Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Sie können Streaming-Aufträge für ETL-Aufträge (Extract, Transform, Load) erstellen, die kontinuierlich ausgeführt werden und Daten aus Streaming-Quellen wie Amazon Kinesis Data Streams, Apache Kafka und Amazon Managed Streaming for Apache Kafka (Amazon MSK) konsumieren. Die Aufträge bereinigen und transformieren die Daten und laden die Ergebnisse dann in Amazon-S3-Data-Lakes oder JDBC-Datenspeicher.
Darüber hinaus können Sie Daten zu Amazon Kinesis Data Streams erstellen. Diese Funktion ist nur beim Schreiben von AWS Glue Skripten verfügbar. Weitere Informationen finden Sie unter Kinesis-Verbindungen.
Standardmäßig AWS Glue verarbeitet und schreibt Daten in 100-Sekunden-Fenstern aus. Dadurch können Daten effizient verarbeitet und Aggregationen für Daten ausgeführt werden, die später als erwartet eintreffen. Sie können die Größe dieses Zeitfensters ändern, um die Aktualität oder Aggregationsgenauigkeit zu erhöhen. AWS Glue Streaming-Jobs verwenden Checkpoints statt Job-Lesezeichen, um die gelesenen Daten nachzuverfolgen.
Anmerkung
AWS Glue berechnet stündlich das Streamen von ETL-Jobs, während sie ausgeführt werden.
In diesem Video werden die Kostenprobleme beim Streamen von ETL und die Funktionen zur Kosteneinsparung in AWS Glue beschrieben.
Die Erstellung eines Streaming-ETL-Auftrags umfasst die folgenden Schritte:
-
Erstellen Sie für eine Apache Kafka-Streaming-Quelle eine AWS Glue Verbindung zur Kafka-Quelle oder zum Amazon MSK-Cluster.
-
Erstellen Sie manuell eine Data-Catalog-Tabelle für die Streaming-Quelle.
-
Erstellen Sie einen ETL-Auftrag für die Streaming-Datenquelle. Definieren Sie streamingspezifische Auftragseigenschaften und geben Sie Ihr eigenes Skript an oder ändern Sie optional das generierte Skript.
Weitere Informationen finden Sie unter ETL einstreamen AWS Glue.
Wenn Sie einen Streaming-ETL-Job für Amazon Kinesis Data Streams erstellen, müssen Sie kein AWS Glue Verbindung. Wenn jedoch eine Verbindung mit dem verbunden ist AWS Glue Streaming-ETL-Job mit Kinesis Data Streams als Quelle, dann ist ein Virtual Private Cloud (VPC) -Endpunkt für Kinesis erforderlich. Weitere Informationen finden Sie unter Erstellung eines Schnittstellenendpunkts im Benutzerhandbuch für Amazon VPC. Wenn Sie einen Amazon-Kinesis-Data-Streams-Stream in einem anderen Konto angeben, müssen Sie die Rollen und Richtlinien einrichten, um den kontenübergreifenden Zugriff zu ermöglichen. Weitere Informationen finden Sie unter Beispiel: Aus einem Kinesis Stream in einem anderen Konto lesen.
AWS Glue Streaming-ETL-Jobs können komprimierte Daten automatisch erkennen, die Streaming-Daten transparent dekomprimieren, die üblichen Transformationen an der Eingabequelle durchführen und in den Ausgabespeicher laden.
AWS Glue unterstützt die automatische Dekomprimierung für die folgenden Komprimierungstypen je nach Eingabeformat:
| Komprimierungsart | Avro-Datei | Avro-Datum | JSON | CSV | Grok |
|---|---|---|---|---|---|
| BZIP2 | Ja | Ja | Ja | Ja | Ja |
| GZIP | Nein | Ja | Ja | Ja | Ja |
| SNAPPY | Ja (rohes Snappy) | Ja (gerahmtes Snappy) | Ja (gerahmtes Snappy) | Ja (gerahmtes Snappy) | Ja (gerahmtes Snappy) |
| XZ | Ja | Ja | Ja | Ja | Ja |
| ZSTD | Ja | Nein | Nein | Nein | Nein |
| DEFLATE | Ja | Ja | Ja | Ja | Ja |
Themen
Erstellen eines AWS Glue Verbindung für einen Apache Kafka-Datenstrom
Um aus einem Apache Kafka-Stream zu lesen, müssen Sie einen erstellen AWS Glue Verbindung.
Um eine zu erstellen AWS Glue Verbindung für eine Kafka-Quelle (Konsole)
Öffnen Sie die AWS Glue Konsole unter. https://console.aws.amazon.com/glue/
-
Wählen Sie im Navigationsbereich unter Data catalog die Option Connections (Verbindungen) aus.
-
Wählen Sie Add connection (Verbindung hinzufügen) und geben Sie auf der Seite Set up your connection’s properties (Einrichten der Verbindungseigenschaften) einen Verbindungsnamen ein.
Anmerkung
Weitere Informationen zum Angeben von Verbindungseigenschaften finden Sie unter Eigenschaften der AWS Glue -Verbindung.
-
Wählen Sie für Verbindungstyp den Eintrag Kafka.
-
Geben Sie für Kafka-Bootstrap-Server URLs den Host und die Portnummer für die Bootstrap-Broker für Ihren Amazon MSK-Cluster oder Apache Kafka-Cluster ein. Verwenden Sie nur TLS-Endpunkte (Transport Layer Security (TLS)) zum Herstellen der ersten Verbindung mit dem Kafka-Cluster. Nur–Text-Endpunkte werden nicht unterstützt.
Im Folgenden finden Sie eine Beispielliste mit Host-Port-Nummerpaaren für einen Amazon-MSK-Cluster.
myserver1.kafka.us-east-1.amazonaws.com:9094,myserver2.kafka.us-east-1.amazonaws.com:9094, myserver3.kafka.us-east-1.amazonaws.com:9094Weitere Informationen zum Abrufen der Bootstrap-Broker-Informationen finden Sie unter Abrufen der Bootstrap Broker für einen Amazon-MSK-Cluster im Amazon Managed Streaming for Apache-Kafka-Entwicklerhandbuch.
-
Wenn Sie eine sichere Verbindung zur Kafka-Datenquelle wünschen, wählen Sie SSL-Verbindung erforderlich und geben für Standort des privaten CA-Zertifikats von Kafka einen gültigen Amazon S3 Pfad zu einem benutzerdefinierten SSL-Zertifikat ein.
Für eine SSL-Verbindung zu selbstverwaltetem Kafka ist das benutzerdefinierte Zertifikat obligatorisch. Es ist optional für Amazon MSK.
Weitere Informationen zur Angabe eines benutzerdefinierten Zertifikats für Kafka finden Sie unter AWS Glue Eigenschaften der SSL-Verbindung.
-
Verwenden Sie AWS Glue Studio oder die AWS CLI, um eine Kafka-Client-Authentifizierungsmethode anzugeben. Um darauf zuzugreifen, AWS Glue Studio wählen Sie im ETL-Menü im linken Navigationsbereich AWS Glueaus.
Weitere Informationen über Kafka-Client-Authentifizierungsmethoden finden Sie unter AWS Glue Kafka-Verbindungseigenschaften für die Client-Authentifizierung .
-
Geben Sie optional eine Beschreibung ein und wählen Sie dann Next (Weiter).
-
Geben Sie für einen Amazon-MSK-Cluster die Virtual Private Cloud (VPC), das Subnetz und die Sicherheitsgruppe an. Für selbstverwaltetes Kafka sind die VPC-Informationen optional.
-
Klicken Sie auf Next (Weiter), um alle Verbindungseigenschaften zu überprüfen, und wählen Sie dann Finish (Abschließen).
Weitere Informationen zur AWS Glue Verbindungen, sieheHerstellen einer Verbindung zu Daten.
AWS Glue Kafka-Verbindungseigenschaften für die Client-Authentifizierung
- SASL/GSSAPI (Kerberos)-Authentifizierung
-
Wenn Sie diese Authentifizierungsmethode wählen, können Sie Kerberos-Eigenschaften angeben.
- Kerberos-Keytab
-
Wählen Sie den Speicherort der Keytab-Datei aus. Ein Keytab speichert Langzeitschlüssel für ein oder mehrere Prinzipale. Weitere Informationen finden Sie unter MIT-Kerberos-Dokumentation: Keytab
. - Kerberos krb5.conf-Datei
-
Wählen Sie die krb5.conf-Datei aus. Dies enthält den Standardbereich (ein logisches Netzwerk, ähnlich einer Domain, das eine Gruppe von Systemen unter demselben KDC definiert) und den Standort des KDC-Servers. Weitere Informationen finden Sie in der MIT-Kerberos-Dokumentation: krb5.conf
. - Kerberos-Prinzipal und Kerberos-Dienstname
-
Geben Sie den Kerberos-Prinzipal und den Dienstnamen ein. Weitere Informationen finden Sie unter MIT Kerberos-Dokumentation: Kerberos-Prinzipal
. - SASL/SCRAM-SHA-512-Authentifizierung
-
Wenn Sie diese Authentifizierungsmethode wählen, können Sie Anmeldeinformationen zur Authentifizierung angeben.
- AWS Secrets Manager
-
Suchen Sie im Suchfeld nach Ihrem Token, indem Sie den Namen oder ARN eingeben.
- Benutzername und Passwort des Anbieters direkt
-
Suchen Sie im Suchfeld nach Ihrem Token, indem Sie den Namen oder ARN eingeben.
- SSL-Client-Authentifizierung
-
Wenn Sie diese Authentifizierungsmethode wählen, können Sie den Standort des Kafka-Client-Keystores auswählen, indem Sie Amazon S3 durchsuchen. Optional können Sie das Kennwort für den Kafka-Client-Keystore und das Kafka-Client-Schlüsselkennwort eingeben.
- IAM-Authentifizierung
-
Diese Authentifizierungsmethode erfordert keine zusätzlichen Spezifikationen und ist nur anwendbar, wenn die Streaming-Quelle MSK Kafka ist.
- SASL/PLAIN-Authentifizierung
-
Wenn Sie diese Authentifizierungsmethode wählen, können Sie Authentifizierungsdaten angeben.
Erstellen einer Data-Catalog-Tabelle für eine Streaming-Quelle
Eine Datenkatalogtabelle, die die Eigenschaften des Quelldatenstroms, einschließlich des Datenschemas, angibt, kann manuell für eine Streaming-Quelle erstellt werden. Diese Tabelle wird als Datenquelle für den Streaming-ETL-Auftrag verwendet.
Wenn Sie das Schema der Daten im Quelldatenstrom nicht kennen, können Sie die Tabelle ohne Schema erstellen. Wenn Sie dann den Streaming-ETL-Job erstellen, können Sie den AWS Glue Funktion zur Schemaerkennung. AWS Glue bestimmt das Schema anhand der Streaming-Daten.
Verwenden der AWS Glue Konsole
Anmerkung
Sie können die AWS Lake Formation Konsole nicht verwenden, um die Tabelle zu erstellen. Sie müssen die AWS Glue console.
Beachten Sie auch die folgenden Informationen für Streaming-Quellen im Avro-Format oder für Protokolldaten, auf die Sie Grok-Muster anwenden können.
Kinesis-Datenquelle
Legen Sie beim Erstellen der Tabelle die folgenden Streaming-ETL-Eigenschaften fest (Konsole).
- Quelltyp
-
Kinesis
- Für eine Kinesis-Quelle im selben Konto:
-
- Region
-
Die AWS Region, in der sich der Amazon Kinesis Data Streams Streams-Service befindet. Der Name der Region und des Kinesis-Streams werden zusammen in einen Stream-ARN übersetzt.
Beispiel: https://kinesis.us-east-1.amazonaws.com
- Kinesis-Streamname
-
Der Stream-Name wie unter Erstellen eines Streams im Entwicklerhandbuch zu Amazon Kinesis Data Streams beschrieben.
- Informationen zu einer Kinesis-Quelle in einem anderen Konto finden Sie in diesem Beispiel zum Einrichten der Rollen und Richtlinien, um den kontenübergreifenden Zugriff zu ermöglichen. Konfigurieren Sie diese Einstellungen:
-
- Stream-ARN
-
Der ARN des Kinesis-Datenstroms, mit dem der Verbraucher registriert ist. Weitere Informationen finden Sie unter Amazon Resource Names (ARNs) und AWS Service Namespaces in der. Allgemeine AWS-Referenz
- Angenommene ARN-Rolle
-
Der angenommene Amazon-Ressourcenname (ARN) der Rolle.
- Sitzungsname (optional)
-
Ein Bezeichner für die Sitzung der angenommenen Rolle.
Verwenden Sie den Namen der Rollensitzung, um eine Sitzung eindeutig zu identifizieren, wenn dieselbe Rolle von verschiedenen Prinzipalen oder aus unterschiedlichen Gründen übernommen wird. In kontenübergreifenden Szenarien ist der Name der Rollensitzung für das Konto sichtbar und kann von dem Konto protokolliert werden, dem die Rolle gehört. Der Rollensitzungsname wird auch im ARN des übernommenen Rollenprinzipals verwendet. Das bedeutet, dass nachfolgende kontoübergreifende API-Anfragen, die die temporären Sicherheitsanmeldedaten verwenden, den Namen der Rollensitzung für das externe Konto in ihren Protokollen offenlegen. AWS CloudTrail
Um Streaming-ETL-Eigenschaften für Amazon Kinesis Data Streams festzulegen (AWS Glue API oder AWS CLI)
-
Um Streaming-ETL-Eigenschaften für eine Kinesis-Quelle in demselben Konto einzurichten, geben Sie die
streamName- undendpointUrl-Parameter in derStorageDescriptor-Struktur derCreateTable-API-Operation oder demcreate_table-CLI-Befehl an."StorageDescriptor": { "Parameters": { "typeOfData": "kinesis", "streamName": "sample-stream", "endpointUrl": "https://kinesis.us-east-1.amazonaws.com" } ... }Oder geben Sie den
streamARNan."StorageDescriptor": { "Parameters": { "typeOfData": "kinesis", "streamARN": "arn:aws:kinesis:us-east-1:123456789:stream/sample-stream" } ... } -
Um Streaming-ETL-Eigenschaften für eine Kinesis-Quelle in einem anderen Konto einzurichten, geben Sie die
streamARN-,awsSTSRoleARN- und (optional)awsSTSSessionName-Parameter in derStorageDescriptor-Struktur derCreateTable-API-Operation oder demcreate_table-CLI-Befehl an."StorageDescriptor": { "Parameters": { "typeOfData": "kinesis", "streamARN": "arn:aws:kinesis:us-east-1:123456789:stream/sample-stream", "awsSTSRoleARN": "arn:aws:iam::123456789:role/sample-assume-role-arn", "awsSTSSessionName": "optional-session" } ... }
Kafka-Datenquelle
Legen Sie beim Erstellen der Tabelle die folgenden Streaming-ETL-Eigenschaften fest (Konsole).
- Quelltyp
-
Kafka
- Für eine Kafka-Quelle:
-
- Themenname
-
Der Topic-Name wie in Kafka angegeben.
- Verbindung
-
Importieren in &S3; AWS Glue Verbindung, die auf eine Kafka-Quelle verweist, wie unter beschriebenErstellen eines AWS Glue Verbindung für einen Apache Kafka-Datenstrom.
AWS Glue Quelle der Schemaregistrierungstabelle
Zur Verwendung AWS Glue Schemaregistrierung für Streaming-Jobs: Folgen Sie den Anweisungen unter Anwendungsfall: AWS Glue Data Catalog So erstellen oder aktualisieren Sie eine Schemaregistry-Tabelle.
Derzeit AWS Glue Streaming unterstützt nur das Avro-Format von Glue Schema Registry mit der Einstellung Schemainferenz auf. false
Hinweise und Einschränkungen für Avro-Streaming-Quellen
Die folgenden Hinweise und Einschränkungen gelten für Streaming-Quellen im Avro-Format:
-
Wenn die Schemaerkennung aktiviert ist, muss das Avro-Schema in die Nutzlast einbezogen werden. Wenn diese Option deaktiviert ist, sollte die Nutzlast nur Daten enthalten.
-
Einige Avro-Datentypen werden in Dynamic Frames nicht unterstützt. Sie können diese Datentypen nicht angeben, wenn Sie das Schema auf der Seite Schema definieren im Assistenten zur Tabellenerstellung im AWS Glue console. Während der Schemaerkennung werden nicht unterstützte Typen im Avro-Schema wie folgt in unterstützte Typen konvertiert:
-
EnumType => StringType -
FixedType => BinaryType -
UnionType => StructType
-
-
Wenn Sie das Tabellenschema auf der Seite Definieren eines Schemas in der Konsole definieren, ist der implizierte Stammelementtyp für das Schema
record. Wenn Sie einen anderen Stammelementtyp alsrecordmöchten, zum Beispielarrayodermap, können Sie das Schema nicht mithilfe der Seite Definieren eines Schemas angeben. Stattdessen müssen Sie diese Seite überspringen und das Schema entweder als Tabelleneigenschaft oder im ETL-Skript angeben.-
Um das Schema in den Tabelleneigenschaften anzugeben, füllen Sie den Assistenten zum Erstellen von Tabellen aus, bearbeiten Sie die Tabellendetails und fügen Sie unter Tabelleneigenschaften ein neues Schlüssel-Wert-Paar hinzu. Verwenden Sie den Schlüssel
avroSchemaund geben Sie ein Schema-JSON-Objekt für den Wert ein, wie im folgenden Screenshot gezeigt.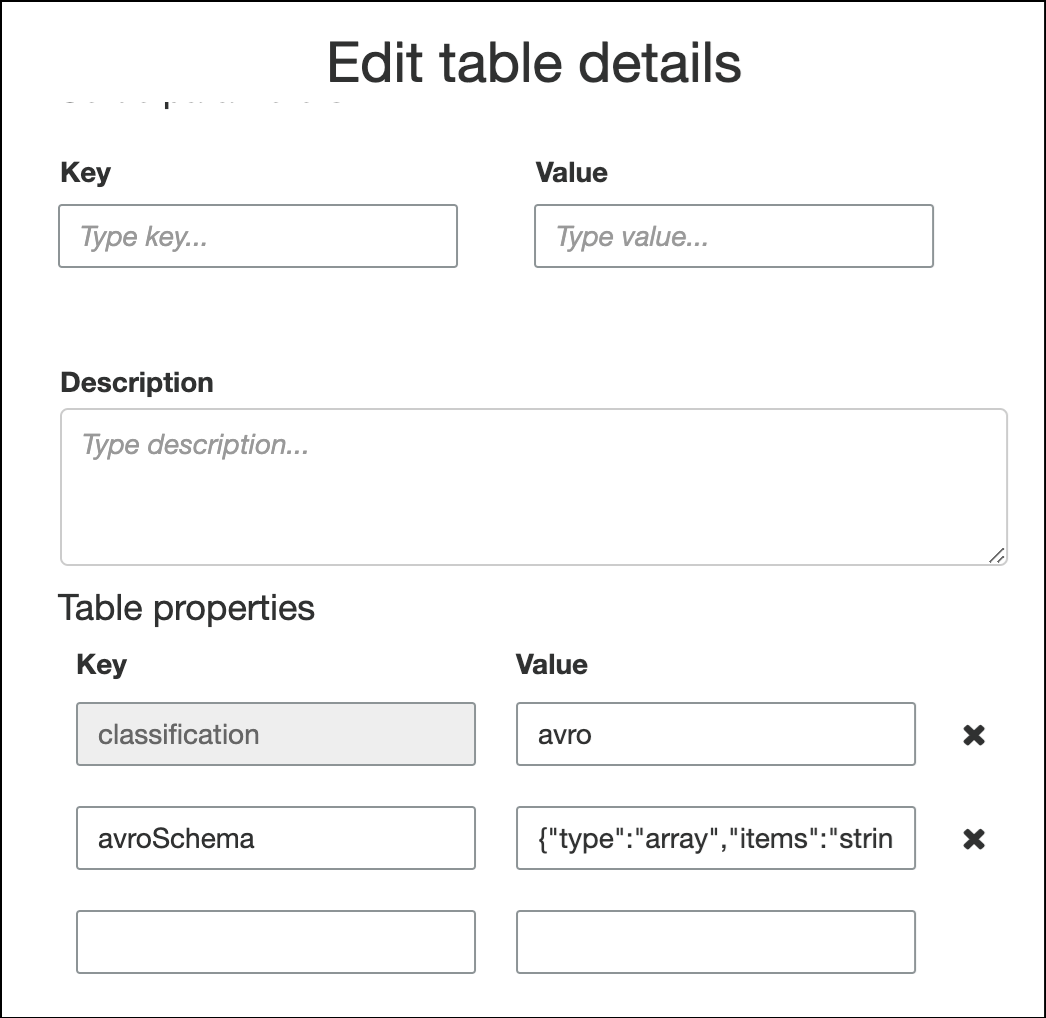
-
Um das Schema im ETL-Skript anzugeben, ändern Sie die
datasource0-Zuweisungsanweisung und fügen Sie den SchlüsselavroSchemazum Argumentadditional_optionshinzu, wie in den folgenden Python- und Scala-Beispielen gezeigt.SCHEMA_STRING = ‘{"type":"array","items":"string"}’ datasource0 = glueContext.create_data_frame.from_catalog(database = "database", table_name = "table_name", transformation_ctx = "datasource0", additional_options = {"startingPosition": "TRIM_HORIZON", "inferSchema": "false", "avroSchema": SCHEMA_STRING})
-
Anwenden von Grok-Mustern auf Streaming-Quellen
Sie können einen Streaming-ETL-Auftrag für eine Protokolldatenquelle erstellen und Grok-Muster verwenden, um die Protokolle in strukturierte Daten zu konvertieren. Der ETL-Auftrag verarbeitet die Daten dann als strukturierte Datenquelle. Sie geben die Grok-Muster an, die angewendet werden sollen, wenn Sie die Data-Catalog-Tabelle für die Streaming-Quelle erstellen.
Informationen zu Grok-Mustern und benutzerdefinierten Musterzeichenfolgenwerten finden Sie unter Angepasste Grok-Classifier schreiben.
So fügen Sie der Data-Catalog-Tabelle (Konsole) Grok-Muster hinzu
-
Verwenden Sie den Assistenten zum Erstellen von Tabellen, und erstellen Sie die Tabelle mit den in Erstellen einer Data-Catalog-Tabelle für eine Streaming-Quelle angegebenen Parametern. Geben Sie als Datenformat Grok an, füllen Sie das Feld Grok-Muster aus und fügen Sie optional benutzerdefinierte Muster unter Benutzerdefinierte Muster (optional) hinzu.
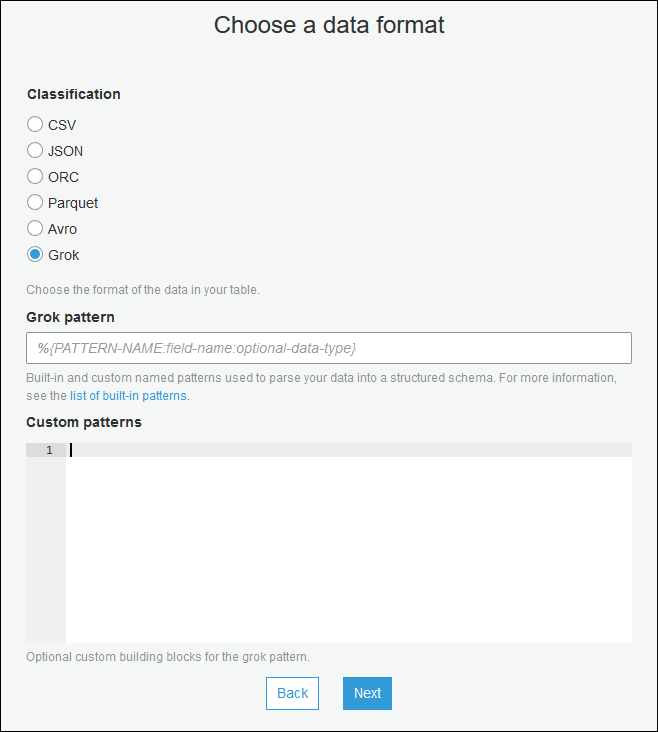
Drücken Sie nach jedem benutzerdefinierten Muster auf Eingabe.
Um Grok-Muster zur Datenkatalogtabelle hinzuzufügen (AWS Glue API oder AWS CLI)
-
Fügen Sie den
GrokPattern-Parameter und optional denCustomPatterns-Parameter zu derCreateTable-API-Operation oder demcreate_table-CLI-Befehl hinzu."Parameters": { ... "grokPattern": "string", "grokCustomPatterns": "string", ... },Drücken Sie
grokCustomPatternsals String aus und verwenden Sie „\ n“ als Trennzeichen zwischen Mustern.Nachfolgend finden Sie ein Beispiel für die Angabe dieser Parameter.
"parameters": { ... "grokPattern": "%{USERNAME:username} %{DIGIT:digit:int}", "grokCustomPatterns": "digit \d", ... }
Definieren von Auftragseigenschaften für einen Streaming-ETL-Auftrag
Wenn Sie einen Streaming-ETL-Job in der definieren AWS Glue Geben Sie in der Konsole die folgenden streamspezifischen Eigenschaften an. Beschreibungen weiterer Auftragseigenschaften finden Sie unter Definieren von Auftragseigenschaften für Spark-Aufträge.
- IAM-Rolle
-
Geben Sie die AWS Identity and Access Management (IAM-) Rolle an, die für die Autorisierung von Ressourcen verwendet wird, die für die Ausführung des Jobs, den Zugriff auf Streaming-Quellen und den Zugriff auf Zieldatenspeicher verwendet werden.
Für den Zugriff auf Amazon Kinesis Data Streams hängen Sie die
AmazonKinesisFullAccessAWS verwaltete Richtlinie an die Rolle an oder fügen Sie eine ähnliche IAM-Richtlinie hinzu, die einen detaillierteren Zugriff ermöglicht. Beispielrichtlinien finden Sie unter Steuern des Zugriffs auf Amazon Kinesis Data Streams-Ressourcen mithilfe von IAM.Weitere Informationen zu Berechtigungen für die Ausführung von Jobs finden Sie in AWS Glue, finden Sie unter Identitäts- und Zugriffsmanagement für AWS Glue.
- Typ
-
Wählen Sie Spark streaming (Spark-Streaming).
- AWS Glue version
-
Das Tool AWS Glue Version bestimmt die Versionen von Apache Spark und Python oder Scala, die für den Job verfügbar sind. Wählen Sie eine Auswahl, die die für den Job verfügbare Version von Python oder Scala angibt. AWS Glue Version 2.0 mit Python-3-Unterstützung ist die Standardeinstellung für Streaming-ETL-Aufträge.
- Wartungsfenster
-
Gibt ein Fenster an, in dem ein Streaming-Job neu gestartet werden kann. Siehe Wartungsfenster für AWS Glue Streaming.
- Zeitüberschreitung von Aufträgen
-
Geben Sie optional eine Dauer in Minuten ein. Der Standardwert ist leer.
Streaming-Jobs müssen einen Timeout-Wert von weniger als 7 Tagen oder 10080 Minuten haben.
Wenn der Wert leer gelassen wird, wird der Job nach 7 Tagen neu gestartet, sofern Sie kein Wartungsfenster eingerichtet haben. Wenn Sie ein Wartungsfenster eingerichtet haben, wird der Job während des Wartungsfensters nach 7 Tagen neu gestartet.
- Datenquelle
-
Geben Sie die Tabelle an, die Sie in Erstellen einer Data-Catalog-Tabelle für eine Streaming-Quelle erstellt haben.
- Datenziel
-
Führen Sie eine der folgenden Aktionen aus:
-
Wählen Sie Create tables in your data target (Tabellen in eigenem Datenziel erstellen) und geben Sie die folgenden Eigenschaften für das Datenziel an.
- Datastore
-
Wählen Sie Amazon S3 oder JDBC.
- Format
-
Wählen Sie ein beliebiges Format aus. Für das Streaming werden alle unterstützt.
-
Wählen Sie Use tables in the data catalog and update your data target (Tabellen im Data Catalog verwenden und Datenziel aktualisieren) und wählen Sie eine Tabelle für einen JDBC-Datastore.
-
- Ausgabeschemadefinition
-
Führen Sie eine der folgenden Aktionen aus:
-
Wählen Sie Schema für jeden Datensatz automatisch erkennen, um die Schemaerkennung zu aktivieren. AWS Glue bestimmt das Schema anhand der Streaming-Daten.
-
Klicken Sie auf Specify output schema for all records (Ausgabeschema für alle Datensätze angeben), um das Ausgabeschema mithilfe der Transformation „Apply Mapping“ (Mapping anwenden) zu definieren.
-
- Script
-
Geben Sie optional Ihr eigenes Skript an oder ändern Sie das generierte Skript, um Operationen auszuführen, die von der Apache-Spark-Engine Structured Streaming unterstützt werden. Informationen zu den verfügbaren Vorgängen finden Sie unter Operationen beim Streamen DataFrames /Datasets
.
Hinweise zu und Einschränkungen für Streaming-ETL
Beachten Sie die folgenden Hinweise und Einschränkungen:
-
Automatische Dekomprimierung für AWS Glue Das Streamen von ETL-Jobs ist nur für die unterstützten Komprimierungstypen verfügbar. Beachten Sie auch das Folgende:
Das gerahmte Snappy bezieht sich auf das offizielle Rahmen-Format
für Snappy. Deflate wird in der Glue-Version 3.0 unterstützt, nicht in der Glue-Version 2.0.
-
Wenn Sie die Schemaerkennung verwenden, können Sie keine Joins von Streamingdaten ausführen.
-
AWS Glue Streaming-ETL-Jobs unterstützen nicht den Union-Datentyp für AWS Glue Schemaregistrierung im Avro-Format.
-
Ihr ETL-Skript kann verwenden AWS GlueDie integrierten Transformationen und die systemeigenen Transformationen von Apache Spark Structured Streaming. Weitere Informationen finden Sie unter Operationen beim Streamen DataFrames /Datasets auf
der Apache Spark-Website oder. AWS Glue PySpark transformiert Referenz -
AWS Glue Streaming-ETL-Jobs verwenden Checkpoints, um den Überblick über die gelesenen Daten zu behalten. Daher wird ein Auftrag, der angehalten und neu gestartet wurde, an dem Punkt fortgesetzt, an dem er im Stream beendet wurde. Wenn Sie Daten neu verarbeiten möchten, können Sie den Checkpoint-Ordner löschen, auf den im Skript verwiesen wird.
-
Auftragslesezeichen werden nicht unterstützt.
-
Zur Verwendung des erweiterten Fan-Out-Features von Kinesis Data Streams in Ihrem Auftrag lesen Sie Verwendung von erweitertem Fan-Out in Kinesis-Streaming-Aufträgen.
-
Wenn Sie eine Datenkatalogtabelle verwenden, die aus erstellt wurde AWS Glue Wenn in der Schemaregistrierung eine neue Schemaversion verfügbar ist, müssen Sie wie folgt vorgehen, um das neue Schema widerzuspiegeln:
-
Stoppen Sie die mit der Tabelle verknüpften Aufträge.
-
Aktualisieren Sie das Schema für die Data Catalog-Tabelle.
-
Starten Sie die mit der Tabelle verknüpften Aufträge neu.
-
