Você pode usar conectores e conexões para nós de origem e de destino de dados no AWS Glue Studio.
Tópicos
Criar trabalhos que usam um conector para a origem dos dados
Ao criar um novo trabalho, você pode escolher um conector para a origem e para os destinos dos dados.
Para criar um trabalho que use conectores para a origem ou destino dos dados
Faça login no AWS Management Console e abra o console do AWS Glue Studio em https://console.aws.amazon.com/gluestudio/
. -
Na página Connectors (Conectores), na lista de recursos Your connections (Suas conexões), escolha a conexão que você deseja usar em seu trabalho e escolha Create job (Criar trabalho).
Como alternativa, na página Jobs (Trabalhos) do AWS Glue Studio, em Create job (Criar trabalho), escolha Source and target added to the graph (Origem e destino adicionados ao gráfico). Na lista suspensa Source (Origem), escolha o conector personalizado que você deseja usar em seu trabalho. Também é possível escolher um conector para Target (Destino).
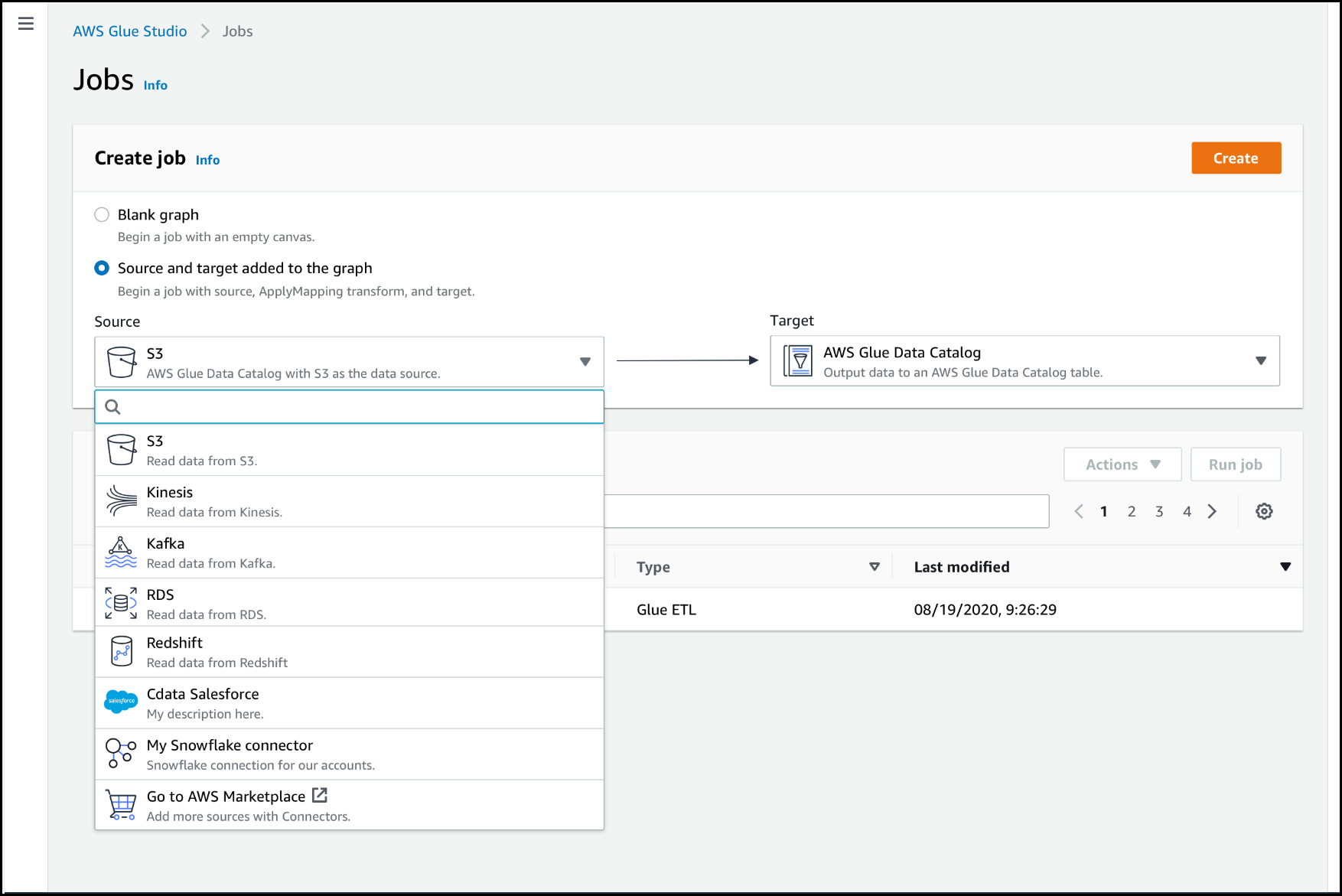
-
Escolha Create (Criar) para abrir o editor de trabalhos visual.
-
Configure o nó da origem dos dados, conforme descrito em Configurar propriedades de origem para nós que usam conectores.
-
Continue criando seu trabalho de ETL adicionando transformações, armazenamentos de dados adicionais e destinos de dados, conforme descrito em Iniciar trabalhos de ETL visual no AWS Glue Studio.
-
Personalize o ambiente de execução de trabalho configurando as propriedades do trabalho, conforme descrito em Modificar as propriedades do trabalho.
-
Salve o trabalho e o execute.
Configurar propriedades de origem para nós que usam conectores
Depois de criar um trabalho que usa um conector para a origem dos dados, o editor de trabalhos visual exibe um gráfico de trabalho com um nó de origem dos dados configurado para o conector. Você deve configurar as propriedades da origem dos dados para esse nó.
Para configurar as propriedades de um nó de origem dos dados que usa um conector
-
Escolha o nó da origem dos dados do conector no gráfico de trabalho ou adicione um novo nó e escolha o conector para Node type (Tipo de nó). Em seguida, no lado direito, no painel de detalhes do nó, escolha a guia Data source properties (Propriedades da origem dos dados), se ainda não estiver selecionada.
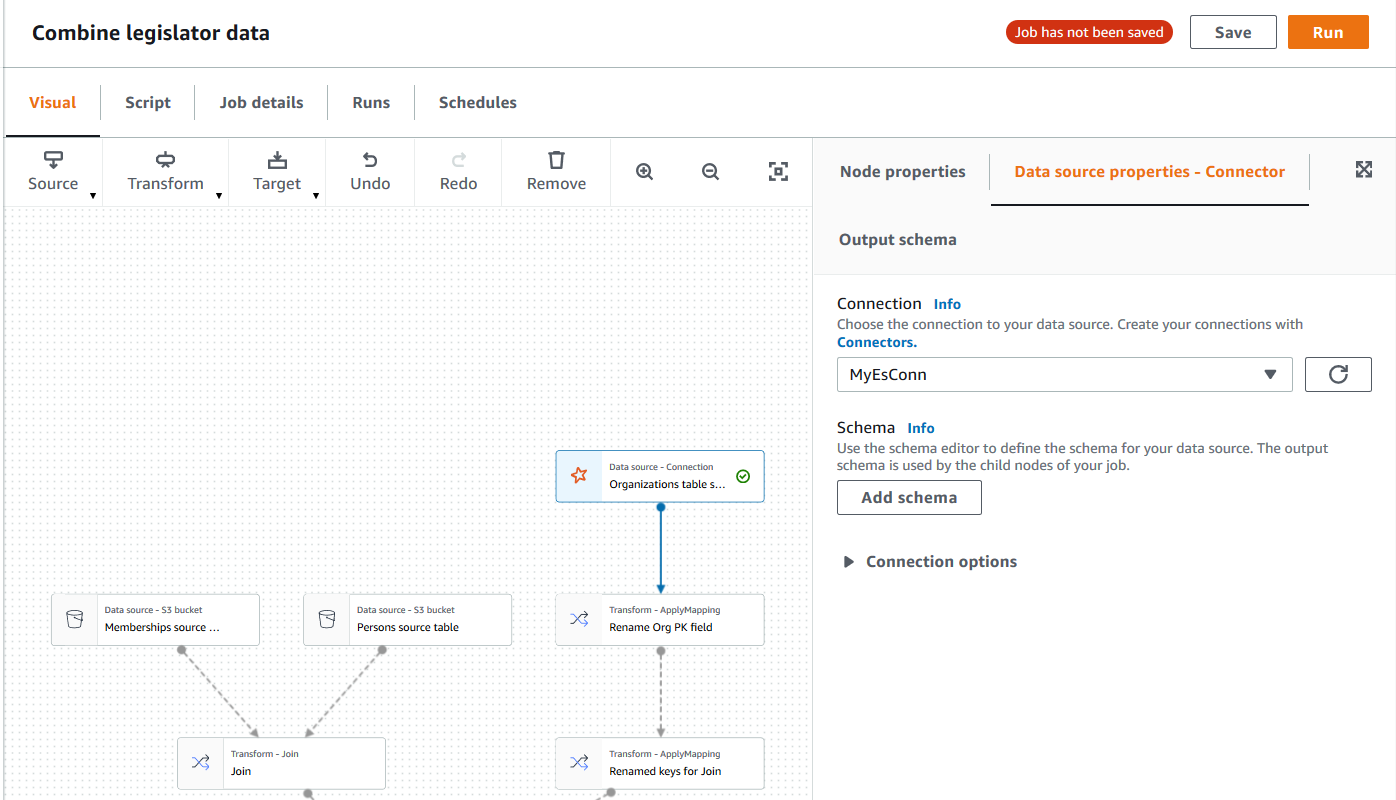
-
Na guia Data source properties (Propriedades da origem dos dados), escolha a conexão que você deseja usar para esse trabalho.
Insira as informações adicionais necessárias para cada tipo de conexão:
-
Data source input type (Tipo de entrada da origem dos dados): opte por fornecer um nome de tabela ou uma consulta SQL como a origem dos dados. Dependendo da sua escolha, você precisará fornecer estas informações adicionais:
-
Table name (Nome da tabela): o nome da tabela na origem dos dados. Se a origem dos dados não usar o termo table (tabela), forneça o nome de uma estrutura de dados apropriada, conforme indicado pelas informações de uso do conector personalizado (disponíveis em AWS Marketplace).
-
Filter predicate (Filtrar predicado): uma cláusula de condição a ser usada ao ler a origem dos dados, semelhante a uma cláusula
WHERE, que é usada para recuperar um subconjunto dos dados. -
Query code (Código de consulta): insira uma consulta SQL a ser usada para recuperar um conjunto de dados específico da origem dos dados. Um exemplo de uma consulta SQL básica é:
SELECTcolumn_listFROMtable_nameWHEREwhere_clause
-
-
Schema (Esquema): como o AWS Glue Studio está usando informações armazenadas na conexão para acessar a origem dos dados em vez de recuperar informações de metadados de uma tabela do Data Catalog, você deve fornecer os metadados do esquema para a origem dos dados. Escolha Add schema (Adicionar esquema) para abrir o editor de esquemas.
Para obter instruções sobre como usar o editor de esquemas, consulte Editar o esquema de um nó de transformação personalizada.
-
Partition column (Coluna da partição): (opcional) você pode optar por particionar as leituras de dados fornecendo valores para Partition column (Coluna da partição), Lower bound (Limite inferior), Upper bound (Limite superior) e Number of partitions (Número de partições).
Os valores de
lowerBoundeupperBoundsão usados para decidir o passo de partição, não para filtrar as linhas na tabela. Todas as linhas na tabela são particionadas e retornadas.nota
O particionamento de colunas adiciona uma condição de particionamento extra à consulta usada para ler os dados. Ao usar uma consulta em vez de um nome de tabela, você deve validar se a consulta funciona com a condição de particionamento especificada. Por exemplo:
-
Se o seu formato de consulta for
"SELECT col1 FROM table1", teste a consulta anexando uma cláusulaWHEREno final da consulta que usa a coluna de partição. -
Se o seu formato de consulta for
"SELECT col1 FROM table1 WHERE col2=val", teste a consulta estendendo a cláusulaWHEREcomANDe uma expressão que usa a coluna de partição.
-
-
Data type casting (Conversão de tipos de dados): se a origem dos dados usar tipos de dados que não estão disponíveis no JDBC, use essa seção para especificar como um tipo de dados da origem dos dados deve ser convertido em tipos de dados do JDBC. Você pode especificar até 50 conversões de tipos de dados diferentes. Todas as colunas na origem dos dados que usam o mesmo tipo de dados são convertidas da mesma maneira.
Por exemplo, se você tiver três colunas na origem dos dados que usam o tipo de dados
Float, e você indicar que o tipo de dadosFloatdeve ser convertido para o tipoStringdo JDBC, então todas as três colunas que usam o tipo de dadosFloatsão convertidas para o tipo de dadosString. -
Job bookmark keys (Chaves de marcadores de trabalho): os marcadores de trabalho ajudam o AWS Glue a manter as informações de estado e a impedir o reprocessamento de dados antigos. Especifique uma ou mais colunas adicionais como chaves de marcadores. O AWS Glue Studio usa chaves de marcadores para rastrear dados que já foram processados durante uma execução anterior do trabalho de ETL. Todas as colunas que você usar para chaves de marcadores personalizadas devem ser estritamente monotônicas, aumentando ou diminuindo, mas lacunas são permitidas.
Se você inserir várias chaves de marcadores, elas serão combinadas para formar uma única chave composta. Uma chave de marcadores de trabalho composta não deve conter colunas duplicadas. Se você não especificar chaves de marcadores, por padrão, o AWS Glue Studio usará a chave primária como chave de marcadores, desde que ela esteja aumentando ou diminuindo sequencialmente (sem lacunas). Se a tabela não tiver uma chave primária, mas a propriedade de marcador de trabalho estiver habilitada, você deverá fornecer chaves de marcadores de trabalho personalizadas. Caso contrário, a pesquisa de chaves primárias a serem usadas como padrão falhará, assim como a execução do trabalho.
Job bookmark keys sorting order (Ordem de classificação de chaves de marcadores de trabalhos): escolha se as chaves-valor aumentam ou diminuem sequencialmente.
-
(Opcional) depois de fornecer as informações necessárias, você pode exibir o esquema de dados resultante para sua origem dos dados escolhendo a guia Output schema (Esquema de saída) no painel de detalhes do nó. O esquema exibido nessa guia é usado por todos os nós filhos adicionados ao gráfico de trabalho.
-
(Opcional) depois de configurar as propriedades do nó e da origem dos dados, você poderá previsualizar o conjunto de dados de sua origem dos dados escolhendo a guia Data preview (Previsualização de dados) no painel de detalhes do nó. Na primeira vez que você escolher essa guia para qualquer nó em seu trabalho, você receberá uma solicitação para fornecer uma função do IAM para acessar os dados. Há um custo associado ao uso desse recurso e o a cobrança começa assim que você fornece uma função do IAM.
Configurar propriedades de destino para nós que usam conectores
Se você usar um conector para o tipo de destino de dados, deverá configurar as propriedades do nó de destino de dados.
Para configurar as propriedades de um nó de destino de dados que usa um conector
-
Escolha o nó de destino de dados do conector no gráfico de trabalho. Em seguida, no lado direito, no painel de detalhes do nó, escolha a guia Data target properties (Propriedades de destino de dados), se ainda não estiver selecionada.
-
Na guia Data target properties (Propriedades de destino de dados), escolha a conexão a ser usada para gravar no destino.
Insira as informações adicionais necessárias para cada tipo de conexão:
-
Connection (Conexão): escolha a conexão a ser usada com o conector. Para obter informações sobre como criar uma conexão, consulte Criar conexões para conectores.
-
Table name (Nome da tabela): o nome da tabela no destino dos dados. Se o destino dos dados não usar o termo table (tabela), forneça o nome de uma estrutura de dados apropriada, conforme indicado pelas informações de uso do conector personalizado (disponíveis em AWS Marketplace).
-
Batch size (Tamanho do lote; opcional): informe o número de linhas ou registros a serem inseridos na tabela de destino em uma única operação. O valor padrão é 1.000 linhas.
-
Depois de fornecer as informações necessárias, você pode exibir o esquema de dados resultante para sua origem dos dados escolhendo a guia Output schema (Esquema de saída), no painel de detalhes do nó.
