Amazon MSK
このコネクタは、Glue 接続を使用して Glue の設定プロパティを一元化しません。接続設定は Lambda を介して行われます。
前提条件
Athena コンソールまたは AWS Serverless Application Repository を使用して AWS アカウント にコネクタをデプロイします。詳細については、「データソース接続を作成する」または「AWS Serverless Application Repository を使用してデータソースコネクタをデプロイする」を参照してください。
制限
-
DDL の書き込みオペレーションはサポートされていません。
-
関連性のある Lambda 上限値。詳細については、AWS Lambda デベロッパーガイドの Lambda のクォータを参照してください。
-
フィルター条件における日付とタイムスタンプのデータ型は、適切なデータ型にキャストする必要があります。
-
日付とタイムスタンプのデータ型は、CSV ファイルタイプではサポートされていないため、varchar 値として扱われます。
-
ネストされた JSON フィールドへのマッピングはサポートされていません。コネクタは最上位のフィールドのみをマッピングします。
-
コネクタは複合型をサポートしていません。複合型は文字列として解釈されます。
-
複合型の JSON 値を抽出または処理するには、Athena に用意されている JSON 関連の関数を使用してください。詳細については、「文字列から JSON データを抽出する」を参照してください。
-
コネクタは、Kafka メッセージメタデータへのアクセスをサポートしていません。
用語
-
メタデータハンドラー – データベースインスタンスからメタデータを取得する Lambda ハンドラー。
-
レコードハンドラー – データベースインスタンスからデータレコードを取得する Lambda ハンドラー。
-
複合ハンドラー — データベースインスタンスからメタデータとデータレコードの両方を取得する Lambda ハンドラー。
-
Kafka エンドポイント - Kafka インスタンスへの接続を確立するテキスト文字列。
クラスター間の互換性
MSK コネクタは、次のクラスタータイプで使用できます。
-
MSK プロビジョニングクラスター - クラスター容量を手動で指定、監視、スケーリングします。
-
MSK Serverless クラスター - アプリケーション I/O のスケーリングに合わせて自動的にスケーリングされるオンデマンドの容量を提供します。
-
スタンドアロン Kafka - Kafka への直接の接続 (認証または非認証)。
サポートされた認証方法
コネクタでは、次の認証方法がサポートされています。
-
SASL/PLAIN
-
SASL/PLAINTEXT
-
NO_AUTH
詳細については、「Athena MSK コネクタの認証の設定」を参照してください。
対応する入力データ形式
コネクタは、次の入力データ形式をサポートします。
-
JSON
-
CSV
パラメータ
このセクションのパラメータを使用して Athena MSK コネクタを設定します。
-
auth_type - クラスターの認証タイプを指定します。コネクタは、次のタイプの認証をサポートしています。
-
NO_AUTH - 認証なしで Kafka に直接接続します (例えば、認証を使用しない EC2 インスタンスにデプロイされた Kafka クラスターなど)。
-
SASL_SSL_PLAIN - このメソッドは、
SASL_SSLセキュリティプロトコルとPLAINSASL メカニズムを使用します。 -
SASL_PLAINTEXT_PLAIN - このメソッドは、
SASL_PLAINTEXTセキュリティプロトコルとPLAINSASL メカニズムを使用します。注記
SASL_SSL_PLAINおよびSASL_PLAINTEXT_PLAIN認証タイプは、Apache Kafka ではサポートされていますが、Amazon MSK ではサポートされていません。 -
SASL_SSL_AWS_MSK_IAM - Amazon MSK の IAM アクセス制御により、MSK クラスターの認証と承認の両方を処理できます。ユーザーの AWS 認証情報 (シークレットキーとアクセスキー) は、クラスターへの接続に使用されます。詳細については、Amazon Managed Streaming for Apache Kafka デベロッパーガイドの「IAM access control」(IAM アクセスコントロール) を参照してください。
-
SASL_SSL_SCRAM_SHA512 - この認証タイプを使用して Amazon MSK クラスターへのアクセスを制御できます。このメソッドでは、ユーザー名とパスワードを AWS Secrets Manager に保存します。シークレットは Amazon MSK クラスターに関連付けられている必要があります。詳細については、Amazon Managed Streaming for Apache Kafka デベロッパーガイドの「Amazon MSK クラスターの SASL/SCRAM 認証のセットアップ」を参照してください。
-
SSL - SSL 認証では、キーストアとトラストストアのファイルを使用して Amazon MSK クラスターに接続します。トラストストアファイルとキーストアファイルを生成し、それらを Amazon S3 バケットにアップロードして、コネクタをデプロイするときに Amazon S3 への参照を提供する必要があります。キーストア、トラストストア、および SSL キーは AWS Secrets Manager に保存されます。コネクタをデプロイする際に、クライアントは AWS のシークレットキーを提供する必要があります。詳細については、Amazon Managed Streaming for Apache Kafka デベロッパーガイドの「相互 TLS 認証」を参照してください。
詳細については、「Athena MSK コネクタの認証の設定」を参照してください。
-
-
certificates_s3_reference - 証明書 (キーストアとトラストストアのファイル) を含む Amazon S3 の場所。
-
disable_spill_encryption – (オプション)
Trueに設定されている場合、スピルに対する暗号化を無効にします。デフォルト値はFalseです。この場合、S3 にスピルされたデータは、AES-GCM を使用して (ランダムに生成されたキー、または KMS により生成したキーにより) 暗号化されます。スピル暗号化を無効にすると、特にスピルされる先でサーバー側の暗号化を使用している場合に、パフォーマンスが向上します。 -
kafka_endpoint - Kafka に提供するエンドポイントの詳細。例えば、Amazon MSK クラスターの場合、クラスターのブートストラップ URL を指定します。
-
secrets_manager_secret - 認証情報が保存されている AWS シークレットの名前。このパラメータは IAM 認証には必要ありません。
-
スピルパラメータ - Lambda 関数は、メモリに収まらないデータを Amazon S3 に一時的に保存 (「スピル」) します。同一の Lambda 関数によってアクセスされるすべてのデータベースインスタンスは、同じ場所にスピルします。次の表のパラメータを使用して、スピル場所を指定します。
パラメータ 説明 spill_bucket必須。Lambda 関数がデータをスピルできる Amazon S3 バケットの名前。 spill_prefix必須。Lambda 関数がデータをスピルさせることができるスピルバケット内のプリフィックス。 spill_put_request_headers(オプション) スピルに使用される Amazon S3 の putObjectリクエスト (例:{"x-amz-server-side-encryption" : "AES256"}) における、リクエストヘッダーと値に関する JSON でエンコードされたマッピング。利用可能な他のヘッダーについては、「Amazon Simple Storage Service API リファレンス」の「PutObject」を参照してください。
サポートされるデータ型
次の表に、Kafka と Apache Arrow に対応するデータ型を示します。
| Kafka | Arrow |
|---|---|
| CHAR | VARCHAR |
| VARCHAR | VARCHAR |
| TIMESTAMP | ミリ秒 |
| DATE | DAY |
| BOOLEAN | BOOL |
| SMALLINT | SMALLINT |
| INTEGER | INT |
| BIGINT | BIGINT |
| DECIMAL | FLOAT8 |
| DOUBLE | FLOAT8 |
パーティションと分割
Kafka トピックはパーティションに分割されています。各パーティションは順序付けられています。パーティション内の各メッセージには、オフセットと呼ばれるインクリメンタル ID があります。各 Kafka パーティションは、並列処理のためにさらに複数のスプリットに分割されます。データは、Kafka クラスターに設定された保持期間中、利用できます。
ベストプラクティス
ベストプラクティスとして、次の例のように、Athena にクエリを実行するときは、述語プッシュダウンを使用してください。
SELECT *
FROM "msk_catalog_name"."glue_schema_registry_name"."glue_schema_name"
WHERE integercol = 2147483647SELECT *
FROM "msk_catalog_name"."glue_schema_registry_name"."glue_schema_name"
WHERE timestampcol >= TIMESTAMP '2018-03-25 07:30:58.878'MSK コネクタのセットアップ
コネクタを使用する前に、Amazon MSK クラスターをセットアップし、AWS Glue スキーマレジストリを使用してスキーマを定義し、コネクタの認証を設定する必要があります。
注記
プライベートリソースにアクセスするためにコネクタを VPC にデプロイし、Confluent などのパブリックにアクセス可能なサービスにも接続する場合は、NAT ゲートウェイを持つプライベートサブネットにコネクタを関連付ける必要があります。詳細については、Amazon VPC ユーザーガイドの「NAT ゲートウェイ」を参照してください。
AWS Glue スキーマレジストリを使用する際は、次の点に注意してください。
-
AWS Glue スキーマレジストリの [Description] (説明) フィールドのテキストに文字列
{AthenaFederationMSK}が含まれていることを確認してください。このマーカー文字列は、Amazon Athena MSK コネクタで使用する AWS Glue レジストリに必要です。 -
最高のパフォーマンスを得るには、 データベース名とテーブル名には小文字のみを使用してください。大文字と小文字が混在すると、コネクタは大文字と小文字を区別しない検索を実行するため、計算量が多くなります。
Amazon MSK 環境と AWS Glue スキーマレジストリをセットアップするには
-
Amazon MSK 環境をセットアップします。詳細と手順については、Amazon Managed Streaming for Apache Kafka デベロッパーガイドの「Amazon MSK のセットアップ」および「Amazon MSK を使い始める」を参照してください。
-
JSON 形式の Kafka トピック記述ファイル (つまり、そのスキーマ) を AWS Glue スキーマレジストリにアップロードします。詳細については、AWS Glue デベロッパーガイドの「AWS Glue スキーマ登録と連携する」を参照してください。スキーマの例については、次のセクションを参照してください。
スキーマを AWS Glue スキーマレジストリにアップロードする際は、このセクションの例の形式を使用してください。
JSON タイプのスキーマの例
次の例では、AWS Glue スキーマレジストリに作成されるスキーマは、dataFormat の値として json を指定し、topicName の値として datatypejson を使用します。
注記
topicName の値は、Kafka のトピック名と同じ大文字と小文字を使用する必要があります。
{
"topicName": "datatypejson",
"message": {
"dataFormat": "json",
"fields": [
{
"name": "intcol",
"mapping": "intcol",
"type": "INTEGER"
},
{
"name": "varcharcol",
"mapping": "varcharcol",
"type": "VARCHAR"
},
{
"name": "booleancol",
"mapping": "booleancol",
"type": "BOOLEAN"
},
{
"name": "bigintcol",
"mapping": "bigintcol",
"type": "BIGINT"
},
{
"name": "doublecol",
"mapping": "doublecol",
"type": "DOUBLE"
},
{
"name": "smallintcol",
"mapping": "smallintcol",
"type": "SMALLINT"
},
{
"name": "tinyintcol",
"mapping": "tinyintcol",
"type": "TINYINT"
},
{
"name": "datecol",
"mapping": "datecol",
"type": "DATE",
"formatHint": "yyyy-MM-dd"
},
{
"name": "timestampcol",
"mapping": "timestampcol",
"type": "TIMESTAMP",
"formatHint": "yyyy-MM-dd HH:mm:ss.SSS"
}
]
}
}CSV タイプスキーマの例
次の例では、AWS Glue スキーマレジストリに作成されるスキーマは、dataFormat の値として csv を指定し、topicName の値として datatypecsvbulk を使用します。topicName の値は、Kafka のトピック名と同じ大文字と小文字を使用する必要があります。
{
"topicName": "datatypecsvbulk",
"message": {
"dataFormat": "csv",
"fields": [
{
"name": "intcol",
"type": "INTEGER",
"mapping": "0"
},
{
"name": "varcharcol",
"type": "VARCHAR",
"mapping": "1"
},
{
"name": "booleancol",
"type": "BOOLEAN",
"mapping": "2"
},
{
"name": "bigintcol",
"type": "BIGINT",
"mapping": "3"
},
{
"name": "doublecol",
"type": "DOUBLE",
"mapping": "4"
},
{
"name": "smallintcol",
"type": "SMALLINT",
"mapping": "5"
},
{
"name": "tinyintcol",
"type": "TINYINT",
"mapping": "6"
},
{
"name": "floatcol",
"type": "DOUBLE",
"mapping": "7"
}
]
}
}Athena MSK コネクタの認証の設定
Amazon MSK クラスターへの認証には、IAM、SSL、SCRAM、スタンドアロン Kafka など、さまざまな方法を使用できます。
次の表は、コネクタの認証タイプと、それぞれのセキュリティプロトコルおよび SASL メカニズムを示しています。詳細については、「Amazon Managed Streaming for Apache Kafka Developer Guide」の「Authentication and authorization for Apache Kafka APIs」を参照してください。
| auth_type | security.protocol | sasl.mechanism |
|---|---|---|
SASL_SSL_PLAIN |
SASL_SSL |
PLAIN |
SASL_PLAINTEXT_PLAIN |
SASL_PLAINTEXT |
PLAIN |
SASL_SSL_AWS_MSK_IAM |
SASL_SSL |
AWS_MSK_IAM |
SASL_SSL_SCRAM_SHA512 |
SASL_SSL |
SCRAM-SHA-512 |
SSL |
SSL |
該当なし |
注記
SASL_SSL_PLAIN および SASL_PLAINTEXT_PLAIN 認証タイプは、Apache Kafka ではサポートされていますが、Amazon MSK ではサポートされていません。
SASL/IAM
クラスターが IAM 認証を使用する場合、クラスターをセットアップする際にユーザーの IAM ポリシーを設定する必要があります。詳細については、Amazon Managed Streaming for Apache Kafka デベロッパーガイドの「IAM access control」(IAM アクセスコントロール) を参照してください。
この認証タイプを使用するには、コネクタの auth_type Lambda 環境変数を SASL_SSL_AWS_MSK_IAM に設定します。
SSL
クラスターが SSL 認証されている場合、トラストストアとキーストアファイルを生成して Amazon S3 バケットにアップロードする必要があります。コネクタをデプロイする際に、この Amazon S3 リファレンスを提供する必要があります。キーストア、トラストストア、および SSL キーは AWS Secrets Manager に保存されます。コネクタをデプロイする際に、AWS のシークレットキーを提供します。
Secrets Manager でのシークレットの作成については、「AWS Secrets Manager シークレットを作成する」を参照してください。
この認証タイプを使用するには、以下の表の説明どおりに環境変数を設定します。
| パラメータ | 値 |
|---|---|
auth_type |
SSL |
certificates_s3_reference |
証明書を格納する Amazon S3 の場所。 |
secrets_manager_secret |
AWS シークレットキーの名前。 |
Secrets Manager でシークレットを作成した後、Secrets Manager コンソールでそのシークレットを確認できます。
Secrets Manager で自分のシークレットを確認するには
Secrets Manager のコンソール (https://console.aws.amazon.com/secretsmanager/
) を開きます。 -
ナビゲーションペインで [Secrets] (シークレット) を選択します。
-
[Secrets] (シークレット) ページで、自分のシークレットを選択します。
-
自分のシークレットの詳細ページで、[Retrieve secret value] (シークレットの値を取得する) を選択します。
次の画像は、3 組のキー/値のペア (
keystore_password、truststore_password、ssl_key_password) を持つシークレットの例を示しています。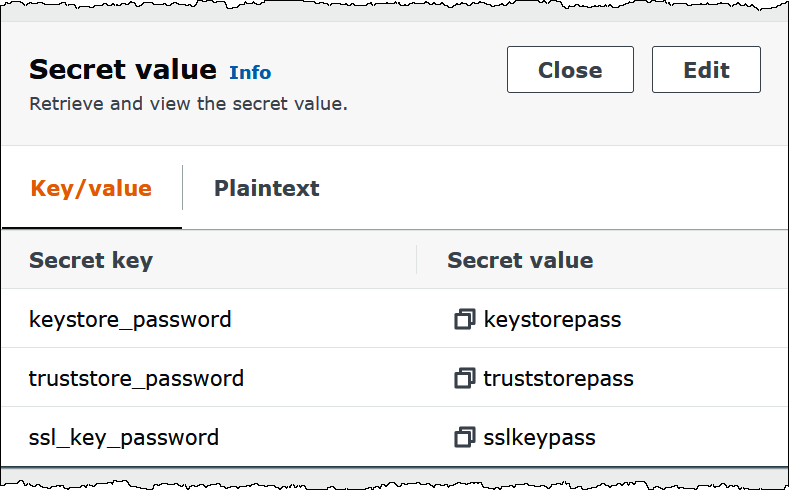
SASL/SCRAM
クラスターが SCRAM 認証を使用している場合は、コネクタをデプロイするときに、クラスターに関連付けられている Secrets Manager キーを指定します。ユーザーの AWS 認証情報 (シークレットキーとアクセスキー) は、クラスターとの認証に使用されます。
下表のように環境変数を設定します。
| パラメータ | 値 |
|---|---|
auth_type |
SASL_SSL_SCRAM_SHA512 |
secrets_manager_secret |
AWS シークレットキーの名前。 |
次の画像は、Secrets Manager コンソールにある 2 つのキー/値のペア (1 つは username 用、もう 1 つは password 用) のシークレットの例を示しています。
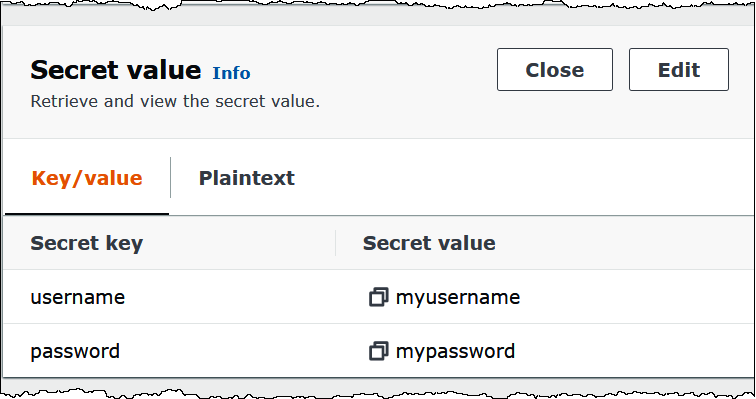
ライセンス情報
このコネクタを使用することにより、pom.xml
追加リソース
このコネクタに関するその他の情報については、GitHub.com で対応するサイト
