特定の時間枠内で最近のデータをクエリする必要がある場合、ほとんどの読み取りオペレーションにパーティションキーを提供する DynamoDB の要件が課題となる可能性があります。このようなシナリオに対処するには、書き込みシャーディングとグローバルセカンダリインデックス (GSI) の組み合わせを使用して、効果的なクエリパターンを実装できます。
このようなアプローチを採用すると、リソースを大量に使用し、コスト高となる可能性がある、テーブル全体のスキャンを実行する必要なく、時間的制約のあるデータを効率的に取得して分析できます。テーブル構造とインデックスを戦略的に設計することで、最適なパフォーマンスを維持しながら、時間ベースのデータ取得をサポートする柔軟なソリューションを作成できます。
パターンの設計
DynamoDB を使用する場合、書き込みシャーディングとグローバルセカンダリインデックスを組み合わせた高度なパターンを実装して、最近のデータウィンドウ全体にわたる柔軟で効率的なクエリを実現することで、時間ベースのデータ取得の課題を克服することができます。
テーブルの構造
パーティションキー (PK):「ユーザー名」
GSI の構造
GSI パーティションキー (PK_GSI): 「ShardNumber#」
GSI ソートキー (SK_GSI): ISO 8601 タイムスタンプ (「2030-04-01T12:00:00Z」など)
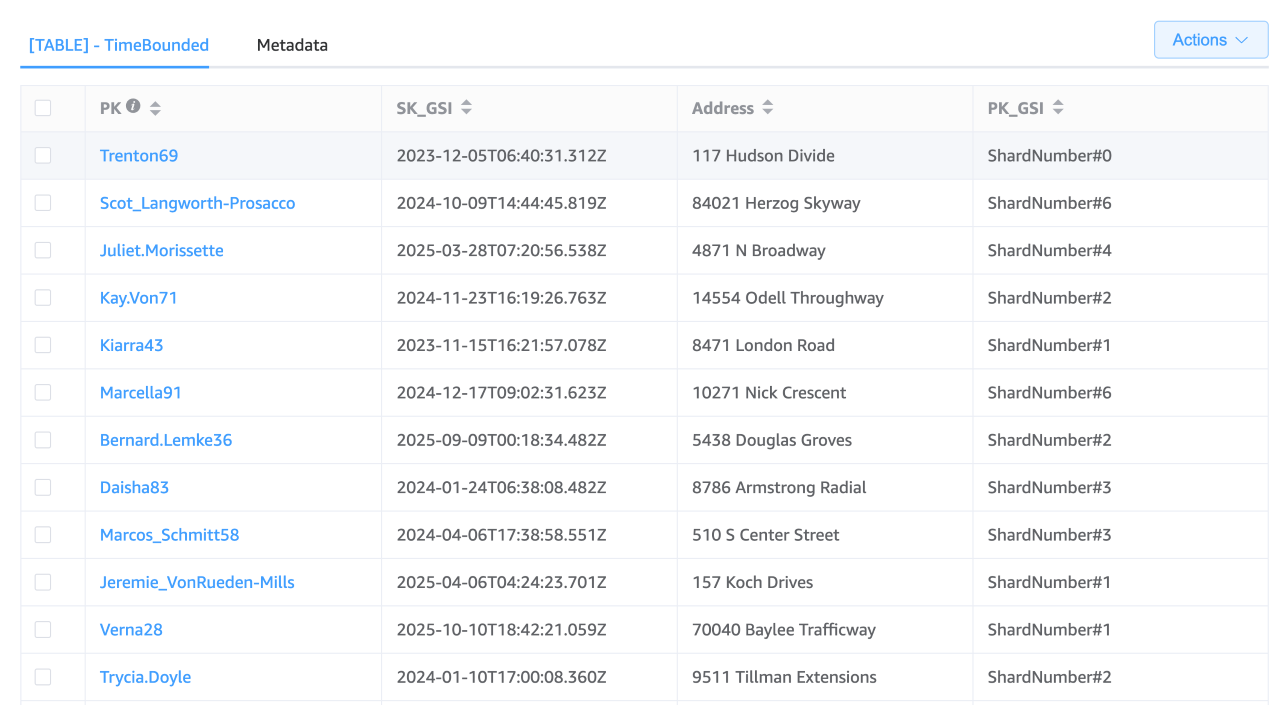
シャーディング戦略
10 個のシャードを使用する場合、シャード番号の範囲は 0~9 の範囲になります。アクティビティをログに記録する際は、シャード番号 を計算し (ユーザー ID でハッシュ関数を使用し、シャード数の係数を取得するなど)、これを GSI パーティションキーに追加します。このような方法を採用すると、エントリをさまざまなシャードに分散するため、ホットパーティションのリスクの軽減につながります。
シャーディングされた GSI のクエリ
データが複数のパーティションキーにシャーディングされている DynamoDB テーブルで、特定の時間範囲内の項目について、すべてのシャードにわたってクエリを実行するには、単一のパーティションのクエリとは異なるアプローチが必要になります。DynamoDB クエリは一度に 1 つのパーティションキーに制限されているため、1 回のクエリオペレーションで複数のシャードにわたって直接クエリを実行することはできません。ただし、複数のクエリを実行し、それぞれが特定のシャードをターゲットにして結果を集計すると、アプリケーションレベルのロジックを介して目的の結果を実現できます。次の手順では、これを行う方法について説明します。
シャードをクエリして集計するには
シャーディング戦略で使用するシャード番号の範囲を特定します。例えば、10 個のシャードがある場合、シャード番号の範囲は 0~9 の範囲になります。
目的の時間範囲内の項目を取得するクエリをシャードごとに構築して実行します。このようなクエリは、効率を向上させるために並行して実行できます。これらのクエリでは、シャード番号のパーティションキーと時間範囲のソートキーを使用します。単一のシャードのクエリサンプルは、次のとおりです。
aws dynamodb query \ --table-name "YourTableName" \ --index-name "YourIndexName" \ --key-condition-expression "PK_GSI = :pk_val AND SK_GSI BETWEEN :start_date AND :end_date" \ --expression-attribute-values '{ ":pk_val": {"S": "ShardNumber#0"}, ":start_date": {"S": "2024-04-01"}, ":end_date": {"S": "2024-04-30"} }'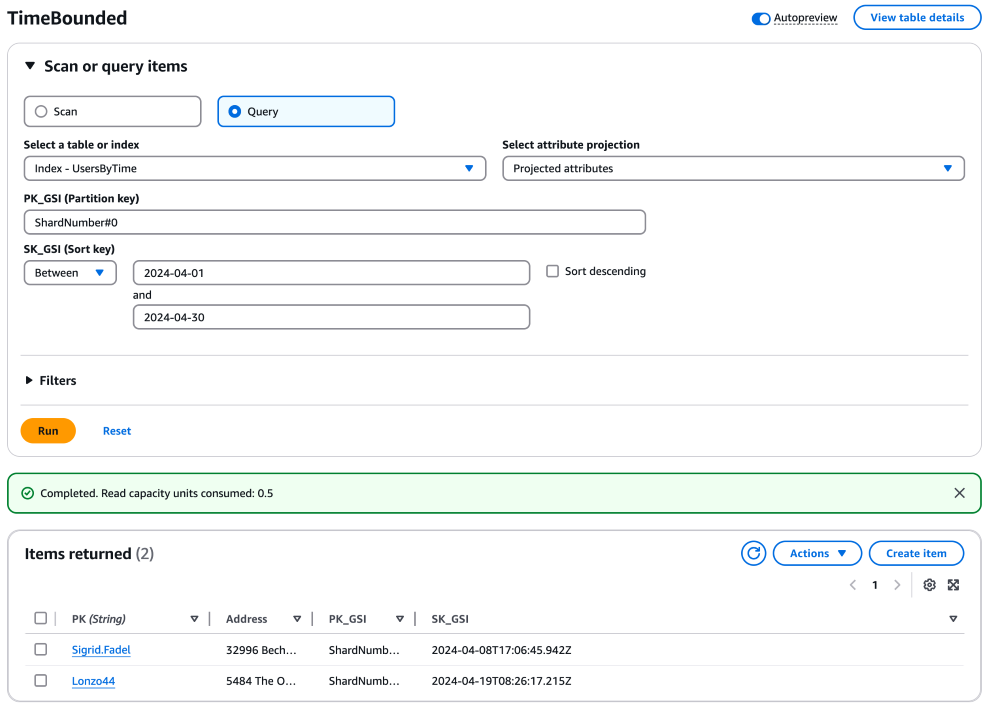
このクエリをシャードごとにレプリケートし、シャードに応じてパーティションキーを調整します (「ShardNumber#1」、「ShardNumber#2」...「ShardNumber#9」など)。
すべてのクエリが完了したら、各クエリの結果を集計します。この集計はアプリケーションコードで実行し、指定した時間範囲内のすべてのシャードの項目を表す単一のデータセットになるように、結果を結合します。
並列クエリの実行に関する考慮事項
各クエリは、テーブルまたはインデックスからの読み取り容量を使用します。プロビジョン済みのスループットを使用している場合は、並列クエリのバースト処理に十分な容量でテーブルがプロビジョンされていることを確認する必要があります。オンデマンド容量を使用している場合は、潜在的なコストへの影響に注意する必要があります。
コード例
Python を使用して DynamoDB シャード間で並列クエリを実行するには、Amazon Web Services SDK for Python である boto3 ライブラリを使用できます。この例は、boto3 がインストール済みで、適切な AWS 認証情報で設定されていることを前提としています。
次の Python コードは、特定の時間範囲で複数のシャードに対して並列クエリを実行する方法を説明しています。concurrent.futures を使用してクエリを並行して実行するため、順次実行と比べて全体的な実行時間が短縮されます。
import boto3
from concurrent.futures import ThreadPoolExecutor, as_completed
# Initialize a DynamoDB client
dynamodb = boto3.client('dynamodb')
# Define your table name and the total number of shards
table_name = 'YourTableName'
total_shards = 10 # Example: 10 shards numbered 0 to 9
time_start = "2030-03-15T09:00:00Z"
time_end = "2030-03-15T10:00:00Z"
def query_shard(shard_number):
"""
Query items in a specific shard for the given time range.
"""
response = dynamodb.query(
TableName=table_name,
IndexName='YourGSIName', # Replace with your GSI name
KeyConditionExpression="PK_GSI = :pk_val AND SK_GSI BETWEEN :date_start AND :date_end",
ExpressionAttributeValues={
":pk_val": {"S": f"ShardNumber#{shard_number}"},
":date_start": {"S": time_start},
":date_end": {"S": time_end},
}
)
return response['Items']
# Use ThreadPoolExecutor to query across shards in parallel
with ThreadPoolExecutor(max_workers=total_shards) as executor:
# Submit a future for each shard query
futures = {executor.submit(query_shard, shard_number): shard_number for shard_number in range(total_shards)}
# Collect and aggregate results from all shards
all_items = []
for future in as_completed(futures):
shard_number = futures[future]
try:
shard_items = future.result()
all_items.extend(shard_items)
print(f"Shard {shard_number} returned {len(shard_items)} items")
except Exception as exc:
print(f"Shard {shard_number} generated an exception: {exc}")
# Process the aggregated results (e.g., sorting, filtering) as needed
# For example, simply printing the count of all retrieved items
print(f"Total items retrieved from all shards: {len(all_items)}")このコードを実行する前に、YourTableName と YourGSIName を必ず DynamoDB セットアップの実際のテーブル名と GSI 名に置き換えます。特定の要件に応じて、total_shards 変数、time_start 変数、time_end 変数を調整する必要もあります。
このスクリプトは、指定された時間範囲内の項目について各シャードをクエリして、結果を集計します。
