DynamoDB でのテーブルのスキャン
Amazon DynamoDB の Scan オペレーションでは、テーブルまたはセカンダリインデックスのすべての項目を読み込みます。デフォルトでは、Scan オペレーションはテーブルまたはインデックスのすべての項目のデータ属性を返します。ProjectionExpression パラメータを使用し、Scan がすべての属性ではなく一部のみを返すようにできます。
Scan は常に結果セットを返します。一致する項目がない場合、結果セットは空になります。
1 回の Scan リクエストで、最大 1 MB のデータを取得できます。DynamoDB では、必要に応じてこのデータにフィルター式を適用して、結果をユーザーに返す前に絞り込むことができます。
Scan のフィルタ式
Scan 結果の絞り込みが必要な場合は、オプションでフィルタ式を指定できます。フィルタ式によって、Scan 結果の内、どの項目を返すべきか確定します。他のすべての結果は破棄されます。
フィルタ式は、Scan の完了後、結果が返される前に適用されます。そのため、Scan は、フィルタ式があるかどうかにかかわらず、同じ量の読み込みキャパシティーを消費します。
1 回の Scan オペレーションで、最大 1 MB のデータを取得できます。この制限は、フィルタ式を評価する前に適用されます。
Scan では、パーティションキー属性やソートキー属性など、フィルター式で任意の属性を指定できます。
フィルタ式の構文は、条件式の構文と同じです。フィルタ式は、条件式と同じコンパレータ、関数および論理演算子を使用できます。論理演算子の詳細については、「DynamoDB の条件式とフィルター式、演算子、関数」を参照してください。
例
次の AWS Command Line Interface (AWS CLI) の例では Thread テーブルをスキャンして、特定のユーザーによって最後に投稿された項目のみを返します。
aws dynamodb scan \ --table-name Thread \ --filter-expression "LastPostedBy = :name" \ --expression-attribute-values '{":name":{"S":"User A"}}'
結果セットの項目数の制限
Scan オペレーションは、結果で返される項目数を制限することができます。これを行うには、フィルタ式を評価する前に、Limit パラメータに、Scan オペレーションが返す項目の最大数を設定します。
たとえば、フィルタ式を使用せず、Scan 値を Limit として、テーブルを 6 するとします。Scan 結果には、テーブルの最初の 6 つの項目が含まれます。
ここで、Scan にフィルタ式を追加するとします。この場合、DynamoDB は返される 6 つの項目にフィルター式を適用し、一致しない項目を廃棄します。最終的な Scan 結果はフィルタリングされる項目の数に応じて、6 つ以下の項目を含みます。
結果のページ分割
DynamoDB では、Scan オペレーションの結果をページ割りします。ページ分割を行うことで Scan 結果が 1 MB サイズ (またはそれ以下) のデータの「ページ」に分割されます。アプリケーションは結果の最初のページ、次に 2 ページと処理できます。
1 つの Scan は、サイズの制限である1 MB 以内の結果セットだけを返します。
さらに結果があるかどうかを確認して、一度に 1 ページずつ結果を取り出すには、アプリケーションで次の操作を行う必要があります。
-
低レベルの
Scan結果を確認します。-
結果に
LastEvaluatedKey要素が含まれる場合、ステップ 2 に進みます。 -
結果に
LastEvaluatedKeyがない場合、これ以上取得する項目はありません。
-
-
以前のものと同じパラメータを使用して新しい
Scanリクエストを作成します。ただし、今回は、ステップ 1 からLastEvaluatedKey値を取得して、新しいScanリクエストのExclusiveStartKeyパラメータとして使用します。 -
新しい
Scanリクエストを実行します。 -
ステップ 1 に進んでください。
言い換えると、LastEvaluatedKey レスポンスからの Scan を次の ExclusiveStartKey リクエストの Scan として使用する必要があります。LastEvaluatedKey レスポンスに Scan 要素がない場合、結果の最後のページを取得します。(結果セットの最後まで到達したことを確認できるのは、LastEvaluatedKey がないときだけです)
AWS CLI を使用してこの動作を表示できます。AWS CLI は低レベル Scan リクエストを DynamoDB に送信し、LastEvaluatedKey が結果に表示されなくなるまで送信を繰り返します。次の AWS CLI の例を見てください。この例は、Movies テーブル全体をスキャンしますが、特定のジャンルの映画のみを返します。
aws dynamodb scan \ --table-name Movies \ --projection-expression "title" \ --filter-expression 'contains(info.genres,:gen)' \ --expression-attribute-values '{":gen":{"S":"Sci-Fi"}}' \ --page-size 100 \ --debug
通常、AWS CLI はページ分割を自動的に処理します。ただし、この例では、AWS CLI --page-size パラメータによりページごとの項目数が制限されています。--debug パラメータは、リクエストとレスポンスについての低レベルの情報を表示します。
注記
ページ分割の結果は、渡した入力パラメータによっても異なります。
-
aws dynamodb scan --table-name Prices --max-items 1を使用するとNextTokenが返されます -
aws dynamodb scan --table-name Prices --limit 1を使用するとLastEvaluatedKeyが返されます。
また、特に --starting-token を使用するには、NextToken 値が必要であることに注意してください。
この例を実行した場合、DynamoDB からの最初のレスポンスは次のようになります。
2017-07-07 12:19:14,389 - MainThread - botocore.parsers - DEBUG - Response body: b'{"Count":7,"Items":[{"title":{"S":"Monster on the Campus"}},{"title":{"S":"+1"}}, {"title":{"S":"100 Degrees Below Zero"}},{"title":{"S":"About Time"}},{"title":{"S":"After Earth"}}, {"title":{"S":"Age of Dinosaurs"}},{"title":{"S":"Cloudy with a Chance of Meatballs 2"}}], "LastEvaluatedKey":{"year":{"N":"2013"},"title":{"S":"Curse of Chucky"}},"ScannedCount":100}'
レスポンスの LastEvaluatedKey は、すべての項目が取得されたわけではないことを示します。その後、AWS CLI は DynamoDB に別の Scan リクエストを送信します。このリクエストとレスポンスのパターンが、最終レスポンスまで繰り返されます。
2017-07-07 12:19:17,830 - MainThread - botocore.parsers - DEBUG - Response body: b'{"Count":1,"Items":[{"title":{"S":"WarGames"}}],"ScannedCount":6}'
LastEvaluatedKey がない場合、これ以上取得する項目がないことを示します。
注記
AWS SDK は低レベルの DynamoDB レスポンス (LastEvaluatedKey の有無を含む) を処理し、ページ割りした Scan 結果のさまざまな抽象化を提供します。たとえば、SDK for Java のドキュメントインターフェイスでは、java.util.Iterator サポートが利用可能なため、結果を一度に 1 つずつ確認できます。
各種のプログラミング言語のコード例については、Amazon DynamoDB 利用開始ガイドと、該当言語の AWS SDK ドキュメントを参照してください。
結果での項目のカウント
Scan レスポンスには、条件に一致する項目に加えて次の要素が含まれます。
-
ScannedCount—ScanFilterが適用される前に評価される項目数。ScannedCount値が大きく、Count結果が小さいまたはない場合は、Scanオペレーションが不十分であることを示しています。リクエストでフィルタを使用していない場合、ScannedCountはCountと同じです。 -
Count— フィルター式 (存在する場合) が適用された後に残っている項目数。
注記
フィルタ式を使用しない場合、ScannedCount と Count は同じ値を持ちます。
Scan 結果セットのサイズが 1 MB より大きい場合、ScannedCount および Count では、合計項目数の一部のみが示されます。すべての結果を取得するためには、複数の Scan オペレーションを実行する必要があります (結果のページ分割 を参照してください)。
各 Scan レスポンスには、特定の ScannedCount によって処理された項目の Count および Scan が含まれます。すべての Scan リクエストの合計を取得するには、ScannedCount および Count の実行中の集計を維持することができます。
Scan で消費されるキャパシティユニット
任意のテーブルまたはセカンダリインデックスで Scan できます。Scan オペレーションでは、次のように読み込み容量単位を消費します。
...を Scan する場合 |
DynamoDB は ... からの読み込み容量ユニットを消費します。 |
|---|---|
| テーブル | テーブルのプロビジョニングされた読み込みキャパシティー。 |
| グローバルセカンダリインデックス | インデックスのプロビジョニングされた読み込みキャパシティー。 |
| ローカルセカンダリインデックス | ベーステーブルのプロビジョニングされた読み込みキャパシティー。 |
注記
セカンダリインデックススキャンオペレーションのクロスアカウントアクセスは、現在、リソースベースのポリシーではサポートされていません。
デフォルトでは、Scanオペレーションはどのくらいの読み込みキャパシティーを消費するかについてのデータを返しません。ただし、この情報を取得するために Scan リクエストで ReturnConsumedCapacity パラメータを指定できます。ReturnConsumedCapacity の有効な設定を以下に示します。
-
NONE— 消費された容量データは返されません。(これがデフォルトです) -
TOTAL— レスポンスには消費された読み込み容量単位の合計値が含まれます。 -
INDEXES— レスポンスは、アクセスする各テーブルとインデックスの消費される容量とともに、消費される読み込み容量単位の合計値を示します。
DynamoDB はアプリケーションに返されるデータ量ではなく、項目の数と項目のサイズに基づいて、消費される読み込みキャパシティユニットの数を計算します。このため、消費される容量ユニットの数は、(デフォルトの動作で) 属性のすべてをリクエストしても、(プロジェクション式を使用して) 一部をリクエストしても、同じになります。この数は、フィルター式を使用していてもいなくても同じです。Scan は最小読み込みキャパシティユニットを消費して、最大 4 KB の項目について強力な整合性のある読み込みを 1 秒あたり 1 回、または結果整合性のある読み込みを 1 秒あたり 2 回実行します。4 KB より大きい項目を読み込む必要がある場合、DynamoDB には追加の読み込みリクエストユニットが必要です。空のテーブルや、パーティションキーの数が少ない非常に大きなテーブルでは、スキャンされたデータ量を超える追加の RCU が課金される場合があります。これにより、データが存在しない場合でも、Scan リクエストを処理するためのコストがカバーされます。
スキャンの読み込み整合性
Scan オペレーションは、結果的に整合性のある読み込みをデフォルトで行います。つまり、Scan 結果が、最近完了した PutItem または UpdateItem オペレーションによる変更を反映しない場合があります。詳細については、「DynamoDB の読み取り整合性」を参照してください。
強力な整合性のある読み込みが必要な場合は、Scan が開始する時に ConsistentRead パラメータを true リクエストで Scan に設定できます。これにより、Scan が開始する前に完了した書き込みオペレーションがすべて Scan 応答に含められます。
ConsistentRead を true に設定し、DynamoDB Streams と同時に使用すると、テーブルのバックアップまたはレプリケーションシナリオで役立ちます。最初に、テーブル内のデータの整合性のあるコピーを取得するため、Scan を true に設定して ConsistentRead を使用します。Scan の実行中、DynamoDB Streams はテーブルで発生した追加の書き込みアクティビティをすべて記録します。Scan が完了したら、ストリームからテーブルへの書き込みアクティビティを適用できます。
注記
Scan を ConsistentRead に設定した true オペレーションでは、ConsistentRead をデフォルト値 (false) のままにした場合と比較して、2 倍の読み込みキャパシティーユニットが使用されます。
並列スキャン
デフォルトでは、Scan オペレーションは、データを順次処理します。Amazon DynamoDB はアプリケーションに 1 MB 単位でデータを返し、アプリケーションは追加の Scan オペレーションを使用して、次の 1 MB のデータを取得できます。
スキャンするテーブルまたはインデックスが大きいほど、Scan を完了するのに時間がかかります。さらに、シーケンシャル Scan は、プロビジョンされた読み込みスループットキャパシティを常に完全に使用できるとは限りません。DynamoDB は大きなテーブルのデータを複数の物理パーティションに分散しますが、Scan オペレーションでは、一度に 1 つのパーティションしか読み込むことができません。このため、Scan のスループットは、単一のパーティションの最大スループットによって制約されます。
これらの問題に対処するために、Scan オペレーションでは、テーブルまたはセカンダリインデックスを論理的に複数のセグメントに分割し、複数のアプリケーションワーカーがセグメントを並行してスキャンします。各ワーカーは、スレッド (マルチスレッドをサポートするプログラミング言語) またはオペレーティングシステムプロセスにすることができます。並列スキャンを実行するには、各ワーカーが独自の Scan リクエストを以下のパラメータで送信します。
-
Segment— 特定のワーカーによってスキャンされるセグメント。各ワーカーは、Segmentに異なる値を使用する必要があります。 -
TotalSegments— 並列スキャンのセグメントの合計数。この値は、アプリケーションが使用するワーカーの数と同じでなければなりません。
次の図表は、マルチスレッドアプリケーションが 3 度の並列処理で並列 Scan を実行する方法を示しています。
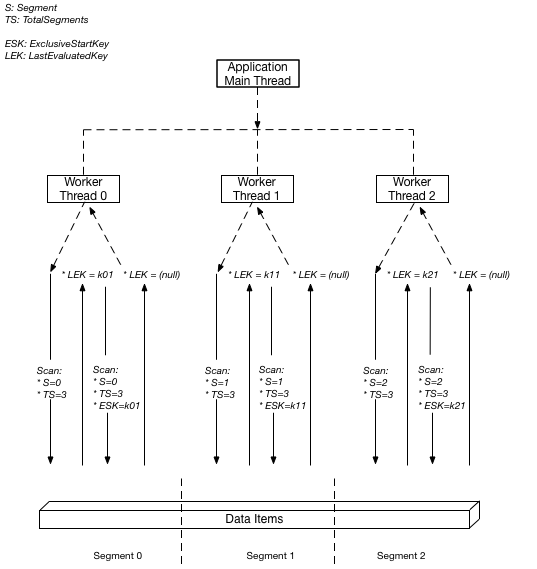
この図では、アプリケーションは 3 つのスレッドを生成し、各スレッドに番号を割り当てます。(セグメントはゼロベースであるため、最初の数値は常に 0 です。) 各スレッドは Scan リクエストを公開し、設定 Segment をその指定された番号に設定し、TotalSegments を 3 に設定します。各スレッドは、指定されたセグメントをスキャンし、一度に 1 MB のデータを取得し、アプリケーションのメインスレッドにデータを返します。
DynamoDB は、各項目のパーティションキーにハッシュ関数を適用して、項目をセグメントに割り当てます。指定された TotalSegments 値の場合、同じパーティションキーを持つすべての項目が常に同じ Segment に割り当てられます。つまり、項目 1、項目 2、項目 3 すべてが pk="account#123" を共有するテーブルでは (ソートキーは異なる)、ソートキーの値や項目コレクションのサイズに関係なく、これらの項目は同じワーカーによって処理されます。
セグメント割り当てはパーティションキーハッシュのみに基づいているため、セグメントは不均等に分散される可能性があります。一部のセグメントには項目が含まれていない場合がありますが、他のセグメントには大きな項目コレクションを持つパーティションキーが多く含まれている場合があります。その結果、セグメントの合計数を増やしても、特にパーティションキーがキースペース全体に均一に分散されていない場合、スキャンパフォーマンスが速くなることは保証されません。
Segment および TotalSegments の値は、個々の Scan リクエストに適用されるため、いつでも異なる値を使用できます。アプリケーションが最高のパフォーマンスを達成するまで、これらの値および使用するワーカーの数を試さなければならない場合があります。
注記
多数のワーカーを使用した並列スキャンでは、スキャン対象のテーブルまたはインデックスに対してプロビジョンされたスループットをすべて簡単に使用できます。テーブルまたはインデックスが他のアプリケーションから大量の読み込みまたは書き込みアクティビティが発生している場合は、このようなスキャンを避けることをお勧めします。
リクエストごとに返されるデータの量を制御するには、Limit パラメータを使用します。これにより、1 人のワーカーがプロビジョンされたスループットをすべて消費し、他のすべてのワーカーが犠牲になる状況を防ぐことができます。
