기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
BDA를 사용하면 특정 요구 사항에 따라 데이터 필드를 분할하고 재구성할 수 있습니다. 이 기능을 사용하면 추출된 데이터를 다운스트림 시스템 또는 분석 요구 사항에 더 잘 맞는 형식으로 변환할 수 있습니다.
대부분의 경우 문서에는 여러 정보를 단일 필드로 결합하는 필드가 포함될 수 있습니다. BDA를 사용하면 이러한 필드를 별도의 개별 필드로 분할하여 데이터 조작 및 분석을 더 쉽게 수행할 수 있습니다. 예를 들어 문서에 사람의 이름이 단일 필드로 포함된 경우 이름, 중간 이름, 성 및 접미사에 대해 별도의 필드로 분할할 수 있습니다.
변환 작업의 경우 값을 정규화해야 하는지 여부에 따라 추출 유형을 명시적 또는 추론으로 정의할 수 있습니다.
| 필드 | 지침 | 추출 유형 | 유형 |
|---|---|---|---|
|
이름 |
이름 |
명시적 |
String |
|
MIDDLE_NAME |
중간 이름 또는 이니셜 |
명시적 |
String |
|
LAST_NAME |
드라이버의 성 |
명시적 |
String |
|
SUFFIX |
PhD, MSc 등의 접미사 |
명시적 |
String |
또 다른 예는 단일 필드로 표시될 수 있는 주소 블록을 사용하는 것입니다.
| 필드 | 지침 | 추출 유형 | 유형 |
|---|---|---|---|
|
거리 |
거리 주소란 무엇입니까? |
명시적 |
String |
|
구/군/시 |
도시란 무엇입니까? |
명시적 |
String |
|
State |
상태는 무엇입니까? |
명시적 |
String |
|
ZipCode |
주소 우편번호란 무엇입니까? |
명시적 |
String |
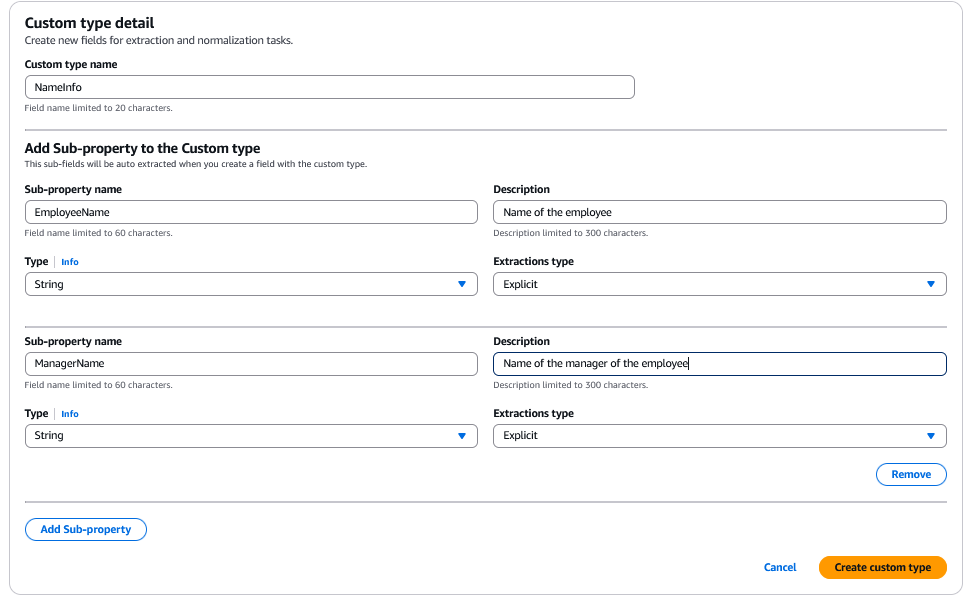
이러한 필드를 완전히 개별 필드로 정의하거나 사용자 지정 유형을 생성할 수 있습니다. 사용자 지정 유형은 다른 필드에 재사용할 수 있는 유형입니다. 아래 예제에서는 'EmployeeName' 및 'ManagerName'에 사용하는 사용자 지정 유형 'NameInfo'를 생성합니다.EmployeeName ManagerName