Migrar o AWS Glue para trabalhos do Spark para o AWS Glue versão 5.0
Este tópico descreve as alterações entre as versões 0.9, 1.0, 2.0, 3.0 e 4.0 do AWS Glue para permitir que você migre suas aplicações do Spark e trabalhos de ETL para o AWS Glue 5.0. Ele também descreve os recursos do AWS Glue 5.0 e as vantagens de usá-lo.
Para usar esse recurso com seus trabalhos de ETL do AWS Glue, escolha 5.0 para a Glue version ao criar seus trabalhos.
Novos atributos
Esta seção descreve novos recursos e vantagens do AWS Glue versão 5.0.
-
Atualização do Apache Spark de versão 3.3.0 no AWS Glue 4.0 para versão 3.5.4 no AWS Glue 5.0. Consulte Principais aprimoramentos da versão Spark 3.3.0 para a versão Spark 3.5.4.
-
Controle de acesso refinado (FGAC) nativo do Spark usando o Lake Formation. Isso inclui FGAC para tabelas do tipo Iceberg, Delta e Hudi. Para obter mais informações, consulte Usar o AWS Glue com AWS Lake Formation para controle de acesso refinado.
Observe as seguintes considerações ou limitações para o FGAC nativo do Spark:
No momento, não há suporte a gravação de dados
Gravar no Iceberg via
GlueContextusando o Lake Formation requer, em vez disso, o uso do controle de acesso do IAM
Para obter uma lista completa das limitações e considerações ao usar o FGAC nativo para o Spark, consulte Considerações e limitações.
-
Suporte à Concessão de Acesso do Amazon S3 como uma solução de controle de acesso escalável aos dados do Amazon S3 do AWS Glue. Para obter mais informações, consulte Usar Concessão de Acesso do Amazon S3 com o AWS Glue.
-
Os formatos de tabelas abertas (OTF, na sigla em inglês) foram atualizados para as versões Hudi 0.15.0, Iceberg 1.7.1 e Delta Lake 3.3.0
-
Suporte ao Amazon SageMaker Unified Studio.
-
Amazon SageMaker Lakehouse e integração de abstração de dados. Para obter mais informações, consulte Consultando catálogos de dados do metastore com base no ETL AWS Glue.
-
Suporte à instalação de bibliotecas Python adicionais usando o arquivo
requirements.txt. Para obter mais informações, consulte Instalar bibliotecas Python adicionais no AWS Glue 5.0 ou superior usando o arquivo requirements.txt. -
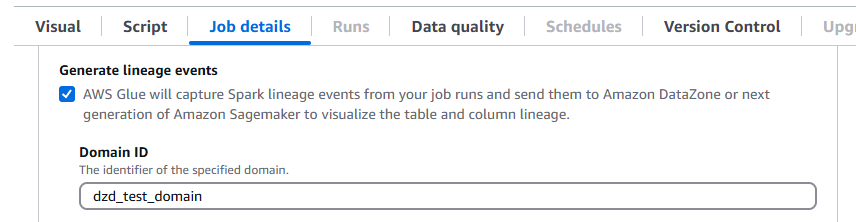
AWS GlueO 5.0 oferece suporte à linhagem de dados no Amazon DataZone. É possível configurar o AWS Glue para coletar automaticamente informações de linhagem durante a execução de trabalhos do Spark e enviar os eventos de linhagem para serem visualizados no Amazon DataZone. Para obter mais informações, consulte Linhagem de dados no Amazon DataZone.
Para configurá-la no console do AWS Glue, ative Gerar eventos de linhagem e insira o ID do seu domínio do Amazon DataZone na guia Detalhes do trabalho.
Como alternativa, é possível fornecer o parâmetro de trabalho a seguir (forneça ID do seu domínio do DataZone):
Chave:
--confValue (Valor):
extraListeners=io.openlineage.spark.agent.OpenLineageSparkListener —conf spark.openlineage.transport.type=amazon_datazone_api -conf spark.openlineage.transport.domainId=<your-domain-ID>
-
Atualizações do conector e do driver JDBC. Para obter mais informações, consulte Apêndice B: upgrades do driver JDBC e Apêndice C: Atualizações de conectores.
-
Atualização do Java de 8 para 17.
-
Maior armazenamento para operadores do AWS Glue
G.1XeG.2Xcom espaço em disco aumentando para 94 GB e 138 GB, respectivamente. Além disso, novos tipos de operadoresG.12X,G.16Xe otimizados para memóriaR.1X,R.2X,R.4X,R.8Xestão disponíveis no AWS Glue 4.0 e versões posteriores. Para obter mais informações, consulte . Tarefas Suporte ao AWS SDK para Java, versão 2: os trabalhos do AWS Glue 5.0 poderão usar o Java versões 1.12.569
ou 2.28.8 se o trabalho for compatível com a v2. O AWS SDK para Java 2.x é uma reescrita principal do código de base da versão 1.x. Ele foi criado com base no Java 8+ e adiciona vários recursos frequentemente solicitados. Entre eles, suporte para E/S sem bloqueio e capacidade de conectar uma implementação HTTP diferente no runtime. Para obter mais informações, incluindo um Guia de migração do SDK para Java v1 a v2, consulte o guia AWS SDK para Java, versão 2.
Alterações que podem causar interrupções
Observe as seguintes alterações importantes:
-
No AWS Glue 5.0, ao usar o sistema de arquivos S3A, e se “fs.s3a.endpoint” e “fs.s3a.endpoint.region” não estiverem definidos, a região padrão usada pelo S3A será “us-east-2”. Isso pode causar problemas, como erros de tempo limite de upload do S3, especialmente para trabalhos da VPC. Para mitigar os problemas causados por essa alteração, defina a configuração “fs.s3a.endpoint.region” do Spark ao usar o sistema de arquivos S3A no AWS Glue 5.0.
-
Controle de acesso de alta granularidade (FGAC) do Lake Formation
-
AWS GlueO 5.0 só é compatível com o novo FGAC nativo do Spark usando Spark DataFrames. Ele não oferece suporte ao FGAC usando AWS Glue DynamicFrames.
-
O uso do FGAC na versão 5.0 requer a migração de AWS Glue DynamicFrames para Spark DataFrames.
-
Se não precisar do FGAC, não será necessário migrar para o Spark DataFrame e os recursos do GlueContext, como marcadores de tarefas e predicados push-down, continuarão funcionando.
-
-
Os trabalhos com o FGAC nativo do Spark exigem no mínimo 4 operadores: um driver de usuário, um driver de sistema, um executor de sistema e um executor de usuário em espera.
-
Para obter mais informações, consulte Usar o AWS Glue com AWS Lake Formation para controle de acesso refinado.
-
-
Acesso total à tabela (FTA) do Lake Formation
-
AWS GlueO 5.0 é compatível com FTA com DataFrames nativo do Spark (novo) e GlueContext DynamicFrames (legado, com limitações)
-
FTA nativo do Spark
-
Se o script 4.0 usar GlueContext, migre para o uso do Spark nativo.
-
Esse recurso é limitado a tabelas do Hive e do Iceberg
-
Para obter mais informações sobre como configurar um trabalho 5.0 para usar o FTA nativo do Spark, consulte FTA nativo do Spark no AWS Glue 5.0.
-
-
FTA DynamicFrame do GlueContext
-
Não é necessário fazer nenhuma alteração de código.
-
Esse recurso é limitado a tabelas não OTF. Ele não funcionará com Iceberg, Delta Lake e Hudi.
-
-
Não há suporte ao Leitor de CSV SIMD vetorizado.
Não há suporte ao registro em log contínuo para grupos de logs de saída. Em vez disso, use o grupo de logs
error.O
job-insights-rule-driverde insights de execução de trabalho do AWS Glue foi descontinuado. O fluxo de logsjob-insights-rca-driveragora está localizado no grupo de logs de erros.Não há suporte a conectores de mercado/personalizados baseados em Athena.
Não há suporte aos conectores Adobe Marketo Engage, Facebook Ads, Google Analytics 4, Planilhas Google, Hubspot, Instagram Ads, Intercom, Jira Cloud, Oracle NetSuite, Salesforce, Salesforce Marketing Cloud, Salesforce Marketing Cloud Account Engagement, SAP OData, ServiceNow, Slack, Snapchat Ads, Stripe, Zendesk e Zoho CRM.
Propriedades log4j personalizadas não são compatíveis no AWS Glue 5.0.
Principais aprimoramentos da versão Spark 3.3.0 para a versão Spark 3.5.4
Observe os seguintes aprimoramentos:
-
Cliente Python para Spark Connect (SPARK-39375
). -
Implementação de suporte a valores DEFAULT para colunas de tabelas (SPARK-38334
). -
Suporte a "Referências a alias de colunas laterais" (SPARK-27561
). -
Fortalecimento do uso do SQLSTATE para classes de erro (SPARK-41994
). -
Habilitação de junções do filtro Bloom por padrão (SPARK-38841
). -
Melhor escalabilidade da interface do usuário do Spark e estabilidade do driver para aplicações grandes (SPARK-41053
). -
Rastreamento de progresso assíncrono em streaming estruturado (SPARK-39591
). -
Processamento stateful arbitrário de Python em streaming estruturado (SPARK-40434
). -
Melhorias na cobertura da API do Pandas (SPARK-42882
) e suporte a entradas NumPy no PySpark (SPARK-39405 ). -
Fornecimento de um profiler de memória para funções do PySpark definidas pelo usuário (SPARK-40281
). -
Implementação do distribuidor PyTorch (SPARK-41589
). -
Publicação de artefatos SBOM (SPARK-41893
). -
Suporte a ambiente somente IPv6 (SPARK-39457
). -
Programador K8s personalizado (Apache UniKorn e Volcano) GA (SPARK-42802
). -
Suporte a clientes Scala e Go no Spark Connect (SPARK-42554
) e (SPARK-43351 ). -
Suporte a ML distribuído baseado em PyTorch para Spark Connect (SPARK-42471
). -
Suporte a streaming estruturado para Spark Connect em Python e Scala (SPARK-42938
). -
Suporte à API do Pandas para o Python Spark Connect Client (SPARK-42497
). -
Introdução das UDFs do Arrow Python (SPARK-40307
). -
Suporte a funções de tabela definidas pelo usuário do Python (SPARK-43798
). -
Migração dos erros do PySpark para classes de erro (SPARK-42986
). -
Estrutura de teste do PySpark (SPARK-44042
). -
Adição de suporte a Datasketches HLLSketch (SPARK-16484
). -
Aprimoramento da função SQL integrada (SPARK-41231
). -
Cláusula IDENTIFIER (SPARK-43205
). -
Adição de funções SQL às APIs do Scala, Python e R (SPARK-43907
). -
Adição de suporte a argumentos nomeados para funções SQL (SPARK-43922
). -
Prevenção de re-execução desnecessária de tarefas em um executor descomissionado perdido se os dados do shuffle forem migrados (SPARK-41469
). -
ML distribuído <> spark connect (SPARK-42471
). -
Distribuidor DeepSpeed (SPARK-44264
). -
Implementação do ponto de verificação do changelog para o armazenamento de estados RocksDB (SPARK-43421
). -
Introdução da propagação da marca d'água entre operadores (SPARK-42376
). -
Introdução de dropDuplicatesWithinWatermark (SPARK-42931
).
Ações para migrar para o AWS Glue 5.0
Para trabalhos existentes, altere a Glue version da versão anterior para Glue 5.0 na configuração do trabalho.
-
No AWS Glue Studio, escolha
Glue 5.0 - Supports Spark 3.5.4, Scala 2, Python 3emGlue version. -
Na API, escolha
5.0no parâmetroGlueVersionna operação da APIUpdateJob.
Para novos trabalhos, escolha Glue 5.0 ao criar um trabalho.
-
No console, escolha
Spark 3.5.4, Python 3 (Glue Version 5.0) or Spark 3.5.4, Scala 2 (Glue Version 5.0)emGlue version. -
No AWS Glue Studio, escolha
Glue 5.0 - Supports Spark 3.5.4, Scala 2, Python 3emGlue version. -
Na API, escolha
5.0no parâmetroGlueVersionna operação da APICreateJob.
Para visualizar os logs de eventos do Spark no AWS Glue 5.0, partindo do AWS Glue 2.0 ou anterior, inicie um servidor de histórico do Spark atualizado para o AWS Glue 5.0 usando o CloudFormation ou o Docker.
Lista de verificação da migração
Revise esta lista de verificação para migração:
-
Atualizações do Java 17
-
[Scala] Atualização das chamadas do AWS SDK de v1 para v2
-
Migração do Python 3.10 para 3.11
-
[Python] Atualização das referências ao boto de 1.26 para 1.34
AWS GlueRecursos do 5.0
Esta seção descreve os recursos do AWS Glue de forma mais detalhada.
Consultando catálogos de dados do metastore com base no ETL AWS Glue
É possível registrar seu trabalho do AWS Glue para acessar o AWS Glue Data Catalog, o que disponibiliza tabelas e outros recursos do metastore para consumidores diferentes. O Catálogo de Dados oferece suporte a uma hierarquia de vários catálogos, que unifica todos os seus dados nos data lakes do Amazon S3. Ele também fornece uma API de metastore do Hive e uma API de código aberto do Apache Iceberg para acessar os dados. Esses recursos estão disponíveis para o AWS Glue e outros serviços orientados por dados, como Amazon EMR, Amazon Athena e Amazon Redshift.
Ao criar recursos no Catálogo de Dados, será possível acessá-los de qualquer mecanismo SQL que ofereça suporte à API REST do Apache Iceberg. O AWS Lake Formation gerencia as permissões. Após a configuração, é possível utilizar os recursos do AWS Glue para consultar dados diferentes fazendo consultas para esses recursos do metastore com aplicações bem conhecidas. Isso inclui o Apache Spark e o Trino.
Como os recursos de metadados são organizados
Os dados são organizados em uma hierarquia lógica de catálogos, bancos de dados e tabelas, usando o AWS Glue Data Catalog:
Catálogo: um contêiner lógico que contém objetos de um armazenamento de dados, como esquemas ou tabelas.
Banco de dados: organiza objetos de dados, como tabelas e visualizações, em um catálogo.
Tabelas e visualizações: objetos de dados em um banco de dados que fornecem uma camada de abstração com um esquema compreensível. Elas facilitam o acesso aos dados subjacentes, que podem estar em vários formatos e em vários locais.
Migrar do AWS Glue 4.0 para o AWS Glue 5.0
Todos os parâmetros de trabalho e principais recursos existentes no AWS Glue 4.0 existirão no AWS Glue 5.0, com exceção das transformações de machine learning.
Os seguintes parâmetros novos foram adicionados:
-
--enable-lakeformation-fine-grained-access: habilita o recurso de controle de acesso refinado (FGAC) nas tabelas do AWS Lake Formation.
Consulte a documentação de migração do Spark:
Migrar do AWS Glue 3.0 para o AWS Glue 5.0
nota
Para ver as etapas de migração relacionadas ao AWS Glue 4.0, consulte Migrar do AWS Glue 3.0 para o AWS Glue 4.0.
Todos os parâmetros de trabalho e principais recursos existentes no AWS Glue 3.0 existirão no AWS Glue 5.0, com exceção das transformações de machine learning.
Migrar do AWS Glue 2.0 para o AWS Glue 5.0
nota
Para obter as etapas de migração relacionadas ao AWS Glue 4.0 e uma lista das diferenças de migração entre as versões 3.0 e 4.0 do AWS Glue, consulte Migrar do AWS Glue 3.0 para o AWS Glue 4.0.
Observe também as seguintes diferenças de migração entre as versões 3.0 e 2.0 do AWS Glue:
Todos os parâmetros de trabalho e principais recursos existentes no AWS Glue 2.0 existirão no AWS Glue 5.0, com exceção das transformações de machine learning.
Várias alterações do Spark sozinhas podem exigir a revisão de seus scripts para garantir que os recursos removidos não estejam sendo referenciados. Por exemplo, o Spark 3.1.1 e as versões posteriores não habilitam UDFs sem tipo Scala, mas o Spark 2.4 as permite.
Não há suporte ao Python 2.7.
Quaisquer jars extras fornecidos em trabalhos do AWS Glue 2.0 existentes podem trazer dependências conflitantes, uma vez que houve atualizações em várias dependências. É possível evitar conflitos de classpath com o parâmetro de trabalho
--user-jars-first.Alterações no comportamento de carregar/salvar de timestamps de/para arquivos parquet. Para obter mais detalhes, consulte Atualização do Spark SQL 3.0 para 3.1.
Paralelismo de tarefas do Spark diferente para configuração do driver/executor. É possível ajustar o paralelismo de tarefas ao passar o argumento
--executor-coresdo trabalho.
Mudanças do comportamento de registro em log no AWS Glue 5.0
Veja a seguir as mudanças no comportamento de registro em log no AWS Glue 5.0. Para obter mais informações, consulte Registro contínuo para trabalhos do AWS Glue.
-
Agora, todos os logs (logs do sistema, logs do daemon do Spark, logs de usuário e logs do Glue Logger) são gravados no grupo de logs do
/aws-glue/jobs/errorpor padrão. -
O grupo de logs do
/aws-glue/jobs/logs-v2usado para registro contínuo em log nas versões anteriores não é mais usado. -
Você não pode mais renomear ou personalizar os nomes do grupo de logs ou do fluxo de logs usando os argumentos de registro contínuo em log que foram removidos. Em vez disso, veja os novos argumentos de trabalho no AWS Glue 5.0.
O 5.0 introduziu dois novos argumentos de trabalho. AWS Glue 5.0
-
––custom-logGroup-prefix: permite que você especifique um prefixo personalizado para os grupos de logs/aws-glue/jobs/errore/aws-glue/jobs/output. -
––custom-logStream-prefix: permite que você especifique um prefixo personalizado para os nomes do fluxo de logs nos grupos de logs.As regras de validação e as limitações para prefixos personalizados incluem:
-
O nome completo do fluxo de logs precisa ter de 1 a 512 caracteres.
-
O prefixo personalizado para nomes de fluxo de logs é limitado a 400 caracteres.
-
Os caracteres permitidos nos prefixos incluem caracteres alfanuméricos, sublinhados (“_”), hifens (“-”) e barras (“/”).
-
Argumentos de registro contínuo em log descontinuados no AWS Glue 5.0
Os seguintes argumentos de trabalho para registro contínuo em log foram descontinuados no 5.0. AWS Glue 5.0
-
––enable-continuous-cloudwatch-log -
––continuous-log-logGroup -
––continuous-log-logStreamPrefix -
––continuous-log-conversionPattern -
––enable-continuous-log-filter
Migração de conectores e drivers JDBC para AWS Glue 5.0
Para as versões do JDBC e dos conectores de data lake que foram atualizadas, consulte:
As alterações a seguir se aplicam às versões do conector ou do driver identificadas nos apêndices do Glue 5.0.
Amazon Redshift
Observe as seguintes alterações:
Adiciona suporte a nomes de tabelas em três partes para permitir que o conector consulte tabelas de compartilhamento de dados do Redshift.
Corrige o mapeamento de
ShortTypedo Spark para usarSMALLINTem vez deINTEGERdo Redshift para corresponder melhor ao tamanho de dados esperado.Adição de suporte a nomes de cluster personalizados (CNAME) para Amazon Redshift sem servidor.
Apache Hudi
Observe as seguintes alterações:
Suporte a índice de nível de registro.
Suporte a geração automática de chaves de registro. Agora você não precisa especificar o campo de chave do registro.
Apache Iceberg
Observe as seguintes alterações:
Suporte ao controle de acesso refinado com o AWS Lake Formation.
Suporte à ramificação e à marcação, que são referências nomeadas a snapshots com seus próprios ciclos de vida independentes.
Adição de um procedimento de visualização do log de alterações que gera uma visualização que contém as alterações feitas em uma tabela durante um período especificado ou entre snapshots específicos.
Delta Lake
Observe as seguintes alterações:
Suporte ao Delta Universal Format (UniForm), que permite acesso contínuo por meio do Apache Iceberg e do Apache Hudi.
Suporte a vetores de exclusão que implementam um paradigma Merge-on-Read.
AzureCosmos
Observe as seguintes alterações:
Adição de suporte a chaves de partição hierárquicas.
Adição de opção para usar um esquema personalizado com StringType (json bruto) para uma propriedade aninhada.
Adição da opção de configuração
spark.cosmos.auth.aad.clientCertPemBase64para permitir o uso da autenticação SPN (nome do ServicePrincipal) com um certificado em vez do segredo do cliente.
Para obter mais informações, consulte Log de alterações do conector Spark do Azure Cosmos DB
Microsoft SQL Server
Observe as seguintes alterações:
A criptografia TLS é habilitada por padrão.
Quando encrypt = false, mas o servidor exige criptografia, o certificado é validado com base na configuração
trustServerCertificateda conexão.aadSecurePrincipalIdeaadSecurePrincipalSecretobsoletos.Remoção da API
getAADSecretPrincipalId.Resolução CNAME adicionada quando o realm é especificado.
MongoDB
Observe as seguintes alterações:
Suporte ao modo de micro lotes com o Spark Structured Streaming.
Suporte a tipos de dados BSON.
Adição de suporte à leitura de várias coleções ao usar os modos de micro lote ou streaming contínuo.
Se o nome de uma coleção usada em sua opção de configuração
collectioncontiver uma vírgula, o Spark Connector a tratará como duas coleções diferentes. Para evitar isso, coloque uma barra invertida (\) antes dela.Se o nome de uma coleção usada em sua opção de configuração
collectionfor "*", o Spark Connector a interpretará como uma instrução para verificar todas as coleções. Para evitar isso, coloque uma barra invertida (\) antes dele.Se o nome de uma coleção usada em sua opção de configuração
collectioncontiver uma barra invertida (\), o Spark Connector tratará a barra invertida como um caractere de escape, o que pode mudar a forma como ele interpreta o valor. Para evitar isso, coloque uma outra barra invertida (\) antes dela.
Para obter mais informações, consulte Notas da versão do conector do MongoDB para Spark
Snowflake
Observe as seguintes alterações:
Introdução de um novo parâmetro
trim_spaceque pode ser usado para cortar valores de colunasStringTypeautomaticamente ao salvar em uma tabela do Snowflake. Padrão:false.Desabilitação do parâmetro
abort_detached_queryno nível da sessão por padrão.Remoção do requisito do parâmetro
SFUSERao usar OAUTH.Remoção do recurso Advanced Query Pushdown. Alternativas ao recurso estão disponíveis. Por exemplo, em vez de carregar dados das tabelas do Snowflake, os usuários podem carregar dados diretamente das consultas SQL do Snowflake.
Para obter mais informações, consulte Notas da versão do conector do Snowflake para Spark
Apêndice A: atualizações de dependência notáveis
Veja a seguir as atualizações de dependência:
| Dependência | Versão no AWS Glue 5.0 | Versão no AWS Glue 4.0 | Versão no AWS Glue 3.0 | Versão no AWS Glue 2.0 | Versão no AWS Glue 1.0 |
|---|---|---|---|---|---|
| Java | 17 | 8 | 8 | 8 | 8 |
| Spark | 3.5.4 | 3.3.0-amzn-1 | 3.1.1-amzn-0 | 2.4.3 | 2.4.3 |
| Hadoop | 3.4.1 | 3.3.3-amzn-0 | 3.2.1-amzn-3 | 2.8.5-amzn-5 | 2.8.5-amzn-1 |
| Scala | 2.12.18 | 2.12 | 2.12 | 2.11 | 2.11 |
| Jackson | 2.15.2 | 2.12 | 2.12 | 2.11 | 2.11 |
| Hive | 2.3.9-amzn-4 | 2,3.9-amzn-2 | 2.3.7-amzn-4 | 1.2 | 1.2 |
| EMRFS | 2.69.0 | 2.54.0 | 2.46.0 | 2.38.0 | 2.30.0 |
| Json4s | 3.7.0 M11 | 3.7.0 M11 | 3.6.6 | 3.5.x | 3.5.x |
| Arrow | 12.0.1 | 7.0.0 | 2.0.0 | 0.10.0 | 0.10.0 |
| AWS GlueCliente do Data Catalog | 4.5.0 | 3.7.0 | 3.0.0 | 1.10.0 | N/D |
| AWS SDK para Java | 2.29.52 | 1.12 | 1.12 | ||
| Python | 3.11 | 3.10 | 3.7 | 2.7 e 3.6 | 2.7 e 3.6 |
| Boto | 1.34.131 | 1.26 | 1.18 | 1.12 | N/D |
| Conector EMR DynamoDB | 5.6.0 | 4.16.0 |
Apêndice B: upgrades do driver JDBC
A seguir estão as atualizações do driver JDBC:
| Driver | Versão do driver JDBC no AWS Glue 5.0 | Versão do driver JDBC no AWS Glue 4.0 | Versão do driver JDBC no AWS Glue 3.0 | Versão do driver JDBC nas versões do AWS Glue anteriores |
|---|---|---|---|---|
| MySQL | 8.0.33 | 8.0.23 | 8.0.23 | 5.1 |
| Microsoft SQL Server | 10.2.0 | 9.4.0 | 7.0.0 | 6.1.0 |
| Bancos de dados da Oracle | 23.3.0.23.09 | 21.7 | 21.1 | 11.2 |
| PostgreSQL | 42.7.3 | 42.3.6 | 42.2.18 | 42.1.0 |
| Amazon Redshift |
redshift-jdbc42-2.1.0.29 |
redshift-jdbc42-2.1.0.16 |
redshift-jdbc41-1.2.12.1017 |
redshift-jdbc41-1.2.12.1017 |
| SAP Hana | 2.20.17 | 2.17.12 | ||
| Teradata | 20.00.00.33 | 20.00.00.06 |
Apêndice C: Atualizações de conectores
As atualizações do conector são as seguintes:
| Driver | Versão do conector no AWS Glue 5.0 | Versão do conector no AWS Glue 4.0 | Versão do conector no AWS Glue 3.0 |
|---|---|---|---|
| Conector EMR DynamoDB | 5.6.0 | 4.16.0 | |
| Amazon Redshift | 6.4.0 | 6.1.3 | |
| OpenSearch | 1.2.0 | 1.0.1 | |
| MongoDB | 10.3.0 | 10.0.4 | 3.0.0 |
| Snowflake | 3.0.0 | 2.12.0 | |
| Google BigQuery | 0.32.2 | 0.32.2 | |
| AzureCosmos | 4.33.0 | 4.22.0 | |
| AzureSQL | 1.3.0 | 1.3.0 | |
| Vertica | 3.3.5 | 3.3.5 |
Apêndice D: Atualizações do formato de tabela aberta
São atualizações do formato de tabela aberta:
| OTF | Versão do conector no AWS Glue 5.0 | Versão do conector no AWS Glue 4.0 | Versão do conector no AWS Glue 3.0 |
|---|---|---|---|
| Hudi | 0.15.0 | 0.12.1 | 0.10.1 |
| Delta Lake | 3.3.0 | 2.1.0 | 1.0.0 |
| Iceberg | 1.7.1 | 1.0.0 | 0.13.1 |
