Amazon Redshift 將不再支援在 2026 年 6 月 30 日之後使用 Python UDFs。我們將開始分階段強制執行。如需 Python 生命週期結束和遷移選項的詳細資訊,請參閱 2025 年 6 月 30 日發佈的部落格文章
本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
教學課程:從 Amazon S3 載入資料
本教學將從頭到尾引導您完成從 Amazon S3 儲存貯體中的資料檔案將資料載入 Amazon Redshift 資料庫資料表的過程。
在此教學課程中,您將執行下列操作:
-
下載使用逗點分隔值 (CSV)、字元分隔或固定寬度格式的資料檔案。
-
建立 Amazon S3 儲存貯體,然後上傳資料檔案至該儲存貯體。
-
啟動 Amazon Redshift 叢集並建立資料庫資料表。
-
使用 COPY 命令從 Amazon S3 上的資料檔案載入資料表。
-
對載入錯誤進行故障診斷,並修改 COPY 命令來更正錯誤。
先決條件
您需要以下的事前準備:
-
用來啟動 Amazon Redshift 叢集並在 Amazon S3 中建立儲存貯體 AWS 的帳戶。
-
用於從 Amazon S3 載入測試資料的 AWS 登入資料 (IAM 角色)。如果您需要新的 IAM 角色,請前往建立 IAM 角色。
-
SQL 用戶端,例如 Amazon Redshift 主控台查詢編輯器。
本教學課程設計為可獨立進行。除了本教學課程之外,我們也建議您完成下列教學課程,以便更全面地了解如何設計和使用 Amazon Redshift 資料庫:
-
Amazon Redshift 入門指南會逐步引導您完成建立 Amazon Redshift 叢集和載入範例資料的程序。
概觀
您可以使用 INSERT 命令或 COPY 命令將資料新增至您的 Amazon Redshift 資料表。以 Amazon Redshift 資料倉儲的規模和速度,COPY 命令比 INSERT 命令快許多倍且更有效率。
COPY 命令會使用 Amazon Redshift 大量平行處理 (MPP) 架構,從多個資料來源平行讀取和載入資料。您可以從 Amazon S3、Amazon EMR 或任何可透過 Secure Shell (SSH) 連線存取遠端主機上的資料檔案進行載入。或者,您可以直接從 Amazon DynamoDB 資料表載入。
在本教學中,您會使用 COPY 命令從 Amazon S3 載入資料。在此運用的許多原則也適合用於從其他資料來源載入。
若要進一步了解 COPY 命令的使用,請參閱以下資源:
步驟 1:建立叢集
如果您已有想要使用的叢集,則可略過此步驟。
針對本教學中的練習,請使用四個節點的叢集。
建立叢集
-
登入 AWS Management Console ,並在 https://console.aws.amazon.com/redshiftv2/
:// 開啟 Amazon Redshift 主控台。 在導覽功能表上,選擇已佈建的叢集儀表板。
重要
請確定您具備執行叢集操作的必要許可。如需授予必要許可的資訊,請參閱授權 Amazon Redshift 存取 AWS 服務。
-
在右上角,選擇您要在其中建立叢集 AWS 的區域。基於本教學的用途,請選擇美國西部 (奧勒岡)。
-
在導覽選單上,選擇叢集,然後選擇建立叢集。建立叢集頁面隨即出現。
-
在建立叢集頁面上輸入叢集的參數。為參數選擇您自己的值,但變更下列值時除外:
選擇
dc2.large作為節點類型。選擇
4作為節點數目。在叢集許可區段中,從可用 IAM 角色中選擇 IAM 角色。此角色應為您先前建立的角色,且具備 Amazon S3 的存取權限。然後選擇與 IAM 角色建立關聯來將其新增至叢集的已關聯 IAM 角色清單。
-
選擇建立叢集。
遵循 Amazon Redshift 入門指南中的步驟,從 SQL 用戶端連線至您的叢集,並測試連線。您不需要完成「入門」其餘的建立資料表、上傳資料、嘗試範例查詢步驟。
步驟 2:下載資料檔案
在此步驟,您會下載一組範例資料檔案到您的電腦。在下一個步驟,您會將檔案上傳到 Amazon S3 儲存貯體。
下載資料檔案
-
下載壓縮檔:LoadingDataSampleFiles.zip。
-
將檔案解壓縮至您電腦中的資料夾。
-
確認資料夾中包含下列檔案。
customer-fw-manifest customer-fw.tbl-000 customer-fw.tbl-000.bak customer-fw.tbl-001 customer-fw.tbl-002 customer-fw.tbl-003 customer-fw.tbl-004 customer-fw.tbl-005 customer-fw.tbl-006 customer-fw.tbl-007 customer-fw.tbl.log dwdate-tab.tbl-000 dwdate-tab.tbl-001 dwdate-tab.tbl-002 dwdate-tab.tbl-003 dwdate-tab.tbl-004 dwdate-tab.tbl-005 dwdate-tab.tbl-006 dwdate-tab.tbl-007 part-csv.tbl-000 part-csv.tbl-001 part-csv.tbl-002 part-csv.tbl-003 part-csv.tbl-004 part-csv.tbl-005 part-csv.tbl-006 part-csv.tbl-007
步驟 3:上傳檔案至 Amazon S3 儲存貯體
在此步驟,您要建立 Amazon S3 儲存貯體,並將資料檔案上傳至該儲存貯體。
將檔案上傳至 Amazon S3 儲存貯體
-
在 Amazon S3 中建立儲存貯體。
如需有關建立儲存貯體的詳細資訊,請參閱《Amazon Simple Storage Service 使用者指南》中的建立儲存貯體。
-
登入 AWS Management Console ,並在 https://console.aws.amazon.com/s3/
:// 開啟 Amazon S3 主控台。 -
選擇建立儲存貯體。
-
選擇 AWS 區域。
在和叢集相同的區域中建立儲存貯體。如果叢集位於美國西部 (奧勒岡) 區域,請選擇美國西部 (奧勒岡) 區域 (us-west-2)。
-
在建立儲存貯體對話方塊的儲存貯體名稱中,輸入儲存貯體名稱。
在 Amazon S3 現有的所有儲存貯體名稱中,您選擇的儲存貯體名稱必須是唯一的。其中一種協助確保唯一性的方法是在儲存貯體名稱的前面加上組織名稱。儲存貯體名稱必須符合一些規則。如需詳細資訊,請參閱 Amazon Simple Storage Service 使用者指南中的儲存貯體限制與局限。
-
為其餘選項選擇建議的預設值。
-
選擇建立儲存貯體。
當 Amazon S3 成功建立您的儲存貯體,主控台會在儲存貯體面板中顯示您的空儲存貯體。
-
-
建立資料夾。
-
選擇新儲存貯體的名稱。
-
選擇建立資料夾按鈕。
-
將新資料夾命名為
load。注意
您建立的儲存貯體不在沙盒中。在此練習中,您會將物件新增至真正的儲存貯體。您需要為您在儲存貯體中儲存物件的期間支付一筆名目費用。如需 Amazon S3 定價的相關資訊,請移至 Amazon S3 定價
頁面。
-
-
將資料檔案上傳至新的 Amazon S3 儲存貯體。
-
選擇資料夾的名稱。
-
在上傳精靈中,選擇新增檔案。
遵循 Amazon S3 主控台的指示,上傳您下載並擷取的所有檔案。
-
選擇上傳。
-
使用者登入資料
Amazon Redshift COPY 命令必須具有讀取 Amazon S3 儲存貯體中檔案物件的存取權。如果您使用相同的使用者登入資料來建立 Amazon S3 儲存貯體以及執行 Amazon Redshift COPY 命令,COPY 命令會具備所有必要的許可。如果您要使用不同的使用者登入資料,可以使用 Amazon S3 存取控制來授予存取權。Amazon Redshift COPY 命令至少需具備 ListBucket 和 GetObject 許可,才能存取 Amazon S3 儲存貯體中的檔案物件。如需對 Amazon S3 資源的存取控制相關資訊,請參閱管理對 Amazon S3 資源的存取許可。
步驟 4:建立範例資料表
在本教學課程中,您會使用以星狀結構描述基準化分析 (SSB) 結構描述為基礎的一組資料表。下圖顯示 SSB 資料模型。
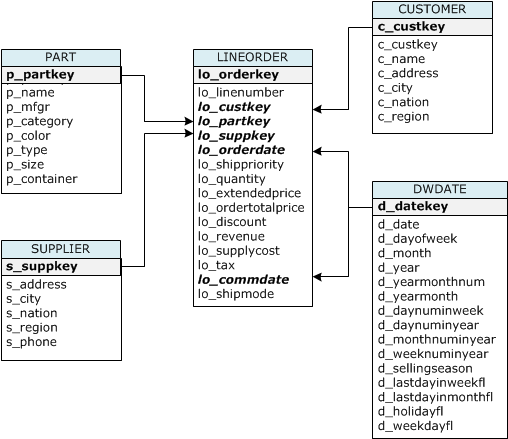
SSB 資料表可能已存在於目前的資料庫中。如果目前資料庫中已有 SSB 資料表,您必須先卸除資料表,將其從資料庫中移除,然後在下一個步驟使用 CREATE TABLE 命令建立。本教學課程中使用的資料表可能會有和現有資料表不同的屬性。
建立範例資料表
-
若要捨棄 SSB 資料表,請在 SQL 用戶端中執行下列命令。
drop table part cascade; drop table supplier; drop table customer; drop table dwdate; drop table lineorder; -
在 SQL 用戶端中執行下列 CREATE TABLE 命令。
CREATE TABLE part ( p_partkey INTEGER NOT NULL, p_name VARCHAR(22) NOT NULL, p_mfgr VARCHAR(6), p_category VARCHAR(7) NOT NULL, p_brand1 VARCHAR(9) NOT NULL, p_color VARCHAR(11) NOT NULL, p_type VARCHAR(25) NOT NULL, p_size INTEGER NOT NULL, p_container VARCHAR(10) NOT NULL ); CREATE TABLE supplier ( s_suppkey INTEGER NOT NULL, s_name VARCHAR(25) NOT NULL, s_address VARCHAR(25) NOT NULL, s_city VARCHAR(10) NOT NULL, s_nation VARCHAR(15) NOT NULL, s_region VARCHAR(12) NOT NULL, s_phone VARCHAR(15) NOT NULL ); CREATE TABLE customer ( c_custkey INTEGER NOT NULL, c_name VARCHAR(25) NOT NULL, c_address VARCHAR(25) NOT NULL, c_city VARCHAR(10) NOT NULL, c_nation VARCHAR(15) NOT NULL, c_region VARCHAR(12) NOT NULL, c_phone VARCHAR(15) NOT NULL, c_mktsegment VARCHAR(10) NOT NULL ); CREATE TABLE dwdate ( d_datekey INTEGER NOT NULL, d_date VARCHAR(19) NOT NULL, d_dayofweek VARCHAR(10) NOT NULL, d_month VARCHAR(10) NOT NULL, d_year INTEGER NOT NULL, d_yearmonthnum INTEGER NOT NULL, d_yearmonth VARCHAR(8) NOT NULL, d_daynuminweek INTEGER NOT NULL, d_daynuminmonth INTEGER NOT NULL, d_daynuminyear INTEGER NOT NULL, d_monthnuminyear INTEGER NOT NULL, d_weeknuminyear INTEGER NOT NULL, d_sellingseason VARCHAR(13) NOT NULL, d_lastdayinweekfl VARCHAR(1) NOT NULL, d_lastdayinmonthfl VARCHAR(1) NOT NULL, d_holidayfl VARCHAR(1) NOT NULL, d_weekdayfl VARCHAR(1) NOT NULL ); CREATE TABLE lineorder ( lo_orderkey INTEGER NOT NULL, lo_linenumber INTEGER NOT NULL, lo_custkey INTEGER NOT NULL, lo_partkey INTEGER NOT NULL, lo_suppkey INTEGER NOT NULL, lo_orderdate INTEGER NOT NULL, lo_orderpriority VARCHAR(15) NOT NULL, lo_shippriority VARCHAR(1) NOT NULL, lo_quantity INTEGER NOT NULL, lo_extendedprice INTEGER NOT NULL, lo_ordertotalprice INTEGER NOT NULL, lo_discount INTEGER NOT NULL, lo_revenue INTEGER NOT NULL, lo_supplycost INTEGER NOT NULL, lo_tax INTEGER NOT NULL, lo_commitdate INTEGER NOT NULL, lo_shipmode VARCHAR(10) NOT NULL );
步驟 5:執行 COPY 命令
您會執行 COPY 命令載入 SSB 結構描述中的每個資料表。在 COPY 命令範例中,將示範使用 COPY 命令的幾個選項從不同檔案格式載入資料,以及進行載入錯誤的故障診斷。
COPY 命令語法
COPY 命令基本語法如下。
COPY table_name [ column_list ] FROM data_source CREDENTIALS access_credentials [options]
執行 COPY 命令需提供下列值。
資料表名稱
COPY 命令的目標資料表。此資料表必須已存在於資料庫中。此資料表可以是暫時性或持久性。COPY 命令會將新的輸入資料附加到資料表中任何現有的資料列。
資料欄清單
根據預設,COPY 會按照順序從來源資料將欄位載入資料表的資料欄。您可以選擇指定資料欄清單 (以逗號分隔資料欄名稱的清單),以便將資料欄位映射到特定的資料欄。您在本教學中不會使用資料行清單。如需詳細資訊,請參閱 COPY 命令參考資料中的Column List。
資料來源
您可以使用 COPY 命令從 Amazon S3 儲存貯體、Amazon EMR 叢集、透過 SSH 連線的遠端主機、或 Amazon DynamoDB 資料表載入資料。在本教學中,您會從 Amazon S3 儲存貯體中的資料檔案載入資料。從 Amazon S3 進行載入時,您必須提供儲存貯體的名稱和資料檔案的位置。若要執行此作業,請提供資料檔案的物件路徑,或是明確列出每個資料檔案及其位置的資訊清單檔案位置。
-
金鑰字首
使用物件索引鍵可以唯一識別儲存在 Amazon S3 中的物件。物件索引鍵包含儲存貯體名稱、資料夾名稱、物件名稱 (如果有)。物件索引鍵字首是指具有相同字首的多個物件。物件路徑就是一種索引鍵字首,COPY 命令用來用來載入具有該索引鍵字首的所有物件。例如,索引鍵字首
custdata.txt可以是指單一檔案或數個檔案,包括custdata.txt.001、custdata.txt.002等。 -
清單檔案
在某些案例中,您可能需要載入具有不同字首的檔案,例如從多個儲存貯體或資料夾進行載入。在其他案例中,您可能需要排除具有特定字首的檔案。在這些案例中,您可以使用資訊清單檔案。資訊清單檔案會明確列出每個載入檔案及其唯一物件索引鍵。稍後在本教學中,您會使用資訊清單檔案載入 PART 資料表。
憑證
若要存取包含要載入資料 AWS 的資源,您必須為具有足夠權限的使用者提供 AWS 存取憑證。這些登入資料包括 IAM 角色 Amazon Resource Name (ARN)。若要從 Amazon S3 載入資料,登入資料必須包含 ListBucket 和 GetObject 許可。如果您的資料已加密,則需要其他登入資料。如需詳細資訊,請參閱 COPY 命令參考資料中的授權參數。如需管理存取權的相關資訊,請前往管理對 Amazon S3 資源的存取許可。
選項
您可以指定數個參數搭配 COPY 命令,藉此指定檔案格式、管理資料格式、管理錯誤、控制其他功能。在本教學中,您會使用下列 COPY 命令選項和功能:
-
金鑰字首
如需如何透過指定金鑰前綴從多個檔案載入的相關資訊,請參閱使用 NULL AS 載入 PART 資料表。
-
CSV format (CSV 格式)
如需如何載入 CSV 格式資料的相關資訊,請參閱使用 NULL AS 載入 PART 資料表。
-
NULL AS
如需如何使用 NULL AS 選項載入 PART 的相關資訊,請參閱使用 NULL AS 載入 PART 資料表。
-
字元分隔的格式
如需如何使用 DELIMITER 選項的相關資訊,請參閱DELIMITER 和 REGION 選項。
-
REGION
如需如何使用 REGION 選項的相關資訊,請參閱DELIMITER 和 REGION 選項。
-
固定格式寬度
如需如何從固定寬度資料載入 CUSTOMER 資料表的相關資訊,請參閱使用 MANIFEST 載入 CUSTOMER 資料表。
-
MAXERROR
如需如何使用 MAXERROR 選項的相關資訊,請參閱使用 MANIFEST 載入 CUSTOMER 資料表。
-
ACCEPTINVCHARS
如需如何使用 ACCEPTINVCHARS 選項的相關資訊,請參閱使用 MANIFEST 載入 CUSTOMER 資料表。
-
MANIFEST
如需如何使用 MANIFEST 選項的相關資訊,請參閱使用 MANIFEST 載入 CUSTOMER 資料表。
-
DATEFORMAT
如需如何使用 DATEFORMAT 選項的相關資訊,請參閱使用 DATEFORMAT 載入 DWDATE 資料表。
-
GZIP、LZOP 與 BZIP2
如需有關如何壓縮檔案的相關資訊,請參閱載入多個資料檔案。
-
COMPUPDATE
如需如何使用 COMPUPDATE 選項的相關資訊,請參閱載入多個資料檔案。
-
多個檔案
如需如何載入多個檔案的相關資訊,請參閱載入多個資料檔案。
載入 SSB 資料表
您會使用下列 COPY 命令載入 SSB 結構描述中的每個資料表。每個資料表的命令分別示範不同的 COPY 選項以及故障診斷技巧。
若要載入 SSB 資料表,請遵循以下步驟:
取代儲存貯體名稱和 AWS 登入資料
本教學課程中的 COPY 命令為以下格式。
copy table from 's3://<your-bucket-name>/load/key_prefix' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' options;
針對所有 COPY 命令,執行下列操作:
-
將
<your-bucket-name>取代為與您的叢集位於同一區域的儲存貯體名稱。本步驟假設儲存貯體與叢集位於同一區域。或者,您可以使用 REGION 選項搭配 COPY 命令來指定區域。
-
將
<aws-account-id>和<role-name>取代為您自己的 AWS 帳戶 和 IAM 角色。以單引號括住的登入資料字串區段不可包含任何空格或分行符號。請注意,ARN 的格式可能與範例略有不同。最好從 IAM 主控台複製角色的 ARN,以確保在執行 COPY 命令時正確無誤。
使用 NULL AS 載入 PART 資料表
在此步驟中,您將使用 CSV 和 NULL AS 選項載入 PART 資料表。
COPY 命令可以從多個檔案平行載入資料,這比從單一檔案載入更快速。為了示範這個原則,本教學課程將每個資料表中的資料分成八個檔案,即使檔案很小。在稍後的步驟中,您會比較從單一檔案與從多個檔案載入之間的時間差異。如需詳細資訊,請參閱載入資料檔案。
金鑰字首
您可以透過為數個檔案指定索引鍵字首,或在資訊清單檔案中明確列出檔案,來從多個檔案載入資料。在此步驟中,您會使用金鑰前綴。在稍後的步驟中,您會使用資訊清單檔案。's3://amzn-s3-demo-bucket/load/part-csv.tbl' 索引鍵字首會載入 load 資料夾中的下列這些檔案。
part-csv.tbl-000 part-csv.tbl-001 part-csv.tbl-002 part-csv.tbl-003 part-csv.tbl-004 part-csv.tbl-005 part-csv.tbl-006 part-csv.tbl-007
CSV format (CSV 格式)
CSV 意指以逗號分隔值,是用於匯入和匯出試算表資料的常見格式。CSV 比逗號分隔的格式更有彈性,因為它可讓您在欄位中包含引用字串。從 CSV 格式 COPY 的預設引號字元是雙引號 ( " ),但您可以使用 QUOTE AS 選項指定其他引號字元。在欄位內使用引號字元時,請多加一個引號字元來逸出此字元。
以下摘錄自 PART 資料表的 CSV 格式資料檔案,顯示以雙引號括起來的字串 ("LARGE ANODIZED
BRASS")。其也顯示了引用字串中以兩個雙引號括起來的字串 ("MEDIUM ""BURNISHED"" TIN")。
15,dark sky,MFGR#3,MFGR#47,MFGR#3438,indigo,"LARGE ANODIZED BRASS",45,LG CASE 22,floral beige,MFGR#4,MFGR#44,MFGR#4421,medium,"PROMO, POLISHED BRASS",19,LG DRUM 23,bisque slate,MFGR#4,MFGR#41,MFGR#4137,firebrick,"MEDIUM ""BURNISHED"" TIN",42,JUMBO JAR
PART 資料表的資料包含會導致 COPY 失敗的字元。在此練習中,您會對錯誤進行故障診斷,並修正錯誤。
若要載入 CSV 格式的資料,請在 COPY 命令中加入 csv。執行下列命令載入 PART 資料表。
copy part from 's3://<your-bucket-name>/load/part-csv.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' csv;
您可能會看到類似下列的錯誤訊息。
An error occurred when executing the SQL command: copy part from 's3://amzn-s3-demo-bucket/load/part-csv.tbl' credentials' ... ERROR: Load into table 'part' failed. Check 'stl_load_errors' system table for details. [SQL State=XX000] Execution time: 1.46s 1 statement(s) failed. 1 statement(s) failed.
若要取得有關錯誤的詳細資訊,請查詢 STL_LOAD_ERRORS 資料表。下列查詢使用 SUBSTRING 函數縮短資料欄以利閱讀,並使用 LIMIT 10 減少傳回的資料列數。您可以調整 substring(filename,22,25) 中的值,以符合您的儲存貯體名稱長度。
select query, substring(filename,22,25) as filename,line_number as line, substring(colname,0,12) as column, type, position as pos, substring(raw_line,0,30) as line_text, substring(raw_field_value,0,15) as field_text, substring(err_reason,0,45) as reason from stl_load_errors order by query desc limit 10;
query | filename | line | column | type | pos | --------+-------------------------+-----------+------------+------------+-----+---- 333765 | part-csv.tbl-000 | 1 | | | 0 | line_text | field_text | reason ------------------+------------+---------------------------------------------- 15,NUL next, | | Missing newline: Unexpected character 0x2c f
NULL AS
part-csv.tbl 資料檔案使用 NUL 結束字元 (\x000 或 \x0) 來指出 NULL 值。
注意
雖然看起來很像,但 NUL 和 NULL 大不相同。NUL 是有 x000 字碼指標的 UTF-8 字元,通常用於表示記錄結束 (EOR)。NULL 是用來代表缺少某個值的 SQL 值。
根據預設,COPY 會將 NUL 結束字元視為 EOR 字元並終止記錄,而這常會造成未預期的結果或錯誤。指出文字資料中的 NULL 沒有任何單一的標準方法。因此,NULL AS COPY 命令選項可讓您指定在載入資料表時,要用哪個字元替換 NULL。在此範例中,要讓 COPY 將 NUL 結束字元當作 NULL 值。
注意
必須將要接收 NULL 值的資料表欄設為 nullable。也就是說,在 CREATE TABLE 規格中,它一定不能包含 NOT NULL 限制。
若要使用 NULL AS 選項載入 PART,請執行以下 COPY 命令。
copy part from 's3://<your-bucket-name>/load/part-csv.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' csv null as '\000';
若要確認 COPY 已載入 NULL 值,執行下列命令可以僅選取包含 NULL 的資料列。
select p_partkey, p_name, p_mfgr, p_category from part where p_mfgr is null;
p_partkey | p_name | p_mfgr | p_category -----------+----------+--------+------------ 15 | NUL next | | MFGR#47 81 | NUL next | | MFGR#23 133 | NUL next | | MFGR#44 (2 rows)
DELIMITER 和 REGION 選項
DELIMITER 和 REGION 選項對於了解如何載入資料至關重要。
字元分隔的格式
字元分隔檔案中的欄位是以特殊字元隔開,例如縱線字元 ( | )、逗號 ( , ) 或 Tab 字元 ( \t )。字元分隔檔案可以使用任可單一 ASCII 字元做為分隔符號,包括其中一個非列印 ASCII 字元。請使用 DELIMITER 選項指定分隔符號。預設分隔符號是縱線字元 ( | )。
下列摘錄自 SUPPLIER 資料表的資料使用縱線分隔格式。
1|1|257368|465569|41365|19950218|2-HIGH|0|17|2608718|9783671|4|2504369|92072|2|19950331|TRUCK 1|2|257368|201928|8146|19950218|2-HIGH|0|36|6587676|9783671|9|5994785|109794|6|19950416|MAIL
REGION
您應該盡可能在與 Amazon Redshift 叢集相同的 AWS 區域中找到負載資料。如果您的資料和叢集位於相同區域中,可以降低延遲,並且避免跨區域傳輸資料的成本。如需詳細資訊,請參閱載入資料的 Amazon Redshift 最佳實務。
如果您必須從不同的 AWS 區域載入資料,請使用 REGION 選項來指定載入資料所在的 AWS 區域。如果指定區域,則所有載入資料 (包括資訊清單檔案) 都必須位於指定的區域。如需詳細資訊,請參閱REGION。
例如,如果您的叢集位於美國東部 (維吉尼亞北部),而您的 Amazon S3 儲存貯體位於美國西部 (奧勒岡) 區域,下列 COPY 命令會顯示如何從縱線分隔資料載入 SUPPLIER 資料表。
copy supplier from 's3://amzn-s3-demo-bucket/ssb/supplier.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' delimiter '|' gzip region 'us-west-2';
使用 MANIFEST 載入 CUSTOMER 資料表
在此步驟中,您會使用 FIXEDWIDTH、MAXERROR、ACCEPTINVCHARS 和 MANIFEST 選項載入 CUSTOMER 資料表。
此練習的範例資料包含 COPY 嘗試載入時會造成錯誤的字元。您會使用 MAXERRORS 選項和 STL_LOAD_ERRORS 系統資料表,針對載入錯誤進行故障診斷,然後使用 ACCEPTINVCHARS 和 MANIFEST 選項消除錯誤。
固定寬度格式
固定寬度格式將每個欄位定義為固定數量的字元,而不是使用分隔符號分隔欄位。下列摘錄自 CUSTOMER 資料表的資料使用固定寬度格式。
1 Customer#000000001 IVhzIApeRb MOROCCO 0MOROCCO AFRICA 25-705 2 Customer#000000002 XSTf4,NCwDVaWNe6tE JORDAN 6JORDAN MIDDLE EAST 23-453 3 Customer#000000003 MG9kdTD ARGENTINA5ARGENTINAAMERICA 11-783
標籤/寬度配對的順序必須完全符合資料表欄的順序。如需詳細資訊,請參閱FIXEDWIDTH。
CUSTOMER 資料表固定寬度的規格字串如下。
fixedwidth 'c_custkey:10, c_name:25, c_address:25, c_city:10, c_nation:15, c_region :12, c_phone:15,c_mktsegment:10'
若要從固定寬度資料載入 CUSTOMER 資料表,執行下列命令。
copy customer from 's3://<your-bucket-name>/load/customer-fw.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' fixedwidth 'c_custkey:10, c_name:25, c_address:25, c_city:10, c_nation:15, c_region :12, c_phone:15,c_mktsegment:10';
您應該會看到類似下列的錯誤訊息。
An error occurred when executing the SQL command: copy customer from 's3://amzn-s3-demo-bucket/load/customer-fw.tbl' credentials'... ERROR: Load into table 'customer' failed. Check 'stl_load_errors' system table for details. [SQL State=XX000] Execution time: 2.95s 1 statement(s) failed.
MAXERROR
根據預設,COPY 第一次遇到錯誤時,命令就會失敗並傳回錯誤訊息。若要在測試期間節省時間,您可以使用 MAXERROR 選項來指示 COPY 在失敗前可略過指定的錯誤數量。因為我們預料到第一次測試載入 CUSTOMER 資料表資料時會發生錯誤,請在 COPY 命令中加入 maxerror 10。
若要使用 FIXEDWIDTH 和 MAXERROR 選項進行測試,執行下列命令。
copy customer from 's3://<your-bucket-name>/load/customer-fw.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' fixedwidth 'c_custkey:10, c_name:25, c_address:25, c_city:10, c_nation:15, c_region :12, c_phone:15,c_mktsegment:10' maxerror 10;
這次,您不會看到錯誤訊息,而是得到類似下列的警示訊息。
Warnings: Load into table 'customer' completed, 112497 record(s) loaded successfully. Load into table 'customer' completed, 7 record(s) could not be loaded. Check 'stl_load_errors' system table for details.
警示表示 COPY 遇到 7 個錯誤。若要查看錯誤,請查詢 STL_LOAD_ERRORS 資料表,如以下範例所示。
select query, substring(filename,22,25) as filename,line_number as line, substring(colname,0,12) as column, type, position as pos, substring(raw_line,0,30) as line_text, substring(raw_field_value,0,15) as field_text, substring(err_reason,0,45) as error_reason from stl_load_errors order by query desc, filename limit 7;
查詢 STL_LOAD_ERRORS 的結果應如下所示。
query | filename | line | column | type | pos | line_text | field_text | error_reason --------+---------------------------+------+-----------+------------+-----+-------------------------------+------------+---------------------------------------------- 334489 | customer-fw.tbl.log | 2 | c_custkey | int4 | -1 | customer-fw.tbl | customer-f | Invalid digit, Value 'c', Pos 0, Type: Integ 334489 | customer-fw.tbl.log | 6 | c_custkey | int4 | -1 | Complete | Complete | Invalid digit, Value 'C', Pos 0, Type: Integ 334489 | customer-fw.tbl.log | 3 | c_custkey | int4 | -1 | #Total rows | #Total row | Invalid digit, Value '#', Pos 0, Type: Integ 334489 | customer-fw.tbl.log | 5 | c_custkey | int4 | -1 | #Status | #Status | Invalid digit, Value '#', Pos 0, Type: Integ 334489 | customer-fw.tbl.log | 1 | c_custkey | int4 | -1 | #Load file | #Load file | Invalid digit, Value '#', Pos 0, Type: Integ 334489 | customer-fw.tbl000 | 1 | c_address | varchar | 34 | 1 Customer#000000001 | .Mayag.ezR | String contains invalid or unsupported UTF8 334489 | customer-fw.tbl000 | 1 | c_address | varchar | 34 | 1 Customer#000000001 | .Mayag.ezR | String contains invalid or unsupported UTF8 (7 rows)
檢查結果時,您可以看到 error_reasons 資料欄中有兩則訊息:
-
Invalid digit, Value '#', Pos 0, Type: Integ這些錯誤是由
customer-fw.tbl.log檔案引起。問題在於,它是日誌檔案不是資料檔案,不應載入它。您可以使用資訊清單檔案來避免載入錯誤的檔案。 -
String contains invalid or unsupported UTF8VARCHAR 資料類型支援最多 3 個位元組的 UTF-8 多位元組字元。如果載入資料包含不支援或無效的字元,您可以使用 ACCEPTINVCHARS 選項用指定的替代字元取代每個無效字元。
另一個載入的問題比較難偵測 — 載入產生非預期的結果。若要調查這個問題,執行下列命令查詢 CUSTOMER 資料表。
select c_custkey, c_name, c_address from customer order by c_custkey limit 10;
c_custkey | c_name | c_address -----------+---------------------------+--------------------------- 2 | Customer#000000002 | XSTf4,NCwDVaWNe6tE 2 | Customer#000000002 | XSTf4,NCwDVaWNe6tE 3 | Customer#000000003 | MG9kdTD 3 | Customer#000000003 | MG9kdTD 4 | Customer#000000004 | XxVSJsL 4 | Customer#000000004 | XxVSJsL 5 | Customer#000000005 | KvpyuHCplrB84WgAi 5 | Customer#000000005 | KvpyuHCplrB84WgAi 6 | Customer#000000006 | sKZz0CsnMD7mp4Xd0YrBvx 6 | Customer#000000006 | sKZz0CsnMD7mp4Xd0YrBvx (10 rows)
這些資料列應該是獨一無二的,但其中有重複。
另一個檢查非預期結果的方法,是去確有已載入的資料列數量。在我們的案例中,應該載入 100000 列資料,但載入訊息指出載入 112497 個記錄。會載入多的資料列,是因為 COPY 載入無關的檔案 customer-fw.tbl0000.bak。
在這個練習中,您會使用資訊清單檔案來避免載入錯誤的檔案。
ACCEPTINVCHARS
根據預設,當 COPY 遇到欄位資料類型不支援的字元,會略過該資料列並傳回錯誤。如需無效 UTF-8 字元的相關資訊,請參閱多位元組字元載入錯誤。
您可以使用 MAXERRORS 選項來略過錯誤並繼續載入,然後查詢 STL_LOAD_ERRORS 來找出無效字元,接著修正資料檔案。不過,MAXERRORS 最好用於進行載入問題的故障診斷,不應廣泛使用在生產環境中。
ACCEPTINVCHARS 選項通常是管理無效字元更好的選擇。ACCEPTINVCHARS 選項會指示 COPY 用指定的有效字元取代每個無效字元,並繼續載入操作。您可以指定 NULL 除外的任何 ASCII 字元做為替代字元。預設的替代字元是問號 ( ? )。COPY 會將多位元組字元取代為相等長度的替代字元。例如,4 個位元組的字元會被取代為 '????'。
COPY 會傳回包含無效 UTF-8 字元的資料列數。其也會將項目新增至每個受影響資料列的 STL_REPLACEMENTS 系統資料表,每個節點分割最多 100 個資料列。也會取代其他無效 UTF-8 字元,但不會記錄那些取代事件。
ACCEPTINVCHARS 僅適用於 VARCHAR 欄。
您會在此步驟中使用替代字元 '^' 新增 ACCEPTINVCHARS。
MANIFEST
當您使用金鑰前綴從 Amazon S3 COPY 時,其中一個風險是您可能會載入不必要的資料表。例如,'s3://amzn-s3-demo-bucket/load/ 資料夾包含 8 個檔案,它們有相同的索引鍵字首 customer-fw.tbl:customer-fw.tbl0000、customer-fw.tbl0001 等。然而,同一資料夾中也包含無關的檔案 customer-fw.tbl.log 和 customer-fw.tbl-0001.bak。
為了確保載入所有正確的檔案,且只有正確的檔案,請使用資訊清單檔案。資訊清單是 JSON 格式的文字檔案,其中明確列出要載入之每個來源檔案的唯一物件索引鍵。檔案物件可以位於不同的資料夾或儲存貯體,但必須在同一個區域中。如需詳細資訊,請參閱MANIFEST。
以下顯示 customer-fw-manifest 的文字。
{ "entries": [ {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-000"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-001"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-002"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-003"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-004"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-005"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-006"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-007"} ] }
使用資訊清單檔案從 CUSTOMER 資料表載入資料
-
在文字編輯器中開啟
customer-fw-manifest檔案。 -
以您的儲存貯體名稱取代
<your-bucket-name>。 -
儲存檔案。
-
將檔案上傳到儲存貯體上的 load 資料夾。
-
執行下列 COPY 命令。
copy customer from 's3://<your-bucket-name>/load/customer-fw-manifest' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' fixedwidth 'c_custkey:10, c_name:25, c_address:25, c_city:10, c_nation:15, c_region :12, c_phone:15,c_mktsegment:10' maxerror 10 acceptinvchars as '^' manifest;
使用 DATEFORMAT 載入 DWDATE 資料表
在此步驟中,您會使用 DELIMITER 和 DATEFORMAT 選項載入 DWDATE 資料表。
載入 DATE 和 TIMESTAMP 資料欄時,COPY 期望是預設格式:日期為 YYYY-MM-DD,時間戳記為 YYYY-MM-DD HH:MI:SS。如果載入的資料不是使用預設格式,您可以使用 DATEFORMAT 和 TIMEFORMAT 指定格式。
下列的摘錄顯示了 DWDATE 資料表中的日期格式。注意兩個資料欄的日期格式不一致。
19920104 1992-01-04 Sunday January 1992 199201 Jan1992 1 4 4 1... 19920112 January 12, 1992 Monday January 1992 199201 Jan1992 2 12 12 1... 19920120 January 20, 1992 Tuesday January 1992 199201 Jan1992 3 20 20 1...
DATEFORMAT
您只能指定一個日期格式。如果載入資料包含不一致的格式 (可能在不同資料欄中),或是載入時格式未知,請使用 DATEFORMAT 與 'auto' 引數。指定 'auto' 時,COPY 會辨識所有有效的日期或時間格式,並將其轉換為預設格式。'auto' 選項可以辨識使用 DATEFORMAT 和 TIMEFORMAT 字串時不支援的多種格式。如需詳細資訊,請參閱對 DATEFORMAT 和 TIMEFORMAT 使用自動辨識。
若要載入 DWDATE 資料表,執行下列 COPY 命令。
copy dwdate from 's3://<your-bucket-name>/load/dwdate-tab.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' delimiter '\t' dateformat 'auto';
載入多個資料檔案
您可以使用 GZIP 和 COMPUPDATE 選項來載入資料表。
您可以從單一資料檔案或多個檔案載入資料表。執行此操作可比較兩種方法的載入時間。
GZIP、LZOP 與 BZIP2
您可以使用 gzip、lzop 或 bzip2 壓縮格式來壓縮您的檔案。從解壓縮檔案載入時,COPY 會在載入程序中將檔案解壓縮。將檔案壓縮可以節省儲存空間及縮短載入時間。
COMPUPDATE
當 COPY 載入無壓縮編碼的空資料表時,會分析載入資料並決定最佳的編碼。接著它會將資料表修改為使用這些編碼,再開始載入。這個分析程序需要一點時間,但幾乎在每個資料表都會發生一次。若要節省時報,您可以關閉 COMPUPDATE 來略過這個步驟。為了準確評估 COPY 時間,您會在這個步驟中關閉 COMPUPDATE。
多個檔案
相較於從單一檔案載入資料,COPY 命令從多個檔案平行載入資料更有效率。您可以將您的資料分割為檔案,使得檔案的數量為您叢集中配量數量的倍數。若您執行此作業,Amazon Redshift 會分割工作負載,並在配量中平均分配資料。每一節點的配量數目取決於叢集的節點大小。如需每個節點大小有多少配量的相關資訊,請參閱《Amazon Redshift 管理指南》中的關於叢集和節點。
例如,在本教學課程中,您叢集中的運算節點可以各有兩個切片,所以四節點的叢集總共有八個切片。先前的步驟將載入的資料分成八個檔案,即使檔案很小。您可以比較從單一大檔案與從多個檔案載入之間的時間差異。
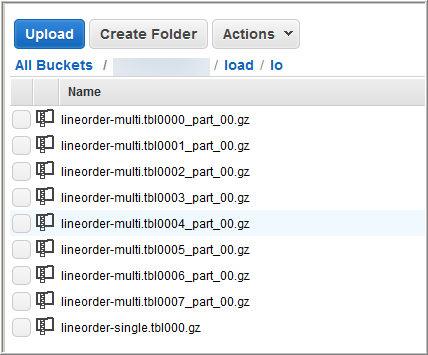
即使是包含 1500 萬筆記錄且佔用約 1.2 GB 的檔案,對於 Amazon Redshift 規模來說仍非常小。但這些檔案足以示範從多個檔案載入的效能優點。
以下影像顯示 LINEORDER 的資料檔案。
評估 COPY 多個檔案的效能
-
在實驗室測試中,執行下列命令從單一檔案 COPY (複製)。此命令會顯示虛構的儲存貯體。
copy lineorder from 's3://amzn-s3-demo-bucket/load/lo/lineorder-single.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' gzip compupdate off region 'us-east-1'; -
結果如下所示。請注意執行時間。
Warnings: Load into table 'lineorder' completed, 14996734 record(s) loaded successfully. 0 row(s) affected. copy executed successfully Execution time: 51.56s -
然後執行下列命令從多個檔案 COPY (複製)。
copy lineorder from 's3://amzn-s3-demo-bucket/load/lo/lineorder-multi.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' gzip compupdate off region 'us-east-1'; -
結果如下所示。請注意執行時間。
Warnings: Load into table 'lineorder' completed, 14996734 record(s) loaded successfully. 0 row(s) affected. copy executed successfully Execution time: 17.7s -
比較執行時間。
在我們的實驗中,載入 1500 萬筆記錄的時間從 51.56 秒縮短到 17.7 秒,減少了 65.7%。
這些結果來自於使用具有四個節點的叢集。如果您的叢集有更多節點,節省的時間會加倍。典型的 Amazon Redshift 叢集有數十到數百個節點,差別更巨大。如果您的叢集只有單一節點,執行時間的差異很小。
步驟 6:清空及分析資料庫
每當您新增、刪除或修改大量資料列時,應先後執行 VACUUM 命令及 ANALYZE 命令。vacuum (清空) 會恢復已刪除資料列的空間,並還原排序。ANALYZE 命令會更新統計中繼資料,後者可讓查詢最佳化工具產生更正確的查詢計畫。如需詳細資訊,請參閱清空資料表。
如果您以排序索引鍵的順序載入資料,清空很快。在本教學課程中,您已新增大量資料列,但是將它們新增到空資料表。在這種情況下,不需要重新排序,您也沒有刪除任何資料列。COPY 會在載入空資料表後自動更新統計,因此您的統計應該是最新的。但基於良好的內務處理,您會清空並分析資料庫以完成本教學。
若要清空並分析資料庫,執行下列命令。
vacuum; analyze;
步驟 7:清理您的資源
叢集只要執行就會繼續產生費用。完成本教學課程後,您應按照 Amazon Redshift 入門指南中的步驟 5:撤銷存取權並刪除範例叢集中的步驟,將環境恢復到先前的狀態。
如果您要保留叢集,但又想復原 SSB 資料表所使用的儲存體,請執行下列命令。
drop table part; drop table supplier; drop table customer; drop table dwdate; drop table lineorder;
下一頁
摘要
在本教學課程中,您已將檔案上傳到 Amazon S3,並使用 COPY 命令將資料從該檔案載入 Amazon Redshift 資料表。
您已使用以下格式載入資料:
-
字元分隔
-
CSV
-
固定寬度
您已使用 STL_LOAD_ERRORS 系統資料表進行載入錯誤的故障診斷,並使用 REGION、MANIFEST、MAXERROR、ACCEPTINVCHARS、DATEFORMAT、NULL AS 選項解決錯誤。
您已運用下列最佳實務來載入資料:
如需 Amazon Redshift 最佳實務的相關資訊,請參閱下列連結:
