Apache Hive メタストアを使用する Amazon S3 内のデータセットをクエリするには、外部 Hive メタストア用の Amazon Athena データコネクタを使用できます。AWS Glue Data Catalog へのメタデータの移行は不要です。Athena マネジメントコンソールでプライベート VPC 内の Hive メタストアと通信する Lambda 関数を設定してから、それをメタストアに接続します。Lambda から Hive メタストアへの接続はプライベート Amazon VPC チャンネルによって保護されており、パブリックインターネットを使用しません。独自の Lambda 関数コードを提供することも、外部 Hive メタストア用の Athena データコネクタのデフォルト実装を使用することもできます。
トピック
機能の概要
外部 Hive メタストア用の Athena データコネクタを使用することで、以下のタスクを実行できます。
-
Athena コンソールを使用して、カスタムカタログを登録し、それらを使用してクエリを実行する。
-
異なる外部 Hive メタストアの Lambda 関数を定義して、Athena クエリでそれらを結合する。
-
AWS Glue Data Catalog と外部 Hive メタストアを同じ Athena クエリで使用する。
-
クエリ実行コンテキストのカタログを現在のデフォルトカタログとして指定する。これにより、クエリのデータベース名にカタログ名のプレフィックスを付ける必要がなくなります。構文
catalog.database.tabledatabase.table -
さまざまなツールを使用して、外部 Hive メタストアを参照するクエリを実行する。これには、Athena コンソール、AWS CLI、AWS SDK、Athena API、更新された Athena JDBC および ODBC ドライバーを使用できます。更新されたドライバーは、カスタムカタログをサポートしています。
API サポート
外部 Hive メタデータ用の Athena データコネクタには、カタログ登録 API オペレーションとメタデータ API オペレーションのサポートが含まれています。
-
カタログ登録 – 外部 Hive メタストアとフェデレーティッドデータソース用のカスタムカタログを登録します。
-
メタデータ – メタデータ API を使用して、AWS Glue と、Athena に登録した任意のカタログのデータベースとテーブル情報を提供します。
-
Athena JAVA SDK クライアント – 更新された Athena Java SDK クライアントのカタログ登録 API、メタデータ API、および
StartQueryExecutionオペレーションでのカタログのサポートを使用します。
リファレンス実装
Athena は、外部 Hive メタストアに接続する Lambda 関数のリファレンス実装を提供します。リファレンス実装は、Athena Hive メタストア
リファレンス実装は、AWS SAM (SAR) で次の 2 つの AWS Serverless Application Repository アプリケーションとして利用できます。これらのアプリケーションのいずれかを SAR で使用して、独自の Lambda 関数を作成できます。
-
AthenaHiveMetastoreFunction– Uber Lambda 関数.jarファイルです。「uber」JAR (fat JAR、または依存関係が含まれる JAR としても知られています) は、Java プログラムとその依存関係の両方を単一のファイルに収めた.jarファイルです。 -
AthenaHiveMetastoreFunctionWithLayer– Lambda レイヤーと thin Lambda 関数.jarファイルです。
ワークフロー
以下の図は、Athena が外部 Hive メタストアとどのようにやり取りするかを説明しています。
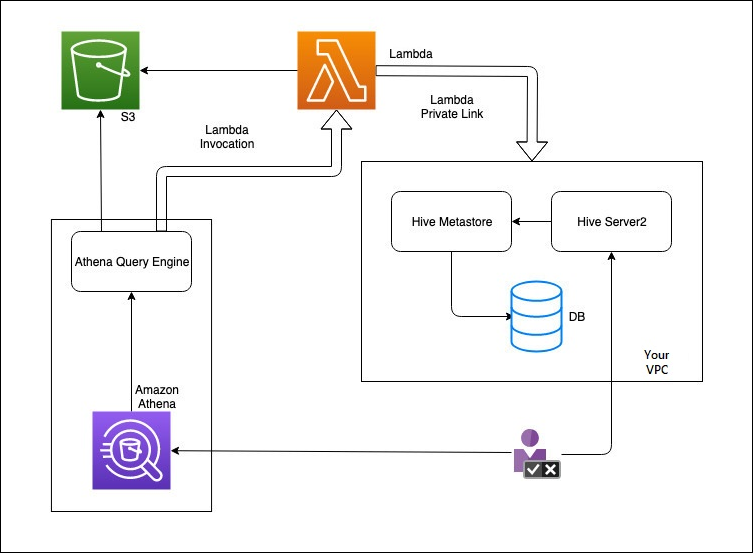
このワークフローでは、データベースに接続された Hive メタストアが VPC 内にあります。Hive Server2 を使用して、Hive CLI を使用して Hive メタストアを管理します。
Athena から外部 Hive メタストアを使用するワークフローには、以下のステップが含まれます。
-
VPC 内の Hive メタストアに Athena を接続する Lambda 関数を作成します。
-
Hive メタストアの一意のカタログ名をアカウントに登録し、対応する関数名を登録します。
-
カタログ名を使用する Athena DML または DDL クエリを実行すると、Athena クエリエンジンがそのカタログ名に関連付けられた Lambda 関数名を呼び出します。
-
AWS PrivateLink を使用すると、Lambda 関数が VPC 内の外部 Hive メタストアと通信し、メタデータリクエストに対する応答を受け取ります。Athena は、デフォルトの AWS Glue Data Catalogからのメタデータを使用する場合と同様に、外部 Hive メタストアからのメタデータを使用します。
考慮事項と制限
外部 Hive メタストア用の Athena データコネクタを使用するときは、以下の点を考慮してください。
-
CTAS を使用して、外部の Hive メタストアにテーブルを作成できます。
-
INSERT INTO を使用して、外部 Hive メタストアにデータを挿入できます。
-
外部 Hive メタストアに対する DDL サポートは、以下のステートメントに限定されています。
-
ALTER DATABASE SET DBPROPERTIES
-
ALTER TABLE ADD COLUMNS
-
ALTER TABLE ADD PARTITION
-
ALTER TABLE DROP PARTITION
-
ALTER TABLE RENAME PARTITION
-
テーブルの変更列の置き換え
-
ALTER TABLE SET LOCATION
-
ALTER TABLE SET TBLPROPERTIES
-
CREATE DATABASE
-
CREATE TABLE
-
CREATE TABLE AS
-
DESCRIBE TABLE
-
DROP DATABASE
-
DROP TABLE
-
SHOW COLUMNS
-
SHOW CREATE TABLE
-
SHOW PARTITIONS
-
SHOW SCHEMAS
-
SHOW TABLES
-
SHOW TBLPROPERTIES
-
-
登録できるカタログの最大数は 1,000 です。
-
Hive メタストアの Kerberos 認証はサポートされていません。
-
外部 Hive メタストア、またはフェデレーティッドクエリで JDBC ドライバーを使用するには、JDBC 接続文字列に
MetadataRetrievalMethod=ProxyAPIを含めます。JDBC ドライバーの詳細については、「JDBC で Amazon Athena に接続する」を参照してください。 -
Hive の非表示列 である
$path、$bucket、$file_size、$file_modified_time、$partition、$row_idはきめ細かいアクセス制御フィルタリングには使用できません。 -
example_table$partitionsexample_table$properties
アクセス許可
構築済みのデータソースコネクタは、正しく機能するために、次のリソースへのアクセスが必要になる場合があります。使用するコネクタの情報をチェックして、VPC が正しく設定されていることを確認します。Athena でクエリを実行してデータソースコネクタを作成するために必要な IAM 許可については、「外部 Hive メタストア用の Athena データコネクタへのアクセスを許可する」および「外部 Hive メタストアへの Lambda 関数アクセスを許可する」を参照してください。
-
Simple Storage Service (Amazon S3) – データコネクタは、Athena のクエリ結果が保存される Amazon S3 内の場所にクエリ結果を書き込むほか、Amazon S3 のスピルバケットにも書き込みます。この Amazon S3 の場所に対する接続と許可が必要です。詳細については、このトピックで後述する「Amazon S3 のスピルの場所」を参照してください。
-
Athena – クエリのステータスをチェックして、オーバースキャンを防止するためのアクセス権が必要です。
-
AWS Glue – コネクタが補足メタデータまたはプライマリメタデータに AWS Glue を使用する場合、アクセス権が必要です。
-
AWS Key Management Service
-
ポリシー – Hive メタストア、Athena Query Federation、および UDF には、AWS 管理ポリシー: AmazonAthenaFullAccess 以外にポリシーが必要です。詳細については、「Athena でのアイデンティティとアクセス権の管理」を参照してください。
Amazon S3 のスピルの場所
Lambda 関数のレスポンスサイズに対する制限のため、しきい値を超えるサイズのレスポンスは、Lambda 関数の作成時に指定する Amazon S3 の場所にスピルされます。Athena は、これらのレスポンスを Amazon S3 から直接読み込みます。
注記
Athena は Amazon S3 上のレスポンスファイルを削除しません。レスポンスファイルを自動的に削除するように保持ポリシーをセットアップすることが推奨されます。
