Amazon Athena HBase コネクタは、Amazon Athena での Apache HBase インスタンスとの通信を可能にし、HBase データを SQL でクエリできるようにします。
従来のリレーショナルデータストアとは異なり、HBase コレクションにはスキーマが設定されていません。HBase にはメタデータストアがありません。HBase コレクションの各エントリには、異なるフィールドとデータ型を設定できます。
HBase コネクタは、テーブルスキーマ情報を生成するために、基本スキーマ推論と AWS Glue Data Catalog メタデータの 2 つのメカニズムをサポートしています。
デフォルトでは、スキーマ推論が選択されます。このオプションは、コレクション内の少数のドキュメントをスキャンし、すべてのフィールドの合併集合を作成して、強制的にフィールドのデータ型が重複しないようにします。このオプションは、ほとんどのエントリが同一であるコレクションに適しています。
より多くのデータ型を持つコレクションに対して、このコネクタでは、AWS Glue Data Catalog からのメタデータの取得をサポートします。HBase 名前空間およびコレクション名と一致する AWS Glue データベースとテーブルがある場合、コネクタは対応する AWS Glue テーブルからスキーマ情報を取得します。AWS Glue テーブルを作成するときは、HBase コレクションからアクセスする可能性のあるすべてのフィールドのスーパーセットにすることをお勧めします。
アカウントで Lake Formation を有効にしている場合、AWS Serverless Application Repository でデプロイした Athena フェデレーション Lambda コネクタの IAM ロールには、Lake Formation での AWS Glue Data Catalog への読み取りアクセス権が必要です。
このコネクタをフェデレーティッドカタログとして Glue データカタログに登録することはできません。このコネクタは、Lake Formation で定義されているデータアクセスコントロールをカタログ、データベース、テーブル、列、行、タグレベルでサポートしていません。このコネクタは、Glue 接続を使用して Glue の設定プロパティを一元管理しています。
前提条件
Athena コンソールまたは AWS Serverless Application Repository を使用して AWS アカウント にコネクタをデプロイします。詳細については、「データソース接続を作成する」または「AWS Serverless Application Repository を使用してデータソースコネクタをデプロイする」を参照してください。
パラメータ
このセクションのパラメータを使用して HBase コネクタを設定します。
注記
2024 年 12 月 3 日以降に作成された Athena データソースコネクタは、AWS Glue 接続を使用します。
以下に示すパラメータ名と定義は、2024 年 12 月 3 日より前に作成された Athena データソースコネクタ用です。これらは、対応する AWS Glue 接続プロパティとは異なる場合があります。2024 年 12 月 3 日以降、以前のバージョンの Athena データソースコネクタを手動でデプロイする場合にのみ、以下のパラメータを使用します。
-
spill_bucket – Lambda 関数の上限を超えたデータに対して、Amazon S3 バケットを指定します。
-
spill_prefix – (オプション) 指定された
athena-federation-spillというspill_bucketの、デフォルトのサブフォルダに設定します。このロケーションで、Amazon S3 のストレージライフサイクルを設定し、あらかじめ決められた日数または時間数以上経過したスピルを削除することをお勧めします。 -
spill_put_request_headers – (オプション) スピリングに使用されるAmazon S3 の
putObjectリクエスト (例:{"x-amz-server-side-encryption" : "AES256"}) に関する、 JSON でエンコードされたリクエストヘッダーと値のマッピング。利用可能な他のヘッダーについては、「Amazon Simple Storage Service API リファレンス」の「PutObject」を参照してください。 -
kms_key_id – (オプション) デフォルトでは、Amazon S3 に送信されるすべてのデータは、AES-GCM で認証された暗号化モードとランダムに生成されたキーを使用して暗号化されます。KMS が生成したより強力な暗号化キー (たとえば
a7e63k4b-8loc-40db-a2a1-4d0en2cd8331) を Lambda 関数に使用させる場合は、KMS キー ID を指定します。 -
disable_spill_encryption – (オプション)
Trueに設定されている場合、スピルに対する暗号化を無効にします。デフォルト値はFalseです。この場合、S3 にスピルされたデータは、AES-GCM を使用して (ランダムに生成されたキー、または KMS により生成したキーにより) 暗号化されます。スピル暗号化を無効にすると、特にスピルされる先でサーバー側の暗号化を使用している場合に、パフォーマンスが向上します。 -
disable_glue – (オプション) これが存在し、true に設定されている場合、コネクタは AWS Glue からの補足メタデータ取得は試みません。
-
glue_catalog – (オプション) クロスアカウントの AWS Glue カタログを指定するために、このオプションを使用します。デフォルトでは、コネクタは自身の AWS Glue アカウントからメタデータを取得しようとします。
-
default_hbase – 存在する場合、カタログ固有の環境変数が存在しない場合に使用する HBase 接続文字列を指定します。
-
enable_case_insensitive_match – (オプション)
trueの場合、HBase 内のテーブル名に対して大文字と小文字を区別しない検索を実行します。デフォルト:false。クエリに大文字のテーブル名が含まれる場合に使用します。
接続文字列の指定
コネクタで使用する HBase インスタンスの HBase 接続の詳細を定義する 1 つまたは複数のプロパティを指定できます。そのためには、Athena で使用するカタログ名と対応した Lambda の環境変数を設定します。例えば、次のクエリを使用して、Athena の 2 つの異なる HBase インスタンスにクエリを実行するとします。
SELECT * FROM "hbase_instance_1".database.tableSELECT * FROM "hbase_instance_2".database.tableこれら 2 つの SQL ステートメントを使用する際には、Lambda 関数 (hbase_instance_1 および hbase_instance_2) に、2 つの環境変数を追加しておく必要があります。それぞれの値は、次の形式の HBase 接続文字列になります。
master_hostname:hbase_port:zookeeper_port
シークレットの使用
オプションで、接続文字列の詳細の一部またはすべての値について、AWS Secrets Manager を使用できます。Athena フェデレーティッドクエリ機能を Secrets Manager で使用するには、Secrets Manager に接続するためのインターネットアクセス
Secrets Manager が提供するシークレット名を接続文字列に入れるために ${my_secret} 構文を使用する場合、コネクタは、シークレット名を Secrets Manager のユーザー名とパスワードの値に置き換えます。
たとえば、hbase_instance_1 で Lambda 環境変数を次の値に設定した場合を考えます。
${hbase_host_1}:${hbase_master_port_1}:${hbase_zookeeper_port_1}
Athena Query Federation SDK は、自動的に hbase_instance_1_creds という名前のシークレットを Secrets Manager から取得しよう試み、取得した値は ${hbase_instance_1_creds} の場所に挿入します。接続文字列の中で、${
} 文字の組み合わせにより囲まれている任意の部分は、Secrets Manager から提供されたシークレットとして認識されます コネクタにより Secrets Manager 内で検出されないシークレット名を指定した場合、コネクタはテキストを置き換えません。
AWS Glue でのデータベースとテーブルのセットアップ
コネクタの組み込みスキーマ推論は、HBase で文字列としてシリアル化された値のみをサポートします (例: String.valueOf(int))。コネクタの組み込みスキーマ推論機能は限られているため、代わりにメタデータに AWS Glue を使用したい場合があるかもしれません。HBase で使用するために AWS Glue テーブルを有効にするには、補足メタデータを供給したい HBase 名前空間とテーブルに一致する名前の AWS Glue データベースとテーブルが必要です。HBase 列ファミリーの命名規則の使用はオプションで、必須ではありません。
補足メタデータのために AWS Glue を使用するには
-
AWS Glue コンソールでテーブルとデータベースを編集する場合は、次のテーブルプロパティを追加します。
hbase-metadata-flag – このプロパティは、補足メタデータのテーブルをコネクタが使用できることを HBase コネクタに示します。
hbase-metadata-flagプロパティがテーブルプロパティのリスト内に存在するのであれば、このhbase-metadata-flagに任意の値を指定することが可能です。-
hbase-native-storage-flag – このフラグを使用して、コネクタでサポートされている 2 つの値のシリアル化モードを切り替えます。デフォルトでは、このフィールドが存在しない場合、コネクタはすべての値が HBase に文字列として格納されていると見なします。そのため、HBase からの
INT、BIGINT、DOUBLEなどのデータ型を文字列として解析しようとします。このフィールドに AWS Glue のテーブルのいずれかの値が設定されている場合、コネクタは「ネイティブ」ストレージモードに切り替わり、次の関数を使用してINT、BIGINT、BIT、およびDOUBLEをバイトとして読み取ろうとします。ByteBuffer.wrap(value).getInt() ByteBuffer.wrap(value).getLong() ByteBuffer.wrap(value).get() ByteBuffer.wrap(value).getDouble()
-
このドキュメントに記載されているとおりに、AWS Glue 用として適切なデータ型を使用しているか確認してください。
列ファミリーのモデリング
Athena HBase コネクタは HBase 列ファミリーをモデル化する 2 つの方法 (family:column のような完全修飾 (フラット) 命名法、または STRUCT オブジェクトの使用) をサポートしています。
STRUCT モデルでは、STRUCT フィールドの名前は列ファミリーと一致し、STRUCT の子要素はファミリーの列の名前と一致するようになっています。ただし、述語プッシュダウンと列指向の読み込みが STRUCT のような複合型ではまだ完全にはサポートされていないので、STRUCT の使用は現時点では推奨されていません。
次の画像は、2 つのアプローチを組み合わせて使用している AWS Glue で設定されたテーブルを示しています。
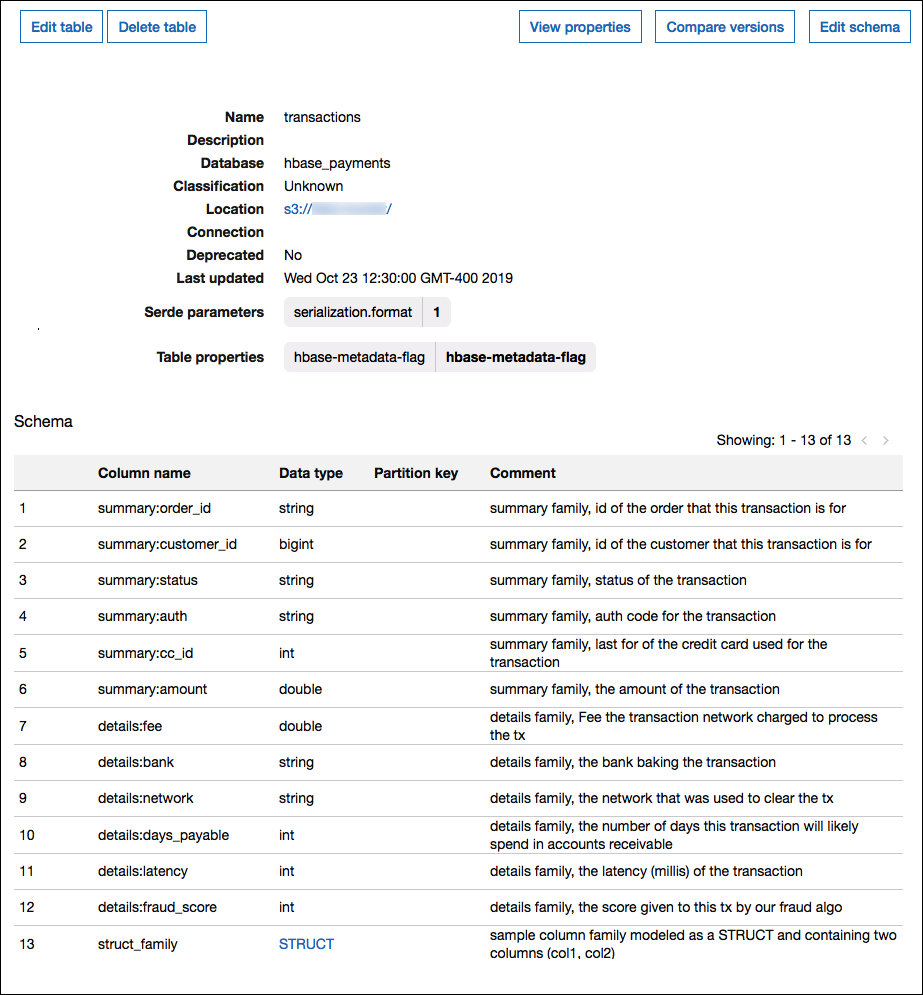
サポートされるデータ型
コネクタはすべての HBase 値を基本バイト型として取得します。次に、AWS Glue データカタログでテーブルをどのように定義したかに基づいて、値を次の表の Apache Arrow データ型の 1 つにマッピングします。
| AWS Glue データ型 | Apache Arrow データ型 |
|---|---|
| 整数 | INT |
| bigint | BIGINT |
| double | FLOAT8 |
| フロート | FLOAT4 |
| ブール値 | BIT |
| バイナリ | VARBINARY |
| string | VARCHAR |
注記
AWS Glue を使用してメタデータを補足しない場合、コネクタのスキーマ推論ではデータ型 BIGINT、FLOAT8、および VARCHAR のみを使用します。
必要な許可
このコネクタが必要とする IAM ポリシーの完全な詳細については、athena-hbase.yamlPolicies セクションを参照してください。次のリストは、必要なアクセス権限をまとめたものです。
-
Amazon S3 への書き込みアクセス – 大規模なクエリからの結果をスピルするために、コネクタは Amazon S3 内のロケーションへの書き込みアクセス権限を必要とします。
-
Athena GetQueryExecution – コネクタはこの権限を使用して、アップストリームの Athena クエリが終了した際に fast-fail を実行します。
-
AWS Glue Data Catalog – HBase コネクタには、スキーマ情報を取得するために AWS Glue Data Catalog への読み込み専用アクセス権が必要です。
-
CloudWatch Logs – コネクタは、ログを保存するために CloudWatch Logs にアクセスする必要があります。
-
AWS Secrets Manager 読み込みアクセス – HBase エンドポイントの詳細を Secrets Manager に保存する場合は、それらのシークレットへのアクセスをコネクタに許可する必要があります。
-
VPC アクセス – コネクタには、VPC に接続して HBase インスタンスと通信できるように、VPC にインターフェイスをアタッチおよびデタッチできることが必要です。
パフォーマンス
Athena HBase コネクタは、各リージョンサーバーを並行して読み込むことによって、HBase インスタンスに対するクエリを並列化しようとします。Athena HBase コネクタは、述語のプッシュダウンを実行して、クエリによってスキャンされるデータを減少させます。
また、Lambda 関数は、クエリがスキャンするデータを削減するために、射影プッシュダウンを実行します。ただし、列のサブセットを選択した場合は、クエリの実行時間が長くなることがあります。LIMIT 句はスキャンされるデータ量を減らしますが、述語を提供しない場合、LIMIT 句を含む SELECT クエリは少なくとも 16 MB のデータをスキャンすることを想定する必要があります。
HBase はクエリに失敗しやすく、クエリの実行時間が変動しやすいです。クエリを正常に実行するために、何度も再試行する必要がある場合があります。HBase コネクタは同時実行によるスロットリングに強いです。
パススルークエリ
HBase コネクタはパススルークエリをサポートしており、NoSQL ベースです。Apache HBase のクエリに関する詳細については、Apache ドキュメントの「Filter language
HBase でパススルークエリを使用するには、以下の構文を使用します。
SELECT * FROM TABLE(
system.query(
database => 'database_name',
collection => 'collection_name',
filter => '{query_syntax}'
))以下の HBase パススルークエリ例は、default データベースの employee コレクション内で 24 歳または 30 歳の従業員をフィルタリングします。
SELECT * FROM TABLE(
system.query(
DATABASE => 'default',
COLLECTION => 'employee',
FILTER => 'SingleColumnValueFilter(''personaldata'', ''age'', =, ''binary:30'')' ||
' OR SingleColumnValueFilter(''personaldata'', ''age'', =, ''binary:24'')'
))ライセンス情報
Amazon Athena HBase コネクタプロジェクトは、Apache-2.0 License
追加リソース
このコネクタに関するその他の情報については、GitHub.com で対応するサイト
