Você pode usar um Crawler do AWS Glue para preencher o AWS Glue Data Catalog com bancos de dados e tabelas. Este é o principal método usado pela maioria dos usuários do AWS Glue. Um crawler pode rastrear vários armazenamentos de dados em uma única execução. Após a conclusão, o crawler cria ou atualiza uma ou mais tabelas no Data Catalog. As tarefas de extração, transformação e carregamento (ETL) que você define no AWS Glue usam essas tabelas do Data Catalog como fontes e destinos. O trabalho de ETL lê e grava os armazenamentos de dados que são especificados nas tabelas do Data Catalog de fonte e de destino.
Fluxo de trabalho
O seguinte diagrama de fluxo de trabalho mostra como os crawlers do AWS Glue interagem com os armazenamentos de dados e outros elementos para preencher o Data Catalog.
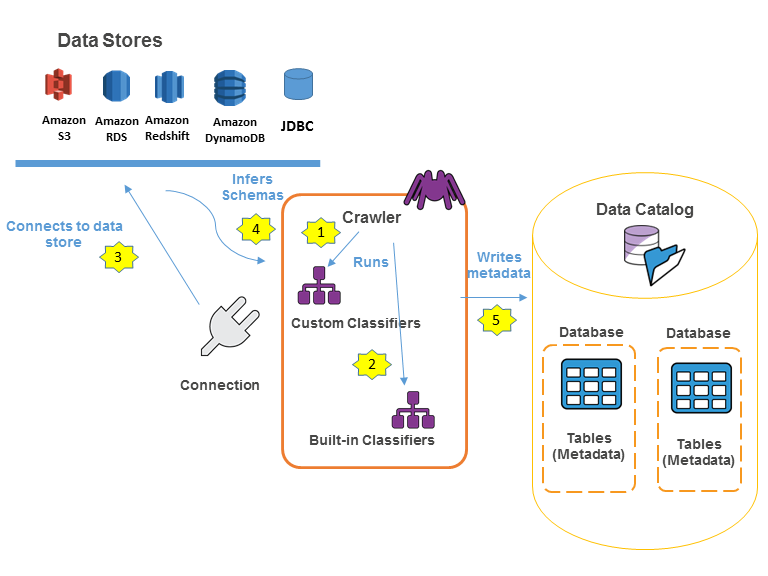
Veja a seguir o fluxo de trabalho geral sobre como um crawler preenche o AWS Glue Data Catalog:
-
Um crawler executa todos os classificadores personalizados que você escolhe para inferir o formato e o esquema dos seus dados. Você fornece o código para classificadores personalizados, e eles são executados na ordem especificada.
O primeiro classificador personalizado a reconhecer com sucesso a estrutura de dados é usado para criar um esquema. Os classificadores personalizados em posições inferiores na lista são ignorados.
-
Se nenhum classificador personalizado corresponder ao esquema dos seus dados, os classificadores integrados tentarão reconhecê-lo. Um exemplo de um classificador integrado é um que reconhece JSON.
-
O crawler se conecta ao armazenamento de dados. Alguns armazenamentos de dados requerem propriedades de conexão para o acesso ao crawler.
-
O esquema inferido é criado para os seus dados.
-
O crawler grava os metadados no Data Catalog. Uma definição de tabela contém metadados sobre os dados no seu armazenamento de dados. A tabela é gravada em um banco de dados, que é um contêiner de tabelas no Data Catalog. Os atributos de uma tabela incluem a classificação, que é um rótulo criado pelo classificador que inferiu o esquema da tabela.
Tópicos
Como funcionam os crawlers
Quando um crawler é executado, ele obtém as ações a seguir para interrogar um armazenamento de dados:
-
Classifica dados para determinar o formato, o esquema e as propriedades associadas de dados brutos – Você pode configurar os resultados de classificação criando um classificador personalizado.
-
Agrupa dados em tabelas ou partições – Os dados são agrupados com base na heurística do crawler.
-
Grava metadados no Data Catalog: você pode configurar como o crawler adiciona, atualiza e exclui tabelas e partições.
Ao definir um crawler, você escolhe um ou mais classificadores que avaliam o formato dos seus dados para inferir um esquema. Quando o crawler é executado, o primeiro classificador da sua lista a reconhecer com sucesso seu armazenamento de dados é usado para criar um esquema para a sua tabela. Você pode usar classificadores integrados ou definir o seu próprio. Você define os classificadores personalizados em uma operação separada, antes de definir os rastreamentos. O AWS Glue fornece classificadores integrados para inferir esquemas de arquivos comuns com formatos que incluem JSON, CSV e Apache Avro. Para ver a lista atual de classificadores integrados no AWS Glue, consulte Classificadores integrados.
As tabelas de metadados que um crawler cria ficam contidas em um banco de dados quando você define um crawler. Se o seu crawler não especificar um banco de dados, suas tabelas serão colocadas no banco de dados padrão. Além disso, cada tabela possui uma coluna de classificação preenchida pelo primeiro classificador que reconheceu com sucesso o armazenamento de dados.
Se o arquivo rastreado estiver compactado, o crawler precisará fazer download dele para processá-lo. Quando um crawler é executado, ele interroga os arquivos para determinar seu formato e tipo de compactação e grava essas propriedades no Data Catalog. Alguns formatos de arquivo (por exemplo, Apache Parquet) permitem que você compacte partes do arquivo à medida que ele é gravado. Para esses arquivos, os dados compactados são um componente interno do arquivo e o AWS Glue não preenche a propriedade compressionType quando grava tabelas no Data Catalog. Por outro lado, se um arquivo inteiro for compactado por um algoritmo de compactação (por exemplo, gzip), a propriedade compressionType será preenchida quando as tabelas forem gravadas no Data Catalog.
O crawler gera os nomes das tabelas que ele cria. Os nomes das tabelas armazenadas no AWS Glue Data Catalog obedecem a estas regras:
-
São permitidos somente caracteres alfanuméricos e sublinhados (
_). -
Prefixos personalizados não podem conter mais do que 64 caracteres.
-
O comprimento máximo do nome não pode ser superior a 128 caracteres. O crawler trunca nomes gerados para ajustá-los de acordo com o limite.
-
Se forem encontrados nomes de tabelas duplicados, o crawler adicionará um sufixo de string hash a esse nome.
Se seu crawler for executado mais de uma vez (talvez em uma programação), ele procurará arquivos ou tabelas novos ou alterados no seu armazenamento de dados. A saída do crawler inclui novas tabelas e partições encontradas desde a execução anterior.
Como um crawler determina quando criar partições?
Quando um crawler do AWS Glue examina o armazenamento de dados do Amazon S3 e detecta várias pastas em um bucket, ele determina a raiz de uma tabela na estrutura de pastas e quais pastas são partições de uma tabela. O nome da tabela é baseado no prefixo do Amazon S3 ou no nome da pasta. Você fornece um Include path (caminho de inclusão) que indica o nível da pasta a ser rastreada. Quando a maioria dos esquemas em um nível de pasta é semelhante, o crawler cria partições de uma tabela em vez de duas tabelas separadas. Para influenciar o crawler a criar tabelas separadas, adicione a pasta raiz de cada tabela como um repositório de dados separado ao definir o crawler.
Por exemplo, considere a seguinte estrutura de pastas do Amazon S3.
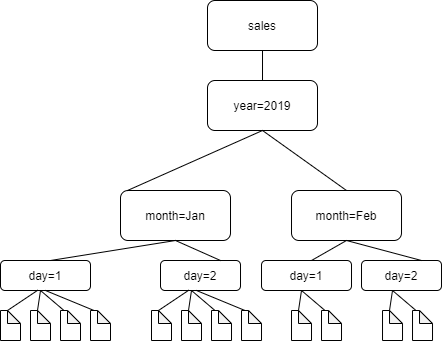
Os caminhos para as quatro pastas de nível mais baixo são os seguintes:
S3://sales/year=2019/month=Jan/day=1
S3://sales/year=2019/month=Jan/day=2
S3://sales/year=2019/month=Feb/day=1
S3://sales/year=2019/month=Feb/day=2Suponha que o destino do crawler esteja definido em Sales e que todos os arquivos no day=n têm o mesmo formato (por exemplo, JSON, não criptografado) e têm os mesmos esquemas, ou esquemas muito semelhantes. O crawler criará uma única tabela com quatro partições, com chaves de partição year, month e day.
No exemplo a seguir, considere a seguinte estrutura do Amazon S3:
s3://bucket01/folder1/table1/partition1/file.txt
s3://bucket01/folder1/table1/partition2/file.txt
s3://bucket01/folder1/table1/partition3/file.txt
s3://bucket01/folder1/table2/partition4/file.txt
s3://bucket01/folder1/table2/partition5/file.txt
Se os esquemas para arquivos em table1 e table2 forem semelhantes e um único armazenamento de dados estiver definido no crawler com Include path (Caminho de inclusão) s3://bucket01/folder1/, o crawler cria uma única tabela com duas colunas de chave de partição. A primeira coluna de chave de partição contém table1 e table2, e a segunda coluna de chave de partição contém partition1 a partition3 para a partição da table1 e partition4 e partition5 para a partição da table2. Para criar duas tabelas separadas, defina o crawler com dois armazenamentos de dados. Neste exemplo, defina o primeiro Include path (Caminho de inclusão) como s3://bucket01/folder1/table1/, e o segundo como s3://bucket01/folder1/table2.
nota
No Amazon Athena, cada tabela corresponde a um prefixo do Amazon S3 com todos os objetos nele. Se os objetos têm diferentes esquemas, o Athena não reconhece os objetos diferentes no mesmo prefixo como tabelas separadas. Isso pode acontecer se um crawler criar várias tabelas a partir do mesmo prefixo do Amazon S3. Isso pode levar a consultas no Athena que retornam zero resultados. Para que o Athena reconheça e consulte corretamente as tabelas, crie o crawler com um Include path (Caminho de inclusão) separado para cada esquema de tabela diferente na estrutura de pastas do Amazon S3. Para obter mais informações, consulte Práticas recomendadas ao usar o Athena com o AWS Glue e este artigo da Central de Conhecimento da AWS
