Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Solution de surveillance de l'infrastructure Amazon EKS avec Amazon Managed Grafana
La surveillance de l'infrastructure Amazon Elastic Kubernetes Service est l'un des scénarios les plus courants pour lesquels Amazon Managed Grafana est utilisé. Cette page décrit un modèle qui fournit une solution pour ce scénario. La solution peut être installée à l'aide AWS Cloud Development Kit (AWS CDK)ou avec Terraform
Cette solution permet de configurer :
-
Votre espace de travail Amazon Managed Service for Prometheus permet de stocker les métriques de votre cluster Amazon EKS et de créer un collecteur géré pour extraire les métriques et les transférer vers cet espace de travail. Pour plus d'informations, voir Ingérer des métriques avec des collecteurs AWS gérés.
-
Collecte de journaux à partir de votre cluster Amazon EKS à l'aide d'un CloudWatch agent. Les journaux sont stockés et interrogés par Amazon Managed Grafana. CloudWatch Pour plus d'informations, consultez la section Journalisation pour Amazon EKS
-
Votre espace de travail Amazon Managed Grafana pour extraire ces journaux et statistiques, et créer des tableaux de bord et des alertes pour vous aider à surveiller votre cluster.
L'application de cette solution créera des tableaux de bord et des alertes qui :
-
Évaluez l'état général du cluster Amazon EKS.
-
Affichez l'état et les performances du plan de contrôle Amazon EKS.
-
Affichez l'état et les performances du plan de données Amazon EKS.
-
Affichez des informations sur les charges de travail Amazon EKS dans les espaces de noms Kubernetes.
-
Affichez l'utilisation des ressources dans les espaces de noms, notamment l'utilisation du processeur, de la mémoire, du disque et du réseau.
À propos de cette solution
Cette solution configure un espace de travail Grafana géré par Amazon afin de fournir des métriques pour votre cluster Amazon EKS. Les métriques sont utilisées pour générer des tableaux de bord et des alertes.
Les métriques vous aident à exploiter les clusters Amazon EKS de manière plus efficace en fournissant des informations sur l'état et les performances du plan de contrôle et de données Kubernetes. Vous pouvez comprendre votre cluster Amazon EKS du niveau du nœud aux pods, en passant par le niveau Kubernetes, y compris la surveillance détaillée de l'utilisation des ressources.
La solution fournit à la fois des capacités d'anticipation et de correction :
-
Les capacités d'anticipation incluent :
-
Gérez l'efficacité des ressources en pilotant les décisions de planification. Par exemple, pour fournir des SLA de performance et de fiabilité à vos utilisateurs internes du cluster Amazon EKS, vous pouvez allouer suffisamment de ressources de processeur et de mémoire à leurs charges de travail sur la base du suivi de l'historique de l'utilisation.
-
Prévisions d'utilisation : en fonction de l'utilisation actuelle des ressources de votre cluster Amazon EKS, telles que les nœuds, les volumes persistants soutenus par Amazon EBS ou les équilibreurs de charge d'application, vous pouvez planifier à l'avance, par exemple pour un nouveau produit ou un nouveau projet présentant des exigences similaires.
-
Détectez rapidement les problèmes potentiels : par exemple, en analysant les tendances de consommation de ressources au niveau de l'espace de noms Kubernetes, vous pouvez comprendre le caractère saisonnier de l'utilisation de la charge de travail.
-
-
Les capacités correctives incluent :
-
Réduisez le délai moyen de détection (MTTD) des problèmes sur l'infrastructure et le niveau de charge de travail de Kubernetes. Par exemple, en consultant le tableau de bord de résolution des problèmes, vous pouvez rapidement tester des hypothèses sur ce qui s'est mal passé et les éliminer.
-
Déterminez où le problème se produit dans la pile. Par exemple, le plan de contrôle Amazon EKS est entièrement géré par AWS et certaines opérations, telles que la mise à jour d'un déploiement Kubernetes, peuvent échouer si le serveur d'API est surchargé ou si la connectivité est affectée.
-
L'image suivante montre un exemple du dossier du tableau de bord de la solution.
Vous pouvez choisir un tableau de bord pour obtenir plus de détails. Par exemple, si vous choisissez d'afficher les ressources de calcul pour les charges de travail, un tableau de bord, tel que celui illustré dans l'image suivante, s'affichera.
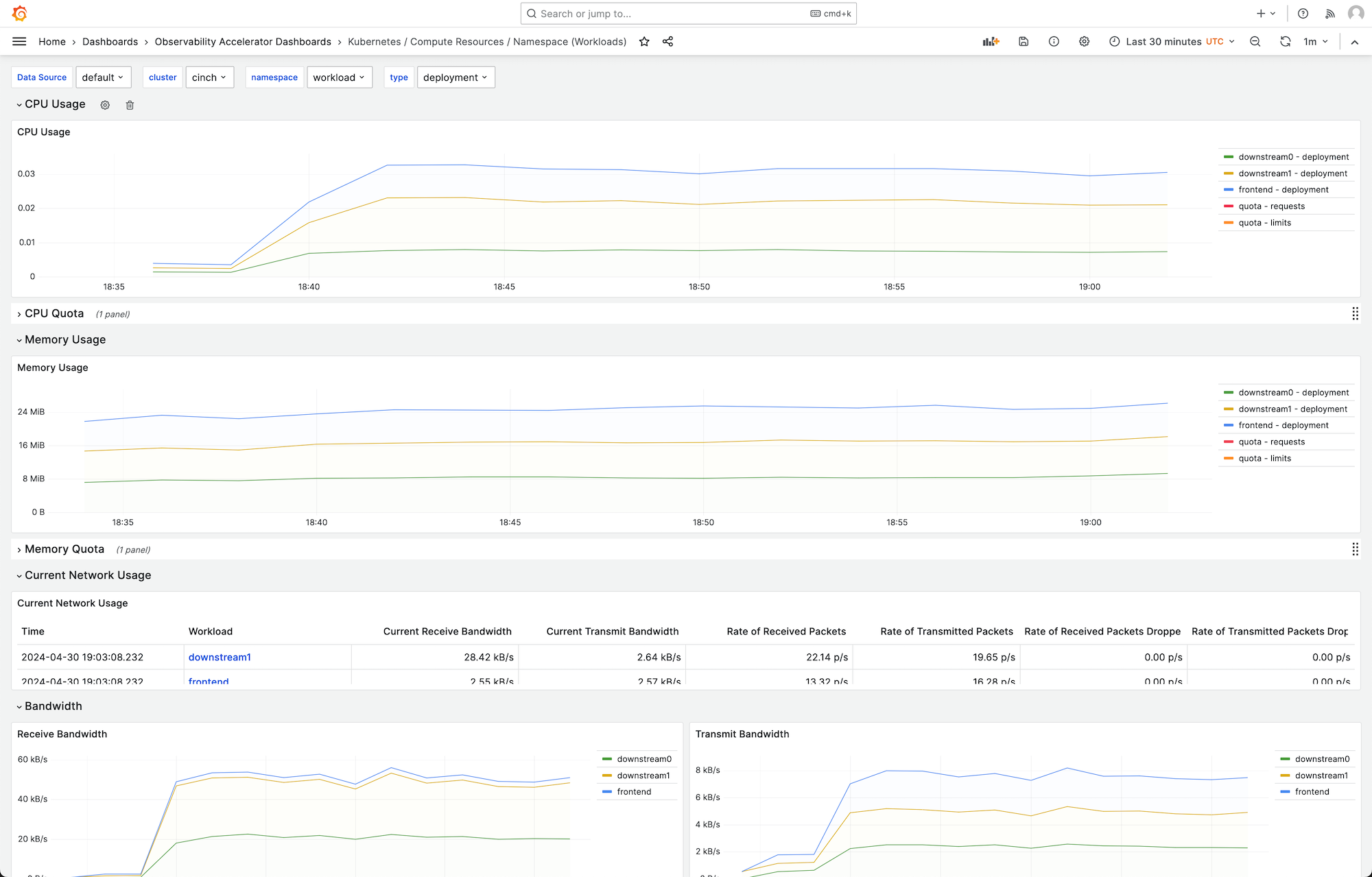
Les métriques sont extraites avec un intervalle d'une minute. Les tableaux de bord affichent des statistiques agrégées à 1 minute, 5 minutes ou plus, en fonction de la métrique spécifique.
Les journaux sont également affichés dans des tableaux de bord, afin que vous puissiez les interroger et les analyser afin de trouver les causes profondes des problèmes. L'image suivante montre un tableau de bord de journal.
Pour obtenir la liste des mesures suivies par cette solution, consultezListe des indicateurs suivis.
Pour obtenir la liste des alertes créées par la solution, consultezListe des alertes créées.
Coûts
Cette solution crée et utilise des ressources dans votre espace de travail. L'utilisation standard des ressources créées vous sera facturée, notamment :
-
Accès des utilisateurs à l'espace de travail de Grafana géré par Amazon. Pour plus d'informations sur les tarifs, consultez les tarifs d'Amazon Managed Grafana
. -
Ingestion et stockage des métriques Amazon Managed Service for Prometheus, y compris l'utilisation du collecteur sans agent Amazon Managed Service for Prometheus, et l'analyse métrique (traitement des échantillons de requêtes). Le nombre de métriques utilisées par cette solution dépend de la configuration et de l'utilisation du cluster Amazon EKS.
Vous pouvez consulter les statistiques d'ingestion et de stockage dans Amazon Managed Service for Prometheus à CloudWatch l'aide de Pour plus d'informations, CloudWatchconsultez le guide de l'utilisateur d'Amazon Managed Service for Prometheus.
Vous pouvez estimer le coût à l'aide du calculateur de prix sur la page de tarification d'Amazon Managed Service for Prometheus
. Le nombre de métriques dépendra du nombre de nœuds de votre cluster et des métriques produites par vos applications. -
CloudWatch Ingestion, stockage et analyse des journaux. Par défaut, la durée de conservation des journaux est définie pour ne jamais expirer. Vous pouvez l'ajuster dans CloudWatch. Pour plus d'informations sur les tarifs, consultez Amazon CloudWatch Pricing
. -
Coûts de mise en réseau. Des frais AWS réseau standard peuvent vous être facturés pour le trafic entre les zones de disponibilité, les régions ou tout autre trafic.
Les calculateurs de prix, disponibles sur la page de tarification de chaque produit, peuvent vous aider à comprendre les coûts potentiels de votre solution. Les informations suivantes peuvent vous aider à obtenir un coût de base pour la solution exécutée dans la même zone de disponibilité que le cluster Amazon EKS.
| Produit (langue française non garantie) | Métrique du calculateur | Value |
|---|---|---|
Amazon Managed Service for Prometheus |
Série Active |
8000 (base) 15 000 (par nœud) |
Intervalle de collecte moyen |
60 (secondes) |
|
Amazon Managed Service pour Prometheus (collecteur géré) |
Nombre de collecteurs |
1 |
Nombre d'échantillons |
15 (base) 150 (par nœud) |
|
Nombre de règles |
161 |
|
Intervalle moyen d'extraction des règles |
60 (secondes) |
|
Amazon Managed Grafana |
Nombre de personnes actives editors/administrators |
1 (ou plus, en fonction de vos utilisateurs) |
CloudWatch (Journaux) |
Journaux standard : données ingérées |
24,5 Go (base) 0,5 Go (par nœud) |
Journal Storage/Archival (journaux standard et vendus) |
Oui au stockage des journaux : en supposant une conservation d'un mois |
|
Données de journaux attendues scannées |
Chaque requête d'information sur les journaux de Grafana analysera tout le contenu des journaux du groupe au cours de la période spécifiée. |
Ces numéros sont les numéros de base d'une solution exécutant EKS sans logiciel supplémentaire. Cela vous donnera une estimation des coûts de base. Cela exclut également les coûts d'utilisation du réseau, qui varient selon que l'espace de travail Amazon Managed Grafana, l'espace de travail Amazon Managed Service for Prometheus et le cluster Amazon EKS se trouvent dans la même zone de disponibilité, et le VPN. Région AWS
Note
Lorsqu'un élément de ce tableau inclut une (base) valeur et une valeur par ressource (par exemple,(per node)), vous devez ajouter la valeur de base à la valeur par ressource multipliée par le nombre que vous avez de cette ressource. Par exemple, pour Average des séries chronologiques actives, entrez un nombre qui est8000 + the number of nodes in your cluster * 15,000. Si vous avez 2 nœuds, vous devez entrer38,000, c'est-à-dire8000 + ( 2 * 15,000 ).
Conditions préalables
Cette solution nécessite que vous ayez effectué les opérations suivantes avant de l'utiliser.
-
Vous devez avoir ou créer un cluster Amazon Elastic Kubernetes Service que vous souhaitez surveiller, et le cluster doit comporter au moins un nœud. L'accès au point de terminaison du serveur API doit être configuré pour inclure l'accès privé (il peut également autoriser l'accès public).
Le mode d'authentification doit inclure l'accès à l'API (il peut être défini sur l'un
APIou l'autreAPI_AND_CONFIG_MAP). Cela permet au déploiement de la solution d'utiliser des entrées d'accès.Les éléments suivants doivent être installés dans le cluster (vrai par défaut lors de la création du cluster via la console, mais doivent être ajoutés si vous créez le cluster à l'aide de l' AWS API ou AWS CLI) : AWS CNI, CoreDNS et. Kube-proxy AddOns
Enregistrez le nom du cluster pour le spécifier ultérieurement. Cela se trouve dans les détails du cluster dans la console Amazon EKS.
Note
Pour en savoir plus sur la création d'un cluster Amazon EKS, consultez Getting started with Amazon EKS.
-
Vous devez créer un espace de travail Amazon Managed Service for Prometheus identique à celui de votre cluster Compte AWS Amazon EKS. Pour plus de détails, consultez la section Créer un espace de travail dans le guide de l'utilisateur d'Amazon Managed Service for Prometheus.
Enregistrez l'ARN de l'espace de travail Amazon Managed Service for Prometheus pour le spécifier ultérieurement.
-
Vous devez créer un espace de travail Amazon Managed Grafana avec la version 9 ou une version ultérieure de Grafana, au même titre que Région AWS votre cluster Amazon EKS. Pour plus de détails sur la création d'un nouvel espace de travail, consultezCréation d'un espace de travail Grafana géré par Amazon.
Le rôle de l'espace de travail doit disposer des autorisations nécessaires pour accéder à Amazon Managed Service for Prometheus et CloudWatch aux API Amazon. Le moyen le plus simple de le faire est d'utiliser Service-managedles autorisations et de sélectionner Amazon Managed Service pour Prometheus et. CloudWatch Vous pouvez également ajouter manuellement les AmazonGrafanaCloudWatchAccesspolitiques AmazonPrometheusQueryAccesset au rôle IAM de votre espace de travail.
Enregistrez l'identifiant et le point de terminaison de l'espace de travail Amazon Managed Grafana pour les spécifier ultérieurement. L'identifiant se trouve dans le formulaire
g-123example. L'ID et le point de terminaison se trouvent dans la console Amazon Managed Grafana. Le point de terminaison est l'URL de l'espace de travail et inclut l'ID. Par exemple,https://g-123example.grafana-workspace.<region>.amazonaws.com/. -
Si vous déployez la solution avec Terraform, vous devez créer un compartiment Amazon S3 accessible depuis votre compte. Cela sera utilisé pour stocker les fichiers d'état Terraform pour le déploiement.
Enregistrez l'ID du compartiment Amazon S3 pour le spécifier ultérieurement.
-
Pour consulter les règles d'alerte Amazon Managed Service for Prometheus, vous devez activer les alertes Grafana pour l'espace de travail Amazon Managed Grafana.
En outre, Amazon Managed Grafana doit disposer des autorisations suivantes pour vos ressources Prometheus. Vous devez les ajouter aux politiques gérées par le service ou aux politiques gérées par le client décrites dans Autorisations et politiques d'Amazon Managed Grafana pour les sources de données AWS.
aps:ListRulesaps:ListAlertManagerSilencesaps:ListAlertManagerAlertsaps:GetAlertManagerStatusaps:ListAlertManagerAlertGroupsaps:PutAlertManagerSilencesaps:DeleteAlertManagerSilence
Note
Bien que cela ne soit pas strictement obligatoire pour configurer la solution, vous devez configurer l'authentification des utilisateurs dans votre espace de travail Amazon Managed Grafana avant que les utilisateurs puissent accéder aux tableaux de bord créés. Pour de plus amples informations, veuillez consulter Authentifier les utilisateurs dans les espaces de travail Amazon Managed Grafana.
Utilisation de cette solution
Cette solution configure AWS l'infrastructure pour prendre en charge les métriques de reporting et de surveillance à partir d'un cluster Amazon EKS. Vous pouvez l'installer en utilisant l'un ou l'autre AWS Cloud Development Kit (AWS CDK)ou avec Terraform
Liste des indicateurs suivis
Cette solution crée un scraper qui collecte les métriques de votre cluster Amazon EKS. Ces statistiques sont stockées dans Amazon Managed Service for Prometheus, puis affichées dans les tableaux de bord Amazon Managed Grafana. Par défaut, le scraper collecte toutes les Prometheus-compatible métriques exposées par le cluster. L'installation d'un logiciel dans votre cluster qui produit davantage de métriques augmentera les métriques collectées. Si vous le souhaitez, vous pouvez réduire le nombre de métriques en mettant à jour le scraper avec une configuration qui filtre les métriques.
Les métriques suivantes sont suivies avec cette solution, dans une configuration de cluster Amazon EKS de base sans logiciel supplémentaire installé.
| Métrique | Description/Objectif |
|---|---|
|
|
Jauge des services API marqués comme indisponibles, ventilée par nom d'API. |
|
|
Histogramme de latence du webhook d'admission en secondes, identifié par son nom et ventilé pour chaque opération, ressource d'API et type (validation ou admission). |
|
|
Nombre maximal de demandes en vol actuellement utilisées (limite de ce serveur d'API) par type de demande au cours de la dernière seconde. |
|
|
Pourcentage des emplacements de cache actuellement occupés par les DEK mis en cache. |
|
|
Nombre de demandes lors de la phase d'exécution initiale (pour un WATCH) ou de toute autre étape (pour une étape non WATCH) dans le sous-système API Priority and Fairness. |
|
|
Nombre de demandes rejetées lors de la phase d'exécution initiale (pour un WATCH) ou de toute autre étape (pour une étape non WATCH) dans le sous-système API Priority and Fairness. |
|
|
Nombre nominal de sièges d'exécution configurés pour chaque niveau de priorité. |
|
|
L'histogramme segmenté de la durée de l'étape initiale (pour un WATCH) ou de toute étape (pour une étape non WATCH) d'exécution des demandes dans le sous-système API Priority and Fairness. |
|
|
Le nombre d'étapes initiales (pour un WATCH) ou de toute étape (pour un non-WATCH) d'exécution des demandes dans le sous-système API Priority and Fairness. |
|
|
Indique une demande de serveur d'API. |
|
|
Jauge des API obsolètes qui ont été demandées, ventilées par groupe d'API, version, ressource, sous-ressource et removed_release. |
|
|
Distribution de la latence de réponse en secondes pour chaque verbe, valeur d'essai, groupe, version, ressource, sous-ressource, portée et composant. |
|
|
L'histogramme segmenté de la distribution de la latence de réponse en secondes pour chaque verbe, valeur d'essai, groupe, version, ressource, sous-ressource, portée et composant. |
|
|
Distribution de la latence de réponse en fonction de l'objectif de niveau de service (SLO) en secondes pour chaque verbe, valeur d'exécution à sec, groupe, version, ressource, sous-ressource, étendue et composant. |
|
|
Nombre de demandes auxquelles apiserver a mis fin en état de légitime défense. |
|
|
Le compteur de requêtes apiserver est ventilé pour chaque verbe, valeur d'exécution à sec, groupe, version, ressource, étendue, composant et code de réponse HTTP. |
|
|
Temps de processeur cumulé consommé. |
|
|
Nombre cumulé d'octets lus. |
|
|
Nombre cumulé de lectures effectuées. |
|
|
Nombre cumulé d'octets écrits. |
|
|
Nombre cumulé d'écritures effectuées. |
|
|
Mémoire cache totale des pages. |
|
|
Taille du flux RSS. |
|
|
Utilisation de l'échange de conteneurs. |
|
|
Set de travail actuel. |
|
|
Nombre cumulé d'octets reçus. |
|
|
Nombre cumulé de paquets abandonnés lors de la réception. |
|
|
Nombre cumulé de paquets reçus. |
|
|
Nombre cumulé d'octets transmis. |
|
|
Nombre cumulé de paquets abandonnés lors de la transmission. |
|
|
Nombre cumulé de paquets transmis. |
|
|
L'histogramme en compartiments de la latence des demandes etcd en secondes pour chaque opération et type d'objet. |
|
|
Nombre de goroutines qui existent actuellement. |
|
|
Nombre de threads du système d'exploitation créés. |
|
|
L'histogramme segmenté de la durée en secondes pour les opérations de cgroup manager. Décomposé par méthode. |
|
|
Durée en secondes pour les opérations du cgroup manager. Décomposé par méthode. |
|
|
Cette métrique est vraie (1) si le nœud rencontre une erreur liée à la configuration, fausse (0) dans le cas contraire. |
|
|
Le nom du nœud. Le décompte est toujours de 1. |
|
|
L'histogramme segmenté de la durée en secondes pour la remise en vente des pods dans PLEG. |
|
|
Durée en secondes de remise en vente de pods dans PLEG. |
|
|
L'histogramme segmenté de l'intervalle en secondes entre les remises en vente dans PLEG. |
|
|
Le nombre de secondes entre le moment où Kubelet voit un pod pour la première fois et celui où le pod commence à fonctionner. |
|
|
L'histogramme segmenté de la durée en secondes pour synchroniser un seul pod. Répartie par type d'opération : création, mise à jour ou synchronisation. |
|
|
Durée en secondes nécessaire à la synchronisation d'un seul pod. Répartie par type d'opération : création, mise à jour ou synchronisation. |
|
|
Nombre de conteneurs actuellement en service. |
|
|
Nombre de pods équipés d'un bac à sable fonctionnel. |
|
|
L'histogramme segmenté de la durée en secondes des opérations d'exécution. Réparti par type d'opération. |
|
|
Nombre cumulé d'erreurs d'exécution par type d'opération. |
|
|
Nombre cumulé d'opérations d'exécution par type d'opération. |
|
|
La quantité de ressources allouables aux pods (après en avoir réservé une partie aux démons du système). |
|
|
La quantité totale de ressources disponibles pour un nœud. |
|
|
Le nombre de ressources limites demandées par un conteneur. |
|
|
Le nombre de ressources limites demandées par un conteneur. |
|
|
Le nombre de ressources de demande demandées par un conteneur. |
|
|
Le nombre de ressources de demande demandées par un conteneur. |
|
|
Informations sur le propriétaire du Pod. |
|
|
Les quotas de ressources dans Kubernetes imposent des limites d'utilisation aux ressources telles que le processeur, la mémoire et le stockage au sein des espaces de noms. |
|
|
Les mesures d'utilisation du processeur pour un nœud, y compris l'utilisation par cœur et l'utilisation totale. |
|
|
Les processeurs ont passé quelques secondes dans chaque mode. |
|
|
Temps cumulé passé par un nœud à effectuer I/O des opérations sur le disque. |
|
|
Temps total passé par le nœud à effectuer I/O des opérations sur le disque. |
|
|
Nombre total d'octets lus sur le disque par le nœud. |
|
|
Nombre total d'octets écrits sur le disque par le nœud. |
|
|
Quantité d'espace disponible en octets sur le système de fichiers d'un nœud d'un cluster Kubernetes. |
|
|
Taille totale du système de fichiers sur le nœud. |
|
|
Charge moyenne sur 1 minute de l'utilisation du processeur d'un nœud. |
|
|
Charge moyenne sur 15 minutes de l'utilisation du processeur d'un nœud. |
|
|
Charge moyenne sur 5 minutes de l'utilisation du processeur d'un nœud. |
|
|
Quantité de mémoire utilisée pour la mise en cache de la mémoire tampon par le système d'exploitation du nœud. |
|
|
Quantité de mémoire utilisée pour la mise en cache du disque par le système d'exploitation du nœud. |
|
|
La quantité de mémoire disponible pour les applications et les caches. |
|
|
La quantité de mémoire libre disponible sur le nœud. |
|
|
La quantité totale de mémoire physique disponible sur le nœud. |
|
|
Nombre total d'octets reçus sur le réseau par le nœud. |
|
|
Nombre total d'octets transmis sur le réseau par le nœud. |
|
|
Temps total passé par l'utilisateur et le processeur du système en secondes. |
|
|
Taille de la mémoire résidente en octets. |
|
|
Nombre de requêtes HTTP, partitionnées par code d'état, méthode et hôte. |
|
|
L'histogramme segmenté de la latence des demandes en secondes. Décomposé par verbe et par hôte. |
|
|
L'histogramme en compartiments de la durée des opérations de stockage. |
|
|
Le décompte de la durée des opérations de stockage. |
|
|
Nombre cumulé d'erreurs lors des opérations de stockage. |
|
|
Une métrique indiquant si la cible surveillée (par exemple, le nœud) est opérationnelle. |
|
|
Nombre total de volumes gérés par le gestionnaire de volumes. |
|
|
Nombre total d'ajouts gérés par la file d'attente. |
|
|
Profondeur actuelle de la file d'attente de travail. |
|
|
L'histogramme en compartiments indiquant le temps en secondes pendant lequel un élément reste dans la file d'attente avant d'être demandé. |
|
|
L'histogramme en compartiments indiquant le temps en secondes nécessaire au traitement d'un élément de la file d'attente de travail. |
Liste des alertes créées
Les tableaux suivants répertorient les alertes créées par cette solution. Les alertes sont créées sous forme de règles dans Amazon Managed Service for Prometheus et affichées dans votre espace de travail Amazon Managed Grafana.
Vous pouvez modifier les règles, notamment en ajouter ou en supprimer, en modifiant le fichier de configuration des règles dans votre espace de travail Amazon Managed Service for Prometheus.
Ces deux alertes sont des alertes spéciales qui sont traitées légèrement différemment des alertes classiques. Au lieu de vous avertir d'un problème, ils vous fournissent des informations qui sont utilisées pour surveiller le système. La description inclut des détails sur l'utilisation de ces alertes.
| Alerte | Description et utilisation |
|---|---|
|
Il s'agit d'une alerte destinée à garantir que l'ensemble du pipeline d'alertes est fonctionnel. Cette alerte est toujours déclenchée, elle doit donc toujours être déclenchée dans Alertmanager et toujours être déclenchée contre un récepteur. Vous pouvez l'intégrer à votre mécanisme de notification pour envoyer une notification lorsque cette alerte ne se déclenche pas. Par exemple, vous pouvez utiliser l'DeadMansSnitchintégration dans PagerDuty. |
|
Il s'agit d'une alerte qui est utilisée pour inhiber les alertes d'information. En elles-mêmes, les alertes au niveau des informations peuvent être très bruyantes, mais elles sont pertinentes lorsqu'elles sont combinées à d'autres alertes. Cette alerte se déclenche en cas d' |
Les alertes suivantes vous fournissent des informations ou des avertissements concernant votre système.
| Alerte | Sévérité | Description |
|---|---|---|
|
|
warning |
L'interface réseau change souvent de statut |
|
|
warning |
Le système de fichiers devrait manquer d'espace dans les prochaines 24 heures. |
|
|
critical |
Le système de fichiers devrait manquer d'espace dans les 4 prochaines heures. |
|
|
warning |
Il reste moins de 5 % d'espace dans le système de fichiers. |
|
|
critical |
Il reste moins de 3 % d'espace dans le système de fichiers. |
|
|
warning |
Le système de fichiers devrait manquer d'inodes dans les prochaines 24 heures. |
|
|
critical |
Le système de fichiers devrait manquer d'inodes dans les 4 prochaines heures. |
|
|
warning |
Il reste moins de 5 % d'inodes dans le système de fichiers. |
|
|
critical |
Il reste moins de 3 % d'inodes dans le système de fichiers. |
|
|
warning |
L'interface réseau signale de nombreuses erreurs de réception. |
|
|
warning |
L'interface réseau signale de nombreuses erreurs de transmission. |
|
|
warning |
Le nombre d'entrées conntrack approche de la limite. |
|
|
warning |
Le collecteur de fichiers texte Node Exporter n'a pas pu être supprimé. |
|
|
warning |
Un décalage d'horloge a été détecté. |
|
|
warning |
L'horloge ne se synchronise pas. |
|
|
critical |
La matrice RAID est dégradée |
|
|
warning |
Périphérique défaillant dans la matrice RAID |
|
|
warning |
Le noyau devrait bientôt épuiser la limite des descripteurs de fichiers. |
|
|
critical |
Le noyau devrait bientôt épuiser la limite des descripteurs de fichiers. |
|
|
warning |
Le nœud n'est pas prêt. |
|
|
warning |
Le nœud est inaccessible. |
|
|
info |
Kubelet fonctionne à pleine capacité. |
|
|
warning |
L'état de préparation du nœud fluctue. |
|
|
warning |
Le Kubelet Pod Lifecycle Event Generator met trop de temps à être remis en vente. |
|
|
warning |
La latence de démarrage du Kubelet Pod est trop élevée. |
|
|
warning |
Le certificat client Kubelet est sur le point d'expirer. |
|
|
critical |
Le certificat client Kubelet est sur le point d'expirer. |
|
|
warning |
Le certificat du serveur Kubelet est sur le point d'expirer. |
|
|
critical |
Le certificat du serveur Kubelet est sur le point d'expirer. |
|
|
warning |
Kubelet n'a pas réussi à renouveler son certificat client. |
|
|
warning |
Kubelet n'a pas réussi à renouveler son certificat de serveur. |
|
|
critical |
La cible a disparu lors de la découverte de Prometheus Target. |
|
|
warning |
Différentes versions sémantiques des composants Kubernetes en cours d'exécution. |
|
|
warning |
Le client du serveur d'API Kubernetes rencontre des erreurs. |
|
|
warning |
Le certificat client est sur le point d'expirer. |
|
|
critical |
Le certificat client est sur le point d'expirer. |
|
|
warning |
L'API agrégée Kubernetes a signalé des erreurs. |
|
|
warning |
L'API agrégée Kubernetes est en panne. |
|
|
critical |
La cible a disparu lors de la découverte de Prometheus Target. |
|
|
warning |
Le serveur d'API Kubernetes a mis fin à {{$value | HumanizePercentage}} de ses demandes entrantes. |
|
|
critical |
Le volume persistant est en train de se remplir. |
|
|
warning |
Le volume persistant est en train de se remplir. |
|
|
critical |
Persistent Volume Inodes se remplit. |
|
|
warning |
Les inodes de volume persistants se remplissent. |
|
|
critical |
Persistent Volume rencontre des problèmes de provisionnement. |
|
|
warning |
Le cluster a surchargé les demandes de ressources du processeur. |
|
|
warning |
Le cluster a surchargé les demandes de ressources de mémoire. |
|
|
warning |
Le cluster a surchargé les demandes de ressources du processeur. |
|
|
warning |
Le cluster a surchargé les demandes de ressources de mémoire. |
|
|
info |
Le quota d'espace de noms va être complet. |
|
|
info |
Le quota d'espace de noms est pleinement utilisé. |
|
|
warning |
Le quota d'espace de noms a dépassé les limites. |
|
|
info |
Les processus subissent un ralentissement élevé du processeur. |
|
|
warning |
Le pod est en train de tourner en boucle. |
|
|
warning |
Le pod n'est pas prêt depuis plus de 15 minutes. |
|
|
warning |
Incompatibilité entre la génération du déploiement en raison d'un éventuel retour en arrière |
|
|
warning |
Le déploiement n'a pas atteint le nombre de répliques attendu. |
|
|
warning |
StatefulSet n'a pas atteint le nombre de répliques attendu. |
|
|
warning |
StatefulSet inadéquation de génération due à un éventuel retour en arrière |
|
|
warning |
StatefulSet la mise à jour n'a pas été déployée. |
|
|
warning |
DaemonSet le déploiement est bloqué. |
|
|
warning |
Le conteneur à dosettes attend plus d'une heure |
|
|
warning |
DaemonSet les pods ne sont pas programmés. |
|
|
warning |
DaemonSet les pods sont mal programmés. |
|
|
warning |
Job non terminé à temps |
|
|
warning |
Le Job n'a pas pu être terminé. |
|
|
warning |
HPA n'a pas atteint le nombre de répliques souhaité. |
|
|
warning |
HPA fonctionne au maximum de répliques |
|
|
critical |
kube-state-metrics rencontre des erreurs dans les opérations de liste. |
|
|
critical |
kube-state-metrics rencontre des erreurs lors des opérations de surveillance. |
|
|
critical |
Le sharding kube-state-metrics est mal configuré. |
|
|
critical |
les partitions kube-state-metrics sont manquantes. |
|
|
critical |
Le serveur d'API consomme trop d'erreurs. |
|
|
critical |
Le serveur d'API consomme trop d'erreurs. |
|
|
warning |
Le serveur d'API consomme trop d'erreurs. |
|
|
warning |
Le serveur d'API consomme trop d'erreurs. |
|
|
warning |
Une ou plusieurs cibles sont abaissées. |
|
|
critical |
Le cluster Etcd ne compte pas suffisamment de membres. |
|
|
warning |
Etcd Cluster un nombre élevé de changements de leader. |
|
|
critical |
Le cluster Etcd n'a pas de leader. |
|
|
warning |
Nombre élevé de requêtes gRPC échouées dans le cluster Etcd. |
|
|
critical |
Les requêtes gRPC du cluster Etcd sont lentes. |
|
|
warning |
La communication entre les membres du cluster Etcd est lente. |
|
|
warning |
Nombre élevé de propositions rejetées dans le cluster Etcd. |
|
|
warning |
Durées de synchronisation élevées du cluster Etcd. |
|
|
warning |
Le cluster Etcd a des durées de validation plus élevées que prévu. |
|
|
warning |
Le cluster Etcd a échoué aux requêtes HTTP. |
|
|
critical |
Le cluster Etcd a un nombre élevé de requêtes HTTP échouées. |
|
|
warning |
Les requêtes HTTP du cluster Etcd sont lentes. |
|
|
warning |
L'horloge de l'hôte ne se synchronise pas. |
|
|
warning |
Host OOM kill a été détecté. |
Résolution des problèmes
Plusieurs facteurs peuvent entraîner l'échec de la configuration du projet. Assurez-vous de vérifier les points suivants.
-
Vous devez remplir tous les prérequis avant d'installer la solution.
-
Le cluster doit contenir au moins un nœud avant de tenter de créer la solution ou d'accéder aux métriques.
-
Les modules complémentaires
CoreDNSet leskube-proxymodules complémentaires doivent être installés surAWS CNIvotre cluster Amazon EKS. S'ils ne sont pas installés, la solution ne fonctionnera pas correctement. Ils sont installés par défaut, lors de la création du cluster via la console. Vous devrez peut-être les installer si le cluster a été créé via un AWS SDK. -
Le délai d'installation des modules Amazon EKS a expiré. Cela peut se produire si la capacité des nœuds n'est pas suffisante. Les causes de ces problèmes sont multiples, notamment :
-
Le cluster Amazon EKS a été initialisé avec Fargate au lieu d'Amazon EC2. Ce projet nécessite Amazon EC2.
-
Les nœuds sont endommagés et ne sont donc pas disponibles.
Vous pouvez l'utiliser
kubectl describe nodepour vérifier les taches. Ensuite,NODENAME| grep Taintskubectl taint nodepour enlever les souillures. Assurez-vous d'inclure le nomNODENAMETAINT_NAME--après le nom de la tache. -
Les nœuds ont atteint la limite de capacité. Dans ce cas, vous pouvez créer un nouveau nœud ou augmenter la capacité.
-
-
Vous ne voyez aucun tableau de bord dans Grafana : l'identifiant de l'espace de travail Grafana est incorrect.
Exécutez la commande suivante pour obtenir des informations sur Grafana :
kubectl describe grafanas external-grafana -n grafana-operatorVous pouvez vérifier les résultats pour trouver l'URL de l'espace de travail correcte. Si ce n'est pas celui que vous attendez, redéployez-le avec le bon identifiant d'espace de travail.
Spec: External: API Key: Key: GF_SECURITY_ADMIN_APIKEY Name: grafana-admin-credentials URL: https://g-123example.grafana-workspace.aws-region.amazonaws.com Status: Admin URL: https://g-123example.grafana-workspace.aws-region.amazonaws.com Dashboards: ... -
Vous ne voyez aucun tableau de bord dans Grafana : vous utilisez une clé d'API expirée.
Pour rechercher ce cas, vous devez obtenir l'opérateur grafana et vérifier la présence d'erreurs dans les journaux. Obtenez le nom de l'opérateur Grafana avec cette commande :
kubectl get pods -n grafana-operatorCela renverra le nom de l'opérateur, par exemple :
NAME READY STATUS RESTARTS AGEgrafana-operator-1234abcd5678ef901/1 Running 0 1h2mUtilisez le nom de l'opérateur dans la commande suivante :
kubectl logsgrafana-operator-1234abcd5678ef90-n grafana-operatorLes messages d'erreur tels que les suivants indiquent une clé d'API expirée :
ERROR error reconciling datasource {"controller": "grafanadatasource", "controllerGroup": "grafana.integreatly.org", "controllerKind": "GrafanaDatasource", "GrafanaDatasource": {"name":"grafanadatasource-sample-amp","namespace":"grafana-operator"}, "namespace": "grafana-operator", "name": "grafanadatasource-sample-amp", "reconcileID": "72cfd60c-a255-44a1-bfbd-88b0cbc4f90c", "datasource": "grafanadatasource-sample-amp", "grafana": "external-grafana", "error": "status: 401, body: {\"message\":\"Expired API key\"}\n"} github.com/grafana-operator/grafana-operator/controllers.(*GrafanaDatasourceReconciler).ReconcileDans ce cas, créez une nouvelle clé d'API et déployez à nouveau la solution. Si le problème persiste, vous pouvez forcer la synchronisation à l'aide de la commande suivante avant le redéploiement :
kubectl delete externalsecret/external-secrets-sm -n grafana-operator -
Installations du CDK — Paramètre SSM manquant. Si le message d'erreur suivant s'affiche, exécutez
cdk bootstrapet réessayez.Deployment failed: Error: aws-observability-solution-eks-infra-$EKS_CLUSTER_NAME: SSM parameter /cdk-bootstrap/xxxxxxx/version not found. Has the environment been bootstrapped? Please run 'cdk bootstrap' (see https://docs.aws.amazon.com/cdk/latest/ guide/bootstrapping.html) -
Le déploiement peut échouer si le fournisseur OIDC existe déjà. Vous verrez un message d'erreur semblable à celui-ci (dans ce cas, pour les installations de CDK) :
| CREATE_FAILED | Custom::AWSCDKOpenIdConnectProvider | OIDCProvider/Resource/Default Received response status [FAILED] from custom resource. Message returned: EntityAlreadyExistsException: Provider with url https://oidc.eks.REGION.amazonaws.com/id/PROVIDER IDalready exists.Dans ce cas, accédez au portail IAM, supprimez le fournisseur OIDC et réessayez.
-
Terraform s'installe — Vous voyez un message d'erreur qui inclut et.
cluster-secretstore-sm failed to create kubernetes rest client for update of resourcefailed to create kubernetes rest client for update of resourceCette erreur indique généralement que l'opérateur secret externe n'est pas installé ou activé dans votre cluster Kubernetes. Il est installé dans le cadre du déploiement de la solution, mais il n'est parfois pas prêt lorsque la solution en a besoin.
Vous pouvez vérifier qu'il est installé à l'aide de la commande suivante :
kubectl get deployments -n external-secretsS'il est installé, l'opérateur peut mettre un certain temps à être complètement prêt à être utilisé. Vous pouvez vérifier l'état des définitions de ressources personnalisées (CRD) nécessaires en exécutant la commande suivante :
kubectl get crds|grep external-secretsCette commande doit répertorier les CRD associés à l'opérateur secret externe, y compris
clustersecretstores.external-secrets.ioetexternalsecrets.external-secrets.io. S'ils ne figurent pas dans la liste, attendez quelques minutes et vérifiez à nouveau.Une fois les CRD enregistrés, vous pouvez exécuter à
terraform applynouveau pour déployer la solution.
