기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Amazon Bedrock Knowledge Bases는 데이터 저장소에서 정보를 가져와 대규모 언어 모델(LLM)에서 생성된 응답을 보강하는 것으로 널리 사용되는 기술인 검색 증강 생성(RAG)을 활용할 수 있도록 도와줍니다. 데이터 소스로 지식 기반을 설정할 때 애플리케이션은 지식 기반을 쿼리하여 소스의 직접 인용 또는 쿼리 결과에서 생성된 자연 응답을 사용하여 쿼리에 응답하는 정보를 반환할 수 있습니다.
Amazon Bedrock 지식 기반을 사용하면 지식 기반 쿼리에서 수신한 컨텍스트로 보강된 애플리케이션을 구축할 수 있습니다. 복잡한 구축 파이프라인을 축약하고 바로 사용할 수 있는 RAG 솔루션을 제공하여 애플리케이션 빌드 시간을 단축함으로써 출시 시간을 단축할 수 있습니다. 지식 기반을 추가하면 프라이빗 데이터를 활용하기 위해 모델을 지속적으로 학습시킬 필요가 없으므로 비용 효율성도 향상됩니다.
다음 다이어그램은 RAG가 수행되는 방식을 개략적으로 보여 줍니다. 지식 기반은 이 프로세스의 여러 단계를 자동화하여 RAG의 설정 및 구현을 간소화합니다.
비정형 데이터 사전 처리
비정형 프라이빗 데이터(정형 데이터 스토어에 없는 데이터)에서 효과적으로 검색할 수 있도록 하려면 데이터를 텍스트로 변환하고 관리 가능한 부분으로 분할하는 것이 일반적인 방법입니다. 그런 다음 청크는 원본 문서와의 매핑을 유지하면서 임베딩으로 변환되고 벡터 인덱스에 작성됩니다. 이러한 임베딩은 데이터 소스의 쿼리와 텍스트 간의 시맨틱 유사성을 결정하는 데 사용됩니다. 아래 이미지에서는 벡터 데이터베이스의 데이터 사전 처리 과정을 보여줍니다.
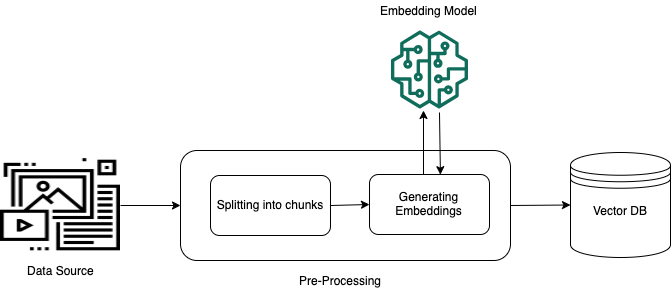
벡터 임베딩은 각 텍스트 청크를 나타내는 일련의 숫자입니다. 모델은 각 텍스트 청크를 벡터라고 하는 일련의 숫자로 변환하므로 텍스트를 수학적으로 비교할 수 있습니다. 이러한 벡터는 부동 소수점 숫자(float32) 또는 바이너리 숫자일 수 있습니다. Amazon Bedrock에서 지원하는 대부분의 임베딩 모델은 기본적으로 부동 소수점 벡터를 사용합니다. 그러나 일부 모델은 바이너리 벡터를 지원합니다. 바이너리 임베딩 모델을 선택하는 경우 바이너리 벡터를 지원하는 모델 및 벡터 스토어도 선택해야 합니다.
차원당 1비트만 사용하는 바이너리 벡터는 차원당 32비트를 사용하는 부동 소수점(float32) 벡터만큼 스토리지 비용이 많이 들지 않습니다. 그러나 이진 벡터는 텍스트 표현에서 부동 소수점 벡터만큼 정확하지 않습니다.
다음 예제에서는 텍스트 조각을 세 가지 표현으로 보여줍니다.
| 표시 | 값 |
|---|---|
| 텍스트 | “Amazon Bedrock은 선도적인 AI 기업과 Amazon의 고성능 파운데이션 모델을 사용합니다.” |
| 부동 소수점 벡터 | [0.041..., 0.056..., -0.018..., -0.012..., -0.020...,
...] |
| 바이너리 벡터 | [1,1,0,0,0, ...] |
런타임 실행
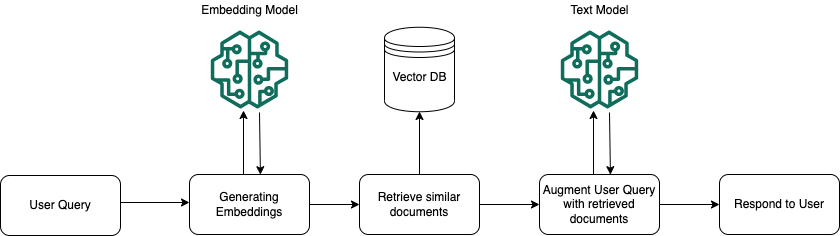
런타임 시 임베딩 모델을 사용하여 사용자 쿼리를 벡터로 변환합니다. 그런 다음, 벡터 인덱스를 쿼리하여 문서 벡터와 사용자 쿼리 벡터를 비교하는 방식으로 사용자 쿼리와 의미상 유사한 문서를 찾습니다. 마지막 단계에서는 벡터 인덱스에서 검색된 청크의 추가 컨텍스트를 사용하여 사용자 프롬프트를 증강합니다. 그런 다음 추가 컨텍스트와 함께 프롬프트가 모델로 전송되어 사용자를 위한 응답을 생성합니다. 아래 이미지에서는 RAG가 런타임 시 어떤 방식으로 작동하여 사용자 쿼리에 대한 응답을 증강하는지 보여줍니다.
데이터를 지식 기반으로 전환하는 방법, 지식 기반을 설정한 후 쿼리하는 방법, 수집 중에 데이터 소스에 적용할 수 있는 사용자 지정에 대해 자세히 알아보려면 다음 주제를 참조하세요.
