DynamoDB の苦情管理システムのスキーマ設計
苦情管理システムのビジネスユースケース
DynamoDB は、苦情管理システム (またはコンタクトセンター) のユースケースに最適なデータベースです。関連するほとんどのアクセスパターンが key-value ベースのトランザクションルックアップであるためです。このシナリオの一般的なアクセスパターンは、次のとおりです。
-
苦情を作成および更新する
-
苦情をエスカレートする
-
苦情に関するコメントを作成および閲覧する
-
顧客からのすべての苦情を取得する
-
エージェントからのすべてのコメントを取得し、すべてのエスカレーションを取得する
一部のコメントには、苦情または解決策を説明する添付ファイルが付いている場合があります。これらはすべて key-value アクセスパターンですが、苦情に新しいコメントが追加されたときに通知を送信したり、分析クエリを実行して重大度 (またはエージェントのパフォーマンス) 別に苦情の分布を毎週調べたりするなど、追加の要件が伴う場合があります。ライフサイクル管理やコンプライアンスに関連するその他の要件としては、苦情を 3 年間記録した後に苦情データをアーカイブすることが挙げられます。
苦情管理システムのアーキテクチャ図
次の図は、苦情管理システムのアーキテクチャ図を示しています。この図は、苦情管理システムが使用するさまざまな AWS のサービス統合を示しています。
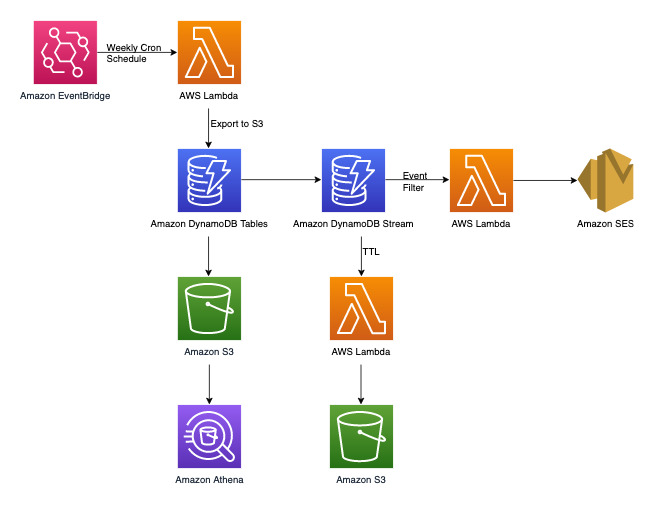
後述の DynamoDB データモデリングセクションで扱う key-value トランザクションアクセスパターンとは別に、非トランザクション要件が 3 つあります。上のアーキテクチャ図は、次の 3 つのワークフローに分けることができます。
-
苦情に新しいコメントが追加されたときに通知を送信する
-
週次データに対して分析クエリを実行する
-
3 年より前のデータをアーカイブする
それぞれを詳しく見ていきましょう。
苦情に新しいコメントが追加されたときに通知を送信する
この要件を満たすには、次のワークフローを使用できます。
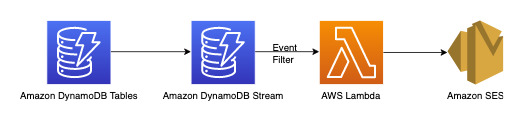
DynamoDB ストリームは、DynamoDB テーブルに対するすべての書き込みアクティビティを記録する変更データキャプチャメカニズムです。これらの変更の一部またはすべてに応じてトリガーされるように Lambda 関数を設定できます。Lambda トリガーにイベントフィルターを設定して、ユースケースに関係のないイベントを除外できます。この例では、フィルターを使用して、新しいコメントが追加されたときにのみ Lambda をトリガーし、関連する E メール ID (AWS Secret Manager またはその他の認証情報ストアから取得可能) に通知を送信できます。
週次データに対して分析クエリを実行する
DynamoDB は、オンライントランザクション処理 (OLTP) を主眼とするワークロードに適しています。分析が必要な他の 10~20% のアクセスパターンについては、マネージド機能の Amazon S3 へのエクスポートを使用してデータを S3 にエクスポートできます。この機能を使用しても、DynamoDB テーブルのライブトラフィックには影響がありません。次のワークフローをご覧ください。
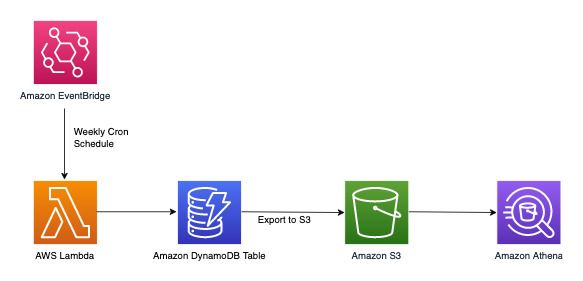
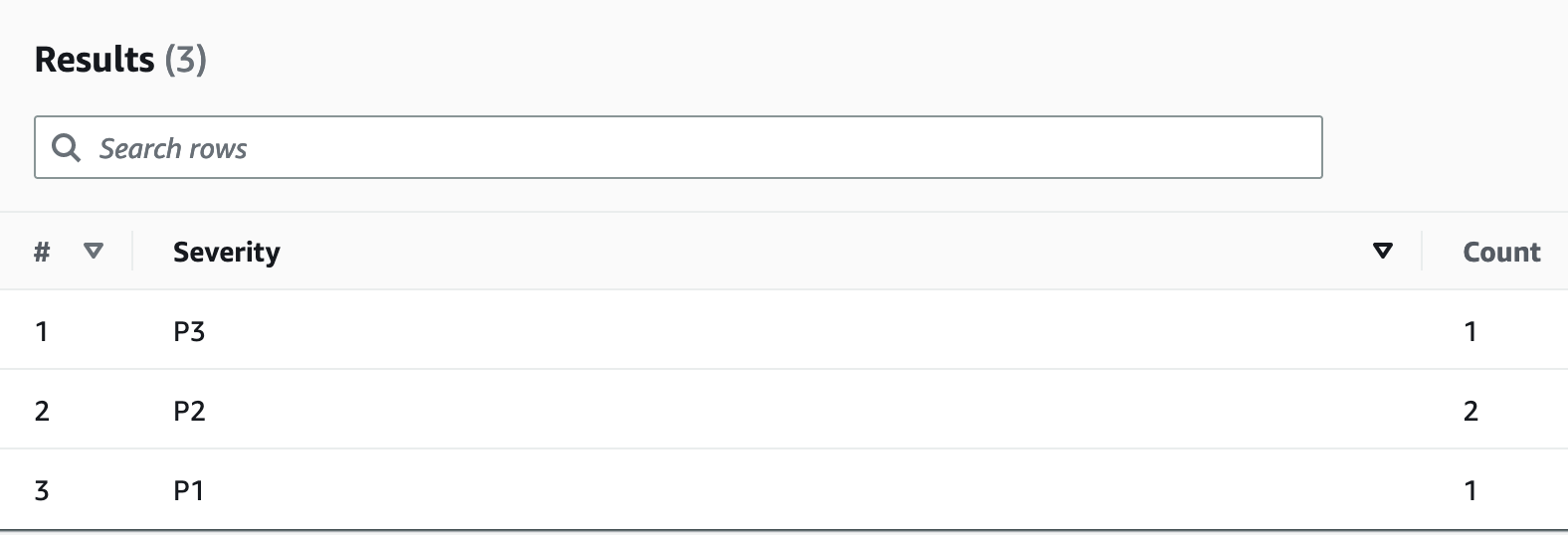
Amazon EventBridge を使用すると、AWS Lambda をスケジュールどおりにトリガーできます。これにより、Lambda を定期的に呼び出すように cron 式を設定できます。Lambda は ExportToS3 API コールを呼び出し、DynamoDB データを S3 に保存します。この S3 データに Amazon Athena などの SQL エンジンからアクセスし、テーブルのライブトランザクションワークロードには影響を与えることなく、DynamoDB データに対して分析クエリを実行できます。重大度レベル別に苦情数を調べる Athena クエリの例は、次のようになります。
SELECT Item.severity.S as "Severity", COUNT(Item) as "Count" FROM "complaint_management"."data" WHERE NOT Item.severity.S = '' GROUP BY Item.severity.S ;
この Athena クエリは次の結果を返します。
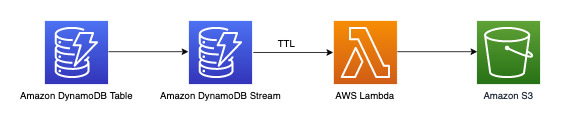
3 年より前のデータをアーカイブする
DynamoDB の Time to Live (TTL) 機能を使用して、追加費用なしで、DynamoDB テーブルから古いデータを削除できます (ただし、2019.11.21 (現行) バージョンのグローバルテーブルレプリカは除きます。TTL 削除が他のリージョンにレプリケートされると書き込み容量が消費されるためです)。このデータを DynamoDB ストリームで表示し、使用できます。その後に、Amazon S3 にアーカイブできます。この要件のワークフローは次のとおりです。
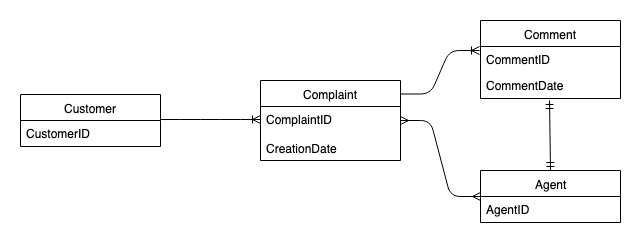
苦情管理システムのエンティティ関係図
次に示すのは、苦情管理システムのスキーマ設計に使用するエンティティ関係図 (ERD) です。
苦情管理システムのアクセスパターン
以下は、苦情管理システムのスキーマ設計で検討するアクセスパターンです。
-
createComplaint
-
updateComplaint
-
updateSeveritybyComplaintID
-
getComplaintByComplaintID
-
addCommentByComplaintID
-
getAllCommentsByComplaintID
-
getLatestCommentByComplaintID
-
getAComplaintbyCustomerIDAndComplaintID
-
getAllComplaintsByCustomerID
-
escalateComplaintByComplaintID
-
getAllEscalatedComplaints
-
getEscalatedComplaintsByAgentID (新しいものから古いものへの順)
-
getCommentsByAgentID (2 つの日付間)
苦情管理システムのスキーマ設計の進化
これは苦情管理システムであるため、ほとんどのアクセスパターンはプライマリエンティティとしての苦情を中心に展開します。ComplaintID のカーディナリティが高いと、基盤となるパーティションにデータが均等に分散されます。また、特定したアクセスパターンの最も一般的な検索条件となります。したがって、ComplaintID は、このデータセットのパーティションキー候補として適しています。
ステップ 1: アクセスパターン 1 (createComplaint)、2 (updateComplaint)、3 (updateSeveritybyComplaintID)、4 (getComplaintByComplaintID) に対処する
「metadata」(または「AA」) という汎用ソートキー値を使用して、CustomerID、State、Severity、CreationDate などの苦情固有の情報を保存できます。PK=ComplaintID と SK=“metadata” でシングルトンオペレーションを使用して、以下を行います。
-
PutItemで新しい苦情を作成する -
UpdateItemで苦情メタデータの重大度やその他のフィールドを更新する -
GetItemで苦情のメタデータを取得する

ステップ 2: アクセスパターン 5 (addCommentByComplaintID) に対処する
このアクセスパターンでは、苦情と苦情に関するコメントとの間に 1 対多リレーションシップモデルが必要です。ここでは、垂直パーティショニング手法を通じてソートキーを使用し、さまざまなタイプのデータを含む項目コレクションを作成します。アクセスパターン 6 (getAllCommentsByComplaintID) と 7 (getLatestCommentByComplaintID) に注目すると、コメントを時間順に並べ替える必要があることがわかります。また、複数のコメントを同時に受け取ることができるため、複合ソートキー手法を使用して時間と CommentID をソートキー属性に追加できます。
このようなコメント競合の可能性に対処する他のオプションとしては、タイムスタンプの粒度を増やすか、Comment_ID を使用する代わりに増分数値をサフィックスとして追加します。この場合、範囲ベースの操作を可能にするために、コメントに対応する項目のソートキー値の前に「comm#」を付けます。
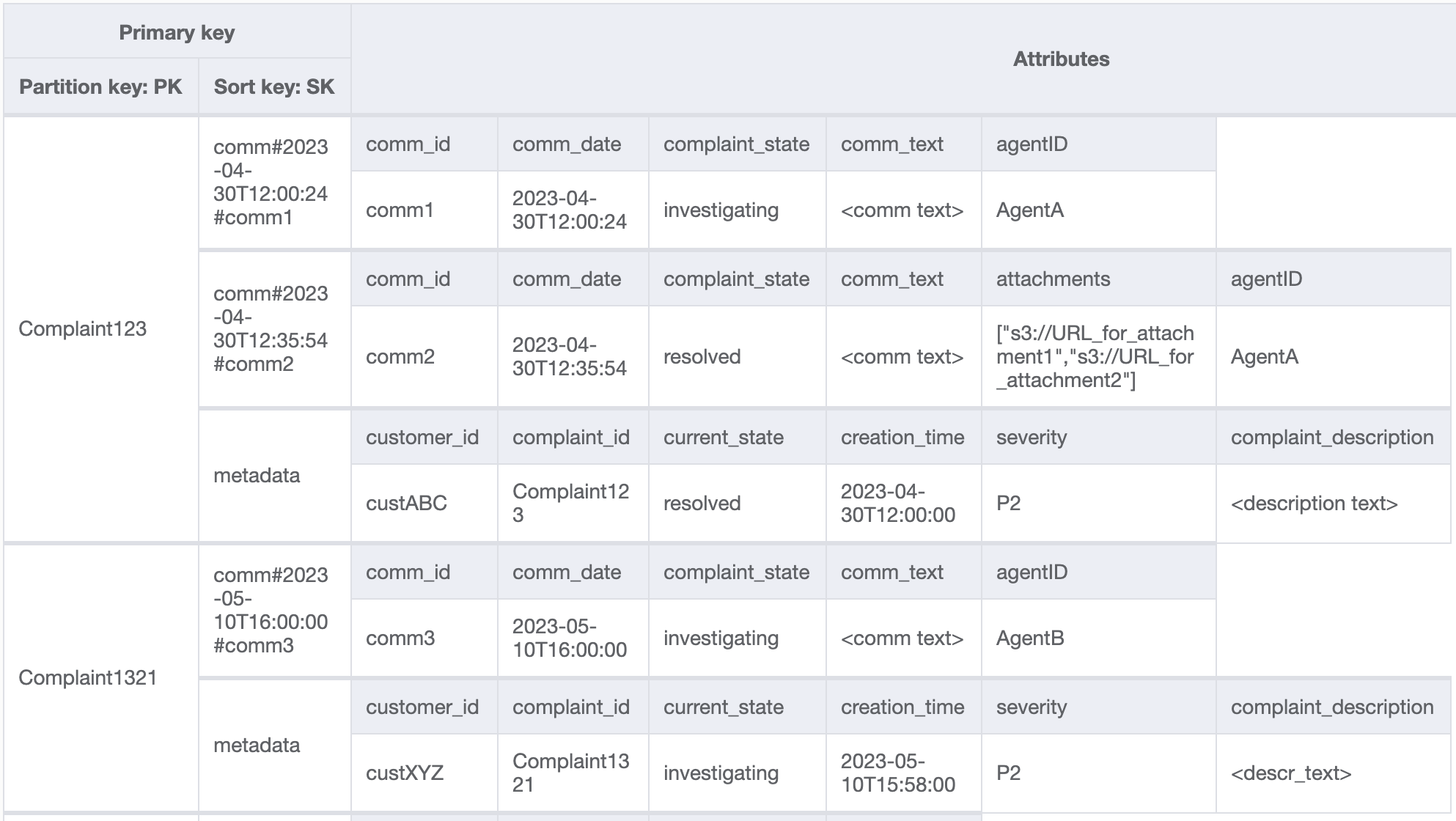
また、苦情メタデータの currentState に、新しいコメントを追加したときの状態が反映されることを確認する必要があります。コメントの追加は、エージェントへの苦情の割り当てや苦情の解決などを示す場合があります。コメントの追加と現在の状態の更新をオールオアナッシング方式で苦情メタデータにバンドルするには、TransactWriteItems API を使用します。結果として得られるテーブルの状態は次のようになります。

テーブルにさらにデータを追加し、PK とは別のフィールドとして ComplaintID も追加しましょう。ComplaintID に追加のインデックスが必要な場合に備えて、モデルを将来的に保証するためです。また、一部のコメントには添付ファイルが含まれている場合があることに注意してください。添付ファイルは、Amazon Simple Storage Service に保存し、その参照または URL のみを DynamoDB で管理します。コストとパフォーマンスを最適化するために、トランザクションデータベースはできるだけリーンな状態に保つことがベストプラクティスです。これで、データは次のようになります。
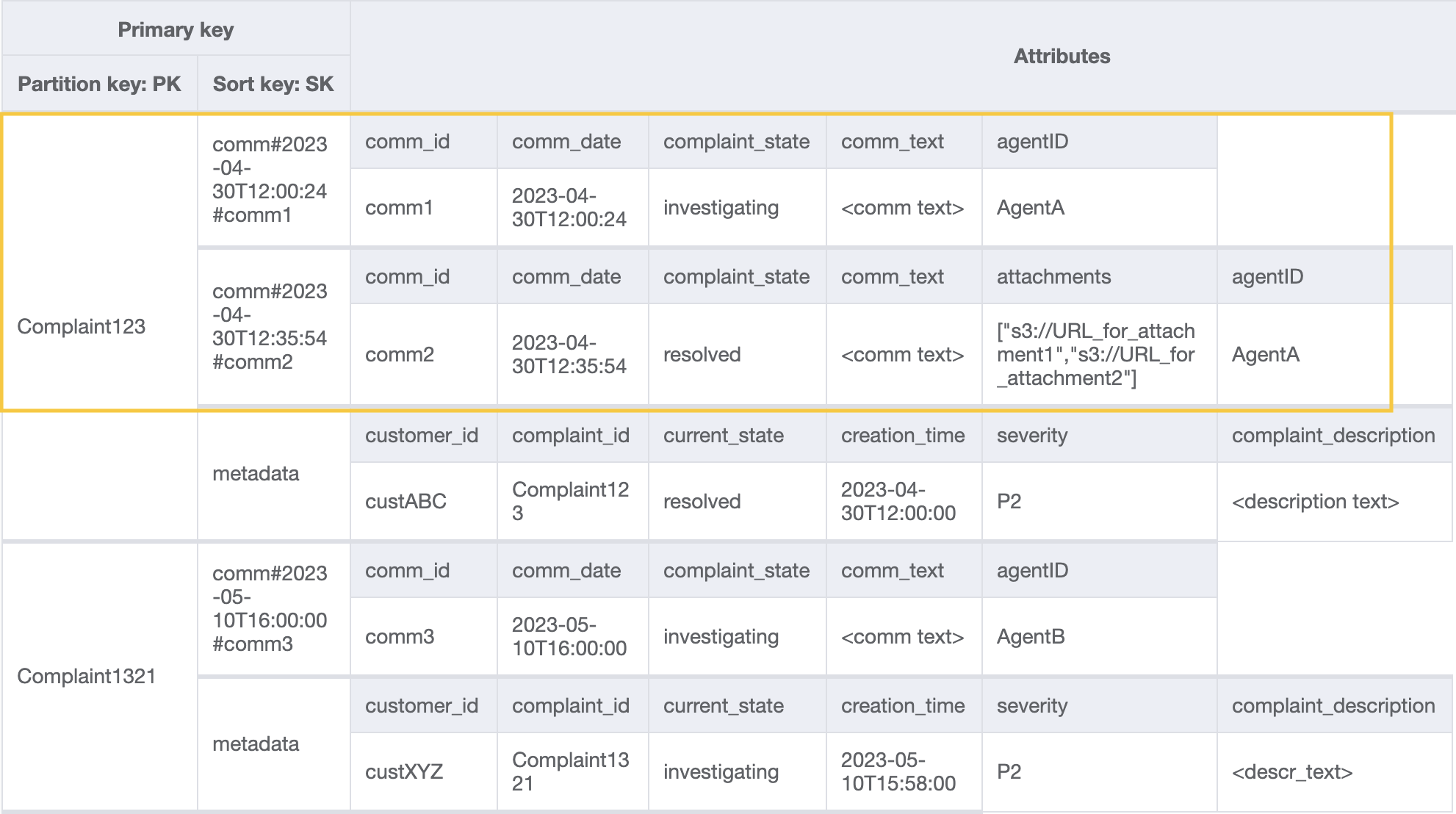
ステップ 3: アクセスパターン 6 (getAllCommentsByComplaintID) と 7 (getLatestCommentByComplaintID) に対処する
苦情に関するすべてのコメントを取得するには、ソートキーに対する query オペレーションで begins_with 条件を使用できます。メタデータエントリを読み取るために追加の読み取り容量を消費したり、関連する結果をフィルタリングするためのオーバーヘッドを生じたりせずに、このようなソートキー条件を設定することで、必要なものだけを読み取ることができます。例えば、SK および PK=Complaint123 begins_with comm# を使用したクエリオペレーションは、メタデータエントリをスキップして、以下を返します。
パターン 7 (getLatestCommentByComplaintID) では苦情に関する最新のコメントが必要であるため、次の 2 つのクエリパラメータを追加しましょう。
-
結果を降順にソートするために False に設定する
ScanIndexForward -
最新のコメントを (1つだけ) 取得するために 1 に設定する
Limit
アクセスパターン 6 (getAllCommentsByComplaintID) と同じように、ソートキー条件として begins_with comm# を使用してメタデータエントリを省略します。これで、クエリオペレーションで PK=Complaint123 と SK=begins_with comm# に加えて、ScanIndexForward=False と Limit を使用し、この設計でアクセスパターン 7 を実行できるようになりました。結果として、次のターゲット項目が返されます。
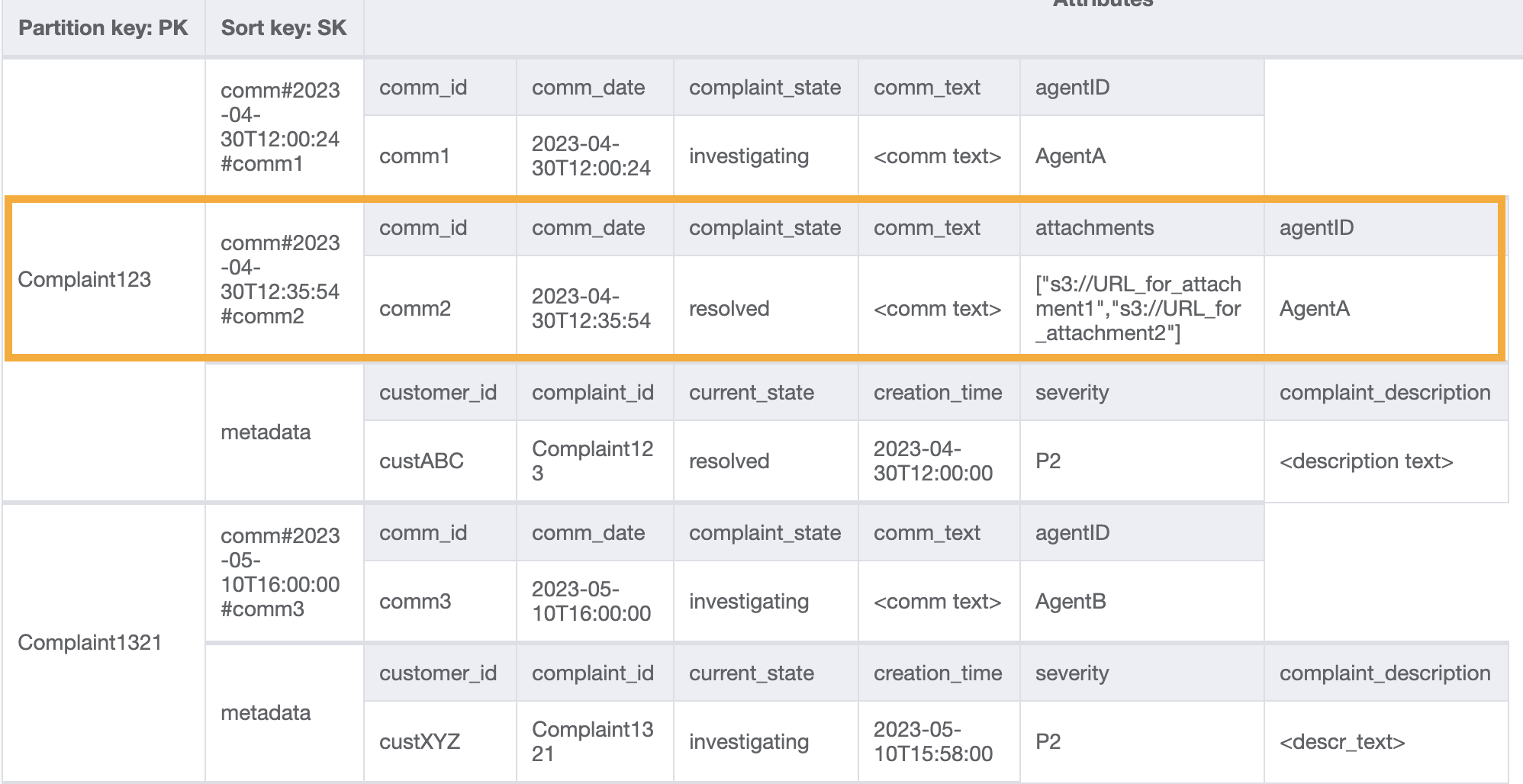
さらにダミーデータをテーブルに追加してみましょう。
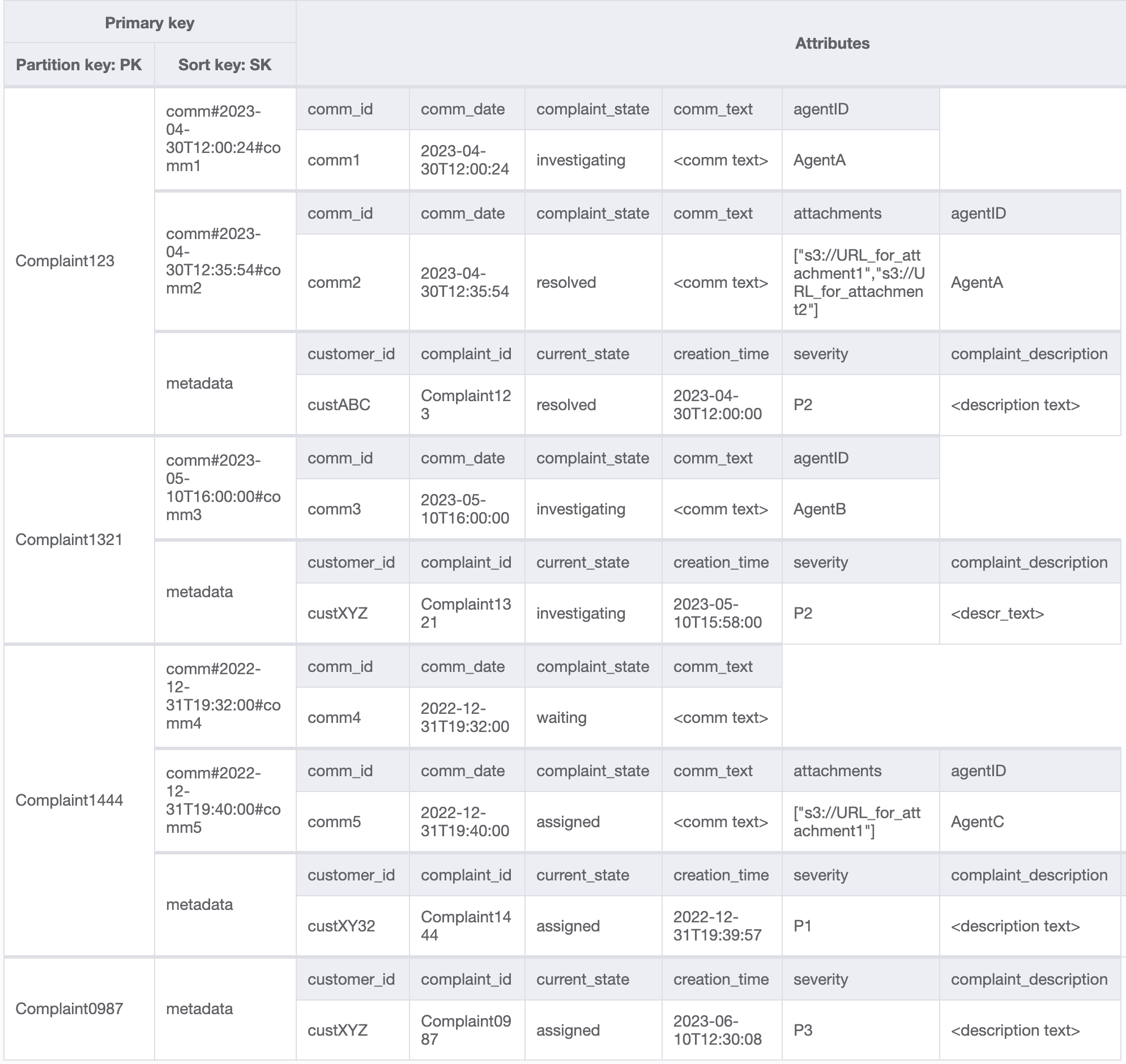
ステップ 4: アクセスパターン 8 (getAComplaintbyCustomerIDAndComplaintID) と 9 (getAllComplaintsByCustomerID) に対処する
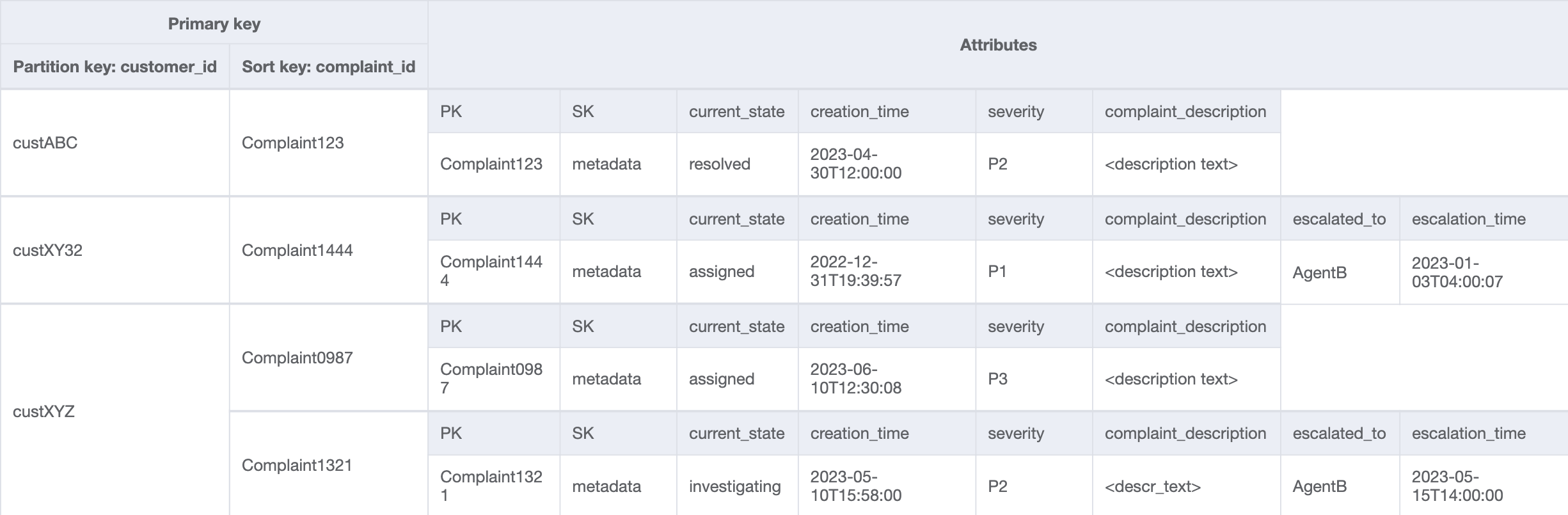
アクセスパターン 8 (getAComplaintbyCustomerIDAndComplaintID) と 9 (getAllComplaintsByCustomerID) は、新しい検索条件 CustomerID を導入します。これを既存のテーブルから取得するには、すべてのデータを読み取って当の CustomerID の関連項目をフィルタリングするために、コストの高い Scan が必要になります。この検索をより効率的にするには、CustomerID をパーティションキーとしてグローバルセカンダリインデックス (GSI) を作成できます。顧客と苦情の 1 対多リレーションシップおよびアクセスパターン 9 (getAllComplaintsByCustomerID) を考慮すると、ComplaintID がソートキーの適切な候補となります。
GSI のデータは次のようになります。
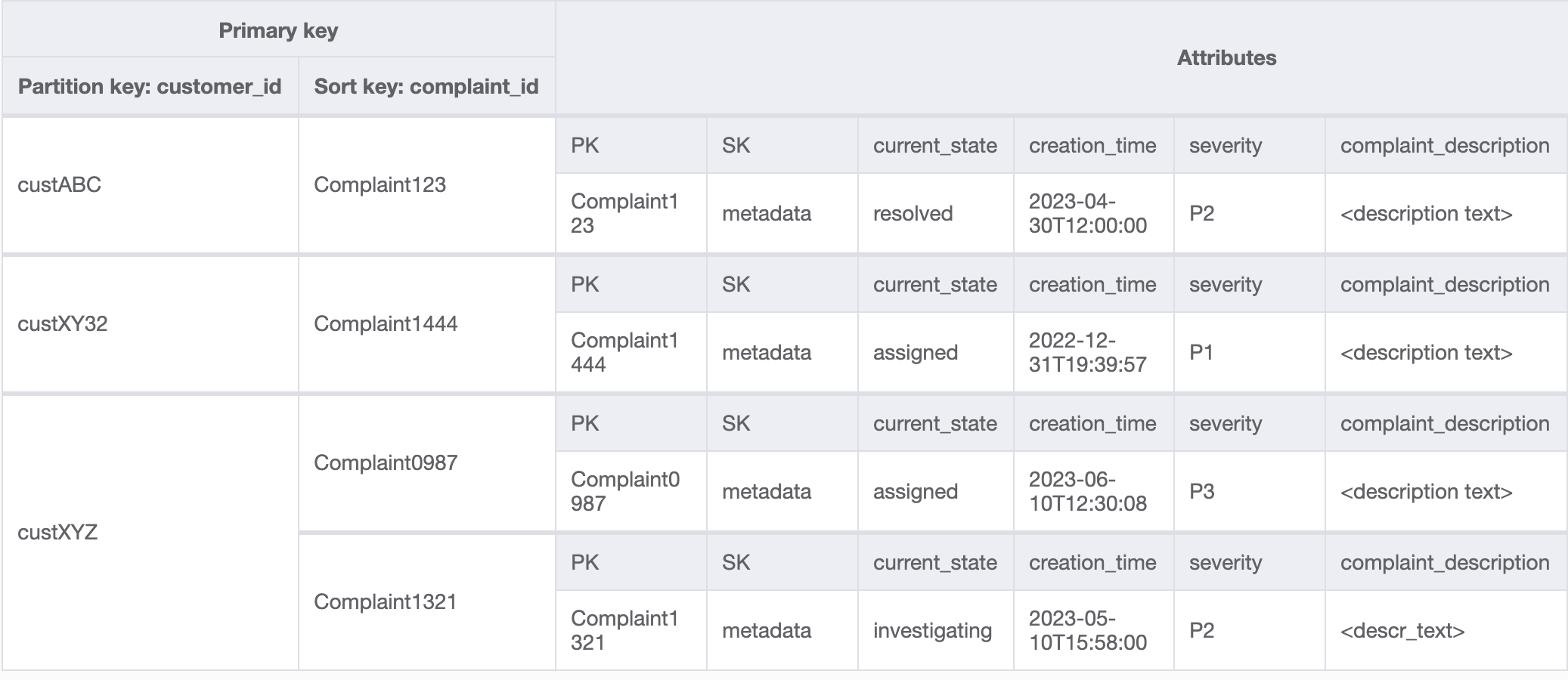
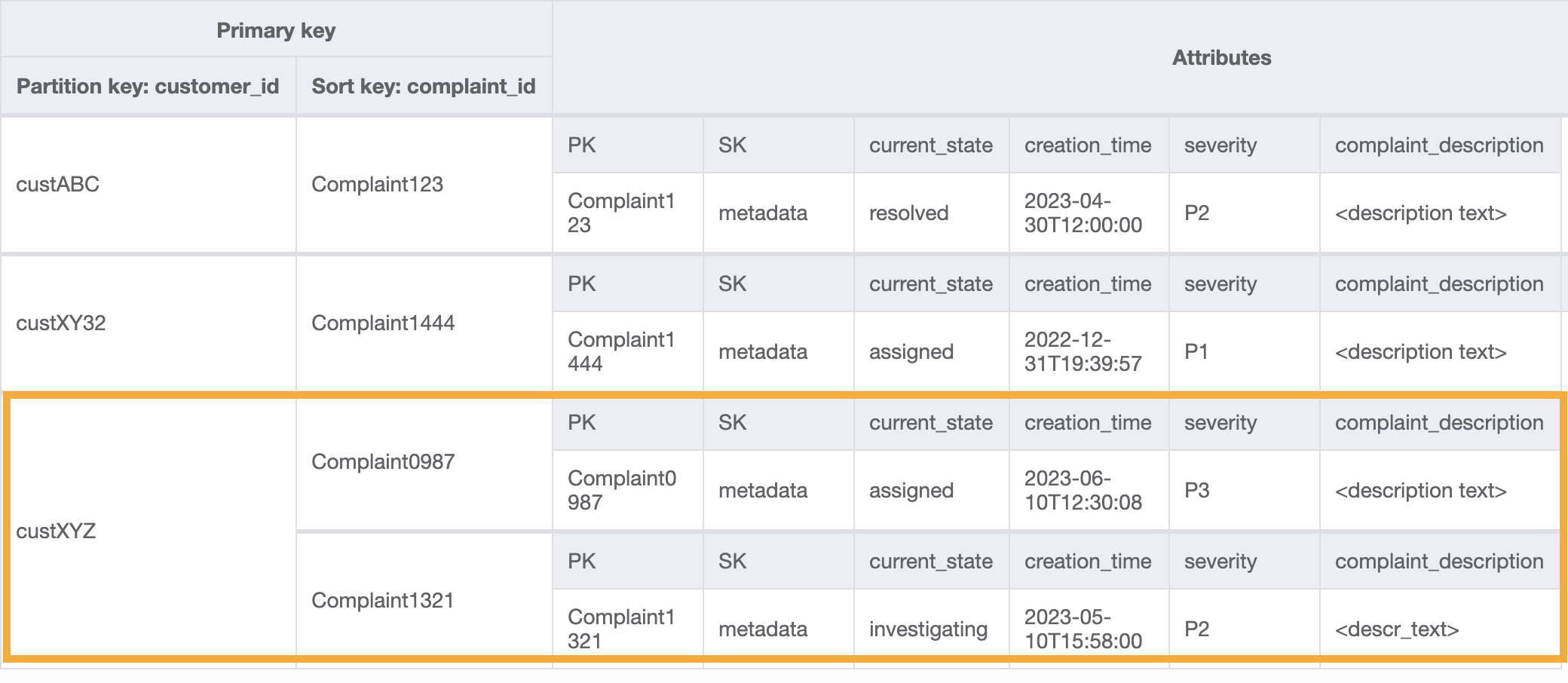
この GSI のクエリ例はアクセスパターン 8 (getAComplaintbyCustomerIDAndComplaintID) で customer_id=custXYZ、sort key=Complaint1321 となります。結果は次のようになります。
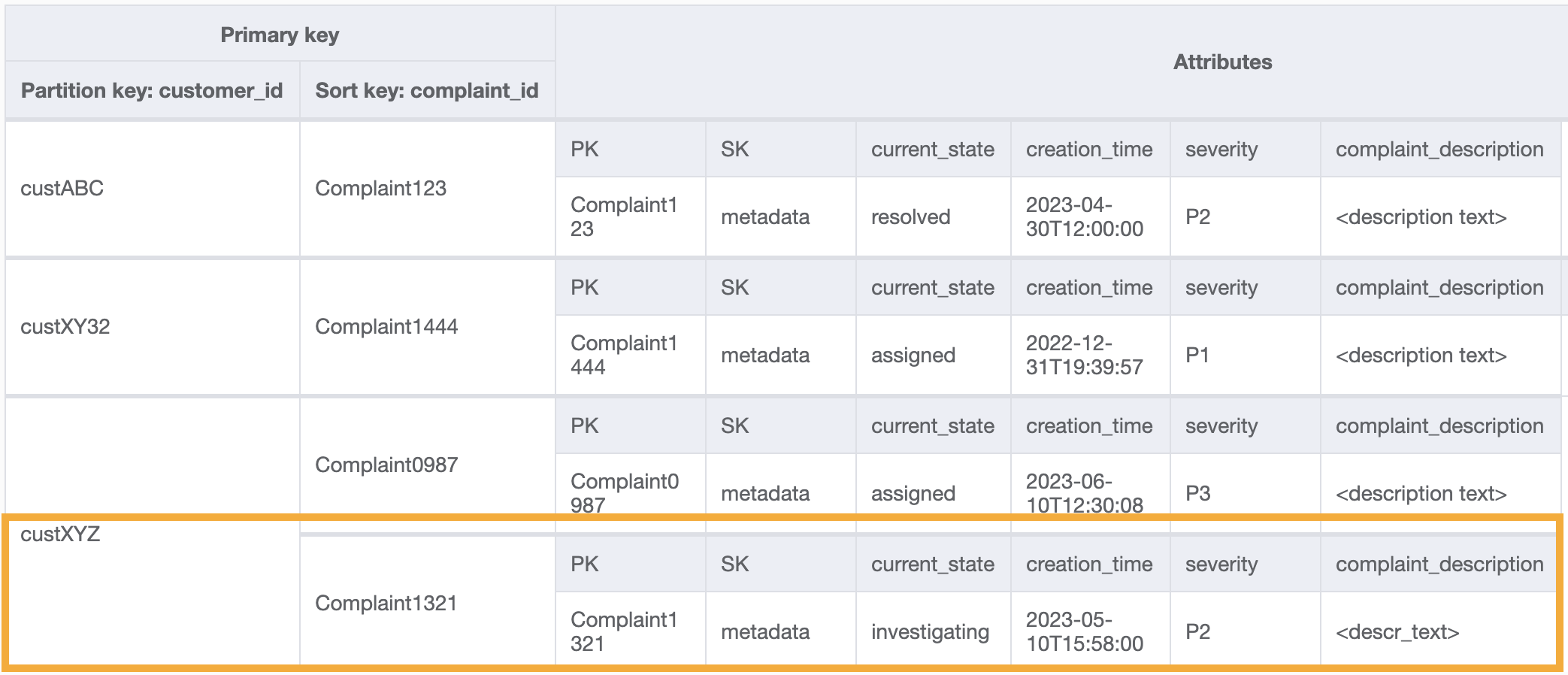
アクセスパターン 9 (getAllComplaintsByCustomerID) でお客様の苦情をすべて取得する場合、GSI のクエリはパーティションキー条件が customer_id=custXYZ になります。結果は次のようになります。
ステップ 5: アクセスパターン 10 (escalateComplaintByComplaintID) に対処する
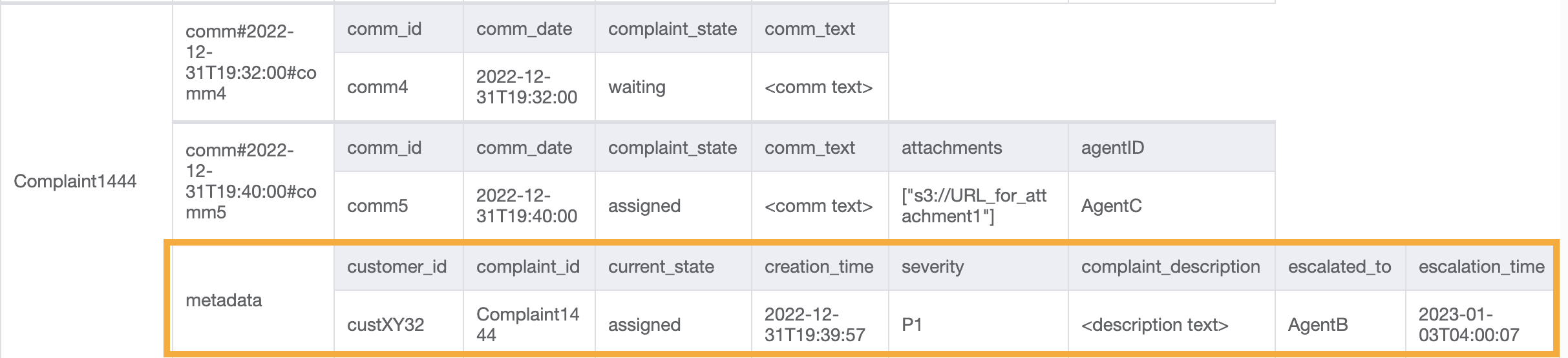
このアクセスでは、エスカレーションのディメンションを導入します。苦情をエスカレーションするには、UpdateItem を使用して escalated_to や escalation_time などの属性を既存の苦情メタデータ項目に追加します。DynamoDB のスキーマ設計は柔軟であるため、キー以外の属性のセットをさまざまな項目間で均一にすることも、個別にすることもできます。次の例を参照してください。
UpdateItem with PK=Complaint1444, SK=metadata
ステップ 6: アクセスパターン 11 (getAllEscalatedComplaints) と 12 (getEscalatedComplaintsByAgentID) に対処する
データセット全体からエスカレーションされると予想される苦情はほんの一握りです。したがって、エスカレーション関連の属性にインデックスを作成すると、効率的な検索と費用対効果の高い GSI ストレージが実現します。これを実現するには、スパースインデックス手法を活用できます。パーティションキーを escalated_to、ソートキーを escalation_time とする GSI は、次のようになります。

アクセスパターン 11 (getAllEscalatedComplaints) ですべてのエスカレーションされた苦情を取得するには、この GSI を単にスキャンします。このスキャンは、GSI のサイズにより、パフォーマンスとコスト効率が向上することに注意してください。特定のエージェント (アクセスパターン 12 (getEscalatedComplaintsByAgentID)) でエスカレーションされた苦情を取得する場合は、パーティションキーを escalated_to=agentID とし、ScanIndexForward を False に設定して新しいものから古いものへの順に取得します。
ステップ 7: アクセスパターン 13 (getCommentsByAgentID) に対処する
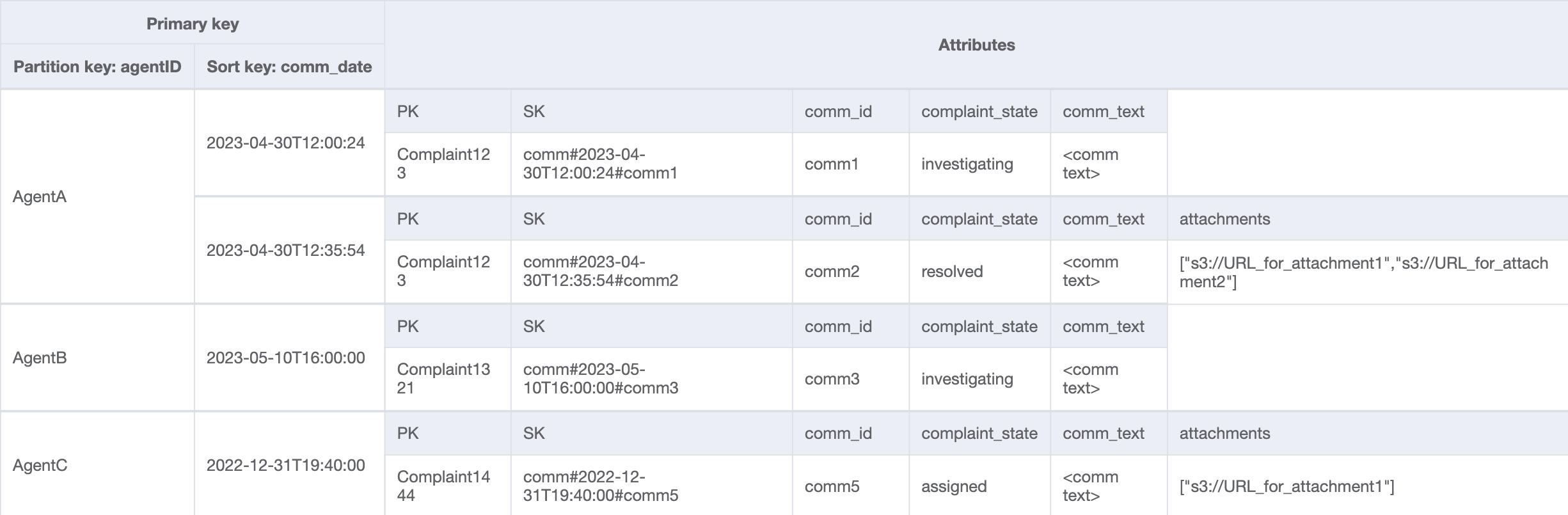
最後のアクセスパターンでは、新しいディメンション AgentID によるルックアップを実行する必要があります。また、2 つの日付間のコメントを読み取るには時間ベースの順序付けも必要であるため、パーティションキーを agent_id、ソートキーを comm_date として GSI を作成します。この GSI のデータは次のようになります。
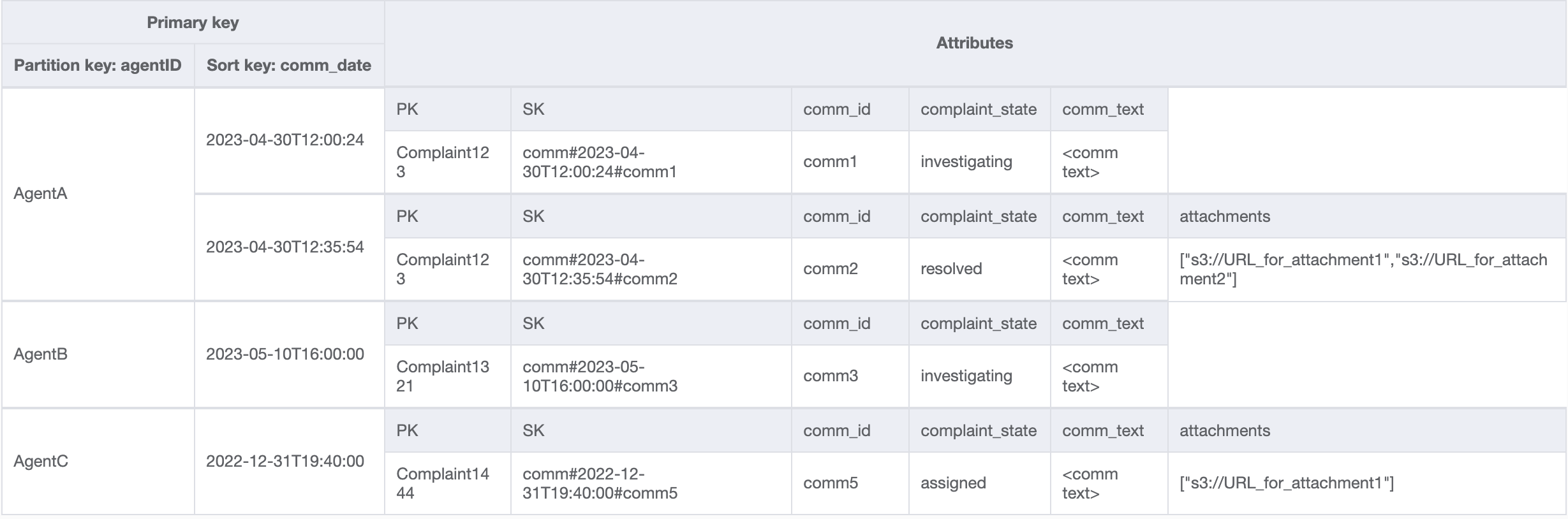
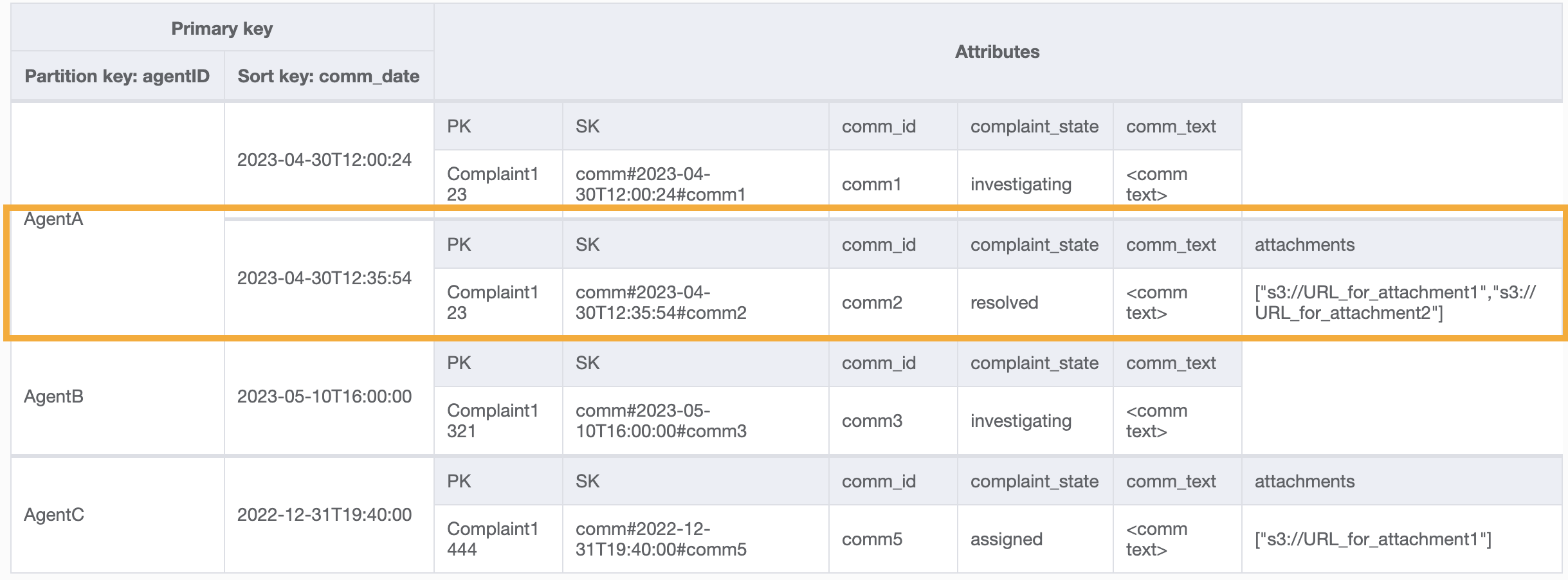
この GSI のクエリの例は partition key agentID=AgentA および sort key=comm_date between (2023-04-30T12:30:00, 2023-05-01T09:00:00) となり、その結果は次のようになります。
すべてのアクセスパターンと各アクセスパターンにスキーマ設計で対処する方法を次の表にまとめています。
| アクセスパターン | ベーステーブル/GSI/LSI | Operation | パーティションキー値 | ソートキー値 | その他の条件/フィルター |
|---|---|---|---|---|---|
| createComplaint | ベーステーブル | PutItem | PK=complaint_id | SK=metadata | |
| updateComplaint | ベーステーブル | UpdateItem | PK=complaint_id | SK=metadata | |
| updateSeveritybyComplaintID | ベーステーブル | UpdateItem | PK=complaint_id | SK=metadata | |
| getComplaintByComplaintID | ベーステーブル | GetItem | PK=complaint_id | SK=metadata | |
| addCommentByComplaintID | ベーステーブル | TransactWriteItems | PK=complaint_id | SK=metadata, SK=comm#comm_date#comm_id | |
| getAllCommentsByComplaintID | ベーステーブル | クエリ | PK=complaint_id | SK begins_with "comm#" | |
| getLatestCommentByComplaintID | ベーステーブル | クエリ | PK=complaint_id | SK begins_with "comm#" | scan_index_forward=False, Limit 1 |
| getAComplaintbyCustomerIDAndComplaintID | Customer_complaint_GSI | クエリ | customer_id=customer_id | complaint_id = complaint_id | |
| getAllComplaintsByCustomerID | Customer_complaint_GSI | クエリ | customer_id=customer_id | 該当なし | |
| escalateComplaintByComplaintID | ベーステーブル | UpdateItem | PK=complaint_id | SK=metadata | |
| getAllEscalatedComplaints | Escalations_GSI | Scan | 該当なし | 該当なし | |
| getEscalatedComplaintsByAgentID (新しいものから古いものへの順) | Escalations_GSI | クエリ | escalated_to=agent_id | 該当なし | scan_index_forward=False |
| getCommentsByAgentID (2 つの日付間) | Agents_Comments_GSI | クエリ | agent_id=agent_id | SK between (date1, date2) |
苦情管理システムの最終スキーマ
最終的なスキーマ設計は次のとおりです。このスキーマ設計を JSON ファイルとしてダウンロードするには、GitHub の DynamoDB の例
ベーステーブル
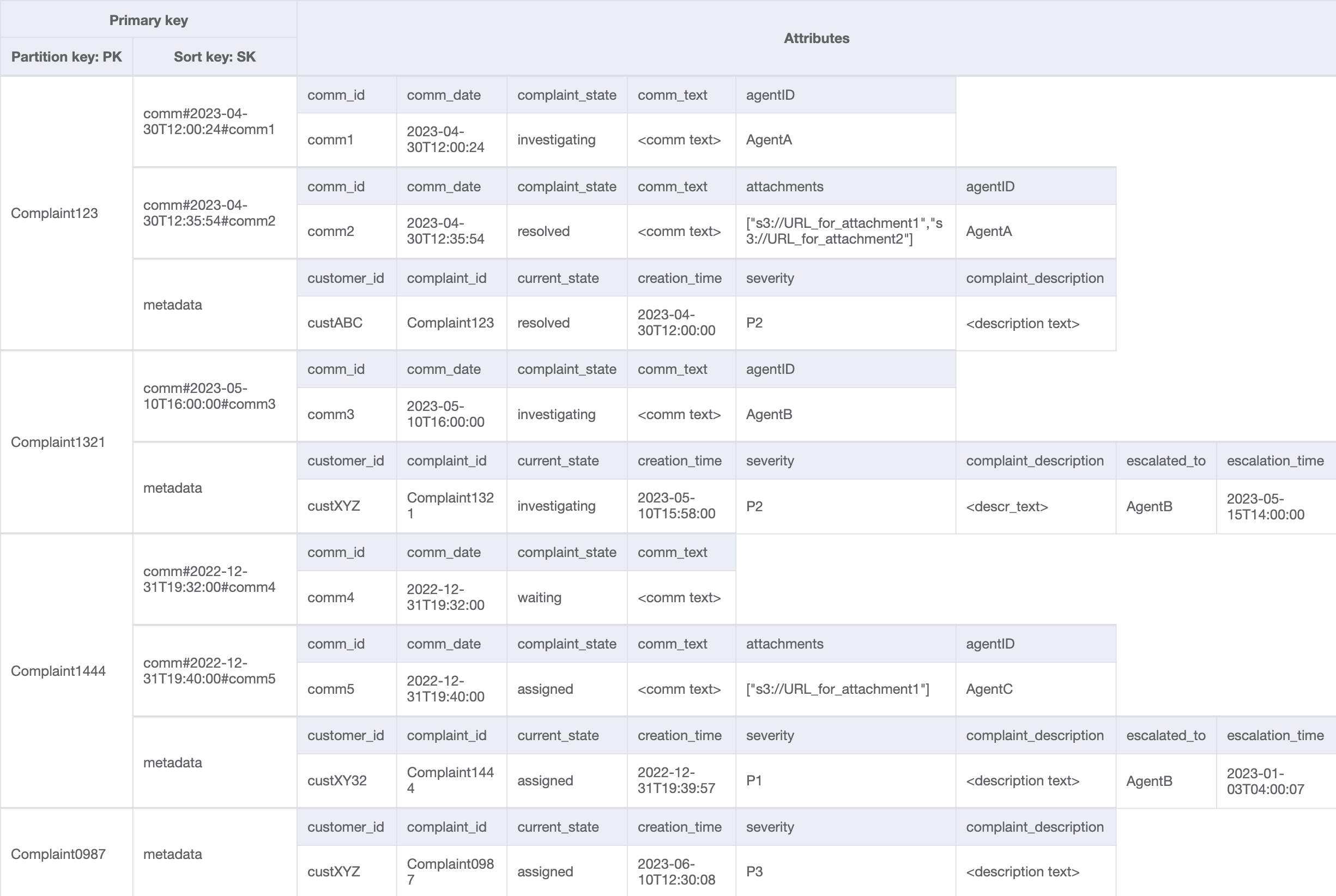
Customer_Complaint_GSI
Escalations_GSI

Agents_Comments_GSI
このスキーマ設計での NoSQL Workbench の使用
この最終スキーマを、DynamoDB のデータモデリング、データ視覚化、クエリ開発機能を提供するビジュアルツールである NoSQL Workbench にインポートして、新しいプロジェクトを詳しく調べたり編集したりできます。使用を開始するには、次の手順に従います。
-
NoSQL Workbench をダウンロードします。詳細については、「DynamoDB 用の NoSQL Workbench のダウンロード」を参照してください。
-
上記の JSON スキーマファイルをダウンロードします。このファイルは既に NoSQL Workbench モデル形式になっています。
-
JSON スキーマファイルを NoSQL Workbench にインポートします。詳細については、「既存のデータモデルのインポート」を参照してください。
-
NOSQL Workbench にインポートしたら、データモデルを編集できます。詳細については、「既存のデータモデルの編集」を参照してください。
