Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Menggunakan machine learning Amazon Aurora dengan Aurora PostgreSQL
Dengan menggunakan pembelajaran mesin Amazon Aurora dengan cluster DB Aurora PostgreSQL Anda, Anda dapat menggunakan Amazon Comprehend atau Amazon AI atau Amazon Bedrock, tergantung pada kebutuhan Anda. SageMaker Layanan ini masing-masing mendukung kasus penggunaan pembelajaran mesin tertentu.
Pembelajaran mesin Aurora didukung dalam versi tertentu Wilayah AWS dan khusus dari Aurora PostgreSQL saja. Sebelum mencoba menyiapkan machine learning Aurora, periksa ketersediaan untuk versi Aurora PostgreSQL dan Wilayah Anda. Untuk detailnya, lihat Machine learning Aurora dengan Aurora PostgreSQL.
Topik
Persyaratan untuk menggunakan machine learning Aurora dengan Aurora PostgreSQL
Fitur yang didukung dan batasan machine learning Aurora dengan Aurora PostgreSQL
Menyiapkan klaster DB Aurora PostgreSQL untuk menggunakan machine learning Aurora
Menggunakan Amazon Bedrock dengan cluster Aurora PostgreSQL DB Anda
Menggunakan Amazon Comprehend dengan klaster DB Aurora PostgreSQL
Menggunakan SageMaker AI dengan cluster Aurora PostgreSQL DB Anda
Mengekspor data ke Amazon S3 SageMaker untuk pelatihan model AI (Lanjutan)
Pertimbangan performa untuk machine learning Aurora dengan Aurora PostgreSQL
Persyaratan untuk menggunakan machine learning Aurora dengan Aurora PostgreSQL
AWS Layanan pembelajaran mesin adalah layanan terkelola yang diatur dan dijalankan di lingkungan produksi mereka sendiri. Pembelajaran mesin Aurora mendukung integrasi dengan Amazon Comprehend, AI, dan Amazon SageMaker Bedrock. Sebelum mencoba menyiapkan klaster DB Aurora PostgreSQL untuk menggunakan machine learning Aurora, pastikan Anda memahami persyaratan dan prasyarat berikut.
Layanan Amazon SageMaker Comprehend, AI, dan Amazon Bedrock harus berjalan sama Wilayah AWS dengan cluster Aurora PostgreSQL DB Anda. Anda tidak dapat menggunakan layanan Amazon SageMaker Comprehend atau AI atau Amazon Bedrock dari klaster DB PostgreSQL Aurora di Wilayah yang berbeda.
Jika klaster DB PostgreSQL Aurora Anda berada di cloud publik virtual (VPC) yang berbeda berdasarkan layanan VPC Amazon daripada layanan Amazon Comprehend dan AI Anda SageMaker , grup Keamanan VPC perlu mengizinkan koneksi keluar ke layanan pembelajaran mesin Aurora target. Untuk informasi selengkapnya, lihat Mengaktifkan komunikasi jaringan dari Amazon Aurora ke layanan lain AWS.
Untuk SageMaker AI, komponen pembelajaran mesin yang ingin Anda gunakan untuk inferensi harus diatur dan siap digunakan. Selama proses konfigurasi untuk cluster Aurora PostgreSQL DB, Anda harus memiliki Nama Sumber Daya Amazon (ARN) dari titik akhir AI yang tersedia. SageMaker Ilmuwan data di tim Anda kemungkinan besar paling mampu menangani bekerja dengan SageMaker AI untuk mempersiapkan model dan menangani tugas-tugas semacam itu lainnya. Untuk memulai dengan Amazon SageMaker AI, lihat Memulai dengan Amazon SageMaker AI. Untuk informasi lebih lanjut tentang kesimpulan dan titik akhir, lihat Real-time inferensi.
-
Untuk Amazon Bedrock, Anda harus memiliki ID model model Bedrock yang ingin Anda gunakan untuk inferensi yang tersedia selama proses konfigurasi cluster DB PostgreSQL Aurora Anda. Ilmuwan data di tim Anda kemungkinan besar paling mampu bekerja dengan Bedrock untuk memutuskan model mana yang akan digunakan, menyempurnakannya jika diperlukan, dan menangani tugas-tugas semacam itu lainnya. Untuk memulai dengan Amazon Bedrock, lihat Cara mengatur Bedrock.
-
Pengguna Amazon Bedrock perlu meminta akses ke model sebelum tersedia untuk digunakan. Jika Anda ingin menambahkan model tambahan untuk pembuatan teks, obrolan, dan gambar, Anda perlu meminta akses ke model di Amazon Bedrock. Untuk informasi selengkapnya, lihat Akses model.
Fitur yang didukung dan batasan machine learning Aurora dengan Aurora PostgreSQL
Pembelajaran mesin Aurora mendukung titik akhir SageMaker AI apa pun yang dapat membaca dan menulis format nilai dipisahkan koma (CSV) melalui nilai. ContentType text/csv Algoritma SageMaker AI bawaan yang saat ini menerima format ini adalah sebagai berikut.
Linear Learner
Random Cut Forest
XGBoost
Untuk mempelajari lebih lanjut tentang algoritme ini, lihat Memilih Algoritma di Panduan Pengembang Amazon SageMaker AI.
Saat menggunakan Amazon Bedrock dengan pembelajaran mesin Aurora, batasan berikut berlaku:
-
Fungsi yang ditentukan pengguna (UDF) menyediakan cara asli untuk berinteraksi dengan Amazon Bedrock. UDF tidak memiliki permintaan atau persyaratan respons khusus, sehingga mereka dapat menggunakan model apa pun.
-
Anda dapat menggunakan UDF untuk membangun alur kerja apa pun yang diinginkan. Misalnya, Anda dapat menggabungkan primitif dasar seperti
pg_cronmenjalankan kueri, mengambil data, menghasilkan kesimpulan, dan menulis ke tabel untuk menyajikan kueri secara langsung. -
UDF tidak mendukung panggilan batch atau parallel.
-
Ekstensi Machine Learning Aurora tidak mendukung antarmuka vektor. Sebagai bagian dari ekstensi, fungsi tersedia untuk menampilkan penyematan respons model dalam
float8[]format untuk menyimpan embeddings tersebut di Aurora. Untuk informasi lebih lanjut tentang penggunaanfloat8[], lihatMenggunakan Amazon Bedrock dengan cluster Aurora PostgreSQL DB Anda.
Menyiapkan klaster DB Aurora PostgreSQL untuk menggunakan machine learning Aurora
Agar pembelajaran mesin Aurora dapat bekerja dengan cluster DB PostgreSQL Aurora Anda, Anda perlu membuat peran AWS Identity and Access Management (IAM) untuk setiap layanan yang ingin Anda gunakan. Peran IAM memungkinkan klaster DB Aurora PostgreSQL Anda menggunakan layanan machine learning Aurora atas nama klaster. Anda juga perlu menginstal ekstensi machine learning Aurora. Dalam topik berikut, Anda dapat menemukan prosedur penyiapan untuk masing-masing layanan machine learning Aurora ini.
Topik
Menyiapkan Aurora PostgreSQL untuk menggunakan Amazon Bedrock
Dalam prosedur berikut, pertama-tama Anda membuat peran dan kebijakan IAM yang memberikan izin Aurora PostgreSQL Anda untuk menggunakan Amazon Bedrock atas nama klaster. Anda kemudian melampirkan kebijakan ke peran IAM yang digunakan klaster Aurora PostgreSQL DB Anda untuk bekerja dengan Amazon Bedrock. Demi kesederhanaan, prosedur ini menggunakan AWS Management Console untuk menyelesaikan semua tugas.
Untuk mengatur cluster DB PostgreSQL Aurora Anda untuk menggunakan Amazon Bedrock
Masuk ke AWS Management Console dan buka konsol IAM di https://console.aws.amazon.com/iam/
. Buka konsol IAM di https://console.aws.amazon.com/iam/
. Pilih Kebijakan (di bawah Manajemen akses) pada menu Konsol AWS Identity and Access Management (IAM).
Pilih Buat kebijakan. Di halaman Editor Visual, pilih Layanan dan kemudian masukkan Bedrock di bidang Pilih layanan. Perluas tingkat akses Baca. Pilih InvokeModeldari pengaturan baca Amazon Bedrock.
Pilih Foundation/Provisioned model yang ingin Anda berikan akses baca melalui kebijakan.
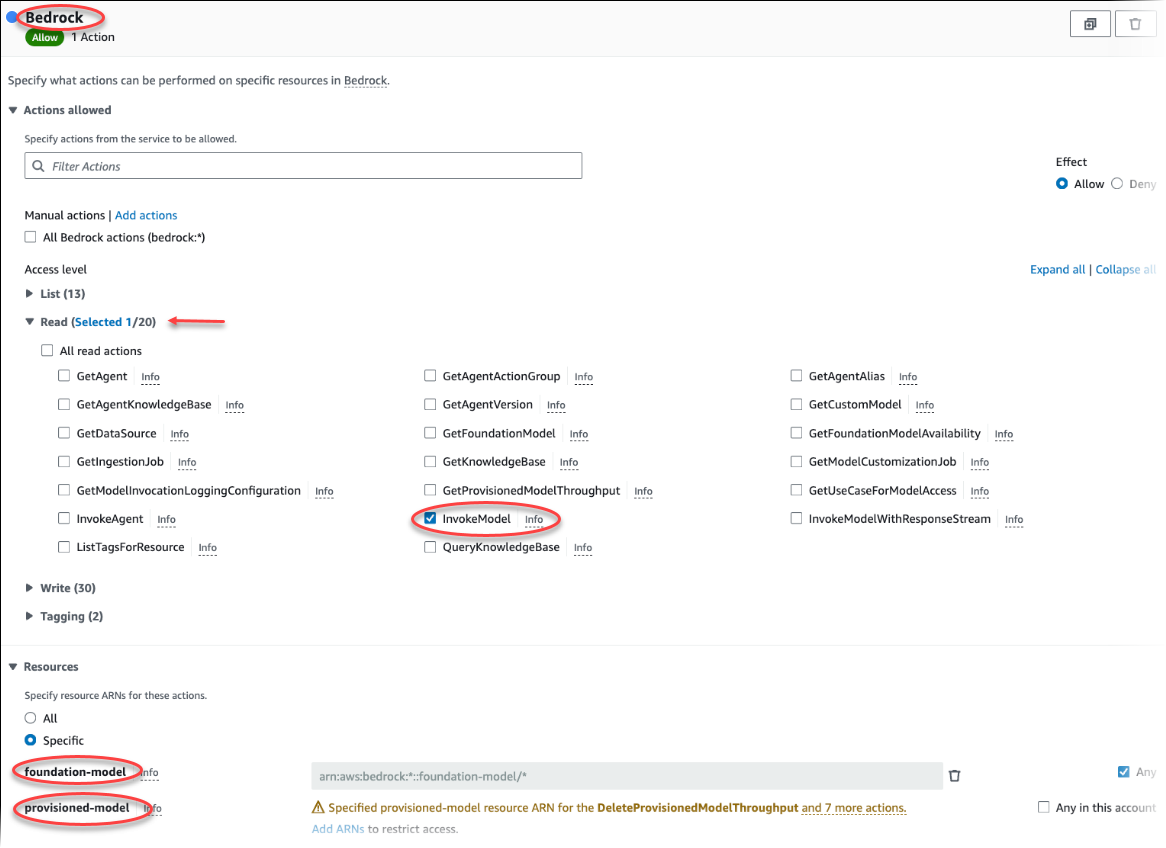
Pilih Berikutnya: Tag dan tentukan tag apa pun (opsional). Pilih Berikutnya: Peninjauan. Masukkan nama untuk kebijakan dan deskripsi, seperti diperlihatkan pada gambar.
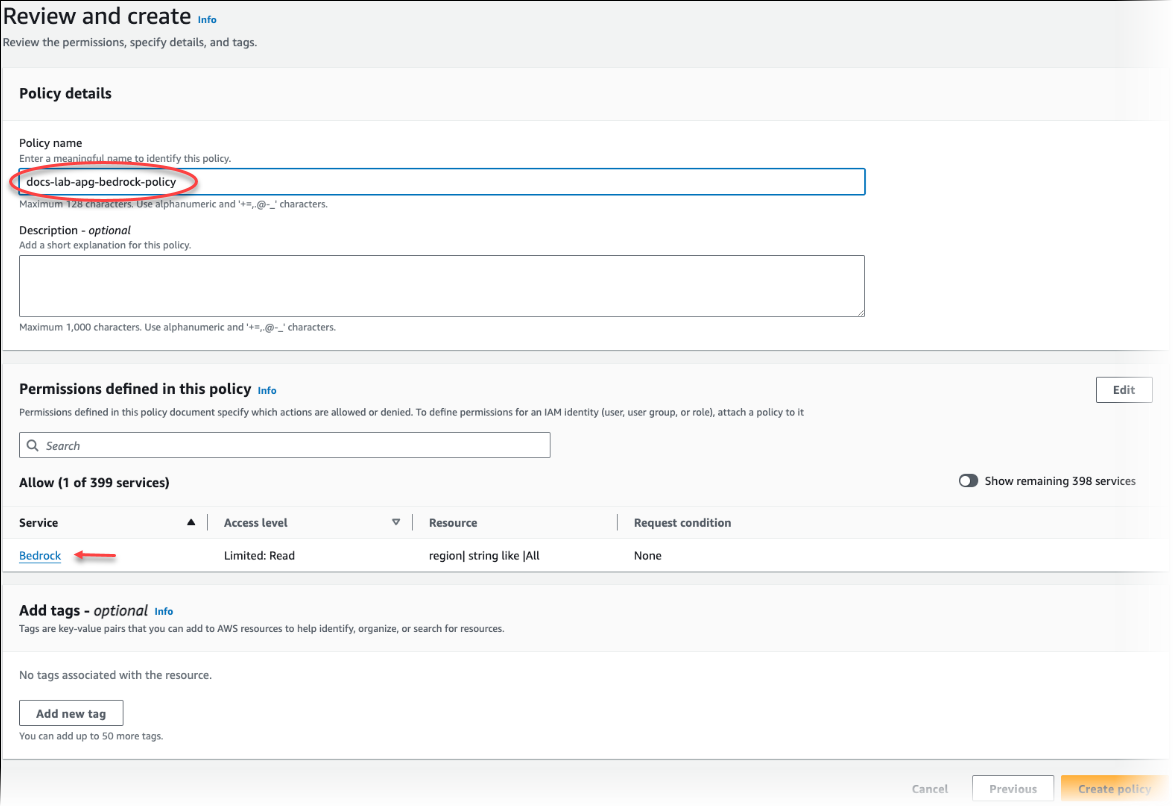
Pilih Buat kebijakan. Konsol menampilkan peringatan saat kebijakan telah disimpan. Anda dapat menemukannya di daftar Kebijakan.
Pilih Peran (di bagian Manajemen akses) di Konsol IAM.
Pilih Buat peran.
Di halaman Pilih entitas tepercaya, pilih kotak layanan AWS , lalu pilih RDS untuk membuka pemilih.
Pilih RDS – Tambahkan Peran ke Basis Data.
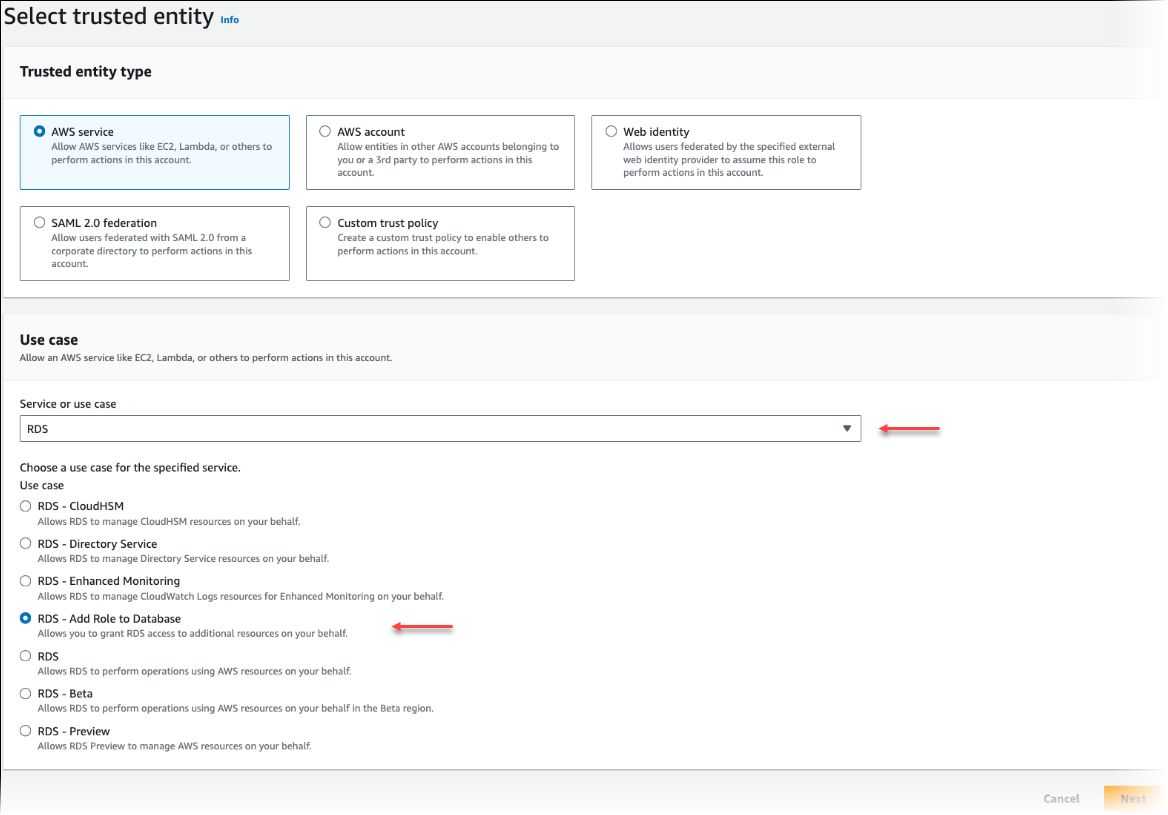
Pilih Berikutnya. Di halaman Tambahkan izin, temukan kebijakan yang Anda buat di langkah sebelumnya dan pilih kebijakan dari daftar tersebut. Pilih Berikutnya.
Berikutnya: Tinjau. Masukkan nama peran IAM dan deskripsinya.
Buka konsol Amazon RDS di https://console.aws.amazon.com/rds/
. Arahkan ke Wilayah AWS tempat cluster Aurora PostgreSQL DB Anda berada.
-
Di panel navigasi, pilih Databases, dan kemudian pilih cluster Aurora PostgreSQL DB yang ingin Anda gunakan dengan Bedrock.
-
Pilih tab Konektivitas & keamanan dan gulir untuk menemukan bagian Kelola peran IAM pada halaman. Dari pemilih Tambahkan peran IAM ke klaster ini, pilih peran yang Anda buat di langkah sebelumnya. Di pemilih Fitur, pilih Batuan Dasar, lalu pilih Tambah peran.
Peran (dengan kebijakannya) dikaitkan dengan klaster DB Aurora PostgreSQL. Setelah proses selesai, peran tersebut dicantumkan dalam peran IAM saat ini untuk daftar klaster ini, seperti yang ditunjukkan berikut.
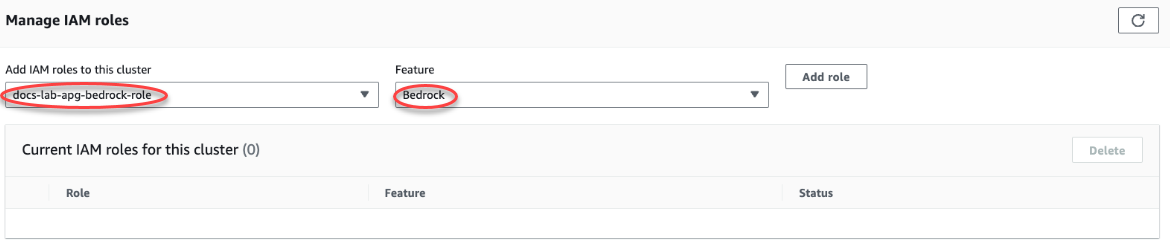
Pengaturan IAM untuk Amazon Bedrock selesai. Lanjutkan penyiapan Aurora PostgreSQL Anda untuk bekerja dengan machine learning Aurora dengan menginstal ekstensi seperti yang dijelaskan dalam Menginstal ekstensi machine learning Aurora
Menyiapkan Aurora PostgreSQL untuk menggunakan Amazon Comprehend
Dalam prosedur berikut, pertama-tama Anda membuat kebijakan dan peran IAM yang memberikan izin kepada Aurora PostgreSQL untuk menggunakan Amazon Comprehend atas nama klaster. Anda kemudian melampirkan kebijakan ke peran IAM yang digunakan klaster DB Aurora PostgreSQL untuk bekerja dengan Amazon Comprehend. Untuk memudahkan, prosedur ini menggunakan AWS Management Console untuk menyelesaikan semua tugas.
Untuk menyiapkan klaster DB Aurora PostgreSQL untuk menggunakan Amazon Comprehend
Masuk ke AWS Management Console dan buka konsol IAM di https://console.aws.amazon.com/iam/
. Buka konsol IAM di https://console.aws.amazon.com/iam/
. Pilih Kebijakan (di bawah Manajemen akses) pada menu Konsol AWS Identity and Access Management (IAM).
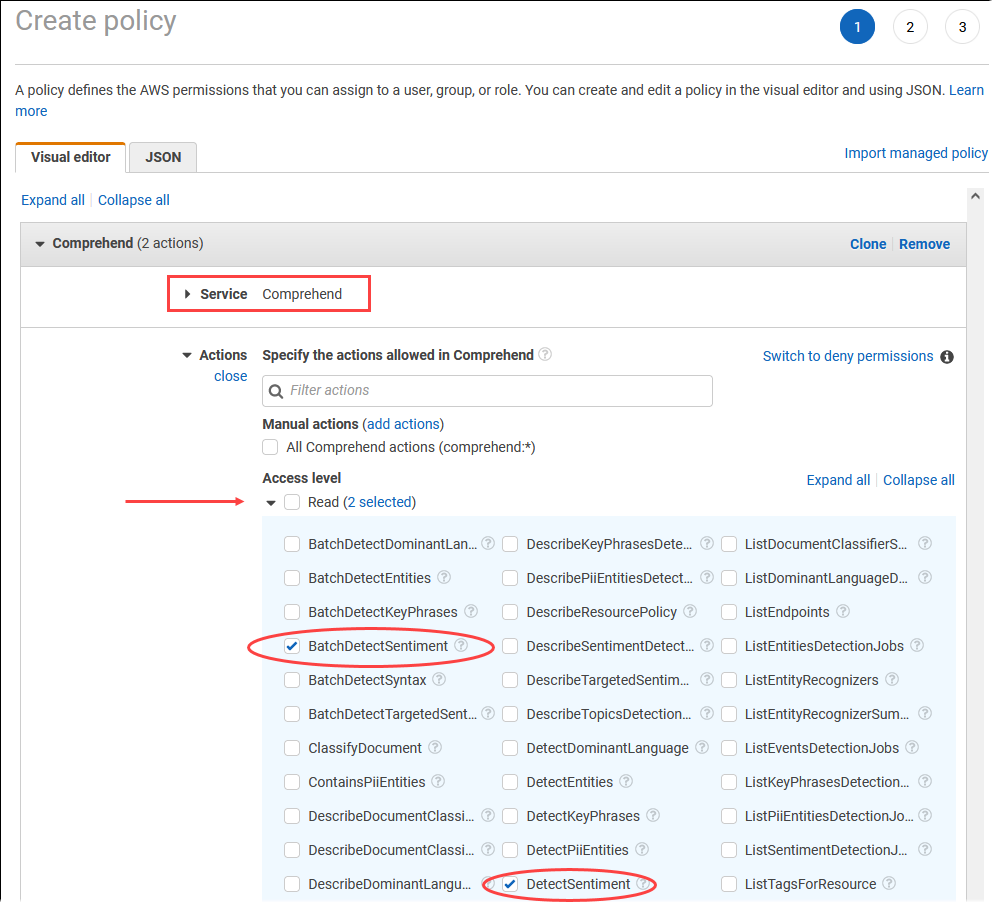
Pilih Buat kebijakan. Di halaman Editor Visual, pilih Layanan, lalu masukkan Comprehend di kolom Pilih layanan. Perluas tingkat akses Baca. Pilih BatchDetectSentimentdan DetectSentimentdari pengaturan baca Amazon Comprehend.
Pilih Berikutnya: Tag dan tentukan tag apa pun (opsional). Pilih Berikutnya: Peninjauan. Masukkan nama untuk kebijakan dan deskripsi, seperti diperlihatkan pada gambar.
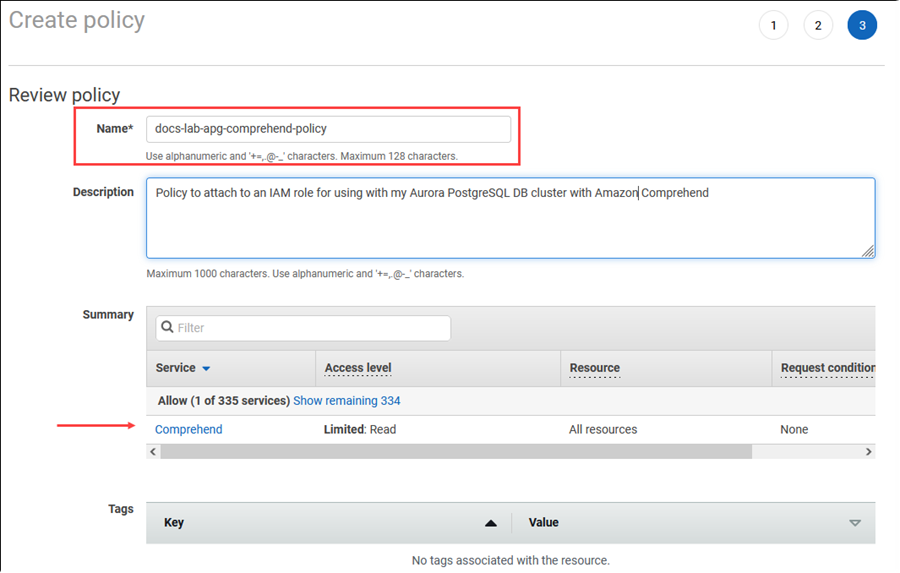
Pilih Buat kebijakan. Konsol menampilkan peringatan saat kebijakan telah disimpan. Anda dapat menemukannya di daftar Kebijakan.
Pilih Peran (di bagian Manajemen akses) di Konsol IAM.
Pilih Buat peran.
Di halaman Pilih entitas tepercaya, pilih kotak layanan AWS , lalu pilih RDS untuk membuka pemilih.
Pilih RDS – Tambahkan Peran ke Basis Data.
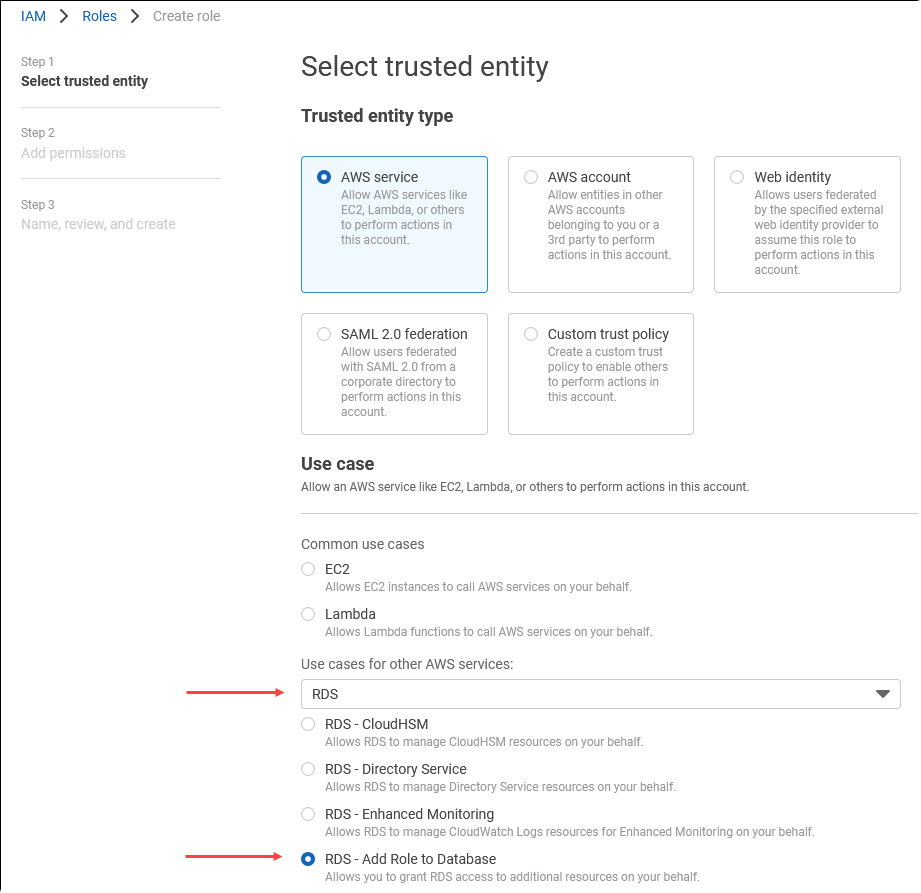
Pilih Selanjutnya. Di halaman Tambahkan izin, temukan kebijakan yang Anda buat di langkah sebelumnya dan pilih kebijakan dari daftar tersebut. Pilih Selanjutnya
Berikutnya: Tinjau. Masukkan nama peran IAM dan deskripsinya.
Buka konsol Amazon RDS di https://console.aws.amazon.com/rds/
. Arahkan ke Wilayah AWS tempat cluster Aurora PostgreSQL DB Anda berada.
-
Di panel navigasi, pilih Basis data, lalu pilih klaster DB Aurora PostgreSQL yang ingin digunakan dengan Amazon Comprehend.
-
Pilih tab Konektivitas & keamanan dan gulir untuk menemukan bagian Kelola peran IAM pada halaman. Dari pemilih Tambahkan peran IAM ke klaster ini, pilih peran yang Anda buat di langkah sebelumnya. Di pemilih Fitur, pilih Comprehend, lalu pilih Tambah peran.
Peran (dengan kebijakannya) dikaitkan dengan klaster DB Aurora PostgreSQL. Setelah proses selesai, peran tersebut dicantumkan dalam peran IAM saat ini untuk daftar klaster ini, seperti yang ditunjukkan berikut.
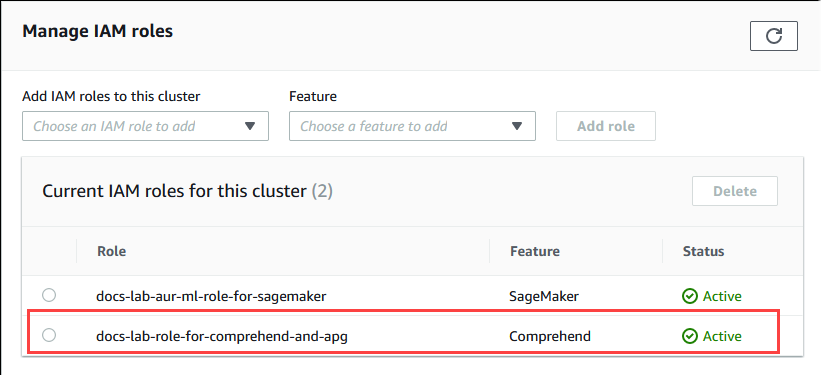
Penyiapan IAM untuk Amazon Comprehend selesai. Lanjutkan penyiapan Aurora PostgreSQL Anda untuk bekerja dengan machine learning Aurora dengan menginstal ekstensi seperti yang dijelaskan dalam Menginstal ekstensi machine learning Aurora
Menyiapkan Aurora PostgreSQL untuk menggunakan Amazon AI SageMaker
Sebelum Anda dapat membuat kebijakan dan peran IAM untuk cluster Aurora PostgreSQL DB Anda, Anda harus SageMaker memiliki pengaturan model AI dan titik akhir Anda tersedia.
Untuk mengatur cluster Aurora PostgreSQL DB Anda untuk menggunakan AI SageMaker
Masuk ke AWS Management Console dan buka konsol IAM di https://console.aws.amazon.com/iam/
. Pilih Kebijakan (di bawah Manajemen akses) pada menu Konsol AWS Identity and Access Management (IAM), lalu pilih Buat kebijakan. Di editor Visual, pilih SageMakeruntuk Layanan. Untuk Tindakan, buka pemilih Baca (di bawah tingkat Akses) dan pilih InvokeEndpoint. Saat Anda melakukannya, ikon peringatan akan muncul.
Buka pemilih Resources dan pilih tautan Tambahkan ARN untuk membatasi akses di bawah Tentukan ARN sumber daya titik akhir untuk tindakan tersebut. InvokeEndpoint
Masukkan Wilayah AWS sumber daya SageMaker AI Anda dan nama titik akhir Anda. AWS Akun Anda sudah diisi sebelumnya.
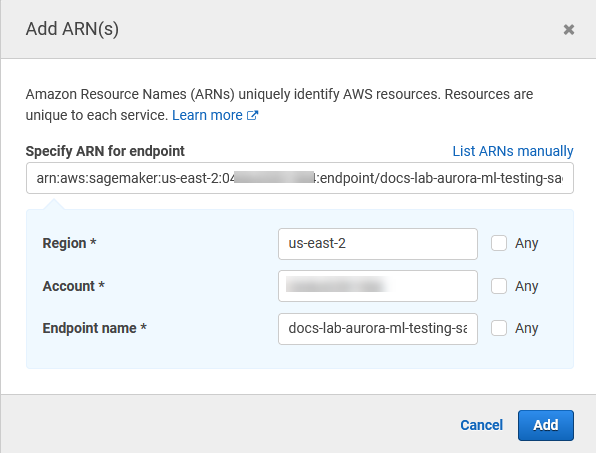
Pilih Tambah untuk menyimpan. Pilih Berikutnya: Tag dan Berikutnya: Tinjau untuk membuka halaman terakhir proses pembuatan kebijakan.
Masukkan Nama dan Deskripsi untuk kebijakan ini, lalu pilih Buat kebijakan. Kebijakan dibuat dan ditambahkan ke daftar Kebijakan. Anda melihat peringatan di Konsol saat ini terjadi.
Di Konsol IAM, pilih Peran.
Pilih Buat peran.
Di halaman Pilih entitas tepercaya, pilih kotak layanan AWS , lalu pilih RDS untuk membuka pemilih.
Pilih RDS – Tambahkan Peran ke Basis Data.
Pilih Selanjutnya. Di halaman Tambahkan izin, temukan kebijakan yang Anda buat di langkah sebelumnya dan pilih kebijakan dari daftar tersebut. Pilih Selanjutnya
Berikutnya: Tinjau. Masukkan nama peran IAM dan deskripsinya.
Buka konsol Amazon RDS di https://console.aws.amazon.com/rds/
. Arahkan ke Wilayah AWS tempat cluster Aurora PostgreSQL DB Anda berada.
-
Di panel navigasi, pilih Databases, lalu pilih cluster Aurora PostgreSQL DB yang ingin Anda gunakan dengan AI. SageMaker
-
Pilih tab Konektivitas & keamanan dan gulir untuk menemukan bagian Kelola peran IAM pada halaman. Dari pemilih Tambahkan peran IAM ke klaster ini, pilih peran yang Anda buat di langkah sebelumnya. Di pemilih Fitur, pilih SageMaker AI, lalu pilih Tambah peran.
Peran (dengan kebijakannya) dikaitkan dengan klaster DB Aurora PostgreSQL. Saat proses selesai, peran tersebut tercantum dalam peran IAM saat ini untuk daftar klaster ini.
Pengaturan IAM untuk SageMaker AI selesai. Lanjutkan penyiapan Aurora PostgreSQL Anda untuk bekerja dengan machine learning Aurora dengan menginstal ekstensi seperti yang dijelaskan dalam Menginstal ekstensi machine learning Aurora.
Menyiapkan Aurora PostgreSQL untuk menggunakan Amazon S3 untuk AI (Advanced) SageMaker
Untuk menggunakan SageMaker AI dengan model Anda sendiri daripada menggunakan komponen pra-bangun yang disediakan oleh SageMaker AI, Anda perlu menyiapkan bucket Amazon Simple Storage Service (Amazon S3) untuk cluster Aurora PostgreSQL DB untuk digunakan. Ini adalah topik lanjutan, dan tidak sepenuhnya didokumentasikan dalam Panduan Pengguna Amazon Aurora ini. Proses umumnya sama dengan mengintegrasikan dukungan untuk SageMaker AI, sebagai berikut.
Buat kebijakan dan peran IAM untuk Amazon S3.
Tambahkan peran IAM dan impor atau ekspor Amazon S3 sebagai fitur pada tab Konektivitas & keamanan klaster Aurora PostgreSQL DB Anda.
Tambahkan ARN peran ke grup parameter klaster DB kustom Anda untuk klaster DB Aurora Anda.
Untuk informasi penggunaan dasar, lihat Mengekspor data ke Amazon S3 SageMaker untuk pelatihan model AI (Lanjutan).
Menginstal ekstensi machine learning Aurora
Ekstensi pembelajaran mesin Aurora aws_ml 1.0 menyediakan dua fungsi yang dapat Anda gunakan untuk memanggil Amazon Comprehend, layanan SageMaker AI, dan aws_ml 2.0 menyediakan dua fungsi tambahan yang dapat Anda gunakan untuk menjalankan layanan Amazon Bedrock. Menginstal ekstensi ini di cluster Aurora PostgreSQL DB Anda juga menciptakan peran administratif untuk fitur tersebut.
catatan
Menggunakan fungsi-fungsi ini tergantung pada penyiapan IAM untuk layanan pembelajaran mesin Aurora (Amazon Comprehend, SageMaker AI, Amazon Bedrock) yang lengkap, seperti yang dijelaskan dalam. Menyiapkan klaster DB Aurora PostgreSQL untuk menggunakan machine learning Aurora
aws_comprehend.detect_sentiment – Anda menggunakan fungsi ini untuk menerapkan analisis sentimen ke teks yang disimpan dalam basis data pada klaster DB Aurora PostgreSQL Anda.
aws_sagemaker.invoke_endpoint — Anda menggunakan fungsi ini dalam kode SQL Anda untuk berkomunikasi dengan titik akhir AI dari cluster Anda. SageMaker
aws_bedrock.invoke_model — Anda menggunakan fungsi ini dalam kode SQL Anda untuk berkomunikasi dengan Model Batuan Dasar dari cluster Anda. Respon fungsi ini akan dalam format TEXT, jadi jika model merespons dalam format badan JSON maka output dari fungsi ini akan diteruskan dalam format string ke pengguna akhir.
aws_bedrock.invoke_model_get_embeddings - Anda menggunakan fungsi ini dalam kode SQL Anda untuk memanggil Model Batuan Dasar yang mengembalikan penyematan keluaran dalam respons JSON. Ini dapat dimanfaatkan saat Anda ingin mengekstrak penyematan yang terkait langsung dengan json-key untuk merampingkan respons dengan alur kerja yang dikelola sendiri.
Menyiapkan ekstensi machine learning Aurora dalam klaster DB Aurora PostgreSQL Anda
Gunakan
psqluntuk terhubung ke instans penulis klaster DB Aurora PostgreSQL. Hubungkan ke basis data tertentu tempat untuk menginstal ekstensiaws_ml.psql --host=cluster-instance-1.111122223333.aws-region.rds.amazonaws.com --port=5432 --username=postgres --password --dbname=labdb
labdb=>CREATE EXTENSION IF NOT EXISTS aws_ml CASCADE;NOTICE: installing required extension "aws_commons" CREATE EXTENSIONlabdb=>
Menginstal aws_ml ekstensi juga menciptakan peran aws_ml administratif dan tiga skema baru, sebagai berikut.
aws_comprehend– Skema untuk layanan Amazon Comprehend dan sumber fungsidetect_sentiment(aws_comprehend.detect_sentiment).aws_sagemaker— Skema untuk layanan SageMaker AI dan sumberinvoke_endpointfungsi (aws_sagemaker.invoke_endpoint).aws_bedrock— Skema untuk layanan Amazon Bedrock dan sumberinvoke_model(aws_bedrock.invoke_model)daninvoke_model_get_embeddings(aws_bedrock.invoke_model_get_embeddings)fungsi.
Peran tersebut diberikan rds_superuser peran aws_ml administratif dan dibuat OWNER dari tiga skema pembelajaran mesin Aurora ini. Untuk mengizinkan pengguna basis data lain mengakses fungsi machine learning Aurora, rds_superuser harus memberikan hak istimewa EXECUTE pada fungsi machine learning Aurora. Secara default, hak istimewa EXECUTE dicabut dari PUBLIC pada fungsi dalam dua skema machine learning Aurora.
Dalam konfigurasi basis data multi-penghuni, Anda dapat mencegah penghuni mengakses fungsi machine learning Aurora dengan menggunakan REVOKE USAGE pada skema machine learning Aurora tertentu yang ingin dilindungi.
Menggunakan Amazon Bedrock dengan cluster Aurora PostgreSQL DB Anda
Untuk Aurora PostgreSQL, pembelajaran mesin Aurora menyediakan fungsi Amazon Bedrock berikut untuk bekerja dengan data teks Anda. Fungsi ini hanya tersedia setelah Anda menginstal ekstensi aws_ml 2.0 dan menyelesaikan semua prosedur pengaturan. Untuk informasi selengkapnya, lihat Menyiapkan klaster DB Aurora PostgreSQL untuk menggunakan machine learning Aurora.
- aws_bedrock.invoke_model
-
Fungsi ini mengambil teks yang diformat dalam JSON sebagai input dan memprosesnya untuk berbagai model yang dihosting di Amazon Bedrock dan mendapatkan kembali respons teks JSON dari model. Respons ini bisa berisi teks, gambar, atau embeddings. Ringkasan dokumentasi fungsinya adalah sebagai berikut.
aws_bedrock.invoke_model( IN model_id varchar, IN content_type text, IN accept_type text, IN model_input text, OUT model_output varchar)
Input dan output dari fungsi ini adalah sebagai berikut.
-
model_id— Pengidentifikasi model. content_type— Jenis permintaan untuk model Bedrock.accept_type— Jenis respons yang diharapkan dari model Bedrock. Biasanya application/JSON untuk sebagian besar model.model_input— Prompts; satu set input tertentu ke model dalam format seperti yang ditentukan oleh content_type. Untuk informasi lebih lanjut tentang permintaan format/structure yang diterima model, lihat Parameter inferensi untuk model pondasi.model_output— Output model Bedrock sebagai teks.
Contoh berikut menunjukkan cara memanggil model Anthropic Claude 2 untuk Bedrock menggunakan invoke_model.
contoh Contoh: Kueri sederhana menggunakan fungsi Amazon Bedrock
SELECT aws_bedrock.invoke_model ( model_id := 'anthropic.claude-v2', content_type:= 'application/json', accept_type := 'application/json', model_input := '{"prompt": "\n\nHuman: You are a helpful assistant that answers questions directly and only using the information provided in the context below.\nDescribe the answer in detail.\n\nContext: %s \n\nQuestion: %s \n\nAssistant:","max_tokens_to_sample":4096,"temperature":0.5,"top_k":250,"top_p":0.5,"stop_sequences":[]}' );
- aws_bedrock.invoke_model_get_embeddings
-
Output model dapat menunjuk ke penyematan vektor untuk beberapa kasus. Mengingat respons bervariasi per model, fungsi lain invoke_model_get_embeddings dapat dimanfaatkan yang berfungsi persis seperti invoke_model tetapi mengeluarkan penyematan dengan menentukan json-key yang sesuai.
aws_bedrock.invoke_model_get_embeddings( IN model_id varchar, IN content_type text, IN json_key text, IN model_input text, OUT model_output float8[])
Input dan output dari fungsi ini adalah sebagai berikut.
-
model_id— Pengidentifikasi model. content_type— Jenis permintaan untuk model Bedrock. Di sini, accept_type diatur ke nilai default.application/jsonmodel_input— Prompts; satu set input tertentu ke Model dalam format seperti yang ditentukan oleh content_type. Untuk informasi lebih lanjut tentang permintaan format/structure yang diterima Model, lihat Parameter inferensi untuk model dasar.json_key— Referensi ke bidang untuk mengekstrak embedding dari. Ini dapat bervariasi jika model penyematan berubah.-
model_output— Output model Bedrock sebagai array embeddings yang memiliki desimal 16 bit.
Contoh berikut menunjukkan cara menghasilkan embedding menggunakan Titan Embeddings G1 — Model penyematan teks untuk frasa PostgreSQL monitoring views. I/O
contoh Contoh: Kueri sederhana menggunakan fungsi Amazon Bedrock
SELECT aws_bedrock.invoke_model_get_embeddings( model_id := 'amazon.titan-embed-text-v1', content_type := 'application/json', json_key := 'embedding', model_input := '{ "inputText": "PostgreSQL I/O monitoring views"}') AS embedding;
Menggunakan Amazon Comprehend dengan klaster DB Aurora PostgreSQL
Untuk Aurora PostgreSQL, machine learning Aurora menyediakan fungsi Amazon Comprehend berikut agar berfungsi dengan data teks Anda. Fungsi ini hanya tersedia setelah Anda menginstal ekstensi aws_ml dan menyelesaikan semua prosedur penyiapan. Untuk informasi selengkapnya, lihat Menyiapkan klaster DB Aurora PostgreSQL untuk menggunakan machine learning Aurora.
- aws_comprehend.detect_sentiment
-
Fungsi ini mengambil teks sebagai input dan mengevaluasi apakah teks memiliki postur emosional positif, negatif, netral, atau campuran. Fungsi ini menghasilkan sentimen ini bersama dengan tingkat kepercayaan untuk evaluasinya. Ringkasan dokumentasi fungsinya adalah sebagai berikut.
aws_comprehend.detect_sentiment( IN input_text varchar, IN language_code varchar, IN max_rows_per_batch int, OUT sentiment varchar, OUT confidence real)
Input dan output dari fungsi ini adalah sebagai berikut.
-
input_text– Teks untuk mengevaluasi dan menetapkan sentimen (negatif, positif, netral, campuran). language_code– Bahasainput_textyang diidentifikasi menggunakan ID 2-huruf ISO 639-1 dengan sub-tag regional (sesuai kebutuhan) atau kode tiga huruf ISO 639-2, yang sesuai. Misalnya,enadalah kode untuk bahasa Inggris,zhadalah kode untuk bahasa Mandarin yang disederhanakan. Untuk informasi selengkapnya, lihat Bahasa yang didukung di Panduan Developer Amazon Comprehend.max_rows_per_batch– Jumlah baris maksimum per batch untuk pemrosesan mode batch. Untuk informasi selengkapnya, lihat Memahami mode batch dan fungsi machine learning Aurora.sentiment– Sentimen teks input, yang diidentifikasi sebagai POSITIVE, NEGATIVE, NEUTRAL, atau MIXED.confidence– Tingkat kepercayaan dalam keakuratan yang ditentukansentiment. Rentang nilai dari 0,0 hingga 1,0.
Berikut ini, Anda dapat menemukan contoh cara menggunakan fungsi ini.
contoh Contoh: Kueri sederhana menggunakan fungsi Amazon Comprehend
Berikut adalah contoh kueri sederhana yang menginvokasi fungsi ini untuk menilai kepuasan pelanggan dengan tim dukungan Anda. Misalkan Anda memiliki tabel basis data (support) yang menyimpan umpan balik pelanggan setelah setiap permintaan bantuan. Contoh kueri ini menerapkan fungsi aws_comprehend.detect_sentiment ke teks di kolom feedback tabel dan menghasilkan sentimen dan tingkat kepercayaan untuk sentimen tersebut. Kueri ini juga menghasilkan urutan menurun.
SELECT feedback, s.sentiment,s.confidence FROM support,aws_comprehend.detect_sentiment(feedback, 'en') s ORDER BY s.confidence DESC;feedback | sentiment | confidence ----------------------------------------------------------+-----------+------------ Thank you for the excellent customer support! | POSITIVE | 0.999771 The latest version of this product stinks! | NEGATIVE | 0.999184 Your support team is just awesome! I am blown away. | POSITIVE | 0.997774 Your product is too complex, but your support is great. | MIXED | 0.957958 Your support tech helped me in fifteen minutes. | POSITIVE | 0.949491 My problem was never resolved! | NEGATIVE | 0.920644 When will the new version of this product be released? | NEUTRAL | 0.902706 I cannot stand that chatbot. | NEGATIVE | 0.895219 Your support tech talked down to me. | NEGATIVE | 0.868598 It took me way too long to get a real person. | NEGATIVE | 0.481805 (10 rows)
Agar tidak ditagih untuk deteksi sentimen lebih dari sekali per baris tabel, Anda dapat mewujudkan hasilnya. Lakukan ini di baris yang diinginkan. Misalnya, catatan dokter sedang diperbarui sehingga hanya yang berbahasa Prancis (fr) yang menggunakan fungsi deteksi sentimen.
UPDATE clinician_notes SET sentiment = (aws_comprehend.detect_sentiment (french_notes, 'fr')).sentiment, confidence = (aws_comprehend.detect_sentiment (french_notes, 'fr')).confidence WHERE clinician_notes.french_notes IS NOT NULL AND LENGTH(TRIM(clinician_notes.french_notes)) > 0 AND clinician_notes.sentiment IS NULL;
Untuk informasi selengkapnya tentang cara mengoptimalkan panggilan fungsi Anda, lihat Pertimbangan performa untuk machine learning Aurora dengan Aurora PostgreSQL.
Menggunakan SageMaker AI dengan cluster Aurora PostgreSQL DB Anda
Setelah menyiapkan lingkungan SageMaker AI Anda dan mengintegrasikan dengan Aurora PostgreSQL seperti yang Menyiapkan Aurora PostgreSQL untuk menggunakan Amazon AI SageMaker diuraikan, Anda dapat menjalankan operasi dengan menggunakan fungsi tersebut. aws_sagemaker.invoke_endpoint Fungsi aws_sagemaker.invoke_endpoint hanya terhubung ke titik akhir model dalam Wilayah AWS yang sama. Jika instans database Anda memiliki replika dalam beberapa, Wilayah AWS
pastikan Anda menyiapkan dan menerapkan setiap model SageMaker AI ke setiap model. Wilayah AWS
Panggilan ke aws_sagemaker.invoke_endpoint diautentikasi menggunakan peran IAM yang Anda atur untuk mengaitkan klaster DB PostgreSQL Aurora Anda dengan layanan SageMaker AI dan titik akhir yang Anda berikan selama proses penyiapan. SageMaker Titik akhir model AI dicakup ke akun individu dan tidak bersifat publik. endpoint_nameURL tidak berisi ID akun. SageMaker AI menentukan ID akun dari token otentikasi yang disediakan oleh peran SageMaker AI IAM dari instance database.
- aws_sagemaker.invoke_endpoint
Fungsi ini mengambil titik akhir SageMaker AI sebagai input dan jumlah baris yang harus diproses sebagai batch. Ini juga membutuhkan input berbagai parameter yang diharapkan oleh titik akhir model SageMaker AI. Dokumentasi referensi fungsi ini adalah sebagai berikut.
aws_sagemaker.invoke_endpoint( IN endpoint_name varchar, IN max_rows_per_batch int, VARIADIC model_input "any", OUT model_output varchar )
Input dan output dari fungsi ini adalah sebagai berikut.
endpoint_name— URL titik akhir yang Wilayah AWS—independen.max_rows_per_batch– Jumlah baris maksimum per batch untuk pemrosesan mode batch. Untuk informasi selengkapnya, lihat Memahami mode batch dan fungsi machine learning Aurora.model_input– Satu atau beberapa parameter input untuk model. Ini bisa berupa tipe data apa pun yang dibutuhkan oleh model SageMaker AI. PostgreSQL memungkinkan Anda menentukan hingga 100 parameter input untuk satu fungsi. Tipe data array harus satu dimensi, tetapi dapat berisi elemen sebanyak yang diharapkan oleh model SageMaker AI. Jumlah input ke model SageMaker AI hanya dibatasi oleh batas ukuran pesan SageMaker AI 6 MB.model_output— Output model SageMaker AI sebagai teks.
Membuat fungsi yang ditentukan pengguna untuk memanggil model AI SageMaker
Buat fungsi terpisah yang ditentukan pengguna aws_sagemaker.invoke_endpoint untuk memanggil setiap model SageMaker AI Anda. Fungsi yang ditentukan pengguna Anda mewakili titik akhir SageMaker AI yang menghosting model. aws_sagemaker.invoke_endpointFungsi berjalan dalam fungsi yang ditentukan pengguna. User-defined fungsi memberikan banyak keuntungan:
-
Anda dapat memberikan nama model SageMaker AI Anda sendiri alih-alih hanya memanggil
aws_sagemaker.invoke_endpointsemua model SageMaker AI Anda. -
Anda dapat menentukan URL titik akhir model hanya di satu tempat di kode aplikasi SQL Anda.
-
Anda dapat mengontrol hak istimewa
EXECUTEuntuk setiap fungsi machine learning Aurora secara mandiri. -
Anda dapat menyatakan jenis input dan output model menggunakan jenis SQL. SQL memberlakukan jumlah dan jenis argumen yang diteruskan ke model SageMaker AI Anda dan melakukan konversi tipe jika perlu. Menggunakan tipe SQL juga akan diterjemahkan
SQL NULLke nilai default yang sesuai yang diharapkan oleh model SageMaker AI Anda. -
Anda dapat mengurangi ukuran batch maksimum jika Anda ingin menampilkan beberapa baris pertama sedikit lebih cepat.
Untuk menentukan fungsi yang ditentukan pengguna, gunakan pernyataan bahasa definisi data (DDL) SQL CREATE FUNCTION. Saat menentukan fungsi, Anda juga menentukan:
-
Parameter input ke model.
-
Titik akhir SageMaker AI spesifik untuk dipanggil.
-
Jenis yang ditampilkan.
Fungsi yang ditentukan pengguna mengembalikan inferensi yang dihitung oleh titik akhir SageMaker AI setelah menjalankan model pada parameter input. Contoh berikut membuat fungsi yang ditentukan pengguna untuk model SageMaker AI dengan dua parameter input.
CREATE FUNCTION classify_event (IN arg1 INT, IN arg2 DATE, OUT category INT)
AS $$
SELECT aws_sagemaker.invoke_endpoint (
'sagemaker_model_endpoint_name', NULL,
arg1, arg2 -- model inputs are separate arguments
)::INT -- cast the output to INT
$$ LANGUAGE SQL PARALLEL SAFE COST 5000;Perhatikan hal-hal berikut:
-
Input fungsi
aws_sagemaker.invoke_endpointdapat berupa satu parameter atau lebih dari jenis data apa pun. -
Contoh ini menggunakan jenis output INT. Jika Anda mengirimkan output dari jenis
varcharke jenis yang berbeda, output ini harus dikirimkan ke jenis tipe skalar default PostgreSQL sepertiINTEGER,REAL,FLOAT, atauNUMERIC. Untuk informasi selengkapnya tentang jenis ini, lihat Data typesdalam dokumentasi PostgreSQL. -
Tentukan
PARALLEL SAFEuntuk mengaktifkan pemrosesan kueri paralel. Untuk informasi selengkapnya, lihat Meningkatkan waktu respons dengan pemrosesan kueri paralel. -
Tentukan
COST 5000untuk mengestimasi biaya menjalankan fungsi. Gunakan bilangan positif yang memberikan estimasi biaya eksekusi untuk fungsi tersebut, dalam unitcpu_operator_cost.
Melewati array sebagai input ke model SageMaker AI
Fungsi aws_sagemaker.invoke_endpoint dapat memiliki hingga 100 parameter input, yang merupakan batas untuk fungsi PostgreSQL. Jika model SageMaker AI membutuhkan lebih dari 100 parameter dengan tipe yang sama, berikan parameter model sebagai array.
Contoh berikut mendefinisikan fungsi yang meneruskan array sebagai input ke model regresi SageMaker AI. Output dikirim ke nilai REAL.
CREATE FUNCTION regression_model (params REAL[], OUT estimate REAL) AS $$ SELECT aws_sagemaker.invoke_endpoint ( 'sagemaker_model_endpoint_name', NULL, params )::REAL $$ LANGUAGE SQL PARALLEL SAFE COST 5000;
Menentukan ukuran batch saat menjalankan model AI SageMaker
Contoh berikut membuat fungsi yang ditentukan pengguna untuk model SageMaker AI yang menetapkan ukuran batch default ke NULL. Fungsi ini juga memungkinkan Anda untuk memberikan ukuran batch yang berbeda saat Anda menginvokasinya.
CREATE FUNCTION classify_event (
IN event_type INT, IN event_day DATE, IN amount REAL, -- model inputs
max_rows_per_batch INT DEFAULT NULL, -- optional batch size limit
OUT category INT) -- model output
AS $$
SELECT aws_sagemaker.invoke_endpoint (
'sagemaker_model_endpoint_name', max_rows_per_batch,
event_type, event_day, COALESCE(amount, 0.0)
)::INT -- casts output to type INT
$$ LANGUAGE SQL PARALLEL SAFE COST 5000;Perhatikan hal berikut:
-
Gunakan parameter
max_rows_per_batchopsional untuk memberikan kontrol jumlah baris untuk invokasi fungsi mode batch. Jika Anda menggunakan nilai NULL, maka pengoptimal kueri secara otomatis memilih ukuran batch maksimum. Untuk informasi selengkapnya, lihat Memahami mode batch dan fungsi machine learning Aurora. -
Secara default, meneruskan NULL sebagai nilai parameter diterjemahkan ke string kosong sebelum diteruskan ke SageMaker AI. Untuk contoh ini, input memiliki jenis-jenis yang berbeda.
-
Jika Anda memiliki masukan non-teks, atau input teks yang perlu diatur ke default ke beberapa nilai selain string kosong, gunakan pernyataan
COALESCE. GunakanCOALESCEuntuk menerjemahkan NULL ke nilai pengganti null yang diinginkan dalam panggilan keaws_sagemaker.invoke_endpoint. Untuk parameteramountdalam contoh ini, nilai NULL dikonversi menjadi 0,0.
Memohon model SageMaker AI yang memiliki banyak output
Contoh berikut membuat fungsi yang ditentukan pengguna untuk model SageMaker AI yang mengembalikan beberapa output. Fungsi Anda perlu mentransmisikan output dari fungsi aws_sagemaker.invoke_endpoint ke jenis data yang terkait. Misalnya, Anda dapat menggunakan jenis titik PostgreSQL default untuk pasangan (x,y) atau jenis komposit yang ditentukan oleh pengguna.
Fungsi yang ditentukan oleh pengguna ini menampilkan nilai dari model yang menampilkan beberapa output menggunakan jenis gabungan untuk output.
CREATE TYPE company_forecasts AS ( six_month_estimated_return real, one_year_bankruptcy_probability float); CREATE FUNCTION analyze_company ( IN free_cash_flow NUMERIC(18, 6), IN debt NUMERIC(18,6), IN max_rows_per_batch INT DEFAULT NULL, OUT prediction company_forecasts) AS $$ SELECT (aws_sagemaker.invoke_endpoint('endpt_name', max_rows_per_batch,free_cash_flow, debt))::company_forecasts; $$ LANGUAGE SQL PARALLEL SAFE COST 5000;
Untuk jenis komposit, gunakan kolom dalam urutan yang sama seperti yang muncul di output model dan transmisikan keluaran aws_sagemaker.invoke_endpoint ke jenis komposit Anda. Pemanggil dapat mengekstrak kolom satu per satu, baik dengan nama maupun dengan notasi ".*" PostgreSQL.
Mengekspor data ke Amazon S3 SageMaker untuk pelatihan model AI (Lanjutan)
Kami menyarankan agar Anda terbiasa dengan pembelajaran mesin Aurora dan SageMaker AI dengan menggunakan algoritme dan contoh yang disediakan daripada mencoba melatih model Anda sendiri. Untuk informasi selengkapnya, lihat Memulai dengan Amazon SageMaker AI
Untuk melatih model SageMaker AI, Anda mengekspor data ke bucket Amazon S3. Bucket Amazon S3 digunakan oleh SageMaker AI untuk melatih model Anda sebelum digunakan. Anda dapat membuat kueri data dari klaster DB Aurora PostgreSQL dan menyimpannya langsung ke dalam file teks yang disimpan dalam bucket Amazon S3. Kemudian SageMaker AI mengkonsumsi data dari bucket Amazon S3 untuk pelatihan. Untuk informasi lebih lanjut tentang pelatihan model SageMaker AI, lihat Melatih model dengan Amazon SageMaker AI.
catatan
Saat Anda membuat bucket Amazon S3 untuk pelatihan model SageMaker AI atau penilaian batch, gunakan sagemaker nama bucket Amazon S3. Untuk informasi selengkapnya, lihat Menentukan Bucket Amazon S3 untuk Mengunggah Kumpulan Data Pelatihan dan Menyimpan Data Output di Panduan Pengembang Amazon SageMaker AI.
Untuk informasi lebih lanjut tentang mengekspor data Anda, lihat Mengekspor data dari klaster DB Aurora PostgreSQL ke Amazon S3.
Pertimbangan performa untuk machine learning Aurora dengan Aurora PostgreSQL
Layanan Amazon SageMaker Comprehend dan AI melakukan sebagian besar pekerjaan ketika dipanggil oleh fungsi pembelajaran mesin Aurora. Itu berarti Anda dapat menskalakan sumber daya tersebut sesuai kebutuhan, secara mandiri. Untuk klaster DB Aurora PostgreSQL, Anda dapat membuat panggilan fungsi seefisien mungkin. Berikut ini, Anda dapat menemukan beberapa pertimbangan performa yang perlu diperhatikan saat bekerja dengan machine learning Aurora dari Aurora PostgreSQL.
Topik
Memahami mode batch dan fungsi machine learning Aurora
Biasanya, PostgreSQL menjalankan fungsi satu baris dalam satu waktu. Machine learning Aurora dapat mengurangi overhead ini dengan menggabungkan panggilan ke layanan machine learning Aurora eksternal untuk banyak baris menjadi batch dengan pendekatan yang disebut eksekusi mode-batch. Dalam mode batch, machine learning Aurora menerima respons untuk batch baris input, lalu mengirimkan respons kembali ke kueri yang berjalan satu baris dalam satu waktu. Pengoptimalan ini meningkatkan throughput kueri Aurora Anda tanpa membatasi pengoptimal kueri PostgreSQL.
Aurora secara otomatis menggunakan mode batch jika fungsi direferensikan dari daftar SELECT, klausul WHERE, atau klausul HAVING. Perhatikan bahwa CASE ekspresi sederhana tingkat atas memenuhi syarat untuk eksekusi mode batch. Top-level CASEekspresi yang dicari juga memenuhi syarat untuk eksekusi mode batch asalkan WHEN klausa pertama adalah predikat sederhana dengan panggilan fungsi mode batch.
Fungsi yang Anda tentukan harus berupa fungsi LANGUAGE SQL dan harus mencantumkan PARALLEL SAFE dan COST 5000.
Migrasi fungsi dari pernyataan SELECT ke klausul FROM
Biasanya, fungsi aws_ml yang memenuhi syarat untuk eksekusi mode-batch secara otomatis dimigrasikan oleh Aurora ke klausul FROM.
Migrasi fungsi mode batch yang memenuhi syarat ke klausul FROM dapat diperiksa secara manual pada tingkat per kueri. Untuk melakukan ini, gunakan pernyataan EXPLAIN (serta ANALYZE dan VERBOSE) dan cari informasi "Pemrosesan Batch" di bawah setiap mode batch Function Scan. Anda juga dapat menggunakan EXPLAIN (dengan VERBOSE) tanpa menjalankan kueri. Selanjutnya, amati apakah panggilan ke fungsi tersebut muncul sebagai Function
Scan di dalam loop join bertingkat yang tidak ditentukan dalam pernyataan asli.
Dalam contoh berikut, operator loop join bertingkat dalam rencana menunjukkan bahwa Aurora memigrasi fungsi anomaly_score. Fungsi ini dimigrasikan dari daftar SELECT ke klausul FROM, yang memenuhi syarat untuk eksekusi mode-batch.
EXPLAIN (VERBOSE, COSTS false)
SELECT anomaly_score(ts.R.description) from ts.R;
QUERY PLAN
-------------------------------------------------------------
Nested Loop
Output: anomaly_score((r.description)::text)
-> Seq Scan on ts.r
Output: r.id, r.description, r.score
-> Function Scan on public.anomaly_score
Output: anomaly_score.anomaly_score
Function Call: anomaly_score((r.description)::text)Untuk menonaktifkan eksekusi mode-batch, atur parameter apg_enable_function_migration ke false. Hal ini mencegah migrasi dari fungsi aws_ml dari SELECT ke klausul FROM. Berikut caranya.
SET apg_enable_function_migration = false;Parameter apg_enable_function_migration adalah parameter Grand Unified Configuration (GUC) yang dikenali oleh ekstensi apg_plan_mgmt Aurora PostgreSQL untuk manajemen rencana kueri. Untuk menonaktifkan migrasi fungsi dalam sesi, gunakan manajemen rencana kueri untuk menyimpan rencana yang dihasilkan sebagai rencana approved. Saat runtime, manajemen rencana kueri menerapkan rencana approved dengan pengaturan apg_enable_function_migration-nya. Penerapan ini terjadi, terlepas dari pengaturan parameter GUC apg_enable_function_migration. Untuk informasi selengkapnya, lihat Mengelola rencana eksekusi kueri untuk Aurora PostgreSQL.
Menggunakan parameter max_rows_per_batch
Baik fungsi aws_comprehend.detect_sentiment maupun fungsi aws_sagemaker.invoke_endpoint memiliki parameter max_rows_per_batch. Parameter ini menentukan jumlah baris yang dapat dikirim ke layanan machine learning Aurora. Semakin besar set data yang diproses oleh fungsi Anda, semakin besar ukuran batch yang bisa Anda buat.
Batch-mode fungsi meningkatkan efisiensi dengan membangun batch baris yang menyebarkan biaya panggilan fungsi pembelajaran mesin Aurora melalui sejumlah besar baris. Namun, jika pernyataan SELECT selesai lebih awal karena klausul LIMIT, maka konsep batch dapat dibuat di lebih banyak baris daripada yang digunakan kueri. Pendekatan ini dapat mengakibatkan biaya tambahan ke AWS akun Anda. Untuk memanfaatkan eksekusi mode batch, tetapi menghindari pembuatan batch yang terlalu besar, gunakan nilai yang lebih kecil untuk parameter max_rows_per_batch dalam panggilan fungsi Anda.
Jika Anda melakukan EXPLAIN (VERBOSE, ANALYZE) kueri yang menggunakan eksekusi mode batch, Anda akan melihat operator FunctionScan yang berada di bawah loop join bertingkat. Jumlah loop yang dilaporkan EXPLAIN sama dengan frekuensi sebuah baris diambil dari operator FunctionScan. Jika pernyataan menggunakan klausul LIMIT, jumlah pengambilannya konsisten. Untuk mengoptimalkan ukuran batch, atur parameter max_rows_per_batch ke nilai ini. Namun, jika fungsi mode batch direferensikan dalam predikat dalam klausul WHERE atau klausul HAVING, Anda mungkin tidak dapat mengetahui jumlah pengambilan sebelumnya. Dalam kasus ini, gunakan loop sebagai pedoman dan percobaan dengan max_rows_per_batch untuk menemukan pengaturan yang mengoptimalkan performa.
Memverifikasi eksekusi mode batch
Untuk melihat apakah fungsi berjalan dalam mode batch, gunakan EXPLAIN ANALYZE. Jika eksekusi mode batch digunakan, rencana kueri akan menyertakan informasi di bagian "Pemrosesan Batch".
EXPLAIN ANALYZE SELECT user-defined-function();
Batch Processing: num batches=1 avg/min/max batch size=3333.000/3333.000/3333.000
avg/min/max batch call time=146.273/146.273/146.273Dalam contoh ini, ada 1 batch yang berisi 3.333 baris, yang memerlukan waktu proses 146,273 md. Bagian "Pemrosesan Batch" menunjukkan berikut:
-
Banyaknya batch yang tersedia untuk operasi pemindaian fungsi ini
-
Ukuran batch rata-rata, minimum, dan maksimum
-
Rata-rata waktu eksekusi batch, minimum, dan maksimum
Biasanya batch akhir lebih kecil daripada batch lain, yang sering kali menghasilkan ukuran batch minimum yang jauh lebih kecil dari rata-rata.
Untuk menampilkan beberapa baris pertama dengan lebih cepat, atur parameter max_rows_per_batch ke nilai yang lebih kecil.
Untuk mengurangi jumlah panggilan mode batch ke layanan ML saat Anda menggunakan LIMIT dalam fungsi yang ditentukan pengguna, atur parameter max_rows_per_batch ke nilai yang lebih kecil.
Meningkatkan waktu respons dengan pemrosesan kueri paralel
Untuk mendapatkan hasil secepat mungkin dari banyak baris, Anda dapat menggabungkan pemrosesan kueri paralel dengan pemrosesan mode batch. Anda dapat menggunakan pemrosesan kueri paralel untuk pernyataan SELECT, CREATE TABLE AS SELECT, dan CREATE
MATERIALIZED VIEW.
catatan
PostgreSQL belum mendukung kueri paralel untuk pernyataan bahasa manipulasi data (DML).
Pemrosesan kueri paralel terjadi baik dalam basis data maupun dalam layanan ML. Jumlah inti dalam kelas instans basis data membatasi tingkat paralelisme yang dapat digunakan saat menjalankan kueri. Server basis data dapat membuat konsep rencana eksekusi kueri paralel yang membagi tugas di antara sekumpulan pekerja paralel. Selanjutnya, setiap pekerja ini bisa membangun permintaan batch yang berisi puluhan ribu baris (atau sebanyak yang diizinkan oleh setiap layanan).
Permintaan batch dari semua pekerja paralel dikirim ke titik akhir SageMaker AI. Tingkat paralelisme yang dapat didukung titik akhir dibatasi oleh jumlah dan jenis instans yang mendukungnya. Untuk K tingkat paralelisme, Anda memerlukan kelas instans basis data yang memiliki setidaknya K inti. Anda juga perlu mengonfigurasi titik akhir SageMaker AI agar model Anda memiliki K instance awal dari kelas instans berkinerja cukup tinggi.
Untuk menggunakan pemrosesan kueri paralel, Anda dapat mengatur parameter parallel_workers penyimpanan dari tabel yang berisi data yang ingin Anda teruskan. Anda mengatur parallel_workers ke fungsi mode-batch seperti aws_comprehend.detect_sentiment. Jika pengoptimal memilih paket query paralel, layanan AWS ML dapat dipanggil baik dalam batch maupun paralel.
Anda dapat menggunakan parameter berikut dengan fungsi aws_comprehend.detect_sentiment untuk mendapatkan rencana dengan paralelisme empat arah. Jika Anda mengubah salah satu dari dua parameter berikut, Anda harus memulai ulang instans basis data untuk menerapkan perubahan.
-- SET max_worker_processes to 8; -- default value is 8
-- SET max_parallel_workers to 8; -- not greater than max_worker_processes
SET max_parallel_workers_per_gather to 4; -- not greater than max_parallel_workers
-- You can set the parallel_workers storage parameter on the table that the data
-- for the Aurora machine learning function is coming from in order to manually override the degree of
-- parallelism that would otherwise be chosen by the query optimizer
--
ALTER TABLE yourTable SET (parallel_workers = 4);
-- Example query to exploit both batch-mode execution and parallel query
EXPLAIN (verbose, analyze, buffers, hashes)
SELECT aws_comprehend.detect_sentiment(description, 'en')).*
FROM yourTable
WHERE id < 100;Untuk informasi selengkapnya tentang cara mengontrol kueri paralel, lihat Parallel plans
Menggunakan tampilan terwujud dan kolom terwujud
Ketika Anda memanggil AWS layanan seperti SageMaker AI atau Amazon Comprehend dari database Anda, akun Anda dibebankan sesuai dengan kebijakan harga layanan tersebut. Untuk meminimalkan biaya ke akun Anda, Anda dapat mewujudkan hasil pemanggilan AWS layanan ke kolom yang terwujud sehingga AWS layanan tidak dipanggil lebih dari sekali per baris input. Jika diinginkan, Anda dapat menambahkan kolom stempel waktu materializedAt untuk mencatat waktu saat kolom tersebut dibuat.
Latensi pernyataan INSERT baris tunggal biasa biasanya jauh lebih kecil daripada latensi pemanggilan fungsi mode batch. Dengan demikian, Anda mungkin tidak dapat memenuhi persyaratan latensi aplikasi Anda jika menginvokasi fungsi mode batch untuk setiap baris tunggal INSERT yang dijalankan oleh aplikasi Anda. Untuk mewujudkan hasil pemanggilan AWS layanan ke dalam kolom yang terwujud, aplikasi berkinerja tinggi umumnya perlu mengisi kolom yang terwujud. Untuk melakukannya, aplikasi tersebut secara berkala mengeluarkan pernyataan UPDATE yang beroperasi pada batch baris yang besar secara bersamaan.
UPDATE menggunakan penguncian level baris yang dapat memengaruhi aplikasi yang sedang berjalan. Jadi, Anda mungkin perlu menggunakan SELECT ... FOR UPDATE SKIP LOCKED, atau menggunakan MATERIALIZED
VIEW.
Kueri analitik yang beroperasi pada banyak baris secara real-time dapat menggabungkan perwujudan mode batch dengan pemrosesan real-time. Untuk melakukan ini, kueri ini mengumpulkan UNION ALL dari hasil yang telah diwujudkan sebelumnya dengan kueri di atas baris yang belum memiliki hasil yang terwujud. Dalam beberapa kasus, UNION ALL seperti itu diperlukan di banyak tempat, atau kueri dibuat oleh aplikasi pihak ketiga. Jika demikian, Anda dapat membuat VIEW untuk merangkum operasi UNION ALL sehingga detail ini tidak diekspos ke aplikasi SQL lainnya.
Anda bisa menggunakan tampilan terwujud untuk mewujudkan hasil dari pernyataan SELECT arbitrer pada snapshot tepat waktu. Anda juga dapat menggunakannya untuk menyegarkan tampilan terwujud kapan saja di masa mendatang. Saat ini, PostgreSQL tidak mendukung refresh inkremental, sehingga setiap kali tampilan terwujud di-refresh, tampilan terwujud akan dihitung ulang sepenuhnya.
Anda dapat me-refresh tampilan terwujud dengan opsi CONCURRENTLY, yang memperbarui konten tampilan terwujud tanpa mengambil kunci eksklusif. Tindakan ini memungkinkan aplikasi SQL membaca dari tampilan terwujud saat sedang di-refresh.
Memantau machine learning Aurora
Anda dapat memantau fungsi aws_ml dengan mengatur parameter track_functions di grup parameter klaster DB kustom Anda ke all. Secara default, parameter ini diatur ke pl yang berarti bahwa hanya fungsi bahasa prosedur yang akan dilacak. Dengan mengubah ini menjadi all, fungsi aws_ml juga akan dilacak. Untuk informasi selengkapnya, lihat Run-time Statistik
Untuk informasi tentang pemantauan kinerja operasi SageMaker AI yang disebut dari fungsi pembelajaran mesin Aurora, lihat Memantau Amazon SageMaker AI di Panduan Pengembang Amazon SageMaker AI.
Dengan track_functions diatur ke all, Anda dapat mengueri tampilan pg_stat_user_functions untuk mendapatkan statistik tentang fungsi yang Anda tentukan dan gunakan untuk menginvokasi layanan machine learning Aurora. Untuk setiap fungsi, tampilan ini memberikan jumlah calls, total_time, dan self_time.
Untuk melihat statistik untuk fungsi aws_sagemaker.invoke_endpoint dan aws_comprehend.detect_sentiment, Anda dapat memfilter hasil berdasarkan nama skema menggunakan kueri berikut.
SELECT * FROM pg_stat_user_functions WHERE schemaname LIKE 'aws_%';
Untuk menghapus statistik, ikuti langkah berikut.
SELECT pg_stat_reset();
Anda bisa mendapatkan nama fungsi SQL Anda yang memanggil fungsi aws_sagemaker.invoke_endpoint dengan mengueri katalog sistem pg_proc PostgreSQL. Katalog ini menyimpan informasi tentang fungsi, prosedur, dan banyak lagi. Untuk informasi selengkapnya, lihat pg_procproname) yang sumbernya (prosrc) mencakup teks invoke_endpoint.
SELECT proname FROM pg_proc WHERE prosrc LIKE '%invoke_endpoint%';
