DynamoDB でのソーシャルネットワークのスキーマ設計
ソーシャルネットワークのビジネスユースケース
このユースケースでは、DynamoDB をソーシャルネットワークとして使用する方法について説明します。ソーシャルネットワークは、さまざまなユーザーが相互に交流できるオンラインサービスです。これから設計するソーシャルネットワークでは、ユーザーの投稿、フォロワー、フォローしている相手、およびフォローしている相手による投稿で構成されるタイムラインをユーザーが表示できるようにします。このスキーマ設計のアクセスパターンは以下のとおりです。
-
特定のユーザー ID のユーザー情報を取得する。
-
特定のユーザー ID のフォロワーリストを取得する。
-
特定のユーザー ID のフォローリストを取得する。
-
特定のユーザー ID の投稿リストを取得する。
-
特定の投稿 ID による投稿に「いいね!」したユーザーのリストを取得する。
-
特定の投稿 ID の「いいね!」数を取得する。
-
特定のユーザー ID のタイムラインを取得する。
ソーシャルネットワークエンティティ関係図
これは、ソーシャルネットワークのスキーマ設計に使用するエンティティ関係図 (ERD) です。
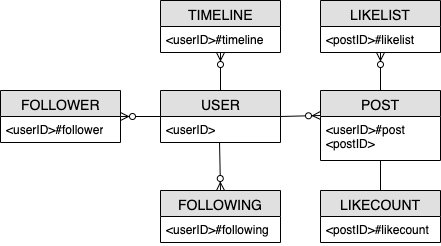
ソーシャルネットワークのアクセスパターン
これらは、ソーシャルネットワークのスキーマ設計のために検討するアクセスパターンです。
-
getUserInfoByUserID -
getFollowerListByUserID -
getFollowingListByUserID -
getPostListByUserID -
getUserLikesByPostID -
getLikeCountByPostID -
getTimelineByUserID
ソーシャルネットワークのスキーマ設計の進化
DynamoDB は NoSQL データベースであるため、結合 (複数のデータベースのデータを結合する操作) は実行できません。DynamoDB に慣れていないお客様は、必要がない場合でも、リレーショナルデータベース管理システム (RDBMS) の設計理念 (エンティティごとにテーブルを作成するなど) を DynamoDB に適用する可能性があります。DynamoDB のシングルテーブル設計の目的は、アプリケーションのアクセスパターンに従って事前に結合された形式でデータを書き込み、追加の計算を行わずにそのデータをすぐに使用することにあります。詳細については、「DynamoDB のシングルテーブル設計とマルチテーブル設計
それでは、すべてのアクセスパターンに対処するためにスキーマ設計をどのように進化させるかをステップ別に見ていきましょう。
ステップ 1: アクセスパターン 1 (getUserInfoByUserID) に対処する
特定のユーザーに関する情報を取得するには、キー条件を PK=<userID> にしてベーステーブルに Query を実行する必要があります。クエリ操作では、結果をページ分割できます。これは、ユーザーに多数のフォロワーがいる場合に便利です。Query の詳細については、「DynamoDB のテーブルに対するクエリの実行」を参照してください。
この例では、ユーザーの「count」と「info」の 2 種類のデータを追跡します。ユーザーの「count」は、ユーザーのフォロワー数、フォローしている相手の数、相手が作成した投稿の数を反映します。ユーザーの「info」は、名前などの個人情報を反映します。
これら 2 種類のデータは、以下の 2 つの項目で表されます。ソートキー (SK) に「count」が含まれている項目は、「info」が含まれている項目よりも変更される可能性が高くなります。DynamoDB は、更新前と更新後に表示される項目のサイズを考慮し、消費されるプロビジョニングされたスループットに、これらの項目サイズの大きい方を反映します。したがって、項目の属性の一部だけを更新した場合でも、UpdateItem は、プロビジョニングされたスループットの総量 (前後の項目サイズの大きい方) を消費します。単一の Query 操作で項目を取得し、UpdateItem を使用して既存の数値属性の加算または減算ができます。

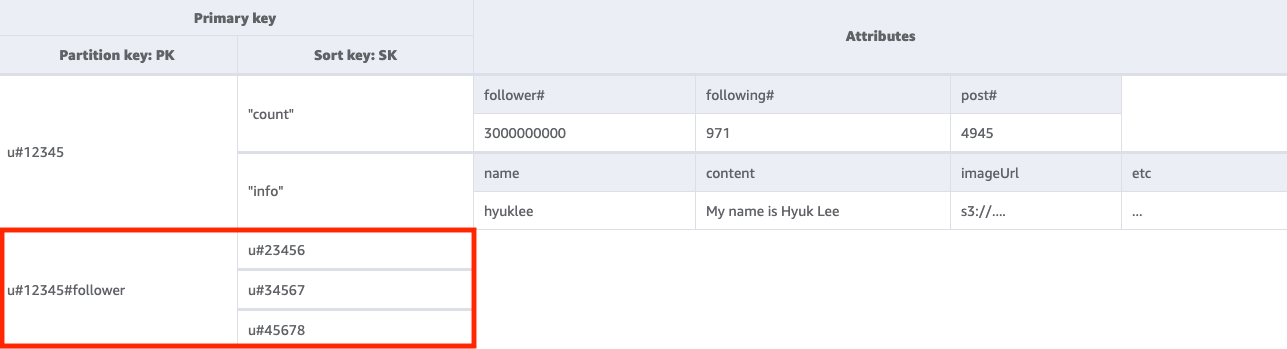
ステップ 2: アクセスパターン 2 (getFollowerListByUserID) に対処する
特定のユーザーのフォロワーリストを取得するには、キー条件を PK=<userID>#follower にしてベーステーブルに Query を実行する必要があります。
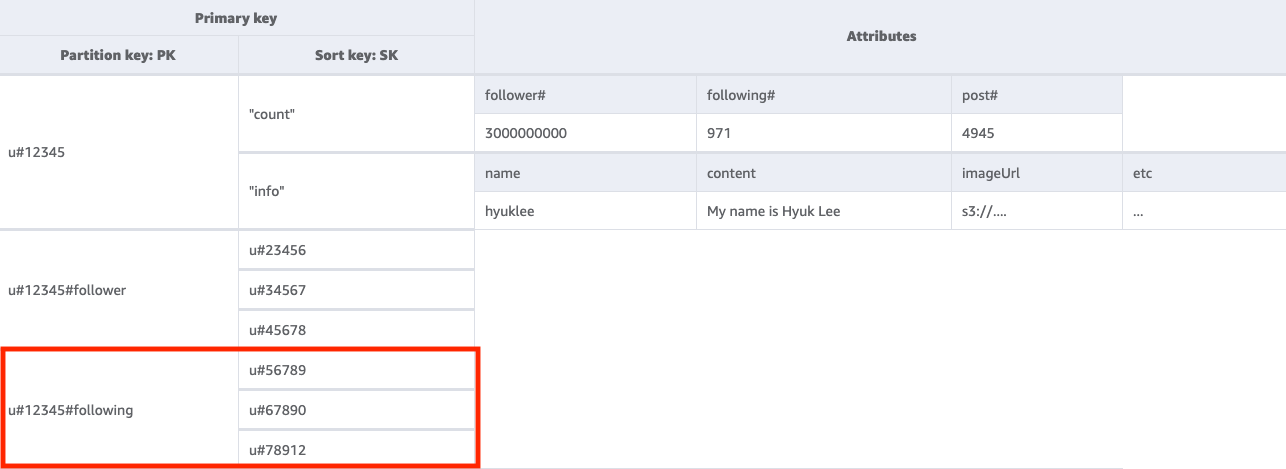
ステップ 3: アクセスパターン 3 (getFollowingListByUserID) に対処する
特定のユーザーがフォローしている相手のリストを取得するには、キー条件を PK=<userID>#following にしてベーステーブルに Query を実行する必要があります。次に、TransactWriteItems オペレーションを使用して複数のリクエストをグループ化し、以下のことを実行できます。
-
ユーザー A をユーザー B のフォロワーリストに追加し、ユーザー B のフォロワー数を 1 つ増やします。
-
ユーザー B をユーザー A のフォロワーリストに追加し、ユーザー A のフォロワー数を 1 つ増やします
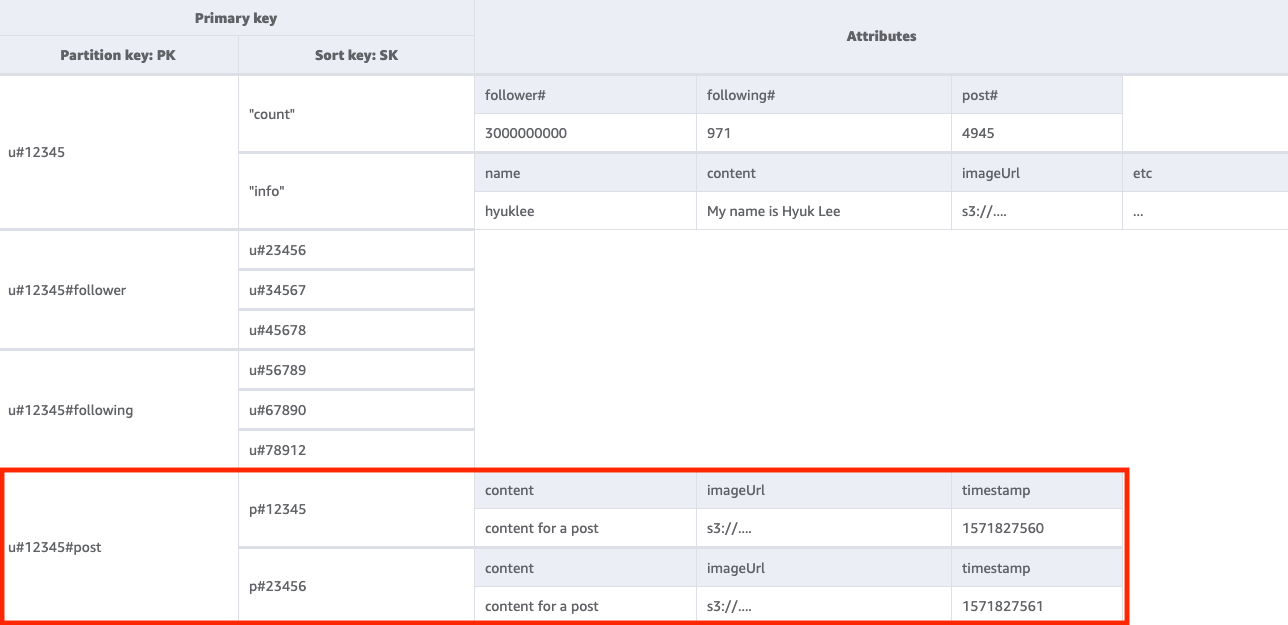
ステップ 4: アクセスパターン 4 (getPostListByUserID) に対処する
特定のユーザーが作成した投稿のリストを取得するには、キー条件を PK=<userID>#post にしてベーステーブルに Query を実行する必要があります。ここで注意すべき重要な点の 1 つは、ユーザーの postID はインクリメンタルでなければならないということです。つまり、2 番目の PostID 値は 1 番目の PostID 値よりも大きくなければなりません (ユーザーは自分の投稿を並べ替えて表示したいはずです)。これを行うには、Universally Unique Lexicographically Sortable Identifier (ULID) などの時間値に基づいて postID を生成できます。
ステップ 5: アクセスパターン 5 (getUserLikesByPostID) に対処する
特定のユーザーの投稿に「いいね!」を付けた人のリストを取得するには、キー条件を PK=<postID>#likelist にしてベーステーブルに Query を実行する必要があります。このアプローチは、アクセスパターン 2 (getFollowerListByUserID) とアクセスパターン 3 (getFollowingListByUserID) でフォロワーリストとフォローしている相手のリストを取得するときに使用したのと同じパターンです。
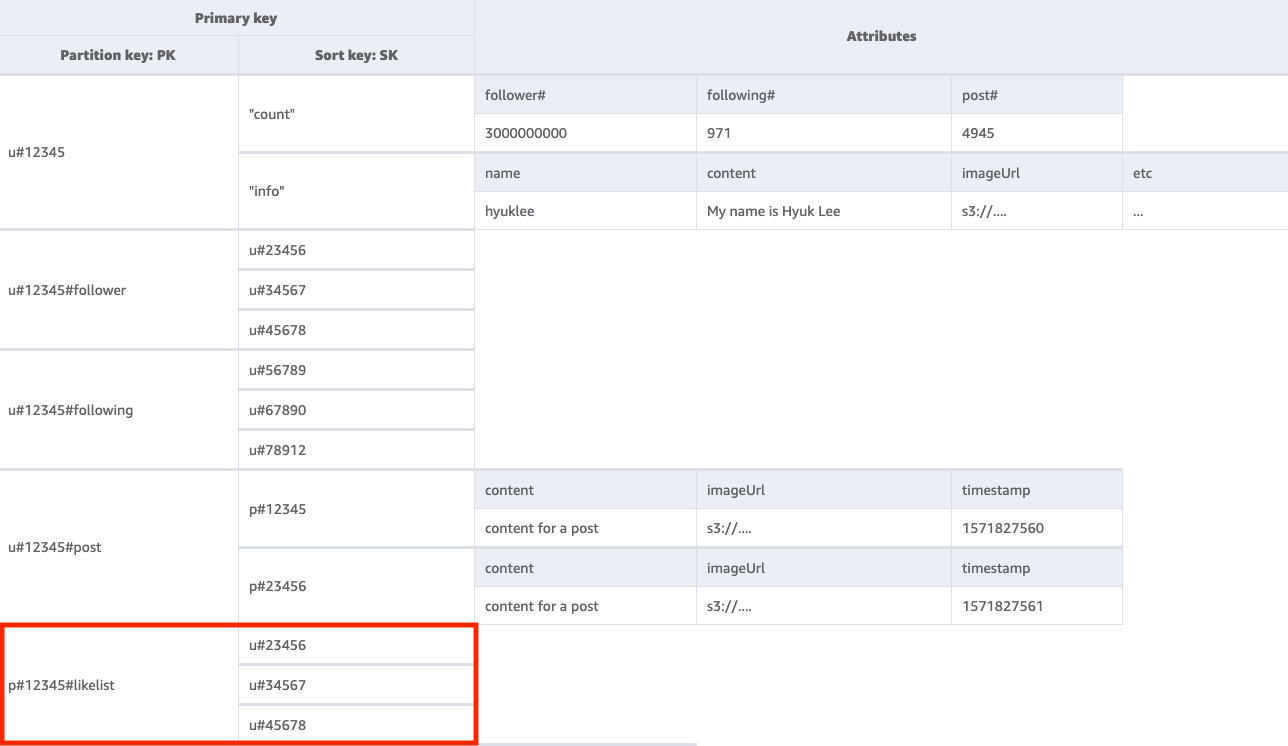
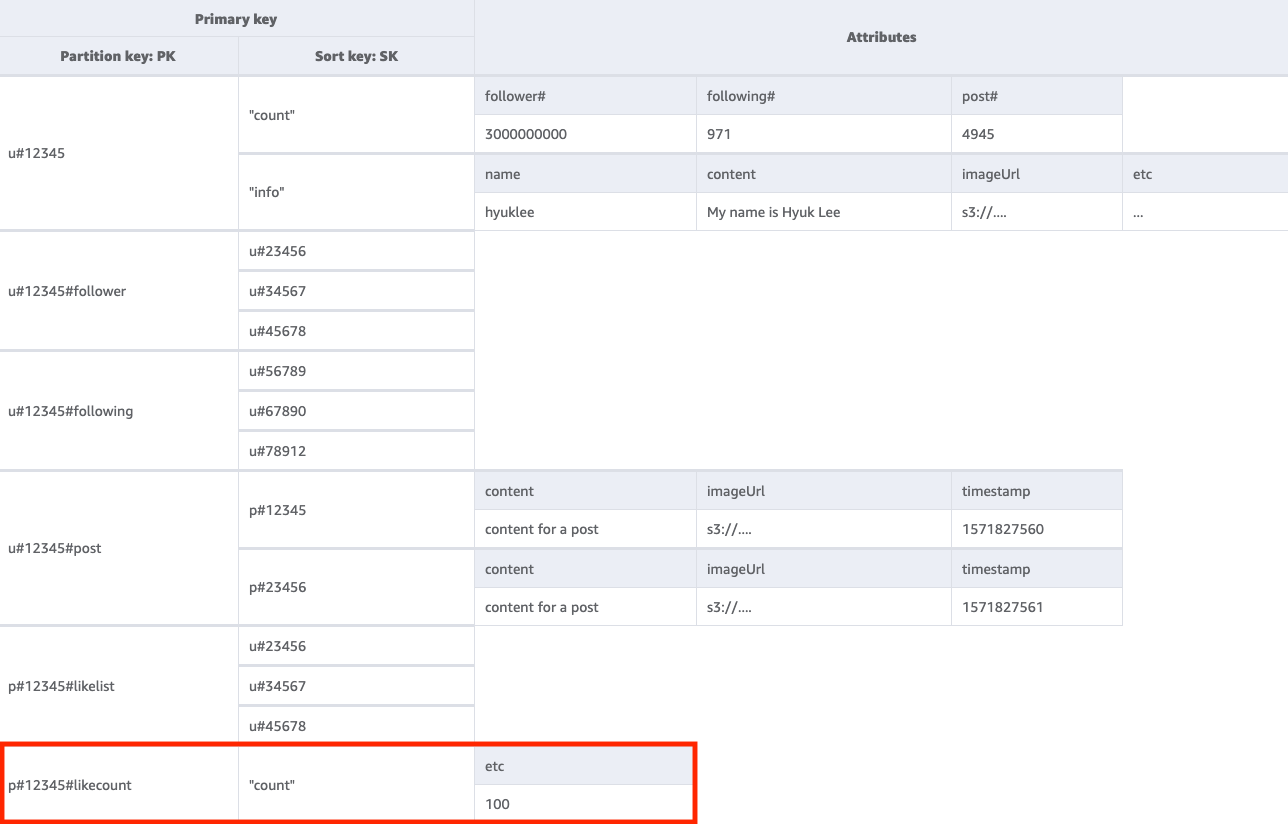
ステップ 6: アクセスパターン 6 (getLikeCountByPostID) に対処する
特定の投稿の「いいね!」の数を取得するには、キー条件を PK=<postID>#likecount にしてベーステーブルに GetItem 操作を実行する必要があります。このアクセスパターンでは、パーティションのスループットが 1 秒あたり 1000 WCU を超えるとスロットリングが発生するため、フォロワーの多いユーザー (有名人など) が投稿を作成するたびにスロットリングの問題が発生する可能性があります。この問題は DynamoDB が原因ではなく、DynamoDB がソフトウェアスタックの最後にあるため、DynamoDB に現れるだけです。
すべてのユーザーに「いいね!」の数を同時に表示することが本当に必要か、それとも時間の経過と共に徐々に表示できるかを評価する必要があります。一般的に、投稿の「いいね!」の数はすぐに 100% 正確である必要はありません。この戦略を実装するには、アプリケーションと DynamoDB の間にキューを置き、更新が定期的に行われるようにします。
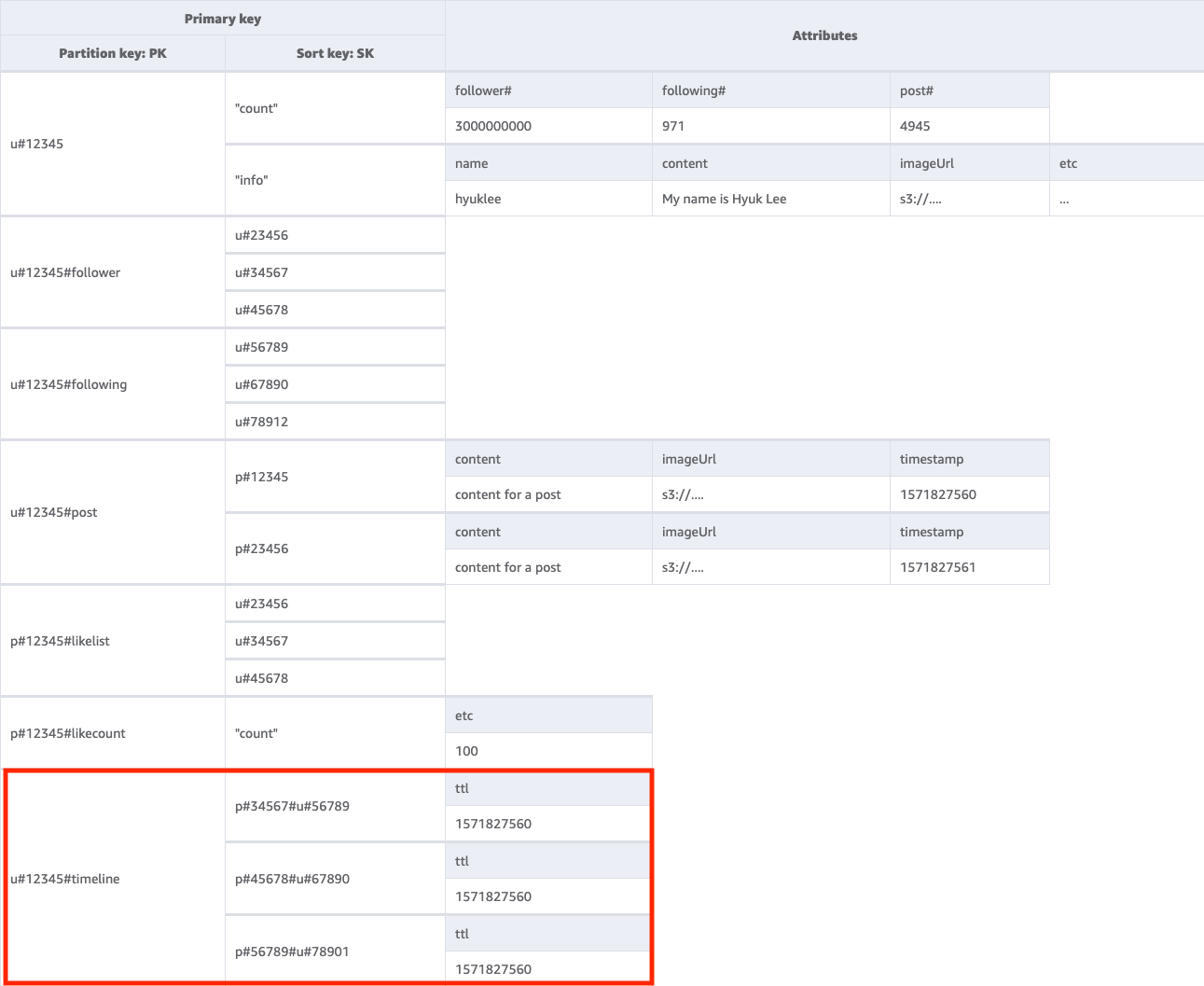
ステップ 7: アクセスパターン 7 (getTimelineByUserID) に対処する
特定のユーザーのタイムラインを取得するには、キー条件を PK=<userID>#timeline にしてベーステーブルに Query 操作を実行する必要があります。ユーザーのフォロワーが自分の投稿を同期的に表示する必要があるシナリオを考えてみましょう。ユーザーが投稿を書くたびに、フォロワーリストが読み取られ、useIDと postID がすべてのフォロワーのタイムラインキーにゆっくりと入力されます。次に、アプリケーションを起動すると、Query 操作でタイムラインキーを読み取り、新しい項目に対して BatchGetItem 操作を使用して userID と postID の組み合わせをタイムライン画面に入力できます。API コールでタイムラインを読み取ることはできませんが、投稿が頻繁に編集される可能性がある場合、これはより費用対効果の高いソリューションです。
タイムラインは最近の投稿を表示する場所なので、古い投稿をクリーンアップする方法が必要です。WCU を使用して削除する代わりに、DynamoDB の TTL 機能を使用して無料で削除できます。
すべてのアクセスパターンと各アクセスパターンにスキーマ設計で対処する方法を次の表にまとめています。
| アクセスパターン | ベーステーブル/GSI/LSI | Operation | パーティションキー値 | ソートキー値 | その他の条件/フィルター |
|---|---|---|---|---|---|
| getUserInfoByUserID | ベーステーブル | クエリ | PK=<userID> | ||
| getFollowerListByUserID | ベーステーブル | クエリ | PK=<userID>#follower | ||
| getFollowingListByUserID | ベーステーブル | クエリ | PK=<userID>#following | ||
| getPostListByUserID | ベーステーブル | クエリ | PK=<userID>#post | ||
| getUserLikesByPostID | ベーステーブル | クエリ | PK=<postID>#likelist | ||
| getLikeCountByPostID | ベーステーブル | GetItem | PK=<postID>#likecount | ||
| getTimelineByUserID | ベーステーブル | クエリ | PK=<userID>#timeline |
ソーシャルネットワークの最終スキーマ
これが最終的なスキーマ設計です。このスキーマ設計を JSON ファイルとしてダウンロードするには、GitHub の DynamoDB の例
ベーステーブル:
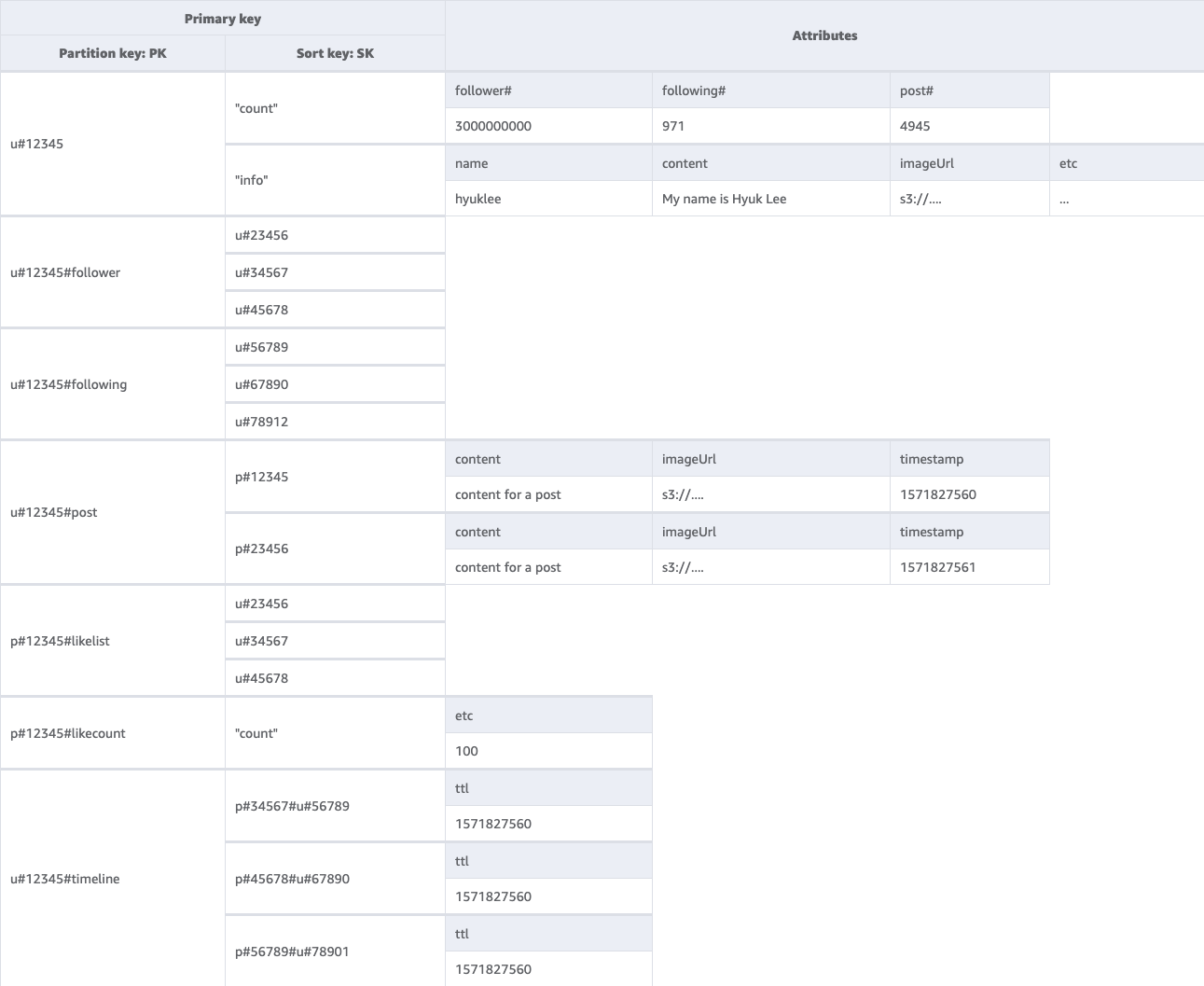
このスキーマ設計での NoSQL Workbench の使用
この最終スキーマを、DynamoDB のデータモデリング、データ視覚化、クエリ開発機能を提供するビジュアルツールである NoSQL Workbench にインポートして、新しいプロジェクトを詳しく調べたり編集したりできます。使用を開始するには、次の手順に従います。
-
NoSQL Workbench をダウンロードします。詳細については、「DynamoDB 用の NoSQL Workbench のダウンロード」を参照してください。
-
上記の JSON スキーマファイルをダウンロードします。このファイルは既に NoSQL Workbench モデル形式になっています。
-
JSON スキーマファイルを NoSQL Workbench にインポートします。詳細については、「既存のデータモデルのインポート」を参照してください。
-
NOSQL Workbench にインポートしたら、データモデルを編集できます。詳細については、「既存のデータモデルの編集」を参照してください。
