Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Data Quality Definition Language (DQDL) ist eine domänenspezifische Sprache, mit der Sie Regeln für AWS Glue Data Quality definieren.
In diesem Handbuch werden wichtige DQDL-Konzepte vorgestellt, die Ihnen beim Verständnis der Sprache helfen. Es bietet auch eine Referenz für DQDL-Regeltypen mit Syntax und Beispielen. Bevor Sie dieses Handbuch verwenden, empfehlen wir Ihnen, sich mit AWS Glue Data Quality vertraut zu machen. Weitere Informationen finden Sie unter AWS Glue Qualität der Daten.
Anmerkung
DynamicRules werden nur unterstützt in AWS Glue ETL.
Inhalt
DQDL-Syntax
Ein DQDL-Dokument unterscheidet zwischen Groß- und Kleinschreibung und enthält einen Regelsatz, der einzelne Datenqualitätsregeln zusammenfasst. Um einen Regelsatz zu erstellen, müssen Sie eine Liste mit dem Namen Rules (groß geschrieben) erstellen, die durch ein Paar eckiger Klammern begrenzt ist. Die Liste sollte eine oder mehrere durch Kommas getrennte DQDL-Regeln wie im folgenden Beispiel enthalten.
Rules = [
IsComplete "order-id",
IsUnique "order-id"
]Regelstruktur
Die Struktur einer DQDL-Regel hängt vom Regeltyp ab. Allerdings passen DQDL-Regeln im Allgemeinen in das folgende Format.
<RuleType> <Parameter> <Parameter> <Expression>
RuleType ist der zwischen Groß- und Kleinschreibung zu unterscheidende Name des Regeltyps, den Sie konfigurieren möchten. Beispiel: IsComplete, IsUnique oder CustomSql. Die Regelparameter unterscheiden sich für jeden Regeltyp. Eine vollständige Referenz der DQDL-Regeltypen und ihrer Parameter finden Sie unter DQDL-Regeltypreferenz.
Zusammengesetzte Regeln
DQDL unterstützt die folgenden logischen Operatoren, die Sie zum Kombinieren von Regeln verwenden können. Diese Regeln werden als zusammengesetzte Regeln bezeichnet.
- and
-
Der logische
and-Operator ergibt genau danntrue, wenn die Regeln, die er verbindet,truesind. Andernfalls führt die kombinierte Regel zufalse. Jede Regel, die Sie mit demand-Operator verbinden, muss in runde Klammern eingeschlossen werden.Im folgenden Beispiel wird der
and-Operator zum Kombinieren zweier DQDL-Regeln verwendet.(IsComplete "id") and (IsUnique "id") - or
-
Der logische
or-Operator ergibt genau danntrue, wenn eine oder mehrere der Regeln, die er verbindet,truesind. Jede Regel, die Sie mit demor-Operator verbinden, muss in runde Klammern eingeschlossen werden.Im folgenden Beispiel wird der
or-Operator zum Kombinieren zweier DQDL-Regeln verwendet.(RowCount "id" > 100) or (IsPrimaryKey "id")
Sie können denselben Operator verwenden, um mehrere Regeln zu verbinden, daher ist die folgende Regelkombination zulässig.
(Mean "Star_Rating" > 3) and (Mean "Order_Total" > 500) and (IsComplete "Order_Id")Sie können die logischen Operatoren zu einem einzigen Ausdruck kombinieren. Zum Beispiel:
(Mean "Star_Rating" > 3) and ((Mean "Order_Total" > 500) or (IsComplete "Order_Id"))Sie können auch komplexere, verschachtelte Regeln erstellen.
(RowCount > 0) or ((IsComplete "colA") and (IsUnique "colA"))So funktionieren zusammengesetzte Regeln
Standardmäßig werden Verbundregeln als einzelne Regeln für den gesamten Datensatz oder die gesamte Tabelle ausgewertet, und anschließend werden die Ergebnisse kombiniert. Mit anderen Worten, zuerst wird die gesamte Spalte ausgewertet und dann der Operator angewendet. Dieses Standardverhalten wird im Folgenden anhand eines Beispiels erklärt:
# Dataset
+------+------+
|myCol1|myCol2|
+------+------+
| 2| 1|
| 0| 3|
+------+------+
# Overall outcome
+----------------------------------------------------------+-------+
|Rule |Outcome|
+----------------------------------------------------------+-------+
|(ColumnValues "myCol1" > 1) OR (ColumnValues "myCol2" > 2)|Failed |
+----------------------------------------------------------+-------+
Im obigen Beispiel AWS Glue Data Quality bewertet zunächst(ColumnValues "myCol1" > 1), was zu einem Ausfall führen wird. Dann wird bewertet(ColumnValues "myCol2" > 2), was ebenfalls fehlschlagen wird. Die Kombination beider Ergebnisse wird als FEHLGESCHLAGEN vermerkt.
Wenn Sie jedoch ein SQL-ähnliches Verhalten bevorzugen, bei dem die gesamte Zeile ausgewertet werden muss, müssen Sie den ruleEvaluation.scope Parameter explizit festlegen, wie additionalOptions im folgenden Codeausschnitt gezeigt.
object GlueApp {
val datasource = glueContext.getCatalogSource(
database="<db>",
tableName="<table>",
transformationContext="datasource"
).getDynamicFrame()
val ruleset = """
Rules = [
(ColumnValues "age" >= 26) OR (ColumnLength "name" >= 4)
]
"""
val dq_results = EvaluateDataQuality.processRows(
frame=datasource,
ruleset=ruleset,
additionalOptions=JsonOptions("""
{
"compositeRuleEvaluation.method":"ROW"
}
"""
)
)
}
In AWS Glue Data Catalog können Sie diese Option einfach in der Benutzeroberfläche konfigurieren, wie unten gezeigt.
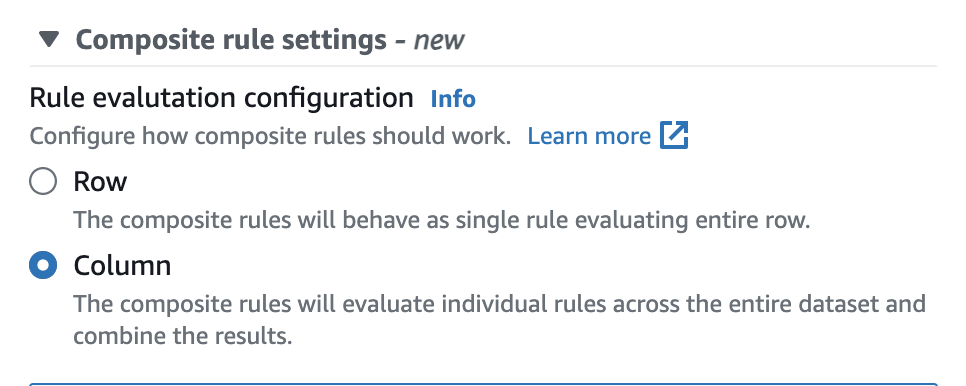
Sobald sie festgelegt sind, verhalten sich die zusammengesetzten Regeln wie eine einzige Regel, die die gesamte Zeile auswertet. Das folgende Beispiel veranschaulicht dieses Verhalten.
# Row Level outcome
+------+------+------------------------------------------------------------+---------------------------+
|myCol1|myCol2|DataQualityRulesPass |DataQualityEvaluationResult|
+------+------+------------------------------------------------------------+---------------------------+
|2 |1 |[(ColumnValues "myCol1" > 1) OR (ColumnValues "myCol2" > 2)]|Passed |
|0 |3 |[(ColumnValues "myCol1" > 1) OR (ColumnValues "myCol2" > 2)]|Passed |
+------+------+------------------------------------------------------------+---------------------------+
Einige Regeln können in dieser Funktion nicht unterstützt werden, da ihr Gesamtergebnis von Schwellenwerten oder Verhältnissen abhängt. Sie sind unten aufgeführt.
Regeln, die sich auf Kennzahlen stützen:
-
Vollständigkeit
-
DatasetMatch
-
ReferentialIntegrity
-
Eindeutigkeit
Regeln, die von Schwellenwerten abhängen:
Wenn die folgenden Regeln einen Schwellenwert enthalten, werden sie nicht unterstützt. Regeln, die das nicht beinhalten, werden jedoch with threshold weiterhin unterstützt.
-
ColumnDataType
-
ColumnValues
-
CustomSQL
Ausdrücke
Wenn ein Regeltyp keine boolesche Antwort erzeugt, müssen Sie einen Ausdruck als Parameter angeben, um eine boolesche Antwort zu erstellen. Die folgende Regel prüft beispielsweise den Mittelwert (Durchschnitt) aller Werte in einer Spalte anhand eines Ausdrucks, um ein wahres oder falsches Ergebnis zurückzugeben.
Mean "colA" between 80 and 100Einige Regeltypen wie IsUnique und IsComplete geben bereits eine boolesche Antwort zurück.
In der folgenden Tabelle sind Ausdrücke aufgeführt, die Sie in DQDL-Regeln verwenden können.
| Expression | Beschreibung | Beispiel |
|---|---|---|
=x |
Löst den Wert auf, true wenn der Regeltyp der Antwort gleich ist. x |
|
!=x
|
x Wird als wahr aufgelöst, wenn die Regeltypantwort ungleich ist. x |
|
> x |
Löst den Wert auf, true wenn die Regeltypantwort größer als ist. x |
|
< x |
Löst das Problem auf, true wenn die Regeltypantwort kleiner als ist. x |
|
>= x |
Löst auf, true ob die Regeltypantwort größer oder gleich ist. x |
|
<= x |
Löst auf, true ob die Regeltypantwort kleiner oder gleich ist. x |
|
zwischen und x y |
Löst sich zu true auf, wenn die Antwort des Regeltyps in einen bestimmten Bereich fällt (exklusiv). Verwenden Sie diesen Ausdruckstyp nur für Zahlen- und Datumstypen. |
|
nicht zwischen x und y |
Wird als wahr aufgelöst, wenn die Regeltyp-Antwort nicht in einen bestimmten Bereich (einschließlich) fällt. Sie sollten diesen Ausdruckstyp nur für Zahlen- und Datumstypen verwenden. |
|
in [] a, b, c, ... |
Löst sich zu true auf, wenn die Antwort des Regeltyps in der angegebenen Menge enthalten ist. |
|
nicht in [a, b, c, ...] |
Löst das Problem auf, true wenn die Antwort vom Regeltyp nicht im angegebenen Satz enthalten ist. |
|
stimmt überein /ab+c/i |
Löst sich zu true auf, wenn die Antwort des Regeltyps mit einem regulären Ausdruck übereinstimmt. |
|
keine Spiele /ab+c/i |
Löst das Problem auf, true wenn die Regeltyp-Antwort keinem regulären Ausdruck entspricht. |
|
now() |
Funktioniert nur mit dem ColumnValues-Regeltyp zum Erstellen eines Datumsausdrucks. |
|
matches/in […]/not matches/notin [...] with threshold |
Gibt den Prozentsatz der Werte an, die den Regelbedingungen entsprechen. Funktioniert nur mit den CustomSQL Regeltypen ColumnValuesColumnDataType, und. |
|
Schlüsselwörter für NULL, EMPTY und WHITESPACES_ONLY
Wenn Sie überprüfen möchten, ob eine Zeichenkettenspalte eine Null, eine leere Spalte oder eine Zeichenfolge mit nur Leerzeichen enthält, können Sie die folgenden Schlüsselwörter verwenden:
-
NULL/null — Dieses Schlüsselwort wird für einen
nullWert in einer Zeichenkettenspalte als wahr aufgelöst.ColumnValues "colA" != NULL with threshold > 0.5würde true zurückgeben, wenn mehr als 50% Ihrer Daten keine Nullwerte enthalten.(ColumnValues "colA" = NULL) or (ColumnLength "colA" > 5)würde für alle Zeilen, die entweder einen Nullwert oder eine Länge von > 5 haben, true zurückgeben. Beachten Sie, dass dafür die Option „compositeRuleEvaluation.method“ = „ROW“ verwendet werden muss. -
EMPTY/empty — Dieses Schlüsselwort wird für einen leeren Zeichenkettenwert („“) in einer Zeichenkettenspalte als wahr aufgelöst. Bei einigen Datenformaten werden Nullen in einer Zeichenkettenspalte in leere Zeichenketten umgewandelt. Dieses Schlüsselwort hilft dabei, leere Zeichenketten in Ihren Daten herauszufiltern.
(ColumnValues "colA" = EMPTY) or (ColumnValues "colA" in ["a", "b"])würde true zurückgeben, wenn eine Zeile entweder leer ist, „a“ oder „b“. Beachten Sie, dass dies die Verwendung der Option „compositeRuleEvaluation.method“ = „ROW“ erfordert. -
WHITESPACES_ONLY//whitespaces_only — Dieses Schlüsselwort wird für eine Zeichenfolge mit nur Leerzeichen („“) in einer Zeichenkettenspalte als wahr aufgelöst.
ColumnValues "colA" not in ["a", "b", WHITESPACES_ONLY]würde true zurückgeben, wenn eine Zeile weder „a“ oder „b“ noch nur Leerzeichen enthält.Unterstützte Regeln:
Wenn Sie für einen numerischen oder datumsbasierten Ausdruck überprüfen möchten, ob eine Spalte eine Null enthält, können Sie die folgenden Schlüsselwörter verwenden.
-
NULL/null — Dieses Schlüsselwort wird für einen Nullwert in einer Zeichenfolgenspalte als wahr aufgelöst.
ColumnValues "colA" in [NULL, "2023-01-01"]würde true zurückgeben, wenn ein Datum in Ihrer Spalte entweder2023-01-01oder Null ist.(ColumnValues "colA" = NULL) or (ColumnValues "colA" between 1 and 9)würde für alle Zeilen, die entweder einen Nullwert oder Werte zwischen 1 und 9 haben, true zurückgeben. Beachten Sie, dass hierfür die Option „compositeRuleEvaluation.method“ = „ROW“ verwendet werden muss.Unterstützte Regeln:
Filterung mit der Where-Klausel
Anmerkung
Where Clause wird nur in AWS Glue 4.0 unterstützt.
Sie können Ihre Daten beim Erstellen von Regeln filtern. Dies ist hilfreich, wenn Sie bedingte Regeln anwenden möchten.
<DQDL Rule> where "<valid SparkSQL where clause> " Der Filter muss mit dem where Schlüsselwort angegeben werden, gefolgt von einer gültigen SparkSQL, die in Anführungszeichen eingeschlossen ist. ("")
Wenn die Regel, der Sie die WHERE-Klausel hinzufügen möchten, zu einer Regel mit einem Schwellenwert hinzufügen möchten, sollte die WHERE-Klausel vor der Schwellenwertbedingung angegeben werden.
<DQDL Rule> where "valid SparkSQL statement>" with threshold <threshold condition>
Mit dieser Syntax können Sie Regeln wie die folgenden schreiben.
Completeness "colA" > 0.5 where "colB = 10"
ColumnValues "colB" in ["A", "B"] where "colC is not null" with threshold > 0.9
ColumnLength "colC" > 10 where "colD != Concat(colE, colF)" Wir werden überprüfen, ob die SparkSQL SparkSQL-Anweisung gültig ist. Falls ungültig, schlägt die Regelauswertung fehl und wir geben eine an im folgenden IllegalArgumentException Format aus:
Rule <DQDL Rule> where "<invalid SparkSQL>" has provided an invalid where clause :
<SparkSQL Error>Verhalten der Where-Klausel, wenn die Identifizierung von Fehlerdatensätzen auf Zeilenebene aktiviert ist
Mit AWS Glue Data Quality können Sie bestimmte Datensätze identifizieren, bei denen Fehler aufgetreten sind. Wenn wir eine WHERE-Klausel auf Regeln anwenden, die Ergebnisse auf Zeilenebene unterstützen, kennzeichnen wir die Zeilen, die durch die WHERE-Klausel herausgefiltert werden, alsPassed.
Wenn Sie es vorziehen, die herausgefilterten Zeilen separat als zu kennzeichnenSKIPPED, können Sie additionalOptions für den ETL-Job Folgendes festlegen.
object GlueApp {
val datasource = glueContext.getCatalogSource(
database="<db>",
tableName="<table>",
transformationContext="datasource"
).getDynamicFrame()
val ruleset = """
Rules = [
IsComplete "att2" where "att1 = 'a'"
]
"""
val dq_results = EvaluateDataQuality.processRows(
frame=datasource,
ruleset=ruleset,
additionalOptions=JsonOptions("""
{
"rowLevelConfiguration.filteredRowLabel":"SKIPPED"
}
"""
)
)
}Sehen Sie sich als Beispiel die folgende Regel und den folgenden Datenrahmen an:
IsComplete att2 where "att1 = 'a'"| id | att1 | att2 | Ergebnisse auf Zeilenebene (Standard) | Ergebnisse auf Zeilenebene (Option übersprungen) | Kommentare |
|---|---|---|---|---|---|
| 1 | a | f | BESTANDEN | BESTANDEN | |
| 2 | b | d | BESTANDEN | SKIPPED | Zeile ist herausgefiltert, att1 da nicht "a" |
| 3 | a | Null | FEHLGESCHLAGEN | FEHLGESCHLAGEN | |
| 4 | a | f | BESTANDEN | BESTANDEN | |
| 5 | b | Null | BESTANDEN | SKIPPED | Zeile ist herausgefiltert, att1 da nicht "a" |
| 6 | a | f | BESTANDEN | BESTANDEN |
Dynamische Regeln
Anmerkung
Dynamische Regeln werden nur in AWS Glue ETL unterstützt und nicht im AWS Glue Data Catalog.
Sie können jetzt dynamische Regeln erstellen, um aktuelle Metriken, die anhand Ihrer Regeln erstellt wurden, mit ihren historischen Werten zu vergleichen. Diese historischen Vergleiche werden durch die Verwendung des Operators last() in Ausdrücken ermöglicht. Beispielsweise ist die Regel RowCount >
last() erfolgreich, wenn die Anzahl der Zeilen im aktuellen Durchlauf größer ist als die letzte vorherige Anzahl der Zeilen im selben Datensatz. last() verwendet ein optionales Argument mit einer natürlichen Zahl, das beschreibt, wie viele vorherige Metriken berücksichtigt werden sollen. Bei last(k) verweist k
>= 1 auf die letzten k Metriken.
-
Wenn keine Datenpunkte verfügbar sind, gibt
last(k)den Standardwert 0,0 zurück. -
Wenn weniger als
kMetriken verfügbar sind, gibtlast(k)alle vorherigen Metriken zurück.
Verwenden Sie zur Bildung von Ausdrücken last(k), wobei k > 1 eine Aggregationsfunktion erfordert, um mehrere historische Ergebnisse auf eine einzelne Zahl zu reduzieren. Beispielsweise prüft RowCount > avg(last(5)), ob die aktuelle Zeilenanzahl des Datensatzes grundsätzlich höher ist als der Durchschnitt der letzten fünf Zeilenanzahlen desselben Datensatzes. RowCount > last(5) gibt einen Fehler aus, weil die aktuelle Zeilenanzahl des Datensatzes nicht aussagekräftig mit einer Liste verglichen werden kann.
Unterstützte Aggregationsfunktionen:
-
avg -
median -
max -
min -
sum -
std(Standardabweichung) -
abs(absoluter Wert) -
index(last(k), i)ermöglicht die Auswahl desi.-letzten Werts der letztenk.ihat einen Nullindex,index(last(3), 0)gibt also den neuesten Datenpunkt zurück undindex(last(3), 3)führt zu einem Fehler, da es nur drei Datenpunkte gibt und wir versuchen, den viertletzten zu indizieren.
Beispielausdrücke
ColumnCorrelation
ColumnCorrelation "colA" "colB" < avg(last(10))
DistinctValuesCount
DistinctValuesCount "colA" between min(last(10))-1 and max(last(10))+1
Die meisten Regeltypen mit numerischen Bedingungen oder Schwellenwerten unterstützen dynamische Regeln. In der bereitgestellten Tabelle Analysatoren und Regeln können Sie ermitteln, ob Ihr Regeltyp dynamische Regeln unterstützt.
Ausschließen von Statistiken aus dynamischen Regeln
Manchmal müssen Sie Datenstatistiken von Ihren dynamischen Regelberechnungen ausschließen. Nehmen wir an, Sie haben historische Daten geladen und möchten nicht, dass sich dies auf Ihre Durchschnittswerte auswirkt. Öffnen Sie dazu den Job in AWS Glue ETL und wählen Sie die Registerkarte Datenqualität. Wählen Sie dann Statistik und wählen Sie die Statistiken aus, die Sie ausschließen möchten. Sie werden ein Trenddiagramm zusammen mit einer Statistiktabelle sehen können. Wählen Sie die Werte aus, die Sie ausschließen möchten, und wählen Sie Statistik ausschließen. Jetzt werden die ausgeschlossenen Statistiken nicht in die dynamischen Regelberechnungen einbezogen.

Analysatoren
Anmerkung
Analysatoren werden im AWS Glue Data Catalog nicht unterstützt.
DQDL-Regeln verwenden Funktionen, die als Analysatoren bezeichnet werden, um Informationen über Ihre Daten zu sammeln. Diese Informationen werden vom booleschen Ausdruck einer Regel verwendet, um zu bestimmen, ob die Regel erfolgreich sein oder fehlschlagen soll. Die RowCount Regel RowCount > 5 verwendet beispielsweise einen Analysator für die Zeilenanzahl, um die Anzahl der Zeilen in Ihrem Datensatz zu ermitteln und diese Anzahl mit dem Ausdruck > 5 zu vergleichen, um zu überprüfen, ob im aktuellen Datensatz mehr als fünf Zeilen vorhanden sind.
Manchmal empfehlen wir, anstelle von Regeln Analysatoren zu erstellen und diese dann Statistiken generieren zu lassen, anhand derer Anomalien erkannt werden können. In solchen Fällen können Sie Analysatoren erstellen. Analysatoren unterscheiden sich folgendermaßen von Regeln.
| Merkmal | Analysatoren | Regeln |
|---|---|---|
| Teil des Regelsatzes | Ja | Ja |
| Generiert Statistiken | Ja | Ja |
| Generiert Beobachtungen | Ja | Ja |
| Kann eine Bedingung bewerten und durchsetzen | Nein | Ja |
| Aktionen wie das Stoppen von Aufträgen bei einem Fehler oder die Fortsetzung der Auftragsverarbeitung können konfiguriert werden | Nein | Ja |
Analysatoren können unabhängig voneinander ohne Regeln existieren, sodass Sie sie schnell konfigurieren und schrittweise Regeln für die Datenqualität erstellen können.
Einige Regeltypen können in den Analyzers-Block Ihres Regelsatzes eingegeben werden, um die für Analysatoren erforderlichen Regeln auszuführen und Informationen zu sammeln, ohne auf Bedingungen zu prüfen. Einige Analysatoren sind nicht mit Regeln verknüpft und können nur in den Analyzers-Block eingegeben werden. Die folgende Tabelle gibt an, ob einzelne Elemente als Regel oder als eigenständige Analysatoren unterstützt werden und enthält zusätzliche Details zu jedem Regeltyp.
Beispiel für einen Regelsatz mit Analyzer
Der folgende Regelsatz verwendet
-
eine dynamische Regel, mit der überprüft wird, ob ein Datensatz den Durchschnitt seiner letzten drei Auftragsausführungen überschreitet;
-
einen
DistinctValuesCount-Analysator, um die Anzahl unterschiedlicher Werte in der SpalteNamedes Datensatzes zu erfassen; -
einen
ColumnLength-Analysator, um die minimale und maximale Größe desNameim Laufe der Zeit nachzuverfolgen.
Die Ergebnisse der Analysatormetriken können auf der Registerkarte „Datenqualität“ der Auftragsausführung eingesehen werden.
Rules = [
RowCount > avg(last(3))
]
Analyzers = [
DistinctValuesCount "Name",
ColumnLength "Name"
]
AWS Glue Data Quality unterstützt die folgenden Analysatoren.
| Name des Analyzers | Funktionalität |
|---|---|
RowCount |
Berechnet die Zeilenanzahl für einen Datensatz |
Completeness |
Berechnet den Vollständigkeitsgrad einer Spalte |
Uniqueness |
Berechnet den Eindeutigkeitsprozentsatz einer Spalte |
Mean |
Berechnet den Mittelwert einer numerischen Spalte |
Sum |
Berechnet die Summe einer numerischen Spalte |
StandardDeviation |
Berechnet die Standardabweichung einer numerischen Spalte |
Entropy |
Berechnet die Entropie einer numerischen Spalte |
DistinctValuesCount |
Berechnet die Anzahl der unterschiedlichen Werte in einer Spalte |
UniqueValueRatio |
Berechnet das Verhältnis der Einzelwerte in einer Spalte |
ColumnCount |
Berechnet die Anzahl der Spalten in einem Datensatz |
ColumnLength |
Berechnet die Länge einer Spalte |
ColumnValues |
Berechnet das Minimum und Maximum für numerische Spalten. Berechnet das Minimum ColumnLength und das Maximum ColumnLength für nicht numerische Spalten |
ColumnCorrelation |
Berechnet Spaltenkorrelationen für gegebene Spalten |
CustomSql |
Berechnet Statistiken, die von CustomSQL zurückgegeben werden |
AllStatistics |
Berechnet die folgenden Statistiken:
|
Kommentare
Sie können das Zeichen '#' verwenden, um Ihrem DQDL-Dokument einen Kommentar hinzuzufügen. Alles nach dem Zeichen '#' und bis zum Ende der Zeile wird von DQDL ignoriert.
Rules = [
# More items should generally mean a higher price, so correlation should be positive
ColumnCorrelation "price" "num_items" > 0
]