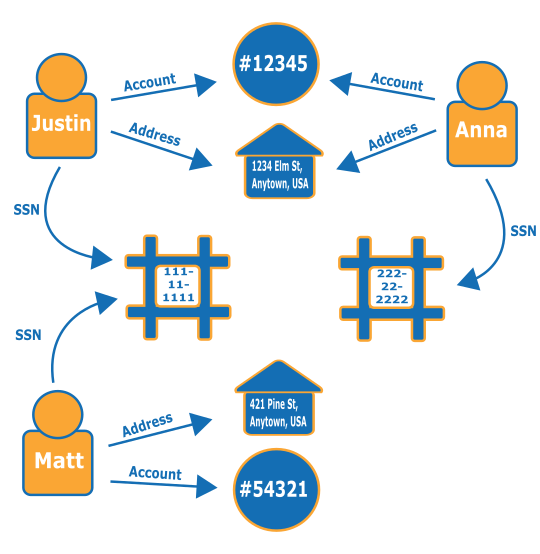
Weitere Informationen zu Betrugsgrafiken und deren Verwendung finden Sie unter Betrugsgrafiken auf AWS
. -
Soziale Netzwerke – Einer der ersten und häufigsten Bereiche, in denen Graphdatenbanken verwendet wurden und werden, sind Anwendungen für soziale Netzwerke.
Angenommen, Sie möchten einen sozialen Feed in eine Website integrieren. Sie können ganz einfach eine Graphdatenbank im Backend verwenden, um Benutzern Ergebnisse zu bieten, die die neuesten Updates von ihren Familien und Freunden, von Personen, deren Updates ihnen „gefallen“, und von Personen, die ihnen nahe stehen, widerspiegeln.
Wegbeschreibungen – Ein Graph kann dabei helfen, die optimale Route von einem Startpunkt zu einem Ziel zu finden, wobei der aktuelle Verkehr und typische Verkehrsmuster berücksichtigt werden.
Logistik – Mithilfe von Graphen können Sie ermitteln, wie die verfügbaren Versand- und Vertriebsressourcen am effizientesten genutzt werden können, um Kundenanforderungen zu erfüllen.
Diagnose – Graphen können komplexe Diagnosestrukturen darstellen, die abgefragt werden können, um die Ursache beobachteter Probleme und Ausfälle zu ermitteln.
Wissenschaftliche Forschung – Mit einer Graphdatenbank können Sie Anwendungen erstellen, die wissenschaftliche Daten und sogar sensible medizinische Informationen mithilfe von Verschlüsselung im Ruhezustand speichern, und darin navigieren. So können Sie beispielsweise Modelle von Krankheits- und Gen-Interaktionen speichern. Sie können nach Graphmustern in Proteinwegen suchen, um andere Gene zu finden, die mit einer Krankheit assoziiert sein könnten. Sie können chemische Verbindungen als Graph modellieren und Muster in molekularen Strukturen abfragen. Sie können Patientendaten aus Krankenakten in verschiedenen Systemen korrelieren. Sie können veröffentlichte Forschungsergebnisse thematisch organisieren, um schnell relevante Informationen zu finden.
Regulatorische Regeln – Sie können komplexe regulatorische Anforderungen als Graphen speichern und diese abfragen, um Situationen zu erkennen, in denen sie für Ihren täglichen Geschäftsbetrieb gelten könnten.
-
Netzwerktopologie und Ereignisse – Eine Graphdatenbank kann Ihnen bei der Verwaltung und dem Schutz eines IT-Netzwerks helfen. Wenn Sie die Netzwerktopologie als Graph speichern, können Sie auch viele verschiedene Arten von Ereignissen im Netzwerk speichern und verarbeiten. Sie können beispielsweise Fragen beantworten, auf wie vielen Hosts eine bestimmte Anwendung ausgeführt wird. Sie können nach Mustern suchen, die darauf hinweisen könnten, dass ein bestimmter Host durch ein Schadprogramm kompromittiert wurde, und Verbindungsdaten abfragen, anhand derer das Programm bis zu dem ursprünglichen Host, der es heruntergeladen hat, zurückverfolgt werden kann.
Wie fragt man einen Graphen ab?
Neptune unterstützt drei spezielle Abfragesprachen, die für die Abfrage von Graphdaten verschiedener Art entwickelt wurden. Sie können diese Sprachen verwenden, um Daten in einer Neptune-Graphdatenbank hinzuzufügen, zu ändern, zu löschen und abzufragen:
-
Gremlin ist eine Sprache für Graph-Transversalen für Eigenschaftsgraphen. Eine Abfrage in Gremlin ist eine Transversale, die aus verschiedenen Schritten besteht. Jeder Schritt folgt einem Edge zu einem Knoten. Weitere Informationen finden Sie in der Gremlin-Dokumentation TinkerPop bei Apache
. Die Neptune-Implementierung von Gremlin weist einige Unterschiede zu anderen Implementierungen auf, insbesondere wenn Sie Gremlin-Groovy (Gremlin-Abfragen, die als serialisierter Text gesendet werden) verwenden. Weitere Informationen finden Sie unter Einhaltung der Gremlin-Standards in Amazon Neptune.
-
openCypher – openCypher ist eine deklarative Abfragesprache für Eigenschaftsdiagramme. Ursprünglich von Neo4j entwickelt, wurde sie 2015 als Open-Source-Software veröffentlicht und ist unter einer Apache 2-Open-Source-Lizenz für das openCypher
-Projekt verfügbar. Siehe die Referenz zur Cypher Query Language (Version 9) für die Sprachspezifikation sowie den Cypher Style Guide für weitere Informationen. -
SPARQL ist eine deklarative Abfragesprache für RDF
-Daten, basierend auf dem durch das World Wide Web Consortium (W3C) standardisierten Graph-Musterabgleich. Eine Beschreibung finden Sie in der Spezifikation SPARQL 1.1 – Übersicht ) und SPARQL 1.1 Abfragesprache . Spezifische Informationen zur Neptune-Implementierung von SPARQL finden Sie unter Einhaltung von SPARQL-Standards in Amazon Neptune.
Beispiele für passende Gremlin- und SPARQL-Abfragen
Anhand des folgenden Grafen von Personen (Knoten) und ihrer Beziehungen (Edges), können Sie feststellen, wer die Freunde von Freunden einer bestimmten Person sind, beispielsweise wer die Freunde von Howards Freunden sind.
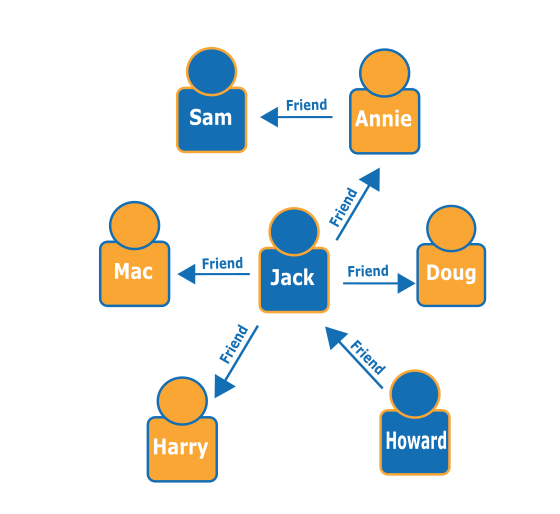
Wenn Sie sich den Graphen ansehen, erkennen Sie, dass Howard einen Freund namens Jack hat und Jack mit den vier Personen Annie, Harry, Doug und Mac befreundet ist. Dies ist ein einfaches Beispiel für einen einfachen Graphen. Diese Arten von Abfragen können aber an Komplexität, Datensatzgröße und Ergebnismenge zunehmen.
Im Folgenden finden Sie eine Gremlin-Transversal-Abfrage, die die Namen der Freunde von Howards Freunden zurückgibt.
g.V().has('name', 'Howard').out('friend').out('friend').values('name')
Im Folgenden finden Sie eine SPARQL-Abfrage, die die Namen der Freunde von Howards Freunden zurückgibt.
prefix : <#> select ?names where { ?howard :name "Howard" . ?howard :friend/:friend/:name ?names . }
Anmerkung
Jedem Teil eines Resource Description Framework (RDF)-Tripels ist ein URI zugeordnet. In diesem Beispiel ist das URI-Präfix absichtlich kurz.
Nehmen Sie an einem Online-Kurs zur Nutzung von Amazon Neptune teil
Wenn Sie gerne mit Videos lernen, AWS bietet Ihnen die Online-Tech-Talks Online-Kurse an, die Ihnen den Einstieg erleichtern AWS .
Einführung zu Graphdatenbanken, detaillierte Informationen und Demo mit Amazon Neptune
Eingehendere Informationen zur Graph-Referenzarchitektur
Wenn Sie darüber nachdenken, welche Probleme eine Graphdatenbank für Sie lösen könnte und wie Sie sie angehen können, ist das Neptune Graph Reference GitHub Architectures
Dort finden Sie detaillierte Beschreibungen der Graph-Workload-Typen sowie drei Abschnitte, die Ihnen beim Entwerfen einer effektiven Graphdatenbank helfen:
Datenmodelle und Abfragesprachen
– Dieser Abschnitt führt Sie durch die Unterschiede zwischen Gremlin und SPARQL und zeigt Ihnen, wie Sie zwischen ihnen wählen können. Graphdatenmodellierung
– Dies ist eine gründliche Darlegung dazu, wie Entscheidungen bei der Graphdatenmodellierung getroffen werden können, einschließlich detaillierter Anleitungen zur Modellierung von Eigenschaftsgraphen mit Gremlin und zur RDF-Modellierung mit SPARQL. Konvertierung anderer Datenmodelle in ein Graphmodell
– Hier erfahren Sie, wie Sie ein relationales Datenmodell in ein Graphmodell übersetzen können.
Es gibt auch drei Abschnitte, die Sie durch die spezifischen Schritte zur Verwendung von Neptune führen:
Herstellen einer Verbindung zu Amazon Neptune von Clients außerhalb der Neptune-VPC aus
– In diesem Abschnitt finden Sie verschiedene Optionen für die Verbindung mit Neptune von außerhalb der VPC aus, in der sich Ihr DB-Cluster befindet. Zugriff auf Amazon Neptune von AWS Lambda Functions aus
— Hier erfahren Sie, wie Sie über Lambda Functions eine zuverlässige Verbindung zu Neptune herstellen können. Schreiben zu Amazon Neptune von einem Amazon Kinesis Data Stream aus
– Dieser Abschnitt kann Ihnen helfen, Szenarien mit hohem Schreibdurchsatz mit Neptune zu bewältigen.
