Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Zu Sicherheits-, Überwachungs- oder Kontrollzwecken möchten Sie möglicherweise, dass auf Ihren Amazon-S3-Datenspeicher oder Ihre Amazon-S3-gestützte Datenkatalog-Tabelle nur über eine Amazon-Virtual-Private-Cloud(Amazon VPC)-Umgebung zugegriffen wird. In diesem Thema wird beschrieben, wie Sie eine Verbindung zum Amazon-S3-Datenspeicher oder zur Amazon-S3-gestützten Datenkatalog-Tabelle in einem VPC-Endpunkt mithilfe der Network-Verbindung herstellen.
Führen Sie die folgenden Aufgaben aus, um einen Crawler im Datenspeicher auszuführen:
Voraussetzungen
Überprüfen Sie, ob Sie diese Voraussetzungen für die Einrichtung Ihres Amazon-S3-Datenspeichers oder Ihrer Amazon-S3-gestützten Datenkatalog-Tabelle für den Zugriff über eine Amazon-Virtual-Private-Cloud(Amazon VPC)-Umgebung erfüllt haben.
-
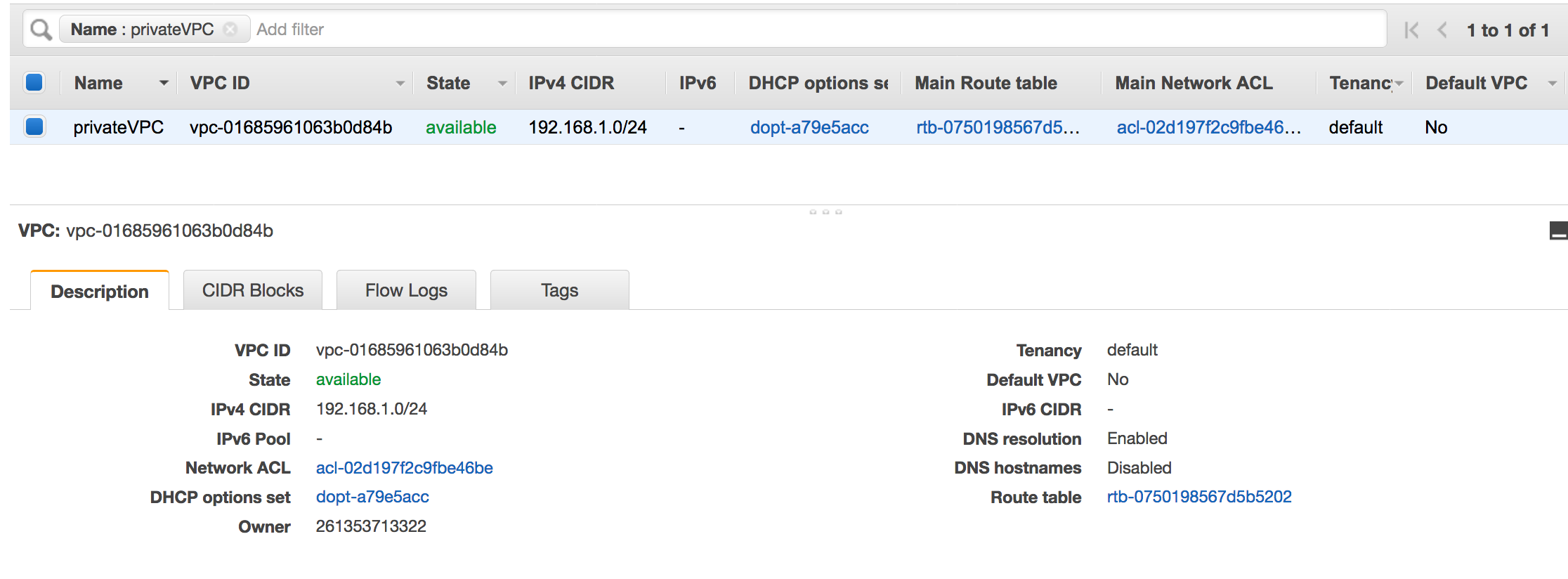
Eine konfigurierte VPC. Zum Beispiel: vpc-01685961063b0d84b. Weitere Informationen finden Sie unter Getting started with Amazon VPC (Erste Schritte mit Amazon VPC) im Amazon-VPC-Benutzerhandbuch.
-
Ein Amazon-S3-Endpunkt, der an die VPC angeschlossen ist. Zum Beispiel: vpc-01685961063b0d84b. Weitere Informationen finden Sie unter Endpoints for Amazon S3 (Endpunkte für Amazon S3) im Amazon-VPC-Benutzerhandbuch.
-
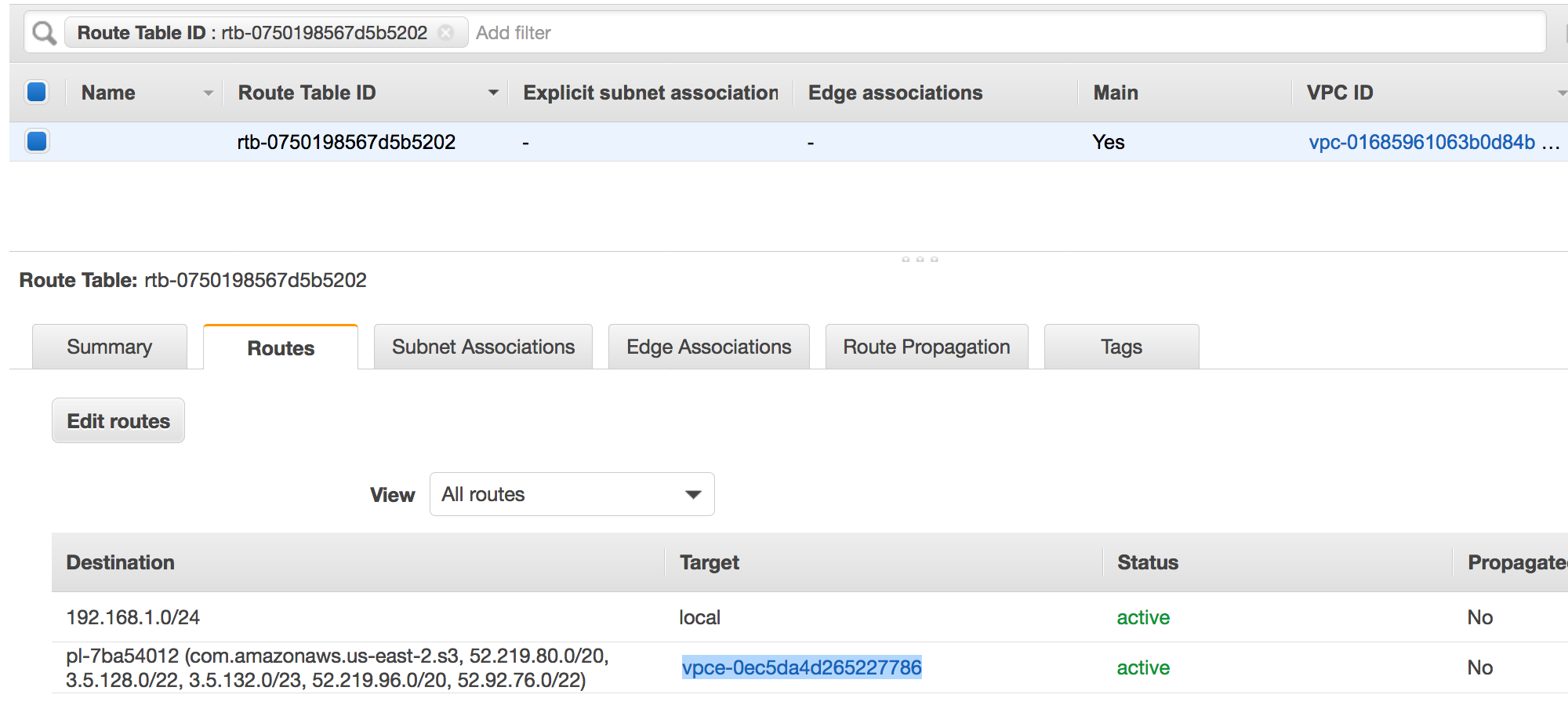
Ein Routeneintrag, der auf den VPC-Endpunkt verweist. Zum Beispiel vpce-0ec5da4d265227786 in der Routing-Tabelle, die vom VPC-Endpunkt verwendet wird (vpce-0ec5da4d265227786).
-
Eine Netzwerk-ACL, die an die VPC angeschlossen ist, erlaubt den Datenverkehr.
-
Eine an die VPC angeschlossene Sicherheitsgruppe erlaubt den Datenverkehr.
Herstellen der Verbindung zu Amazon S3
Typischerweise erstellen Sie diese Ressourcen innerhalb von Amazon Virtual Private Cloud (Amazon VPC), so dass sie nicht über das öffentliche Internet zugänglich sind. Standardmäßig AWS Glue kann nicht auf Ressourcen innerhalb einer VPC zugegriffen werden. Um den Zugriff auf Ressourcen innerhalb Ihrer VPC AWS Glue zu ermöglichen, müssen Sie zusätzliche VPC-spezifische Konfigurationsinformationen angeben, die das IDs VPC-Subnetz und die Sicherheitsgruppe umfassen. IDs Um eine Network-Verbindung herzustellen, benötigen Sie folgende Informationen:
-
EINE VPC-ID
-
Ein Subnetz innerhalb der VPC
-
Eine Sicherheitsgruppen-ID
Eine Network-Verbindung einrichten:
-
Wählen Sie im Navigationsbereich der AWS Glue -Konsole Add connection (Verbindung hinzufügen) aus.
-
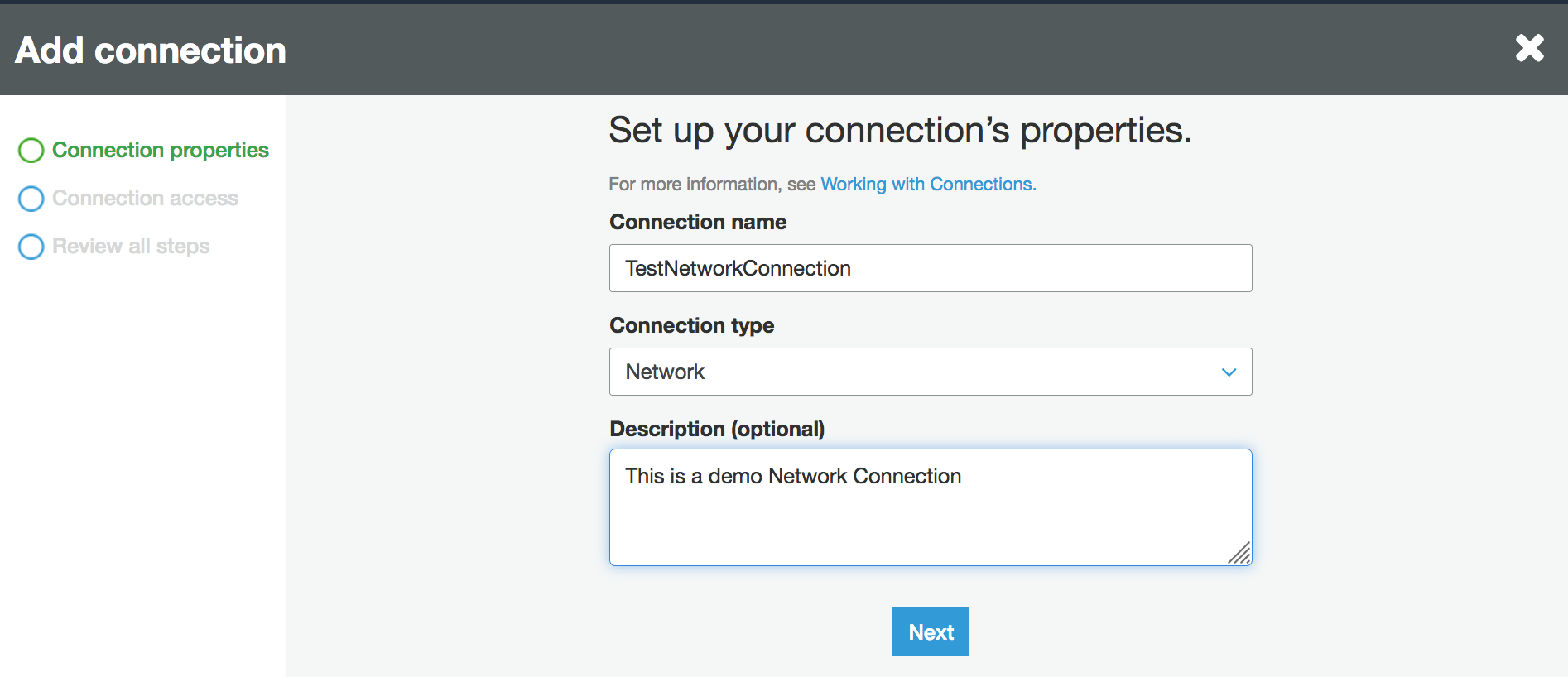
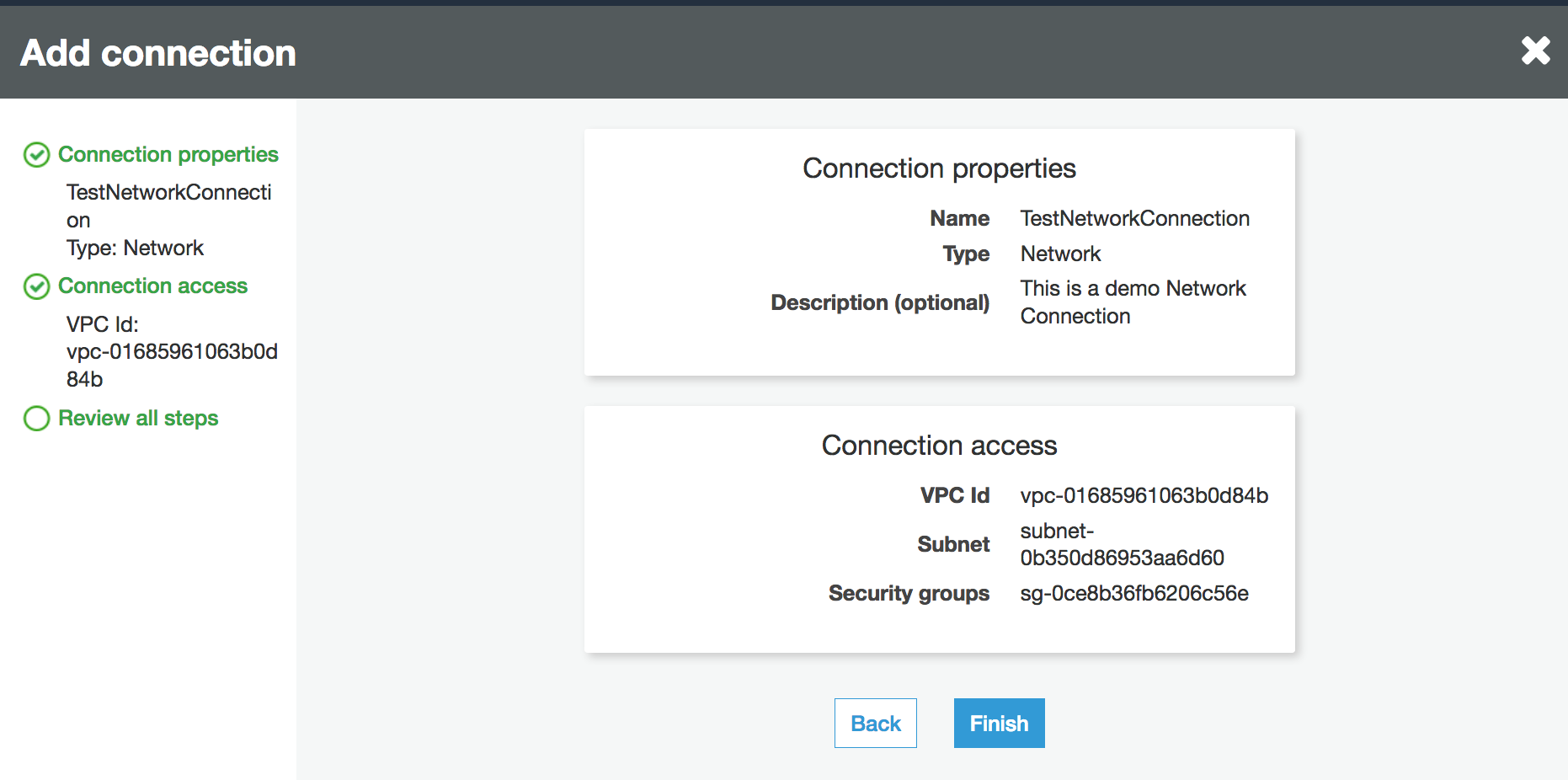
Geben Sie den Verbindungsnamen ein und wählen Sie Network (Netzwerk) als Verbindungstyp. Wählen Sie Next (Weiter).
-
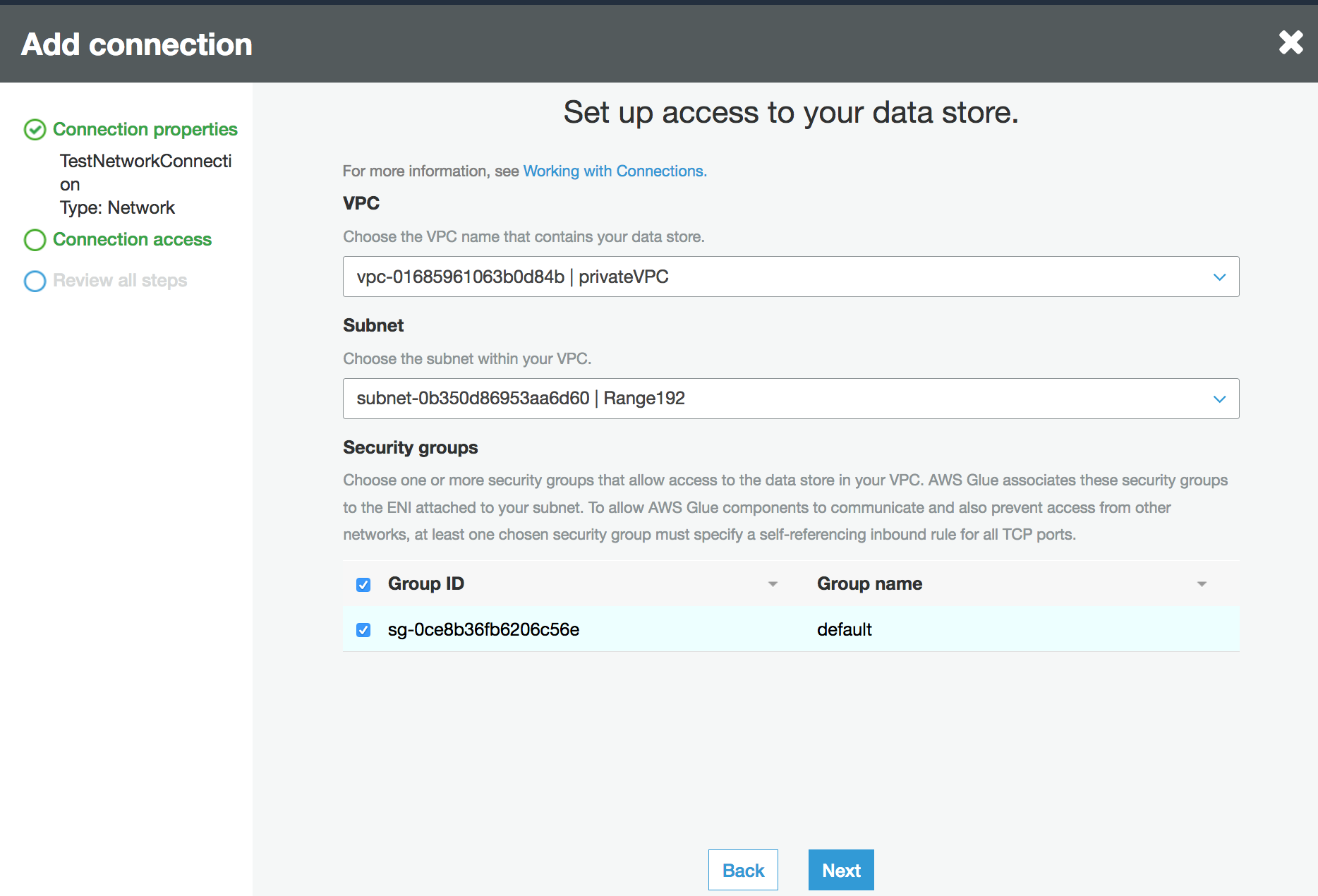
Konfigurieren Sie die VPC -, Subnetz- und Sicherheitsgruppeninformationen.
-
VPC: Wählen Sie den Namen der VPC aus, der Ihren Datenspeicher enthält.
-
Subnetz: Wählen Sie das Subnetz in Ihrer VPC aus.
-
Sicherheitsgruppen: Wählen Sie eine oder mehrere Sicherheitsgruppen aus, die den Zugriff auf den Datenspeicher in Ihrer VPC ermöglichen.
-
-
Wählen Sie Weiter.
-
Überprüfen Sie die Verbindungsinformationen und wählen Sie Finish (Beenden) aus.
Testen der Verbindung zu Amazon S3
Sobald Sie Ihre Network-Verbindung erstellt haben, können Sie die Konnektivität zu Ihrem Amazon-S3-Datenspeicher in einem VPC-Endpunkt testen.
Beim Testen einer Verbindung können folgende Fehler auftreten:
-
INTERNET-VERBINDUNGSFEHLER: zeigt ein Problem mit der Internetverbindung an
-
UNGÜLTIGER BUCKET FEHLER: deutet auf ein Problem mit dem Amazon S3 Bucket hin
-
S3 VERBINDUNGSFEHLER: zeigt einen Fehler bei der Verbindung zu Amazon S3 an
-
UNGÜLTIGER VERBINDUNGSTYP: weist darauf hin, dass der Verbindungstyp nicht den erwarteten Wert hat,
NETWORK -
UNGÜLTIGER VERBINDUNGSTESTTYP: weist auf ein Problem mit dem Typ des Netzwerkverbindungstests hin
-
INVALID TARGET: weist darauf hin, dass der Amazon S3 Bucket nicht richtig angegeben wurde
So testen Sie eine Network-Verbindung:
-
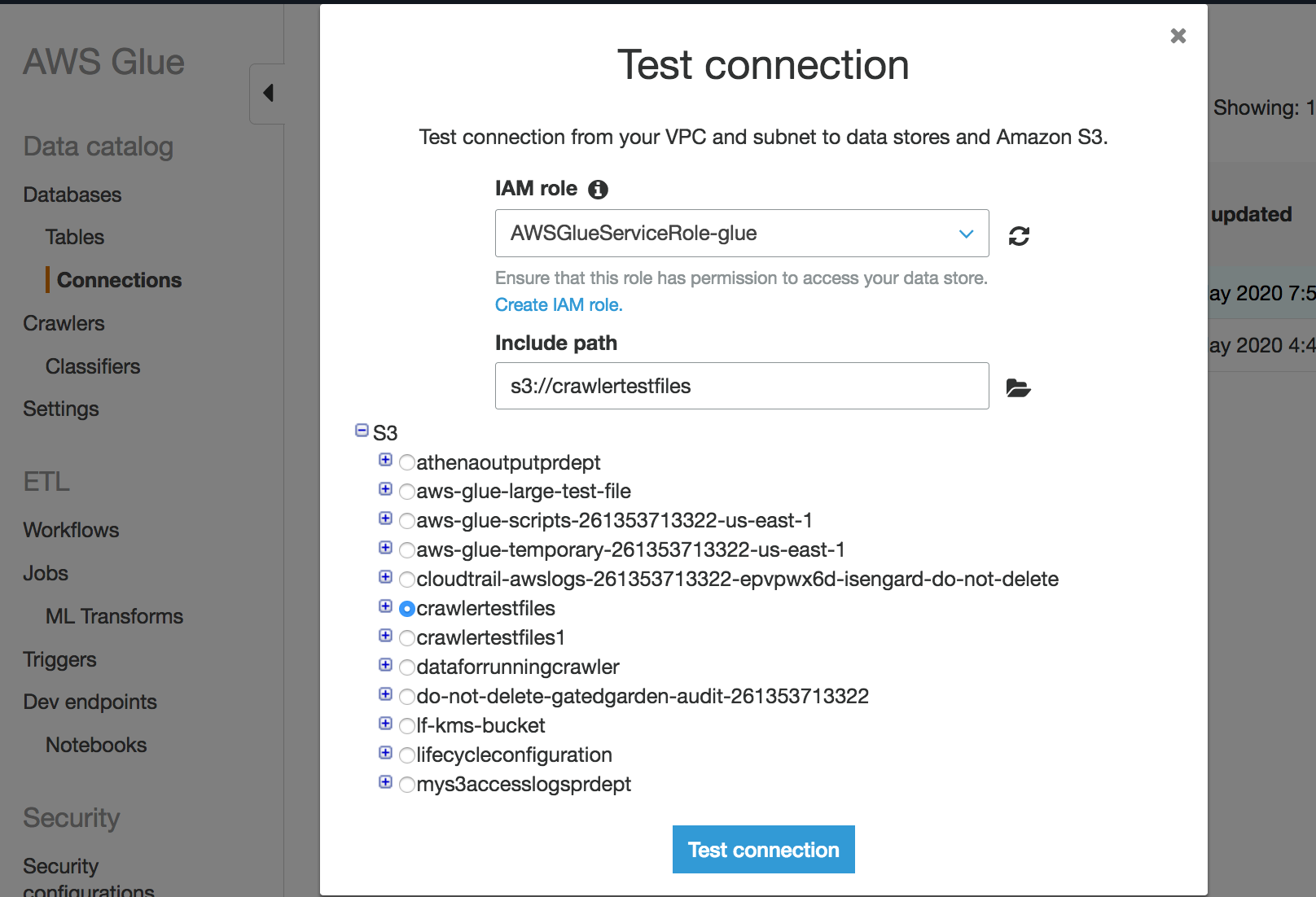
Wählen Sie die Netzwerkverbindung in der AWS Glue -Konsole aus.
-
Wählen Sie Test connection (Verbindung testen) aus.
-
Wählen Sie die IAM-Rolle aus, die Sie im vorherigen Schritt erstellt haben, und geben Sie einen Amazon S3 Bucket an.
-
Wählen Sie zum Starten des Tests Test connection (Verbindung testen) aus. Es kann einige Augenblicke dauern, um das Ergebnis zu zeigen.
Wenn Ihnen ein Fehler angezeigt wird, gehen Sie folgendermaßen vor:
-
Die richtigen Berechtigungen werden für die ausgewählte Rolle bereitgestellt.
-
Der richtige Amazon S3 Bucket wird bereitgestellt.
-
Die Sicherheitsgruppen und die Netzwerk-ACL ermöglichen den erforderlichen eingehenden und ausgehenden Datenverkehr.
-
Die angegebene VPC ist mit einem Amazon-S3-VPC-Endpunkt verbunden.
Sobald Sie die Verbindung erfolgreich getestet haben, können Sie einen Crawler erstellen.
Erstellen eines Crawlers für einen Amazon-S3-Datenspeicher
Jetzt können Sie einen Crawler erstellen, der die Network-Verbindung angibt, die Sie erstellt haben. Weitere Informationen zum Erstellen eines Crawlers finden Sie unter Konfiguration eines Crawlers.
-
Wählen Sie zunächst im Navigationsbereich der Konsole Crawlers aus. AWS Glue
-
Wählen Sie Add crawler (Crawler hinzufügen).
-
Geben Sie dem Crawler einen Namen und klicken Sie auf Next (Weiter).
-
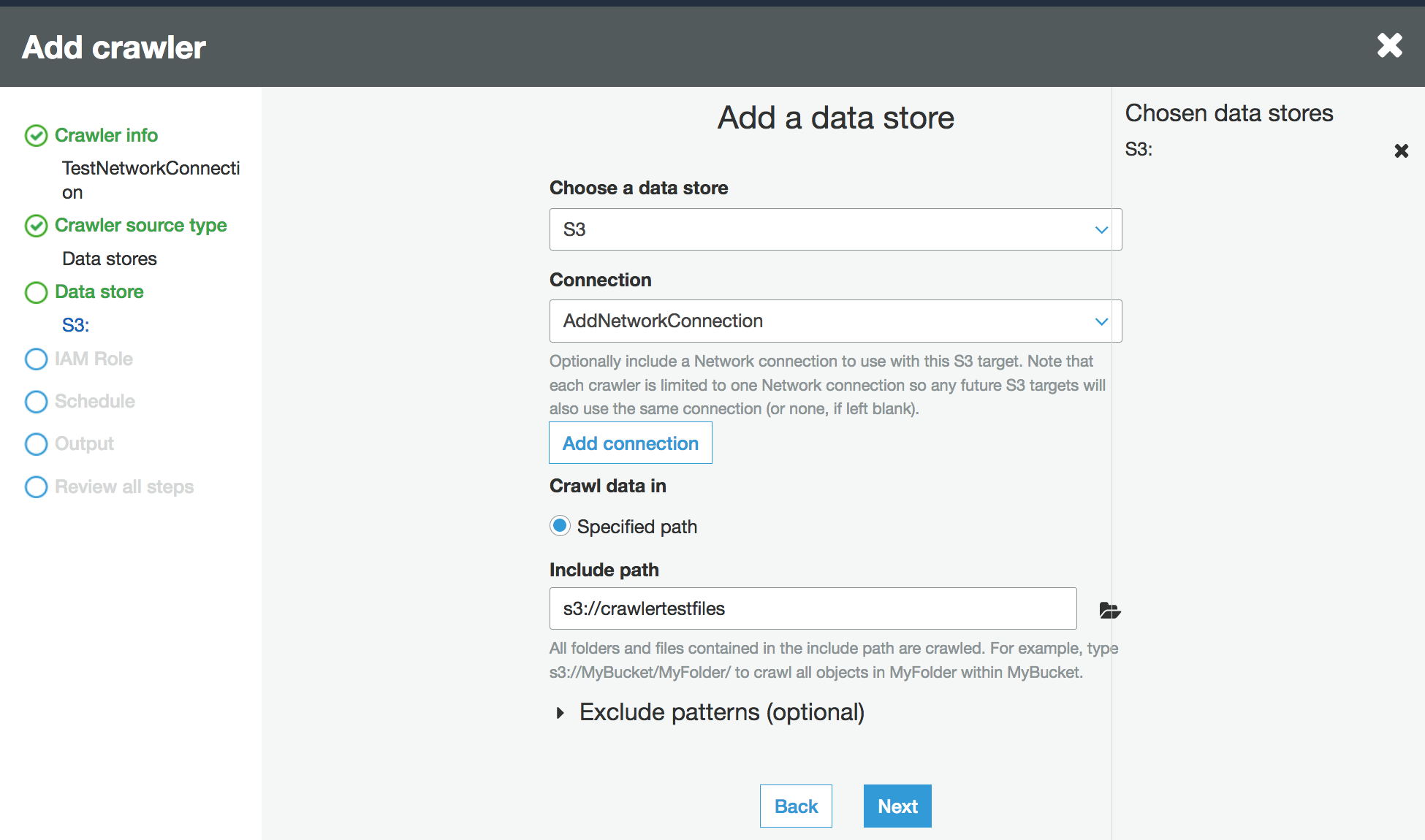
Wählen Sie bei der Aufforderung zur Datenquelle S3 aus und geben Sie das Präfix für den Amazon S3 Bucket und die Verbindung an, die Sie zuvor erstellt haben.
-
Fügen Sie ggf. einen anderen Datenspeicher auf derselben Netzwerkverbindung hinzu.
-
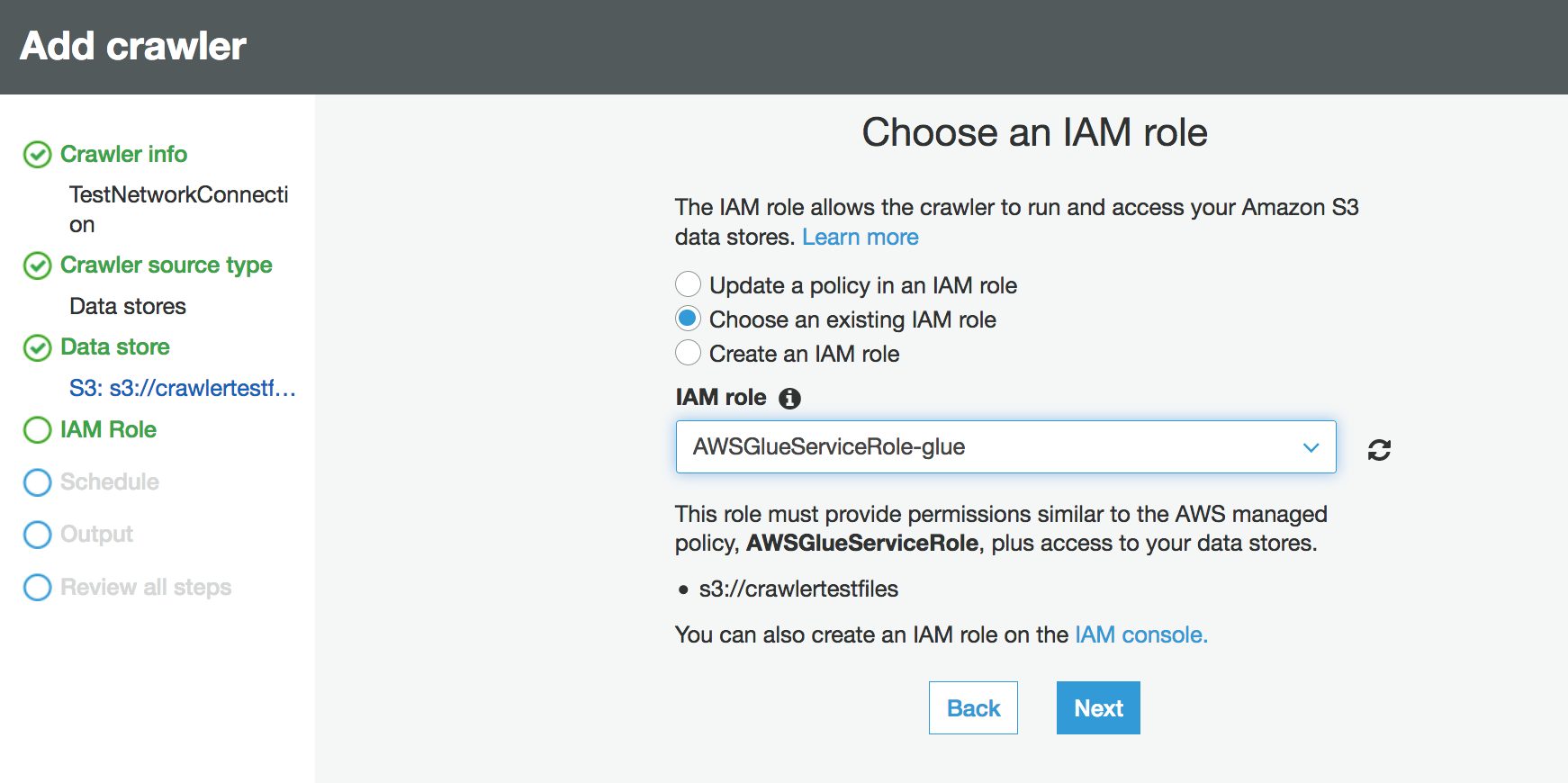
Wählen Sie die IAM-Rolle aus. Die IAM-Rolle muss den Zugriff auf den AWS Glue -Service und den Amazon S3 Bucket gestatten. Weitere Informationen finden Sie unter Konfiguration eines Crawlers.
-
Definieren Sie den Zeitplan für den Crawler.
-
Wählen Sie eine vorhandene Datenbank im Data Catalog aus oder erstellen Sie einen neuen Datenbankeintrag.
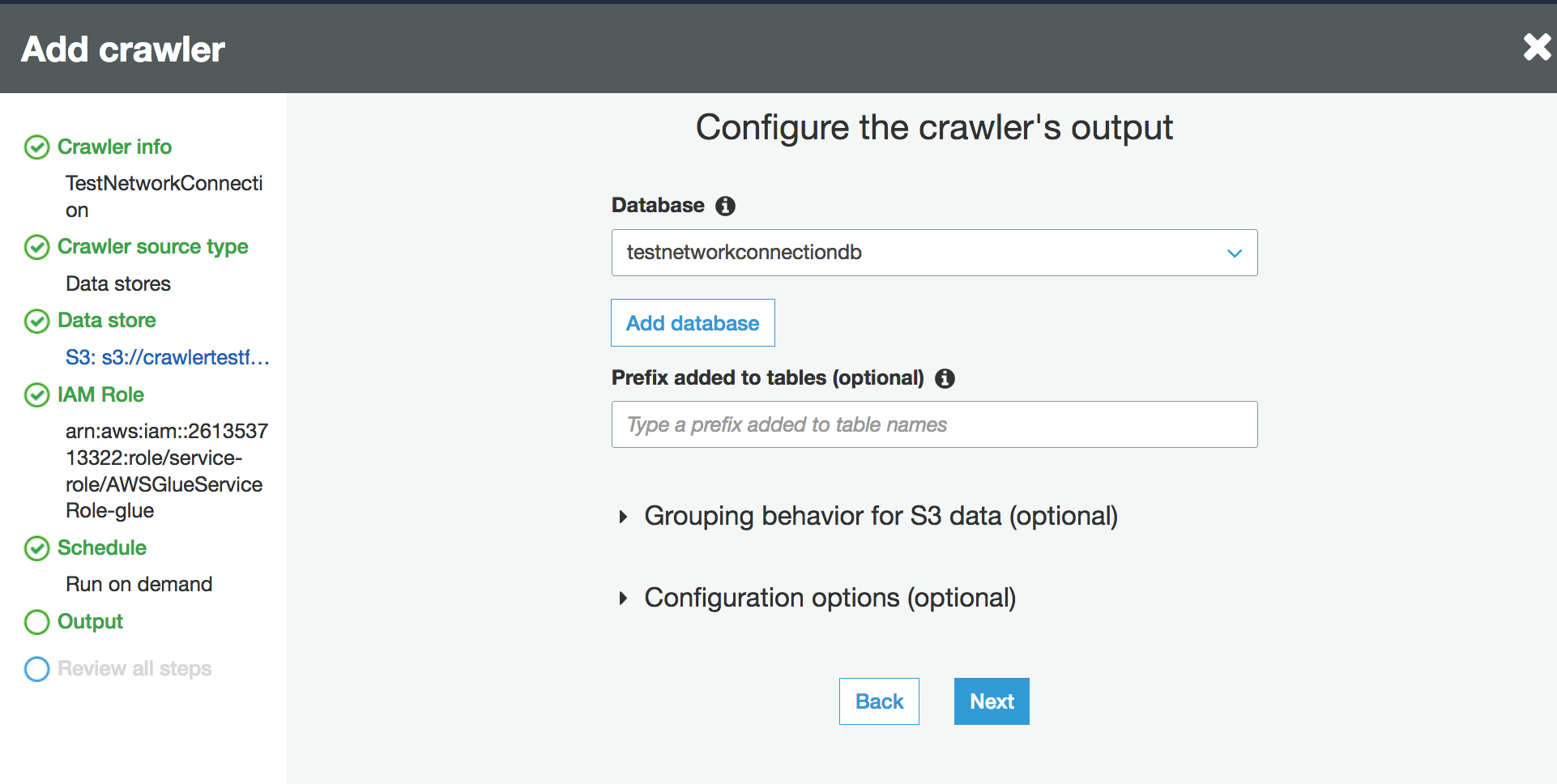
-
Beenden Sie die verbleibende Einrichtung.
Erstellen eines Crawlers für Amazon-S3-unterstützte Datenkatalog-Tabellen
Sie können jetzt einen Crawler erstellen, der die von Ihnen erstellte Network-Verbindung und einen Katalogquelltyp angibt. Weitere Informationen zum Erstellen eines Crawlers finden Sie unter Konfiguration eines Crawlers.
-
Wählen Sie zunächst im Navigationsbereich der Konsole Crawlers aus. AWS Glue
-
Wählen Sie Add crawler (Crawler hinzufügen).
-
Geben Sie dem Crawler einen Namen und klicken Sie auf Next (Weiter).
-
Wenn Sie nach dem Crawler-Quellentyp gefragt werden, wählen Sie Bestehende Katalogtabellen, und geben Sie die vorhandenen Katalogtabellen an, die aus der Liste der verfügbaren Tabellen gecrawlt werden sollen.
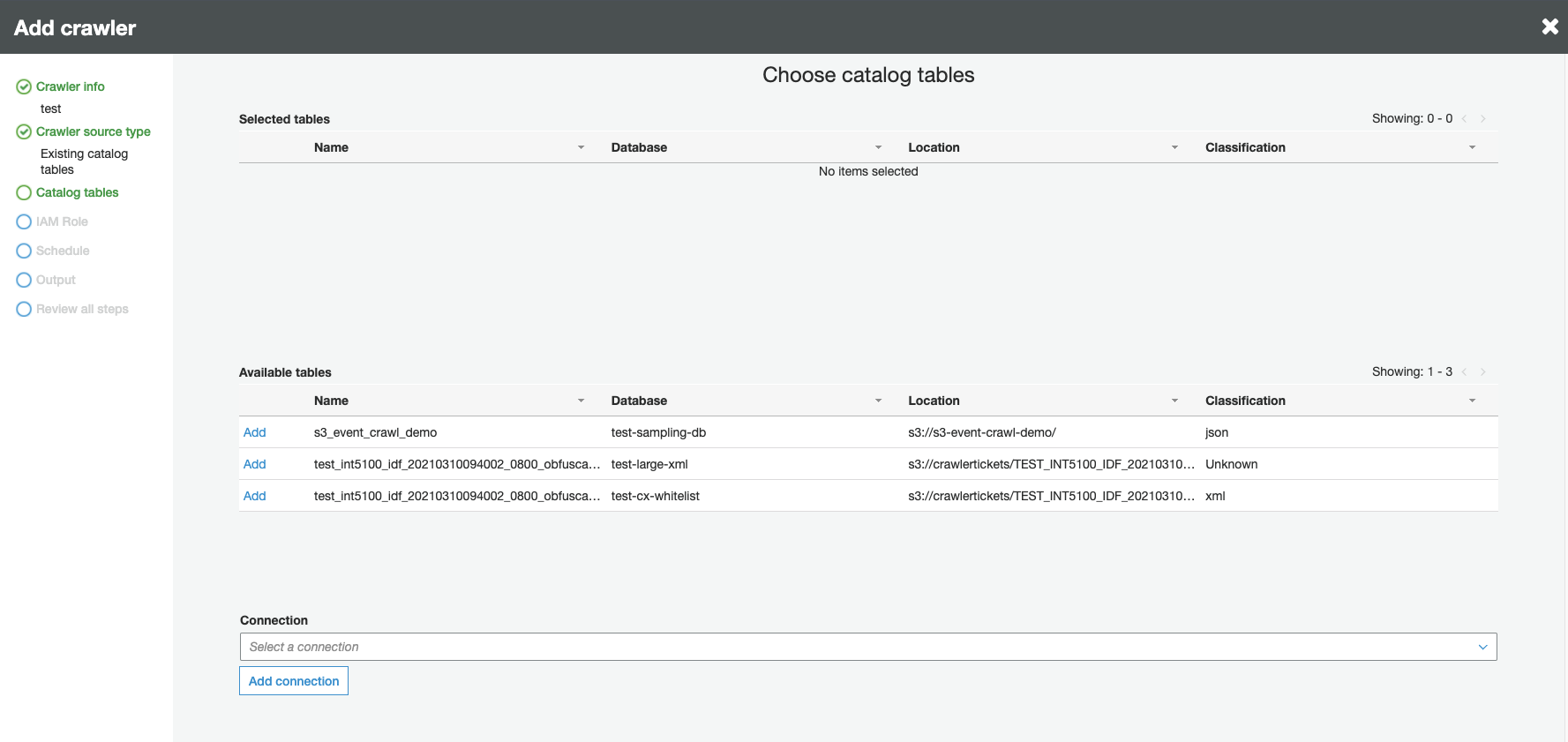
-
Wählen Sie die IAM-Rolle aus. Die IAM-Rolle muss den Zugriff auf den AWS Glue -Service und den Amazon S3 Bucket gestatten. Weitere Informationen finden Sie unter Konfiguration eines Crawlers.
-
Definieren Sie den Zeitplan für den Crawler.
-
Wählen Sie eine vorhandene Datenbank im Data Catalog aus oder erstellen Sie einen neuen Datenbankeintrag.
-
Beenden Sie die verbleibende Einrichtung und überprüfen Sie Ihre Schritte.
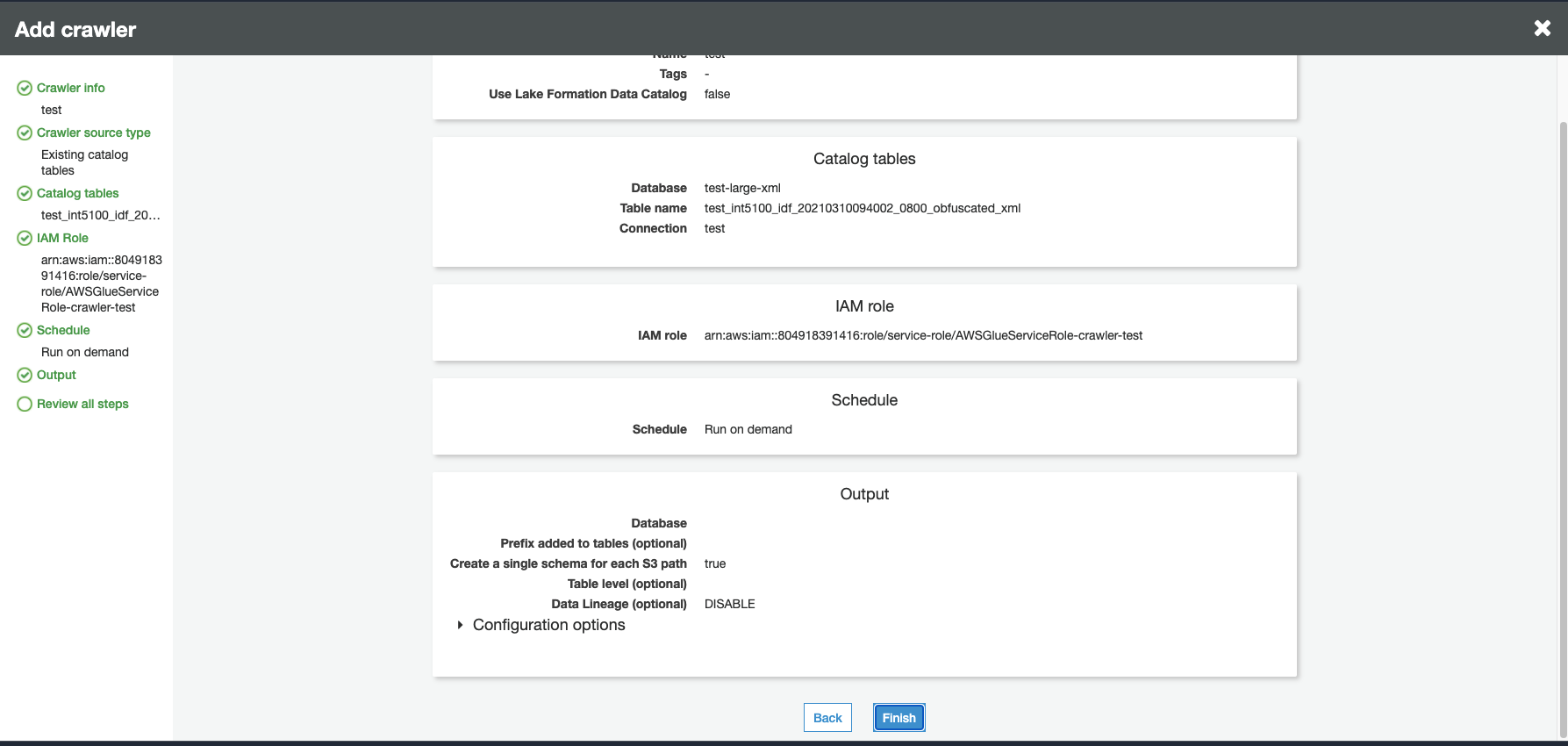
Ausführen eines Crawlers
Führen Sie Ihren Crawler aus.

Fehlerbehebung
Informationen zur Fehlerbehebung in Bezug auf Amazon S3 Buckets mit einem VPC Gateway finden Sie unter Why can't I connect to an S3 bucket using a gateway VPC endpoint? (Warum kann ich keine Verbindung zu einem S3 Bucket unter Verwendung eines Gateway-VPC-Endpunkts herstellen?)
