Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Membuat klaster DB Aurora tanpa kepala di Wilayah sekunder
Meskipun database global Aurora memerlukan setidaknya satu cluster Aurora DB sekunder yang berbeda Wilayah AWS dari yang utama, Anda dapat menggunakan konfigurasi tanpa kepala untuk cluster sekunder. Klaster DB Aurora sekunder tanpa kepala adalah klaster DB Aurora sekunder yang tidak memiliki instans DB. Jenis konfigurasi ini dapat menurunkan biaya untuk basis data global Aurora. Dalam klaster DB Aurora, komputasi dan penyimpanan dipisahkan. Tanpa instans DB, Anda tidak dikenakan biaya untuk komputasi, hanya untuk penyimpanan. Jika diatur dengan benar, volume penyimpanan sekunder tanpa kepala tetap sinkron dengan klaster DB Aurora primer.
Anda menambahkan klaster sekunder seperti yang biasanya Anda lakukan saat membuat basis data global Aurora. Jika Anda membuat semua cluster di database global, ikuti prosedur diMembuat basis data global Amazon Aurora. Jika Anda sudah memiliki cluster DB untuk digunakan sebagai cluster utama, ikuti prosedur diMenambahkan Wilayah AWS ke database global Amazon Aurora.
Setelah cluster Aurora DB primer memulai replikasi ke sekunder, Anda menghapus instans DB hanya-baca Aurora dari cluster Aurora DB sekunder. Klaster sekunder ini sekarang dianggap “tanpa kepala” karena sudah tidak memiliki instans DB. Bahkan tanpa instans DB di cluster sekunder, Aurora menjaga volume penyimpanan tetap sinkron dengan cluster Aurora DB utama.
Awas
Dengan Aurora PostgreSQL, untuk membuat klaster tanpa kepala di sekunder Wilayah AWS, gunakan atau RDS API untuk menambahkan sekunder. AWS CLI Wilayah AWS Lewati langkah ini untuk membuat instans DB pembaca untuk klaster sekunder. Saat ini, membuat klaster tanpa kepala tidak didukung di konsol RDS. Untuk prosedur CLI dan API yang akan digunakan, lihat Menambahkan Wilayah AWS ke database global Amazon Aurora.
Jika database global Anda menggunakan versi mesin PostgreSQL Aurora yang lebih rendah dari 13.4, 12.8, atau 11.13, membuat instans DB pembaca di Wilayah sekunder dan kemudian menghapusnya dapat menyebabkan masalah vakum Aurora PostgreSQL pada instans DB penulis Wilayah utama. Jika Anda mengalami masalah ini, mulai ulang instans DB penulis Wilayah primer setelah Anda menghapus instans DB pembaca sekunder Wilayah tersebut.
Menambahkan klaster DB Aurora sekunder tanpa kepala ke basis data global Aurora Anda
Masuk ke Konsol Manajemen AWS dan buka konsol Amazon RDS di https://console.aws.amazon.com/rds/
. -
Di panel navigasi Konsol Manajemen AWS, pilih Database.
-
Pilih basis data global Aurora yang membutuhkan klaster DB Aurora sekunder. Pastikan klaster DB Aurora primer berstatus
Available. -
Untuk Tindakan, pilih Tambah AWS Wilayah.
-
Pada halaman Tambahkan wilayah, pilih yang kedua Wilayah AWS.
Anda tidak dapat memilih Wilayah AWS yang sudah memiliki cluster Aurora DB sekunder untuk database global Aurora yang sama. Selain itu, Wilayah tersebut tidak boleh sama dengan Wilayah klaster DB Aurora primer.
-
Lengkapi bidang yang tersisa untuk cluster Aurora sekunder di yang baru. Wilayah AWS Opsi konfigurasi ini sama dengan opsi konfigurasi untuk setiap instans klaster DB Aurora.
Untuk basis data global Aurora berbasis Aurora MySQL, abaikan opsi Aktifkan penerusan tulis replika baca. Opsi ini tidak memiliki fungsi setelah Anda menghapus instans pembaca.
Pilih Tambah AWS Wilayah. Setelah Anda selesai menambahkan Wilayah ke database global Aurora Anda, Anda dapat melihatnya di daftar Database Konsol Manajemen AWS seperti yang ditunjukkan pada tangkapan layar.

Periksa status cluster Aurora DB sekunder dan instance pembacanya sebelum melanjutkan, dengan menggunakan Konsol Manajemen AWS atau. AWS CLI Contoh:
$aws rds describe-db-clusters --db-cluster-identifiersecondary-cluster-id--query '*[].[Status]' --output textMungkin diperlukan waktu beberapa menit hingga status klaster DB Aurora sekunder yang baru ditambahkan berubah dari
creatingmenjadiavailable. Ketika klaster DB Aurora tersedia, Anda dapat menghapus instans pembaca.Pilih instans pembaca di klaster DB Aurora sekunder, kemudian pilih Hapus.

Setelah menghapus instans pembaca, klaster sekunder tetap menjadi bagian basis data global Aurora. Klaster tersebut tidak memiliki instans yang terkait dengannya, seperti yang ditunjukkan berikut ini.
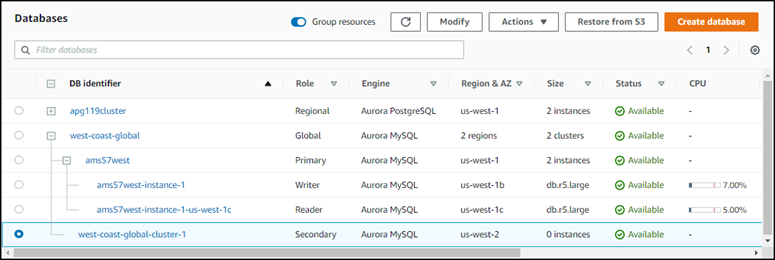
Anda dapat menggunakan klaster DB Aurora sekunder tanpa kepala ini untuk secara manual memulihkan basis data global Amazon Aurora Anda dari pemadaman yang tidak direncanakan di Wilayah AWS primer jika terjadi pemadaman seperti itu.
