DynamoDB と Amazon Managed Streaming for Apache Kafka の統合
Amazon Managed Streaming for Apache Kafka (Amazon MSK) では、フルマネージドで可用性の高い Apache Kafka サービスを使用して、ストリーミングデータをリアルタイムで簡単に取り込み、処理できます。
Apache Kafka
これらの機能により、Apache Kafka はリアルタイムストリーミングデータパイプラインの構築によく使用されます。データパイプラインは、あるシステムから別のシステムにデータを確実に処理して移動し、それぞれが異なるユースケースをサポートする複数のデータベースの使用を容易にすることで、目的別データベース戦略を採用する上で重要な部分となる可能性があります。
Amazon DynamoDB は、キーバリューまたはドキュメントデータモデルを使用し、一貫した 1 桁ミリ秒のパフォーマンスで無制限のスケーラビリティを求めるアプリケーションをサポートするために、これらのデータパイプラインで一般的なターゲットとなっています。
仕組み
Amazon MSK と DynamoDB の統合では、Lambda 関数を使用して Amazon MSK からのレコードを消費し、DynamoDB に書き込みます。
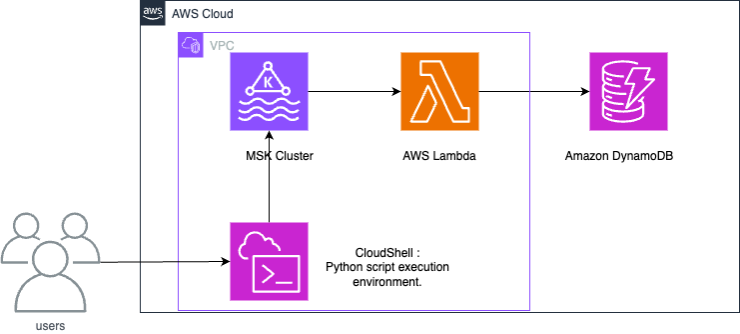
Lambda は、Amazon MSK からの新しいメッセージを内部的にポーリングした後、ターゲットの Lambda 関数を同期的に呼び出します。Lambda 関数のイベントペイロードには、Amazon MSK からのメッセージのバッチが含まれています。Amazon MSK と DynamoDB の統合のために、Lambda 関数はこれらのメッセージを DynamoDB に書き込みます。
Amazon MSK と DynamoDB の統合を設定する
注記
この例で使用されているリソースは、次の GitHub リポジトリ
以下の手順は、Amazon MSK と Amazon DynamoDB 間のサンプル統合を設定する方法を示しています。この例では、モノのインターネット (IoT) デバイスによって生成され、Amazon MSK に取り込まれたデータを表します。データが Amazon MSK に取り込まれると、Apache Kafka と互換性のある分析サービスまたはサードパーティーツールと統合できるため、さまざまな分析ユースケースが可能になります。DynamoDB を統合することで、個々のデバイスレコードのキー値も検索できます。
この例では、Python スクリプトが IoT センサーデータを Amazon MSK に書き込む方法を示します。次に、Lambda 関数はパーティションキー「deviceid」を持つ項目を DynamoDB に書き込みます。
提供された CloudFormation テンプレートは、Amazon S3 バケット、Amazon VPC、Amazon MSK クラスター、データオペレーションをテストするための AWS CloudShell のリソースを作成します。
テストデータを生成するには、Amazon MSK トピックを作成し、DynamoDB テーブルを作成します。マネジメントコンソールからセッションマネージャーを使用して CloudShell のオペレーティングシステムにログインし、Python スクリプトを実行できます。
CloudFormation テンプレートを実行したら、次のオペレーションを実行して、このアーキテクチャの構築を完了できます。
-
CloudFormation テンプレート
S3bucket.yamlを実行して、S3 バケットを作成します。以降のスクリプトまたはオペレーションについては、同じリージョンで実行してください。CloudFormation スタックの名前としてForMSKTestS3を入力します。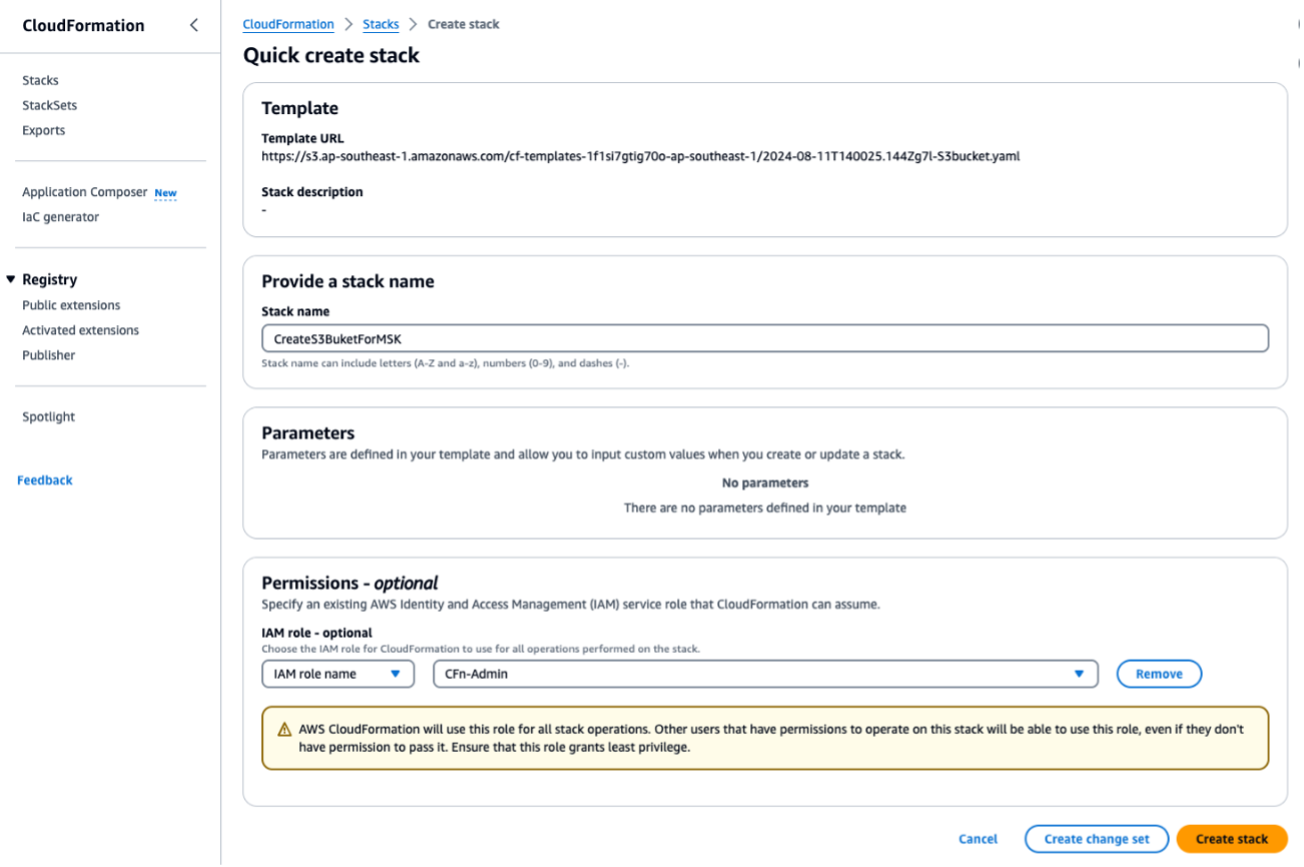
これが完了したら、出力の下にある S3 バケット名出力を書き留めます。ステップ 3 でこの S3 バケット名出力が必要になります。

-
作成した S3 バケットにダウンロードした ZIP ファイル
fromMSK.zipをアップロードします。
-
CloudFormation のテンプレート
VPC.yamlを実行して、VPC、Amazon MSK クラスター、Lambda 関数を作成します。パラメータ入力画面で S3 バケットを求められたら、ステップ 1 で作成した S3 バケット名を入力します。CloudFormation スタック名をForMSKTestVPCに設定します。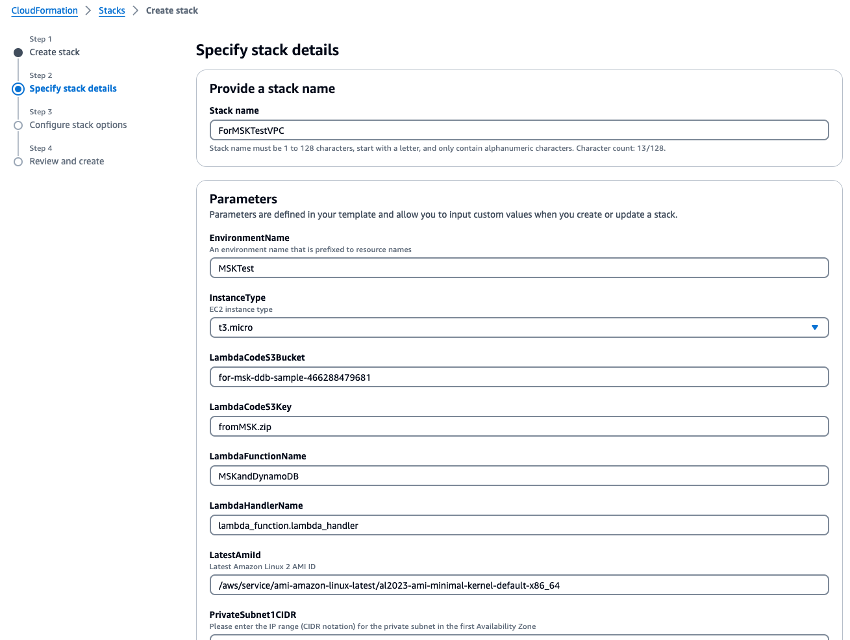
-
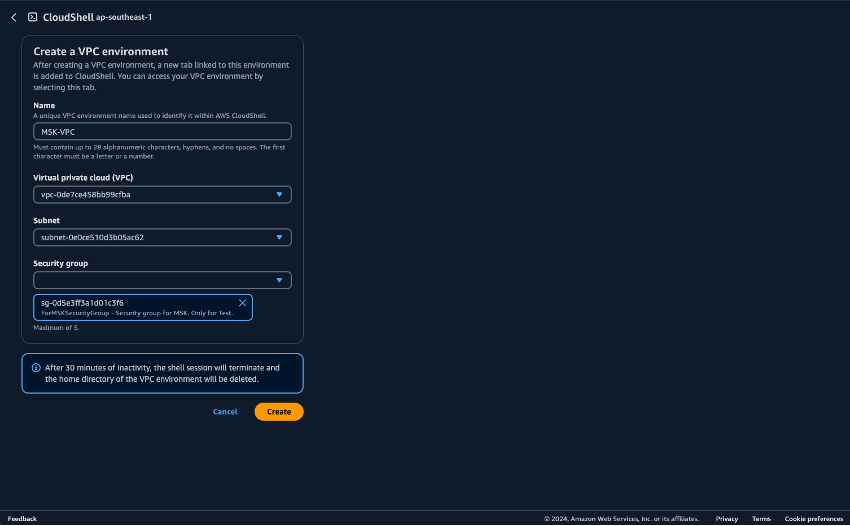
CloudShell で Python スクリプトを実行するための環境を準備します。AWS マネジメントコンソール で CloudShell を使用できます。CloudShell の使用の詳細については、「AWS CloudShell の開始方法」を参照してください。CloudShell を起動したら、Amazon MSK クラスターに接続するために作成した VPC に属する CloudShell を作成します。プライベートサブネットに CloudShell を作成します。以下のフィールドに入力します。
-
名前 - 任意の名前に設定できます。例: MSK-VPC
-
VPC - MSKTest を選択します。
-
サブネット - MSKTest プライベートサブネット (AZ1) を選択します。
-
SecurityGroup - ForMSKSecurityGroup を選択します。
![[環境を開く] オプションが表示された ap-southeast-1 環境を示す CloudShell インターフェイス。](images/msk-dynamodb-cshell-1.png)
プライベートサブネットに属する CloudShell が開始されたら、次のコマンドを実行します。
pip install boto3 kafka-python aws-msk-iam-sasl-signer-python -
-
S3 バケットから Python スクリプトをダウンロードします。
aws s3 cp s3://[YOUR-BUCKET-NAME]/pythonScripts.zip ./ unzip pythonScripts.zip -
マネジメントコンソールを確認し、Python スクリプトでブローカー URL とリージョン値の環境変数を設定します。マネジメントコンソールで Amazon MSK クラスターブローカーエンドポイントを確認します。

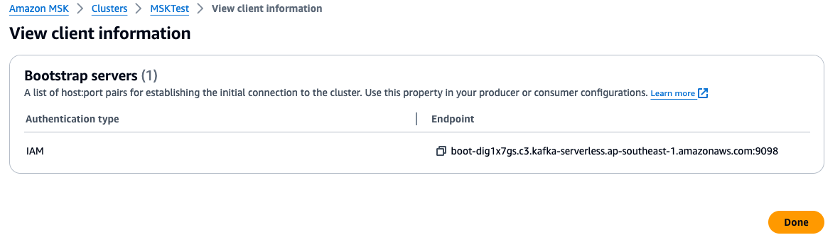
-
CloudShell で環境変数を設定します。米国西部 (オレゴン) を使用している場合:
export AWS_REGION="us-west-2" export MSK_BROKER="boot-YOURMSKCLUSTER.c3.kafka-serverless.ap-southeast-1.amazonaws.com:9098" -
以下の Python スクリプトを実行します。
Amazon MSK トピックを作成します。
python ./createTopic.pyDynamoDB テーブルを作成します。
python ./createTable.pyAmazon MSK トピックにテストデータを書き込みます。
python ./kafkaDataGen.py -
作成した Amazon MSK、Lambda、DynamoDB リソースの CloudWatch メトリクスを確認し、DynamoDB Data Explorer を使用して
device_statusテーブルに保存されているデータを検証して、すべてのプロセスが正しく実行されたことを確認します。各プロセスがエラーなしで実行される場合は、CloudShell から Amazon MSK に書き込まれたテストデータも DynamoDB に書き込まれていることを確認できます。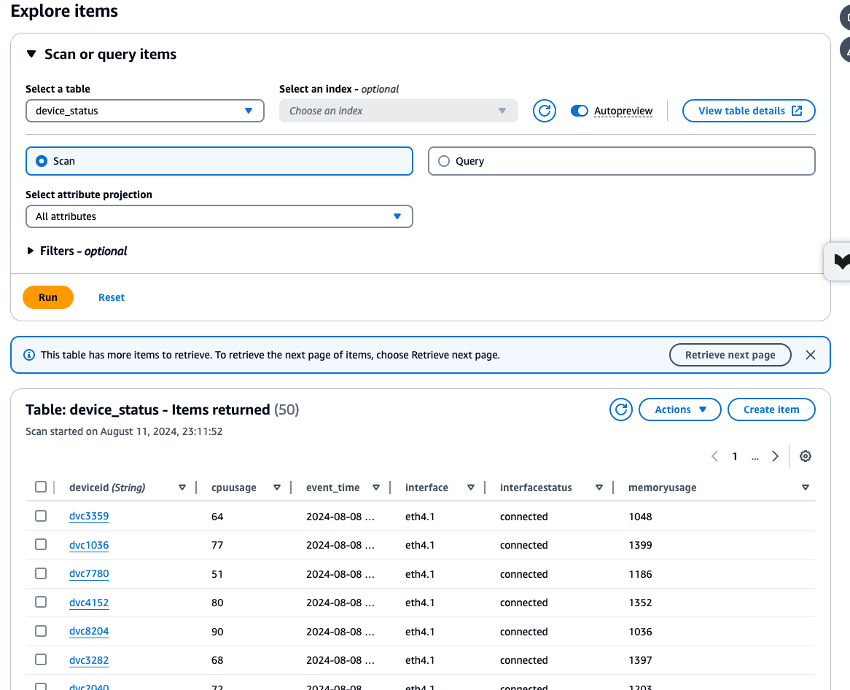
-
この例が完了したら、このチュートリアルで作成したリソースを削除します。
ForMSKTestS3とForMSKTestVPCの 2 つの CloudFormation スタックを削除します。スタックの削除が正常に完了すると、すべてのリソースが削除されます。
次のステップ
注記
この例に従ってリソースを作成した場合は、予期しない料金が発生しないように、リソースを削除してください。
統合では、Amazon MSK と DynamoDB をリンクして、ストリームデータを OLTP ワークロードをサポートできるようにするアーキテクチャを特定しました。ここから、DynamoDB と Amazon OpenSearch を連携することで、より複雑な検索を実現できます。より複雑なイベント駆動型のニーズには EventBridge との統合を検討し、スループットを高め、レイテンシー要件を低くするには Amazon Managed Service for Apache Flink などの拡張機能を検討してください。
