기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
rank 함수는 지정 분할과 비교한 차원 또는 치수의 순위를 계산합니다. 중복까지 각 항목을 한 번 계산하며 순위에 "취약점 포함"을 할당하여 중복값을 보완합니다.
구문
괄호를 사용해야 합니다. 어떤 인수가 옵션인지 보려면 다음 설명을 확인합니다.
rank ([ sort_order_field ASC_or_DESC, ... ],[ partition_field, ... ])
인수
- 정렬 순서 필드
-
하나 이상의 집계 치수와 차원 데이터를 정렬하는 기준으로, 쉼표로 구분합니다. 오름차순(
ASC) 또는 내림차순(DESC)으로 정렬 순서를 지정할 수 있습니다.두 단어 이상이면 목록의 각 필드가 {}(중괄호)로 묶입니다. 전체 목록은 [ ](대괄호)로 묶입니다.
- partition field
-
(선택 사항) 하나 이상의 차원을 분할하는 기준으로, 쉼표로 구분합니다.
두 단어 이상이면 목록의 각 필드가 {}(중괄호)로 묶입니다. 전체 목록은 [ ](대괄호)로 묶입니다.
- 계산 수준
-
(선택 사항) 사용할 계산 수준을 지정합니다.
-
PRE_FILTER- 사전 필터 계산이 데이터 세트 필터보다 먼저 계산됩니다. -
PRE_AGG- 사전 집계 계산이 집계 및 상위/하위 N 필터를 시각적 객체에 적용하기 전에 계산됩니다. -
POST_AGG_FILTER- (기본값) 시각적 객체가 표시될 때 테이블 계산이 수행됩니다.
비어 있을 때 이 값은 기본적으로
POST_AGG_FILTER로 설정됩니다. 자세한 내용은 Amazon QuickSight에서 레벨 인식 계산 사용 단원을 참조하십시오. -
예제
다음 예제는 WA의 State 안에서 State 및 City 기준으로 내림차순으로 정렬한 max(Sales)의 순위입니다. max(Sales)가 동일한 모든 도시에는 동일 순위를 할당하지만, 그다음 순위는 앞 순위의 개수를 모두 합한 이후의 순위를 표시합니다. 예를 들어 순위가 같은 도시가 세 곳이라면 네 번째 도시는 4위입니다.
rank
(
[max(Sales) DESC],
[State, City]
)다음 예제는 State 기준으로 오름차순 정렬 순서에 따른 max(Sales)의 순위입니다. max(Sales)가 동일한 모든 주에는 동일 순위를 할당하지만, 그다음 순위는 앞 순위의 개수를 모두 합한 이후의 순위를 표시합니다. 예를 들어 순위가 같은 주가 세 곳이라면 네 번째 주는 4위입니다.
rank
(
[max(Sales) ASC],
[State]
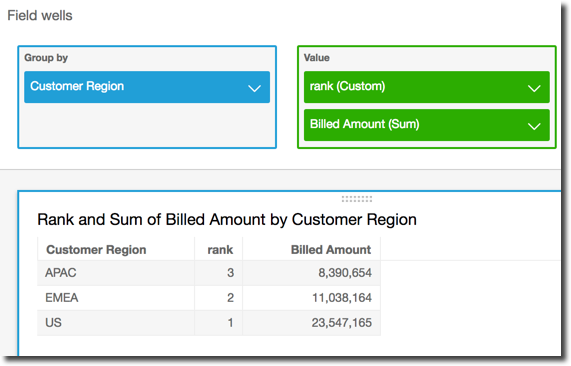
)다음은 Billed
Amount 기준의 Customer Region 순위 예시입니다. 테이블 계산의 필드는 시각적 객체의 필드 모음에 있습니다.
rank(
[sum({Billed Amount}) DESC]
)다음 스크린샷은 총 Billed Amount와 함께 예제의 결과를 표시하므로 각 리전의 순위를 볼 수 있습니다.