翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon QuickSight で結合インターフェイスを使用して、1 つ以上のデータソースからオブジェクトを結合できます。Amazon QuickSight を使用してデータを結合することで、異なるソースのデータを複製することなく、分散したデータをマージできます。
結合されたデータセットのタイプ
2 つの QuickSight 論理テーブル間で結合が実行されます。各論理テーブルには、データのフェッチ方法に関する情報が含まれています。QuickSight でデータセットを編集する場合、ページの上半分にある結合ダイアグラムには、各論理テーブルが四角形のブロックとして表示されます。
QuickSight には、同じソースとクロスソースという 2 つの異なるタイプの結合データセットがあります。データセットは、結合がない場合、または次の条件がすべて満たされた場合に、同じソースと見なされます。
-
いずれかの論理テーブルが QuickSight データソースを参照している場合:
-
このデータセット内のすべての論理テーブルは、同じ QuickSight データソースを参照する必要があります。これは、2 つの別々の QuickSight データソースが同じ基となるデータベースを参照している場合は適用されません。これはまったく同じ QuickSight データソースである必要があります。単一データソースの使用の詳細については、「既存のデータソースを使用したデータセットの作成」を参照してください。
-
-
いずれかの論理テーブルが、親データセットである QuickSight データセットを参照している場合:
-
親データセットは直接クエリを使用する必要があります。
-
親データセットは同じ QuickSight データソースを参照する必要があります。
-
上記の条件が満たされない場合、データセットはクロスソース結合と見なされます。
データセットの結合に関する事実
同じソースのデータセット結合とクロスソースのデータセット結合には、次の制限があります。
結合データセットに含めることができるテーブルの最大数はいくつですか。
すべての結合データセットには、最大 32 個のテーブルを含めることができます。
結合データの大きさはどれくらいにできますか。
結合の最大許容サイズは、使用されるクエリモードとクエリエンジンによって決まります。以下のリストは、結合するテーブルのさまざまなサイズ制限に関する情報を示しています。サイズ制限は、すべてのセカンダリテーブルの組み合わせに適用されます。プライマリテーブルには結合サイズ制限はありません。
-
同じソーステーブル – テーブルが単一のクエリデータソースから発信された場合、QuickSight は結合サイズに制限を適用しません。ソースクエリエンジンが設定している結合サイズの制限が上書きされることはありません。
-
クロスソールのデータセット – このタイプの結合には、SPICE に保存されていないさまざまなデータソースからのテーブルが含まれます。これらのタイプの結合の場合、QuickSight はデータセット内の最大のテーブルを自動的に識別します。他のすべてのセカンダリテーブルの合計サイズは 1 GB 未満である必要があります。
-
SPICE に保存されているデータセット — このタイプの結合には、すべて SPICE に取り込まれているテーブルが含まれます。この結合内のすべてのセカンダリテーブルの合計サイズは 20 GB を超えることはできません。
SPICE データセットサイズの計算の詳細については、「SPICE データセットのサイズの推定」を参照してください。
結合されたデータセットは直接クエリを使用できますか。
同じソースのデータセットは、直接クエリの使用に関して他の制限がない場合、直接クエリをサポートします。例えば、S3 データソースは直接クエリをサポートしていないため、同じソースの S3 データセットでも SPICE を使用する必要があります。
クロスソースのデータセットは SPICE を使用する必要があります。
結合で計算フィールドを使用できますか。
すべての結合されたデータセットは計算フィールドを使用できますが、計算フィールドはどの on 句でも使用できません。
結合で地理データを使用できますか。
同じソースのデータセットは地理データ型をサポートしますが、地理フィールドはどの on 句でも使用できません。
クロスソースのデータセットは、いかなる形式でも地理データをサポートしていません。
データソース間でテーブルを結合するいくつかの例については、 AWS ビッグデータブログの「Joining across data sources on Amazon QuickSight
結合の作成
以下の手順に従って、データセットで使用するテーブルを結合します。開始する前に、データのインポートまたはデータへの接続を行います。Amazon QuickSight がサポートする任意のデータソース間の結合を作成できます (IoT データを除く)。例えば、コンマ区切り値 (.csv) ファイル、テーブル、ビュー、SQL クエリ、JSON オブジェクトを Amazon S3 バケットに追加できます。
1 つ以上のファイルを追加するには
-
使用するデータセットを開きます。
-
(オプション) 開始する前に、データのサンプルに基づいて自動生成されたプレビューを無効にするかどうかを決定します。この機能をオフにするには、右上の [Auto-preview] を選択します。これは、デフォルトで有効になっています。
-
クエリモードをまだ選択していない場合は、[Query mode]を選択します。
[SPICE] を選択してデータセットを SPICE に保存するか、[Direct query] (直接クエリ) を選択して毎回ライブデータをプルします。データセットに手動でアップロードされたファイルが 1 つ以上含まれている場合、データセットは SPICE に自動的に保存されます。
[SPICE] を選択すると、データは QuickSight に取り込まれます。データセットを使用するビジュアルは、データベースではなく SPICE でクエリを実行します。
[Direct query] (直接クエリ) を選択する場合、データは SPICE に取り込まれません。データセットを使用するビジュアルは、SPICE ではなく、データベースでクエリを実行します。
[Query mode] を選択した場合は、ビジュアルのロード時のパフォーマンスを向上するために、必要に応じて結合に一意のキーを設定してください。
-
データ準備ページで、[Add data (データの追加)] を選択します。
-
開いた [Add data] ページで、次のいずれかのオプションを選択し、次の手順を実行します。
-
データセットからデータを追加する。
-
[Dataset] を選択する。
-
リストからデータセットを選択する。
-
[選択] を選びます。
-
-
データソースからデータを追加する。
-
[Data source] を選択する。
-
リストからデータソースを選択する。
-
[選択] を選びます。
-
リストからテーブルを選択する。
-
[選択] を選びます。
-
-
複数回、テーブルを追加して自己結合を作成する。名前の後にカウンターが表示されます。例えば、[Product (製品)]、[Product (2) (製品 (2))]、[Product (3) (製品 (3))] と表示されます。特定のフィールドがどのテーブルインスタンスからのものかを確認できるように、[Fields (フィールド)] セクションや [Filters (フィルター)] セクションのフィールド名には同じカウンターが含まれるようにします。
-
[Upload a file] を選択して新しいファイルを追加し、統合するファイルを選択する。
-
-
(オプション) SQL データソースのクエリを書き込むには、[カスタム SQL の使用] を選択してクエリエディタを開きます。
-
(オプション) データを追加したら、メニューアイコンを選択して各テーブルを操作します。テーブルをドラッグアンドドロップして再配置します。
この結合を設定する必要があることを示す、赤いドットの付いたアイコンが表示されます。まだ設定されていない結合には、2 つの赤いドットが表示されます。結合を作成するには、最初の結合設定アイコンを選択します。
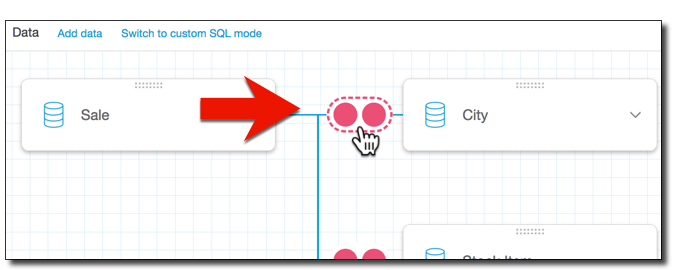
-
(オプション) 既存の結合を変更するには、2 つのテーブル間の結合アイコンを選択して、[Join configuration (結合の設定)] をもう一度開きます。
[Join configuration (結合の設定)] ペインが開きます。結合インターフェイスで、テーブルを結合するために使用する結合タイプとフィールドを指定します。
-
画面の下部に、別のテーブルのフィールドと同等のテーブルのフィールドを設定するオプションが表示されます。
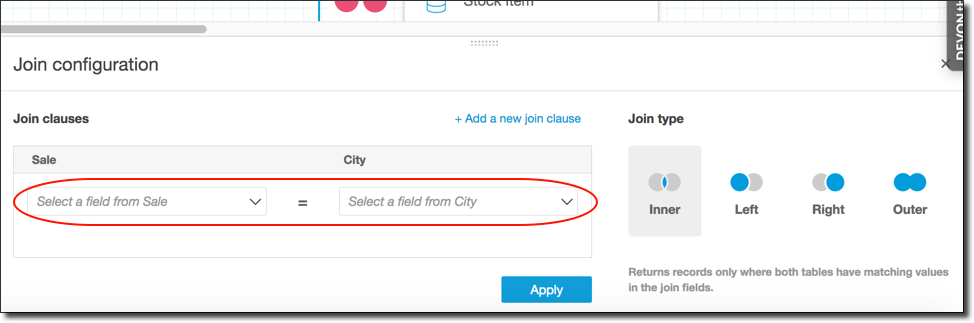
-
[Join clauses (結合句)] セクションで、各テーブルの結合列を選択します。
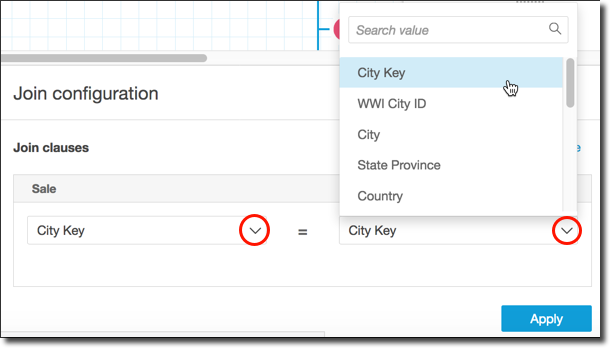
(オプション)選択したテーブルが複数の列で結合する場合は、[Add a new join clause (新しい結合句の追加)] を選択します。これにより、結合句に別の行が追加され、結合する次の列セットを指定できます。2 つのデータオブジェクトのすべての結合列を指定するまで、このプロセスを繰り返します。
-
-
[Join configuration (結合の設定)] で、適用する結合の種類を選択します。結合フィールドが一方または両方のテーブルの一意のキーである場合は、一意のキー設定を有効にします。一意のキーは直接クエリにのみ適用され、SPICE データには適用されません。
結合の詳細については、結合の種類 を参照してください。
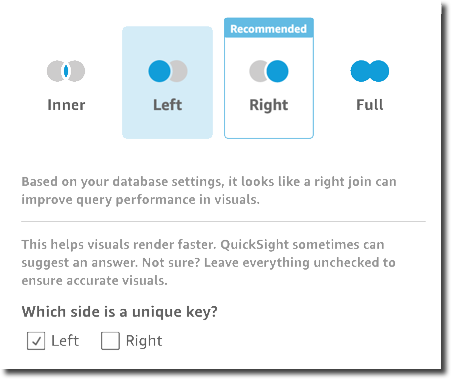
-
[Apply (適用)] を選択して選択内容を確定します。
変更を加えずに終了するには、[Cancel (キャンセル)] を選択します。
-
WorkSpace の結合アイコンが変更され、新しい関係が表示されます。
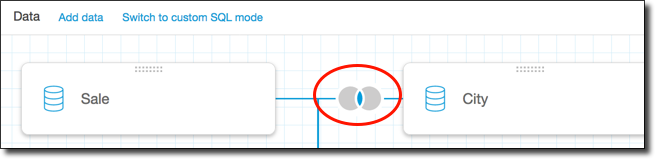
-
(オプション) [Fields (フィールド)] セクションでは、各フィールドのメニューを使用して、次の 1 つ以上の操作を実行できます。
-
地理空間フィールドに階層を追加する。
-
フィールドを含めるまたは除外する。
-
フィールドの名前および説明を編集する。
-
データ型の変更
-
計算を追加する (計算フィールド)。
-
アクセスを自分のみに制限する (自身のみがアクセスできます)。これは、すでに使用しているデータセットにフィールドを追加する場合に便利です。
-
-
(オプション) [Filters (フィルター)] セクションで、フィルターを追加または編集できます。詳細については、Amazon QuickSight でのデータのフィルタリングを参照してください。
結合の種類
Amazon QuickSight では、以下の結合タイプがサポートされています。
-
内部結合
-
左と右の外部結合
-
完全外部結合
これらの結合タイプでのデータの処理について詳しく見ていきます。このサンプルデータでは、widget と safety rating という名前の次のテーブルを使用しています。
SELECT * FROM safety-rating
rating_id safety_rating
1 A+
2 A
3 A-
4 B+
5 B
SELECT * FROM WIDGET
widget_id widget safety_rating_id
1 WidgetA 3
2 WidgetB 1
3 WidgetC 1
4 WidgetD 2
5 WidgetE
6 WidgetF 5
7 WidgetG内部結合
2 つのテーブル間で一致するデータのみを表示するには、内部結合 (
![]() ) を使用します。例えば、[safety-rating] テーブルと [widget] テーブルで内部結合を実行したとします。
) を使用します。例えば、[safety-rating] テーブルと [widget] テーブルで内部結合を実行したとします。
次の結果セットでは、安全評価のないウィジェットは削除され、関連付けられたウィジェットがない安全評価も削除されています。含まれるのは、完全に一致する行のみです。
SELECT * FROM safety-rating INNER JOIN widget ON safety_rating.rating_id = widget.safety_rating_id rating_id safety_rating widget_id widget safety_rating_id 3 A- 1 WidgetA 3 1 A+ 2 WidgetB 1 1 A+ 3 WidgetC 1 2 A 4 WidgetD 2 5 B 6 WidgetF 5
左と右の外部結合
これらは左または右の外部結合とも呼ばれます。1 つのテーブルのすべてのデータと、別のテーブルの一致する行のみを表示するには、左 (
![]() ) または右 (
) または右 (
![]() ) の外部結合を使用します。
) の外部結合を使用します。
グラフィカルインターフェイスで、右または左にあるテーブルを確認できます。SQL ステートメントでは、最初のテーブルは左側にあると見なされます。そのため、右外部結合ではなく左外部結合を選択することは、テーブルのクエリツールでの配置方法のみに依存します。
例えば、safety-rating (左のテーブル) と widgets (右のテーブル) に対して左外部結合 (
![]() ) を実行したとします。この場合、すべての
) を実行したとします。この場合、すべての safety-rating 行が返され、一致する widget 行だけが返されます。一致するデータがない箇所は結果セットで空白になります。
SELECT * FROM safety-rating LEFT OUTER JOIN widget ON safety_rating.rating_id = widget.safety_rating_id rating_id safety_rating widget_id widget safety_rating_id 1 A+ 2 WidgetB 1 1 A+ 3 WidgetC 1 2 A 4 WidgetD 2 3 A- 1 WidgetA 3 4 B+ 5 B 6 WidgetF 5
代わりに右外部結合 (
![]() ) を使用する場合は、
) を使用する場合は、safety-rating が左側、widgets が右側になるように同じ順序でテーブルを呼び出します。この場合、一致する safety-rating 行だけが返され、すべての widget 行が返されます。一致するデータがない箇所は結果セットで空白になります。
SELECT * FROM safety-rating RIGHT OUTER JOIN widget ON safety_rating.rating_id = widget.safety_rating_id rating_id safety_rating widget_id widget safety_rating_id 3 A- 1 WidgetA 3 1 A+ 2 WidgetB 1 1 A+ 3 WidgetC 1 2 A 4 WidgetD 2 5 WidgetE 5 B 6 WidgetF 5 7 WidgetG
完全外部結合
これらは単に外部結合と呼ばれることもありますが、この用語は左外部結合、右外部結合、完全外部結合のいずれかを意味する場合もあります。意味を定義するため、完全な名前の完全外部結合を使用します。
一致するデータに加えて、一致しない両方のテーブルのデータを表示するには、完全外部結合 (
![]() ) を使用します。この結合タイプには、両方のテーブルのすべての行が含まれます。例えば、
) を使用します。この結合タイプには、両方のテーブルのすべての行が含まれます。例えば、safety-rating テーブルと widget テーブルに対して完全外部結合を実行した場合、すべての行が返されます。行は一致する場所で整列されて、余分なデータはすべて別個の行に含まれます。一致するデータがない箇所は結果セットで空白になります。
SELECT * FROM safety-rating FULL OUTER JOIN widget ON safety_rating.rating_id = widget.safety_rating_id rating_id safety_rating widget_id widget safety_rating_id 1 A+ 2 WidgetB 1 1 A+ 3 WidgetC 1 2 A 4 WidgetD 2 3 A- 1 WidgetA 3 4 B+ 5 B 6 WidgetF 5 5 WidgetE 7 WidgetG
