Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Aurora Integrasi nol-ETL
Ini adalah solusi yang dikelola sepenuhnya untuk membuat data transaksional tersedia di tujuan analitik Anda setelah ditulis ke DB cluster. Extract, transform, and load (ETL) adalah proses menggabungkan data dari berbagai sumber menjadi gudang data sentral yang besar.
Integrasi nol-ETL membuat data dalam DB tersedia di Amazon Redshift atau lakehouse dalam waktu dekat. Amazon SageMaker AI Setelah data tersebut berada di gudang data target atau data lake, Anda dapat memberi daya pada beban kerja analitik, ML, dan AI Anda menggunakan kemampuan bawaan, seperti pembelajaran mesin, tampilan terwujud, berbagi data, akses gabungan ke beberapa penyimpanan data dan data lake, dan integrasi dengan SageMaker Amazon AI, Quick, dan lainnya. Layanan AWS
Untuk membuat integrasi nol-ETL, Anda menentukan DB cluster sebagai sumber, dan gudang data atau lakehouse yang didukung sebagai target. Integrasi mereplikasi data dari database sumber ke gudang data target atau lakehouse.
Diagram berikut menggambarkan fungsi ini untuk integrasi nol-ETL dengan Amazon Redshift:
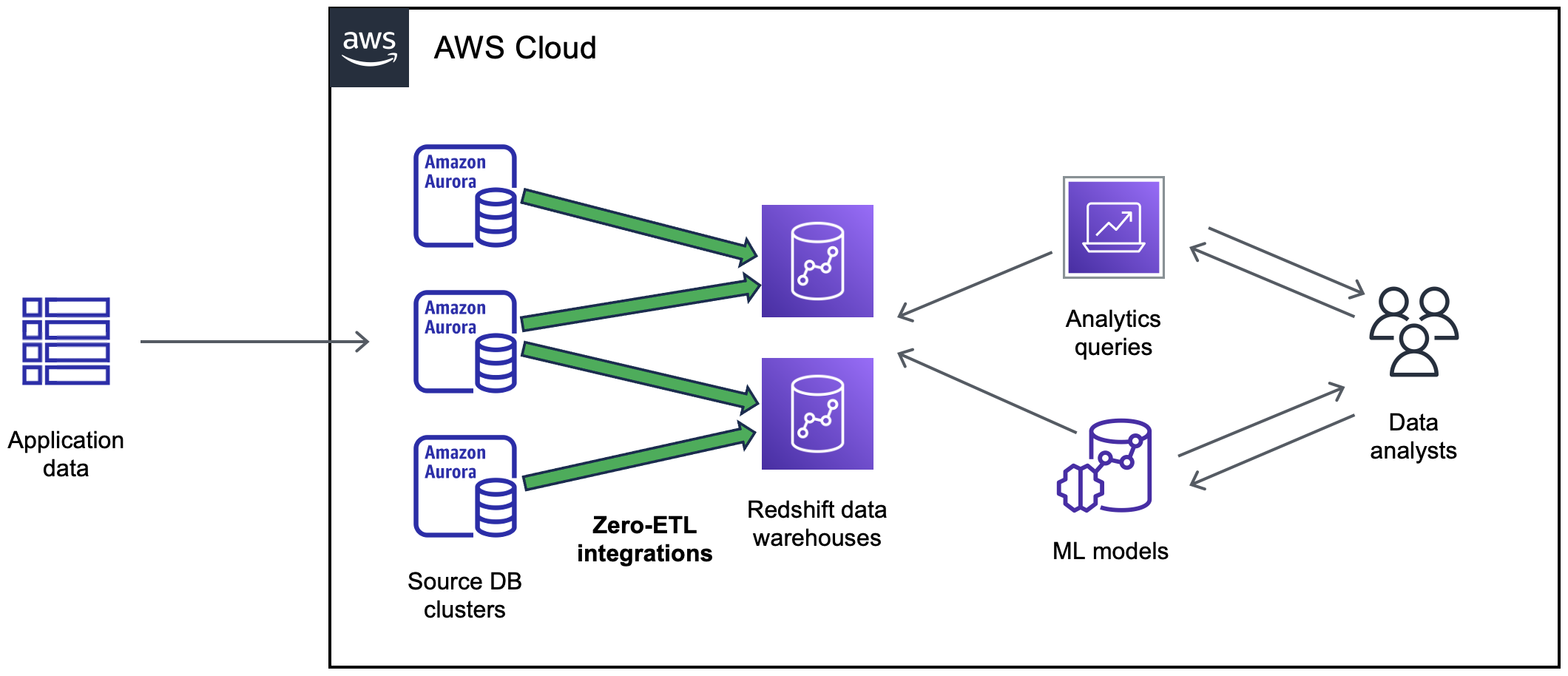
Diagram berikut menggambarkan fungsi ini untuk integrasi nol-ETL dengan rumah danau: Amazon SageMaker AI

Integrasi memantau kondisi pipeline data dan memulihkan dari masalah jika memungkinkan. Anda dapat membuat integrasi dari beberapa cluster Aurora DB ke dalam satu gudang data target tunggal atau lakehouse yang memungkinkan Anda memperoleh wawasan di beberapa aplikasi.
Untuk informasi tentang harga integrasi nol-ETL, lihat Harga Amazon Aurora
Topik
Manfaat
Integrasi Aurora Zero-ETL memiliki manfaat sebagai berikut:
-
Membantu Anda memperoleh wawasan menyeluruh dari berbagai sumber data.
-
Menghilangkan kebutuhan untuk membangun dan memelihara jaringan data kompleks yang melakukan operasi ekstrak, transformasi, dan beban (ETL). Zero-ETL integrasi menghilangkan tantangan yang datang dengan membangun dan mengelola jaringan pipa dengan menyediakan dan mengelolanya untuk Anda.
-
Mengurangi beban dan biaya operasional, serta membantu Anda fokus pada peningkatan aplikasi Anda.
-
Memungkinkan Anda memanfaatkan analitik tujuan target dan kemampuan ML untuk memperoleh wawasan dari data transaksional dan lainnya, untuk merespons secara efektif peristiwa kritis dan sensitif terhadap waktu.
Konsep utama
Saat mulai menggunakan integrasi nol-ETL, pertimbangkan konsep berikut ini:
- Integrasi
-
Pipa data yang dikelola sepenuhnya yang secara otomatis mereplikasi data dan skema transaksional dari DB cluster ke gudang data atau katalog.
- sumber DB cluster
-
Aurora DB cluster tempat data direplikasi. Anda dapat menentukan cluster DB yang menggunakan instans DB atau instans DB yang disediakan sebagai Aurora serverless sumbernya.
- Target
-
Gudang data atau lakehouse tempat data direplikasi. Ada dua jenis gudang data: gudang data klaster terprovisi dan gudang data nirserver. Gudang data klaster terprovisi adalah kumpulan sumber daya komputasi yang disebut simpul, yang diatur ke dalam grup yang disebut klaster. Gudang data nirserver terdiri dari grup kerja yang menyimpan sumber daya komputasi, serta ruang nama yang menampung objek basis data dan pengguna. Kedua gudang data menjalankan mesin analitik dan berisi satu atau lebih database.
Target lakehouse terdiri dari katalog, database, tabel, dan tampilan. Untuk informasi lebih lanjut tentang arsitektur lakehouse, lihat SageMaker Lakehouse componentsdi Amazon SageMaker AI Unified StudioPanduan Pengguna.
Beberapa sumber DB cluster dapat menulis ke target yang sama.
Untuk informasi selengkapnya, lihat Arsitektur sistem gudang data dalam Panduan Developer Amazon Redshift.
Batasan
Keterbatasan berikut berlaku untuk integrasi .
Topik
Batasan umum
-
Cluster DB sumber harus berada di Wilayah yang sama dengan target.
-
Anda tidak dapat mengganti nama cluster DB atau instance-nya jika memiliki integrasi yang ada.
-
Anda tidak dapat membuat beberapa integrasi antara database sumber dan target yang sama.
-
Anda tidak dapat menghapus cluster DB yang memiliki integrasi yang ada. Anda harus menghapus semua integrasi yang terkait terlebih dahulu.
-
Jika Anda menghentikan cluster DB sumber, beberapa transaksi terakhir mungkin tidak direplikasi ke target sampai Anda melanjutkan cluster .
-
Jika kluster Anda adalah sumber blue/green penerapan, lingkungan biru dan hijau tidak dapat memiliki integrasi nol-ETL selama peralihan. Anda harus menghapus integrasi tersebut terlebih dahulu dan beralih, lalu membuat ulang integrasi.
-
Cluster DB harus berisi setidaknya satu instans DB untuk menjadi sumber integrasi.
-
Anda tidak dapat membuat integrasi untuk cluster DB sumber yang merupakan klon lintas akun, seperti yang dibagikan menggunakan AWS Resource Access Manager ()AWS RAM.
-
Jika klaster sumber Anda adalah klaster DB primer dalam basis data global Aurora dan melakukan failover ke salah satu klaster sekundernya, integrasi menjadi tidak aktif. Anda harus menghapus dan membuat ulang integrasi.
-
Anda tidak dapat membuat integrasi untuk database sumber yang memiliki integrasi lain yang sedang dibuat secara aktif.
-
Saat Anda pertama kali membuat integrasi, atau ketika tabel sedang disinkronkan ulang, seeding data dari sumber ke target dapat memakan waktu 20-25 menit atau lebih tergantung ukuran basis data sumber. Penundaan ini dapat menyebabkan peningkatan lag replika.
-
Beberapa jenis data tidak didukung. Untuk informasi selengkapnya, lihat Perbedaan tipe data antara Aurora dan basis data Amazon Redshift.
-
Tabel sistem, tabel sementara, dan tampilan tidak direplikasi ke gudang target.
-
Melakukan perintah DDL (misalnya
ALTER TABLE) pada tabel sumber dapat memicu sinkronisasi ulang tabel, membuat tabel tidak tersedia untuk kueri saat disinkronkan ulang. Untuk informasi selengkapnya, lihat Satu atau beberapa tabel Amazon Redshift saya memerlukan sinkronisasi ulang.
Aurora MySQL keterbatasan
-
Cluster DB sumber Anda harus menjalankan versi Aurora MySQL yang didukung. Untuk daftar versi yang didukung, lihat Daerah yang Didukung dan mesin Aurora DB untuk integrasi Nol-ETL.
-
Zero-ETL integrasi mengandalkan MySQL binary logging (binlog) untuk menangkap perubahan data yang sedang berlangsung. Jangan gunakan pemfilteran data berbasis binlog, karena dapat menyebabkan inkonsistensi data antara basis data sumber dan target.
-
Zero-ETL integrasi hanya didukung untuk database yang dikonfigurasi untuk menggunakan mesin penyimpanan InnoDB.
-
Referensi kunci asing dengan pembaruan tabel yang telah ditentukan sebelumnya tidak didukung. Secara khusus,
ON DELETEdanON UPDATEaturan tidak didukung denganCASCADE,SET NULL, danSET DEFAULTtindakan. Mencoba membuat atau memperbarui tabel dengan referensi tersebut ke tabel lain akan menempatkan tabel ke dalam keadaan gagal. -
Transaksi XA
yang dilakukan pada cluster DB sumber menyebabkan integrasi memasuki status. Syncing
Keterbatasan Aurora PostgreSQL
-
Cluster DB sumber Anda harus menjalankan versi Aurora PostgreSQL yang didukung. Untuk daftar versi yang didukung, lihat Daerah yang Didukung dan mesin Aurora DB untuk integrasi Nol-ETL.
-
Jika Anda memilih cluster DB sumber PostgreSQL Aurora, Anda harus menentukan setidaknya satu pola filter data. Minimal, pola harus menyertakan database tunggal (
database-name.*.* -
Semua database yang dibuat dalam sumber Aurora PostgreSQL DB cluster harus menggunakan encoding. UTF-8
-
Saat menggunakan partisi deklaratif, partisi tabel akan direplikasi ke Amazon Redshift. Namun, tabel yang dipartisi itu sendiri tidak direplikasi ke Amazon Redshift.
-
Two-phase Transaksi
tidak didukung. -
Jika Anda menghapus semua instance DB dari cluster DB yang merupakan sumber integrasi dan kemudian menambahkan kembali instance DB, replikasi akan terputus antara sumber dan kluster target.
-
Cluster DB sumber tidak dapat menggunakan Database Aurora Limitless.
-
Kunci primer diperlukan pada semua tabel yang ada di filter data. Setiap tabel tanpa kunci utama akan dimasukkan ke dalam status gagal.
Batasan Amazon Redshift
Untuk daftar batasan Amazon Redshift yang terkait dengan integrasi Nol-ETL, lihat Pertimbangan saat menggunakan integrasi Nol-ETL dengan Amazon Redshift di Panduan Manajemen Pergeseran Merah Amazon.
Amazon SageMaker AI keterbatasan lakehouse
Berikut ini adalah batasan untuk integrasi Amazon SageMaker AI lakehouse zero-ETL.
-
Nama katalog dibatasi hingga 19 karakter panjangnya.
Kuota
Akun Anda memiliki kuota berikut yang terkait dengan integrasi Zero-ETL. Kecuali ditentukan lain, masing-masing kuota ditentukan untuk setiap Wilayah.
| Nama | Default | Deskripsi |
|---|---|---|
| Integrasi | 100 | Jumlah total integrasi dalam sebuah Akun AWS. |
| Integrasi per target | 50 | Jumlah integrasi yang mengirimkan data ke gudang data target tunggal atau lakehouse. |
| Integrasi per klaster sumber | 5 | Jumlah integrasi yang mengirimkan data dari klaster DB sumber tunggal. |
Selain itu, gudang target menempatkan batasan tertentu pada jumlah tabel yang diizinkan di setiap instance DB atau node cluster. Untuk informasi selengkapnya tentang kuota dan batas Amazon Redshift, lihat Kuota dan batas di Amazon Redshift di Panduan Manajemen Pergeseran Merah Amazon.
Wilayah yang Didukung
Integrasi Aurora Zero-ETL tersedia dalam subset. Wilayah AWS Untuk mengetahui daftar Wilayah yang didukung, lihat Daerah yang Didukung dan mesin Aurora DB untuk integrasi Nol-ETL.
