Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Sie können die Apache Spark-Weboberfläche zum Überwachen und Debuggen verwenden AWS Glue ETL-Jobs laufen auf dem AWS Glue Jobsystem und auch Spark-Anwendungen, die auf ausgeführt werden AWS Glue Entwicklungsendpunkte. Sie können in der Spark-Benutzeroberfläche folgende Punkte für die einzelnen Aufgaben überprüfen:
-
Ereignis-Zeitplan der einzelnen Spark-Phasen
-
Ausgerichtetes azyklisches Diagramm (Directed Acyclic Graph, DAG) der Aufgabe
-
Physische und logische Pläne für SparkSQL-Abfragen
-
Zugrunde liegende Spark-Umgebungsvariablen für die einzelnen Aufgaben
Weitere Informationen zur Verwendung der Spark-Web-UI finden Sie unter Web-UI
Sie können die Spark-Benutzeroberfläche in der AWS Glue Konsole sehen. Dies ist verfügbar, wenn ein AWS Glue Job auf Versionen AWS Glue 3.0 oder höher ausgeführt wird, wobei die Logs im Standardformat (und nicht im Legacy-Format) generiert werden, was der Standard für neuere Jobs ist. Wenn Sie über Protokolldateien mit mehr als 0,5 GB verfügen, können Sie die Unterstützung für fortlaufende Protokolle für Auftragsausführungen in Versionen AWS Glue 4.0 oder höher aktivieren, um die Archivierung, Analyse und Problembehandlung von Protokollen zu vereinfachen.
Sie können die Spark-Benutzeroberfläche aktivieren, indem Sie AWS Glue Konsole oder die AWS Command Line Interface (AWS CLI). Wenn Sie die Spark-Benutzeroberfläche aktivieren, AWS Glue ETL-Jobs und Spark-Anwendungen auf AWS Glue Entwicklungsendpunkte können Spark-Ereignisprotokolle an einem Speicherort sichern, den Sie in Amazon Simple Storage Service (Amazon S3) angeben. Die so in Amazon S3 gesicherten Ereignisprotokolle können in der Spark-Benutzeroberfläche in Echtzeit während der Auftragsausführung und nach Abschluss des Auftrags verwendet werden. Die Protokolle verbleiben zwar in Amazon S3, können aber über die Spark-Benutzeroberfläche in der AWS Glue Konsole angezeigt werden.
Berechtigungen
Um die Spark-Benutzeroberfläche in der AWS Glue Konsole zu verwenden, können Sie alle einzelnen Dienste verwenden UseGlueStudio oder hinzufügen APIs. Alle APIs sind erforderlich, um die Spark-Benutzeroberfläche vollständig nutzen zu können. Benutzer können jedoch auf die Funktionen von SparkUI zugreifen, indem sie den Dienst APIs zu ihrer IAM-Berechtigung hinzufügen, um einen detaillierten Zugriff zu erhalten.
RequestLogParsingist am kritischsten, da es das Parsen von Logs durchführt. Die übrigen APIs dienen zum Lesen der jeweiligen analysierten Daten. GetStagesBietet beispielsweise Zugriff auf die Daten zu allen Phasen eines Spark-Jobs.
Die Liste der APIs zugewiesenen Spark-UI-Services finden UseGlueStudio Sie weiter unten in der Beispielrichtlinie. Die folgende Richtlinie bietet Zugriff auf die Nutzung nur der Funktionen der Spark-Benutzeroberfläche. Informationen zum Hinzufügen weiterer Berechtigungen wie Amazon S3 und IAM finden Sie unter Erstellen benutzerdefinierter IAM-Richtlinien für. AWS Glue Studio
Die Liste der APIs zugewiesenen Spark-UI-Services finden Sie weiter unten in der Beispielrichtlinie. UseGlueStudio Wenn Sie eine Spark-UI-Service-API verwenden, verwenden Sie den folgenden Namespace:. glue:<ServiceAPI>
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowGlueStudioSparkUI",
"Effect": "Allow",
"Action": [
"glue:RequestLogParsing",
"glue:GetLogParsingStatus",
"glue:GetEnvironment",
"glue:GetJobs",
"glue:GetJob",
"glue:GetStage",
"glue:GetStages",
"glue:GetStageFiles",
"glue:BatchGetStageFiles",
"glue:GetStageAttempt",
"glue:GetStageAttemptTaskList",
"glue:GetStageAttemptTaskSummary",
"glue:GetExecutors",
"glue:GetExecutorsThreads",
"glue:GetStorage",
"glue:GetStorageUnit",
"glue:GetQueries",
"glue:GetQuery"
],
"Resource": [
"*"
]
}
]
}
Einschränkungen
-
Die Spark-Benutzeroberfläche in der AWS Glue Konsole ist für Jobausführungen, die vor dem 20. November 2023 stattfanden, nicht verfügbar, da sie im alten Protokollformat vorliegen.
-
Die Spark-Benutzeroberfläche in der AWS Glue Konsole unterstützt fortlaufende Logs für AWS Glue 4.0, wie sie beispielsweise standardmäßig bei Streaming-Jobs generiert werden. Die maximale Summe aller generierten gerollten Protokollereignisdateien beträgt 2 GB. Für AWS Glue Jobs ohne Unterstützung für Rolling-Logs beträgt die maximale Größe der Protokollereignisdatei, die für SparkUI unterstützt wird, 0,5 GB.
-
Die serverlose Spark-Benutzeroberfläche ist nicht für Spark-Ereignisprotokolle verfügbar, die in einem Amazon S3 S3-Bucket gespeichert sind und auf die nur Ihre VPC zugreifen kann.
Beispiel: Web-UI von Apache Spark
In diesem Beispiel wird veranschaulicht, wie Sie die Spark-Benutzeroberfläche verwenden, um Ihre Auftragsleistung nachzuvollziehen. Die Screenshots zeigen die Spark-Weboberfläche, wie sie von einem selbstverwalteten Spark History-Server bereitgestellt wird. Die Spark-Benutzeroberfläche in der AWS Glue Konsole bietet ähnliche Ansichten. Weitere Informationen zur Verwendung der Spark-Web-UI finden Sie unter Web-UI
Im Folgenden finden Sie ein Beispiel für eine Spark-Anwendung, die aus zwei Datenquellen liest, eine Join-Transformation ausführt und diese im Parquet-Format zu Amazon S3 schreibt.
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql.functions import count, when, expr, col, sum, isnull
from pyspark.sql.functions import countDistinct
from awsglue.dynamicframe import DynamicFrame
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'])
df_persons = spark.read.json("s3://awsglue-datasets/examples/us-legislators/all/persons.json")
df_memberships = spark.read.json("s3://awsglue-datasets/examples/us-legislators/all/memberships.json")
df_joined = df_persons.join(df_memberships, df_persons.id == df_memberships.person_id, 'fullouter')
df_joined.write.parquet("s3://aws-glue-demo-sparkui/output/")
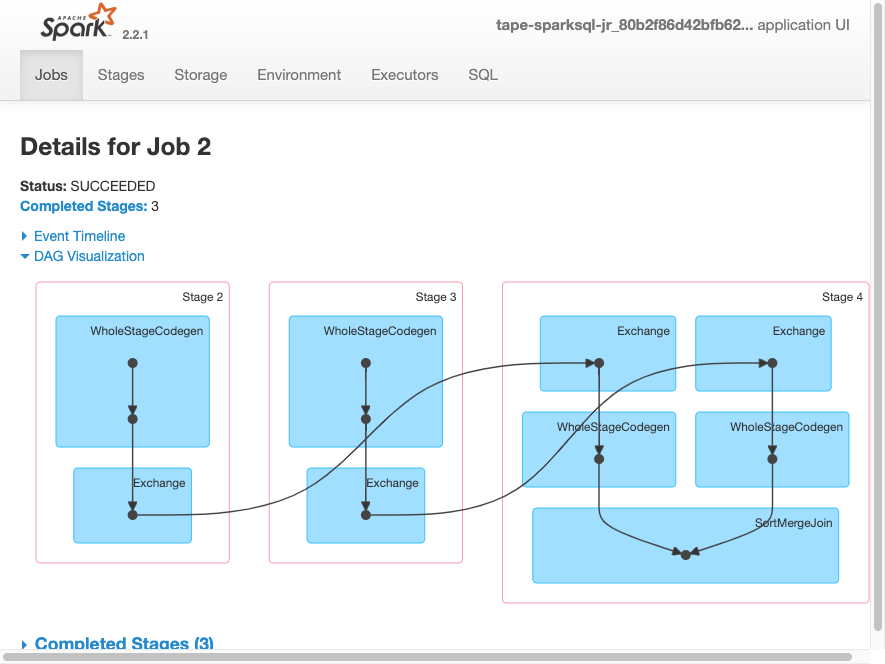
job.commit()Die folgende DAG-Visualisierung zeigt die verschiedenen Phasen in dieser Spark-Aufgabe.
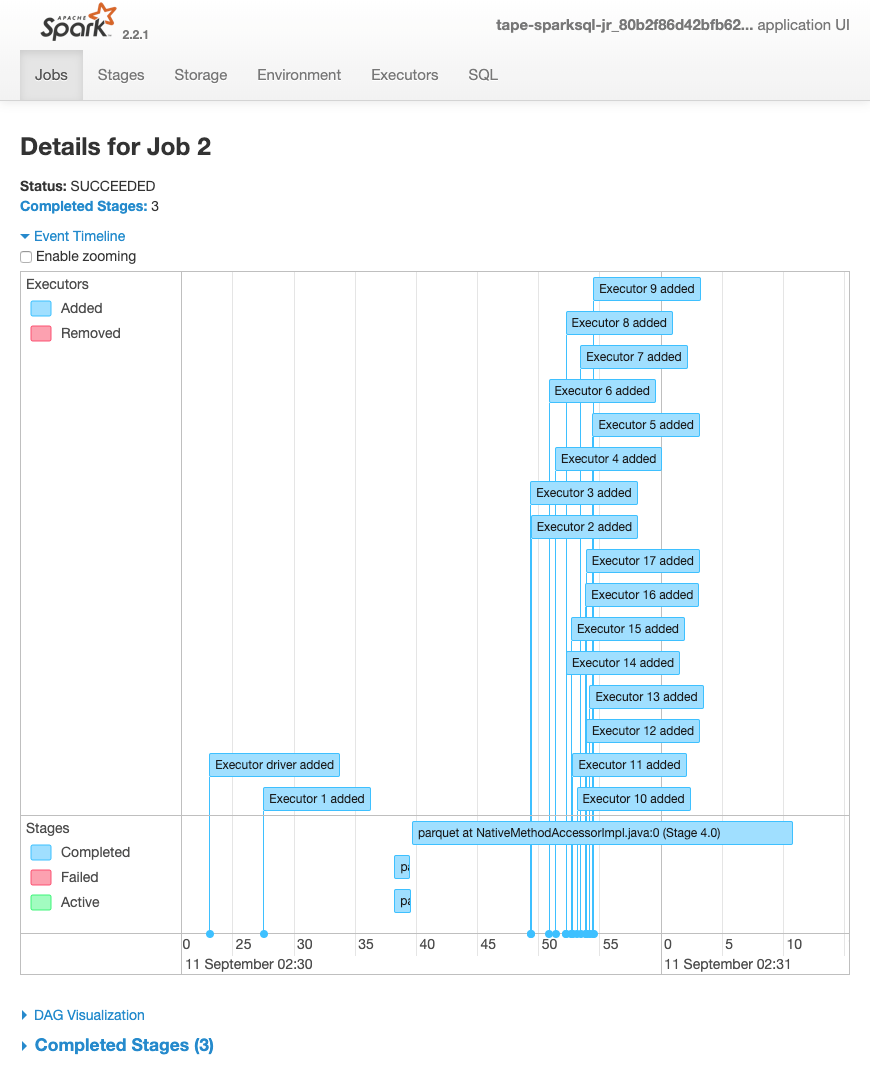
Der folgende Ereigniszeitplan für eine Aufgabe zeigt Start, Ausführung und Beendigung verschiedener Spark-Executors.
Der folgende Bildschirm zeigt die Details der SparkSQL-Abfragepläne:
-
Geparster logischer Plan
-
Analysierter logischer Plan
-
Optimierter logischer Plan
-
Physischer Plan für die Ausführung

