Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Aurora Intégrations zéro ETL
Il s’agit d’une solution entièrement gérée qui permet de rendre les données transactionnelles disponibles dans votre destination d’analytique après leur écriture dans un cluster de bases de données Aurora. Le processus d’extraction, transformation et chargement (ETL) consiste à combiner des données provenant de plusieurs sources dans un grand entrepôt de données central.
Une intégration zéro ETL rend les données de votre cluster de bases de données Aurora disponibles dans Amazon Redshift ou un Amazon SageMaker AI Lakehouse en temps quasi réel. Une fois que ces données se trouvent dans l'entrepôt de données ou le lac de données cible, vous pouvez optimiser vos charges de travail d'analyse, de machine learning et d'IA à l'aide des fonctionnalités intégrées, telles que l'apprentissage automatique, les vues matérialisées, le partage de données, l'accès fédéré à plusieurs magasins de données et lacs de données, et les intégrations avec SageMaker Amazon AI, Quick, etc. Services AWS
Pour créer une intégration zéro ETL, vous devez spécifier un cluster de bases de données Aurora comme source et un entrepôt de données ou un lakehouse pris en charge comme cible. L’intégration réplique les données de la base de données source vers l’entrepôt de données ou le lakehouse cible.
Le schéma suivant illustre cette fonctionnalité d’intégration zéro ETL à Amazon Redshift :
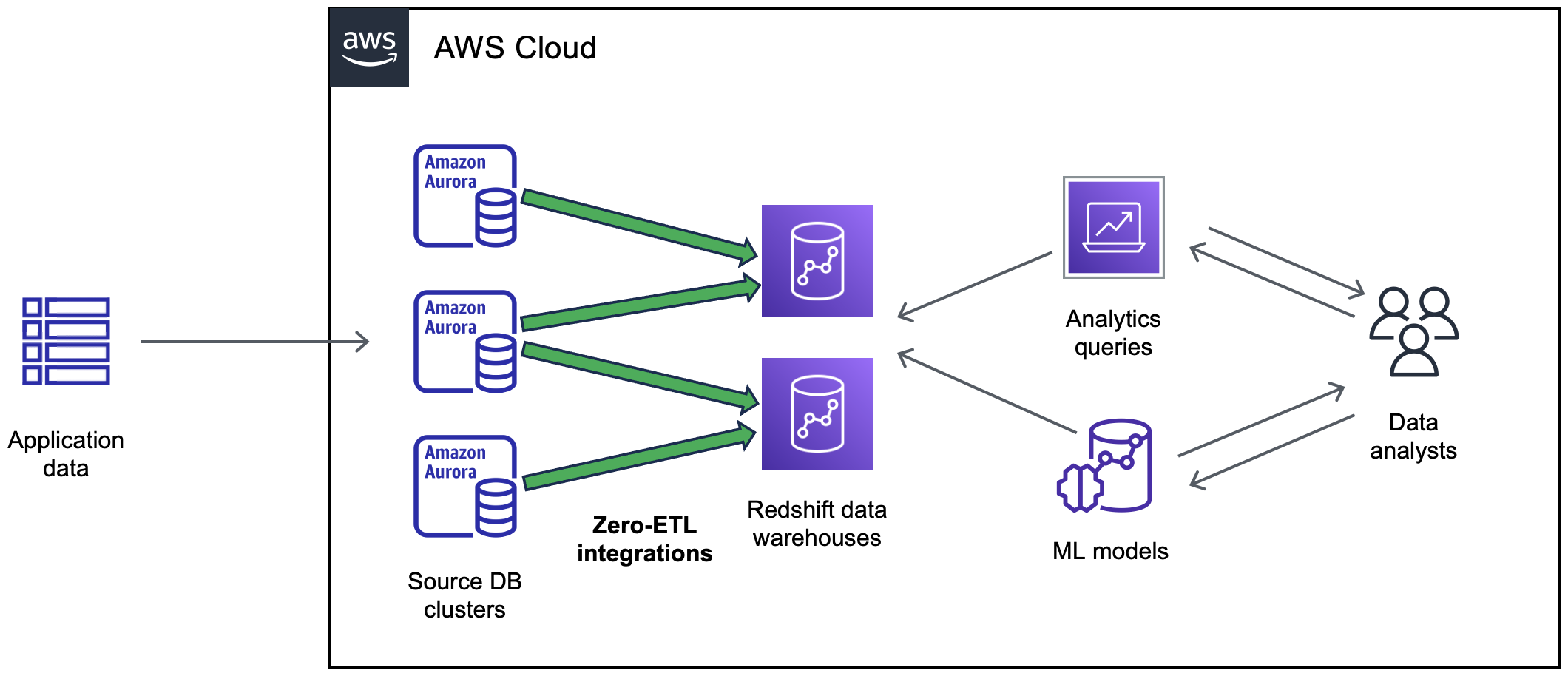
Le schéma suivant illustre cette fonctionnalité pour l’intégration zéro ETL avec un Amazon SageMaker AI Lakehouse :

L’intégration surveille l’état du pipeline de données et effectue la récupération en cas de problèmes, lorsque cela est possible. Vous pouvez créer des intégrations à partir de plusieurs clusters de bases de données Aurora dans un seul entrepôt de données ou lakehouse cible, ce qui vous permet de dériver des informations entre plusieurs applications.
Pour plus d’informations sur la tarification des intégrations zéro ETL, consultez Tarification d’Amazon Aurora
Rubriques
Avantages
Les intégrations zéro ETL Aurora présentent les avantages suivants :
-
Elles vous aident à dériver des informations holistiques de plusieurs sources de données.
-
Éliminez le besoin de créer et de gérer des pipelines de données complexes qui exécutent des opérations d'extraction, de transformation et de chargement (ETL). Zero-ETL les intégrations éliminent les défis liés à la création et à la gestion de pipelines en les provisionnant et en les gérant pour vous.
-
Elles réduisent la charge opérationnelle et les coûts, et vous permettent de vous concentrer sur l'amélioration de vos applications.
-
Elles vous permettent de tirer parti des fonctionnalités d’analytique et de machine learning de la destination cible pour dériver des informations à partir de données transactionnelles et autres, afin de répondre efficacement aux événements critiques et urgents.
Concepts clés
Lorsque vous commencez à utiliser des intégrations zéro ETL, tenez compte des concepts suivants :
- Integration
-
Pipeline de données entièrement géré qui réplique automatiquement les données transactionnelles et les schémas d’un cluster de bases de données Aurora vers un entrepôt de données ou un catalogue.
- Base de données source
-
Cluster de bases de données Aurora à partir d’où les données sont répliquées. Vous pouvez spécifier un cluster de base de données qui utilise des instances de base de données provisionnées ou des Aurora serverless instances de base de données comme source.
- Cible
-
L’entrepôt de données ou le lakehouse vers lequel les données sont répliquées. Il existe deux types d'entrepôts de données : l'entrepôt de données en cluster provisionné et l'entrepôt de données sans serveur. Un entrepôt de données en cluster provisionné est une collection de ressources informatiques appelées nœuds, qui sont organisées en un groupe appelé cluster. Un entrepôt de données sans serveur est composé d'un groupe de travail qui stocke les ressources de calcul et d'un espace de noms qui héberge les utilisateurs et les objets de base de données. Les deux entrepôts de données exécutent un moteur d’analytique et contiennent une ou plusieurs bases de données.
Un lakehouse cible se compose de catalogues, de bases de données, de tables et de vues. Pour plus d’informations sur l’architecture de lakehouse, consultez la section SageMaker Lakehouse components dans le Guide de l’utilisateur Amazon SageMaker AI Unified Studio.
Plusieurs clusters de bases de données sources peuvent écrire sur la même cible.
Pour plus d'informations, consultez Architecture système de l'entrepôt de données dans le Guide du développeur de base de données Amazon Redshift.
Limitations
Les limitations suivantes s’appliquent aux intégrations zéro ETL Aurora.
Rubriques
Limitations générales
-
Le cluster de bases de données source doit se trouver dans la même région que la cible.
-
Vous ne pouvez pas renommer un cluster de bases de données ni aucune de ses instances possédant des intégrations existantes.
-
Vous ne pouvez pas créer plusieurs intégrations entre les mêmes bases de données source et cible.
-
Vous ne pouvez pas supprimer un cluster de bases de données qui possède des intégrations existantes. Vous devez d’abord supprimer toutes les intégrations associées.
-
Si vous arrêtez le cluster de bases de données source, les dernières transactions risquent de ne pas être répliquées vers l’entrepôt de données cible tant que vous ne reprenez pas l’exécution du cluster.
-
Si votre cluster de données est à l'origine d'un blue/green déploiement, les environnements bleu et vert ne peuvent pas comporter d'intégrations zéro ETL existantes lors du passage au numérique. Vous devez d'abord supprimer l'intégration et basculer, puis la recréer.
-
Un cluster de bases de données doit contenir au moins une instance de base de données pour être la source d’une intégration.
-
Vous ne pouvez pas créer d'intégration pour un cluster de base de données source qui est un clone entre comptes, tel que ceux partagés à l'aide de AWS Resource Access Manager (AWS RAM).
-
Si votre cluster source est le cluster de bases de données principal d’une base de données globale Aurora et qu’il bascule sur l’un de ses clusters secondaires, l’intégration devient inactive. Vous devez supprimer et recréer l'intégration.
-
Vous ne pouvez pas créer d’intégration pour une base de données source dont une autre intégration est activement créée.
-
Lors de la création initiale d'une intégration ou lors de la resynchronisation d'une table, l'ensemencement des données de la source vers la cible peut prendre 20 à 25 minutes, voire plus, selon la taille de la base de données source. Ce délai peut entraîner une augmentation du retard de réplica.
-
Certains types de données ne sont pas pris en charge. Pour de plus amples informations, veuillez consulter Différences entre les types de données Aurora et bases de données Amazon Redshift.
-
Les tables système, les tables temporaires et les vues ne sont pas répliquées vers les entrepôts cibles.
-
L’exécution de commandes DDL (par exemple
ALTER TABLE) sur une table source peut déclencher une resynchronisation de la table, rendant la table indisponible pour les requêtes pendant la resynchronisation. Pour de plus amples informations, veuillez consulter Une ou plusieurs de mes tables Amazon Redshift nécessitent une resynchronisation.
Aurora MySQL limites
-
Votre cluster de bases de données source doit exécuter une version prise en charge d’Aurora MySQL. Pour une liste de versions prises en charge, consultez Régions et moteurs de base de données Aurora pris en charge pour les intégration zéro ETL d’Amazon RDS.
-
Zero-ETL les intégrations s'appuient sur la journalisation binaire MySQL (binlog) pour capturer les modifications continues des données. N’utilisez par le filtrage de données basé sur binlog, car cela peut entraîner des incohérences de données entre les bases de données source et cible.
-
Zero-ETL les intégrations ne sont prises en charge que pour les bases de données configurées pour utiliser le moteur de stockage InnoDB.
-
Les références de clé étrangère avec des mises à jour de table prédéfinies ne sont pas prises en charge. Plus précisément, les règles
ON DELETEetON UPDATEne sont pas prises en charge avec les actionsCASCADE,SET NULLetSET DEFAULT. Toute tentative de création ou de mise à jour d'une table contenant de telles références à une autre table entraînera l'échec de la table. -
Les transactions XA
effectuées sur le cluster de bases de données source font passer l’intégration à l’état Syncing.
Limitations relatives à Aurora PostgreSQL
-
Votre cluster de bases de données source doit exécuter une version prise en charge d’Aurora PostgreSQL. Pour une liste de versions prises en charge, consultez Régions et moteurs de base de données Aurora pris en charge pour les intégration zéro ETL d’Amazon RDS.
-
Si vous sélectionnez un cluster de bases de données Aurora PostgreSQL source, vous devez spécifier au moins un modèle de filtre de données. Le modèle doit au minimum inclure une seule base de données (
database-name.*.* -
Toutes les bases de données créées dans le cluster de base de données Aurora PostgreSQL source doivent utiliser le codage. UTF-8
-
Lorsque le partitionnement déclaratif est utilisé, les partitions de table sont répliquées sur Amazon Redshift. Cependant, la table partitionnée elle-même n’est pas répliquée sur Amazon Redshift.
-
Two-phase les transactions
ne sont pas prises en charge. -
Si vous supprimez toutes les instances de base de données d’un cluster de bases de données à l’origine d’une intégration, puis que vous ajoutez à nouveau une instance de base de données, la réplication est interrompue entre les clusters source et cible.
-
Le cluster de bases de données source ne peut pas utiliser la base de données Aurora Limitless.
-
Les clés primaires sont requises sur toutes les tables présentes dans le filtre de données. Toutes les tables dépourvues de clé primaire seront mises en état d’échec.
Limitations propres à Amazon Redshift
Pour une liste des limitations Amazon Redshift liées aux intégrations zéro ETL, consultez la section Considérations relatives au moment d’utiliser les intégrations zéro ETL avec Amazon Redshift dans le Guide de gestion Amazon Redshift.
Amazon SageMaker AI limites du lakehouse
Voici une limite pour les intégrations Amazon SageMaker AI Lakehouse Zero-ETL.
-
Les noms de catalogue sont limités à 19 caractères.
Quotas
Votre compte possède les quotas suivants relatifs aux intégrations zéro ETL Aurora. Chaque quota s'applique par région, sauf indication contraire.
| Nom | Par défaut | Description |
|---|---|---|
| Intégrations | 100 | Nombre total d'intégrations au sein d'un Compte AWS. |
| Intégrations par cible | 50 | Nombre d’intégrations envoyant des données à un entrepôt de données ou un lakehouse cible unique. |
| Intégrations par cluster source | 5 | Nombre d’intégrations envoyant des données à partir d’un cluster de bases de données source unique. |
En outre, l’entrepôt cible impose certaines limites au nombre de tables autorisées dans chaque instance de base de données ou nœud de cluster. Pour plus d’informations sur les quotas et limites relatifs à Amazon Redshift, consultez la section Quotas et limites dans Amazon Redshift dans le Guide de gestion Amazon Redshift.
Régions prises en charge
Les intégrations Aurora Zero-ETL sont disponibles dans un sous-ensemble de. Régions AWS Pour obtenir une liste des régions prises en charge, consultez Régions et moteurs de base de données Aurora pris en charge pour les intégration zéro ETL d’Amazon RDS.
