Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Überblick über die Verwendung des Features Neptune ML
Die Neptune ML-Funktion in Amazon Neptune bietet einen optimierten Arbeitsablauf für die Nutzung von Modellen für maschinelles Lernen in einer Graphdatenbank. Der Prozess umfasst mehrere wichtige Schritte: das Exportieren von Daten aus Neptune in das CSV-Format, die Vorverarbeitung der Daten, um sie für das Modelltraining vorzubereiten, das maschinelle Lernmodell mit Amazon SageMaker AI zu trainieren, einen Inferenzendpunkt für Vorhersagen zu erstellen und dann das Modell direkt aus Gremlin-Abfragen abzufragen. Die Neptune Workbench bietet praktische Befehle für Linien- und Zellenmagie, mit denen Sie diese Schritte verwalten und automatisieren können. Durch die direkte Integration von Funktionen für maschinelles Lernen in die Graphdatenbank ermöglicht Neptune ML Benutzern, anhand der umfangreichen relationalen Daten, die im Neptun-Diagramm gespeichert sind, wertvolle Erkenntnisse abzuleiten und Vorhersagen zu treffen.
Starten des Workflows für die Verwendung von Neptune ML
Die Verwendung des Features Neptune ML in Amazon Neptune umfasst in der Regel zunächst die folgenden fünf Schritte:
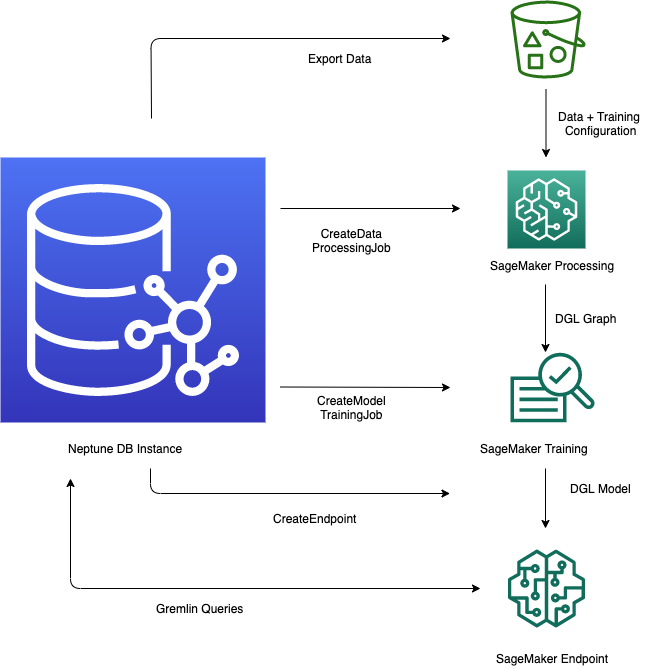
-
Datenexport und Konfiguration – Beim Datenexport werden mithilfe des Service Neptune-Export oder des
neptune-export-Befehlszeilen-Tools Daten aus Neptune im CSV-Format in Amazon Simple Storage Service (Amazon S3) exportiert. Gleichzeitig wird automatisch eine Konfigurationsdatei mit dem Namentraining-data-configuration.jsongeneriert, in der angegeben ist, wie die exportierten Daten in ein trainierbares Diagramm geladen werden können. -
Datenvorverarbeitung – In diesem Schritt wird der exportierte Datensatz mithilfe von Standardverfahren vorverarbeitet, um ihn für das Modelltraining vorzubereiten. Für numerische Daten kann eine Merkmalsnormalisierung durchgeführt und Textmerkmale können mit
word2veccodiert werden. Am Ende dieses Schritts wird aus dem exportierten Datensatz ein DGL-Diagramm (Deep Graph Library) generiert, das während des Modelltrainings verwendet wird.Dieser Schritt wird mithilfe eines SageMaker KI-Verarbeitungsauftrags in Ihrem Konto implementiert, und die resultierenden Daten werden an einem von Ihnen angegebenen Amazon S3 S3-Standort gespeichert.
-
Modelltraining – Beim Modelltraining wird das Machine-Learning-Modell trainiert, das für Prognosen verwendet wird.
Das Modelltraining erfolgt in zwei Phasen:
In der ersten Phase wird mithilfe eines SageMaker KI-Verarbeitungsauftrags ein Konfigurationssatz für die Modelltrainingsstrategie generiert, der festlegt, welcher Modelltyp und welche Modell-Hyperparameterbereiche für das Modelltraining verwendet werden.
In der zweiten Phase werden dann mithilfe eines SageMaker KI-Modeltuning-Jobs verschiedene Hyperparameter-Konfigurationen ausprobiert und der Trainingsjob ausgewählt, der das Modell mit der besten Leistung hervorgebracht hat. Der Optimierungsauftrag führt eine vordefinierte Anzahl von Modelloptimierungsaufträgen mit den verarbeiteten Daten durch. Am Ende dieser Phase werden die trainierten Modellparameter des besten Trainingsauftrags verwendet, um Modellartefakte für Inferenzen zu generieren.
-
Erstellen Sie einen Inferenzendpunkt in Amazon SageMaker AI — Der Inferenzendpunkt ist eine SageMaker KI-Endpunkt-Instance, die mit den Modellartefakten gestartet wird, die durch den besten Trainingsjob erzeugt wurden. Jedes Modell ist an einen einzelnen Endpunkt gebunden. Der Endpunkt ist in der Lage, eingehende Anfragen von der Graphdatenbank anzunehmen und die Modellvorhersagen für die Eingaben in den Anfragen zurückzugeben. Nach der Erstellung des Endpunkts bleibt dieser aktiv, bis Sie ihn löschen.
Abfragen des Machine-Learning-Modells mithilfe von Gremlin – Sie können Erweiterungen der Gremlin-Abfragesprache verwenden, um Prognosen vom Inferenzendpunkt abzufragen.
Anmerkung
Die Neptune-Workbench enthält ein Line-Magic und ein Zell-Magic, mit denen Sie bei der Verwaltung dieser Schritte viel Zeit sparen können, nämlich:
