Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Notes de mise à jour
Décrit les fonctions, les améliorations et les corrections de bogues d'Amazon Athena par date de publication.
Notes de publication d'Athena pour 2026
6 juillet 2026
Amazon Athena publie la version 2.2.0.1 du pilote ODBC. Pour plus d’informations sur cette version du pilote, consultez Notes de mise à jour Amazon Athena ODBC 2.x. Pour télécharger le pilote ODBC 2.x, consultez Téléchargement du pilote ODBC 2.x.
1 juillet 2026
Publié le 1 juillet 2026
Amazon Athena a résolu un problème selon lequel l'interrogation d'une table via un connecteur géré ne renvoyait aucun résultat lorsque la table était partagée entre un projet producteur Amazon SageMaker Unified Studio et un projet client au sein du même compte. AWS Les connecteurs gérés résolvent désormais les références de table et de schéma partagées via la bonne source de données sous-jacente.
3 juin 2026
Amazon Athena publie la version 3.8.0 du pilote JDBC. Pour plus d’informations sur cette version du pilote, consultez Notes de mise à jour d’Amazon Athena JDBC 3.x. Pour télécharger le dernier pilote JDBC, consultez Téléchargement du pilote JDBC 3.x.
29 mai 2026
Amazon Athena publie la version 2.2.0.0 du pilote ODBC. Pour plus d’informations sur cette version du pilote, consultez Notes de mise à jour Amazon Athena ODBC 2.x. Pour télécharger le pilote ODBC 2.x, consultez Téléchargement du pilote ODBC 2.x.
12 mai 2026
Publié le 12/05/2026-05
Mises à jour et améliorations de sécurité
Nous avons mis à jour les versions des bibliothèques tierces comme suit.
-
Mis à jour
logback-coredu 1.3.15 au 1.3.16 -
Mis à jour
logback-classicdu 1.3.15 au 1.3.16 -
Mis à jour
jackson-annotationsde la version 2.16.0 à la version 2.21.2 -
Mis à jour
jackson-corede la version 2.16.0 à la version 2.21.2 -
Mis à jour
jackson-databindde la version 2.16.0 à la version 2.21.2 -
Remplacement de
NTLMl'authentification codée en dur par leNegotiateprotocole dans le flux d'authentification ADFS SAML, permettant le support de Kerberos avec repli automatiqueNTLMv2
Pour plus d’informations et pour télécharger le pilote JDBC 2.x, les notes de publication et la documentation, consultez Pilote JDBC 2.x d'Athena.
21 avril 2026
Publié le 2026-04-21
Amazon Athena propose désormais des connecteurs gérés pour 12 sources de données, notamment Amazon DynamoDB, PostgreSQL, MySQL et Snowflake. Les connecteurs gérés sont des connecteurs AWS Glue Data Catalog fédérés qu'Athena crée et gère en votre nom, afin que vous puissiez interroger des données en dehors d'Amazon S3 sans déployer ni gérer les ressources du connecteur dans AWS votre compte. Ces connecteurs sont enregistrés sous forme de catalogues fédérés dans AWS Glue Data Catalog, et vous pouvez éventuellement configurer des contrôles d'accès précis via. AWS Lake Formation Pour de plus amples informations, veuillez consulter Utilisation de la requête fédérée Amazon Athena.
27 mars 2026
Publié le 2026-03-27
Amazon Athena prend désormais en charge les réservations de capacité dans les zones commerciales suivantes Régions AWS : États-Unis Ouest (Californie du Nord), Afrique (Le Cap), Asie-Pacifique (Hong Kong), Asie-Pacifique (Hyderabad), Asie-Pacifique (Jakarta), Asie-Pacifique (Malaisie), Asie-Pacifique (Melbourne), Asie-Pacifique (Osaka), Asie-Pacifique (Séoul), Asie-Pacifique (Thaïlande), Asie-Pacifique (Taipei), Canada (Centre), Canada Ouest (Calgary), Europe (Francfort), Europe (Londres), Europe (Milan), Europe (Paris), Europe (Zurich) et Mexique (Centre).
Pour en savoir plus, consultez Gestion de la capacité de traitement des requêtes les tarifs d'Amazon Athena
20 mars 2026
Publié le 2026-03-20
Athena publie la version 2.1.0.0 du pilote ODBC. Cette version inclut des améliorations de sécurité relatives aux flux d'authentification, au traitement des requêtes et à la sécurité du transport. Nous vous recommandons de passer à cette version dès que possible. Pour plus d’informations sur cette version du pilote, consultez Notes de mise à jour Amazon Athena ODBC 2.x. Pour télécharger le pilote ODBC 2.x, consultez Téléchargement du pilote ODBC 2.x.
17 mars 2026
Publié le 2026-03-17
Athena prend désormais en charge AWS IAM-based l'autorisation pour les tables Amazon S3 et les vues matérialisées Apache Iceberg. Avec IAM-based l'autorisation, vous pouvez définir toutes les autorisations nécessaires sur les moteurs de stockage, de catalogue et de requête dans une seule stratégie IAM.
10 février 2026
Publié le 10-02-2026/
Athena annonce les fonctions et améliorations suivantes.
Amazon Athena prend désormais en charge les réservations de capacité d'une minute et la capacité minimale de 4 unités de traitement des données (DPU). Les réservations de capacité fournissent un calcul sans serveur dédié pour les charges de travail SQL interactives nécessitant une hiérarchisation des requêtes et des contrôles de simultanéité. Avec cette version, vous pouvez désormais démarrer avec moins de capacité et ajuster la capacité plus fréquemment pour qu'elle corresponde étroitement aux modèles de charge de travail variables. Pour en savoir plus, consultez le guide de l'utilisateur d'Athena.
12 janvier 2026
Publié le 12/01/2020
Amazon Athena annonce la disponibilité d'Athena SQL dans la région Asie-Pacifique (Nouvelle Zélande).
Pour une liste complète des services Services AWS disponibles dans chacun d'entre eux Région AWS, voir AWS Services par région
Notes de publication d'Athena pour 2025
30 novembre 2025
Publié le 2025-11-30
Athena annonce les fonctions et améliorations suivantes.
Amazon Athena prend désormais en charge les vues matérialisées du catalogue de AWS Glue données, un nouveau type de table de résultats de requête précalculée qui est automatiquement mise à jour à mesure que vos données changent. Les vues matérialisées du catalogue de données Glue sont stockées sous forme de tables Apache Iceberg et peuvent être interrogées à l'aide des instructions SELECT SQL Athena et d'Apache Spark version 3.5. Pour en savoir plus, voir Vues matérialisées du catalogue de AWS Glue données de requête et Utiliser des vues matérialisées.
21 novembre 2025
Publié le 21/11/2025
Athena annonce les fonctions et améliorations suivantes.
-
Amazon Athena pour Apache Spark est désormais disponible sous forme de blocs-notes. Il fournit aux ingénieurs de données, aux analystes et aux data scientists un espace de travail unifié pour interroger des données, développer des tâches, former des modèles et travailler avec l'IA. Athena pour Apache Spark fonctionne sur Spark 3.5.6 et propose de nouvelles fonctionnalités de débogage, une surveillance en temps réel via l'interface utilisateur Spark, Spark Connect pour une interaction sécurisée avec le cluster et AWS Lake Formation des contrôles d'accès au niveau des tables. Pour en savoir plus, consultez le guide de SageMaker l'utilisateur.
-
Contrôles des coûts et des performances des réservations de capacité — Vous pouvez désormais définir des limites d'utilisation de l'unité de traitement des données (DPU) au niveau du groupe de travail ou de la requête et obtenir des informations détaillées sur l'utilisation du DPU pour les requêtes que vous exécutez sur Capacity Reservations. Ces contrôles vous aident à optimiser les performances des requêtes et à gérer les coûts en contrôlant l'utilisation des ressources pour vos charges de travail SQL les plus importantes. Pour en savoir plus, veuillez consulter la section Contrôler l'utilisation des capacités.
-
Solution d'auto-scaling des réservations de capacité : vous pouvez désormais ajuster automatiquement les réservations de capacité en fonction de l'utilisation. La solution d'Athena utilise CloudFormation et Step Functions pour supprimer le besoin d'ajustements manuels de capacité, vous aidant ainsi à trouver un équilibre entre les exigences de performance et l'optimisation des coûts, et est personnalisable en fonction de différents besoins. Pour en savoir plus, veuillez consulter la section Régler automatiquement la capacité.
-
Optimisation avec les statistiques d'Iceberg : Athena a amélioré la façon dont elle utilise les statistiques d'Iceberg pour prendre des décisions intelligentes concernant l'ordre des jointures, les filtres et le comportement d'agrégation, afin d'améliorer les performances des requêtes et de réduire les coûts. Pour en savoir plus, voir Utiliser les statistiques des tables Iceberg.
-
Indexation des colonnes Iceberg Parquet — Athena prend désormais en charge l'indexation des colonnes Parquet sur les tables Iceberg pour un élagage précis des données lors de l'exécution des requêtes. Il utilise les min/max statistiques au niveau des pages pour réduire la quantité de données numérisées, améliorer les performances des requêtes et réduire les coûts, en particulier pour les requêtes utilisant des prédicats de filtre sélectifs sur des colonnes triées. Pour en savoir plus, voir Utiliser l'indexation des colonnes Parquet.
-
Améliorations des performances des icebergs grâce à Lake Formation : Athena a ajouté de nouveaux comportements d'élagage des partitions pour les tables Iceberg dotées de filtres de lignes et de masques de colonnes pour Lake Formation, ainsi que des comportements de renvoi des prédicats supplémentaires pour tous les autres types de tables dotés de filtres de ligne et de masques de colonne Lake Formation. Cette mise à jour améliore les performances des requêtes tout en maintenant les protections de sécurité.
-
Réutilisation des résultats des requêtes — Athena a amélioré la réutilisation des résultats des requêtes afin de permettre à un plus grand nombre de requêtes de bénéficier des résultats mis en cache. Athena traite désormais les requêtes sémantiquement équivalentes comme identiques, quelles que soient les différences de formatage. Les clients qui utilisent la réutilisation des résultats de requêtes bénéficieront automatiquement de taux de réussite du cache accrus, ce qui se traduira par une exécution plus rapide des requêtes et une réduction des coûts, sans aucune action requise. Pour en savoir plus, voir Réutiliser les résultats des requêtes dans Athena.
-
Fichier de lac de données amélioré SerDes — Athena a mis à niveau ses fichiers SerDes pour Parquet, JSON, CSV et texte. Cela améliore les performances et la fiabilité des requêtes tout en corrigeant les scénarios dans lesquels le précédent SerDes renvoyait des résultats non déterministes ou incorrects. Les clients bénéficieront automatiquement de ces améliorations sans qu'aucune action ne soit nécessaire, car elles sont mises à niveau sur la base des contrôles de compatibilité effectués par Athena.
-
Mise à niveau vers Hudi 0.15.0 — Vous pouvez désormais utiliser Athena pour interroger les tables Hudi 0.15.0. Pour plus d'informations, voir Interroger les ensembles de données Apache Hudi.
-
Intégration de la propagation d'identité sécurisée par navigateur — Athena a ajouté un nouveau plugin d'authentification pour prendre en charge l'intégration de la propagation d'identité sécurisée JWT avec les pilotes JDBC et ODBC. Ce type d'authentification vous permet de récupérer un jeton Web JSON (JWT) auprès d'un fournisseur d'identité externe et de vous authentifier auprès d'Athena. Pour de plus amples informations, veuillez consulter Utilisation de la propagation d’identité de confiance avec les pilotes Amazon Athena.
-
Pilote JDBC 3.7.0 — Athena publie la version 3.7.0 du pilote JDBC. Pour plus d’informations sur cette version du pilote, consultez Notes de mise à jour d’Amazon Athena JDBC 3.x. Pour télécharger le dernier pilote JDBC, consultez Téléchargement du pilote JDBC 3.x.
-
Pilote ODBC 2.0.6.0 — Athena publie la version 2.0.6.0 du pilote ODBC. Pour plus d’informations sur cette version du pilote, consultez Notes de mise à jour Amazon Athena ODBC 2.x. Pour télécharger le dernier pilote JDBC, consultez Téléchargement du pilote ODBC 2.x.
13 octobre 2025
Date de publication : 13/10/2025
Athena publie la version 2.0.5.1 du pilote ODBC. Pour plus d’informations sur cette version du pilote, consultez Notes de mise à jour Amazon Athena ODBC 2.x. Pour télécharger le pilote ODBC 2.x, consultez Téléchargement du pilote ODBC 2.x.
19 septembre 2025
Date de publication : 19/09/2025
Amazon Athena ajoute les méthodes d’authentification par paire de clés et OAuth pour le connecteur Amazon Athena pour Snowflake. Ces méthodes d’authentification remplacent la méthode d’authentification par nom d’utilisateur et mot de passe que Snowflake prévoit de désactiver d’ici novembre 2025. Pour plus d’informations sur la configuration des nouvelles méthodes d’authentification, consultez Authentification auprès de Snowflake.
10 septembre 2025
Date de publication : 10/09/2025
Athena annonce les fonctions et améliorations suivantes.
Intégration de la propagation d’identité de confiance basée sur un JWT
Athena a ajouté un nouveau plug-in d’authentification pour prendre en charge l’intégration de la propagation d’identité de confiance basée sur un JWT aux pilotes JDBC et ODBC. Ce type d’authentification vous permet d’utiliser un jeton Web JSON (JWT) obtenu auprès d’un fournisseur d’identité externe comme paramètre de connexion pour vous authentifier auprès d’Athena. Pour plus d’informations, consultez Utilisation de la propagation d’identité de confiance avec les pilotes Amazon Athena.
Pilote ODBC 2.0.5.0
Athena publie la version 2.0.5.0 du pilote ODBC. Pour plus d’informations sur cette version du pilote, consultez Notes de mise à jour Amazon Athena ODBC 2.x. Pour télécharger le dernier pilote JDBC, consultez Téléchargement du pilote ODBC 2.x.
Pilote JDBC 3.6.0
Athena publie la version 3.6.0 du pilote JDBC. Pour plus d’informations sur cette version du pilote, consultez Notes de mise à jour d’Amazon Athena JDBC 3.x. Pour télécharger le dernier pilote JDBC, consultez Téléchargement du pilote JDBC 3.x.
05 septembre 2025
Date de publication : 05/09/2025
Athena annonce les fonctions et améliorations suivantes.
Pilote JDBC 2.2.2
Publication du pilote JDBC 2.2.2 pour Athena.
Mises à jour et corrections de bogues
Nous avons mis à jour les versions des bibliothèques tierces comme suit.
-
Mise à jour de
commons-codecde la version 1.15 à 1.18.0 -
Mise à jour de
commons-csvde la version 1.8 à 1.14.0 -
Mise à jour de
commons-loggingde la version 1.2 à 1.3.5 -
Mise à jour du composant Log4j vers la version 2.24.3.
Corrections de bugs
-
Correction d’une erreur qui se produisait dans le connecteur lorsqu’une valeur nulle était transmise au paramètre
loginToRplors de l’authentification ADFS.
Pour plus d’informations et pour télécharger le pilote JDBC 2.x, les notes de publication et la documentation, consultez Pilote JDBC 2.x d'Athena.
15 août 2025
Date de publication : 15/08/2025
Athena annonce les fonctions et améliorations suivantes.
Requêtes CREATE TABLE AS SELECT (CTAS) pour les tables S3 : Athena prend désormais en charge les requêtes CREATE TABLE AS SELECT (CTAS) pour les tables S3. Pour de plus amples informations, veuillez consulter Création de tables S3 dans Athena.
Suppression de la prise en charge des statistiques des tables Iceberg héritées : nous avons supprimé la prise en charge du suivi des statistiques des tables Iceberg héritées dans Athena. Si vous disposez de tables écrites avant le 7 mai 2023, vous devez les réanalyser.
11 août 2025
Date de publication : 11/08/2025
Athena annonce les corrections et améliorations suivantes :
-
Nous avons modifié le comportement de
lead()etlag()en matière de gestion des décalagesNULL. Avant cette modification, le transfert d’un décalageNULLverslead()etlag()aurait généréNULLen sortie. Désormais, Athena renvoie l’erreur Offset must not be null.Cette modification a été apportée pour rendre le comportement conforme aux normes SQL et pour éviter des résultats
NULLinattendus à la sortie en les empêchant de manière proactive à l’entrée. Grâce à cette erreur, il est conseillé de ne pas transférerNULLen tant que décalage verslead()etlag(). Bien que cela ne soit pas recommandé, vous pouvez conserver l’ancien comportement en le réécrivant comme indiqué dans l’exemple suivant :Modèle de requête d’origine
lead(column1, column_containing_nulls) OVER (...) as transformedModèle de requête mis à jour
CASE WHEN column_containing_nulls IS NULL THEN NULL ELSE (lead(column1, coalesce(column_containing_nulls, 1)) OVER (...)) END as transformed
17 juillet 2025
Date de publication : 17/07/2025
Athena publie la version 3.5.1 du pilote JDBC. Pour plus d’informations sur cette version du pilote, consultez Notes de mise à jour d’Amazon Athena JDBC 3.x. Pour télécharger le dernier pilote JDBC, consultez Téléchargement du pilote JDBC 3.x.
30 juin 2025
Date de publication : 30/06/2025
Amazon Athena annonce la disponibilité d’Athena SQL dans la région Asie-Pacifique (Taipei).
Pour une liste complète des services Services AWS disponibles dans chacun d'entre eux Région AWS, voir AWS Services par région
17 juin 2025
Date de publication : 17/06/2024
Athena publie la version 2.0.4.0 du pilote ODBC. Pour plus d’informations sur cette version du pilote, consultez Notes de mise à jour Amazon Athena ODBC 2.x. Pour télécharger le pilote ODBC 2.x, consultez Téléchargement du pilote ODBC 2.x.
3 juin 2025
Date de publication : 03/06/2025
Athena présente la nouvelle fonctionnalité de gestion des résultats des requêtes, qui stocke, sécurise et gère automatiquement et gratuitement les données des résultats de requête pour vous. La fonctionnalité de gestion des résultats des requêtes vous aide à vous lancer en moins d’étapes, en évitant d’avoir à utiliser des compartiments Amazon S3 pour stocker les résultats de requête et pour nettoyer les processus afin de supprimer les résultats des requêtes dont vous n’avez plus besoin. Les résultats des requêtes gérées sont généralement disponibles dans toutes les régions où Athena est disponible
Lorsque vous utilisez la fonctionnalité de gestion des résultats des requêtes, vous pouvez continuer à accéder aux résultats des requêtes via les mêmes interfaces qu’avec le stockage des compartiments S3 traditionnel. Pour commencer, utilisez le AWS Management Console AWS SDK ou configurez vos groupes de travail nouveaux ou existants AWS CLI afin d'utiliser les résultats des requêtes gérées. Pour de plus amples informations, veuillez consulter Résultats de requêtes gérés.
27 mai 2025
Date de publication : 27/05/2025
Athena annonce les corrections et améliorations suivantes :
Amélioration des messages d’erreur concernant les tables de métadonnées Delta Lake : nous avons amélioré les messages d’erreur concernant les tables de métadonnées Delta Lake et fournissons désormais des informations plus claires lorsque vous essayez d’interroger ces tables non prises en charge.
14 mai 2025
Date de publication : 14/05/2025
Athena annonce les corrections et améliorations suivantes :
Nous avons résolu un problème qui pouvait entraîner la création de fichiers ORC avec des tailles de fichier supérieures à celles prévues.
-
Amélioration des performances des analyses sur les tables Delta Lake qui utilisent des points de contrôle v2.
18 avril 2025
Date de publication : 18/04/2025
Athena annonce les corrections et améliorations suivantes :
Suivi des réserves de capacité : nous avons résolu un problème dans notre système de suivi des réserves de capacité, problème en raison duquel les réserves n’étaient pas correctement publiées dans le cadre de scénarios d’annulation de requête, notamment après la planification d’une requête et avant le recrutement d’effectifs par Athena pour exécuter les requêtes. La correction permet au moteur de requêtes Athena de publier la réserve de capacité de façon explicite lorsque le scénario ci-dessus se produit.
16 avril 2025
Date de publication : 16/04/2025
Amazon Athena annonce la disponibilité d’Athena SQL dans les régions Asie-Pacifique (Thaïlande) et Mexique (Centre).
Pour une liste complète des services Services AWS disponibles dans chacun d'entre eux Région AWS, voir AWS Services par région
9 avril 2025
Date de publication : 09/04/2025
Athena annonce les fonctions et améliorations suivantes.
Pilote JDBC 2.2.1
Publication du pilote JDBC 2.2.1 pour Athena.
Mises à jour et améliorations :
-
Mise à jour des bibliothèques Logback pour utiliser la version 1.3.15.
Pour plus d’informations et pour télécharger le pilote JDBC 2.x, les notes de publication et la documentation, consultez Pilote JDBC 2.x d'Athena.
18 mars 2025
Date de publication : 18/03/2025
Athena publie la version 3.5.0 du pilote JDBC. Pour plus d’informations sur cette version du pilote, consultez Notes de mise à jour d’Amazon Athena JDBC 3.x. Pour télécharger le dernier pilote JDBC, consultez Téléchargement du pilote JDBC 3.x.
14 mars 2025
Date de publication : 14/03/2025
Amazon Athena propose des fonctionnalités permettant de créer et d’interroger des opérations de table directement depuis la console S3.
Pour de plus amples informations, veuillez consulter Enregistrement de catalogues de compartiment de table S3 et interrogation de tables à partir d’Athena.
07 mars 2025
Date de publication : 07/03/2025
La capacité provisionnée est désormais globalement disponible dans la région Asie-Pacifique (Mumbai). La capacité provisionnée permet d’exécuter des requêtes SQL sur une capacité de calcul entièrement gérée et fournit des fonctions de gestion des charges de travail qui vous aident à prioriser, contrôler et mettre à l’échelle vos charges de travail interactives les plus importantes. Vous pouvez ajouter une capacité à tout moment pour augmenter le nombre de requêtes que vous pouvez exécuter simultanément, contrôler les charges de travail utilisant cette capacité et partager la capacité entre les charges de travail.
Pour de plus amples informations, veuillez consulter Gestion de la capacité de traitement des requêtes. Pour obtenir des informations sur la tarification, consultez la page Tarification Amazon Athena
18 février 2025
Date de publication : 18/02/2025
Athena publie la version 3.4.0 du pilote JDBC. Pour plus d’informations sur cette version du pilote, consultez Notes de mise à jour d’Amazon Athena JDBC 3.x. Pour télécharger le dernier pilote JDBC, consultez Téléchargement du pilote JDBC 3.x.
22 janvier 2025
Date de publication : 22/01/2025
Athena prend désormais en charge les requêtes fédérées via Lambda et le chiffrement des résultats des requêtes à l’aide de KMS sur les groupes de travail compatibles TIP. Pour de plus amples informations, veuillez consulter Utilisation de groupes de travail Athena compatibles avec IAM Identity Center.
Notes de publication d'Athena pour 2024
17 décembre 2024
Date de publication : 17/12/2024
Amazon Athena annonce la disponibilité d’Athena SQL dans la région Asie-Pacifique (Malaisie).
Pour une liste complète des services Services AWS disponibles dans chacun d'entre eux Région AWS, voir AWS Services par région
16 décembre 2024
Date de publication : 16/12/2024
Correction des vecteurs de suppression : correction d’un problème lié aux vecteurs de suppression, problème en raison duquel les tables partitionnées renvoyaient des résultats incorrects dans le connecteur Delta Lake.
3 décembre 2024
Date de publication : 03/12/2024
Athena annonce les fonctions et améliorations suivantes.
-
Connexions aux sources de données : Amazon Athena annonce une console et un flux de travail d’API rationalisés dans le cadre de la création des connexions aux sources de données. Vous pouvez désormais créer et gérer entièrement les connexions de données Athena dans la console Athena, et les propriétés de vos connexions sont désormais stockées de manière centralisée dans le AWS Glue Data Catalog.
Le stockage des propriétés de connexion vous AWS Glue permet de réutiliser les connexions dans d'autres AWS services. Par exemple, après avoir configuré un connecteur Athena pour Amazon DynamoDB, vous pouvez réutiliser les propriétés et les autorisations que vous avez spécifiées pour la connexion pour AWS Glue une tâche ETL qui accède à vos données dans DynamoDB. Pour plus d'informations, consultez Utilisation de la console Athena pour se connecter à une source de données le guide de l'utilisateur Amazon Athena et le manuel de référence CreateDataCatalogdes API Amazon Athena.
-
Interrogation des données Redshift enregistrées dans le AWS Glue Data Catalog : Athena prend désormais en charge la lecture et l’écriture dans les tables Redshift enregistrées dans le Catalogue de données Glue. Pour de plus amples informations, veuillez consulter Enregistrement de catalogues de données Redshift dans Athena.
-
Interrogation des tables S3 à partir d’Athena : les compartiments de table S3 sont un type de compartiment dans Amazon S3 spécialement conçu pour stocker des données tabulaires dans des tables Apache Iceberg. Athena prend désormais en charge les requêtes DQL et DML sur les tables S3. Pour de plus amples informations, veuillez consulter Enregistrement de catalogues de compartiment de table S3 et interrogation de tables à partir d’Athena.
30 octobre 2024
Date de publication : 30/10/2024
Athena publie la version 3.3.0 du pilote JDBC. Pour plus d’informations sur cette version du pilote, consultez Notes de mise à jour d’Amazon Athena JDBC 3.x. Pour télécharger le pilote JDBC 3.x, veuillez consulter Téléchargement du pilote JDBC 3.x.
23 août 2024
Date de publication : 05/09/2024
Athena annonce les changements suivants :
-
Interrogation de vues fédérées à l’aide de requêtes de transmission : les requêtes de transmission fédérées sont désormais prises en charge dans le cadre des vues. Pour de plus amples informations, veuillez consulter Interrogation de vues fédérées.
-
Requêtes de transmission multiples : vous pouvez désormais exécuter plusieurs requêtes de transmission fédérées au cours de la même exécution de requêtes. Pour de plus amples informations, veuillez consulter Utilisation des requêtes de transmission fédérées.
-
Correction de la requête OPTIMIZE de la table Iceberg : correction d’un problème en raison duquel l’exécution de
OPTIMIZEsur une table Iceberg ne supprimait pas les fichiers « delete » lors de la réécriture de fichiers de données auxquels un fichier delete était associé. Pour de plus amples informations, veuillez consulter OPTIMIZE. -
Prise en charge de l’écriture de fichiers Parquet aux formats LZ4 et LZO : Athena ne prend plus en charge l’écriture de fichiers Parquet compressés aux formats LZ4 ou LZO. La lecture de ces formats de compression est toujours prise en charge. Pour plus d’informations sur les formats de compression dans Athena, consultez Utilisation de la compression dans Athena.
29 juillet 2024
Date de publication : 29/07/2024
Athena publie la version 3.2.2 du pilote JDBC. Pour plus d’informations sur cette version du pilote, consultez Notes de mise à jour d’Amazon Athena JDBC 3.x. Pour télécharger le pilote JDBC 3.x, veuillez consulter Téléchargement du pilote JDBC 3.x.
26 juillet 2024
Date de publication : 01/08/2024
Athena annonce l’amélioration suivante.
-
Prise en charge des vecteurs de suppression des tables Delta Lake : Athena prend désormais en charge la lecture à partir de tables Delta Lake avec vecteurs de suppression
. Pour de plus amples informations, veuillez consulter Interrogation des tables Linux Foundation Delta Lake.
3 juillet 2024
Date de publication : 03/07/2024
Athena publie la version 3.2.1 du pilote JDBC. Pour plus d’informations sur cette version du pilote, consultez Notes de mise à jour d’Amazon Athena JDBC 3.x. Pour télécharger le pilote JDBC 3.x, veuillez consulter Téléchargement du pilote JDBC 3.x.
26 juin 2024
Date de publication : 26/06/2024
La capacité provisionnée est désormais globalement disponible dans les régions Amérique du Sud (São Paulo) et Europe (Espagne). La capacité provisionnée permet d’exécuter des requêtes SQL sur une capacité de calcul entièrement gérée et fournit des fonctions de gestion des charges de travail qui vous aident à prioriser, contrôler et mettre à l’échelle vos charges de travail interactives les plus importantes. Vous pouvez ajouter une capacité à tout moment pour augmenter le nombre de requêtes que vous pouvez exécuter simultanément, contrôler les charges de travail utilisant cette capacité et partager la capacité entre les charges de travail.
Pour de plus amples informations, veuillez consulter Gestion de la capacité de traitement des requêtes. Pour obtenir des informations sur la tarification, consultez la page Tarification Amazon Athena
10 mai 2024
Date de publication : 15/07/2024
Athena annonce les fonctions et améliorations suivantes.
-
Delta Lake : Athena a ajouté des optimisations qui filtrent les entrées inutiles des fichiers de points de contrôle. Ces optimisations permettent d’améliorer sensiblement les performances des requêtes qui comportent des fichiers de points de contrôle volumineux référençant de nombreux fichiers de données Parquet.
Pour plus d’informations sur l’utilisation des tables Linux Foundation Delta Lake avec Athena, consultez Interrogation des tables Linux Foundation Delta Lake.
26 avril 2024
Date de publication : 26/04/2024
Athena publie la version 3.2.0 du pilote JDBC. Pour plus d’informations sur cette version du pilote, consultez Notes de mise à jour d’Amazon Athena JDBC 3.x. Pour télécharger le pilote JDBC 3.x, veuillez consulter Téléchargement du pilote JDBC 3.x.
24 avril 2024
Date de publication : 24/04/2024
Athena annonce les correctifs et améliorations suivants.
-
Parquet : Athena prend désormais en charge la lecture rétrocompatible dans Parquet pour les champs primitifs répétés et non annotés qui ne figurent pas dans une liste ou un groupe de mappage. Cette modification empêche de façon silencieuse le renvoi de résultats incorrects et améliore les messages d’erreur en cas d’incohérence entre les schémas.
Pour plus d'informations, voir Support des lectures rétrocompatibles pour les champs primitifs répétés non annotés dans
Parquet on. GitHub.com -
OPTIMIZE pour Iceberg : résolution d’un problème lié aux requêtes
OPTIMIZEqui entraînait la perte de données lorsqu’un filtre d’une clé autre qu’une clé de partition était utilisé dans une clauseWHERE. Pour de plus amples informations, veuillez consulter OPTIMIZE.
16 avril 2024
Date de publication : 16/04/2024
Utilisez la nouvelle fonctionnalité de transmission dans les requêtes fédérées Amazon Athena pour exécuter des requêtes complètes directement sur la source de données sous-jacente. Les requêtes de transmission fédérées vous aident à tirer parti des fonctions spécifiques, du langage de requête et des capacités en matière de performances de la source de données d’origine. Par exemple, vous pouvez exécuter des requêtes Athena sur DynamoDB à l’aide du langage PartiQL. Les requêtes de transmission fédérées sont également utiles lorsque vous souhaitez exécuter des requêtes SELECT qui regroupent, joignent ou invoquent des fonctions de votre source de données qui ne sont pas disponibles dans Athena. L’utilisation de requêtes de transmission permet de réduire le volume de données traitées par Athena et d’accélérer les temps de requête.
Pour de plus amples informations, veuillez consulter Utilisation des requêtes de transmission fédérées. Pour mettre à niveau les connecteurs que vous utilisez aujourd’hui vers la dernière version, consultez Mise à jour d’un connecteur de source de données.
10 avril 2024
Date de publication : 10/04/2024
Athena annonce les fonctions et améliorations suivantes.
Pilote ODBC 1.2.3.1000
Publication du pilote ODBC 1.2.3.1000 pour Athena.
Problèmes résolus :
-
Problème de connexion au serveur proxy : lorsqu’un serveur proxy était utilisé sans le certificat racine, le connecteur ne parvenait pas à établir de connexion.
Pour plus d’informations et pour télécharger le pilote ODBC 1.x, les notes de publication et la documentation, consultez Pilote ODBC 1.x d'Athena.
Pilote JDBC 2.1.5
Publication du pilote JDBC 2.1.5 pour Athena.
Mises à jour et améliorations :
-
Mise à jour du SDK AWS Java pour utiliser la version 1.12.687.
-
Mise à jour des bibliothèques Jackson pour utiliser la version 2.16.0.
-
Mise à jour des bibliothèques Logback pour utiliser la version 1.3.14.
Pour plus d’informations et pour télécharger le pilote JDBC 2.x, les notes de publication et la documentation, consultez Pilote JDBC 2.x d'Athena.
8 avril 2024
Date de publication : 08/04/2024
Athena annonce la version 2.0.3.0 du pilote ODBC. Pour plus d'informations, consultez les notes de mise à jour de 2.0.3.0. Pour télécharger le nouveau pilote ODBC v2, veuillez consulter Téléchargement du pilote ODBC 2.x. Pour obtenir des informations de connexion, veuillez consulter Amazon Athena ODBC 2.x.
15 mars 2024
Date de publication : 18/03/2024
Amazon Athena annonce la disponibilité d’Athena SQL dans la région Canada-Ouest (Calgary)
Pour une liste complète des services Services AWS disponibles dans chacun d'entre eux Région AWS, voir AWS Services par région
15 février 2024
Date de publication : 15/02/2024
Athena publie la version 3.1.0 du pilote JDBC.
La version 3.1.0 du pilote JDBC Amazon Athena ajoute la prise en charge de l’authentification intégrée Windows et de l’authentification par formulaire des services de fédération Microsoft Active Directory (AD FS). La version 3.1.0 inclut également d’autres améliorations mineures et des corrections de bogues.
Pour télécharger le pilote JDBC v3, consultez Téléchargement du pilote JDBC 3.x.
31 janvier 2024
Date de publication : 31/01/2024
Athena annonce les fonctions et améliorations suivantes.
-
Mise à niveau de Hudi : vous pouvez désormais utiliser Athena SQL pour interroger les tables Hudi 0.14.0. Pour plus d’informations sur l’utilisation d’Athena SQL pour interroger les tables Hudi, consultez Interrogation de jeux de données Apache Hudi.
Notes de mise à jour d'Athena pour 2023
14 décembre 2023
Date de publication : 14/12/2023
Athena annonce les correctifs et améliorations suivants.
Athena publie la version 2.1.3 du pilote JDBC. Le pilote résout les problèmes suivants :
-
La journalisation a été améliorée pour éviter les conflits avec la journalisation des applications Spring Boot et Gradle.
-
Lorsque la méthode JDBC
executeBatch()était utilisée pour insérer des enregistrements, le pilote n’insérait qu’un seul enregistrement. Athena ne prenant pas en charge l’exécution par lots de requêtes, le pilote signale désormais une erreur lorsque vous utilisezexecuteBatch(). Pour contourner cette limitation, vous pouvez soumettre des requêtes uniques dans une boucle.
Pour télécharger le nouveau pilote JDBC, les notes de mise à jour et la documentation, consultez Pilote JDBC 2.x d'Athena.
9 décembre 2023
Date de publication : 09/12/2023
Publication du pilote ODBC 1.2.1.1000 pour Athena.
Fonctionnalités et améliorations :
-
Mise à jour de la prise en charge de RStudio : le pilote ODBC est désormais compatible avec RStudio sur macOS.
-
Prise en charge des catalogues et schémas uniques : le connecteur peut désormais renvoyer un catalogue et un schéma uniques. Pour plus d’informations, consultez le guide de configuration et d’installation téléchargeable.
Problèmes résolus :
-
Instructions préparées : lorsque des instructions préparées avec un tableau de paramètres à l’aide d’un schéma en colonnes étaient exécutées, le connecteur renvoyait un résultat de requête incorrect.
-
Taille de colonne : lorsque la colonne système
$file_modified_timeétait sélectionnée, le connecteur renvoyait une taille de colonne incorrecte. -
SQLPrepare : lorsque des paramètres relatifs à
SQLPreparedans des requêtesSELECTétaient liés, le connecteur renvoyait une erreur.
Pour plus d'informations et pour télécharger les nouveaux pilotes, les notes de mise à jour et la documentation, consultez Pilote ODBC 1.x d'Athena.
7 décembre 2023
Date de publication : 07/12/2023
Athena annonce la version 2.0.2.1 du pilote ODBC. Pour plus d'informations, consultez les notes de mise à jour de 2.0.2.1. Pour télécharger le nouveau pilote ODBC v2, veuillez consulter Téléchargement du pilote ODBC 2.x. Pour obtenir des informations de connexion, veuillez consulter Amazon Athena ODBC 2.x.
5 décembre 2023
Date de publication : 05/12/2023
Vous pouvez désormais créer des groupes de travail Athena SQL utilisant AWS IAM Identity Center le mode d'authentification. Ces groupes de travail prennent en charge la fonctionnalité de propagation d’identité de confiance d’IAM Identity Center. La propagation fiable des identités permet d'utiliser les identités dans des services AWS d'analyse tels qu'Amazon Athena et Amazon EMR Studio.
Pour de plus amples informations, veuillez consulter Utilisation de groupes de travail Athena compatibles avec IAM Identity Center.
28 novembre 2023
Date de publication : 28/11/2023
Vous pouvez désormais interroger les données dans la classe de stockage Amazon S3 Express One Zone
Pour de plus amples informations, veuillez consulter Interrogation des données S3 Express One Zone.
27 novembre 2023
Date de publication : 27/11/2023
Athena annonce les fonctions et améliorations suivantes.
-
Vues du catalogue de données Glue : les vues du catalogue de données Glue fournissent une vue commune unique sur AWS des services tels qu'Amazon Athena et Amazon Redshift. Dans les affichages du Catalogue de données Glue, les autorisations d’accès sont définies par l’utilisateur qui a créé l’affichage, et non par l’utilisateur qui interroge l’affichage. Ces affichages permettent de mieux contrôler l’accès, aident à garantir le caractère complet des enregistrements, offrent une sécurité renforcée et peuvent empêcher l’accès aux tables sous-jacentes.
Pour de plus amples informations, veuillez consulter Utilisation des vues de catalogue de données dans Athena.
-
CloudTrail Support Lake — Vous pouvez désormais utiliser Amazon Athena pour analyser les données dans AWS CloudTrail Lake. AWS CloudTrail Lake est un lac de données géré CloudTrail que vous pouvez utiliser pour agréger, stocker et analyser de manière immuable les journaux d'activité à des fins d'audit, de sécurité et d'enquêtes opérationnelles. Pour interroger vos journaux d'activité CloudTrail du lac auprès d'Athena, vous n'avez pas besoin de déplacer des données ou de créer des pipelines de traitement de données distincts. Aucune opération ETL n’est requise.
Pour commencer, activez la fédération des données dans CloudTrail Lake. Lorsque vous partagez les métadonnées de votre magasin de données d'événements CloudTrail Lake avec AWS Glue Data Catalog, que vous CloudTrail créez les AWS Glue Data Catalog ressources nécessaires et que vous enregistrez les données auprès de AWS Lake Formation. Dans Lake Formation, vous pouvez spécifier les utilisateurs et les rôles qui peuvent utiliser Athena pour interroger votre entrepôt de données d’événements.
Pour plus d’informations, consultez la rubrique Enable Lake query federation dans le Guide de l’utilisateur AWS CloudTrail .
17 novembre 2023
Date de publication : 17/11/2023
Athena annonce les fonctions et améliorations suivantes.
Caractéristiques
-
Cost-based optimiseur — Athena annonce la disponibilité générale de l'optimisation basée sur les coûts à l'aide des statistiques de. AWS Glue Pour optimiser vos requêtes dans Athena SQL, vous pouvez demander à Athena de recueillir des statistiques au niveau des tables ou des colonnes pour vos tables dans AWS Glue. Si toutes les tables de votre requête contiennent des statistiques, Athena utilise ces statistiques pour examiner d'autres plans d'exécution et sélectionner celui ayant le plus de chances d'être le plus rapide.
Pour de plus amples informations, veuillez consulter Utilisation de l’optimiseur basé sur les coûts.
-
Intégration à Amazon EMR Studio : vous pouvez désormais utiliser Athena dans un Amazon EMR Studio sans avoir à utiliser directement la console Athena. Avec l'intégration Athena dans Amazon EMR, vous pouvez effectuer les tâches suivantes :
-
Exécuter des requêtes Athena SQL
-
Afficher les résultats des requêtes
-
Afficher l'historique des requêtes
-
Afficher les requêtes enregistrées
-
Exécuter des requêtes paramétrées
-
Afficher les bases de données, les tables et les vues d'un catalogue de données
Pour plus d’informations, consultez la section Amazon EMR Studio dans la rubriqueService AWS intégrations avec Athena.
-
-
Contrôle d'accès imbriqué : Athena annonce la prise en charge du contrôle d'accès aux données imbriquées dans Lake Formation. Dans Lake Formation, vous pouvez définir et appliquer des filtres de données sur des colonnes imbriquées contenant des types de données
struct. Vous pouvez utiliser le filtrage des données pour restreindre l'accès des utilisateurs aux sous-structures des colonnes imbriquées. Pour plus d'informations sur la création de filtres de données pour les données imbriquées, veuillez consulter Créer un filtre de données dans le Guide du développeur AWS Lake Formation (langue française non garantie). -
Mesures d'utilisation de la capacité allouée — Athena annonce de CloudWatch nouvelles mesures pour les réservations de capacité. Vous pouvez utiliser les nouvelles métriques pour suivre le nombre de DPU que vous avez allouées et le nombre de DPU utilisées par vos requêtes. Lorsque les requêtes sont terminées, vous pouvez également afficher le nombre de DPU consommées par la requête.
Pour de plus amples informations, veuillez consulter Surveillez les métriques des requêtes Athena avec CloudWatch.
Améliorations
-
Modification du message d'erreur : le message d'erreur
Insufficient Lake Formation permissionsest désormais libelléTable not foundouSchema not found. Cette modification a été apportée pour empêcher les acteurs malveillants de déduire l'existence de ressources de table ou de base de données à partir du message d'erreur.
16 novembre 2023
Date de publication : 16/11/2023
Athena publie un nouveau pilote JDBC qui améliore l'expérience de connexion, d'interrogation et de visualisation des données à partir d'applications de développement SQL et de business intelligence compatibles. La mise à jour du nouveau pilote est simple. Le pilote peut lire les résultats des requêtes directement à partir d'Amazon S3, ce qui permet de les mettre à votre disposition plus rapidement.
Pour de plus amples informations, veuillez consulter Pilote Athena JDBC 3.x.
31 octobre 2023
Date de publication : 31/10/2023
Amazon Athena annonce des réserves d'une heure pour la capacité allouée. À compter d'aujourd'hui, vous pouvez réserver et libérer de la capacité allouée au bout d'une heure. Cette modification simplifie l'optimisation des coûts pour les charges de travail dont la demande évolue au fil du temps.
La capacité allouée est une fonctionnalité d'Athena qui fournit des capacités de gestion des charges de travail vous permettant de hiérarchiser, de contrôler et de mettre à l'échelle vos charges de travail interactives les plus importantes. Vous pouvez ajouter une capacité à tout moment pour augmenter le nombre de requêtes que vous pouvez exécuter simultanément, contrôler les charges de travail utilisant cette capacité et partager la capacité entre les charges de travail.
Pour de plus amples informations, veuillez consulter Gestion de la capacité de traitement des requêtes. Pour obtenir des informations sur la tarification, consultez la page de Tarification d'Amazon Athena
25 octobre 2023
Date de publication : 26/10/2023
Athena annonce les correctifs et améliorations suivants.
Package jackson-core : le texte JSON dont la valeur numérique est supérieure à 1 000 caractères échouera désormais.
17 octobre 2023
Date de publication : 17/10/2023
Athena annonce la version 2.0.2.0 du pilote ODBC. Pour plus d'informations, consultez les notes de mise à jour de 2.0.2.0. Pour télécharger le nouveau pilote ODBC v2, veuillez consulter Téléchargement du pilote ODBC 2.x. Pour obtenir des informations de connexion, veuillez consulter Amazon Athena ODBC 2.x.
26 septembre 2023
Date de publication : 26/09/2023
Athena annonce les fonctions et améliorations suivantes.
-
Support de lecture de Lake Formation pour les tables Delta Lake. Pour plus d'informations sur l'utilisation des tables Delta Lake avec Athena, veuillez consulter Interrogation des tables Linux Foundation Delta Lake.
23 août 2023
Date de publication : 23/08/2023
Amazon Athena annonce la disponibilité d'Athena SQL dans la région d'Israël (Tel Aviv).
Pour une liste complète des services Services AWS disponibles dans chacun d'entre eux Région AWS, voir AWS Services par région
10 août 2023
Date de publication : 10/08/2023
Athena annonce les correctifs et améliorations suivants.
Version 2.0.1.1 du pilote ODBC
Athena annonce la version 2.0.1.1 du pilote ODBC. Pour plus d'informations, consultez les notes de mise à jour de 2.0.1.1. Pour télécharger le nouveau pilote ODBC v2, veuillez consulter Téléchargement du pilote ODBC 2.x. Pour obtenir des informations de connexion, veuillez consulter Amazon Athena ODBC 2.x.
Version 2.1.1 du pilote JDBC
Athena publie la version 2.1.1 du pilote JDBC. Le pilote résout les problèmes suivants :
-
Erreur survenue lors de la création d'une table avec une instruction contenant une expression régulière.
-
Problème causant une application incorrecte du paramètre de connexion
ApplicationName.
Pour télécharger le nouveau pilote JDBC, les notes de mise à jour et la documentation, consultez Connexion à Amazon Athena avec JDBC.
31 juillet 2023
Date de publication : 31/07/2023
Amazon Athena annonce la disponibilité d'Athena SQL dans des Régions AWS supplémentaires.
Cette version étend la disponibilité d'Athena SQL pour inclure l'Asie-Pacifique (Hyderabad), l'Asie-Pacifique (Melbourne), l'Europe (Espagne) et l'Europe (Zurich).
Pour une liste complète des services Services AWS disponibles dans chacun d'entre eux Région AWS, voir AWS Services par région
27 juillet 2023
Date de publication : 27/07/2023
Athena lance la version 2023.30.1 BigQuery du connecteur Google. Cette version du connecteur réduit le temps d'exécution des requêtes et permet d'effectuer des requêtes sur des points de terminaison BigQuery privés.
Pour plus d'informations sur le BigQuery connecteur Google, consultezConnecteur Amazon Athena pour Google BigQuery. Pour de plus amples informations sur la mise à jour de vos connecteurs de source de données existants, consultez Mise à jour d’un connecteur de source de données.
24 juillet 2023
Date de publication : 24/07/2023
Athena annonce les correctifs et améliorations suivants.
-
Requêtes comprenant des unions : amélioration des performances de certaines requêtes comprenant des unions.
-
Jointures comprenant des comparaisons de types : correction d'un échec de requête potentiel des instructions
JOINincluant une comparaison entre deux types différents. -
Sous-requêtes sur des colonnes imbriquées : correction d'un problème lié aux échecs de requêtes lorsque les sous-requêtes étaient corrélées sur des colonnes imbriquées.
-
Vues Iceberg : correction d'un problème de compatibilité lié à la précision des colonnes d'horodatage dans les vues Apache Iceberg. Les vues Iceberg comportant des colonnes d’horodatage sont désormais lisibles, que les colonnes aient été créées sur les précédentes versions du moteur ou sur la version 3 du moteur Athena.
20 juillet 2023
Date de publication : 20/07/2023
Athena publie la version 2.1.0 du pilote JDBC. Le pilote inclut de nouvelles améliorations et a résolu un problème.
Améliorations
Les bibliothèques d'analyseurs JSON de Jackson
-
jackson-annotations 2.15.2 (auparavant 2.14.0)
-
jackson-core 2.15.2 (auparavant 2.14.0)
-
jackson-databind 2.15.2 (auparavant 2.14.0)
Problèmes résolus
-
Correction d'un problème de transfert de paramètres de tableau lors de l'utilisation de la bibliothèque sql2o
.
Pour plus d'informations et pour télécharger les nouveaux pilotes, les notes de mise à jour et la documentation, consultez Connexion à Amazon Athena avec JDBC.
13 juillet 2023
Date de publication : 19/09/2023
Athena annonce les fonctions et améliorations suivantes.
-
EXPLAIN ANALYZE : ajout de la prise en charge de la file d'attente, de l'analyse, de la planification et de la durée d'exécution à la sortie de
EXPLAIN ANALYZE. -
EXPLAIN : la sortie
EXPLAINaffiche désormais des statistiques lorsque la requête contient des agrégations. -
Parquet Hive SerDe — Ajout de la
parquet.ignore.statisticspropriété permettant d'ignorer les statistiques de traitement lors de la lecture des données Parquet. Pour plus d'informations, consultez Ignorer les statistiques Parquet.
Pour plus d’informations sur EXPLAIN et EXPLAIN ANALYZE, consultez Utilisation de EXPLAIN et EXPLAIN ANALYZE sur Athena. Pour plus d'informations sur le Parquet Hive SerDe, consultezParquet SerDe.
3 juillet 2023
Date de publication : 25/07/2023
Depuis le 3 juillet 2023, Athéna a commencé à supprimer les chaînes de requête des journaux. CloudTrail La chaîne de requête a désormais une valeur de ***OMITTED***. Cette modification a été apportée pour empêcher la divulgation involontaire de noms de tables ou de valeurs de filtres susceptibles d'inclure des informations sensibles. Si vous utilisiez auparavant les CloudTrail journaux pour accéder aux chaînes de requête complètes, nous vous recommandons d'utiliser l'Athena::GetQueryExecutionAPI et de transmettre la valeur de responseElements.queryExecutionId from the CloudTrail log. Pour plus d'informations, consultez l'GetQueryExecutionaction dans le manuel Amazon Athena API Reference.
30 juin 2023
Date de publication : 30/06/2023
L'éditeur de requêtes Athena prend désormais en charge les suggestions de code de saisie anticipée pour une expérience de création de requêtes plus rapide. Vous pouvez maintenant écrire des requêtes SQL avec une précision et une efficacité accrues à l'aide des fonctionnalités suivantes :
-
Au fur et à mesure que vous tapez, des suggestions apparaissent en temps réel pour les mots-clés, les variables locales, les extraits et les éléments du catalogue.
-
Lorsque vous tapez le nom d'une base de données ou d'une table suivi d'un point, l'éditeur affiche facilement une liste de tables ou de colonnes parmi lesquelles choisir.
-
Lorsque vous passez le pointeur sur une suggestion d'extrait, un résumé présente un bref aperçu de la syntaxe et de l'utilisation de l'extrait.
-
Pour améliorer la lisibilité du code, les mots-clés et leurs règles de mise en surbrillance ont également été mis à jour pour s'aligner sur la dernière syntaxe de Trino et Hive.
Cette caractéristique est activée par défaut. Vous pouvez activer ou désactiver cette fonctionnalité dans les paramètres de préférences de l'éditeur de code.
Pour essayer les suggestions de code dactylographiées dans l'éditeur de requêtes Athena, visitez la console Athena à l'adresse. https://console.aws.amazon.com/athena/
29 juin 2023
Date de publication : 29/06/2023
-
Athena annonce la version 2.0.1.0 du pilote ODBC. Pour plus d'informations, consultez les notes de mise à jour de 2.0.1.0. Pour télécharger le nouveau pilote ODBC v2, veuillez consulter Téléchargement du pilote ODBC 2.x. Pour obtenir des informations de connexion, veuillez consulter Amazon Athena ODBC 2.x.
-
Athena et ses fonctionnalités
sont désormais disponibles dans la région du Moyen-Orient (EAU). Pour une liste complète des services Services AWS disponibles dans chacun d'entre eux Région AWS, voir AWS Services par région .
28 juin 2023
Date de publication : 28/06/2023
Vous pouvez désormais utiliser Amazon Athena pour interroger des objets restaurés à partir des classes de stockage Amazon S3 S3 Glacier Flexible Retrieval (anciennement Glacier) et S3 Glacier Deep Archive. Vous configurez cette fonctionnalité par table. La fonctionnalité est prise en charge uniquement pour les tables Apache Hive sur la version 3 du moteur Athena.
Pour de plus amples informations, veuillez consulter Interrogation d’objets Amazon Glacier restaurés.
12 juin 2023
Date de publication : 12/06/2023
Athena annonce les correctifs et améliorations suivants.
-
Horodatages de Parquet Reader : ajout de la prise en charge de la lecture des horodatages en tant que
bigint(millis) pour Parquet Reader. Cette mise à jour fournit une parité avec la prise en charge des précédentes versions du moteur. -
EXPLAIN ANALYZE : ajout du temps de lecture physique des entrées aux statistiques de requête et à la sortie de
EXPLAIN ANALYZE. Pour plus d’informations surEXPLAIN ANALYZE, consultez Utilisation de EXPLAIN et EXPLAIN ANALYZE sur Athena. -
INSERT : amélioration des performances de requête sur les tables écrites avec
INSERT. Pour plus d’informations surINSERT, consultez INSERT INTO. -
Tables Delta Lake : correction d'un problème lié à
DROP TABLEsur les tables Delta Lake qui empêchait leur suppression complète en cas de modifications simultanées.
8 juin 2023
Date de publication : 08/06/2023
Amazon Athena pour Apache Spark annonce les nouvelles fonctionnalités suivantes.
-
Prise en charge des bibliothèques et configurations Java personnalisées : vous pouvez désormais utiliser vos propres packages Java et une configuration personnalisée pour vos sessions Apache Spark dans Athena. Utilisez les propriétés Spark pour spécifier
.jardes fichiers, des packages ou toute autre configuration personnalisée avec la console Athena AWS CLI, ou l'API Athena. Pour de plus amples informations, veuillez consulter Utilisation de propriétés Spark pour spécifier une configuration personnalisée. -
Prise en charge des tables Apache Hudi, Apache Iceberg et Delta Lake : Athena pour Spark prend désormais en charge les formats de tables de stockage de lacs de données open source Apache Iceberg, Apache Hudi et Linux Foundation Delta Lake. Pour plus d'informations, consultez Utilisation de formats de table autres que Hive dans Athena pour Spark et les rubriques individuelles relatives à l'utilisation des tables Utilisation de tables Apache Iceberg dans Athena pour Spark., Utilisation de tables Apache Hudi dans Athena pour Spark. et Utilisation de tables Linux Foundation Delta Lake dans Athena pour Spark dans Athena pour Spark.
-
Prise en charge du chiffrement pour Apache Spark : dans Athena pour Spark, vous pouvez désormais activer le chiffrement des données en transit entre les nœuds Spark et des données locales au repos stockées sur disque par Spark. Pour activer le chiffrement Spark, vous pouvez utiliser la console Athena AWS CLI, ou l'API Athena. Pour de plus amples informations, veuillez consulter Activation du chiffrement Apache Spark.
Pour plus d'informations sur Amazon Athena pour Apache Spark, consultez Utilisation d’Apache Spark dans Amazon Athena.
2 juin 2023
Date de publication : 02/06/2023
Vous pouvez désormais supprimer les réservations de capacité dans Athéna et utiliser des CloudFormation modèles pour spécifier les réservations de capacité d'Athéna.
-
Suppression de réserves de capacité : vous pouvez désormais supprimer les réserves de capacité annulées dans Athena. La réserve doit être annulée avant de pouvoir être supprimée. La suppression d'une réserve de capacité entraîne la suppression immédiate de la réserve de votre compte. La réserve supprimée ne peut plus être référencée, y compris par son ARN. Pour supprimer une réserve, vous pouvez utiliser la console Athena ou l'API Athena. Pour plus d'informations, consultez Suppression d’une réserve de capacité le guide de l'utilisateur Amazon Athena et le manuel de référence DeleteCapacityReservationdes API Amazon Athena.
-
Utiliser CloudFormation des modèles pour les réservations de capacité — Vous pouvez désormais utiliser des AWS CloudFormation modèles pour spécifier les réservations de capacité d'Athena à l'aide de la
AWS::Athena::CapacityReservationressource. Pour plus d'informations, consultez AWS: :Athena : : CapacityReservation dans le guide de l'AWS CloudFormation utilisateur.
Pour plus d'informations sur l'utilisation des réserves de capacité pour allouer votre capacité dans Athena, consultez Gestion de la capacité de traitement des requêtes.
25 mai 2023
Date de publication : 25/05/2023
Athena a publié des mises à jour du connecteur de source de données qui améliorent les performances des requêtes fédérées. Les nouvelles optimisations de la poussée vers le bas et le filtrage dynamique permettent d'effectuer davantage d'opérations dans la base de données source plutôt que dans Athena. Ces optimisations réduisent la durée d'exécution des requêtes et la quantité de données analysées. Ces améliorations nécessitent la version 3 du moteur Athena.
Les connecteurs suivants ont été mis à jour :
Pour de plus amples informations sur la mise à niveau des connecteurs de source de données, consultez Mise à jour d’un connecteur de source de données.
18 mai 2023
Date de publication : 18/05/2023
Vous pouvez désormais utiliser AWS PrivateLink les connexions entrantes IPv6 vers Amazon Athena.
Amazon Athena a étendu sa prise en charge des connexions entrantes via les points de terminaison IPv6 (Internet Protocol version 6) pour y inclure AWS PrivateLink
La croissance rapide d'Internet épuise la disponibilité des adresses IPv4 (Internet Protocol version 4). IPv6 multiplie plusieurs fois le nombre d'adresses disponibles, de sorte que vous n'avez plus à gérer les espaces d'adresses qui se chevauchent dans vos VPC. Avec cette version, vous pouvez désormais combiner les avantages de l'adressage IPv6 avec les avantages de sécurité et de performances de AWS PrivateLink.
Pour vous connecter par programmation à un AWS service, vous pouvez utiliser le AWS SDK AWS CLI
15 mai 2023
Date de publication : 15/05/2023
Athena annonce la sortie des connecteurs Apache Spark DataSource V2 (DSV2) pour DynamoDB, Logs, CloudWatch Metrics et CMDB. CloudWatch AWS Utilisez les nouveaux connecteurs DSV2 pour interroger ces sources de données à l'aide de Spark. Les connecteurs DSV2 utilisent les mêmes paramètres que les connecteurs fédérés Athena correspondants. Les connecteurs DSV2 s'exécutent directement sur les applications de travail Spark et vous n'avez pas besoin de déployer une fonction Lambda pour les utiliser.
Pour de plus amples informations, veuillez consulter Utilisation des connecteurs de source de données pour Apache Spark.
10 mai 2023
Date de publication : 10/05/2023
Publication du pilote ODBC 1.1.20 pour Athena.
Fonctionnalités et améliorations :
-
Prise en charge du remplacement des point de terminaison Lake Formation.
-
Le plug-in d'authentification ADFS dispose d'un nouveau paramètre permettant de définir la valeur de partie utilisatrice (
LoginToRP). -
AWS mises à jour de la bibliothèque.
Correctifs de bogue :
-
Échec de l'annulation de l'allocation de l'instruction préparée lorsque la méthode
SQLPrepare()n'a pas été soumise. -
Erreur de liaison des paramètres de l'instruction préparée lors de la conversion d'un type C en type SQL.
-
Impossible de renvoyer les données quand les requêtes
EXPLAINetEXPLAIN ANALYZEutilisaientSQLPrepare()etSQLExecute().
Pour plus d'informations et pour télécharger les nouveaux pilotes, les notes de mise à jour et la documentation, consultez Connexion à Amazon Athena avec ODBC.
8 mai 2023
Date de publication : 08/05/2023
Athena annonce les correctifs et améliorations suivants.
-
Intégration à Hudi mise à jour : Athena a mis à jour son intégration à Apache Hudi. Vous pouvez désormais utiliser Athena pour interroger les tables Hudi 0.12.2 et le listage des métadonnées Hudi pour les tables Hudi est désormais pris en charge. Pour plus d’informations, consultez Interrogation de jeux de données Apache Hudi et Utilisation de métadonnées Hudi pour améliorer les performances.
-
Correctif de conversion d'horodatage : correction de la gestion des conversions d'horodatage vers un type de données de moindre précision. Auparavant, la version 3 du moteur Athena arrondissait incorrectement la valeur au type de cible au lieu de la tronquer lors de la conversion.
Les exemples suivants illustrent la gestion incorrecte avant le correctif.
Exemple 1 : conversion d'un horodatage en microsecondes en millisecondes
Exemples de données
A, 2020-06-10 15:55:23.383 B, 2020-06-10 15:55:23.382 C, 2020-06-10 15:55:23.383345 D, 2020-06-10 15:55:23.383945 E, 2020-06-10 15:55:23.383345734 F, 2020-06-10 15:55:23.383945278La requête suivante tente de récupérer les horodatages correspondant à une valeur spécifique.
SELECT * FROM table WHERE timestamps.col = timestamp'2020-06-10 15:55:23.383'La requête renvoyait les résultats suivants.
A, 2020-06-10 15:55:23.383 C, 2020-06-10 15:55:23.383 E, 2020-06-10 15:55:23.383Avant le correctif, Athena n'incluait pas les valeurs
2020-06-10 15:55:23.383945ou2020-06-10 15:55:23.383945278parce qu'elles avaient été arrondies à2020-06-10 15:55:23.384.Exemple 2 : conversion d'un horodatage en date
La requête suivante renvoyait un résultat erroné.
SELECT date(timestamp '2020-12-31 23:59:59.999')Résultat
2021-01-01Avant le correctif, Athena arrondissait la valeur, avançant ainsi la journée. Ces valeurs sont désormais tronquées au lieu d'être arrondies.
28 avril 2023
Date de publication : 28/04/2023
Vous pouvez désormais utiliser les réserves de capacité sur Amazon Athena pour exécuter des requêtes SQL sur une capacité de calcul entièrement gérée.
la capacité allouée fournit des capacités de gestion des charges de travail qui vous aident à hiérarchiser, contrôler et mettre à l'échelle vos charges de travail interactives les plus importantes. Vous pouvez ajouter une capacité à tout moment pour augmenter le nombre de requêtes que vous pouvez exécuter simultanément, contrôler les charges de travail utilisant cette capacité et partager la capacité entre les charges de travail.
Pour de plus amples informations, veuillez consulter Gestion de la capacité de traitement des requêtes. Pour obtenir des informations sur la tarification, consultez la page Tarification Amazon Athena
17 avril 2023
Date de publication : 17/04/2023
Athena publie la version 2.0.36 du pilote JDBC. Le pilote inclut de nouvelles fonctionnalités et a résolu un problème.
Nouvelles fonctionnalités
-
Vous pouvez désormais utiliser des identifiants de parties utilisatrices personnalisables avec l'authentification AD FS.
-
Vous pouvez désormais ajouter le nom de l'application qui utilise le connecteur à la chaîne de l'agent utilisateur.
Problèmes résolus
-
Correction d'une erreur qui se produisait lors de l'utilisation de
getSchema()pour récupérer un schéma inexistant.
Pour plus d'informations et pour télécharger les nouveaux pilotes, les notes de mise à jour et la documentation, consultez Connexion à Amazon Athena avec JDBC.
14 avril 2023
Date de publication : 20/06/2023
Athena annonce les correctifs et améliorations suivants.
-
Lorsque vous convertissez une chaîne en horodatage, un espace est requis entre le jour et l'heure ou le fuseau horaire. Pour de plus amples informations, veuillez consulter Espace requis entre les valeurs de date et d'heure lors de la conversion d'une chaîne en un horodatage.
-
Suppression d'un changement critique dans la façon dont la précision de l'horodatage était gérée. Pour garantir la cohérence entre les précédentes versions du moteur et la version 3 du moteur Athena, la précision de l’horodatage est désormais définie par défaut en millisecondes au lieu de microsecondes.
-
Athena impose désormais systématiquement l'accès au compartiment de sortie des requêtes lorsqu'elle exécute des requêtes. Assurez-vous que tous les principaux IAM qui exécutent l'StartQueryExecutionaction ont l'S3:GetBucketLocationautorisation d'accéder au compartiment de sortie de la requête.
4 avril 2023
Date de publication : 04/04/2023
Vous pouvez désormais utiliser Amazon Athena pour créer et interroger des vues sur des sources de données fédérées. Utilisez une vue fédérée unique pour interroger plusieurs tables externes ou sous-jeux de données. Cela simplifie le SQL requis et vous permet d'obscurcir les sources de données des utilisateurs finaux qui doivent utiliser le SQL pour interroger les données.
Pour plus d’informations, consultez Utilisation de vues et Exécution de requêtes fédérées.
30 mars 2023
Date de publication : 30/03/2023
Amazon Athena annonce la disponibilité d'Amazon Athena pour Apache Spark dans des Régions AWS supplémentaires.
Cette version étend la disponibilité d'Amazon Athena pour Apache Spark pour inclure l'Asie-Pacifique (Mumbai), l'Asie-Pacifique (Singapour), l'Asie-Pacifique (Sydney) et l'Europe (Francfort).
Pour plus d'informations sur Amazon Athena pour Apache Spark, consultez Utilisation d’Apache Spark dans Amazon Athena.
28 mars 2023
Date de publication : 28/03/2023
Athena annonce les correctifs et améliorations suivants.
-
Dans les réponses aux actions d'API Athena
GetQueryExecutionetBatchGetQueryExecution, le nouveau champsubStatementTypeindique le type de requête exécutée (par exemple,SELECT,INSERT,UNLOAD,CREATE_TABLEouCREATE_TABLE_AS_SELECT). -
Correction d'un bogue qui entraînait un chiffrement incorrect des fichiers manifestes pour les opérations d'écriture d'Apache Hive.
-
La version 3 du moteur Athena gère désormais correctement les valeurs
NaNetInfinitydans la fonctionapprox_percentile. La fonctionapprox_percentilerenvoie le percentile approximatif d'un jeu de données au pourcentage donné.La version 2 du moteur Athena traite incorrectement
NaNcomme une valeur supérieure àInfinity. La version 3 du moteur Athena gère désormaisNaNetInfinityconformément au traitement de ces valeurs dans d'autres fonctions analytiques et statistiques. Les points suivants décrivent le nouveau comportement de manière plus détaillée.-
Si
NaNest présent dans le jeu de données, Athena renvoieNaN. -
Si
NaNn'est pas présente, mais queInfinityest présent, Athena traiteInfinitycomme un très grand nombre. -
Si plusieurs valeurs
Infinitysont présentes, Athena les traite comme le même très grand nombre. Si nécessaire, Athena renvoieInfinity. -
Si un seul jeu de données contient les deux -
Infinityet-Double.MAX_VALUE- et qu'un résultat en percentile est-Double.MAX_VALUE, Athena renvoie-Infinity. -
Si un seul jeu de données contient les deux -
InfinityetDouble.MAX_VALUE- et qu'un résultat en percentile estDouble.MAX_VALUE, Athena renvoieInfinity. -
Pour exclure
InfinityetNaNd'un calcul, utilisez la fonctionis_finite(), comme dans l'exemple suivant.approx_percentile(x, 0.5) FILTER (WHERE is_finite(x))
-
27 mars 2023
Date de publication : 27/03/2023
Vous pouvez désormais spécifier un niveau de chiffrement minimal au niveau des groupes de travail Athena SQL dans Amazon Athena. Cette fonctionnalité garantit le chiffrement des résultats de toutes les requêtes du groupe de travail Athena SQL au niveau de chiffrement que vous spécifiez ou supérieur. Vous pouvez choisir entre plusieurs niveaux de puissance de chiffrement pour protéger vos données. Pour configurer le niveau de chiffrement minimal que vous souhaitez, vous pouvez utiliser la console AWS CLI, l'API ou le SDK Athena.
La fonctionnalité de chiffrement minimum n'est pas disponible pour les groupes de travail compatibles avec Apache Spark. Pour de plus amples informations, veuillez consulter Configuration d’un chiffrement minimal pour un groupe de travail.
17 mars 2023
Date de publication : 17/03/2023
Athena annonce les correctifs et améliorations suivants.
-
Correction d'un problème lié au connecteur Amazon Athena DynamoDB en raison duquel les requêtes échouaient et le message d'erreur ne
KeyConditionExpressions devait contenir qu'une seulecondition par clé.Ce problème se produit car la version 3 du moteur Athena reconnaît la possibilité de pousser vers le bas davantage de types de prédicats que la version 2 du moteur Athena. Dans la version 3 du moteur Athena, des clauses telles que
some_column LIKE 'someprefix%sont poussées vers le bas sous forme de prédicats de filtre qui appliquent des limites inférieure et supérieure à une colonne donnée. La version 2 du moteur Athena n'a pas poussé ces prédicats vers le bas. Dans la version 3 du moteur Athena, lorsquesome_columnest une colonne de clé de tri, le moteur pousse le prédicat du filtre vers le connecteur DynamoDB. Le prédicat de filtre est ensuite redirigé vers le service DynamoDB. DynamoDB ne prenant en charge qu'une seule condition de filtre sur une clé de tri, DynamoDB renvoie l'erreur.Pour résoudre ce problème, mettez à jour votre connecteur Amazon Athena DynamoDB vers la version 2023.11.1. Pour obtenir des instructions sur la mise à jour du connecteur, consultez Mise à jour d’un connecteur de source de données.
8 mars 2023
Date de publication : 08/03/2023
Athena annonce les correctifs et améliorations suivants.
-
Correction d'un problème lié aux requêtes fédérées qui entraînait l'envoi des valeurs des prédicats d'horodatage sous forme de microsecondes au lieu de millisecondes.
15 février 2023
Date de publication : 15/02/2023
Athena annonce les correctifs et améliorations suivants.
-
Vous pouvez désormais utiliser le chiffrement côté client afin de chiffrer les données dans Amazon S3 pour les opérations d'écriture d'Iceberg.
-
Correction d'un problème qui affectait le chiffrement côté serveur dans Amazon S3 pour les opérations d'écriture d'Iceberg.
31 janvier 2023
Date de publication : 31/01/2023
Vous pouvez désormais utiliser Amazon Athena pour interroger les données dans Google Cloud Storage. Comme Amazon S3, Google Cloud Storage est un service géré qui stocke les données dans des compartiments. Utilisez le connecteur Athena pour Google Cloud Storage pour exécuter des requêtes fédérées interactives sur vos données externes.
Pour de plus amples informations, veuillez consulter Connecteur Amazon Athena Google Cloud Storage.
20 janvier 2023
Date de publication : 20/01/2023
Vous pouvez désormais consulter une documentation complète sur la prise en charge de la compression Athena. Des rubriques individuelles ont été ajoutées pour Compression de la table Hive compression de la table Iceberg, et Niveaux de compression ZSTD.
Pour de plus amples informations, veuillez consulter Utilisation de la compression dans Athena.
3 janvier 2023
Date de publication : 03/01/2023
Athena annonce les mises à jour suivantes :
-
Commandes supplémentaires pour les métastores Hive – Vous pouvez utiliser Athena pour vous connecter à votre métastore Apache Hive autogéré en tant que catalogue de métadonnées et interroger des données stockées dans Amazon S3. Dans cette version, vous pouvez utiliser
CREATE TABLE AS(CTAS),INSERT INTOet 12 commandes supplémentaires du langage de définition de données (DDL) pour interagir avec le métastore Apache Hive. Vous pouvez gérer vos schémas de métastore Hive directement à partir d'Athena en utilisant cet ensemble étendu de fonctionnalités SQL.Pour de plus amples informations, veuillez consulter Utilisation d’un metastore Hive externe.
-
Version 2.0.35 du pilote JDBC – Athena publie la version 2.0.35 du pilote JDBC. Le pilote JDBC 2.0.35 contient les mises à jour suivantes :
-
Le pilote utilise maintenant les bibliothèques suivantes pour l'analyseur JSON de Jackson.
-
jackson-annotations 2.14.0 (auparavant 2.13.2)
-
jackson-core 2.14.0 (auparavant 2.13.2)
-
jackson-databind 2.14.0 (auparavant 2.13.2.2)
-
-
La prise en charge de la version 4.1 de JDBC est interrompue.
Pour plus d'informations et pour télécharger le nouveau pilote, les notes de mise à jour et la documentation, voir Connexion à Amazon Athena avec JDBC.
-
Notes de publication d'Athena pour 2022
14 décembre 2022
Date de publication : 14/12/2022
Vous pouvez désormais utiliser le connecteur Amazon Athena pour Kafka pour exécuter des requêtes SQL sur des données en streaming. Par exemple, vous pouvez exécuter des requêtes analytiques sur des données en streaming et en temps réel dans Amazon Managed Streaming for Apache Kafka (Amazon MSK) et les associer aux données historiques de votre lac de données dans Amazon S3.
Le connecteur Amazon Athena pour Kafka prend en charge les requêtes sur plusieurs moteurs de streaming. Vous pouvez utiliser Athena pour exécuter des requêtes SQL sur des clusters provisionnés et sans serveur Amazon MSK, sur des déploiements Kafka autogérés et sur des données en streaming dans Confluent Cloud.
Pour de plus amples informations, veuillez consulter Connecteur Amazon Athena pour MSK.
2 décembre 2022
Date de publication : 02/12/2022
Athena publie la version 2.0.34 du pilote JDBC. Le pilote JDBC 2.0.34 inclut les nouvelles fonctions suivantes et a résolu les problèmes suivants :
-
Prise en charge de la réutilisation des résultats des requêtes – Vous pouvez désormais réutiliser les résultats de requêtes exécutées précédemment jusqu'à une limite de temps que vous spécifiez, au lieu de demander à Athena de recalculer les résultats à chaque exécution de la requête. Pour plus d'informations, consultez le guide d'installation et de configuration, disponible sur la page de téléchargement de JDBC, et Réutilisation des résultats des requêtes dans Athena.
-
Ec2InstanceMetadata support — Le pilote JDBC prend désormais en charge la méthode Ec2InstanceMetadata d'authentification à l'aide de profils d'instance IAM.
-
Character-based correction d'exception — Correction d'une exception qui se produisait avec des requêtes contenant certains caractères de langue.
-
Correction de vulnérabilité — Correction d'une vulnérabilité liée aux AWS dépendances fournies avec le connecteur.
Pour plus d'informations et pour télécharger les nouveaux pilotes, les notes de mise à jour et la documentation, consultez Connexion à Amazon Athena avec JDBC.
30 novembre 2022
Date de publication : 30/11/2022
Vous pouvez désormais créer et exécuter de manière interactive des applications Apache Spark et des blocs-notes compatibles Jupyter sur Athena. Exécutez des analyses de données sur Athena à l'aide de Spark sans avoir à planifier, configurer ou gérer les ressources. Soumettez le code Spark pour traitement et recevez directement les résultats. Utilisez l'expérience simplifiée du bloc-notes dans la console Amazon Athena pour développer des applications Apache Spark en utilisant Python ou Utiliser Athena Spark APIs.
Apache Spark fonctionne sur Amazon Athena sans serveur et offre une mise à l'échelle automatique et à la demande qui permet d'obtenir un calcul instantané pour répondre à l'évolution des volumes de données et des exigences de traitement.
Pour de plus amples informations, veuillez consulter Utilisation d’Apache Spark dans Amazon Athena.
18 novembre 2022
Date de publication : 18/11/2022
Vous pouvez désormais utiliser le connecteur Amazon Athena pour Db2 IBM pour interroger Db2 depuis Athena. Par exemple, vous pouvez exécuter des requêtes analytiques sur un entrepôt des données sur Db2 et un lac de données sur Amazon S3.
Le connecteur Db2 d'Amazon Athena expose plusieurs options de configuration par le biais de variables d'environnement Lambda. Pour plus d'informations sur les options de configuration, les paramètres, les chaînes de connexion, le déploiement et les limitations, voir Connecteur Amazon Athena pour Db2 IBM.
17 novembre 2022
Date de publication : 17/11/2022
La prise en charge d'Apache Iceberg dans la version 3 du moteur Athena offre désormais les fonctionnalités de transaction ACID améliorées suivantes :
-
Prise en charge d'ORC et d'Avro – Créez des tables Iceberg en utilisant les formats de fichiers basés sur les lignes et les colonnes Apache Avro
et Apache ORC . La prise en charge de ces formats s'ajoute à la prise en charge existante de Parquet. -
MERGE INTO – Utilisez la commande
MERGE INTOpour fusionner efficacement des données à grande échelle.MERGE INTOcombine les opérationsINSERT,UPDATEetDELETEen une seule transaction. Cela réduit la charge de traitement dans votre pipeline de données et nécessite moins de SQL pour l'écriture. Pour plus d’informations, consultez Mise à jour des données de tables Iceberg et MERGE INTO. -
Prise en charge de CTAS et de VIEW – Utilisez les instructions
CREATE TABLE AS SELECT(CTAS) andCREATE VIEWavec les tables Iceberg. Pour plus d’informations, consultez CREATE TABLE AS et CREATE VIEW et CREATE PROTECTED MULTI DIALECT VIEW. -
Prise en charge de VACUUM – Vous pouvez utiliser l'instruction
VACUUMpour optimiser votre lac de données en supprimant les instantanés et les données qui ne sont plus nécessaires. Vous pouvez utiliser cette fonctionnalité pour améliorer les performances de lecture et répondre aux exigences réglementaires telles que le RGPD. Pour plus d’informations, consultez Optimisation des tables Iceberg et VACUUM.
Ces nouvelles fonctionnalités nécessitent la version 3 du moteur Athena et sont disponibles dans toutes les régions où le service Athena est pris en charge. Vous pouvez les utiliser avec la console Athena
Pour plus d'informations sur l'utilisation d'Iceberg dans Athena, voir Interrogation des tables Apache Iceberg.
14 novembre 2022
Date de publication : 14/11/2022
Amazon Athena prend désormais en charge les points de terminaison IPv6 pour les connexions entrantes que vous pouvez utiliser pour invoquer des fonctions Athena via IPv6. Vous pouvez utiliser cette fonctionnalité pour répondre aux exigences de conformité IPv6. Elle élimine également le besoin d'équipements réseau supplémentaires pour gérer la traduction d'adresses entre IPv4 et IPv6.
Pour utiliser cette fonctionnalité, configurez vos applications de manière à utiliser les nouveaux points de terminaison à double pile Athena, qui prennent en charge à la fois les protocoles IPv4 et IPv6. Dual-stack les points de terminaison utilisent le format. athena. Par exemple, le point de terminaison à double pile dans la région USA Est (Virginie du Nord) est region.api.awsathena.us-east-1.api.aws.
Lorsque vous adressez une requête à un point de terminaison à double pile d'Athena, celui-ci se résout en une adresse IPv6 ou IPv4, selon le protocole utilisé par votre réseau et votre client. Pour vous connecter par programmation à un AWS service, vous pouvez utiliser le AWS SDK AWS CLI
Pour en savoir plus sur les points de terminaison du service, voir points de terminaison de service AWS. Pour en savoir plus sur les points de terminaison du service Athena, voir Points de terminaison et quotas d'Amazon Athena dans la documentation AWS .
Vous pouvez utiliser les nouveaux points de terminaison à double pile Athena pour les connexions entrantes sans frais supplémentaires. Dual-stack les points de terminaison sont généralement disponibles dans tous les Régions AWS domaines.
11 novembre 2022
Date de publication : 11/11/2022
Athena annonce les correctifs et améliorations suivants.
-
Contrôle d'accès précis Lake Formation étendu – Vous pouvez désormais utiliser des politiques de contrôle d'accès précis AWS Lake Formation
dans les requêtes Athena pour les données stockées dans n'importe quel format de fichier ou de table pris en charge. Vous pouvez utiliser un contrôle d'accès précis dans Lake Formation pour restreindre l'accès aux données des résultats des requêtes à l'aide de filtres de données afin de garantir la sécurité au niveau des colonnes, des lignes et des cellules. Les formats de table pris en charge par Athena sont Apache Iceberg, Apache Hudi et Apache Hive. Le contrôle d'accès précis étendu est disponible dans toutes les régions prises en charge par Athena. La prise en charge étendue des formats de table et de fichier nécessite Version 3 du moteur Athena, qui offre de nouvelles fonctionnalités et améliore les performances des requêtes , mais ne change pas la façon dont vous configurez les politiques de contrôle d'accès précis dans Lake Formation. L'utilisation de ce contrôle d'accès précis étendu dans Athena a les implications suivantes :
-
EXPLAIN – Les informations de filtrage des lignes ou des cellules définies dans Lake Formation et les informations sur les statistiques des requêtes n'apparaissent pas dans la sortie de
EXPLAINetEXPLAIN ANALYZE. Pour plus d'informations surEXPLAINdans Athena, voir Utilisation de EXPLAIN et EXPLAIN ANALYZE sur Athena. -
Métastores Hive externes – Les colonnes cachées d'Apache Hive ne peuvent pas être utilisées pour le filtrage du contrôle d'accès précis, et les tables système cachées d'Apache Hive ne sont pas prises en charge par le contrôle d'accès précis. Pour plus d’informations, consultez Considérations et restrictions dans la rubrique Utilisation d’un metastore Hive externe.
-
Statistiques de requête : le nombre de lignes en Stage-level entrée et en sortie et les informations sur la taille des données ne sont pas affichées dans les statistiques des requêtes Athena lorsqu'une requête comporte des filtres au niveau des lignes définis dans Lake Formation. Pour plus d'informations sur l'affichage des statistiques relatives aux requêtes Athena, reportez-vous Affichage des statistiques et des détails d’exécution des requêtes terminées aux sections et. GetQueryRuntimeStatistics
-
Groupes de travail – Les utilisateurs du même groupe de travail Athena peuvent voir les données que le contrôle d'accès précis de Lake Formation a configurées pour être accessibles au groupe de travail. Pour plus d'informations sur l'utilisation d'Athena pour interroger des données enregistrées dans Lake Formation,voir Utilisez Athena pour interroger les données enregistrées auprès de AWS Lake Formation.
Pour en savoir plus sur l'utilisation du contrôle d'accès précis dans Lake Formation, voir Gérer le contrôle d'accès précis à l'aide de AWS Lake Formation
sur le blog AWS Big Data. -
-
Requête fédérée Athena – La requête fédérée d'Athena préserve désormais la casse originale des noms de champs dans les objets
struct. Auparavant, les noms des champsstructétaient automatiquement mis en minuscules.
8 novembre 2022
Date de publication : 08/11/2022
Vous pouvez désormais utiliser la fonction de mise en cache de la réutilisation des résultats des requêtes pour accélérer les requêtes répétées dans Athena. Une requête répétée est une requête SQL identique à une requête soumise récemment et qui produit les mêmes résultats. Lorsque vous devez exécuter plusieurs requêtes identiques, la mise en cache en vue de la réutilisation des résultats peut réduire le temps nécessaire à la production des résultats. La mise en cache en vue de la réutilisation des résultats permet également de réduire les coûts en diminuant le nombre d'octets analysés.
Pour de plus amples informations, veuillez consulter Réutilisation des résultats des requêtes dans Athena.
13 octobre 2022
Date de publication : 13/10/2022
Athena annonce la version 3 du moteur Athena.
Athena a mis à jour son moteur de requêtes SQL afin d'inclure les dernières fonctionnalités du projet open source Trino
Pour de plus amples informations, veuillez consulter Version 3 du moteur Athena.
10 octobre 2022
Date de publication : 10/10/2022
Athena publie le pilote JDBC version 2.0.33. Le pilote JDBC 2.0.33 comprend les modifications suivantes :
-
La nouvelle version du pilote, la version JDBC et les propriétés du nom du plug-in ont été ajoutées à la chaîne de l'agent utilisateur dans la classe du fournisseur d'informations d'identification.
-
Les messages d'erreur ont été corrigés et les informations nécessaires ajoutées.
-
Les instructions préparées sont désormais désallouées si la connexion est fermée ou si l'exécution d'instruction préparée par Athena échoue.
Pour plus d'informations et pour télécharger les nouveaux pilotes, les notes de mise à jour et la documentation, consultez Connexion à Amazon Athena avec JDBC.
23 septembre 2022
Date de publication : 26/09/2022
Le connecteur Amazon Athena Neptune autorise désormais la mise en correspondance non sensible à la casse pour les noms de colonnes et de tables.
-
Le connecteur de source de données Neptune peut résoudre les noms de colonnes sur les tables Neptune qui utilisent la casse, même si les noms des colonnes sont tous en minuscules dans la table de AWS Glue. Pour activer ce comportement, définissez la variable d'environnement
enable_caseinsensitivematchsurtruedans la fonction Lambda du connecteur Neptune. -
Étant donné que seuls AWS Glue les noms de table en minuscules sont pris en charge, lorsque vous créez une AWS Glue table pour Neptune, spécifiez le paramètre de AWS Glue table.
"glabel" =table_name
Pour plus d'informations sur le connecteur Neptune, veuillez consulter la rubrique Connecteur Amazon Athena pour Neptune.
13 septembre 2022
Date de publication : 13/09/2022
Athena annonce les correctifs et améliorations suivants.
-
Metastore Hive externe – Athena renvoie maintenant
NULLau lieu de lancer une exception lorsqu’une clauseWHEREinclut une partition qui n’existe pas dans un metastore Hive externe (EHMS). Le nouveau comportement correspond à celui du AWS Glue Data Catalog. -
Requêtes paramétrées – Les valeurs dans les requêtes paramétrées peuvent désormais être envoyées au type de données
DOUBLE. -
Apache Iceberg – Les opérations d’écriture sur des tables Iceberg aboutissent désormais lorsque le verrouillage d’objet est activé sur un compartiment Amazon S3.
31 août 2022
Date de publication : 31/08/2022
Amazon Athena annonce la disponibilité d’Athena et ses fonctions
Cette version étend la disponibilité d’Athena dans la région Asie-Pacifique pour inclure Asie-Pacifique (Hong Kong), Asie-Pacifique (Jakarta), Asie-Pacifique (Mumbai), Asie-Pacifique (Osaka), Asie-Pacifique (Séoul), Asie-Pacifique (Singapour), Asie-Pacifique (Sydney) et Asie-Pacifique (Sydney) et Asie-Pacifique (Tokyo). Pour accéder à une liste complète des Services AWS disponibles dans ces régions et dans d'autres, consultez la Région AWS Liste des services régionaux
23 août 2022
Date de publication : 23/08/2022
La version v2022.32.1
-
Ajout de la prise en charge du connecteur de source de données Oracle d'Amazon Athena pour les connexions basées sur SSL aux instances Amazon RDS. La prise en charge est limitée au protocole TLS (Transport Layer Security) et à l'authentification du serveur par le client. Comme l'authentification mutuelle n'est pas prise en charge dans Amazon RDS, la mise à jour n'inclut pas la prise en charge de l'authentification mutuelle.
Pour de plus amples informations, veuillez consulter Connecteur Amazon Athena pour Oracle.
3 août 2022
Date de publication : 03/08/2022
Athena publie le pilote JDBC version 2.0.32. Le pilote JDBC 2.0.32 comprend les modifications suivantes :
-
La chaîne
User-Agentenvoyée au kit SDK Athena a été étendue pour contenir la version du pilote, la version de spécification JDBC et le nom du plugin d'authentification. -
Correction d'un
NullPointerExceptionqui était lancé lorsqu'aucune valeur n'était fournie pour le paramètreCheckNonProxyHost. -
Correction d'un problème d'
login_urlanalyse dans le plugin BrowserSaml d'authentification. -
Correction d'un problème d'hôte proxy qui survenait lorsque le paramètre
UseProxyforIdpétait défini surtrue.
Pour plus d'informations et pour télécharger les nouveaux pilotes, les notes de mise à jour et la documentation, consultez Connexion à Amazon Athena avec JDBC.
1er août 2022
Date de publication : 01/08/2022
Athena annonce des améliorations apportées au kit SDK Athena Query Federation et aux connecteurs de source de données prédéfinis Athena Les améliorations apportées sont les suivantes :
-
Analyse syntaxique des structures – Correction d'un problème d'analyse syntaxique
GlueFieldLexerdans le kit SDK Athena Query Federation qui empêchait l'affichage de toutes les données de certaines structures complexes. Ce problème a affecté les connecteurs créés sur le kit SDK Athena Query Federation. -
AWS Glue tables — Ajout d'un support supplémentaire pour les types
setetdecimalcolonnes dans AWS Glue les tableaux. -
Connecteur DynamoDB – Ajout de la possibilité d'ignorer la casse des noms d'attributs DynamoDB. Pour plus d'informations, voir
disable_projection_and_casingdans la section Parameters de la page Connecteur Amazon Athena pour DynamoDB.
Pour plus d'informations, consultez la version v2022.30.2 d'Athena
21 juillet 2022
Date de publication : 21/07/2022
Vous pouvez désormais analyser et déboguer vos requêtes à l'aide de mesures de performances et d'outils d'analyse de requêtes visuels interactifs dans la console Athena. Les données de performance des requêtes et les détails d'exécution peuvent vous aider à identifier les goulots d'étranglement dans les requêtes, à inspecter les opérateurs et les statistiques pour chaque étape d'une requête, à suivre le volume de données circulant entre les étapes et à valider l'impact des prédicats de requête. Vous pouvez désormais :
-
Accédez au plan d'exécution distribué et logique de votre requête en un seul clic.
-
Explorez les opérations à chaque étape avant que l'étape ne soit exécutée.
-
Visualisez les performances des requêtes terminées avec des mesures du temps passé dans les étapes de mise en file d'attente, de planification et d'exécution.
-
Obtenez des informations sur le nombre de lignes et la quantité de données sources traitées et sorties par votre requête.
-
Consultez les détails d'exécution granulaires de vos requêtes, présentés dans leur contexte et formatés sous forme de graphique interactif.
-
Utilisez des détails d'exécution précis au niveau de l'étape pour comprendre le flux de données dans votre requête.
-
Analysez les données de performance des requêtes par programmation à l'aide de nouvelles API pour obtenir des statistiques d'exécution de requête, également publié aujourd'hui.
Pour savoir comment utiliser ces fonctionnalités dans le cadre de vos requêtes, regardez le didacticiel vidéo Optimize Amazon Athena Queries with New Query Analysis Tools
Pour obtenir la documentation, consultez Affichage des plans d’exécution des requêtes SQL et Affichage des statistiques et des détails d’exécution des requêtes terminées.
11 juillet 2022
Date de publication : 11/07/2022
Vous pouvez désormais exécuter des requêtes paramétrées directement à partir de la console Athena ou de l'API sans préparer d'instructions SQL à l'avance.
Lorsque vous exécutez des requêtes dans la console Athena dont les paramètres se présentent sous la forme de points d'interrogation, l'interface utilisateur vous invite désormais à saisir directement des valeurs pour les paramètres. Cela évite de devoir modifier les valeurs littérales dans l'éditeur de requête chaque fois que vous souhaitez exécuter la requête.
Si vous utilisez l'API d'exécution de requêtes améliorée, vous pouvez désormais fournir les paramètres d'exécution et leurs valeurs en un seul appel.
Pour plus d'informations, consultez Utilisation des requêtes paramétrées dans ce guide de l'utilisateur et l'article du Big Data Blog intitulé AWS
Utiliser des requêtes paramétrées Amazon Athena pour fournir des données en tant que service
8 juillet 2022
Date de publication : 08/07/2022
Athena annonce les correctifs et améliorations suivants.
-
Correction d'un problème lié à
DATEla gestion de la conversion des colonnes pour les points de terminaison SageMaker AI (UDF) qui provoquait des échecs de requêtes.
6 juin 2022
Date de publication : 06/06/2022
Athena publie le pilote JDBC version 2.0.31. Le pilote JDBC 2.0.31 comprend les modifications suivantes :
-
problème de dépendance log4j – Résolution d'un message d'erreur
Cannot find driver class(Impossible de trouver une classe de pilote) causé par une dépendance log4j.
Pour plus d'informations et pour télécharger les nouveaux pilotes, les notes de mise à jour et la documentation, consultez Connexion à Amazon Athena avec JDBC.
25 mai 2022
Date de publication : 25/05/2022
Athena annonce les correctifs et améliorations suivants.
-
Support Iceberg
-
Introduction d'un support pour les requêtes entre régions. Vous pouvez désormais interroger les tables Iceberg dans un Région AWS fichier différent de celui Région AWS que vous utilisez. Cross-region les requêtes ne sont pas prises en charge dans les régions de Chine.
-
Introduction d'un support pour la configuration du chiffrement côté serveur. Vous pouvez désormais chiffrer SSE-S3/SSE-KMSles données issues des opérations d'écriture d'Iceberg dans Amazon S3.
Pour plus d'informations sur l'utilisation d'Apache Iceberg dans Athena, consultez Interrogation des tables Apache Iceberg.
-
-
Publication du pilote JDBC 2.0.30
Le pilote JDBC 2.0.30 pour Athena présente les améliorations suivantes :
-
Corrige un problème de course de données qui affectait les déclarations préparées paramétrisées.
-
Corrige un problème de démarrage d'application qui survenait dans les environnements de création Gradle.
Pour télécharger le pilote JDBC 2.0.30, les notes de mise à jour et la documentation, consultez Connexion à Amazon Athena avec JDBC.
-
6 mai 2022
Date de publication : 06/05/2022
Publication des pilotes JDBC 2.0.29 et ODBC 1.1.17 pour Athena.
Ces pilotes comprennent les modifications suivantes :
-
Mise à jour du processus de lancement du navigateur du plugin SAML.
Pour plus d'informations sur ces changements et pour télécharger les nouveaux pilotes, les notes de mise à jour et la documentation, veuillez consulter Connexion à Amazon Athena avec JDBC et Connexion à Amazon Athena avec ODBC.
22 avril 2022
Date de publication : 22/04/2022
Athena annonce les correctifs et améliorations suivants.
-
Résolution d'un problème dans les index de partition et la fonction de filtrage
avec le cache de partition qui s'est produit lorsque les conditions suivantes ont été remplies : -
La
partition_filtering.enabledclé a été définie surtruedans les AWS Glue propriétés d'une table. -
La même table a été utilisée plusieurs fois avec des valeurs de filtre de partition différentes.
-
21 avril 2022
Date de publication : 21/04/2022
Vous pouvez désormais utiliser Amazon Athena pour exécuter des requêtes fédérées sur de nouvelles sources de données, notamment Google BigQuery, Azure Synapse et Snowflake. Les nouveaux connecteurs de source de données incluent :
Pour une liste complète des sources de données prises en charge par Athena, consultez Connecteurs de source de données disponibles.
Pour faciliter la navigation dans les sources disponibles et la connexion à vos données, vous pouvez désormais rechercher, trier et filtrer les connecteurs disponibles à partir d'une mise à jour des sources de données dans la console Athena.
Pour en savoir plus sur l'interrogation de sources fédérées, veuillez consulter Utilisation de la requête fédérée Amazon Athena et Exécution de requêtes fédérées.
13 avril 2022
Date de publication : 13/04/2022
Athena publie le pilote JDBC version 2.0.28. Le pilote JDBC 2.0.28 inclut les modifications suivantes :
-
Support JWT – Le pilote prend désormais en charge les jetons web JSON (JWT) pour l'authentification. Pour plus d'informations sur l'utilisation de JWT avec le pilote JDBC, consultez le Guide d'installation et de configuration, téléchargeable depuis la page du pilote JDBC.
-
Bibliothèque Log4j mise à jour – Le pilote JDBC utilise désormais les bibliothèques Log4j suivantes :
-
Log4j-api 2.17.1 (auparavant 2.17.0)
-
Log4j-core 2.17.1 (auparavant 2.17.0)
-
Log4j-jcl 2.17,2
-
-
Autres améliorations – Le nouveau pilote inclut également les améliorations et corrections de bugs suivantes :
-
La fonctionnalité des déclarations préparées par Athena est désormais disponible via JDBC. Pour plus d'informations sur les instructions préparées, consultez Utilisation des requêtes paramétrées.
-
La fédération Athena JDBC SAML est désormais fonctionnelle pour les régions chinoises.
-
Améliorations mineures supplémentaires.
-
Pour plus d'informations et pour télécharger les nouveaux pilotes, les notes de mise à jour et la documentation, consultez Connexion à Amazon Athena avec JDBC.
30 mars 2022
Date de publication : 30/03/2022
Athena annonce les correctifs et améliorations suivants.
-
Cross-region interrogation : vous pouvez désormais utiliser Athena pour interroger des données situées dans un compartiment Amazon S3 Régions AWS , notamment en Asie-Pacifique (Hong Kong), au Moyen-Orient (Bahreïn), en Afrique (Le Cap) et en Europe (Milan). Cross-region les requêtes ne sont pas prises en charge dans les régions de Chine.
-
Pour obtenir la liste des sites Régions AWS dans lesquels Athena est disponible, consultez la section Points de terminaison et quotas Amazon Athena.
-
Pour plus d'informations sur l'activation d'une Région AWS zone désactivée par défaut, consultez la section Activation d'une région.
-
Pour plus d'informations sur les requêtes entre régions, consultez Interrogation entre régions.
-
18 mars 2022
Date de publication : 18/03/2022
Athena annonce les correctifs et améliorations suivants.
-
Dynamic filtering (Filtrage dynamique) – Dynamic filtering (Filtrage dynamique) a été amélioré pour les colonnes entières en appliquant efficacement le filtre à chaque registre d'une table correspondante.
-
Iceberg — Correction d'un problème qui entraînait des échecs lors de l'écriture de fichiers Iceberg Parquet de plus de 2 Go.
-
Uncompressed output (Sortie non compressée) – CREATE TABLE les instructions prennent désormais en charge l'écriture de fichiers non compressés. Pour écrire des fichiers non compressés, utilisez la syntaxe suivante :
-
CREATE TABLE (fichier texte ou JSON) — Dans
TBLPROPERTIES, spécifiezwrite.compression = NONE. -
CREATE TABLE (Parquet) — Dans
TBLPROPERTIES, spécifiezparquet.compression = UNCOMPRESSED. -
CREATE TABLE (ORC) — Dans
TBLPROPERTIES, spécifiezorc.compress = NONE.
-
-
Compression — Correction d'un problème lié aux insertions de tables de fichiers texte qui créaient des fichiers compressés dans un format mais qui utilisaient une autre extension de fichier de format de compression lorsque des méthodes de compression autres que par défaut étaient utilisées.
-
Avro — Correction de problèmes survenus lors de la lecture de décimales de type fixe à partir de fichiers Avro.
2 mars 2022
Date de publication : 02/03/2022
Athena annonce les fonctions et améliorations suivantes.
-
Vous pouvez désormais accorder au propriétaire du compartiment Simple Storage Service (Amazon S3) un accès total sur les résultats de la requête lorsque les listes de contrôle d'accès (ACL) sont activées pour le compartiment de résultats de la requête. Pour de plus amples informations, veuillez consulter Spécification d’un emplacement de résultats des requêtes.
-
Vous pouvez désormais mettre à jour les requêtes nommées existantes. Pour de plus amples informations, veuillez consulter Utilisation de requêtes enregistrées.
23 février 2022
Date de publication : 23/02/2022
Athena annonce les correctifs et améliorations de performances suivants.
-
Amélioration du traitement de la mémoire pour améliorer les performances et réduire les erreurs de mémoire.
-
Athena lit désormais les colonnes d'horodatage ORC avec les informations de fuseau horaire stockées dans des pieds de page de bande et écrit des fichiers ORC avec fuseau horaire (UTC) dans les pieds de page. Cela n'affecte le comportement des lectures d'horodatage ORC que si le fichier ORC à lire a été créé dans un environnement de fuseau horaire non UTC.
-
Correction des estimations incorrectes de la taille des tables de liens symboliques qui entraînaient des plans de requête sous-optimaux.
-
Les vues éclatées latérales peuvent désormais être interrogées dans la console Athena à partir de sources de données de métastore Hive.
-
Amélioration des messages d'erreur de lecture de Simple Storage Service (Amazon S3) pour inclure des informations plus détaillées sur les codes d'erreur de Simple Storage Service (Amazon S3).
-
Correction d'un problème qui entraînait l'incompatibilité des fichiers de sortie au format ORC avec Apache Hive 3.1.
-
Correction d'un problème qui entraînait l'échec des noms de table avec des guillemets dans certaines requêtes DML et DDL.
15 février 2022
Date de publication : 15/02/2022
Amazon Athena a augmenté le quota de requêtes DML actives dans toutes les régions. AWS Les requêtes actives incluent à la fois les requêtes en cours d'exécution et en file d'attente. Avec cette modification, vous pouvez désormais avoir plus de requêtes DML dans un état actif qu'auparavant.
Pour plus d'informations sur les quotas de service Athena, consultez Service Quotas. Pour connaître les quotas de requête dans la région où vous utilisez Athena, consultez Points de terminaison et quotas Amazon Athena dans la Références générales AWS.
Pour surveiller l'utilisation de vos quotas, vous pouvez utiliser les statistiques CloudWatch d'utilisation. Athena publie la métrique ActiveQueryCount dans l'espace de nom AWS/Usage. Pour de plus amples informations, veuillez consulter Surveillez les statistiques d'utilisation d'Athena avec CloudWatch.
Après avoir examiné votre utilisation, vous pouvez utiliser la console Service Quotas
14 février 2022
Date de publication : 14/02/2022
Cette version ajoute le ErrorType sous-champ à l'objet de AthenaErrorréponse dans l'action d'API GetQueryExecutionAthena.
Alors que le champ ErrorCategory existant indique la source générale de l'échec d'une requête (système, utilisateur ou autre), le nouveau champ ErrorType fournit des informations plus précises sur l'erreur qui s'est produite. Combinez les informations des deux champs pour mieux comprendre les causes de l'échec de la requête.
Pour de plus amples informations, veuillez consulter Catalogue d'erreurs Athena.
9 février 2022
Date de publication : 09/02/2022
L'ancienne console Athena n'est plus disponible. La nouvelle console d'Athena prend en charge toutes les fonctions de la console précédente, mais avec une interface plus facile à utiliser et moderne. Elle comprend de nouvelles fonctions qui améliorent l'expérience de développement de requêtes, d'analyse de données et de gestion de votre utilisation. Pour utiliser la nouvelle console Athena, rendez-vous sur. https://console.aws.amazon.com/athena/
8 février 2022
Date de publication : 08/02/2022
Propriétaire attendu du bucket : par mesure de sécurité supplémentaire, vous pouvez désormais éventuellement spécifier l' Compte AWS identifiant que vous pensez être le propriétaire du bucket d'emplacement de sortie des résultats de votre requête dans Athena. Si l'ID de compte du propriétaire du compartiment des résultats de la requête ne correspond pas à l'ID de compte que vous spécifiez, les tentatives de sortie vers le compartiment échoueront avec une erreur d'autorisation Simple Storage Service (Amazon S3). Vous pouvez définir ce paramètre au niveau du client ou du groupe de travail.
Pour de plus amples informations, veuillez consulter Spécification d’un emplacement de résultats des requêtes.
28 janvier 2022
Date de publication : 28/01/2022
Athena annonce les améliorations suivantes des fonctions du moteur.
-
Apache Hudi : les requêtes d'instantané sur les tables Hudi Merge on Read (MoR) peuvent désormais lire les colonnes d'horodatage qui ont le type de données
INT64. -
Requêtes UNION : amélioration des performances et réduction de l'analyse des données pour certaines requêtes
UNIONqui analysent la même table plusieurs fois. -
Requêtes disjointes : amélioration des performances pour les requêtes qui ne comportent que des valeurs disjointes pour chaque colonne de partition du filtre.
-
Améliorations de la projection de partition
-
Plusieurs valeurs disjointes sont désormais autorisées dans la condition de filtre pour les colonnes de type
injected. Pour de plus amples informations, veuillez consulter Type injecté. -
Amélioration des performances pour les colonnes de types basés sur des chaînes comme
CHARouVARCHAR, qui ne contiennent que des valeurs disjointes sur le filtre.
-
13 janvier 2022
Date de publication : 13/01/2022
Publication des pilotes JDBC 2.0.27 et ODBC 1.1.15 pour Athena.
Le pilote JDBC 2.0.27 inclut les modifications suivantes :
-
Le pilote a été mis à jour pour récupérer des catalogues externes.
-
Le numéro de version du pilote étendu est désormais inclus dans la chaîne
user-agentdans le cadre de l'appel d'API Athena.
Le pilote ODBC 1.1.15 inclut les modifications suivantes :
-
Corrige un problème lié aux seconds appels à
SQLParamData().
Pour plus d'informations sur ces changements et pour télécharger les nouveaux pilotes, les notes de mise à jour et la documentation, veuillez consulter Connexion à Amazon Athena avec JDBC et Connexion à Amazon Athena avec ODBC.
Notes de publication d'Athena pour 2021
26 novembre 2021
Date de publication : 26/11/2021
Athena annonce la version préliminaire publique des transactions Athena ACID, qui ajoutent des opérations d'écriture, de suppression, de mise à jour et de déplacement temporel au langage de manipulation des données (DML) SQL d'Athena. Les transactions Athena ACID permettent à plusieurs utilisateurs simultanés d'apporter des modifications fiables au niveau des lignes aux données Simple Storage Service (Amazon S3). Fondées sur le format de table Apache Iceberg
Les transactions Athena ACID et la syntaxe SQL familière simplifient les mises à jour de vos données commerciales et réglementaires. Par exemple, pour répondre à une demande d'effacement de données, vous pouvez effectuer une opération SQL DELETE. Pour effectuer des corrections d'enregistrement manuelles, vous pouvez utiliser une seule instruction UPDATE. Pour récupérer des données qui ont été récemment supprimées, vous pouvez émettre des requêtes Time Travel en utilisant une instruction SELECT. Les transactions Athena sont disponibles via la console d'Athena, les opérations API et les pilotes ODBC et JDBC.
Pour de plus amples informations, veuillez consulter Utilisation des transactions Athena ACID.
24 novembre 2021
Date de publication : 24/11/2021
Athena annonce la prise en charge de la lecture et de l'écriture de données ORC, Parquet et de fichiers texte compressés selon la norme ZStandard
Pour plus d'informations sur la compression des données dans Athena, veuillez consulter Utilisation de la compression dans Athena.
22 novembre 2021
Date de publication : 22/11/2021
Vous pouvez désormais gérer les AWS Step Functions flux de travail depuis la console Amazon Athena, ce qui facilite la création de pipelines de traitement des données évolutifs, l'exécution de requêtes basées sur une logique métier personnalisée, l'automatisation des tâches administratives et d'alerte, etc.
Step Functions est désormais intégré à la dernière génération de la console d'Athena, et vous pouvez l'utiliser pour visualiser un diagramme de flux interactif de vos machines à état qui invoquent Athena. Pour commencer, sélectionnez Workflows (Flux) dans le panneau de navigation de gauche. Si vous avez déjà des machines à états avec des requêtes Athena, sélectionnez une machine à états pour afficher un diagramme interactif du flux. Si vous débutez dans Step Functions, vous pouvez commencer en lançant un exemple de projet à partir de la console Athena et en le personnalisant en fonction de vos cas d'utilisation.
Pour plus d'informations, consultez Créer et orchestrer des pipelines ETL à l'aide d'Amazon Athena AWS Step Functions
18 novembre 2021
Date de publication : 18/11/2021
Athena annonce de nouvelles fonctions et améliorations.
-
Prise en charge du déversement sur disque pour les requêtes d'agrégation contenant
DISTINCT,ORDER BY, ou les deux, comme dans l'exemple suivant :SELECT array_agg(orderstatus ORDER BY orderstatus) FROM orders GROUP BY orderpriority, custkey -
Résolution des problèmes de traitement de la mémoire pour les requêtes utilisant
DISTINCT. Pour éviter les messages d'erreur tels queQuery exhausted resources at this scale factor (La requête a épuisé les ressources à ce facteur d'échelle.)lorsque vous utilisez des requêtesDISTINCT, choisissez des colonnes dont la cardinalité est faible pourDISTINCT, ou réduisez la taille des données de la requête. -
Dans les requêtes
SELECT COUNT(*)qui ne spécifient pas de colonne particulière, amélioration des performances et de l'utilisation de la mémoire en conservant uniquement le compte sans mise en mémoire tampon des lignes. -
Introduction des fonctions de chaîne suivantes.
-
translate(source, from, to): renvoie la chaînesourceavec les caractères présents dans la chaînefromremplacée par les caractères correspondants dans la chaîneto. Si la chaînefromcontient des doublons, seule la première occurrence est utilisée. Si le caractèresourcen'existe pas dans la chaînefrom, le caractèresourceest copié sans traduction. Si l'index du caractère correspondant dans la chaînefromest supérieur à la longueur de la chaîneto, le caractère est omis de la chaîne résultante. -
concat_ws(string0, array(varchar)): renvoie la concaténation des éléments du tableau à l'aide destring0comme séparateur. Sistring0a la valeur NULL, la valeur de retour est NULL. Toutes les valeurs NULL du tableau sont ignorées.
-
-
Correction d'un bug dans lequel les requêtes échouaient lorsqu'elles tentaient d'accéder à un sous-champ manquant dans un
struct. Les requêtes renvoient désormais une valeur NULL pour le sous-champ manquant. -
Correction d'un problème de hachage incohérent pour le type de données décimales.
-
Correction d'un problème qui entraînait l'épuisement des ressources lorsqu'il y avait trop de colonnes dans une partition.
17 novembre 2021
Date de publication : 17/11/2021
Amazon Athena
Lors de l'interrogation de tables partitionnées, Athena récupère et filtre les partitions de table disponibles vers le sous-ensemble correspondant à votre requête. À mesure que de nouvelles données et partitions sont ajoutées, il faut plus de temps pour traiter les partitions et le temps d'exécution des requêtes peut augmenter. Pour optimiser le traitement des partitions et améliorer les performances des requêtes sur des tables hautement partitionnées, Athena prend désormais en charge les index de partition AWS Glue.
Pour de plus amples informations, veuillez consulter Optimisez les requêtes grâce à l'indexation et au filtrage des AWS Glue partitions.
16 novembre 2021
Date de publication : 16/11/2021
La nouvelle console Amazon Athena
-
Réorganiser, accéder à ou fermer plusieurs onglets de requête à partir d'une barre d'onglets de requête redessinée.
-
Lire et modifier les requêtes plus facilement grâce à une mise en forme améliorée du code SQL et du texte.
-
Copier les résultats de la requête dans votre presse-papiers en plus de télécharger le jeu de résultats complet.
-
Trier l'historique de vos requêtes, vos requêtes enregistrées et vos groupes de travail, et choisir les colonnes à afficher ou à masquer.
-
Utiliser une interface simplifiée pour configurer les sources de données et les groupes de travail en moins de clics.
-
Définir les préférences d'affichage des résultats de la requête, de l'historique des requêtes, de l'encapsulation des lignes, etc.
-
Augmenter votre productivité grâce à des nouveaux et meilleurs raccourcis clavier et à la documentation produit intégrée.
Avec l'annonce d'aujourd'hui, la console repensée
Si vous le souhaitez, vous pouvez utiliser la console précédente en vous connectant à votre console Compte AWS, en choisissant Amazon Athena et en désélectionnant New Athena Experience dans le panneau de navigation de gauche.
12 novembre 2021
Date de publication : 12/11/2021
Vous pouvez désormais utiliser Amazon Athena pour exécuter des requêtes fédérées sur des sources de données situées dans un autre compte AWS que le vôtre. Jusqu'à aujourd'hui, l'interrogation de ces données nécessitait que la source de données et son connecteur utilisent les mêmes informations Compte AWS que l'utilisateur qui a demandé les données.
En tant qu'administrateur de données, vous pouvez activer les requêtes fédérées entre comptes en partageant votre connecteur de données avec le compte d'un analyste de données. En tant qu'analyste de données, vous pouvez ajouter un connecteur de données qu'un administrateur de données a partagé avec vous à votre compte. Les modifications de configuration apportées au connecteur dans le compte d'origine s'appliquent automatiquement au connecteur partagé.
Pour plus d'informations sur l'activation des requêtes fédérées entre comptes, veuillez consulter Activation des requêtes fédérées entre comptes. Pour en savoir plus sur l'interrogation de sources fédérées, veuillez consulter Utilisation de la requête fédérée Amazon Athena et Exécution de requêtes fédérées.
2 novembre 2021
Date de publication : 02/11/2021
Vous pouvez désormais utiliser l'instruction EXPLAIN ANALYZE dans Athena pour visualiser le plan d'exécution distribué et le coût de chaque opération pour vos requêtes SQL.
Pour de plus amples informations, veuillez consulter Utilisation de EXPLAIN et EXPLAIN ANALYZE sur Athena.
29 octobre 2021
Date de publication : 29/10/2021
Athena publie les pilotes JDBC 2.0.25 et ODBC 1.1.13 et annonce des fonctions et des améliorations.
Pilotes JDBC et ODBC
Publication des pilotes JDBC 2.0.25 et ODBC 1.1.13 pour Athena. Les deux pilotes prennent en charge l'authentification multifacteur SAML du navigateur, qui peut être configurée pour fonctionner avec n'importe quel fournisseur SAML 2.0.
Le pilote JDBC 2.0.25 inclut les modifications suivantes :
-
Support de l'authentification SAML du navigateur. Le pilote inclut un plugin SAML de navigateur qui peut être configuré pour fonctionner avec n'importe quel fournisseur SAML 2.0.
-
Support pour les appels AWS Glue d'API. Vous pouvez utiliser le paramètre
GlueEndpointOverridepour remplacer le point de terminaison AWS Glue . -
Modification du classpath de
com.simba.athena.amazonawsàcom.amazonaws.
Le pilote ODBC 1.1.13 inclut les modifications suivantes :
-
Support de l'authentification SAML du navigateur. Le pilote inclut un plugin SAML de navigateur qui peut être configuré pour fonctionner avec n'importe quel fournisseur SAML 2.0. Pour obtenir un exemple d'utilisation du plugin SAML du navigateur avec le pilote ODBC, veuillez consulter Configuration de l’authentification unique à l’aide d’ODBC, de SAML 2.0 et du fournisseur d’identité Okta.
-
Vous pouvez désormais configurer la durée de la session de rôle lorsque vous utilisez ADFS, Azure AD ou Navigateur Azure AD pour l'authentification.
Pour plus d'informations sur ces changements et d'autres, et pour télécharger les nouveaux pilotes, les notes de mise à jour et la documentation, veuillez consulter Connexion à Amazon Athena avec JDBC et Connexion à Amazon Athena avec ODBC.
Fonctionnalités et améliorations
Athena annonce les fonctions et améliorations suivantes.
-
Une nouvelle règle d'optimisation a été introduite pour éviter les analyses de tables en double dans certains cas.
4 octobre 2021
Date de publication : 04/10/2021
Athena annonce les fonctions et améliorations suivantes.
-
DÉCALAGE SQL : la clause SQL
OFFSETest désormais prise en charge dans les instructionsSELECT. Pour de plus amples informations, veuillez consulter SELECT. -
CloudWatch métriques d'utilisation — Athena publie désormais la
ActiveQueryCountmétrique dans l'espace deAWS/Usagenoms. Pour de plus amples informations, veuillez consulter Surveillez les statistiques d'utilisation d'Athena avec CloudWatch. -
Planification des requêtes : correction d'un bug qui pouvait, dans de rares cas, entraîner des délais d'expiration de la planification des requêtes.
16 septembre 2021
Date de publication : 16/09/2021
Athena annonce les nouvelles fonctions et améliorations suivantes.
Caractéristiques
-
Ajout de la prise en charge de la spécification du fichier texte et de la compression JSON dans CTAS à l'aide de la propriété de table
write_compression. Vous pouvez également spécifier la propriétéwrite_compressiondans CTAS pour les formats Parquet et ORC. Pour de plus amples informations, veuillez consulter Propriétés de la table CTAS. -
Le format de compression BZIP2 est désormais pris en charge pour l'écriture de fichiers texte et de fichiers JSON. Pour plus d'informations sur les formats de compression dans Athena, veuillez consulter Utilisation de la compression dans Athena.
Améliorations
-
Correction d'un bug dans lequel les informations d'identité ne pouvaient pas être envoyées à la fonction Lambda UDF.
-
Correction d'un problème de poussée des prédicats avec des conditions de filtre disjointes.
-
Correction d'un problème de hachage pour les types décimaux.
-
Correction d'un problème de collecte inutile de statistiques.
-
Suppression d'un message d'erreur incohérent.
-
Amélioration des performances de la jointure par diffusion en appliquant un élagage dynamique des partitions dans le composant master.
-
Pour les requêtes fédérées :
-
Modification de la configuration pour réduire l'occurrence des erreurs
CONSTRAINT_VIOLATIONdans les requêtes fédérées.
-
15 septembre 2021
Date de publication : 15/09/2021
Vous pouvez désormais utiliser une console Amazon Athena repensée (version préliminaire). Un nouveau pilote Athena JDBC a été publié.
Version préliminaire de la console Athena
Vous pouvez désormais utiliser une console Amazon
Pour passer à la nouvelle console
Commencez dès aujourd'hui avec la nouvelle console
Pilote Athena JDBC 2.0.24
Athena annonce la disponibilité du pilote JDBC version 2.0.24 pour Athena. Cette version met à jour la prise en charge du proxy pour tous les fournisseurs d'informations Le pilote prend désormais en charge l'authentification par proxy pour tous les hôtes qui ne sont pas pris en charge par la propriété de connexion NonProxyHosts.
Pour des raisons pratiques, cette version inclut le téléchargement du pilote JDBC avec et sans le AWS SDK. Cette version du pilote JDBC vous permet d'avoir à la fois le kit SDK AWS et le pilote JDBC Athena intégrés dans le projet.
Pour plus d'informations et pour télécharger le nouveau pilote, les notes de mise à jour et la documentation, voir Connexion à Amazon Athena avec JDBC.
31 août 2021
Date de publication : 31/08/2021
Athena annonce les améliorations de fonctions et les corrections de bogues suivantes.
-
Améliorations de la fédération Athena : athena a ajouté la prise en charge des types de cartes et une meilleure prise en charge des types complexes dans le cadre du kit Athena Query Federation SDK
. Cette version comprend également des améliorations de la mémoire et des optimisations des performances. -
Nouvelles catégories d'erreurs : introduction des catégories d'erreur
USERetSYSTEMdans les messages d'erreur. Ces catégories vous aident à distinguer les erreurs que vous pouvez corriger vous-même (USER) et les erreurs qui peuvent nécessiter l'assistance du support Athena (SYSTEM). -
Messagerie d'erreur de requête fédérée : mise à jour des catégorisations
USER_ERRORpour les erreurs liées aux requêtes fédérées. -
JOIN : correction des bogues liés à l'utilisation du disque et des problèmes de mémoire pour améliorer les performances et réduire les erreurs de mémoire dans les opérations
JOIN.
12 août 2021
Date de publication : 12/08/2021
Publication du pilote ODBC 1.1.12 pour Athena. Cette version corrige les problèmes liés à SQLPrepare(), SQLGetInfo() et EndpointOverride.
Pour télécharger le nouveau pilote, les notes de mise à jour et la documentation, voir Connexion à Amazon Athena avec ODBC.
6 août 2021
Date de publication : 06/08/2021
Amazon Athena annonce la disponibilité d'Athena et ses fonctions
Cette version étend la disponibilité d'Athena dans la région Asie-Pacifique pour inclure Asie-Pacifique (Hong Kong), Asie-Pacifique (Mumbai), Asie-Pacifique (Osaka), Asie-Pacifique (Séoul), Asie-Pacifique (Singapour), Asie-Pacifique (Sydney) et Asie-Pacifique (Sydney) et Asie-Pacifique (Tokyo). Pour une liste complète des services Services AWS disponibles dans ces régions et dans d'autres, consultez la liste Région AWS complète des services
5 août 2021
Date de publication : 05/08/2021
Vous pouvez utiliser l'instruction UNLOAD pour écrire la sortie d'une requête SELECT dans les formats PARQUET, ORC, AVRO et JSON.
Pour de plus amples informations, veuillez consulter UNLOAD.
30 juillet 2021
Date de publication : 30/07/2021
Athena annonce les améliorations de fonctions et les corrections de bogues suivantes.
-
Filtrage dynamique et élagage des partitions : ces améliorations permettent d'augmenter les performances et de réduire la quantité de données analysées dans certaines requêtes, comme dans l'exemple suivant.
Cet exemple suppose que
Table_Best une table non partitionnée dont la taille des fichiers est inférieure à 20 Mo. Pour les requêtes de ce type, moins de données sont lues à partir de laTable_Aet la requête se termine plus rapidement.SELECT * FROM Table_A JOIN Table_B ON Table_A.date = Table_B.date WHERE Table_B.column_A = "value" -
ORDER BY avec LIMIT, DISTINCT with LIMIT : amélioration des performances des requêtes utilisant
ORDER BYouDISTINCTsuivies d'une clauseLIMIT. -
Fichiers Amazon Glacier Deep Archive : lorsqu’Athena interroge une table contenant à la fois des fichiers Amazon Glacier Deep Archive et des fichiers autres qu’Amazon Glacier, Athena ignore désormais les fichiers Amazon Glacier Deep Archive. Auparavant, vous deviez déplacer manuellement ces fichiers depuis l'emplacement de la requête, faute de quoi la requête échouait. Si vous souhaitez utiliser Athena pour interroger des objets dans la mémoire de stockage Amazon Glacier Deep Archive, vous devez les restaurer. Pour plus d'informations, consultez la rubrique Restauration d'un objet archivé du Guide de l'utilisateur de Simple Storage Service (Amazon S3).
-
Correction d'un bogue qui faisait que les fichiers vides créés par la propriété de table
bucketed_byCTAS n'étaient pas chiffrés correctement.
21 juillet 2021
Date de publication : 21/07/2021
Avec la version de juillet 2021 de Microsoft Power BI Desktop
Étant donné que le connecteur utilise votre nom de source de données (DSN) ODBC existant pour se connecter à Athena et exécuter des requêtes sur Athena, il nécessite le pilote ODBC Athena. Pour télécharger le dernier pilote ODBC, voir Connexion à Amazon Athena avec ODBC.
Pour de plus amples informations, veuillez consulter Utilisation du connecteur Amazon Athena pour Power BI.
16 juillet 2021
Date de publication : 16/07/2021
Amazon Athena a mis à jour son intégration à Apache Hudi. Hudi est un cadre de gestion de données open source utilisé pour simplifier le traitement progressif des données dans les lacs de données Simple Storage Service (Amazon S3). L'intégration mise à jour vous permet d'utiliser Athena pour interroger les tables Hudi 0.8.0 gérées par Amazon EMR, Apache Spark, Apache Hive ou d'autres services compatibles. En outre, Athena prend désormais en charge deux fonctionnalités supplémentaires : les requêtes instantanées sur les tables ( Merge-on-Read MoR) et la prise en charge de la lecture sur les tables bootstrap.
Apache Hudi fournit un traitement des données de niveau record qui peut vous aider à simplifier le développement de pipelines de capture des données modifiées (CDC), à respecter les GDPR-driven mises à jour et les suppressions, et à mieux gérer les données en streaming provenant de capteurs ou d'appareils nécessitant une insertion de données et des mises à jour d'événements. La version 0.8.0 facilite la migration des grandes tables Parquet vers Hudi sans copier les données afin de pouvoir les interroger et les analyser via Athena. Vous pouvez utiliser la nouvelle prise en charge des requêtes d'instantané d'Athena pour obtenir des vues en temps quasi réel des mises à jour de vos tables diffusées en streaming.
Pour en savoir plus sur l'utilisation de Hudi avec Athena, voir Interrogation de jeux de données Apache Hudi.
8 juillet 2021
Date de publication : 08/07/2021
Publication du pilote ODBC 1.1.11 pour Athena. Le pilote ODBC peut désormais authentifier la connexion à l'aide d'un jeton Web JSON (JWT). Sous Linux, la valeur par défaut de la propriété Groupe de travail a été définie sur Primaire.
Pour plus d'informations et pour télécharger le nouveau pilote, les notes de mise à jour et la documentation, voir Connexion à Amazon Athena avec ODBC.
1er juillet 2021
Date de publication : 01/07/2021
Le 1er juillet 2021, le traitement spécial des groupes de travail de prévisualisation a pris fin. Bien que les groupes de travail AmazonAthenaPreviewFunctionality retiennent leur nom, ils n'ont plus de statut spécial. Vous pouvez continuer à utiliser les groupes de travail AmazonAthenaPreviewFunctionality pour visualiser, modifier, organiser et exécuter des requêtes. Toutefois, les requêtes qui utilisent des fonctions qui étaient auparavant en prévisualisation sont désormais soumises aux conditions de facturation standard d'Athena. Pour plus d'informations sur la facturation, consultez la rubrique Tarification Amazon Athena
23 juin 2021
Date de publication : 23/06/2021
Publication des pilotes JDBC 2.0.23 et ODBC 1.1.10 pour Athena. Les deux pilotes offrent des performances de lecture améliorées et prennent en charge les instructions EXPLAIN et les requêtes paramétrées.
Les instructions EXPLAIN montrent le plan d'exécution logique ou distribué d'une requête SQL. Les requêtes paramétrées permettent d'utiliser la même requête plusieurs fois avec des valeurs différentes fournies au moment de l'exécution.
La version JDBC ajoute également la prise en charge d'Active Directory Federation Services 2019 et une option de remplacement du point de terminaison personnalisé pour AWS STS. La version ODBC corrige un problème avec les informations d'identification du profil IAM.
Pour plus d'informations et pour télécharger les nouveaux pilotes, les notes de mise à jour et la documentation, voir Connexion à Amazon Athena avec JDBC et Connexion à Amazon Athena avec ODBC.
12 mai 2021
Date de publication : 12/05/2021
Vous pouvez désormais utiliser Amazon Athena pour enregistrer un AWS Glue catalogue à partir d'un compte autre que le vôtre. Après avoir configuré les autorisations IAM requises pour AWS Glue, vous pouvez utiliser Athena pour exécuter des requêtes entre comptes.
Pour plus d’informations, consultez Enregistrement d’un catalogue de données à partir d’un autre compte et Configuration de l'accès entre comptes aux catalogues de AWS Glue données.
10 mai 2021
Date de publication : 10/05/2021
Publication de la version 1.1.9.1001 du pilote ODBC pour Athena. Cette version corrige un problème avec le type d'authentification BrowserAzureAD lors de l'utilisation d'Azure Active Directory (AD).
Pour télécharger les nouveaux pilotes, les notes de mise à jour et la documentation, voir Connexion à Amazon Athena avec ODBC.
5 mai 2021
Date de publication : 05/05/2021
Vous pouvez désormais utiliser le connecteur Vertica d'Amazon Athena dans les requêtes fédérées pour interroger les sources de données Vertica depuis Athena. Par exemple, vous pouvez exécuter des requêtes analytiques sur un entrepôt de données sur Vertica et un lac de données sur Simple Storage Service (Amazon S3).
Pour déployer le connecteur Athena Vertica, rendez-vous AthenaVerticaConnector
Le connecteur Vertica d'Amazon Athena expose plusieurs options de configuration par le biais de variables d'environnement Lambda. Pour plus d'informations sur les options de configuration, les paramètres, les chaînes de connexion, le déploiement et les limitations, voir Connecteur Amazon Athena pour Vertica.
Pour obtenir des informations détaillées sur l'utilisation du connecteur Vertica, consultez la rubrique Interrogation d'une source de données Vertica dans Amazon Athena à l'aide du kit SDK de requête fédérée d’Athena
30 avril 2021
Date de publication : 30/04/2021
Publication des pilotes JDBC 2.0.21 et ODBC 1.1.9 pour Athena. Les deux versions prennent en charge l'authentification SAML avec Azure Active Directory (AD) et l'authentification SAML avec. PingFederate La version JDBC prend également en charge les requêtes paramétrées. Pour plus d'informations sur les requêtes paramétrées dans Athena, voir Utilisation des requêtes paramétrées.
Pour télécharger les nouveaux pilotes, les notes de mise à jour et la documentation, voir Connexion à Amazon Athena avec JDBC et Connexion à Amazon Athena avec ODBC.
29 avril 2021
Date de publication : 29/04/2021
Amazon Athena annonce la disponibilité de la version 2 du moteur Athena dans les régions Chine (Beijing) et Chine (Ningxia).
26 avril 2021
Date de publication : 26/04/2021
Les fonctions de valeur de fenêtre dans la version 2 du moteur Athena prennent désormais en charge IGNORE NULLS et RESPECT NULLS.
Pour plus d'informations, consultez la rubrique Fonctions de valeur
21 avril 2021
Date de publication : 21/04/2021
Amazon Athena annonce la disponibilité de la version 2 du moteur Athena dans les régions Europe (Milan) et Afrique (Le Cap).
5 avril 2021
Date de publication : 05/04/2021
Instruction EXPLAIN
Vous pouvez maintenant utiliser l'instruction EXPLAIN dans Athena pour visualiser le plan d'exécution de vos requêtes SQL.
Pour plus d’informations, consultez Utilisation de EXPLAIN et EXPLAIN ANALYZE sur Athena et Présentation des résultats de l’instruction EXPLAIN d’Athena.
SageMaker Modèles de Machine Learning basés sur l'IA dans les requêtes SQL
L'inférence de modèles d'apprentissage automatique avec Amazon SageMaker AI est désormais généralement disponible pour Amazon Athena. Utilisez des modèles de machine learning dans des requêtes SQL pour simplifier des tâches complexes telles que la détection d'anomalies, l'analyse de cohortes de clients et les prédictions de séries temporelles en invoquant une fonction dans une requête SQL.
Pour de plus amples informations, veuillez consulter Utilisation du machine learning (ML) avec Amazon Athena.
Fonctions définies par l'utilisateur (UDF)
Les fonctions définies par l'utilisateur (UDF) sont désormais généralement disponibles pour Athena. Utilisez les UDF pour exploiter des fonctions personnalisées qui traitent des registres ou des groupes de registres dans une seule requête SQL.
Pour de plus amples informations, veuillez consulter Interrogation avec des fonctions définies par l’utilisateur.
30 mars 2021
Date de publication : 30/03/2021
Amazon Athena annonce la disponibilité de la version 2 du moteur Athena dans les régions Asie-Pacifique (Hong Kong) et Moyen-Orient (Bahreïn).
25 mars 2021
Date de publication : 25/03/2021
Amazon Athena annonce la disponibilité de la version 2 du moteur Athena dans la région Europe (Stockholm).
5 mars 2021
Date de publication : 05/03/2021
Amazon Athena annonce la disponibilité de la version 2 du moteur Athena dans les régions Canada (Centre), Europe (Francfort) et Amérique du Sud (Sao Paulo).
25 février 2021
Date de publication : 25/02/2021
Amazon Athena annonce la disponibilité générale de la version 2 du moteur Athena dans les régions Asie-Pacifique (Séoul), Asie-Pacifique (Singapour), Asie-Pacifique (Sydney), Europe (Londres) et Europe (Paris).
Notes de publication d'Athena pour 2020
16 décembre 2020
Date de publication : 16/12/2020
Amazon Athena annonce la disponibilité de la version 2 du moteur Athena, Athena Federated Query, et dans d'autres régions. AWS PrivateLink
Version 2 du moteur Athena et requête fédérée d’Athena
Amazon Athena annonce la disponibilité générale de la version 2 du moteur Athena et de la requête fédérée d’Athena dans les régions Asie-Pacifique (Mumbai), Asie-Pacifique (Tokyo), Europe (Irlande) et USA Ouest (Californie du Nord). La version 2 du moteur Athena et les requêtes fédérées sont déjà disponibles dans les régions USA Est (Virginie du Nord), USA Est (Ohio) et USA Ouest (Oregon).
AWS PrivateLink
AWS PrivateLink for Athena est désormais pris en charge dans la région Europe (Stockholm). Pour plus d'informations sur AWS PrivateLink Athéna, voir. Connexion à Amazon Athena à l'aide d'un point de terminaison de VPC d'interface
24 novembre 2020
Date de publication : 24/11/2020
Publication des pilotes JDBC 2.0.16 et ODBC 1.1.6 pour Athena. Ces versions prennent en charge, au niveau du compte, l'authentification multifactorielle (MFA) Okta Verify. Vous pouvez également utiliser Okta MFA pour configurer l'authentification SMS et l'authentification Google Authenticator en tant que facteurs.
Pour télécharger les nouveaux pilotes, les notes de mise à jour et la documentation, voir Connexion à Amazon Athena avec JDBC et Connexion à Amazon Athena avec ODBC.
11 novembre 2020
Date de publication : 11/11/2020
Amazon Athena annonce la disponibilité générale de la version 2 du moteur Athena et des requêtes fédérées dans les régions USA Est (Virginie du Nord), USA Est (Ohio) et USA Ouest (Oregon).
Version 2 du moteur Athena
Amazon Athena annonce la disponibilité générale d'une nouvelle version du moteur de requête, la version 2 du moteur Athena, dans les régions USA Est (Virginie du Nord), USA Est (Ohio) et USA Ouest (Oregon).
La version 2 du moteur Athena comprend des améliorations des performances et de nouvelles fonctions telles que la prise en charge de l'évolution des schémas pour les données au format Parquet, des fonctions géospatiales supplémentaires, la prise en charge de la lecture de schémas imbriqués pour réduire les coûts et des améliorations des performances des opérations JOIN et AGGREGATE.
-
Pour plus d'informations sur la procédure de mise à niveau, voir Modification des versions du moteur Athena.
-
Pour plus d'informations sur le test des requêtes, voir Essai des requêtes avant la mise à niveau d’une version du moteur.
Requêtes SQL fédérées
Vous pouvez désormais utiliser la requête fédérée d'Athena dans les régions USA Est (Virginie du Nord), USA Est (Ohio) et USA Ouest (Oregon) sans utiliser le groupe de travail AmazonAthenaPreviewFunctionality.
Utilisez les requêtes SQL fédérées pour exécuter des requêtes SQL sur des sources de données relationnelles, non relationnelles, objet et personnalisées. Grâce aux requêtes fédérées, vous pouvez soumettre une seule requête SQL qui analyse les données provenant de plusieurs sources exécutées sur site ou hébergées dans le cloud.
L'exécution d'analyses sur les données réparties entre les applications peut être complexe et chronophage pour les raisons suivantes :
-
Les données nécessaires aux analyses sont souvent réparties dans des magasins de données relationnels, valeurs clés, de documents, en mémoire, de recherche, de graphiques, d'objets, de séries chronologiques et de grand livre.
-
Pour analyser les données provenant de ces sources, les analystes construisent des pipelines complexes pour extraire, transformer et charger un entrepôt de données afin que les données puissent être interrogées.
-
L'accès aux données provenant de différentes sources nécessite l'apprentissage de nouveaux langages de programmation et de nouveaux concepts d'accès aux données.
Les requêtes SQL fédérées dans Athena éliminent cette complexité en permettant aux utilisateurs d'interroger les données sur place, où qu'elles se trouvent. Les analystes peuvent utiliser des structures SQL familières pour joindre (JOIN) des données à plusieurs sources de données pour une analyse rapide et stocker les résultats dans Simple Storage Service (Amazon S3) pour une utilisation ultérieure.
Connecteurs de source de données
Pour traiter les requêtes fédérées, Athena utilise les connecteurs de sources de données Athena qui s'exécutent sur AWS Lambda
Connecteurs de source de données personnalisés
Grâce au kit Athena Query Federation SDK
Étapes suivantes
-
Pour en savoir plus sur la fonction de requête fédérée, voir Utilisation de la requête fédérée Amazon Athena.
-
Pour commencer à utiliser un connecteur existant, consultez Création d’une connexion à une source de données.
-
Pour savoir comment créer votre propre connecteur de source de données à l'aide du SDK Athena Query Federation, consultez Example Athena
Connector on. GitHub
22 octobre 2020
Date de publication : 22/10/2020
Tu peux maintenant appeler Athéna avec. AWS Step Functions AWS Step Functions peut contrôler certains Services AWS directement à l'aide de l'Amazon States Language. Vous pouvez utiliser Step Functions avec Athena pour lancer et arrêter l'exécution de requêtes, obtenir des résultats de requêtes, exécuter des requêtes de données ad hoc ou planifiées et récupérer les résultats des lacs de données dans Amazon S3.
Pour plus d'informations, consultez la rubrique Appel d'Athena avec Step Functions du Guide du développeur AWS Step Functions .
29 juillet 2020
Date de publication : 29/07/2020
Publication du pilote JDBC version 2.0.13. Cette version prend en charge l'utilisation de plusieurs catalogues de données enregistrés dans Athena, le service Okta pour l'authentification et les connexions aux points de terminaison de VPC.
Pour télécharger et utiliser la nouvelle version du pilote, voir Connexion à Amazon Athena avec JDBC.
9 juillet 2020
Date de publication : 09/07/2020
Amazon Athena prend en charge l'interrogation des ensembles de données Hudi compactés et ajoute la CloudFormation
AWS::Athena::DataCatalog ressource permettant de créer, de mettre à jour ou de supprimer les catalogues de données que vous enregistrez dans Athena.
Jeux de données Apache Hudi
Apache Hudi est un cadre de gestion de données open source qui simplifie le traitement progressif des données. Amazon Athena prend désormais en charge l'interrogation de la vue optimisée en lecture d'un ensemble de données Apache Hudi dans votre lac de données Amazon. S3-based
Pour de plus amples informations, veuillez consulter Interrogation de jeux de données Apache Hudi.
CloudFormation Ressource de catalogue de données
Pour utiliser la fonction de requête fédérée d'Amazon Athena afin d'interroger n'importe quelle source de données, vous devez d'abord enregistrer votre catalogue de données dans Athena. Vous pouvez désormais utiliser cette CloudFormation AWS::Athena::DataCatalog ressource pour créer, mettre à jour ou supprimer les catalogues de données que vous enregistrez dans Athena.
Pour plus d'informations, voir AWS::Athena: : DataCatalog dans le guide de CloudFormation l'utilisateur.
1er juin 2020
Date de publication : 01/06/2020
Utilisation du métastore Apache Hive comme métacatalogue avec Amazon Athena
Vous pouvez désormais connecter Athena à un ou plusieurs métastores Apache Hive en plus du AWS Glue Data Catalog avec Athena.
Pour vous connecter à un métastore Hive auto-hébergé, vous avez besoin d'un connecteur de métastore Hive Athena. Athena fournit un connecteur de mise en œuvre de référence que vous pouvez utiliser. Le connecteur s'exécute en tant que fonction AWS Lambda dans votre compte.
Pour de plus amples informations, veuillez consulter Utilisation d’un metastore Hive externe.
21 mai 2020
Date de publication : 21/05/2020
Amazon Athena ajoute la prise en charge de la projection de partition. Utilisez la projection de partition pour accélérer le traitement des requêtes de tables hautement partitionnées et automatiser la gestion des partitions. Pour de plus amples informations, veuillez consulter Utilisation de la projection de partition avec Amazon Athena.
1er avril 2020
Date de publication : 01/04/2020
Outre la région USA Est (Virginie du Nord), les fonctions de requête fédérée Amazon Athena, les fonctions définies par l’utilisateur (UDF), l’inférence de machine learning et le métastore Hive externe sont désormais disponibles en version préliminaire dans les régions Asie-Pacifique (Mumbai), Europe (Irlande) et USA Ouest (Oregon).
11 mars 2020
Date de publication : 11/03/2020
Amazon Athena publie désormais des EventBridge événements Amazon pour les transitions d'état des requêtes. Lorsqu'une requête passe d'un état à un autre, par exemple, de l'état En cours à un état terminal tel que Successed ou Annulé, Athena publie un événement de changement d'état de requête sur. EventBridge Cet événement contient des informations sur le changement de l'état de la requête. Pour de plus amples informations, veuillez consulter Surveillez les événements de requête Athena avec EventBridge.
6 mars 2020
Date de publication : 06/03/2020
Vous pouvez désormais créer et mettre à jour des groupes de travail Amazon Athena à l'aide de cette ressource. CloudFormation
AWS::Athena::WorkGroup Pour plus d'informations, voir AWS::Athena: : WorkGroup dans le guide de CloudFormation l'utilisateur.
Notes de publication d'Athena pour 2019
26 novembre 2019
Date de publication : 17/12/2019
Amazon Athena s'enrichit de la prise en charge de l'exécution de requêtes SQL sur des sources de données relationnelles, non relationnelles, objet et personnalisées, l'invocation de modèles de machine learning dans des requêtes SQL, des fonctions définies par l'utilisateur (UDF) (Prévisualisation), l'utilisation du métastore Apache Hive comme catalogue de métadonnées avec Amazon Athena (Prévisualisation), ainsi que quatre métriques supplémentaires liées aux requêtes.
Requêtes SQL fédérées
Utilisez les requêtes SQL fédérées pour exécuter des requêtes SQL sur des sources de données relationnelles, non relationnelles, objet et personnalisées.
Vous pouvez désormais utiliser la requête fédérée d'Athena pour analyser les données stockées dans des sources de données relationnelles, non relationnelles, objet et personnalisées. Grâce aux requêtes fédérées, vous pouvez soumettre une seule requête SQL qui analyse les données provenant de plusieurs sources exécutées sur site ou hébergées dans le cloud.
L'exécution d'analyses sur les données réparties entre les applications peut être complexe et chronophage pour les raisons suivantes :
-
Les données nécessaires aux analyses sont souvent réparties dans des magasins de données relationnels, valeurs clés, de documents, en mémoire, de recherche, de graphiques, d'objets, de séries chronologiques et de grand livre.
-
Pour analyser les données provenant de ces sources, les analystes construisent des pipelines complexes pour extraire, transformer et charger un entrepôt de données afin que les données puissent être interrogées.
-
L'accès aux données provenant de différentes sources nécessite l'apprentissage de nouveaux langages de programmation et de nouveaux concepts d'accès aux données.
Les requêtes SQL fédérées dans Athena éliminent cette complexité en permettant aux utilisateurs d'interroger les données sur place, où qu'elles se trouvent. Les analystes peuvent utiliser des structures SQL familières pour joindre (JOIN) des données à plusieurs sources de données pour une analyse rapide et stocker les résultats dans Simple Storage Service (Amazon S3) pour une utilisation ultérieure.
Connecteurs de source de données
Athena traite les requêtes fédérées à l'aide des connecteurs de sources de données Athena qui s'exécutent sur AWS Lambda
Connecteurs de source de données personnalisés
Grâce au kit Athena Query Federation SDK
Disponibilité de l'aperçu
La requête fédérée d’Athena est disponible en prévisualisation dans la région USA Est (Virginie du Nord).
Étapes suivantes
-
Pour commencer votre prévisualisation, suivez les instructions de la FAQ des fonctions en prévisualisation d'Athena
. -
Pour en savoir plus sur la fonction de requête fédérée, consultez la rubrique Utilisation de la requête fédérée d’Amazon Athena (prévisualisation).
-
Pour commencer à utiliser un connecteur existant, consultez Création d’une connexion à une source de données.
-
Pour savoir comment créer votre propre connecteur de source de données à l'aide du SDK Athena Query Federation, consultez Example Athena
Connector on. GitHub
Invocation de modèles dde Machine Learning dans les requêtes SQL
Vous pouvez désormais invoquer des modèles de machine learning pour l'inférence directement à partir de vos requêtes Athena. La possibilité d'utiliser des modèles de machine learning dans les requêtes SQL rend les tâches complexes comme la détection d'anomalies, l'analyse de cohortes de clients, et les prédictions de ventes, aussi simples que l'invocation d'une fonction dans une requête SQL.
Modèles ML
Vous pouvez utiliser plus d'une douzaine d'algorithmes d'apprentissage automatique intégrés fournis par Amazon SageMaker
Disponibilité de l'aperçu
La fonctionnalité ML d'Athena est disponible aujourd'hui en prévisualisation dans la région USA Est (Virginie du Nord).
Étapes suivantes
-
Pour commencer votre prévisualisation, suivez les instructions de la FAQ des fonctions en prévisualisation d'Athena
. -
Pour en savoir plus sur la fonction de machine learning, consultez la rubrique Utilisation de machine learning (ML) avec Amazon Athena (version de prévisualisation).
Fonctions définies par l'utilisateur (UDF) (version de prévisualisation)
Vous pouvez désormais écrire des fonctions scalaires personnalisées et les invoquer dans vos requêtes Athena. Vous pouvez écrire vos UDF en Java à l'aide du kit Athena Query Federation SDKSELECT et les clauses FILTER d'une requête SQL. Vous pouvez invoquer plusieurs UDF dans la même requête.
Disponibilité de l'aperçu
La fonctionnalité UDF d'Athena est disponible en mode Prévisualisation dans la région USA Est (Virginie du Nord).
Étapes suivantes
-
Pour commencer votre prévisualisation, suivez les instructions de la FAQ des fonctions en prévisualisation d'Athena
. -
Pour en savoir plus, consultez Interrogation avec des fonctions définies par l'utilisateur (version de prévisualisation).
-
Pour des exemples d'implémentations UDF, consultez Amazon Athena
UDF Connector activé. GitHub -
Pour apprendre à écrire vos propres fonctions à l'aide du kit Athena Query Federation SDK, consultez la rubrique Création et déploiement d'une UDF avec Lambda.
Utilisation du métastore Apache Hive comme métacatalogue avec Amazon Athena (version de prévisualisation)
Vous pouvez désormais connecter Athena à un ou plusieurs métastores Apache Hive en plus du AWS Glue Data Catalog avec Athena.
Connecteur Metastore
Pour vous connecter à un métastore Hive auto-hébergé, vous avez besoin d'un connecteur de métastore Hive Athena. Athena fournit un connecteur de mise en œuvre de référence
Disponibilité de l'aperçu
La fonction de métastore Hive est disponible en mode Prévisualisation dans la région USA Est (Virginie du Nord).
Étapes suivantes
-
Pour commencer votre prévisualisation, suivez les instructions de la FAQ des fonctions en prévisualisation d'Athena
. -
Pour en savoir plus sur cette fonction, veuillez consulter notre article intitulé Utilisation du connecteur de données Athena pour le métastore Hive externe (version de prévisualisation).
Nouvelles Query-Related métriques
Athena publie désormais des métriques de requête supplémentaires qui peuvent vous aider à comprendre les performances d'Amazon Athena
-
Durée de planification de requêtes : temps nécessaire à la planification de la requête. Cela inclut le temps passé à récupérer les partitions de la table à partir de la source de données,
-
Durée de mise en file d'attente des requêtes : temps pendant lequel la requête est restée dans une file d'attente de ressources.
-
Durée de traitement du service : temps nécessaire à l'écriture des résultats après la fin du traitement du moteur de requête.
-
Durée totale d'exécution : temps nécessaire pour qu'Athena exécute la requête.
Pour utiliser ces nouvelles métriques de requête, vous pouvez créer des tableaux de bord personnalisés, définir des alarmes et des déclencheurs sur les métriques ou utiliser des tableaux de bord préremplis directement depuis la console Athena. CloudWatch
Étapes suivantes
Pour plus d'informations, consultez la section Surveillance des requêtes Athena à l'aide CloudWatch de métriques.
12 novembre 2019
Date de publication : 17/12/2019
Amazon Athena est désormais disponible dans la région Moyen-Orient (Bahreïn).
8 novembre 2019
Date de publication : 17/12/2019
Amazon Athena est désormais disponible dans les régions USA Ouest (Californie du Nord) et Europe (Paris).
8 octobre 2019
Date de publication : 17/12/2019
Amazon Athena
Pour créer un point de terminaison VPC d'interface pour vous connecter à Athena, vous pouvez utiliser le AWS Management Console ou (). AWS Command Line Interface AWS CLI Pour plus d'informations sur la création d'un point de terminaison d'interface, voir Création d'un point de terminaison d'interface.
Lorsque vous utilisez un point de terminaison VPC d'interface, la communication entre votre VPC et les API Athena est sécurisée et reste au sein du réseau. AWS Cette fonction est disponible sans frais supplémentaires pour Athena. Des frais
Pour en savoir plus sur cette fonction, consultez la rubrique Connexion à Amazon Athena à l'aide d'un point de terminaison de VPC d'interface.
19 septembre 2019
Date de publication : 17/12/2019
Amazon Athena ajoute la prise en charge de l'insertion de nouvelles données dans une table existante à l'aide de l'instruction INSERT INTO. Vous pouvez insérer de nouvelles lignes dans un tableau de destination basé sur une instruction de requête SELECT qui s'exécute sur un tableau source, ou basé sur un ensemble de valeurs fourni dans le cadre d'une instruction de requête. Formats de données pris en charge : Avro, JSON, ORC, Parquet et fichiers textes.
Les instructions INSERT INTO peuvent également vous aider à simplifier votre processus ETL. Par exemple, vous pouvez utiliser INSERT INTO dans une seule requête pour sélectionner des données d'un tableau source au format JSON et écrire dans un tableau de destination au format Parquet.
Les instructions INSERT INTO sont facturées en fonction du nombre d'octets analysés dans la phase SELECT, de la même manière qu'Athena le fait pour les requêtes SELECT. Pour plus d'informations, consultez la rubrique Tarification Amazon Athena
Pour plus d'informations sur l'utilisationINSERT INTO, y compris les formats pris en charge, SerDes et pour des exemples, voir INSERT INTO dans le guide de l'utilisateur d'Athena.
12 septembre 2019
Date de publication : 17/12/2019
Amazon Athena est désormais disponible dans la région Asie-Pacifique (Hong Kong).
16 août 2019
Date de publication : 17/12/2019
Amazon Athena
Lorsqu'un compartiment Simple Storage Service (Amazon S3) est configuré en tant que Paiement par le demandeur, c'est le demandeur, et non le propriétaire du compartiment, qui paie la requête Simple Storage Service (Amazon S3) et les coûts de transfert des données. Dans Athena, les administrateurs de groupes de travail peuvent désormais configurer les paramètres des groupes de travail pour permettre aux membres de ces derniers d'interroger les compartiments S3 de type Paiement par le demandeur.
Pour plus d'informations sur la configuration du paramètre Paiement par le demandeur pour votre groupe de travail, reportez-vous à la section Création d'un groupe de travail du Guide de l'utilisateur d'Amazon Athena. Pour plus d'informations sur les compartiments de type Paiement par le demandeur, consultez la rubrique Compartiments de type Paiement par le demandeur du Guide du développeur Amazon Simple Storage Service.
9 août 2019
Date de publication : 17/12/2019
Amazon Athena prend désormais en charge l'application de politiques AWS Lake Formation
Vous pouvez utiliser cette fonctionnalité dans les pays suivants Régions AWS : USA Est (Ohio), USA Est (Virginie du Nord), USA Ouest (Oregon), Asie-Pacifique (Tokyo) et Europe (Irlande). Cette fonctionnalité est disponible sans frais additionnels.
Pour plus d’informations sur l’utilisation de cette fonction, consultez Utilisez Athena pour interroger les données enregistrées auprès de AWS Lake Formation. Pour plus d’informations sur AWS Lake Formation, consultez AWS Lake Formation
26 juin 2019
Amazon Athena est désormais disponible dans la région Europe (Stockholm). Pour obtenir la liste des régions prises en charge, consultez Régions AWS et Points de terminaison.
24 mai 2019
Date de publication : 24/05/2019
Amazon Athena est désormais disponible dans les régions AWS GovCloud (US-East) et AWS GovCloud (US-West). Pour obtenir la liste des régions prises en charge, consultez Régions AWS et Points de terminaison.
5 mars 2019
Date de publication : 05/03/2019
Amazon Athena est désormais disponible dans la région Canada (Centre). Pour obtenir la liste des régions prises en charge, consultez Régions AWS et Points de terminaison. Publication de la nouvelle version du pilote ODBC avec prise en charge des groupes de travail Athena. Pour plus d'informations, consultez les Notes de mise à jour du pilote ODBC
Pour télécharger le pilote ODBC version 1.0.5 et sa documentation, consultez Connexion à Amazon Athena avec ODBC. Pour plus d'informations sur cette version, consultez les Notes de mise à jour du pilote ODBC
Pour utiliser des groupes de travail avec le pilote ODBC, définissez la nouvelle propriété de connexion, Workgroup, dans la chaîne de connexion, comme illustré dans l'exemple suivant :
Driver=Simba Athena ODBC Driver;AwsRegion=[Region];S3OutputLocation=[S3Path];AuthenticationType=IAM Credentials;UID=[YourAccessKey];PWD=[YourSecretKey];Workgroup=[WorkgroupName]
Pour plus d'informations, recherchez « groupe de travail » dans le Guide d'installation et de configuration du pilote ODBC version 1.0.5
Ce pilote vous permet d'utiliser des actions de groupe de travail d'API Athena pour créer et gérer des groupes de travail, et des actions d'étiquetage d'API Athena pour ajouter, répertorier ou supprimer des étiquettes sur les groupes de travail. Avant de commencer, veillez à disposer des autorisations au niveau des ressources dans IAM pour exécuter des actions sur les groupes de travail et des étiquettes.
Pour plus d'informations, voir :
Si vous utilisez le pilote JDBC ou le AWS SDK, passez à la dernière version du pilote et du SDK, qui incluent déjà la prise en charge des groupes de travail et des balises dans Athena. Pour de plus amples informations, veuillez consulter Connexion à Amazon Athena avec JDBC.
22 février 2019
Date de publication : 22/02/2019
Ajout de la prise en charge des étiquettes pour les groupes de travail dans Amazon Athena. une identification est constituée d'une clé et d'une valeur que vous définissez. Lorsque vous identifiez un groupe de travail, vous lui attribuez des métadonnées personnalisées. Vous pouvez ajouter des balises aux groupes de travail pour les classer par catégories, en utilisant les meilleures pratiques en matière de AWS balisage. Vous pouvez utiliser des identifications pour limiter l'accès aux groupes de travail et pour suivre les coûts. Par exemple, créez un groupe de travail pour chaque centre de coûts. Ensuite, en ajoutant des étiquettes à ces groupes de travail, vous pouvez suivre vos dépenses Athena pour chaque centre de coûts. Pour plus d'informations, consultez Utilisation d'identifications pour la facturation dans le guide de l'utilisateur AWS Billing and Cost Management .
Vous pouvez travailler avec des étiquettes en utilisant la console Athena ou les opérations d'API. Pour de plus amples informations, veuillez consulter Balisage des ressources Athena.
Dans la console Athena, vous pouvez ajouter une ou plusieurs étiquettes à chacun de vos groupes de travail et effectuer une recherche par étiquette. Les groupes de travail sont une IAM-controlled ressource d'Athena. Dans IAM, vous pouvez limiter les personnes autorisées à ajouter, supprimer ou répertorier des étiquettes sur des groupes de travail que vous créez. Vous pouvez également utiliser l'opération d'API CreateWorkGroup possédant le paramètre d’identification facultative pour ajouter une ou plusieurs identifications au groupe de travail. Pour ajouter, supprimer ou répertorier des identifications, utilisez TagResource, UntagResource et ListTagsForResource. Pour de plus amples informations, veuillez consulter Utiliser les opérations d'API et de AWS CLI balises.
Pour permettre aux utilisateurs d'ajouter des étiquettes lors de la création de groupes de travail, veillez à accorder des autorisations IAM à chaque utilisateur pour exécuter les actions d'API TagResource et CreateWorkGroup. Pour plus d’informations et d’exemples, consultez Utilisation des politiques de contrôle d’accès IAM basé sur des balises.
Aucune modification apportée au pilote JDBC lorsque vous utilisez des identifications sur des groupes de travail. Si vous créez de nouveaux groupes de travail et utilisez le pilote JDBC ou le AWS SDK, passez à la dernière version du pilote et du SDK. Pour plus d'informations, consultez Connexion à Amazon Athena avec JDBC.
18 février 2019
Date de publication : 18/02/2019
Ajout de la possibilité de contrôler les coûts de requête en exécutant des requêtes dans des groupes de travail. Pour plus d'informations, consultez Utilisation de groupes de travail pour contrôler l’accès aux requêtes et les coûts. Amélioration du JSON OpenX SerDe utilisé dans Athena, correction d'un problème en raison duquel Athena n'ignorait pas les objets transférés vers la classe de GLACIER stockage et ajout d'exemples d'interrogation des journaux Network Load Balancer.
Modifications suivantes effectuées :
-
Ajout de la prise en charge des groupes de travail. Utilisation de groupes de travail pour séparer les utilisateurs, les équipes, les applications ou les charges de travail, et pour définir des limites au volume de données pouvant être traité par chaque requête ou groupe de travail entier. Vous pouvez utiliser des autorisations au niveau des ressources IAM pour contrôler l'accès à un groupe de travail spécifique, car les groupes de travail agissent en tant que ressources IAM. Vous pouvez également consulter les métriques relatives aux requêtes dans Amazon CloudWatch, contrôler les coûts des requêtes en limitant la quantité de données numérisées, créer des seuils et déclencher des actions, telles que des alarmes Amazon SNS, lorsque ces seuils sont dépassés. Pour plus d’informations, consultez Utilisation de groupes de travail pour contrôler l’accès aux requêtes et les coûts et Utiliser CloudWatch et EventBridge surveiller les requêtes et contrôler les coûts.
Les groupes de travail sont une ressource IAM. Pour une liste complète des actions, ressources et conditions liées aux groupes de travail dans IAM, consultez la rubrique Actions, ressources et clés de condition pour Amazon Athena dans la Référence d'autorisation de service. Avant de créer de nouveaux groupes de travail, assurez-vous que vous utilisez des politiques IAM de groupe de travail et la AWS politique gérée : AmazonAthenaFullAccess.
Vous pouvez utiliser des groupes de travail dans la console, avec les opérations d’API de groupe de travail ou avec le pilote JDBC. Pour de plus amples informations sur la création de stratégies pour les groupes de travail , consultez Créer un groupe de travail. Pour télécharger le pilote JDBC avec prise en charge de groupe de travail, consultez Connexion à Amazon Athena avec JDBC.
Si vous utilisez des groupes de travail avec le pilote JDBC, vous devez définir le nom du groupe de travail dans la chaîne de connexion à l'aide du paramètre de configuration
Workgroup, comme illustré dans l'exemple suivant :jdbc:awsathena://AwsRegion=<AWSREGION>;UID=<ACCESSKEY>; PWD=<SECRETKEY>;S3OutputLocation=s3://amzn-s3-demo-bucket/<athena-output>-<AWSREGION>/; Workgroup=<WORKGROUPNAME>;Aucune modification dans la manière d'exécuter des instructions SQL ou d'effectuer des appels d'API JDBC au pilote. Le pilote transmet le nom du groupe de travail à Athena.
Pour obtenir des informations sur les différences introduites avec les groupes de travail, consultez Utiliser le groupe de travail Athena APIs et Correction des erreurs liées aux groupes de travail.
-
Amélioration du JSON OpenX SerDe utilisé dans Athena. Ces améliorations incluent, sans toutefois s'y limiter :
-
Prise en charge de la propriété
ConvertDotsInJsonKeysToUnderscores. Lorsqu'il est défini surTRUE, il permet de SerDe remplacer les points dans les noms clés par des traits de soulignement. Par exemple, si le jeu de données JSON contient une clé portant le nom"a.b", vous pouvez utiliser cette propriété pour définir le nom de la colonne comme étant"a_b"dans Athena. La valeur par défaut estFALSE. Par défaut, Athena n'autorise pas les points dans les noms de colonnes. -
Prise en charge de la propriété
case.insensitive. Par défaut, Athena exige que toutes les clés de votre jeu de données JSON soient en minuscules.WITH SERDE PROPERTIES ("case.insensitive"= FALSE;)vous permet d'utiliser des noms de clé sensibles à la casse dans vos données. La valeur par défaut estTRUE. Lorsqu'il est défini surTRUE, il SerDe convertit toutes les colonnes majuscules en minuscules.
Pour de plus amples informations, veuillez consulter OpenX JSON SerDe.
-
-
Correction d'un problème à cause duquel le service Athena renvoyait des messages d'erreur
"access denied"lorsqu'il traitait des objets Simple Storage Service (Amazon S3) archivés dans Glacier par des politiques de cycle de vie Simple Storage Service (Amazon S3). Suite à la correction de ce problème, Athena ignore les objets passés à la classe de stockageGLACIER. Athena ne prend pas en charge l'interrogation des données à partir de la classe de stockageGLACIER.Pour plus d'informations, veuillez consulter les rubriques Éléments à prendre en compte concernant Amazon S3 et Transition vers la classe de stockage GLACIER (archivage d'objets) du Guide de l'utilisateur Amazon Simple Storage Service.
-
Ajout d'exemples d'interrogation des journaux d'accès du Network Load Balancer qui reçoivent des informations sur les requêtes TLS (Transport Layer Security, Sécurité de la couche de transport). Pour de plus amples informations, veuillez consulter Interrogation des journaux du Network Load Balancer.
Notes de publication d'Athena pour 2018
20 novembre 2018
Date de publication : 20/11/2018
Lancement des nouvelles versions des pilotes JDBC et ODBC avec prise en charge de l'accès fédéré à l'API Athena avec AD FS et SAML 2.0 (Security Assertion Markup Language 2.0). Pour plus de détails, consultez les Notes de mise à jour du pilote JDBC
Avec cette version, l'accès fédéré à Athena est pris en charge pour Active Directory Federation Service (AD FS 3.0). L'accès est établi via les versions des pilotes JDBC ou ODBC prenant en charge SAML 2.0. Pour en savoir plus sur la configuration de l'accès fédéré à l'API Athena, voir Activation de l’accès fédéré à l’API Athena.
Pour télécharger le pilote JDBC version 2.0.6 et sa documentation, consultez Connexion à Amazon Athena avec JDBC. Pour plus d'informations sur cette version, consultez les Notes de mise à jour du pilote JDBC
Pour télécharger le pilote ODBC version 1.0.4 et sa documentation, consultez Connexion à Amazon Athena avec ODBC. Pour plus d'informations sur cette version, consultez les Notes de mise à jour du pilote ODBC
Pour plus d'informations sur la prise en charge de SAML 2.0 dans AWS, voir À propos de la fédération SAML 2.0 dans le guide de l'utilisateur IAM.
15 octobre 2018
Date de publication : 15/10/2018
Si vous avez effectué la mise à niveau vers le AWS Glue Data Catalog, deux nouvelles fonctionnalités permettent de prendre en charge les éléments suivants :
-
Chiffrement des métadonnées du catalogue de données. Si vous choisissez de chiffrer les métadonnées dans le catalogue de données, vous devez ajouter des politiques spécifiques à Athena. Pour en savoir plus, consultez Accès aux métadonnées chiffrées dans le AWS Glue Data Catalog.
-
Fine-grained autorisations d'accès aux ressources du AWS Glue Data Catalog. Vous pouvez désormais définir des politiques basées sur l'identité (IAM) qui restreignent ou autorisent l'accès à des bases de données et des tables spécifiques à partir du catalogue de données utilisé dans Athena. Pour de plus amples informations, veuillez consulter Configurez l'accès aux bases de données et aux tables dans le AWS Glue Data Catalog.
Note
Les données résident dans les compartiments Amazon S3 et leur accès est contrôlé par Contrôle de l’accès à Amazon S3 depuis Athena. Pour accéder aux données des bases de données et des tables, continuez à utiliser des politiques de contrôle d'accès aux compartiments Simple Storage Service (Amazon S3) qui stockent les données.
10 octobre 2018
Date de publication : 10/10/2018
Athena prend en charge CREATE TABLE AS SELECT, ce qui crée une table à partir du résultat d'une instruction de requête SELECT. Pour plus de détails, consultez la section Création d'une table à partir des résultats des requêtes (CTAS).
Avant de créer des requêtes CTAS, il est important d'en savoir plus sur leur comportement dans la documentation Athena. Elle contient des informations sur l'emplacement pour enregistrer les résultats de requête dans Simple Storage Service (Amazon S3), la liste des formats pris en charge pour stocker les résultats de requête CTAS, le nombre de partitions que vous pouvez créer et les formats de compression pris en charge. Pour de plus amples informations, veuillez consulter Considérations et limitations relatives aux requêtes CTAS.
Utilisez les requêtes CTAS pour :
-
Créez une table à partir des résultats de la requête en une étape.
-
Créez des requêtes CTAS dans la console Athena, à l'aide d'exemples. Pour obtenir des informations sur la syntaxe, consultez CREATE TABLE AS.
-
Transformez les résultats des requêtes en d'autres formats de stockage, tels que PARQUET, ORC, AVRO, JSON et TEXTFILE. Pour plus d’informations, consultez Considérations et limitations relatives aux requêtes CTAS et Utilisation des formats de stockage en colonnes.
6 septembre 2018
Date de publication : 06/09/2018
Publication de la nouvelle version du pilote ODBC (version 1.0.3). La nouvelle version du pilote ODBC diffuse les résultats par défaut, au lieu de les paginer, ce qui permet aux outils de business intelligence de récupérer de grands ensembles de données plus rapidement. Cette version inclut également des améliorations, des correctifs de bogues et une mise à jour de la documentation pour « Utilisation de SSL avec un serveur proxy ». Pour plus de détails, consultez les Notes de mise à jour
Pour plus d'informations sur le téléchargement du pilote ODBC version 1.0.3 et de sa documentation, consultez Connexion à Amazon Athena avec ODBC.
La fonction de streaming des résultats est uniquement disponible avec cette nouvelle version du pilote ODBC. Elle est également disponible avec le pilote JDBC. Pour plus d'informations sur les résultats du streaming, consultez le Guide d'installation et de configuration du pilote ODBC
Le pilote ODBC version 1.0.3 remplace la version précédente du pilote. Nous vous recommandons de migrer vers le pilote en cours.
Important
Pour utiliser le pilote ODBC version 1.0.3, suivez ces exigences :
-
Gardez le port 444 ouvert pour le trafic sortant.
-
Ajoutez l'action de politique
athena:GetQueryResultsStreamà la liste des politiques pour Athena. Cette action de politique n'est pas exposée directement avec l'API et est utilisé uniquement avec les pilotes ODBC et JDBC, dans le cadre de la prise en charge des résultats de streaming. Pour un exemple de politique, consultez AWS politique gérée : AWSQuicksight AthenaAccess.
23 août 2018
Date de publication : 23/08/2018
Ajout du support pour ces DDL-related fonctionnalités et correction de plusieurs bogues, comme suit :
-
Ajout de la prise en charge pour les types de données
BINARYetDATEdes données dans Parquet, et pour les types de donnéesDATEetTIMESTAMPpour les données dans Avro. -
Ajout de la prise en charge de
INTetDOUBLEdans les requêtes DDL.INTEGERest un alias deINTetDOUBLE PRECISIONun alias deDOUBLE. -
Amélioration des performances des requêtes
DROP TABLEetDROP DATABASE. -
Suppression de la création d'un objet
_$folder$dans Simple Storage Service (Amazon S3) lorsqu'un compartiment de données est vide. -
Résolution d'un problème où
ALTER TABLE ADD PARTITIONgénère une erreur quand aucune valeur de partition n'a été fournie. -
Résolution d'un problème où
DROP TABLEa ignoré le nom de base de données lors de la vérification des partitions après que le nom qualifié a été spécifié dans l'instruction.
Pour plus d'informations sur les types de données prises en charge dans Athena, consultez Types de données dans Amazon Athena.
Pour en savoir plus sur les types de mappages entre des types de données pris en charge dans Athena, le pilote JDBC et les types de données Java, consultez la section « Types de données » du Guide de configuration et d'installation du pilote JDBC
16 août 2018
Date de publication : 16/08/2018
Publication du pilote JDBC version 2.0.5. La nouvelle version du pilote JDBC diffuse les résultats par défaut, au lieu de les paginer, ce qui permet aux outils de business intelligence de récupérer de grands ensembles de données plus rapidement. Par rapport à la version précédente du pilote JDBC, il y a les améliorations de performances suivantes :
-
Augmentation des performances de 2 fois environ lors de l'extraction des performances de moins de 10 000 lignes.
-
Augmentation des performances de 5 à 6 fois environ lors de l'extraction des performances de plus de 10 000 lignes.
La fonction de streaming des résultats est uniquement disponible avec le pilote JDBC. Elle n'est pas disponible avec le pilote ODBC. Vous ne pouvez pas l'utiliser avec l'API Athena. Pour plus d'informations sur les résultats du streaming, consultez le Guide d'installation et de configuration du pilote JDBC
Pour plus d'informations sur le téléchargement du pilote JDBC version 2.0.5 et de sa documentation, consultez Connexion à Amazon Athena avec JDBC.
Le pilote JDBC version 2.0.5 remplace la version précédente du pilote (2.0.2). Pour vous assurer que vous pouvez utiliser le pilote JDBC en version 2.0.5, ajoutez la politique d'action athena:GetQueryResultsStream à la liste des politiques pour Athena. Cette action de politique n'est pas exposée directement avec l'API et est utilisé uniquement avec le pilote JDBC, dans le cadre de la prise en charge des résultats de streaming. Pour un exemple de politique, consultez AWS politique gérée : AWSQuicksight AthenaAccess. Pour plus d'informations sur la migration vers la version 2.0.2 depuis la version 2.0.5 du pilote, consultez le Guide de migration du pilote JDBC
Si vous effectuez une migration depuis un pilote 1.x vers un pilote 2.x, vous devrez migrer vos configurations existantes vers la nouvelle configuration. Nous vous recommandons vivement de migrer vers la version courante du pilote. Pour plus d’informations, consultez le Guide de la migration du pilote JDBC
7 août 2018
Date de publication : 07/08/2018
Vous pouvez désormais stocker les journaux de flux du cloud privé virtuel d'Amazon directement dans Simple Storage Service (Amazon S3) au format GZIP, où vous pouvez les interroger dans Athena. Pour obtenir des informations, consultez Interrogation des journaux de flux Amazon VPC et . Les journaux de flux Amazon VPC peuvent désormais être diffusés vers S3
5 juin 2018
Date de publication : 05/06/2018
Rubriques
Prise en charge des vues
Ajout de la prise en charge des vues. Vous pouvez désormais utiliser CREATE VIEW et CREATE PROTECTED MULTI DIALECT VIEW, DESCRIBE VIEW, DROP VIEW, SHOW CREATE VIEW et SHOW VIEWS dans Athena. La requête qui définit la vue est exécutée chaque fois que vous référencez la vue dans votre requête. Pour de plus amples informations, veuillez consulter Utilisation de vues.
Améliorations et mises à jour des messages d'erreur
-
Une bibliothèque GSON 2.8.0 a été incluse dans le CloudTrail SerDe, afin de résoudre un problème lié à l'analyse des chaînes JSON CloudTrail SerDe et de permettre leur analyse.
-
Amélioration de la validation du schéma de partition dans Athena pour Parquet et, dans certains cas, pour ORC, en permettant la réorganisation des colonnes. Cela permet à Athena de mieux gérer les modifications de l'évolution du schéma au fil du temps et les tables ajoutées par le AWS Glue Crawler. Pour de plus amples informations, veuillez consulter Gestion des mises à jour de schéma.
-
Ajout de la prise en charge de l'analyse pour
SHOW VIEWS. -
Améliorations suivantes apportées à la plupart des messages d'erreur courants :
-
Un message d'
erreur internea été remplacé par un message d'erreur descriptif en cas d' SerDe échec de l'analyse de la colonne dans une requête Athena. Auparavant, Athena émettait une erreur interne en cas d'erreurs d'analyse. Le nouveau message d'erreur indique :« HIVE_BAD_DATA: Error parsing field value for field 0: java.lang.String cannot be cast to org.openx.data.jsonserde.json.JSONObject ». -
Amélioration des messages d'erreur concernant des autorisations insuffisantes par l'ajout de détails.
-
Correctifs de bogue
Les bogues suivants ont été corrigés :
-
Résolution d'un problème qui permet la conversion de
REALen types de donnéesFLOAT. Cela améliore l'intégration au Crawler AWS Glue qui renvoie les types de donnéesFLOAT. -
Correction d'un problème où Athena ne convertissait pas AVRO
DECIMAL(un type logique) en un typeDECIMAL. -
Correction d'un problème pour lequel Athena ne renvoyait pas les résultats des requêtes sur les données Parquet avec des clauses
WHEREfaisant référence à des valeurs dans le type de donnéesTIMESTAMP.
17 mai 2018
Date de publication : 17/05/2018
Augmentation des quotas de simultanéité des requêtes dans Athena de cinq à vingt. Cela signifie que vous pouvez soumettre et exécuter jusqu'à vingt requêtes DDL et vingt requêtes SELECT en même temps. Notez que les quotas de simultanéité sont distincts pour les requêtes DDL et SELECT.
Les quotas de simultanéité dans Athena sont définis en tant que nombre de requêtes pouvant être soumises au service simultanément. Vous pouvez soumettre jusqu'à vingt requêtes du même type (DDL or SELECT) en même temps. Si vous soumettez une requête dépassant le quota de requêtes simultanées, l'API Athena affiche un message d'erreur.
Une fois vos requêtes soumises à Athena, celui-ci traite les requêtes en affectant des ressources en fonction de la charge de service globale et du volume de demandes entrantes. Nous surveillons et apportons en continu les ajustements de service afin que le traitement de vos requêtes soit aussi rapide que possible.
Pour plus d'informations, consultez Service Quotas. Il s'agit d'un quota ajustable. Vous pouvez utiliser la console Service Quotas
19 avril 2018
Date de publication : 19/04/2018
Publication de la nouvelle version du pilote JDBC (version 2.0.2) avec prise en charge du renvoi de données ResultSet en tant que type de données Tableau, améliorations et correctifs de bogue. Pour plus de détails, consultez les Notes de mise à jour
Pour plus d'informations sur le téléchargement du nouveau pilote JDBC version 2.0.2 et de sa documentation, consultez Connexion à Amazon Athena avec JDBC.
La version la plus récente du pilote JDBC est la version 2.0.2. Si vous effectuez une migration depuis un pilote 1.x vers un pilote 2.x, vous devrez migrer vos configurations existantes vers la nouvelle configuration. Nous vous recommandons vivement de migrer vers le pilote en cours.
Pour plus d'informations sur les changements introduits dans la nouvelle version du pilote, les différences de version, et des exemples, consultez la section JDBC Driver Migration Guide
6 avril 2018
Date de publication : 06/04/2018
Utilisation de la saisie semi-automatique pour saisir des requêtes dans la console Athena.
15 mars 2018
Date de publication : 15/03/2018
Ajout de la possibilité de créer automatiquement des tables Athena pour les fichiers CloudTrail journaux directement depuis la CloudTrail console. Pour plus d'informations, consultez Utiliser la CloudTrail console pour créer une table Athena pour les journaux CloudTrail.
2 février 2018
Date de publication : 12/02/2018
Ajout de la possibilité de décharger en toute sécurité des données intermédiaires sur le disque pour les requêtes nécessitant beaucoup de mémoire qui utilisent la clause GROUP BY. Cela permet d'améliorer la fiabilité de ces requêtes et empêche les erreurs liées à l'épuisement des ressources de requête.
19 janvier 2018
Date de publication : 19/01/2018
Athena utilise Presto, un moteur de requête open source, pour exécuter des requêtes.
Avec Athena, il n'y a pas de versions à gérer. Nous avons mis à niveau de façon transparente le moteur sous-jacent dans Athena vers une version basée sur Presto version 0.172. Aucune action de votre part n'est nécessaire.
Grâce à la mise à niveau, vous pouvez désormais utiliser les fonctions et opérateurs Presto 0.172, y compris les expressions Lambda Presto 0.172 dans Athena.
Les mises à jour majeures de cette version, y compris les corrections développées par la communauté, incluent :
-
Prise en charge du non-respect des en-têtes. Vous pouvez utiliser la propriété
skip.header.line.countlors de la définition de tables pour autoriser Athena à ignorer les en-têtes. Ceci est pris en charge pour les requêtes qui utilisent SerDeOpenCSV LazySimpleSerDeet non pour Grok ou Regex. SerDes -
Prise en charge du type de données
CHAR(n)dans les fonctionsSTRING. La plage pourCHAR(n)est[1.255], tandis que la plage pourVARCHAR(n)est[1,65535]. -
Prise en charge des sous-requêtes corrélées.
-
Prise en charge des expressions et fonctions lambda Presto.
-
Amélioration des performances du type
DECIMALet des opérateurs. -
Prise en charge des agrégations filtrées, telles que
SELECT sum(col_name) FILTER, oùid > 0. -
Push-down prédicats pour les types de
REALdonnéesDECIMALTINYINTSMALLINT,, et. -
Prise en charge des prédicats de comparaison quantifiée :
ALL,ANYetSOME. -
Ajout des fonctions :
arrays_overlap(), array_except(), levenshtein_distance(), codepoint(), skewness(), kurtosis()et typeof(). -
Ajout d'une variante de la fonction
from_unixtime()qui accepte un argument de fuseau horaire. -
Ajout des fonctions d'agrégation
bitwise_and_agg()et bitwise_or_agg(). -
Ajout des fonctions
xxhash64()et to_big_endian_64(). -
Ajout de la prise en charge de l'échappement des guillemets doubles et des barres obliques inverses à l'aide d'une barre oblique inverse et d'un indice de chemin JSON vers les fonctions
json_extract()et json_extract_scalar(). Cela change la sémantique de toute invocation utilisant une barre oblique inverse, étant donné que les barres obliques inverses étaient précédemment considérées comme des caractères normaux.
Pour plus d'informations sur les fonctions et les opérateurs, voir Requêtes, fonctions et opérateurs DML dans ce guide et Fonctions et opérateurs
Athena ne prend pas en charge toutes les fonctions Presto. Pour plus d’informations, consultez Limites.
Notes de publication d'Athena pour 2017
13 novembre 2017
Date de publication : 13/11/2017
Ajout de la prise en charge de la connexion d'Athena au pilote ODBC. Pour plus d'informations, consultez Connexion à Amazon Athena avec ODBC.
1er novembre 2017
Date de publication : 01/11/2017
Ajout de la prise en charge pour les requêtes de données géospatiales, et pour les régions Asie-Pacifique (Séoul), Asie-Pacifique (Mumbai) et UE (Londres). Pour plus d'informations, consultez Interrogation des données géospatiales, Régions AWS et Points de terminaison.
19 octobre 2017
Date de publication : 19/10/2017
Ajout de la prise en charge pour UE (Francfort). Pour accéder à la liste des régions prises en charge, consultez Régions AWS et Points de terminaison.
3 octobre 2017
Date de publication : 03/10/2017
Créez des requêtes Athena nommées avec. CloudFormation Pour plus d'informations, voir AWS::Athena: : NamedQuery dans le guide de AWS CloudFormation l'utilisateur.
25 septembre 2017
Date de publication : 25/09/2017
Ajout de la prise en charge de l'Asie-Pacifique (Sydney). Pour accéder à la liste des régions prises en charge, consultez Régions AWS et Points de terminaison.
14 août 2017
Date de publication : 14/08/2017
Intégration ajoutée avec le AWS Glue Data Catalog et assistant de migration pour la mise à jour du catalogue de données géré Athena vers le. AWS Glue Data Catalog Pour de plus amples informations, veuillez consulter AWS Glue Data Catalog À utiliser pour vous connecter à vos données.
4 août 2017
Date de publication : 04/08/2017
Ajout de la prise en charge de Grok SerDe, qui facilite la correspondance de modèles pour les enregistrements dans des fichiers texte non structurés tels que les journaux. Pour de plus amples informations, veuillez consulter Grok SerDe. Ajout de raccourcis clavier pour faire défiler l'historique des requêtes à l'aide de la console (CTRL+⇧/⇩ dans Windows, CMD+⇧/⇩ sur Mac).
22 juin 2017
Date de publication : 22/06/2017
Ajout de la prise en charge des régions Asie-Pacifique (Tokyo) et Asie-Pacifique (Singapour). Pour accéder à la liste des régions prises en charge, consultez Régions AWS et Points de terminaison.
8 juin 2017
Date de publication : 08/06/2017
Ajout de la prise en charge de l'Europe (Irlande). Pour plus d’informations, consultez Régions AWS and Endpoints.
19 mai 2017
Date de publication : 19/05/2017
Ajout d'une API Amazon Athena et AWS CLI prise en charge d'Athena ; mise à jour du pilote JDBC vers la version 1.1.0 ; résolution de divers problèmes.
-
Amazon Athena permet la programmation d'application pour Athena. Pour plus d'informations, consultez la Référence d'API Amazon Athena. Les derniers AWS SDK prennent en charge l'API Athena. Pour des liens vers la documentation et les téléchargements, consultez la section SDK dans Outils pour Amazon Web Services
. -
AWS CLI Cela inclut de nouvelles commandes pour Athéna. Pour plus d'informations, consultez la rubrique Référence d'API Amazon Athena.
-
Un nouveau pilote JDBC 1.1.0 est disponible, qui prend en charge la nouvelle API Athena ainsi que les dernières fonctionnalités et corrections de bogues. Téléchargez le pilote sur https://downloads.athena.us-east-1.amazonaws.com/drivers/AthenaJDBC41-1.1.0.jar
. Nous vous recommandons d'effectuer la mise à niveau vers la dernière version du pilote JDBC d'Athena. Toutefois, vous pouvez encore utiliser l'ancienne version du pilote. Les versions antérieures du pilote ne prennent pas en charge l'API Athena. Pour de plus amples informations, veuillez consulter Connexion à Amazon Athena avec JDBC. -
Les actions spécifiques aux déclarations de politique dans les versions antérieures d'Athena sont désormais obsolètes. Si vous effectuez une mise à niveau vers la version 1.1.0 du pilote JDBC et avez des politiques IAM en ligne ou gérées par le client, associées aux utilisateurs JDBC, vous devez mettre à jour les politiques IAM. En revanche, les versions antérieures du pilote JDBC ne prennent pas en charge l'API Athena, si bien que vous pouvez spécifier uniquement des actions obsolètes dans les politiques associées aux utilisateurs d'une version antérieure de JDBC. C'est pourquoi vous ne devriez pas avoir besoin de mettre à jour les politiques IAM en ligne ou gérées par le client.
-
Ces actions spécifiques de politique ont été utilisées dans Athena avant la parution de l'API Athena. Utilisez ces actions obsolètes dans les politiques uniquement avec les pilotes JDBC antérieurs à la version 1.1.0. Si vous mettez à niveau le pilote JDBC, remplacez les déclarations de politique qui autorisent ou refusent les actions obsolètes par les actions d'API appropriées telles que listées, sinon des erreurs se produiront.
| Action déconseillée Policy-Specific | Action d'API Athena correspondante |
|---|---|
|
|
|
|
|
|
Améliorations
-
Augmentation de la longueur limite des chaînes de requête à 256 Ko.
Correctifs de bogue
-
Correction d'un problème selon lequel des résultats de requête semblaient incorrects lorsque vous les faisiez défiler dans la console.
-
Correction d'un problème selon lequel une chaîne de caractères
\u0000dans des fichiers de données Simple Storage Service (Amazon S3) entraînait des erreurs. -
Correction d'un problème qui provoquait l'échec des demandes d'annulation d'une requête effectuée via le pilote JDBC.
-
Correction d'un problème qui provoquait AWS CloudTrail SerDe l'échec des données Amazon S3 dans l'est des États-Unis (Ohio).
-
Résolution d'un problème lié à l'échec de
DROP TABLEsur une table partitionnée.
4 avril 2017
Date de publication : 04/04/2017
Ajout de la prise en charge du chiffrement des données Simple Storage Service (Amazon S3) et publication de la mise à jour du pilote JDBC (version 1.0.1) avec des améliorations de la prise en charge du chiffrement et des corrections de bogues.
Caractéristiques
-
Les fonctionnalités de chiffrement suivantes ont été ajoutées :
-
Prise en charge des requêtes de données chiffrées dans Simple Storage Service (Amazon S3).
-
Prise en charge du chiffrement des résultats de requête Athena.
-
-
Une nouvelle version du pilote prend en charge les nouvelles fonctions de chiffrement, ajoute des améliorations et corrige des bogues.
-
Ajout de la possibilité d'ajouter, de remplacer et de modifier des colonnes avec
ALTER TABLE. Pour plus d'informations, consultez Alter Columndans la documentation Hive. -
Ajout de la prise en charge des requêtes de LZO-compressed données.
Pour de plus amples informations, veuillez consulter Chiffrement au repos.
Améliorations
-
Meilleures performances des requêtes JDBC avec une taille de page améliorée, renvoyant 1 000 lignes au lieu de 100.
-
Ajout de la possibilité d'annuler une requête à l'aide de l'interface du pilote JDBC.
-
Ajout de la possibilité de spécifier des options JDBC dans l'URL de connexion JDBC. Consultez Connexion à Amazon Athena avec JDBC pour obtenir le pilote JDBC le plus récent.
-
Ajout du paramètre PROXY dans le pilote, qui peut désormais être défini ClientConfigurationdans le AWS SDK for Java.
Correctifs de bogue
Les bogues suivants ont été corrigés :
-
Des erreurs de limitation pouvaient se produire lorsque plusieurs requêtes étaient émises via l'interface du pilote JDBC.
-
Le pilote JDBC s'interrompait lors de la projection d'un type de données décimal.
-
Le pilote JDBC renvoyait chaque type de données sous la forme d'une chaîne, quelle qu'était la façon dont le type de données était défini dans la table. Par exemple, la sélection d'une colonne définie comme type de données
INTen utilisantresultSet.GetObject()renvoyait un type de donnéesSTRINGà la place d'un typeINT. -
Le pilote JDBC vérifiait les informations d'identification au moment où une connexion était effectuée, plutôt qu'au moment où une requête était exécutée.
-
Les requêtes effectuées via le pilote JDBC échouaient lorsqu'un schéma était spécifié avec l'URL.
24 mars 2017
Date de publication : 24/03/2017
Ajout de l' AWS CloudTrail SerDeamélioration des performances, résolution des problèmes de partition.
Caractéristiques
-
Ajouté le AWS CloudTrail SerDe, qui a depuis été remplacé par le Hive JSON SerDe pour lire CloudTrail les journaux. Pour plus d'informations sur l'interrogation CloudTrail des journaux, consultezAWS CloudTrail Journaux de requêtes.
Améliorations
-
Amélioration des performances lors de l'analyse d'un grand nombre de partitions.
-
Amélioration des performances sur l'opération
MSCK Repair Table. -
Ajout de la possibilité d'exécuter des requêtes sur les données Simple Storage Service (Amazon S3) stockées dans des régions autres que votre région principale. Les taux standard de transfert de données entre régions pour Simple Storage Service (Amazon S3) s'appliquent en plus des frais Athena standard.
Correctifs de bogue
-
Correction d'un bogue qui entraînait éventuellement une erreur de type « table introuvable » si aucune partition n'était chargée.
-
Correction d'un bogue pour éviter de lever une exception avec les requêtes
ALTER TABLE ADD PARTITION IF NOT EXISTS. -
Correction d'un bogue dans
DROP PARTITIONS.
20 février 2017
Date de publication : 20/02/2017
Ajout de la AvroSerDe prise en charge de la région USA Est (Ohio) et de la modification groupée de colonnes dans l'assistant de console. OpenCSVSerDe Amélioration des performances sur les tables Parquet volumineuses.
Caractéristiques
-
Support introduit pour les nouveaux SerDes :
-
Lancement de la région USA Est (Ohio) (us-east-2). Vous pouvez désormais exécuter des requêtes dans cette région.
-
Vous pouvez désormais utiliser le formulaire Create Table From S3 bucket data (Créer une table à partir des données du compartiment S3) pour définir le schéma de table en bloc. Dans l’éditeur de requêtes, sélectionnez Créer, Données du compartiment S3, puis Ajouter des colonnes en bloc dans la section Détails de la colonne.
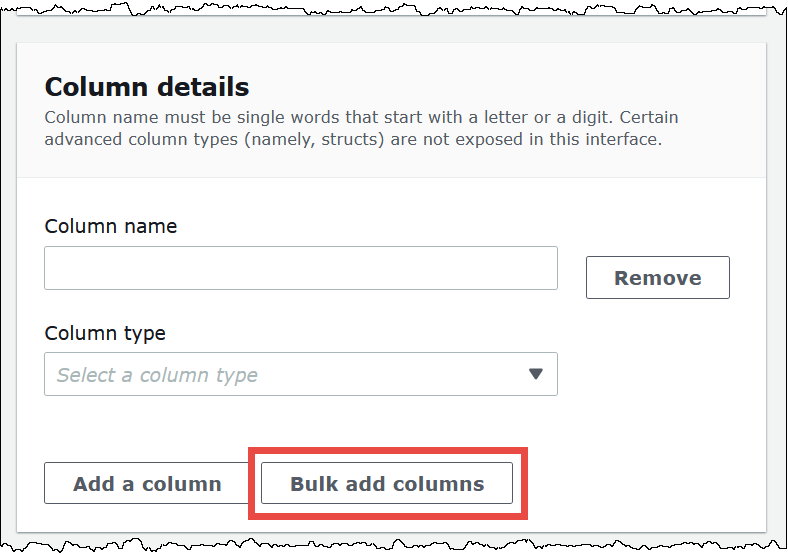
Tapez des paires nom/valeur dans la zone de texte et choisissez Add.
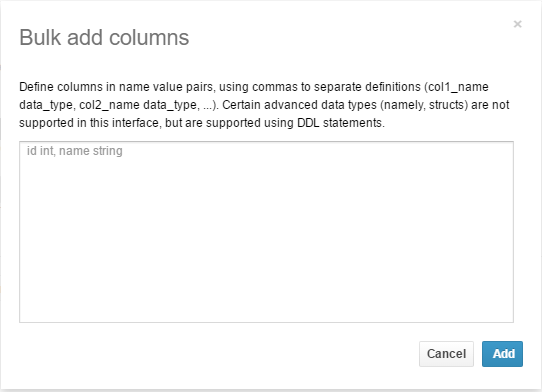
Améliorations
-
Amélioration des performances sur les tables Parquet volumineuses.
