Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
AWS Glue Job Run Insights ist eine Funktion AWS Glue , die das Debuggen und die Optimierung von Jobs für Ihre AWS Glue Jobs vereinfacht. AWS Glue bietet die Spark-Benutzeroberfläche sowie CloudWatch Protokolle und Metriken für die Überwachung Ihrer AWS Glue Jobs. Mit dieser Funktion erhalten Sie folgende Informationen über die Ausführung Ihres AWS Glue Jobs:
Zeilennummer Ihres AWS Glue Job-Skripts, bei dem ein Fehler aufgetreten ist.
Spark-Aktion, die zuletzt im Spark-Abfrageplan kurz vor dem Fehler Ihres Auftrags ausgeführt wurde.
Spark-Ausnahmeereignisse im Zusammenhang mit dem Fehler, der in einem zeitgeordneten Protokollstream dargestellt wird.
Ursachenanalyse und empfohlene Maßnahmen (z. B. die Optimierung Ihres Skripts), um das Problem zu beheben.
Häufige Spark-Ereignisse (Protokollmeldungen in Bezug auf eine Spark-Aktion) mit einer empfohlenen Aktion, die die Ursache behandelt.
All diese Erkenntnisse stehen Ihnen mithilfe von zwei neuen Log-Streams in den CloudWatch Logs für Ihre AWS Glue Jobs zur Verfügung.
Voraussetzungen
Die Funktion „Einblicke in die AWS Glue Auftragsausführung“ ist für die AWS Glue Versionen 2.0, 3.0, 4.0 und 5.0 verfügbar. Sie können dem Migrationsleitfaden für Ihre bestehenden Jobs folgen, um sie von älteren AWS Glue Versionen zu aktualisieren.
Einblicke in die Jobausführung für einen AWS Glue ETL-Job aktivieren
Sie können Einblicke in die Jobausführung über AWS Glue Studio oder über die CLI aktivieren.
AWS Glue Studio
Wenn Sie einen Job über erstellen AWS Glue Studio, können Sie die Einblicke in die Jobausführung auf der Registerkarte Jobdetails aktivieren oder deaktivieren. Vergewissern Sie sich, dass das Feld Job-Insights generieren ausgewählt ist.

Befehlszeile
Wenn Sie einen Auftrag über die CLI erstellen, können Sie eine Auftragsausführung mit einem einzigen neuen Auftrags-Parameter starten: --enable-job-insights = true.
Standardmäßig werden die Protokoll-Streams der Auftragsausführungs-Erkenntnisse unter derselben Standardprotokollgruppe erstellt, die von Kontinuierliche AWS Glue -Protokollierung, das heißt, /aws-glue/jobs/logs-v2/ verwendet wird. Sie können benutzerdefinierte Protokollgruppennamen, Protokollfilter und Protokollgruppenkonfigurationen mit denselben Argumenten für die kontinuierliche Protokollierung einrichten. Weitere Informationen finden Sie unter Kontinuierliche Protokollierung für AWS Glue Jobs aktivieren.
Beim Zugriff auf den Job Run Insights werden Streams protokolliert in CloudWatch
Wenn das Feature „Auftragsausführungs-Erkenntnisse“ aktiviert ist, werden möglicherweise zwei Protokoll-Streams erstellt, wenn eine Auftragsausführung fehlschlägt. Wenn ein Auftrag erfolgreich abgeschlossen ist, wird keiner der Streams generiert.
Protokoll-Stream für Ausnahmeanalyse:
<job-run-id>-job-insights-rca-driver. Dieser Stream bietet Folgendes:Zeilennummer Ihres AWS Glue Job-Skripts, das den Fehler verursacht hat.
Spark-Aktion, die zuletzt im Spark-Abfrageplan (DAG) ausgeführt wurde.
Prägnante zeitgeordnete Ereignisse des Spark-Treibers und der Executors, die mit der Ausnahme zusammenhängen. Hier finden Sie Details wie vollständige Fehlermeldungen, die fehlgeschlagene Spark-Aufgabe und deren Executor-ID, die Ihnen helfen, sich bei Bedarf auf den Protokoll-Stream des jeweiligen Executors zu konzentrieren.
Regelbasierter Erkenntnis-Stream:
Ursachenanalyse und Empfehlungen zur Behebung der Fehler (z. B. Verwendung eines bestimmten Auftrags-Parameters zur Optimierung der Leistung).
Relevante Spark-Ereignisse, die als Grundlage für die Ursachenanalyse und eine empfohlene Aktion dienen.
Anmerkung
Der erste Stream wird nur vorhanden sein, wenn Spark-Ausnahme-Ereignisse für eine fehlgeschlagene Auftragsausführung verfügbar sind und der zweite Stream wird nur vorhanden sein, wenn Erkenntnisse für die fehlgeschlagene Auftragsausführung verfügbar sind. Wenn Ihr Auftrag beispielsweise erfolgreich abgeschlossen ist, wird keiner der Streams generiert. Wenn Ihr Auftrag fehlschlägt, aber keine dienstdefinierte Regel vorhanden ist, die mit Ihrem Fehlerszenario übereinstimmen kann, wird nur der erste Stream generiert.
Wenn der Job aus erstellt wurde AWS Glue Studio, sind die Links zu den oben genannten Streams auch auf der Registerkarte Job-Rundetails (Job Run Insights) als „Präzise und konsolidierte Fehlerprotokolle“ und „Fehleranalyse und Anleitung“ verfügbar.
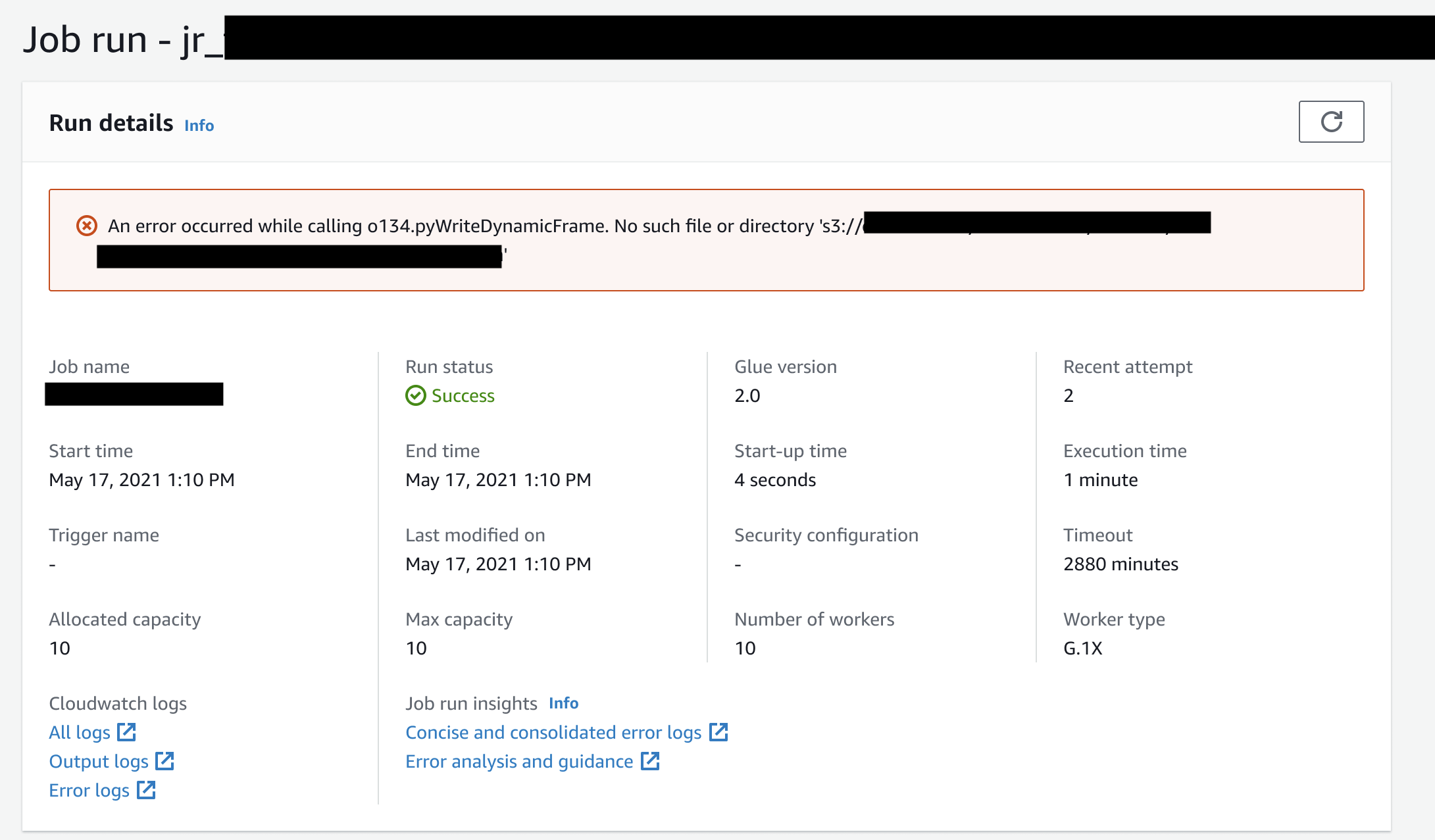
Beispiel für Einblicke in die AWS Glue Auftragsausführung
In diesem Abschnitt stellen wir Ihnen ein Beispiel vor, wie das Feature „Auftragsausführungs-Erkenntnisse“ Ihnen helfen kann, ein Problem in Ihrem fehlgeschlagenen Auftrag zu lösen. In diesem Beispiel hat ein Benutzer vergessen, das erforderliche Modul (Tensorflow) in einen AWS Glue Job zu importieren, um seine Daten zu analysieren und ein Modell für maschinelles Lernen zu erstellen.
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql.types import *
from pyspark.sql.functions import udf,col
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
data_set_1 = [1, 2, 3, 4]
data_set_2 = [5, 6, 7, 8]
scoresDf = spark.createDataFrame(data_set_1, IntegerType())
def data_multiplier_func(factor, data_vector):
import tensorflow as tf
with tf.compat.v1.Session() as sess:
x1 = tf.constant(factor)
x2 = tf.constant(data_vector)
result = tf.multiply(x1, x2)
return sess.run(result).tolist()
data_multiplier_udf = udf(lambda x:data_multiplier_func(x, data_set_2), ArrayType(IntegerType(),False))
factoredDf = scoresDf.withColumn("final_value", data_multiplier_udf(col("value")))
print(factoredDf.collect())
Ohne das Feature „Auftragsausführungs-Erkenntnisse“ wird nur die folgende Nachricht angezeigt, die von Spark ausgelöst wird, da der Auftrag fehlschlägt:
An error occurred while calling o111.collectToPython. Traceback (most recent call last):
Die Nachricht ist mehrdeutig und schränkt Ihre Debugging-Erfahrung ein. In diesem Fall bietet Ihnen diese Funktion zusätzliche Einblicke in zwei CloudWatch Protokollstreams:
Der
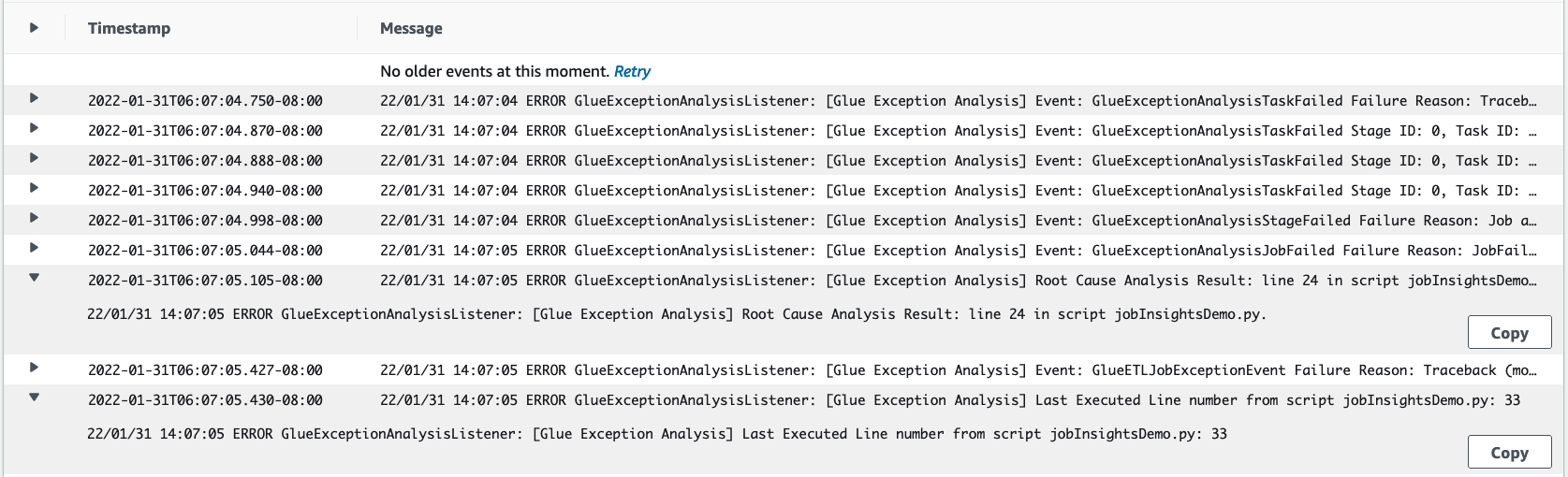
job-insights-rca-driver-Protokoll-Stream:Ausnahme-Ereignisse: Dieser Protokoll-Stream bietet Ihnen die Spark-Ausnahmeereignisse im Zusammenhang mit dem Fehler, der vom Spark-Treiber und verschiedenen verteilten Workern gesammelt wurde. Diese Ereignisse helfen Ihnen, die zeitlich geordnete Ausbreitung der Ausnahme zu verstehen, wenn fehlerhafter Code auf Spark-Aufgaben, Executoren und Stages, die auf die Worker verteilt sind, ausgeführt wird. AWS Glue
Zeilennummern: Dieser Protokoll-Stream identifiziert Zeile 21, die den Aufruf zum Importieren des fehlenden Python-Moduls gemacht hat, das den Fehler verursacht hat; Außerdem wird Zeile 24, der Aufruf von Spark Action
collect(), als die zuletzt ausgeführte Zeile in Ihrem Skript identifiziert.
Der
job-insights-rule-driver-Protokoll-Stream:Grundursache und Empfehlung: Neben der Zeilennummer und der zuletzt ausgeführten Zeilennummer für den Fehler in Ihrem Skript zeigt dieser Protokollstream die Ursachenanalyse und die Empfehlung für Sie, dem AWS Glue Dokument zu folgen und die erforderlichen Jobparameter einzurichten, um ein zusätzliches Python-Modul in Ihrem AWS Glue Job zu verwenden.
Basis-Ereignis: Dieser Protokoll-Stream zeigt auch das Spark-Ausnahmeereignis an, das mit der vom Service definierten Regel ausgewertet wurde, um die Ursache abzuleiten und eine Empfehlung abzugeben.

