翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
ユーザーと Amazon Lex V2 ボット間のストリーミングをアプリケーション内スタートする StartConversation オペレーションを使用します。アプリケーションからの POST リクエストにより、アプリケーションと Amazon Lex V2 ボット間の接続が確立されます。これにより、アプリケーションとボットがイベントを通じて相互の情報交換をスタートできます。
StartConversation オペレーションは、次の SDK でのみサポートされます。
ConfigurationEvent は、アプリケーションが Amazon Lex V2 ボットに送信する必要のある最初のイベントです。このイベントには、レスポンスタイプの形式などの情報が含まれます。設定イベントで使用できるパラメータを次に示します。
-
responseContentType - ボットがユーザー入力に対しテキストまたは音声で応答するかどうかを決定します。
-
sessionState - あらかじめ決められたインテントやダイアログの状態など、ボットとのストリーミングセッションに関連する情報。
-
welcomeMessages - ボットとの会話の開始時の、ユーザーに対して再生されるウェルカムメッセージを指定します。これらのメッセージは、ユーザーが何かしらの入力をする前に再生されます。ウェルカムメッセージを起動されるには、
sessionStateとdialogActionパラメータの値も指定する必要があります。 -
disablePlayback - ボットが発信者の入力を聞き始める前に、クライアントからのキューを待機するかどうかを決定します。デフォルトでは再生が有効になっているため、このフィールドの値は
falseとなります。 -
requestAttributes - リクエストに関する追加情報を提供します。
前述のパラメータの値を指定する方法については、「StartConversation オペレーションの ConfigurationEvent データタイプ」を参照してください。
ボットとアプリケーションの間の各ストリーミングには、1 つの設定イベントのみ持つことができます。アプリケーションが設定イベントを送信した後、ボットはアプリケーションから追加の通信を受け取ることができます。
ユーザーが音声を使用して Amazon Lex V2 ボットと通信するように指定した場合、アプリケーションはその会話中にボットに次のイベントを送信できます。
-
AudioInputEvent – 最大サイズが 320 バイトの音声のチャンクが含まれます。アプリケーションは、サーバーからボットにメッセージを送信するために、複数の音声入力イベントを使用する必要があります。ストリーミング内のすべての音声入力イベントは、同じ音声の形式である必要があります。
-
DTMFInputEvent – DTMF 入力をボットに送信します。DTMF キーを押すごとに、1 つのイベントに対応します。
-
PlaybackCompletionEvent – ユーザーの入力によるレスポンスが再生されたことをサーバーに通知します。ユーザーに音声レスポンスを送信する場合は、再生完了イベントを使用する必要があります。もし構成イベントの
disablePlaybackがtrueの場合、この機能は使用できません。 -
DisconnectionEvent – ユーザーが会話から切断されたことをボットに通知します。
ユーザーがテキストを使用してボットと通信するように指定した場合、アプリケーションはその会話中にボットに次のイベントを送信できます。
-
TextInputEvent – アプリケーションからボットに送信されるテキスト。最大 512 文字まで 1 つのテキスト入力イベントに追加できます。
-
PlaybackCompletionEvent – ユーザーの入力によるレスポンスが再生されたことをサーバーに通知します。音声をユーザーに再生する場合は、このイベントを使用する必要があります。もし構成イベントの
disablePlaybackがtrueの場合、この機能は使用できません。 -
DisconnectionEvent – ユーザーが会話から切断されたことをボットに通知します。
Amazon Lex V2 ボットに送信するすべてのイベントは、正しい形式でエンコードする必要があります。詳細については、「イベントストリームエンコード」を参照してください。
すべてのイベントにはイベント ID があります。ストリーミングで発生する可能性のある問題のトラブルシューティングに役立つように、各入力イベントに一意のイベント ID を割り当てます。その後、処理に失敗した場合のトラブルシューティングをボットで行うことができます。
Amazon Lex V2 では、イベントごとにタイムスタンプも使用されます。イベント ID に加えてこれらのタイムスタンプを使用して、ネットワーク伝送に関する問題のトラブルシューティングに役立てることができます。
ユーザーと Amazon Lex V2 ボット間の会話中に、ボットはユーザーに応答して次のアウトバウンドイベントを送信できます。
-
IntentResultEvent – Amazon Lex V2 がユーザーの発話から判断したインテントが含まれます。各内部結果イベントには以下が含まれます。
-
inputMode - ユーザーの発話のタイプ。有効な値は
Speech、DTMF、またはTextです。 -
interpretations - Amazon Lex V2 がユーザーの発話から判断する解釈。
-
requestAttributes - Lambda 関数でリクエスト属性を変更していない場合、この属性は会話のスタート時に渡された属性と同じになります。
-
sessionId - 会話に使用されるセッション識別子。
-
sessionState - Amazon Lex V2 とのユーザーのセッションの状態。
-
-
TranscriptEvent – ユーザーがアプリケーションへの入力を行った場合、このイベントには、ボットに対するユーザーの発話の内容が記録されます。ユーザー入力がない場合、
TranscriptEventはアプリケーションでは受け取られません。アプリケーションに送信されるトランスクリプトイベントの値は、会話モードとして音声 (スピーチおよび DMTF) とテキストのどちらを指定したかによって異なります。
-
音声入力のトランスクリプト - ユーザーがボットと話している場合、トランスクリプトイベントはユーザーの音声の書き起こしになります。これは、ユーザーが話し始めた時点から話し終わるまでのすべてのスピーチのトランスクリプトです。
-
DTMF 入力のトランスクリプト - ユーザーがキーパッドで入力している場合、トランスクリプトイベントには、ユーザーが入力で押したすべての数字が含まれます。
-
テキスト入力のトランスクリプト - ユーザーがテキスト入力を行っている場合、トランスクリプトイベントにはユーザーの入力したすべてのテキストが含まれます。
-
-
TextResponseEvent – テキスト形式のボットのレスポンスを含んでいます。デフォルトで、テキストレスポンスが返されます。音声レスポンスを返すように Amazon Lex V2 を設定した場合、このテキストは音声レスポンスの生成に使用されます。各テキストレスポンスイベントには、ボットがユーザーに返すメッセージオブジェクトの配列が含まれています。
-
AudioResponseEvent –
TextResponseEventで生成されたテキストから合成された音声レスポンスを含みます。音声レスポンスイベントを受信するには、音声レスポンスを提供するように Amazon Lex V2 を設定する必要があります。すべての音声レスポンスイベントで同じ音声の形式になります。各イベントには 100 バイト以下の音声のチャンクが含まれます。Amazon Lex V2 は、空の音声のチャンクをbytesフィールドセットでnullに送り、アプリケーションに音声レスポンスイベントの終了を示します。 -
PlaybackInterruptionEvent – ボットがアプリケーションに送信したレスポンスをユーザーが中断すると、Amazon Lex V2 はこのイベントをトリガーしてレスポンスの再生を停止します。
-
HeartbeatEvent - Amazon Lex V2 はこのイベントを定期的に返して、アプリケーションとボットの間の接続がタイムアウトしないようにします。
Amazon Lex V2 ボットを使用する際の音声会話イベントの時系列
次の図表は、ユーザーと Amazon Lex V2 ボット間のストリーミングの会話音声を示しています。アプリケーションは継続的に音声をボットにストリーミングし、ボットは音声からユーザー入力を探します。この例では、ユーザーとボットの両方が音声を使用して通信しています。各図表は、ユーザーの発話とその発話に対するボットの反応に対応しています。
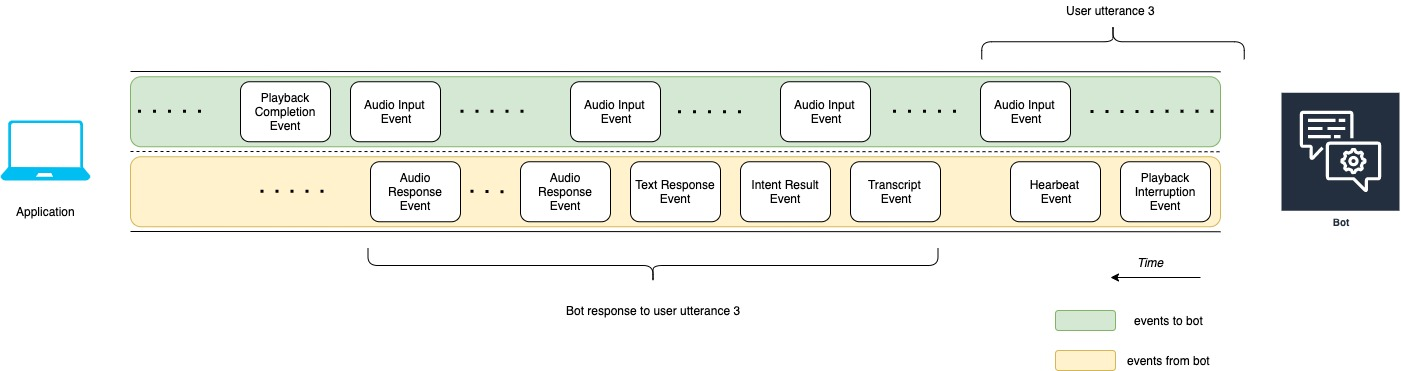
次の図表は、アプリケーションとボットの間の会話の始まりを示しています。ストリーミングは時間軸ゼロ (t0) から始まります。
次のリストは、前の図表のイベントについて説明しています。
-
t0: アプリケーションはボットに設定イベントを送信してストリーミングをスタートします。
-
t1: アプリケーションは音声データをストリーミングします。このデータは、アプリケーションからの一連の入力イベントに分割されます。
-
t2: ユーザーの発話 1 では、ユーザーが話し始めたときにボットが音声入力イベントを検出します。
-
t2: ユーザーが話している間、ボットはハートビートイベントを送信して接続を維持します。接続がタイムアウトしないように、これらのイベントを断続的に送信します。
-
t3: ボットはユーザーの発話の終わりを検出します。
-
t4: ボットは、ユーザーのスピーチのトランスクリプトを含むトランスクリプトイベントをアプリケーションに送信します。これが ユーザーの発話に対するボットのレスポンス 1 の始まりです。
-
t5: ボットは、ユーザーが実行したいアクションを示すインテントの結果イベントを送信します。
-
t6: ボットは、テキストレスポンスイベントでレスポンスをテキストとして提供し始めます。
-
t7: ボットは、ユーザーのために再生するよう、一連の音声レスポンスイベントをアプリケーションに送信します。
-
t8: ボットは別のハートビートイベントを送信して、断続的に接続を維持します。
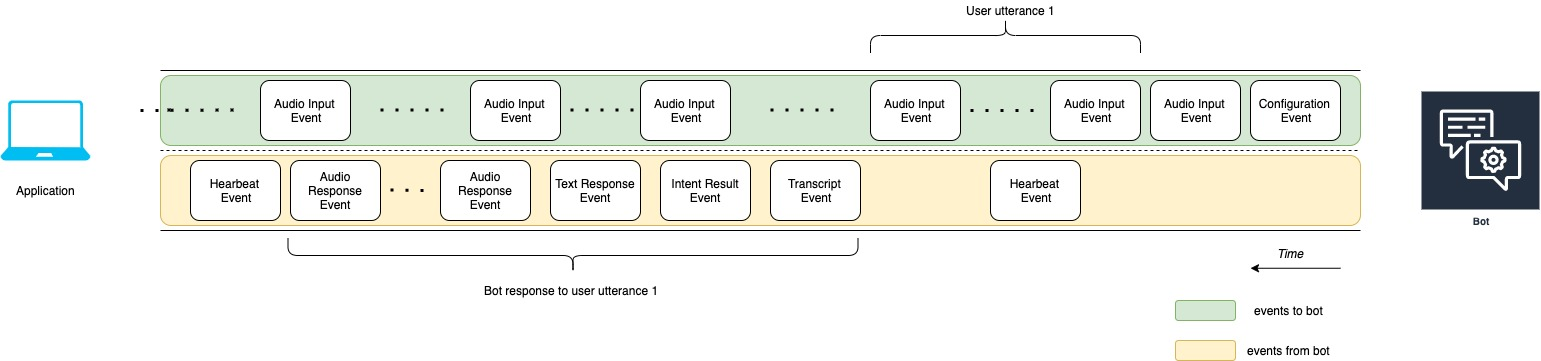
次の図表は、前の図表の続きです。これは、ユーザーのために音声レスポンスの再生を停止したことを示すために、ボットに再生完了イベントを送信するアプリケーションを示します。アプリケーションは ユーザーの発話に対するボットのレスポンス 1 をユーザーに再生します。ユーザーは ユーザー発話に対するボット応答 1 に対して ユーザーの発話 2 で応答します。
次のリストは、前の図表のイベントについて説明しています。
-
t10: アプリケーションは、ユーザーにボットのメッセージの再生が終了したことを示す再生完了イベントを送信します。
-
t11: アプリケーションはユーザーのレスポンスである ユーザーの発話 2 をボットに送信します。
-
t12: ユーザーの発話に対するボットのレスポンス 2 では、ボットはユーザーの発話の終了まで待機し、その後音声レスポンスの提供を開始します。
-
t13: ボットは ユーザーの発話に対するボットのレスポンス 2 をアプリケーションに送信している間、ユーザーの発話 3 のスタートを検出します。ボットは ユーザーの発話に対するボットのレスポンス 2 を停止し、再生中断イベントを送信します。
-
t14: ボットは、ユーザーがプロンプトを中断したことを知らせるために、再生中断イベントをアプリケーションに送信します。
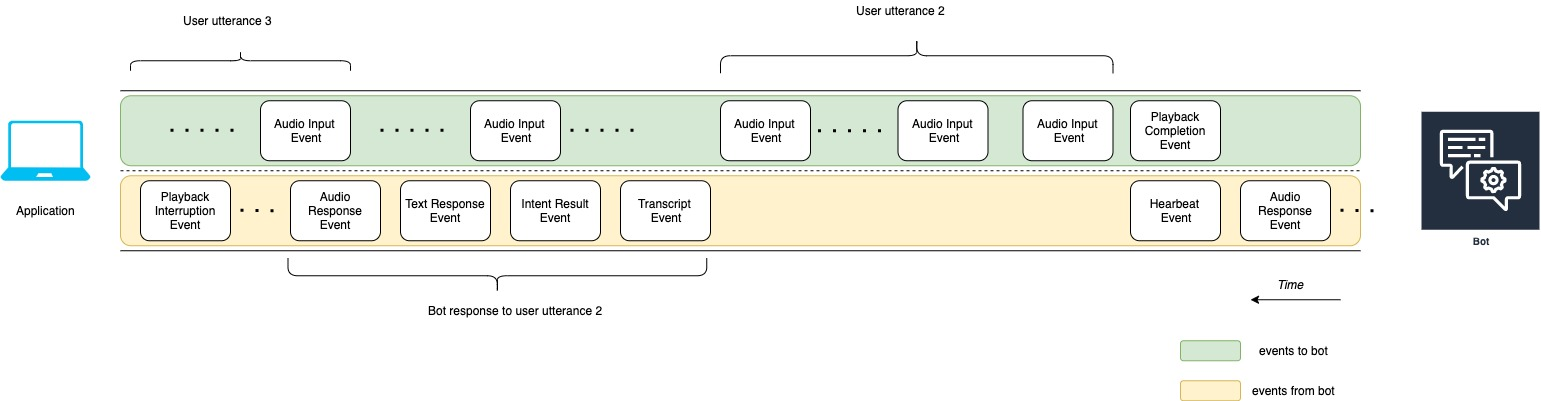
次の図表は、ユーザーの発話に対するボットのレスポンス 3 であり、ボットがユーザーの発話に応答した後も会話が続くことを示しています。