Data Quality Definition Language (DQDL) é uma linguagem específica de domínio que você usa para definir regras para o AWS Glue Data Quality.
Este guia apresenta os principais conceitos de DQDL para ajudar você a entender a linguagem. Ele também fornece uma referência para tipos de regras DQDL com sintaxe e exemplos. Antes de usar este guia, recomendamos que você se familiarize com o AWS Glue Data Quality. Para ter mais informações, consulte AWS Glue Data Quality.
nota
As regras dinâmicas são aceitas somente em ETL do AWS Glue.
Sintaxe DQDL
Um documento DQDL diferencia maiúsculas de minúsculas e contém um conjunto de regras que agrupa regras individuais de qualidade de dados. Para estruturar um conjunto de regras, você deve criar uma lista denominada Rules (em maiúsculas), delimitada por colchetes. A lista deve conter uma ou mais regras DQDL separadas por vírgula, como no exemplo a seguir.
Rules = [
IsComplete "order-id",
IsUnique "order-id"
]Estrutura da regra
A estrutura de uma regra DQDL depende do tipo de regra. No entanto, as regras DQDL geralmente se encaixam no formato a seguir.
<RuleType> <Parameter> <Parameter> <Expression>
RuleType é o nome com distinção entre maiúsculas e minúsculas do tipo de regra que você quer configurar. Por exemplo, IsComplete, IsUnique ou CustomSql. Os parâmetros da regra diferem para cada tipo de regra. Para obter uma referência completa dos tipos de regras DQDL e seus parâmetros, consulte Referência de tipos de regra DQDL.
Regras compostas
A DQDL é compatível com os seguintes operadores lógicos que você pode usar para combinar regras. Essas regras são chamadas de regras compostas.
- e
-
O operador lógico
andresultará emtruese, e somente se, as regras que ele conecta foremtrue. Caso contrário, a regra combinada resultará emfalse. Cada regra que você conecta com o operadoranddeve estar entre parênteses.O exemplo a seguir usa o operador
andpara combinar duas regras DQDL.(IsComplete "id") and (IsUnique "id") - or
-
O operador lógico
orresultará emtruese, e somente se, uma ou mais regras que ele conecta foremtrue. Cada regra que você conecta com o operadorordeve estar entre parênteses.O exemplo a seguir usa o operador
orpara combinar duas regras DQDL.(RowCount "id" > 100) or (IsPrimaryKey "id")
Você pode usar o mesmo operador para conectar várias regras, portanto, a combinação de regras a seguir é permitida.
(Mean "Star_Rating" > 3) and (Mean "Order_Total" > 500) and (IsComplete "Order_Id")Você pode combinar os operadores lógicos em uma única expressão. Por exemplo:
(Mean "Star_Rating" > 3) and ((Mean "Order_Total" > 500) or (IsComplete "Order_Id"))Você também pode criar regras mais complexas e aninhadas.
(RowCount > 0) or ((IsComplete "colA") and (IsUnique "colA"))Como as regras compostas funcionam
Por padrão, as regras compostas são avaliadas como regras individuais em todo o conjunto de dados ou tabela e, em seguida, os resultados são combinados. Em outras palavras, a coluna inteira é avaliada primeiro e, em seguida, o operador é aplicado. Esse comportamento padrão é explicado abaixo com um exemplo:
# Dataset
+------+------+
|myCol1|myCol2|
+------+------+
| 2| 1|
| 0| 3|
+------+------+
# Overall outcome
+----------------------------------------------------------+-------+
|Rule |Outcome|
+----------------------------------------------------------+-------+
|(ColumnValues "myCol1" > 1) OR (ColumnValues "myCol2" > 2)|Failed |
+----------------------------------------------------------+-------+
No exemplo acima, o AWS Glue Data Quality avalia primeiro (ColumnValues "myCol1" > 1), o que resultará em uma falha. Em seguida, ele avaliará (ColumnValues "myCol2" > 2), que também falhará. A combinação de ambos os resultados será anotada como FALHA.
No entanto, se você preferir um comportamento semelhante ao SQL, em que a linha inteira deve ser avaliada, é necessário definir explicitamente o parâmetro ruleEvaluation.scope conforme mostrado em additionalOptions no trecho de código abaixo.
object GlueApp {
val datasource = glueContext.getCatalogSource(
database="<db>",
tableName="<table>",
transformationContext="datasource"
).getDynamicFrame()
val ruleset = """
Rules = [
(ColumnValues "age" >= 26) OR (ColumnLength "name" >= 4)
]
"""
val dq_results = EvaluateDataQuality.processRows(
frame=datasource,
ruleset=ruleset,
additionalOptions=JsonOptions("""
{
"compositeRuleEvaluation.method":"ROW"
}
"""
)
)
}
No Catálogo de Dados do AWS Glue, é possível configurar facilmente essa opção na interface do usuário, conforme demonstrado abaixo.
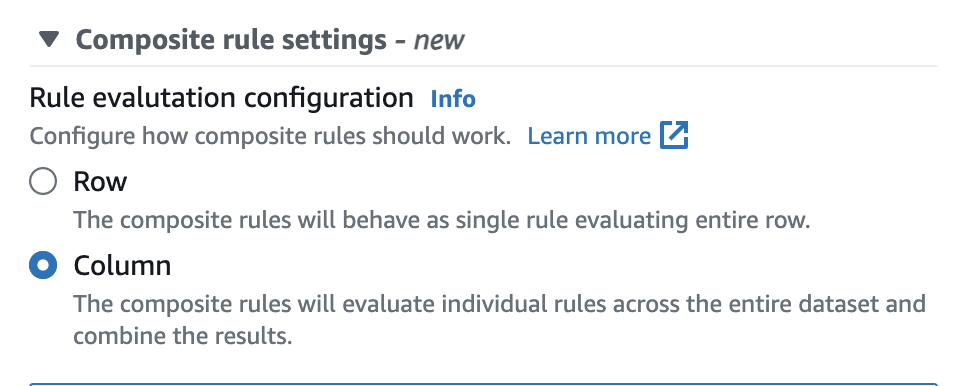
Depois de definidas, as regras compostas se comportarão como uma única regra avaliando a linha inteira. O exemplo a seguir ilustra esse comportamento.
# Row Level outcome
+------+------+------------------------------------------------------------+---------------------------+
|myCol1|myCol2|DataQualityRulesPass |DataQualityEvaluationResult|
+------+------+------------------------------------------------------------+---------------------------+
|2 |1 |[(ColumnValues "myCol1" > 1) OR (ColumnValues "myCol2" > 2)]|Passed |
|0 |3 |[(ColumnValues "myCol1" > 1) OR (ColumnValues "myCol2" > 2)]|Passed |
+------+------+------------------------------------------------------------+---------------------------+
Algumas regras não podem ser aceitas nesse recurso porque seu resultado geral depende de limites ou proporções. Elas estão listadas abaixo.
Regras baseadas em índices:
-
Completeness
-
DatasetMatch
-
ReferentialIntegrity
-
Exclusividade
Regras dependentes de limites:
Quando as regras a seguir incluem limites, elas não são aceitas. No entanto, as regras que não envolvem with threshold permanecem válidas.
-
ColumnDataType
-
ColumnValues
-
CustomSQL
Expressões
Se um tipo de regra não produzir uma resposta booliana, você deverá fornecer uma expressão como parâmetro para criar uma resposta booliana. Por exemplo, a regra a seguir verifica a média de todos os valores em uma coluna em relação a uma expressão para retornar um resultado verdadeiro ou falso.
Mean "colA" between 80 and 100Alguns tipos de regras, como IsUnique e IsComplete já retornam uma resposta booleana.
A tabela a seguir lista as expressões que você pode usar nas regras DQDL.
| Expressão | Descrição | Exemplo |
|---|---|---|
= x |
Será resolvido como true se a resposta do tipo de regra for igual a x. |
|
!=x |
x será resolvido como verdadeiro se a resposta do tipo de regra for diferente de x. |
|
> x |
Será resolvido como true se a resposta do tipo de regra for maior que x. |
|
< x |
Será resolvido como true se a resposta do tipo de regra for menor que x. |
|
>= x |
Será resolvido como true se a resposta do tipo de regra for maior que ou igual a x. |
|
<= x |
Será resolvido como true se a resposta do tipo de regra for menor que ou igual a x. |
|
between x and y |
Será resolvido como true se a resposta do tipo de regra estiver em um intervalo especificado (exclusivo). Use esse tipo de expressão apenas para tipos numéricos e de data. |
|
not between x and y |
Será resolvido como verdadeiro se a resposta do tipo de regra não estiver em um intervalo especificado (inclusive). Você só deve usar esse tipo de expressão para tipos numéricos e dados. |
|
in [a, b, c,... ] |
Será resolvido para true se a resposta do tipo de regra está no conjunto especificado. |
|
not in [a, b, c, ...] |
Será resolvido para true se a resposta do tipo de regra não estiver no conjunto especificado. |
|
matches /ab+c/i |
Será resolvido como true se a resposta do tipo de regra corresponder a uma expressão regular. |
|
not matches /ab+c/i |
Será resolvido como true se a resposta do tipo de regra não corresponder a uma expressão regular. |
|
now() |
Só funciona com o tipo de regra ColumnValues para criar uma expressão de data. |
|
matches/in […]/not matches/not in [...] with threshold |
Especifica a porcentagem de valores que correspondem às condições da regra. Funciona somente com os tipos de regras ColumnValues, ColumnDataType e CustomSQL. |
|
Palavras-chave para NULL, EMPTY e WHITESPACES_ONLY
Se desejar validar se uma coluna de string tem uma string nula, vazia ou apenas com espaços em branco, você pode usar as seguintes palavras-chave:
-
NULL/null: Essa palavra-chave é resolvida como verdadeira para um valor
nullem uma coluna de string.ColumnValues "colA" != NULL with threshold > 0.5retornaria verdadeiro se mais de 50% dos seus dados não tivessem valores nulos.(ColumnValues "colA" = NULL) or (ColumnLength "colA" > 5)retornaria verdadeiro para todas as linhas que têm um valor nulo ou comprimento > 5. Observe que isso exigirá o uso da opção "compositeRuleEvaluation.method" = "ROW". -
EMPTY/empty: essa palavra-chave é resolvida como verdadeira para um valor de string vazio ("") em uma coluna de string. Alguns formatos de dados transformam nulos em uma coluna de string para strings vazias. Essa palavra-chave ajuda a filtrar strings vazias em seus dados.
(ColumnValues "colA" = EMPTY) or (ColumnValues "colA" in ["a", "b"])retornaria verdadeiro se uma linha estivesse vazia, "a" ou "b". Observe que isso exige o uso da opção "compositeRuleEvaluation.method" = "ROW". -
WHITESPACES_ONLY/whitespaces_only: essa palavra-chave é resolvida como verdadeira para uma string somente com espaços em branco (" ") em uma coluna de string.
ColumnValues "colA" not in ["a", "b", WHITESPACES_ONLY]retornaria verdadeiro se uma linha não fosse "a" ou "b" nem apenas espaços em branco.Regras compatíveis:
Para uma expressão numérica ou baseada em data, se você quiser validar se uma coluna tem um valor nulo, poderá usar as palavras-chave a seguir.
-
NULL/null: Essa palavra-chave é resolvida como verdadeira para um valor nulo em uma coluna de string.
ColumnValues "colA" in [NULL, "2023-01-01"]retornaria verdadeiro se as datas em sua coluna fossem iguais a2023-01-01ou nulas.(ColumnValues "colA" = NULL) or (ColumnValues "colA" between 1 and 9)retornaria verdadeiro para todas as linhas que têm um valor nulo ou valores entre 1 e 9. Observe que isso exigirá o uso da opção "compositeRuleEvaluation.method" = "ROW".Regras compatíveis:
Filtragem com a cláusula Where
nota
A cláusula Where só é compatível com o AWS Glue 4.0.
Você pode filtrar seus dados ao criar regras. Isso é útil quando você quiser aplicar regras condicionais.
<DQDL Rule> where "<valid SparkSQL where clause> " É necessário especificar o filtro com a palavra-chave where, seguida por uma instrução válida do SparkSQL entre aspas ("").
Se você quiser adicionar a cláusula where a uma regra com um limite, será necessário especificar a cláusula where antes da condição de limite.
<DQDL Rule> where "valid SparkSQL statement>" with threshold <threshold condition>
Com essa sintaxe, você pode escrever regras como as seguintes.
Completeness "colA" > 0.5 where "colB = 10"
ColumnValues "colB" in ["A", "B"] where "colC is not null" with threshold > 0.9
ColumnLength "colC" > 10 where "colD != Concat(colE, colF)" Vamos validar se a instrução do SparkSQL fornecida é válida. Se for inválida, a avaliação da regra falhará e lançaremos o IllegalArgumentException com o seguinte formato:
Rule <DQDL Rule> where "<invalid SparkSQL>" has provided an invalid where clause :
<SparkSQL Error>Comportamento da cláusula where quando a identificação do registro de erro no nível de linha estiver ativada
Com o AWS Glue Data Quality, você pode identificar registros específicos que falharam. Ao aplicar uma cláusula where às regras compatíveis com resultados no nível de linha, rotularemos como Passed as linhas que forem filtradas pela cláusula where.
Se você preferir rotular separadamente as linhas filtradas como SKIPPED, defina o seguinte additionalOptions para a tarefa de ETL.
object GlueApp {
val datasource = glueContext.getCatalogSource(
database="<db>",
tableName="<table>",
transformationContext="datasource"
).getDynamicFrame()
val ruleset = """
Rules = [
IsComplete "att2" where "att1 = 'a'"
]
"""
val dq_results = EvaluateDataQuality.processRows(
frame=datasource,
ruleset=ruleset,
additionalOptions=JsonOptions("""
{
"rowLevelConfiguration.filteredRowLabel":"SKIPPED"
}
"""
)
)
}Como exemplo, consulte a regra e o quadro de dados a seguir:
IsComplete att2 where "att1 = 'a'"| id | att1 | att2 | Resultados no nível de linha (padrão) | Resultados no nível de linha (opção ignorada) | Comentários |
|---|---|---|---|---|---|
| 1 | a | f | PASSED | PASSED | |
| 2 | b | d | PASSED | SKIPPED | A linha é filtrada, pois att1 não é "a" |
| 3 | a | nulo | COM FALHA | COM FALHA | |
| 4 | a | f | PASSED | PASSED | |
| 5 | b | nulo | PASSED | SKIPPED | A linha é filtrada, pois att1 não é "a" |
| 6 | a | f | PASSED | PASSED |
Regras dinâmicas
nota
As regras dinâmicas são compatíveis somente no ETL do AWS Glue e não são compatíveis no Catálogo de Dados do AWS Glue.
Agora é possível criar regras dinâmicas para comparar as métricas atuais produzidas por suas regras com seus valores históricos. Essas comparações históricas são habilitadas ao usar o operador last() em expressões. Por exemplo, a regra RowCount >
last() terá êxito quando o número de linhas na execução atual for maior do que a contagem de linhas anterior mais recente para o mesmo conjunto de dados. last() usa um argumento opcional de número natural que descreve quantas métricas anteriores devem ser consideradas; last(k) em que k
>= 1 fará referência às últimas k métricas.
-
Se nenhum ponto de dados estiver disponível,
last(k)retornará o valor padrão 0,0. -
Se menos de
kmétricas estiverem disponíveis,last(k)retornará todas as métricas anteriores.
Para formar expressões válidas, use last(k), em que k > 1 requer uma função de agregação para reduzir vários resultados históricos a um único número. Por exemplo, RowCount > avg(last(5)) verificará se a contagem de linhas do conjunto de dados atual é estritamente maior do que a média das últimas cinco contagens de linhas do mesmo conjunto de dados. RowCount > last(5) produzirá um erro porque a contagem de linhas do conjunto de dados atual não pode ser comparada de forma significativa a uma lista.
Funções de agregação compatíveis:
-
avg -
median -
max -
min -
sum -
std(desvio padrão) -
abs(valor absoluto) -
index(last(k), i)permitirá selecionar oivalor mais recente entre os últimosk.ié indexado em zero, entãoindex(last(3), 0)retornará o ponto de dados mais recente eindex(last(3), 3)resultará em um erro, pois há apenas três pontos de dados e tentamos indexar o 4.º mais recente.
Exemplos de expressões
ColumnCorrelation
ColumnCorrelation "colA" "colB" < avg(last(10))
DistinctValuesCount
DistinctValuesCount "colA" between min(last(10))-1 and max(last(10))+1
A maioria dos tipos de regras com condições ou limites numéricos é compatível com as regras dinâmicas. Consulte a tabela fornecida, Analisadores e regras, para determinar se as regras dinâmicas são compatíveis com seu tipo de regra.
Exclusão de estatísticas das regras dinâmicas
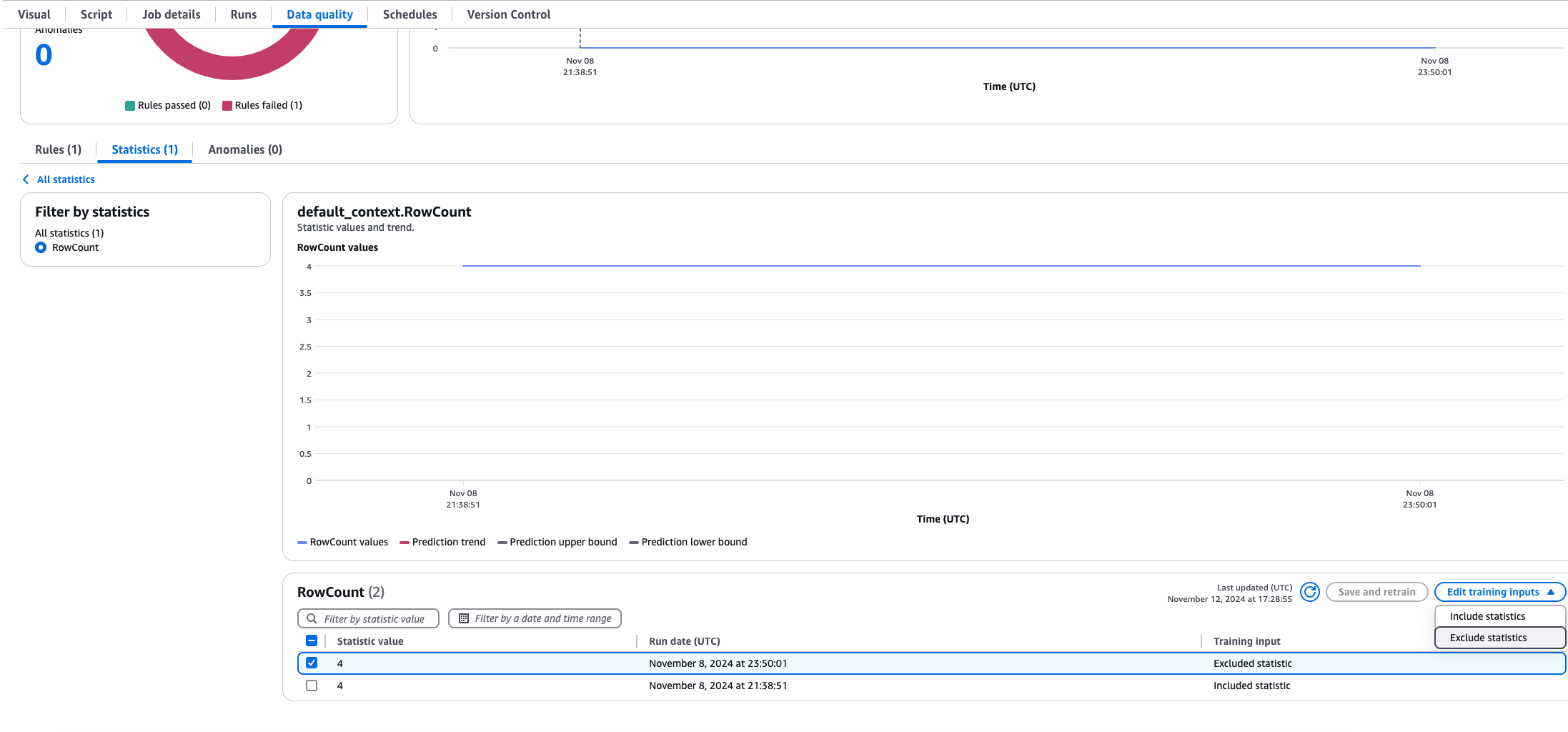
Às vezes, você precisará excluir estatísticas de dados dos cálculos das regras dinâmicas. Digamos que você tenha feito um carregamento de dados históricos e não queira que isso afete as médias. Para fazer isso, abra o trabalho no ETL do AWS Glue e escolha a guia Qualidade de dados, em seguida escolha Estatísticas e selecione as estatísticas que você deseja excluir. Você poderá ver um gráfico de tendências com uma tabela de estatísticas. Selecione os valores que você deseja excluir e escolha Excluir estatísticas. Agora, as estatísticas excluídas não serão consideradas nos cálculos dinâmicos das regras.
Analisadores
nota
Não há suporte a analisadores no Catálogo de Dados do AWS Glue.
As regras de DQDL usam funções chamadas analisadores para coletar informações sobre seus dados. Essas informações são empregadas por uma expressão booleana da regra para determinar se a regra terá êxito ou não. Por exemplo, a regra RowCount RowCount > 5 usará um analisador de contagem de linhas para descobrir o número de linhas em seu conjunto de dados e comparar essa contagem com a expressão > 5 para verificar se existem mais de cinco linhas no conjunto de dados atual.
Às vezes, em vez de criar regras, recomendamos criar analisadores e depois fazer com que eles gerem estatísticas que possam ser usadas para detectar anomalias. Para esses casos, será necessário criar analisadores. Os analisadores diferem das regras nas seguintes maneiras:
| Característica | Analisadores | Regras |
|---|---|---|
| Parte do conjunto de regras | Sim | Sim |
| Gera estatísticas | Sim | Sim |
| Gera observações | Sim | Sim |
| Pode avaliar e afirmar uma condição | Não | Sim |
| É possível configurar ações, como interromper os trabalhos em caso de falha ou continuar o processamento do trabalho | Não | Sim |
Os analisadores podem existir de forma independente, sem a necessidade de regras, permitindo a configuração rápida e a construção progressiva de regras de qualidade de dados.
Alguns tipos de regras podem ser inseridos no bloco de Analyzers do seu conjunto de regras para executar as regras necessárias para os analisadores e coletar informações sem aplicar verificações para nenhuma condição. Alguns analisadores não estão associados a regras e só podem ser inseridos no bloco de Analyzers. A tabela a seguir indica se cada item é compatível como uma regra ou como um analisador independente, junto com detalhes adicionais para cada tipo de regra.
Exemplo de conjunto de regras com o analisador
O seguinte conjunto de regras usa:
-
uma regra dinâmica para verificar se um conjunto de dados está crescendo acima da média final nas últimas três execuções de trabalho;
-
um analisador de
DistinctValuesCountpara registrar o número de valores distintos na colunaNamedo conjunto de dados; -
um analisador de
ColumnLengthpara rastrear o tamanho mínimo e máximo deNameao longo do tempo.
Os resultados das métricas do analisador podem ser visualizados na guia Data Quality da execução do trabalho.
Rules = [
RowCount > avg(last(3))
]
Analyzers = [
DistinctValuesCount "Name",
ColumnLength "Name"
]
O AWS Glue Data Quality é compatível com os seguintes analisadores.
| Nome do analisador | Funcionalidade |
|---|---|
RowCount |
Calcula as quantidades de linhas para um conjunto de dados |
Completeness |
Calcula a porcentagem de completude de uma coluna |
Uniqueness |
Calcula a porcentagem de exclusividade de uma coluna |
Mean |
Calcula a média de uma coluna numérica |
Sum |
Calcula a soma de uma coluna numérica |
StandardDeviation |
Calcula o desvio padrão de uma coluna numérica |
Entropy |
Calcula a entropia de uma coluna numérica |
DistinctValuesCount |
Calcular o número de valores distintos em uma coluna |
UniqueValueRatio |
Calcula a proporção de valores exclusivos em uma coluna |
ColumnCount |
Calcula o número de colunas em um conjunto de dados |
ColumnLength |
Calcula o comprimento de uma coluna |
ColumnValues |
Calcula o mínimo e o máximo para colunas numéricas Calcula o mínimo e o máximo de ColumnLength para colunas não numéricas |
ColumnCorrelation |
Calcula as correlações de colunas para colunas específicas |
CustomSql |
Calcula as estatísticas retornadas pelo CustomSQL |
AllStatistics |
Calcula as seguintes estatísticas:
|
Comentários
É possível usar o caractere "#" para adicionar um comentário ao seu documento DQDL. Qualquer coisa após o caractere "#" e até o final da linha é ignorada pelo DQDL.
Rules = [
# More items should generally mean a higher price, so correlation should be positive
ColumnCorrelation "price" "num_items" > 0
]