Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Vous pouvez utiliser le connecteur de données Amazon Athena pour le métastore Hive externe afin d'interroger les jeux de données Simple Storage Service (Amazon S3) qui utilisent un métastore Apache Hive. Aucune migration des métadonnées vers le AWS Glue Data Catalog n'est nécessaire. Dans la console de gestion Athena, vous configurez une fonction Lambda pour communiquer avec le métastore Hive qui se trouve dans votre VPC privé, puis vous la connectez au métastore. La connexion de Lambda à votre métastore Hive est sécurisée par un canal privé Amazon VPC et n'utilise pas l'internet public. Vous pouvez fournir votre propre code de fonction Lambda ou utiliser l'implémentation par défaut du connecteur de données Athena pour le métastore Hive externe.
Rubriques
Présentation des fonctions
Avec le connecteur de données Athena pour métastore Hive externe, vous pouvez effectuer les tâches suivantes :
-
Utiliser la console Athena pour enregistrer des catalogues personnalisés et exécuter des requêtes à l'aide de ceux-ci.
-
Définir des fonctions Lambda pour différents métastores externes de Hive et les joindre dans des requêtes Athena.
-
Utilisez les métastores Hive AWS Glue Data Catalog et vos métastores externes dans la même requête Athena.
-
Spécifiez un catalogue dans le contexte d'exécution de requête en tant que catalogue par défaut actuel. Cela supprime la nécessité de préfixer les noms de catalogue aux noms de base de données dans vos requêtes. Au lieu d'utiliser la syntaxe
catalog.database.tabledatabase.table -
Utilisez une variété d'outils pour exécuter des requêtes qui font référence aux métastores Hive externes. Vous pouvez utiliser la console Athena, le AWS CLI AWS SDK, Athena et les pilotes JDBC APIs et ODBC Athena mis à jour. Les pilotes mis à jour prennent en charge les catalogues personnalisés.
Prise en charge de l'API
Le connecteur de données Athena pour le métastore Hive externe comprend la prise en charge des opérations d'API d'enregistrement du catalogue et des opérations de l'API de métadonnées.
-
Enregistrement de catalogue – Enregistrez les catalogues personnalisés pour les métastores Hive externes et les sources de données fédérées.
-
Métadonnées : utilisez les métadonnées APIs pour fournir des informations de base de données AWS Glue et de table pour tout catalogue que vous enregistrez auprès d'Athena.
-
Client Athena JAVA SDK : utilisez l'enregistrement du catalogue APIs, les métadonnées APIs et la prise en charge des catalogues dans le cadre du
StartQueryExecutionfonctionnement du client Athena Java SDK mis à jour.
Implémentation de référence
Athena fournit une implémentation de référence pour la fonction Lambda qui se connecte aux métastores Hive externes. L'implémentation de référence est fournie sous GitHub forme de projet open source sur le metastore Athena Hive
L'implémentation de référence est disponible sous la forme AWS SAM des deux applications suivantes dans le AWS Serverless Application Repository (SAR). Vous pouvez utiliser l'une de ces applications dans le SAR pour créer vos propres fonctions Lambda.
-
AthenaHiveMetastoreFunction– Fichier.jarde fonction Lambda uber. Un JAR « uber » (également connu sous le nom de gros JAR ou JAR avec dépendances) est un fichier.jarqui contient à la fois un programme Java et ses dépendances dans un seul fichier. -
AthenaHiveMetastoreFunctionWithLayer– Couche Lambda et fichier.jarde fonction Lambda mince.
Flux de travail
Le diagramme suivant montre comment Athena interagit avec votre métastore Hive externe.
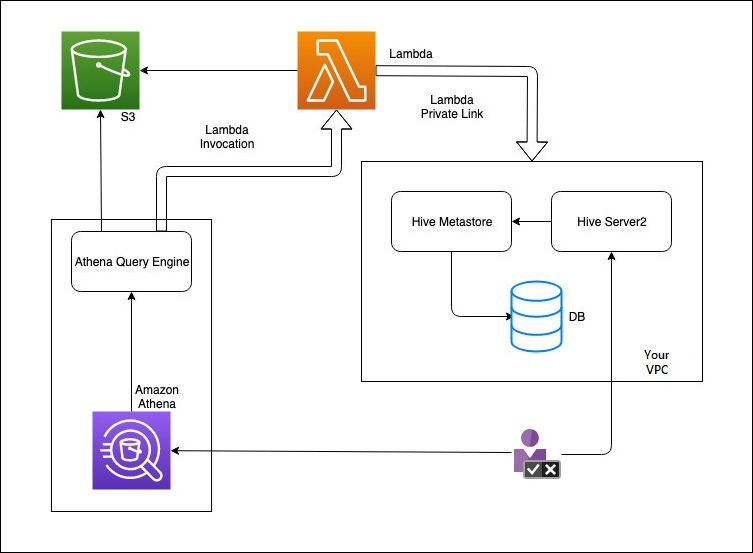
Dans ce flux de travail, votre métastore Hive connecté à une base de données se trouve à l'intérieur de votre VPC. Vous utilisez Hive Server2 pour gérer votre métastore Hive à l'aide de la CLI Hive.
Le flux de travail permettant d'utiliser des métastores Hive externes depuis Athena inclut les étapes suivantes.
-
Vous créez une fonction Lambda qui connecte Athena au métastore Hive se trouvant à l'intérieur de votre VPC.
-
Vous enregistrez un nom de catalogue unique pour votre métastore Hive et un nom de fonction correspondant dans votre compte.
-
Lorsque vous exécutez une requête DML ou DDL Athena qui utilise le nom du catalogue, le moteur de requête Athena appelle le nom de fonction Lambda que vous avez associé au nom du catalogue.
-
À l'aide de AWS PrivateLink, la fonction Lambda communique avec le métastore Hive externe de votre VPC et reçoit des réponses aux demandes de métadonnées. Athena utilise les métadonnées de votre métastore Hive externe tout comme il utilise les métadonnées du AWS Glue Data Catalog par défaut.
Considérations et restrictions
Lorsque vous utilisez le connecteur de données Athena pour le métastore Hive externe, tenez compte des points suivants :
-
Vous pouvez utiliser l'instruction CTAS pour créer une table sur un métastore Hive externe.
-
Vous pouvez utiliser l'instruction INSERT INTO pour insérer des données dans un métastore Hive externe.
-
La prise en charge DDL pour le métastore Hive externe est limitée aux instructions suivantes.
-
ALTER DATABASE SET DBPROPERTIES
-
ALTER TABLE ADD COLUMNS
-
ALTER TABLE ADD PARTITION
-
ALTER TABLE DROP PARTITION
-
ALTER TABLE RENAME PARTITION
-
ALTER TABLE REPLACE COLUMNS
-
ALTER TABLE SET LOCATION
-
ALTER TABLE SET TBLPROPERTIES
-
CREATE DATABASE
-
CREATE TABLE
-
CREATE TABLE AS
-
DESCRIBE TABLE
-
DROP DATABASE
-
DROP TABLE
-
SHOW COLUMNS
-
SHOW CREATE TABLE
-
SHOW PARTITIONS
-
SHOW SCHEMAS
-
SHOW TABLES
-
SHOW TBLPROPERTIES
-
-
Le nombre maximal de catalogues enregistrés que vous pouvez avoir est de 1 000.
-
L'authentification Kerberos pour le métastore Hive n'est pas prise en charge.
-
Pour utiliser le pilote JDBC avec un metastore Hive externe ou des requêtes fédérées, incluez
MetadataRetrievalMethod=ProxyAPIdans votre chaîne de connexion JDBC. Pour plus d'informations sur le pilote JDBC, voir Connectez-vous à Amazon Athena avec JDBC. -
Les colonnes cachées
$path,$bucket,$file_size,$file_modified_time,$partition,$row_idde Hive ne peuvent pas être utilisées pour le filtrage du contrôle d'accès précis. -
Les tables cachées du système Hive comme
example_table$partitionsexample_table$properties
Autorisations
Les connecteurs de données prédéfinis et personnalisés peuvent nécessiter l'accès aux ressources suivantes pour fonctionner correctement. Vérifiez les informations relatives au connecteur que vous utilisez pour vous assurer que vous avez correctement configuré votre VPC. Pour de plus amples informations sur les autorisations IAM requises pour exécuter des requêtes et créer un connecteur de source de données dans Athena, voir Autoriser l'accès au connecteur de données Athena pour le métastore Hive externe et Autorisation d'accès des fonctions Lambda aux métastores Hive externes.
-
Simple Storage Service (Amazon S3) – Outre l'écriture des résultats des requêtes dans l'emplacement des résultats des requêtes Athena dans Simple Storage Service (Amazon S3), les connecteurs de données écrivent également dans un compartiment de déversement dans Simple Storage Service (Amazon S3). Une connectivité et des autorisations d'accès à cet emplacement Simple Storage Service (Amazon S3) sont requises. Pour plus d'informations, consultez Emplacement de déversement dans Simple Storage Service (Amazon S3) plus loin dans cette rubrique.
-
Athena – L'accès est nécessaire pour vérifier l'état de la requête et empêcher le surbalayage.
-
AWS Glue— L'accès est requis si votre connecteur utilise AWS Glue des métadonnées supplémentaires ou principales.
-
AWS Key Management Service
-
Politiques — Hive Metastore, Athena Query Federation et UDFs requière des politiques en plus des. AWS politique gérée : AmazonAthenaFullAccess Pour de plus amples informations, veuillez consulter Gestion des identités et des accès dans Athena.
Emplacement de déversement dans Simple Storage Service (Amazon S3)
En raison de la limite de la taille des réponses des fonctions Lambda, les réponses supérieures au seuil sont déversées dans un emplacement Simple Storage Service (Amazon S3) que vous spécifiez lorsque vous créez votre fonction Lambda. Athena lit directement ces réponses de Simple Storage Service (Amazon S3).
Note
Athena ne supprime pas les fichiers de réponse sur Simple Storage Service (Amazon S3). Nous vous recommandons de configurer une politique de rétention pour supprimer automatiquement les fichiers de réponse.
