As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Solução para monitorar a infraestrutura do Amazon EKS com o Amazon Managed Grafana
O monitoramento da infraestrutura do Amazon Elastic Kubernetes Service é um dos cenários mais comuns para os quais o Amazon Managed Grafana é usado. Esta página descreve um modelo que oferece uma solução para esse cenário. A solução pode ser instalada usando AWS Cloud Development Kit (AWS CDK) ou com o Terraform
Essa solução configura:
-
O espaço de trabalho do Amazon Managed Service for Prometheus armazena métricas do cluster do Amazon EKS e cria um coletor gerenciado para extrair as métricas e enviá-las para esse espaço de trabalho. Para obter mais informações, consulte Métricas de ingestão com coletores AWS gerenciados.
-
Coleta de registros do seu cluster Amazon EKS usando um CloudWatch agente. Os registros são armazenados e consultados pelo Amazon Managed Grafana. CloudWatch Para obter mais informações, consulte Logging for Amazon EKS.
-
Seu espaço de trabalho do Amazon Managed Grafana para extrair esses logs e métricas e criar dashboards e alertas para ajudar a monitorar o cluster.
Aplicar essa solução criará dashboards e alertas que vão:
-
Avaliar a integridade geral do cluster do Amazon EKS.
-
Mostrar a integridade e a performance do ambiente de gerenciamento do Amazon EKS.
-
Mostrar a integridade e a performance do plano de dados do Amazon EKS.
-
Exibir insights sobre as workloads do Amazon EKS em namespaces do Kubernetes.
-
Exibir o uso de recursos em todos os namespaces, incluindo uso de CPU, memória, disco e rede.
Sobre esta solução
Essa solução configura um espaço de trabalho do Amazon Managed Grafana para fornecer métricas para o cluster Amazon EKS. As métricas são usadas para gerar dashboards e alertas.
As métricas ajudam você a operar clusters do Amazon EKS com mais eficiência, fornecendo insights sobre a integridade e a performance do ambiente de gerenciamento e do plano de dados Kubernetes. Você pode entender o cluster do Amazon EKS desde o nível do nó até os pods e o nível do Kubernetes, incluindo o monitoramento detalhado do uso de recursos.
A solução fornece recursos antecipatórios e corretivos:
-
Os recursos antecipatórios incluem:
-
Gerenciar a eficiência dos recursos orientando as decisões de programação. Por exemplo, para fornecer SLAs de performance e confiabilidade aos usuários internos do cluster do Amazon EKS, você pode alocar recursos suficientes de CPU e memória para as workloads com base no rastreamento do uso histórico.
-
Previsões de uso: com base na utilização atual dos recursos de cluster do Amazon EKS, como nós, volumes persistentes com suporte do Amazon EBS ou Application Load Balancers, você pode planejar com antecedência, por exemplo, um novo produto ou projeto com demandas semelhantes.
-
Detecte possíveis problemas com antecedência: por exemplo, ao analisar as tendências de consumo de recursos no nível do namespace do Kubernetes, você pode entender a sazonalidade do uso da workload.
-
-
Os recursos corretivos incluem:
-
Diminua o tempo médio de detecção (MTTD) de problemas na infraestrutura e no nível da workload do Kubernetes. Por exemplo, ao examinar o dashboard de solução de problemas, você pode testar rapidamente hipóteses sobre o que deu errado e eliminá-las.
-
Determine em que parte da pilha um problema está acontecendo. Por exemplo, o plano de controle do Amazon EKS é totalmente gerenciado AWS e determinadas operações, como atualizar uma implantação do Kubernetes, podem falhar se o servidor da API estiver sobrecarregado ou a conectividade for afetada.
-
A imagem a seguir mostra um exemplo da pasta do dashboard da solução.

Você pode escolher um dashboard para ver mais detalhes, por exemplo, escolher visualizar os recursos de computação para workloads mostrará um dashboard, conforme o mostrado na imagem a seguir.

As métricas são extraídas com um intervalo de extração de um minuto. Os dashboards mostram métricas agregadas a um minuto, cinco minutos ou mais, com base na métrica específica.
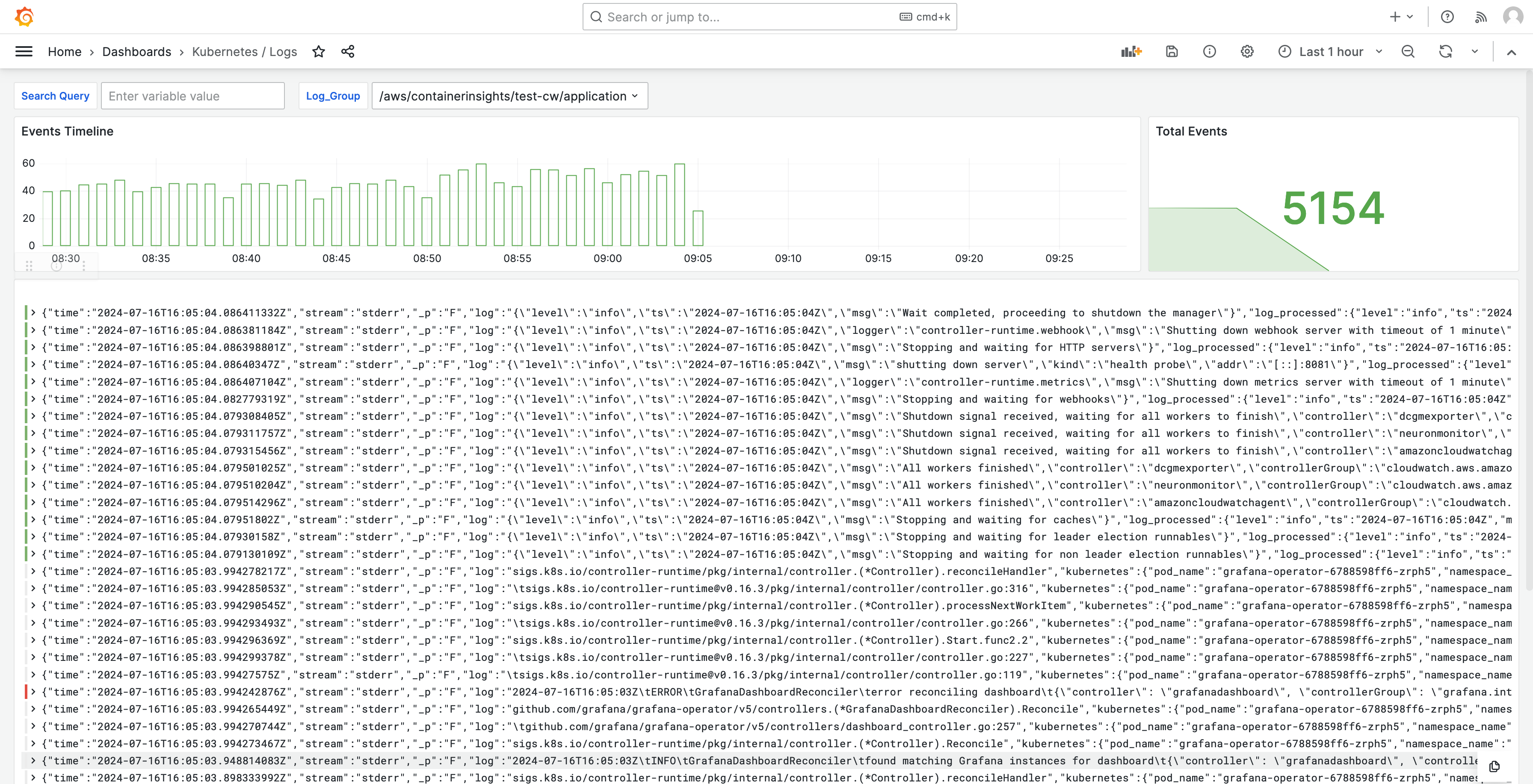
Os logs também são mostrados em dashboards para que você possa consultar e analisar os logs para encontrar as causas raiz dos problemas. A imagem a seguir mostra um dashboard de logs.
Para obter uma lista das métricas rastreadas por essa solução, consulte Lista de métricas monitoradas.
Para obter uma lista dos alertas criados por essa solução, consulte Lista de alertas criados.
Custos
Essa solução cria e usa recursos no seu espaço de trabalho. Você será cobrado pelo uso padrão dos recursos criados, incluindo:
-
Acesso dos usuários ao espaço de trabalho do Amazon Managed Grafana. Para obter mais informações sobre preços, consulte Preço do Amazon Managed Grafana
. -
Ingestão e armazenamento de métricas do Amazon Managed Service for Prometheus, incluindo o uso do Agentless Collector do Amazon Managed Service for Prometheus e análise de métricas (processamento de exemplos de consultas). A quantidade de métricas usadas por essa solução depende da configuração e do uso do cluster do Amazon EKS.
Você pode visualizar as métricas de ingestão e armazenamento no Amazon Managed Service for Prometheus CloudWatch usando Para obter mais informações, consulte as CloudWatchmétricas no Guia do usuário do Amazon Managed Service for Prometheus.
Você pode estimar o custo usando a Calculadora de Preços na página de preços do Amazon Managed Service for Prometheus
. A quantidade de métricas dependerá do número de nós no cluster e das métricas que as aplicações produzem. -
CloudWatch Ingestão, armazenamento e análise de registros. Por padrão, a retenção de logs está configurada para nunca expirar. Você pode ajustar isso em CloudWatch. Para obter mais informações sobre preços, consulte Amazon CloudWatch Pricing
. -
Custos de rede. Você pode incorrer em cobranças AWS de rede padrão para tráfego entre zonas de disponibilidade, regiões ou outros tipos de tráfego.
As calculadoras de preços, disponíveis na página de preços de cada produto, podem ajudar a entender os possíveis custos de sua solução. As informações a seguir podem ajudar a obter um custo básico para a solução em execução na mesma zona de disponibilidade do cluster do Amazon EKS.
| Produto | Métrica da calculadora | Valor |
|---|---|---|
Amazon Managed Service for Prometheus |
Série ativa |
8.000 (base) 15.000 (por nó) |
Intervalo médio da coleta |
60 (segundos) |
|
Amazon Managed Service for Prometheus (coletor gerenciado) |
Número de coletores |
1 |
Número de exemplos |
15 (base) 150 (por nó) |
|
Número de regras |
161 |
|
Intervalo médio de extração de regras |
60 (segundos) |
|
Amazon Managed Grafana |
Número de ativos editors/administrators |
1 (ou mais, com base em seus usuários) |
CloudWatch (Registros) |
Logs padrão: dados ingeridos |
24,5 GB (base) 0,5 GB (por nó) |
Registro Storage/Archival (registros padrão e vendidos) |
Sim para armazenar logs: supondo uma retenção de um mês |
|
Dados de logs esperados verificados |
Cada consulta de insights de logs do Grafana verificará todo o conteúdo do log do grupo durante o período de tempo especificado. |
Esses números são os números base para uma solução que executa o EKS sem software adicional. Isso fornecerá uma estimativa dos custos básicos. Também exclui os custos de uso da rede, que variam de acordo com o espaço de trabalho Amazon Managed Grafana, o espaço de trabalho do Amazon Managed Service for Prometheus e o cluster Amazon EKS estarem na mesma zona de disponibilidade e VPN. Região da AWS
nota
Quando um item nesta tabela inclui um valor (base) e um valor por recurso (por exemplo, (per node)), você deve adicionar o valor base ao valor por recurso multiplicado pelo número que você tem desse recurso. Por exemplo, em Média de séries temporais ativas, insira um número que seja 8000 + the number of nodes in your cluster * 15,000. Se você tiver dois nós, você vai inserir 38,000, que é 8000 + ( 2 * 15,000 ).
Pré-requisitos
Essa solução exige que você tenha realizado as ações a seguir antes de usá-la.
-
Você deve ter ou criar um cluster do Amazon Elastic Kubernetes Service que deseja monitorar, e o cluster deve ter pelo menos um nó. O cluster deve ter o acesso ao endpoint do servidor de API definido para incluir acesso privado (ele também pode permitir acesso público).
O modo de autenticação deve incluir acesso à API (pode ser definido como
APIouAPI_AND_CONFIG_MAP). Isso permite que a implantação da solução use entradas de acesso.O seguinte deve ser instalado no cluster (verdadeiro por padrão ao criar o cluster por meio do console, mas deve ser adicionado se você criar o cluster usando a AWS API ou AWS CLI): AWS CNI, CoreDNS e. Kube-proxy AddOns
Salve o nome do cluster para especificar posteriormente. Isso pode ser encontrado nos detalhes do cluster no console do Amazon EKS.
nota
Para obter detalhes sobre como criar um cluster do Amazon EKS, consulte Conceitos básicos do Amazon EKS.
-
Você deve criar um espaço de trabalho do Amazon Managed Service for Prometheus no mesmo espaço de trabalho do seu cluster Amazon Conta da AWS EKS. Para obter detalhes, consulte Create a workspace no Guia do usuário do Amazon Managed Service for Prometheus.
Salve o ARN do espaço de trabalho do Amazon Managed Service for Prometheus para especificar posteriormente.
-
Você deve criar um espaço de trabalho Amazon Managed Grafana com o Grafana versão 9 ou mais recente, da mesma Região da AWS forma que seu cluster Amazon EKS. Para obter detalhes sobre como criar um espaço de trabalho, consulte Criar um espaço de trabalho do Amazon Managed Grafana.
A função do espaço de trabalho deve ter permissões para acessar o Amazon Managed Service for Prometheus e as APIs da Amazon. CloudWatch A maneira mais fácil de fazer isso é usar Service-managedas permissões e selecionar o Amazon Managed Service para Prometheus e. CloudWatch Você também pode adicionar manualmente AmazonGrafanaCloudWatchAccessas políticas AmazonPrometheusQueryAccesse à sua função do IAM do workspace.
Salve o ID e o endpoint do espaço de trabalho do Amazon Managed Grafana para especificar posteriormente. O ID está no formato
g-123example. O ID e o endpoint podem ser encontrados no console do Amazon Managed Grafana. O endpoint é o URL do espaço de trabalho e inclui o ID. Por exemplo, .https://g-123example.grafana-workspace.<region>.amazonaws.com/ -
Se você estiver implantando a solução com o Terraform, deverá criar um bucket do Amazon S3 que possa ser acessado pela sua conta. Isso será usado para armazenar arquivos de estado do Terraform da implantação.
Salve o ID do bucket do Amazon S3 para especificar posteriormente.
-
Para visualizar as regras de alerta do Amazon Managed Service for Prometheus, você deve habilitar o Grafana Alerting para o espaço de trabalho do Amazon Managed Grafana.
Adicionalmente, o Amazon Managed Grafana deve ter as permissões a seguir para os recursos do Prometheus. Você deve adicioná-los às políticas gerenciadas pelo serviço ou pelo cliente descritas em Permissões e políticas do Amazon Managed Grafana para AWS fontes de dados.
aps:ListRulesaps:ListAlertManagerSilencesaps:ListAlertManagerAlertsaps:GetAlertManagerStatusaps:ListAlertManagerAlertGroupsaps:PutAlertManagerSilencesaps:DeleteAlertManagerSilence
nota
Embora não seja estritamente necessário configurar a solução, você deve configurar a autenticação de usuário no espaço de trabalho do Amazon Managed Grafana antes que os usuários possam acessar os dashboards criados. Para obter mais informações, consulte Autenticar usuários nos espaços de trabalho do Amazon Managed Grafana.
Usar esta solução
Essa solução configura a AWS infraestrutura para oferecer suporte a relatórios e métricas de monitoramento de um cluster Amazon EKS. Você pode instalá-la usando o AWS Cloud Development Kit (AWS CDK) ou com o Terraform
Lista de métricas monitoradas
Essa solução cria um extrator que coleta as métricas do cluster do Amazon EKS. Essas métricas são armazenadas no Amazon Managed Service for Prometheus e exibidas nos dashboards do Amazon Managed Grafana. Por padrão, o raspador coleta todas as Prometheus-compatible métricas expostas pelo cluster. Instalar um software no cluster que produza mais métricas aumentará as métricas coletadas. Se quiser, você pode reduzir o número de métricas atualizando o extrator com uma configuração que filtra as métricas.
As métricas a seguir são rastreadas com essa solução, em uma configuração básica do cluster do Amazon EKS sem nenhum software adicional instalado.
| Métrica | Descrição e Objetivo |
|---|---|
|
|
Indicador de APIServices marcadas como indisponíveis, detalhados pelo nome da APIService. |
|
|
Histograma de latência do webhook de admissão em segundos, identificado por nome e dividido para cada operação e recurso e tipo de API (validar ou admitir). |
|
|
Número máximo do limite de solicitações em andamento usadas atualmente desse apiserver por tipo de solicitação no último segundo. |
|
|
Porcentagem dos slots de cache atualmente ocupados por DEKs em cache. |
|
|
Número de solicitações no estágio de execução inicial (para um WATCH) ou em qualquer estágio de execução (para um não WATCH) no subsistema da API Priority and Fairness. |
|
|
Número de solicitações no estágio de execução inicial (para um WATCH) ou em qualquer estágio de execução (para um não WATCH) no subsistema da API Priority and Fairness que foram rejeitadas. |
|
|
Número nominal de lugares de execução configurados para cada nível de prioridade. |
|
|
O histograma compartimentado da duração do estágio inicial (para um WATCH) ou de qualquer estágio (para um não WATCH) da execução da solicitação no subsistema da API Priority and Fairness. |
|
|
A contagem do estágio inicial (para um WATCH) ou de qualquer estágio (para um não WATCH) da execução da solicitação no subsistema da API Priority and Fairness. |
|
|
Indica uma solicitação do servidor de API. |
|
|
Medidor de APIs obsoletas que foram solicitadas, divididas por grupo de APIs, versão, recurso, sub-recurso e removed_release. |
|
|
Distribuição da latência de resposta em segundos para cada verbo, valor de simulação, grupo, versão, recurso, sub-recurso, escopo e componente. |
|
|
O histograma compartimentado da distribuição da latência de resposta em segundos para cada verbo, valor de simulação, grupo, versão, recurso, sub-recurso, escopo e componente. |
|
|
A distribuição da latência de resposta do objetivo do serviço (SLO) em segundos para cada verbo, valor de simulação, grupo, versão, recurso, sub-recurso, escopo e componente. |
|
|
Número de solicitações que o apiserver encerrou como autodefesa. |
|
|
Contador de solicitações do apiserver divididas para cada verbo, valor de simulação, grupo, versão, recurso, escopo, componente e código de resposta HTTP. |
|
|
Tempo cumulativo de CPU consumido. |
|
|
Contagem cumulativa de bytes lidos. |
|
|
Contagem cumulativa de leituras concluídas. |
|
|
Contagem cumulativa de bytes gravados. |
|
|
Contagem cumulativa de gravações concluídas. |
|
|
Memória total em cache da página. |
|
|
Tamanho do RSS. |
|
|
Uso alternado de contêineres. |
|
|
Conjunto de trabalho atual. |
|
|
Contagem cumulativa de bytes recebidos. |
|
|
Contagem cumulativa de pacotes descartados durante o recebimento. |
|
|
Contagem cumulativa de pacotes recebidos. |
|
|
Contagem cumulativa de bytes transmitidos. |
|
|
Contagem cumulativa de pacotes descartados durante a transmissão. |
|
|
Contagem cumulativa de pacotes transmitidos. |
|
|
O histograma compartimentado da latência da solicitação etcd em segundos para cada operação e tipo de objeto. |
|
|
Número de goroutines que existem atualmente. |
|
|
Número de threads de sistema operacional criados. |
|
|
O histograma compartimentado da duração em segundos para operações do gerenciador de cgroups. Dividido por método. |
|
|
Duração em segundos para operações do gerenciador de cgroups. Dividido por método. |
|
|
Essa métrica será true (1) se o nó estiver enfrentando um erro relacionado à configuração; caso contrário, será false (0). |
|
|
O nome do nó. A contagem é sempre 1. |
|
|
O histograma compartimentado da duração em segundos para listar novamente os pods no PLEG. |
|
|
A contagem da duração em segundos para listar novamente os pods no PLEG. |
|
|
O histograma compartimentado do intervalo em segundos entre a nova listagem no PLEG. |
|
|
A contagem da duração em segundos desde que o kubelet detecta um pod pela primeira vez até o pod começar a funcionar. |
|
|
O histograma compartimentado da duração em segundos para sincronizar um único pod. Detalhado por tipo de operação: criar, atualizar ou sincronizar. |
|
|
A contagem da duração em segundos para sincronizar um único pod. Detalhado por tipo de operação: criar, atualizar ou sincronizar. |
|
|
Número de contêineres em execução no momento. |
|
|
Número de pods que têm uma sandbox de pods em execução. |
|
|
O histograma compartimentado da duração em segundos das operações de runtime. Dividido por tipo de operação. |
|
|
Número cumulativo de erros de operação no runtime por tipo de operação. |
|
|
Número cumulativo de operações no runtime por tipo de operação. |
|
|
A quantidade de recursos alocáveis para pods (depois de reservar alguns para daemons do sistema). |
|
|
A quantidade total de recursos disponíveis para um nó. |
|
|
O número de recursos de limite solicitados por um contêiner. |
|
|
O número de recursos de limite solicitados por um contêiner. |
|
|
O número de recursos de solicitação requeridos por um contêiner. |
|
|
O número de recursos de solicitação requeridos por um contêiner. |
|
|
Informações sobre o proprietário do pod. |
|
|
As cotas de recursos no Kubernetes impõem limites de uso de recursos, como CPU, memória e armazenamento em namespaces. |
|
|
As métricas de uso da CPU para um nó, incluindo o uso por núcleo e o uso total. |
|
|
Segundos que as CPUs passaram em cada modo. |
|
|
A quantidade cumulativa de tempo gasto executando I/O operações em disco por um nó. |
|
|
A quantidade total de tempo gasto executando I/O operações em disco pelo nó. |
|
|
O número total de bytes lidos do disco pelo nó. |
|
|
O número total de bytes gravados no disco pelo nó. |
|
|
A quantidade de espaço disponível em bytes no sistema de arquivos de um nó em um cluster do Kubernetes. |
|
|
O tamanho total do sistema de arquivos no nó. |
|
|
A média de carga de 1 minuto do uso da CPU de um nó. |
|
|
A média de carga de 15 minutos do uso da CPU de um nó. |
|
|
A média de carga de 5 minutos do uso da CPU de um nó. |
|
|
A quantidade de memória usada para o armazenamento em cache do buffer pelo sistema operacional do nó. |
|
|
A quantidade de memória usada para o armazenamento em cache do disco pelo sistema operacional do nó. |
|
|
A quantidade de memória disponível para uso por aplicações e caches. |
|
|
A quantidade de memória livre disponível no nó. |
|
|
A quantidade total de memória física disponível no nó. |
|
|
O número total de bytes recebidos pela rede pelo nó. |
|
|
O número total de bytes transmitidos pela rede pelo nó. |
|
|
Tempo total da CPU do usuário e do sistema gasto em segundos. |
|
|
Tamanho de memória residente em bytes. |
|
|
Número de solicitações HTTP, particionadas por código de status, método e host. |
|
|
O histograma compartimentado da latência da solicitação em segundos. Dividido por verbo e host. |
|
|
O histograma compartimentado da duração das operações de armazenamento. |
|
|
A contagem da duração das operações de armazenamento. |
|
|
Número cumulativo de erros durante as operações de armazenamento. |
|
|
Uma métrica que indica se o destino monitorado (por exemplo, nó) está ativo e funcionando. |
|
|
O número total de volumes gerenciados pelo gerenciador de volumes. |
|
|
Número total de adições tratadas pela fila de trabalho. |
|
|
Profundidade atual da fila de trabalho. |
|
|
O histograma compartimentado de quanto tempo em segundos um item permanece na fila de trabalho antes de ser solicitado. |
|
|
O histograma compartimentado de quanto tempo, em segundos, leva o processamento de um item da fila de trabalho. |
Lista de alertas criados
As tabelas a seguir listam os alertas criados por essa solução. Os alertas são criados como regras no Amazon Managed Service for Prometheus e exibidos no espaço de trabalho do Amazon Managed Grafana.
Você pode modificar as regras, incluindo adicionar ou excluir regras, editando o arquivo de configuração de regras no espaço de trabalho do Amazon Managed Service for Prometheus.
Esses dois alertas são alertas especiais que são tratados de forma um pouco diferente dos alertas típicos. Em vez de alertar sobre um problema, eles fornecem informações que são usadas para monitorar o sistema. A descrição inclui os detalhes sobre como usar esses alertas.
| Alerta | Descrição e uso |
|---|---|
|
Este é um alerta destinado a garantir que todo o pipeline de alertas esteja funcionando. Este alerta está sempre disparando, portanto, ele deve estar sempre disparando no Alertmanager, e sempre em um receptor. Você pode integrar isso ao seu mecanismo de notificação para enviar uma notificação quando esse alerta não estiver sendo disparado. Por exemplo, você pode usar a DeadMansSnitchintegração em PagerDuty. |
|
Este é um alerta usado para inibir alertas de informações. Por si só, os alertas com nível de informações podem ser muito ruidosos, mas são relevantes quando combinados com outros alertas. Esse alerta dispara sempre que há um alerta |
Os alertas a seguir fornecem informações ou avisos sobre o sistema.
| Alerta | Gravidade | Description |
|---|---|---|
|
|
warning |
A interface de rede está mudando de status com frequência |
|
|
warning |
O sistema de arquivos vai ficar sem espaço nas próximas 24 horas. |
|
|
critical |
O sistema de arquivos vai ficar sem espaço nas próximas 4 horas. |
|
|
warning |
O sistema de arquivos tem menos de 5% de espaço livre. |
|
|
critical |
O sistema de arquivos tem menos de 3% de espaço livre. |
|
|
warning |
O sistema de arquivos vai ficar sem inodes nas próximas 24 horas. |
|
|
critical |
O sistema de arquivos vai ficar sem inodes nas próximas 4 horas. |
|
|
warning |
O sistema de arquivos tem menos de 5% de inodes disponíveis. |
|
|
critical |
O sistema de arquivos tem menos de 3% de inodes disponíveis. |
|
|
warning |
A interface de rede está relatando muitos erros de recebimento. |
|
|
warning |
A interface de rede está relatando muitos erros de transmissão. |
|
|
warning |
O número de entradas do conntrack está chegando perto do limite. |
|
|
warning |
Falha na extração do coletor de arquivos de texto do Node Exporter. |
|
|
warning |
Distorção do relógio detectada. |
|
|
warning |
O relógio não está sincronizando. |
|
|
critical |
A matriz RAID está degradada |
|
|
warning |
Dispositivo com falha na matriz RAID |
|
|
warning |
O Kernel vai esgotar o limite de descritores de arquivo em breve. |
|
|
critical |
O Kernel vai esgotar o limite de descritores de arquivo em breve. |
|
|
warning |
O Node não está pronto. |
|
|
warning |
O Node está inacessível. |
|
|
info |
O Kubelet está funcionando com capacidade máxima. |
|
|
warning |
O status de prontidão do nó está oscilando. |
|
|
warning |
O Pod Lifecycle Event Generator do Kubelet está demorando muito para ser listado novamente. |
|
|
warning |
A latência de inicialização do pod do Kubelet é muito alta. |
|
|
warning |
O certificado do cliente Kubelet está prestes a expirar. |
|
|
critical |
O certificado do cliente Kubelet está prestes a expirar. |
|
|
warning |
O certificado do servidor Kubelet está prestes a expirar. |
|
|
critical |
O certificado do servidor Kubelet está prestes a expirar. |
|
|
warning |
O Kubelet não conseguiu renovar seu certificado de cliente. |
|
|
warning |
O Kubelet não conseguiu renovar seu certificado de servidor. |
|
|
critical |
O destino desapareceu da descoberta do destino do Prometheus. |
|
|
warning |
Diferentes versões semânticas dos componentes do Kubernetes em execução. |
|
|
warning |
O cliente do servidor da API do Kubernetes está apresentando erros. |
|
|
warning |
O certificado do cliente está prestes a expirar. |
|
|
critical |
O certificado do cliente está prestes a expirar. |
|
|
warning |
A API agregada do Kubernetes relatou erros. |
|
|
warning |
A API agregada do Kubernetes está inativa. |
|
|
critical |
O destino desapareceu da descoberta do destino do Prometheus. |
|
|
warning |
O apiserver do kubernetes encerrou {{ $value | humanizePercentage }} de suas solicitações recebidas. |
|
|
critical |
O volume persistente está sendo preenchido. |
|
|
warning |
O volume persistente está sendo preenchido. |
|
|
critical |
O inode de volume persistente está sendo preenchido. |
|
|
warning |
Os inodes de volume persistente estão sendo preenchidos. |
|
|
critical |
O volume persistente está tendo problemas com o provisionamento. |
|
|
warning |
O cluster comprometeu demais as solicitações de recursos de CPU. |
|
|
warning |
O cluster comprometeu demais as solicitações de recursos de memória. |
|
|
warning |
O cluster comprometeu demais as solicitações de recursos de CPU. |
|
|
warning |
O cluster comprometeu demais as solicitações de recursos de memória. |
|
|
info |
A cota de namespaces vai ficar cheia. |
|
|
info |
A cota de namespaces foi totalmente usada. |
|
|
warning |
A cota de namespaces excedeu os limites. |
|
|
info |
Os processos estão com o controle de utilização elevado da CPU. |
|
|
warning |
O pod está em um loop de falha. |
|
|
warning |
O pod não está no estado pronto há mais de 15 minutos. |
|
|
warning |
Incompatibilidade de geração de implantação devido à possível reversão |
|
|
warning |
A implantação não correspondeu ao número esperado de réplicas. |
|
|
warning |
StatefulSet não correspondeu ao número esperado de réplicas. |
|
|
warning |
StatefulSet incompatibilidade de geração devido à possível reversão |
|
|
warning |
StatefulSet a atualização não foi lançada. |
|
|
warning |
DaemonSet o lançamento está travado. |
|
|
warning |
Contêiner de pods esperando por mais de uma hora |
|
|
warning |
DaemonSet os pods não estão programados. |
|
|
warning |
DaemonSet os pods estão programados incorretamente. |
|
|
warning |
Trabalho não concluído a tempo |
|
|
warning |
Falha ao concluir o trabalho. |
|
|
warning |
O HPA não correspondeu ao número desejado de réplicas. |
|
|
warning |
O HPA está sendo executado com o máximo de réplicas |
|
|
critical |
kube-state-metrics está apresentando erros nas operações de lista. |
|
|
critical |
kube-state-metrics está apresentando erros nas operações de observação. |
|
|
critical |
A fragmentação kube-state-metrics está configurada incorretamente. |
|
|
critical |
Faltam fragmentos de kube-state-metrics. |
|
|
critical |
O servidor da API está consumindo muito orçamento de erro. |
|
|
critical |
O servidor da API está consumindo muito orçamento de erro. |
|
|
warning |
O servidor da API está consumindo muito orçamento de erro. |
|
|
warning |
O servidor da API está consumindo muito orçamento de erro. |
|
|
warning |
Um ou mais destinos estão inativos. |
|
|
critical |
Membros insuficientes do cluster etcd. |
|
|
warning |
Número alto de alterações do líder do cluster etcd. |
|
|
critical |
O cluster etcd não tem um líder. |
|
|
warning |
Número alto de solicitações de gRPC com falha do cluster etcd. |
|
|
critical |
As solicitações de gRPC do cluster etcd estão lentas. |
|
|
warning |
A comunicação dos membros do cluster etcd está lenta. |
|
|
warning |
Número alto de propostas sem êxito do cluster etcd. |
|
|
warning |
Durações elevadas de fsync do cluster etcd. |
|
|
warning |
O cluster etcd tem durações de confirmação maiores do que as esperadas. |
|
|
warning |
O cluster etcd falhou nas solicitações HTTP. |
|
|
critical |
Número alto de solicitações HTTP com falha do cluster etcd. |
|
|
warning |
As solicitações de HTTP do cluster etcd estão lentas. |
|
|
warning |
O relógio host não está sincronizando. |
|
|
warning |
Detectada a eliminação por memória insuficiente do host. |
Solução de problemas
Há algumas coisas que podem fazer com que a configuração do projeto falhe. Certifique-se de verificar o seguinte:
-
Você deve concluir todos os pré-requisitos antes de instalar a solução.
-
O cluster deve ter pelo menos um nó antes de tentar criar a solução ou acessar as métricas.
-
O cluster do Amazon EKS deve ter os complementos
AWS CNI,CoreDNSekube-proxyinstalados. Se eles não estiverem instalados, a solução não funcionará corretamente. Eles são instalados por padrão ao criar o cluster por meio do console. Talvez seja necessário instalá-los se o cluster tiver sido criado por meio de um AWS SDK. -
O tempo limite de instalação dos pods do Amazon EKS expirou. Isso poderá acontecer se não houver capacidade suficiente de nós disponível. Há várias causas para esses problemas, incluindo:
-
O cluster do Amazon EKS foi inicializado com o Fargate em vez do Amazon EC2. Esse projeto requer o Amazon EC2.
-
Os nós estão corrompidos e, portanto, indisponíveis.
Você pode usar
kubectl describe nodepara verificar os taints. Em seguida,NODENAME| grep Taintskubectl taint nodepara remover os taints. Certifique-se de incluirNODENAMETAINT_NAME--após o nome do taint. -
Os nós atingiram o limite de capacidade. Nesse caso, você pode criar um novo nó ou aumentar a capacidade.
-
-
Você não vê nenhum dashboard no Grafana: você está usando o ID incorreto do espaço de trabalho do Grafana.
Execute o seguinte comando para obter informações sobre o Grafana:
kubectl describe grafanas external-grafana -n grafana-operatorVocê pode verificar os resultados do URL correto do espaço de trabalho. Se não for o que você espera, implante novamente com o ID do espaço de trabalho correto.
Spec: External: API Key: Key: GF_SECURITY_ADMIN_APIKEY Name: grafana-admin-credentials URL: https://g-123example.grafana-workspace.aws-region.amazonaws.com Status: Admin URL: https://g-123example.grafana-workspace.aws-region.amazonaws.com Dashboards: ... -
Você não vê nenhum dashboard no Grafana: você está usando uma chave de API expirada.
Para procurar esse caso, você precisará obter o operador do Grafana e verificar se há erros nos logs. Obtenha o nome do operador do Grafana com este comando:
kubectl get pods -n grafana-operatorIsso retornará o nome do operador, por exemplo:
NAME READY STATUS RESTARTS AGEgrafana-operator-1234abcd5678ef901/1 Running 0 1h2mUse o nome do operador no seguinte comando:
kubectl logsgrafana-operator-1234abcd5678ef90-n grafana-operatorMensagens de erro como as seguintes indicam uma chave de API expirada:
ERROR error reconciling datasource {"controller": "grafanadatasource", "controllerGroup": "grafana.integreatly.org", "controllerKind": "GrafanaDatasource", "GrafanaDatasource": {"name":"grafanadatasource-sample-amp","namespace":"grafana-operator"}, "namespace": "grafana-operator", "name": "grafanadatasource-sample-amp", "reconcileID": "72cfd60c-a255-44a1-bfbd-88b0cbc4f90c", "datasource": "grafanadatasource-sample-amp", "grafana": "external-grafana", "error": "status: 401, body: {\"message\":\"Expired API key\"}\n"} github.com/grafana-operator/grafana-operator/controllers.(*GrafanaDatasourceReconciler).ReconcileNesse caso, crie uma chave de API e implante a solução novamente. Se o problema persistir, você pode forçar a sincronização usando o seguinte comando antes da nova implantação:
kubectl delete externalsecret/external-secrets-sm -n grafana-operator -
Instalações do CDK: o parâmetro SSM não está presente. Se você encontrar um erro como a seguir, execute
cdk bootstrape tente novamente.Deployment failed: Error: aws-observability-solution-eks-infra-$EKS_CLUSTER_NAME: SSM parameter /cdk-bootstrap/xxxxxxx/version not found. Has the environment been bootstrapped? Please run 'cdk bootstrap' (see https://docs.aws.amazon.com/cdk/latest/ guide/bootstrapping.html) -
A implantação poderá falhar se o provedor OIDC já existir. Você verá um erro como o seguinte (neste caso, para instalações do CDK):
| CREATE_FAILED | Custom::AWSCDKOpenIdConnectProvider | OIDCProvider/Resource/Default Received response status [FAILED] from custom resource. Message returned: EntityAlreadyExistsException: Provider with url https://oidc.eks.REGION.amazonaws.com/id/PROVIDER IDalready exists.Neste caso, acesse o portal do IAM, exclua o provedor OIDC e tente novamente.
-
Instalações do Terraform: você vê uma mensagem de erro que inclui
cluster-secretstore-sm failed to create kubernetes rest client for update of resourceefailed to create kubernetes rest client for update of resource.Esse erro normalmente indica que o operador externo de segredos não está instalado ou habilitado no cluster do Kubernetes. Ele é instalado como parte da implantação da solução, mas às vezes não está pronto quando a solução precisa.
Você pode verificar se está instalado com o seguinte comando:
kubectl get deployments -n external-secretsSe estiver instalado, poderá levar um tempo para que o operador esteja totalmente pronto para ser usado. Você pode verificar o status das definições de recursos personalizados (CRDs) necessárias executando o seguinte comando:
kubectl get crds|grep external-secretsEste comando deve listar as CRDs relacionadas ao operador externo de segredos, incluindo
clustersecretstores.external-secrets.ioeexternalsecrets.external-secrets.io. Se não estiverem na lista, aguarde mais alguns minutos e verifique novamente.Depois que as CRDs estiverem registradas, você poderá executar
terraform applynovamente para implantar a solução.
