Siga estas etapas para configurar um crawler para notificações de eventos do Amazon S3 para um destino do Amazon S3 usando o AWS Management Console ou a AWS CLI.
-
Faça login no AWS Management Console e abra o console do GuardDuty em https://console.aws.amazon.com/guardduty/
. -
Defina as propriedades do crawler. Para obter mais informações, consulte Definir opções de configuração do crawler no console do AWS Glue.
-
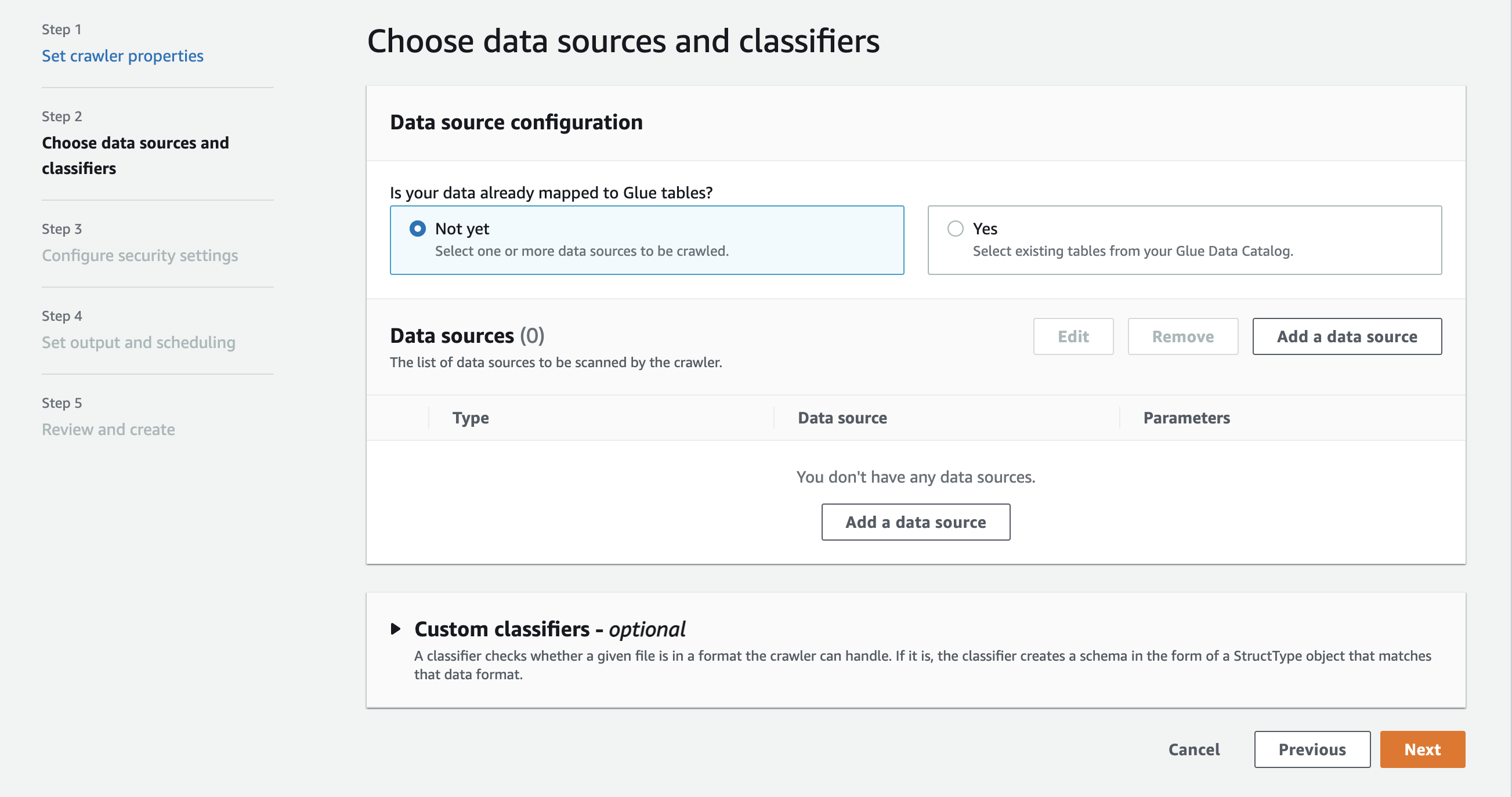
Na seção Configuração da fonte de dados, é perguntado a você se Os dados já estão mapeados para tabelas do AWS Glue?
A opção Not yet (Ainda não) já estará selecionada por padrão. Isso ocorre porque você está usando uma fonte de dados do Amazon S3 e os dados ainda não estão mapeados para as tabelas do AWS Glue.
-
Na seção Data sources (Fontes de dados), escolha Add a data source (Adicionar uma fonte de dados).
-
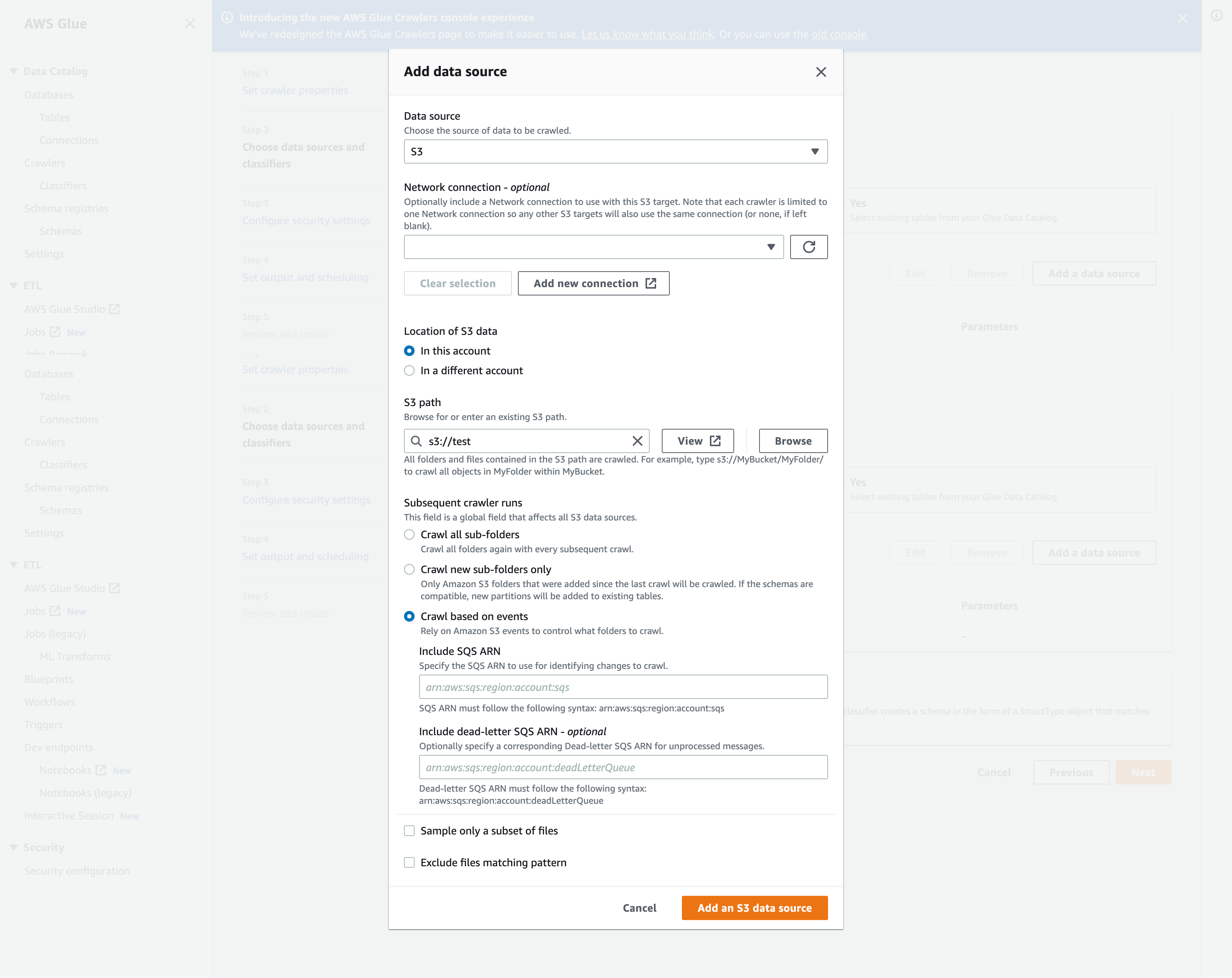
No modal Add data source (Adicionar origem dos dados), configure a fonte de dados do Amazon S3:
-
Data source (Fonte de dados): o Amazon S3 é selecionado por padrão.
-
Network connection (Conexão de rede) (opcional): escolha Add new connection (Adicionar nova conexão).
-
Location of Amazon S3 data (Local de dados do Amazon S3): a opção In this account (Nesta conta) será selecionado por padrão.
-
Amazon S3 path (Caminho do Amazon S3): especifique o caminho do Amazon S3 no qual pastas e arquivos são rastreados.
-
Subsequent crawler runs (Execuções subsequentes do crawler): escolha Crawl based on events (Rastreamento baseado em eventos) para usar notificações de eventos do Amazon S3 para seu crawler.
-
Include SQS ARN (Incluir ARN de SQS): especifique os parâmetros do armazenamento de dados, incluindo um ARN válido do SQS. (Por exemplo,
arn:aws:sqs:region:account:sqs). -
Include dead-letter SQS ARN (Incluir ARN de mensagens não entregues do SQS) (opcional): especifique um ARN válido de mensagens não entregues do SQS na Amazon. (Por exemplo,
arn:aws:sqs:region:account:deadLetterQueue). -
Escolha Add an Amazon S3 data source (Adicionar uma fonte de dados do Amazon S3).
-
