Depurar estágios exigentes e tarefas de retardatário
Você pode usar perfis de trabalho do AWS Glue para identificar estágios exigentes e tarefas de retardatário em seus trabalhos de extração, transformação e carga (ETL). Uma tarefa de retardatário leva muito mais tempo do que o restante das tarefas em um estágio de um trabalho do AWS Glue. Como resultado, o estágio leva mais tempo para ser concluído, o que também atrasa o tempo total de execução do trabalho.
Reunir arquivos de entrada pequenos em arquivos de saída maiores
Uma tarefa de retardatário pode ocorrer quando há uma distribuição não uniforme de trabalho em diferentes tarefas, ou um desvio de dados resulta em uma tarefa processando mais dados.
Você pode criar o perfil do seguinte código (um padrão comum no Apache Spark) para reunir um grande número de arquivos pequenos em arquivos de saída maiores. Para este exemplo, o conjunto de dados de entrada é 32 GB de arquivos JSON com compactação Gzip. O conjunto de dados de saída tem aproximadamente 190 GB de arquivos JSON não compactados.
O código perfilado é assim:
datasource0 = spark.read.format("json").load("s3://input_path") df = datasource0.coalesce(1) df.write.format("json").save(output_path)
Visualizar as métricas perfiladas no console do AWS Glue
Você pode criar o perfil do trabalho para examinar quatro conjuntos de métricas diferentes:
-
Movimentação de dados ETL
-
Embaralhamento de dados em executores
-
Execução de trabalho
-
Perfil de memória
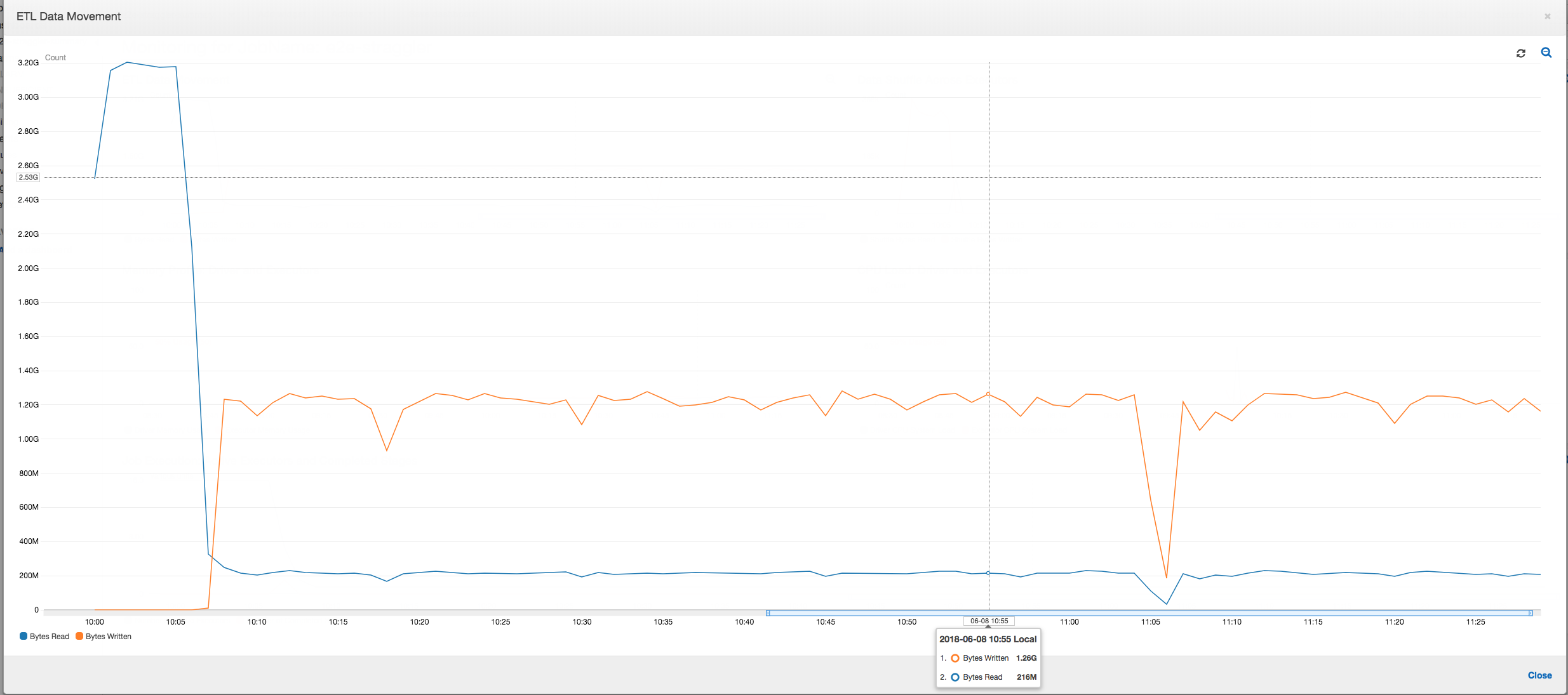
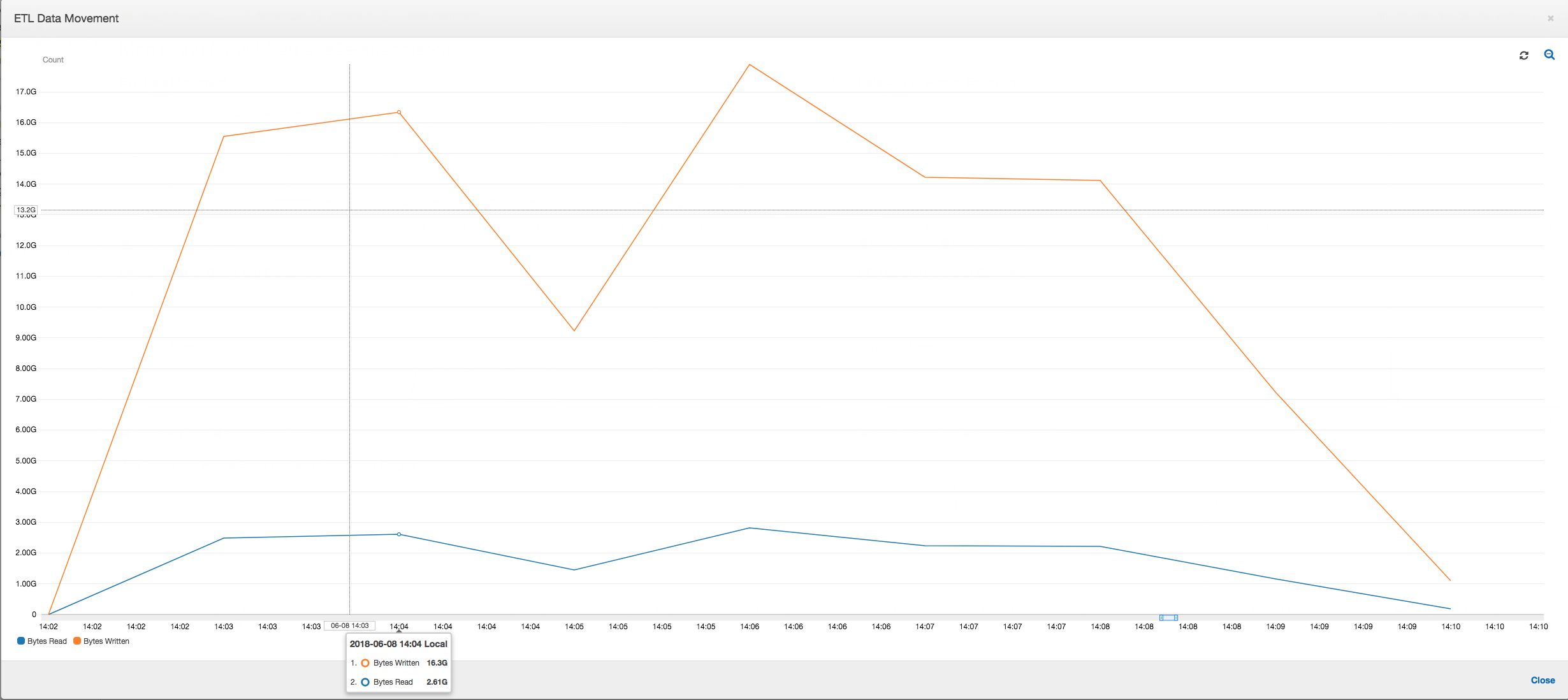
Movimentação de dados ETL: no perfil ETL Data Movement (Movimentação de dados ETL), os bytes são lidos bastante rapidamente por todos os executores no primeiro estágio concluído nos primeiros seis minutos. No entanto, o tempo total de execução do trabalho é de cerca de uma hora, principalmente consistindo em gravações de dados.
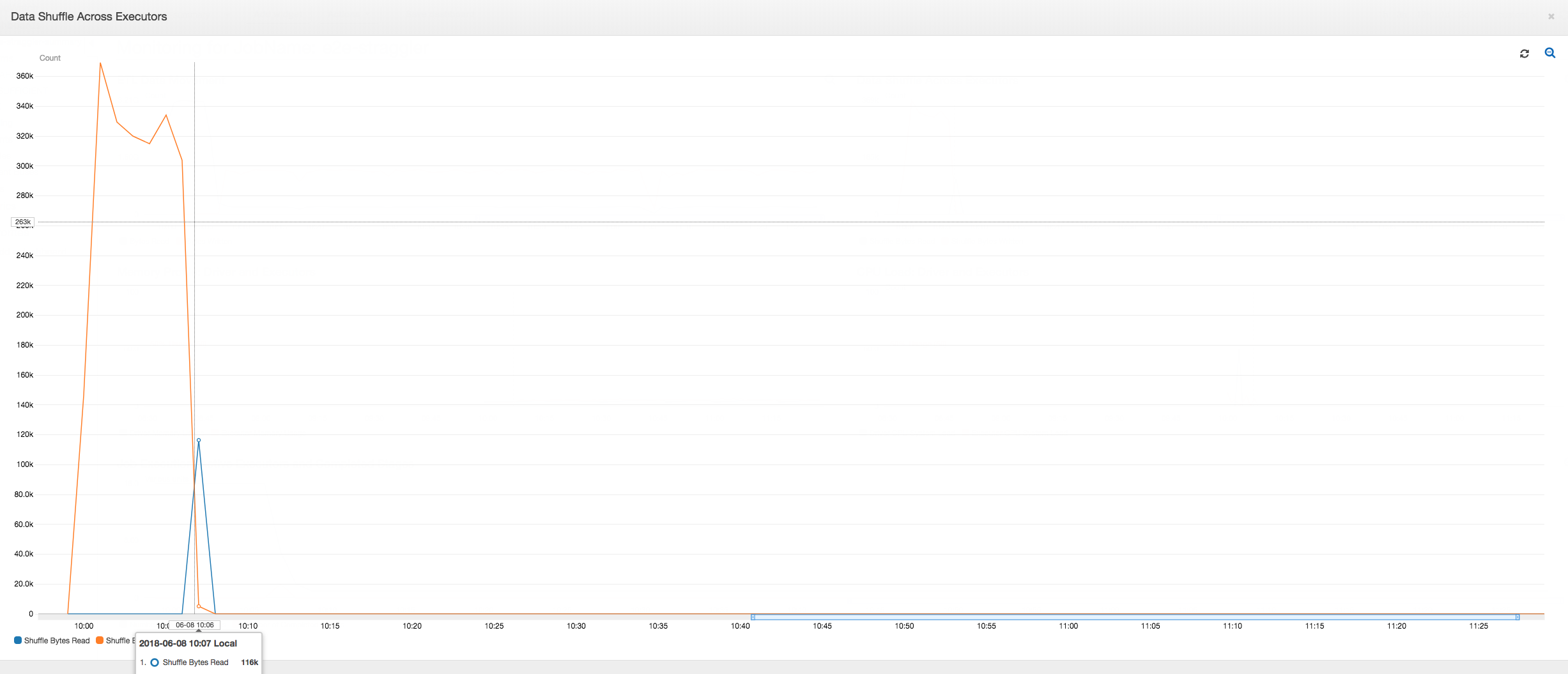
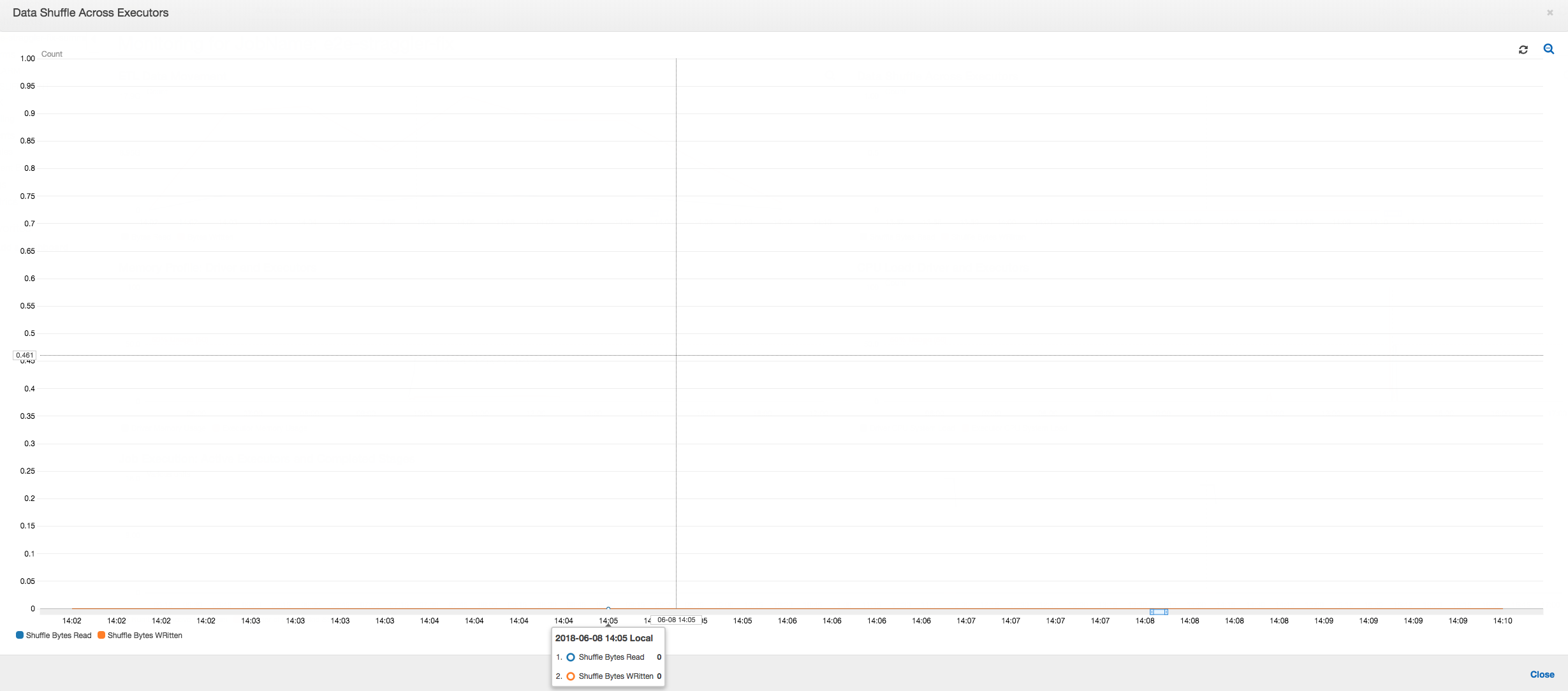
Embaralhamento de dados em executores: o número de bytes lidos e gravados durante o embaralhamento também mostra um pico antes da fase 2 terminar, conforme indicado pelas métricas Job Execution (Execução do trabalho) e Data Shuffle (Embaralhamento de dados). Depois que os dados são embaralhados em todos os executores, as leituras e gravações prosseguem no executor número 3 apenas.
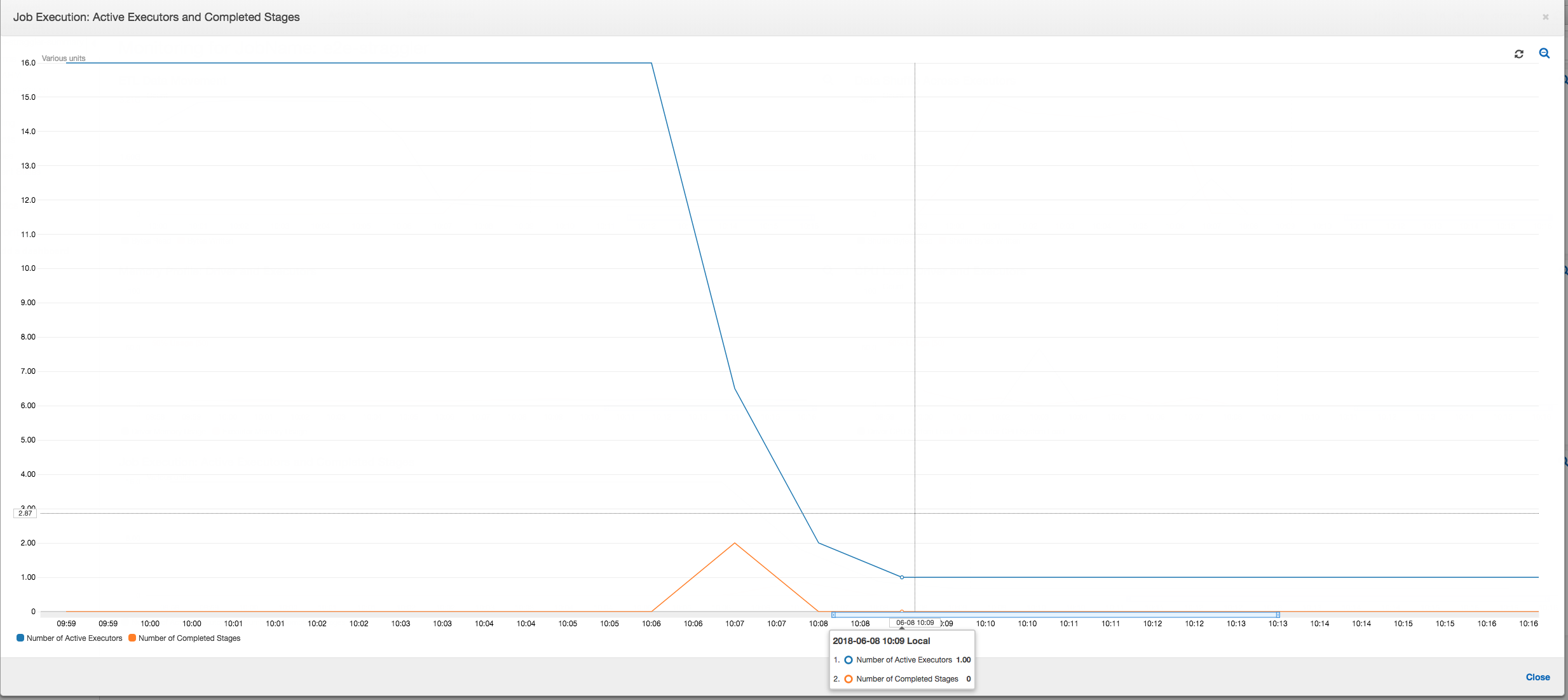
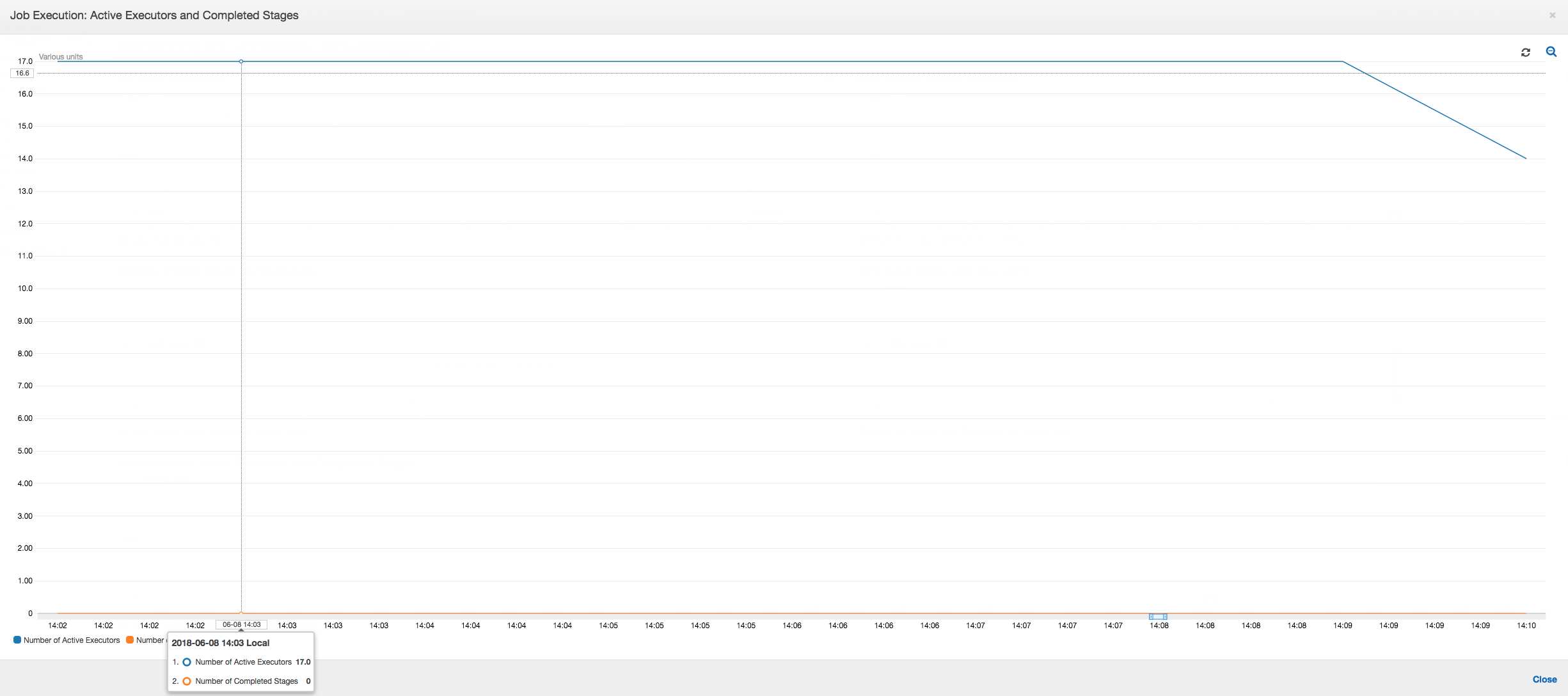
Execução de trabalho: como mostrado no gráfico a seguir, todos os outros executores estão ociosos e acabam sendo desativados às 10h09. Nesse momento, o número total de executores diminui a apenas um. Isso claramente mostra que o executor número 3 consiste na tarefa de retardatário que está levando o tempo de execução mais longo e está contribuindo para a maior parte do tempo de execução do trabalho.
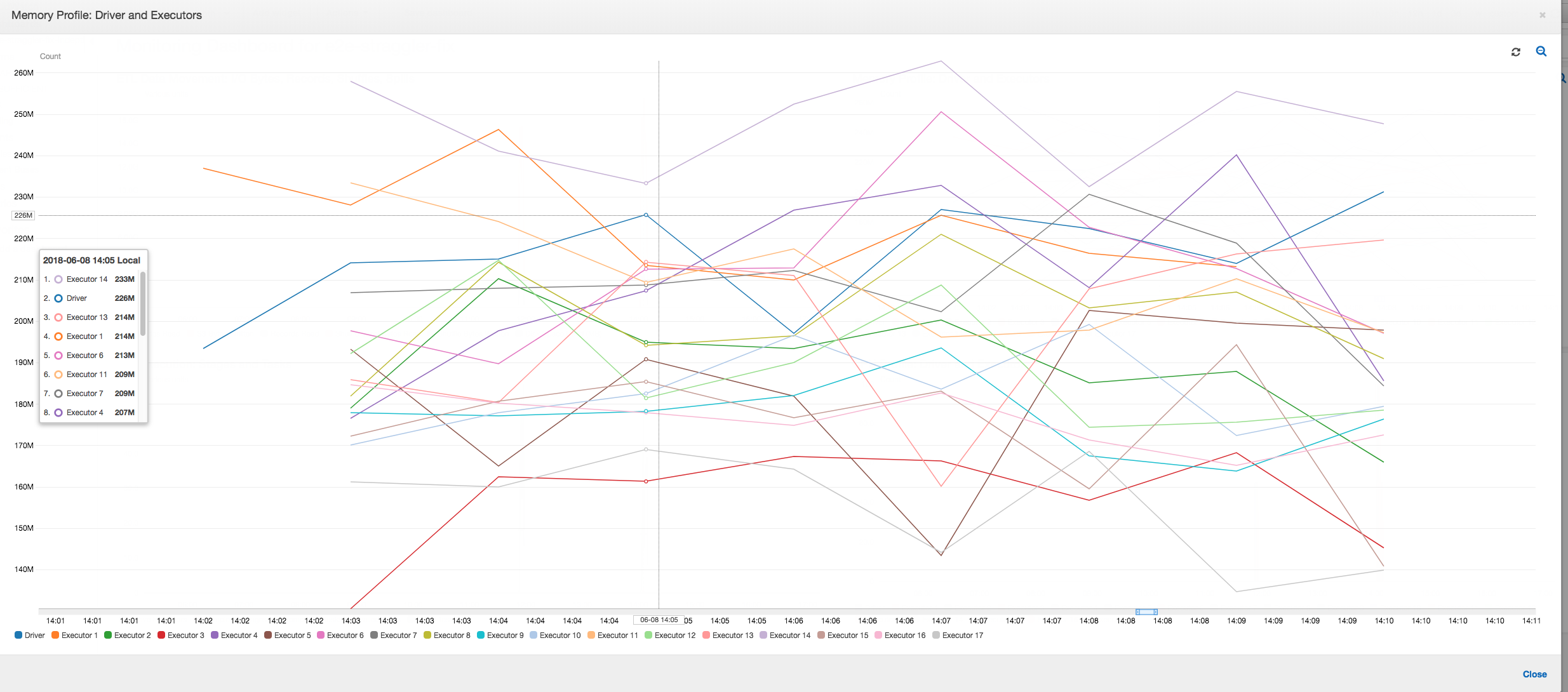
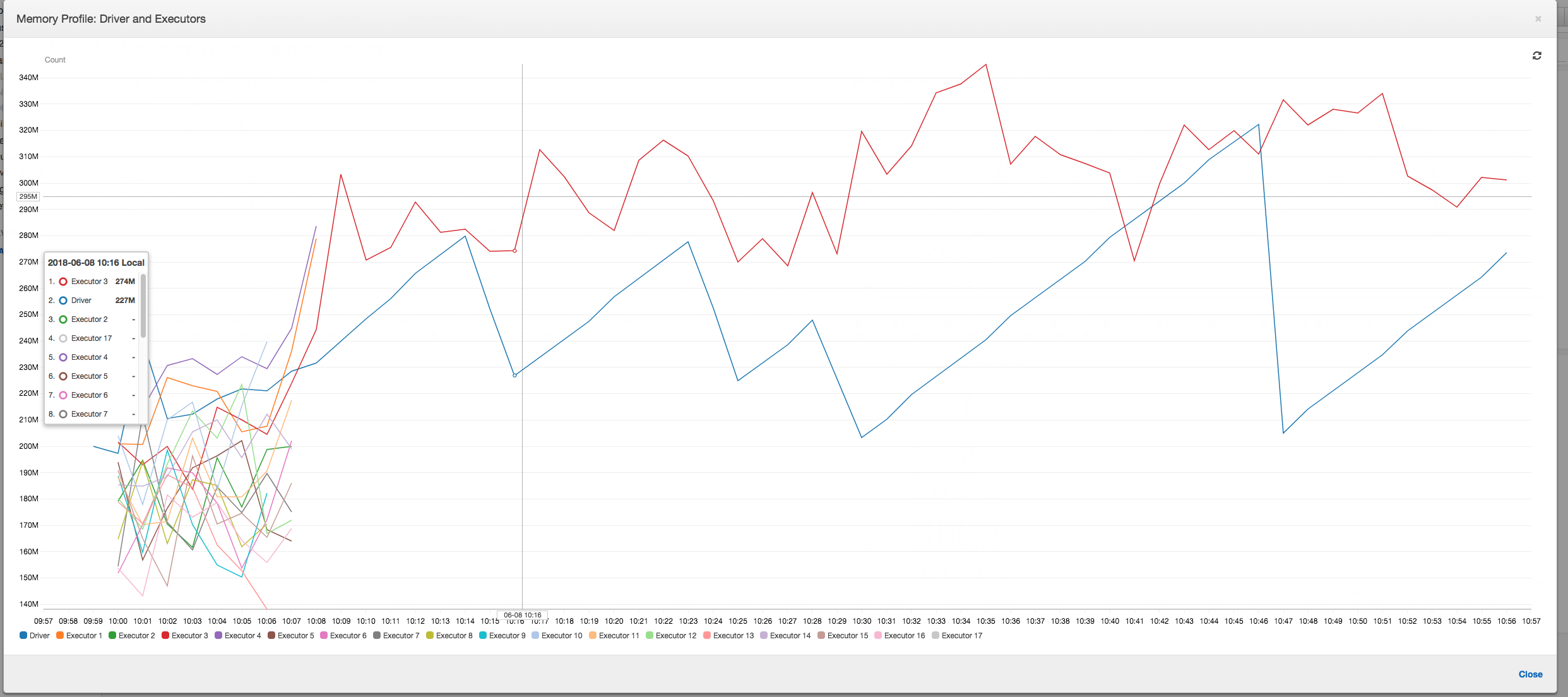
Perfil de memória: após os dois primeiros estágios, apenas o executor número 3 está ativamente consumindo memória para processar os dados. Os executores restantes estão simplesmente ociosos ou foram desativados logo após a conclusão dos dois primeiros estágios.
Corrigir executores retardatários usando agrupamento
Você pode evitar executores retardatários usando o recurso de agrupamento no AWS Glue. Use o agrupamento para distribuir os dados uniformemente em todos os executores e agrupar os arquivos em arquivos maiores usando todos os executores disponíveis no cluster. Para obter mais informações, consulte Ler arquivos de entrada em grupos maiores.
Para verificar as movimentações de dados ETL no AWS Glue, crie o perfil do código a seguir com agrupamento habilitado:
df = glueContext.create_dynamic_frame_from_options("s3", {'paths': ["s3://input_path"], "recurse":True, 'groupFiles': 'inPartition'}, format="json") datasink = glueContext.write_dynamic_frame.from_options(frame = df, connection_type = "s3", connection_options = {"path": output_path}, format = "json", transformation_ctx = "datasink4")
Movimentação de dados ETL: as gravações de dados agora são transmitidas em paralelo com os dados lidos durante todo o tempo de execução do trabalho. Como resultado, o trabalho é concluído em oito minutos, muito mais rápido do que anteriormente.
Embaralhamento de dados em executores: conforme os arquivos de entrada são agrupados durante as leituras usando o recurso de agrupamento, não há embaralhamento de dados dispendioso depois das leituras.
Execução do trabalho: as métricas de execução do trabalho mostram que o número total de executores ativos em execução e o processamento de dados permanece constante. Não há um único retardatário no trabalho. Todos os executores estão ativos e não são desativados até a conclusão do trabalho. Como não há embaralhamento intermediário dos dados nos executores, há somente uma única fase do trabalho.
Perfil de memória: as métricas mostram o consumo de memória ativa em todos os executores, reconfirmando que há atividade em todos eles. À medida que os dados são transmitidos e gravados em paralelo, o total de espaço de memória de todos os executores é aproximadamente uniforme e bem abaixo do limite de segurança para todos os executores.